ЮФеТФПТМ
ДЋЫЭУХ:
- РюухТлЮФОЋЖСЯЕСавЛ: ResNetЁЂTransformerЁЂGANЁЂBERT
- РюухТлЮФОЋЖСЯЕСаЖў:Vision TransformerЁЂMAEЁЂSwin-Transformer
- РюухТлЮФОЋЖСЯЕСаШ§:MoCoЁЂЖдБШбЇЯАзлЪі(аДзїжа)
вЛЁЂCLIP
ВЮПМ:
1.1 МђНщ
1.1.1 ЧАбд
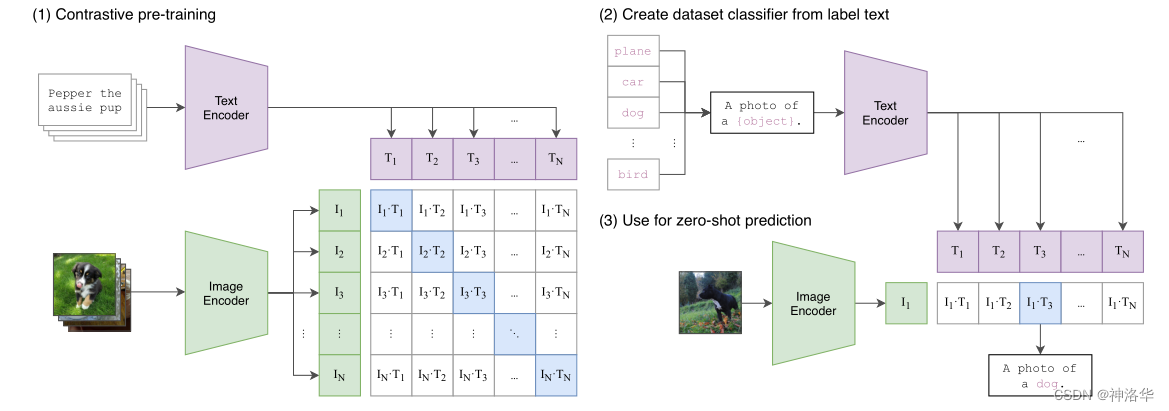
??CLIPЪЧOpenAIдк2021Фъ2дТЗЂБэЕФвЛЦЊЮФеТ,ЦфШЋГЦЮЊContrastive Language-Image Pre-training,МДвЛжжЛљгкЖдБШЮФБО-ЭМЯёЖдЕФдЄбЕСЗЗНЗЈЁЃCLIPгУЮФБОзїЮЊМрЖНаХКХРДбЕСЗПЩЧЈвЦЕФЪгОѕФЃаЭ,ЪЙЕУзюжеФЃаЭЕФzero-shotаЇЙћПАБШResNet50,ЗКЛЏадЗЧГЃКУ,ЖјЧвCLIPЛЙгаКмЖрКУЭцЕФгІгУЁЃ
??
zero-shotОЭЪЧжБНгЭЦРэ,гУМћЙ§ЕФЭМЦЌЬиеїШЅХаЖЯУЛМћЙ§ЕФЭМЦЌЕФРрБ№,ЖјЭъШЋВЛгУЯТгЮШЮЮёбЕСЗМЏНјааЮЂЕїЁЃ(ЯрЕБгкАбФЃаЭгУзїЬиеїЬсШЁ,ЕЋЪЧУЛгаЗжРрЭЗ)
??зїепдк30ЖрИіВЛЭЌЕФМЦЫуЛњЪгОѕЪ§ОнМЏЩЯНјааЛљзМВтЪд,(етаЉЪ§ОнМЏКИЧСЫOCRЁЂЪгЦЕжаЕФЖЏзїЪЖБ№ЁЂЕиРэЖЈЮЛКЭаэЖрРраЭЕФЯИСЃЖШЖдЯѓЗжРрЕШШЮЮё)CLIPЭЈГЃЖМФмЙЛгыМрЖНФЃаЭЕФbaselineаЇЙћЯрцЧУРЁЃ
??Р§ШчдкImageNetЪ§ОнМЏЩЯ,CLIPФЃаЭдкВЛЪЙгУImageNetЪ§ОнМЏЕФШЮКЮвЛеХЭМЦЌНјаабЕСЗЕФЕФЧщПіЯТ,зюжеФЃаЭОЋЖШФмИњвЛИігаМрЖНЕФбЕСЗКУЕФResNet-50ДђГЩЦНЪж(дкImageNetЩЯzero-shotОЋЖШЮЊ76.2%,етдкжЎЧАвЛЖШБЛШЯЮЊЪЧВЛПЩФмЕФ)ЁЃ
1.1.2 ФЃаЭНсЙЙ
бЕСЗЙ§ГЬ:
??ШчЯТЭМЫљЪО,CLIPЕФЪфШыЪЧвЛЖдЖдХфЖдКУЕФЕФЭМЦЌ-ЮФБОЖд(БШШчЪфШыЪЧвЛеХЙЗЕФЭМЦЌ,ЖдгІЮФБОвВБэЪОетЪЧвЛжЛЙЗ)ЁЃетаЉЮФБОКЭЭМЦЌЗжБ№ЭЈЙ§Text EncoderКЭImage EncoderЪфГіЖдгІЕФЬиеїЁЃШЛКѓдкетаЉЪфГіЕФЮФзжЬиеїКЭЭМЦЌЬиеїЩЯНјааЖдБШбЇЯАЁЃ
??МйШчФЃаЭЪфШыЕФЪЧnЖдЭМЦЌ-ЮФБОЖд,ФЧУДетnЖдЛЅЯрХфЖдЕФЭМЯёЈCЮФБОЖдЪЧе§бљБО(ЯТЭМЪфГіЬиеїОиеѓЖдНЧЯпЩЯБъЪЖРЖЩЋЕФВПЮЛ),ЦфЫќ
n
2
?
n
n^2-n
n2?nЖдбљБОЖМЪЧИКбљБОЁЃетбљФЃаЭЕФбЕСЗЙ§ГЬОЭЪЧзюДѓЛЏnИіе§бљБОЕФЯрЫЦЖШ,ЭЌЪБзюаЁЛЏ
n
2
?
n
n^2-n
n2?nИіИКбљБОЕФЯрЫЦЖШЁЃ
??
Text EncoderПЩвдВЩгУNLPжаГЃгУЕФtext transformerФЃаЭ;ЖјImage EncoderПЩвдВЩгУГЃгУCNNФЃаЭЛђепvision transformerЕШФЃаЭЁЃ
??ЯрЫЦЖШЪЧМЦЫуЮФБОЬиеїКЭЭМЯёЬиеїЕФгрЯвЯрЫЦадcosine similarity
??ЮЊСЫбЕСЗCLIP,OpenAIДгЛЅСЊЭјЪеМЏСЫЙВ4ИівкЕФЮФБО-ЭМЯёЖд,ТлЮФГЦжЎЮЊWIT(Web Image TextЁЃWITжЪСПКмИп,ЖјЧвЧхРэЕФЗЧГЃКУ,ЦфЙцФЃЯрЕБгкJFT-300M,етвВЪЧCLIPШчДЫЧПДѓЕФдвђжЎвЛ(КѓајдкWITЩЯЛЙдаг§ГіСЫDALL-EФЃаЭ)ЁЃ
ЗжРр
??CLIPПЩвджБНгЪЕЯжzero-shotЕФЭМЯёЗжРр,МДВЛашвЊШЮКЮбЕСЗКЭЮЂЕї,етвВЪЧCLIPССЕуКЭЧПДѓжЎДІЁЃгУCLIPЪЕЯжzero-shotЗжРржЛашвЊМђЕЅЕФСНВН:
- ИљОнШЮЮёЕФЗжРрБъЧЉЙЙНЈУПИіРрБ№ЕФУшЪіЮФБО:
A photo of {label},ШЛКѓНЋетаЉЮФБОЫЭШыText EncoderЕУЕНЖдгІЕФЮФБОЬиеїЁЃШчЙћРрБ№Ъ§ФПЮЊn,ФЧУДНЋЕУЕНnИіЮФБОЬиеї; - НЋвЊдЄВтЕФЭМЯёЫЭШы
Image EncoderЕУЕНЭМЯёЬиеї,ШЛКѓгыnИіЮФБОЬиеїМЦЫуЫѕЗХЕФгрЯвЯрЫЦЖШ(КЭбЕСЗЙ§ГЬБЃГжвЛжТ),ШЛКѓбЁдёЯрЫЦЖШзюДѓЕФЮФБОЖдгІЕФРрБ№зїЮЊЭМЯёЗжРрдЄВтНсЙћЁЃНјвЛВНЕи,ПЩвдНЋетаЉЯрЫЦЖШПДГЩlogits,ЫЭШыsoftmaxКѓПЩвдЕНУПИіРрБ№ЕФдЄВтИХТЪЁЃ
??ЮвУЧВЛдйашвЊдЄЯШЖЈвхКУЕФБъЧЉ(РрБ№)СаБэ,жБНгНЋЭМЦЌЮЙИјВЛЭЌЕФЮФБООфзг,ОЭПЩвджЊЕРЭМЦЌжаЪЧЗёгаЮвУЧИааЫШЄЕФЮяЬхЁЃМД,CLIPЕФЖрФЃЬЌЬиад(РћгУЮФБОМрЖНаХКХ)ЮЊОпЬхЕФШЮЮёЙЙНЈСЫЖЏЬЌЕФЗжРрЦї,ЪЙЕУФЃаЭВЛдйЪмЯогкдЄЯШЖЈвхКУЕФРрБ№,ИќМгОпгаЭЈгУадКЭПЩгУадЁЃ
??БШШчаТдіШ§ТжГЕЕФЭМЦЌЪБ,жЛашвЊдкЮФБОВПЗжвВМгЩЯШ§ТжГЕетИіРрБ№,ФЃаЭКмгаПЩФмжБНг
zero-shotЭЦРэГіЭМЦЌЪєгкШ§ТжГЕетИіРрЁЃЖјжЎЧАЕФФЃаЭ,ЪЧгРдЖВЛЛсдЄВтГіImageNet1000ИіРржЎЭтЕФРрЕФ,етвВЪЧCLIPзюЮќв§ШЫЕФЕиЗНЁЃ
??РрБ№ЕЅДЪБфГЩОфзг,гаprompt engineeringКЭprompt ensembleСНжжЗНЗЈ,НјвЛВНЬсИпФЃаЭзМШЗТЪ,дкТлЮФКѓУцЛсНВЕН
1.1.3 ФЃаЭаЇЙћ
1.1.3.1 ЖдздШЛЗжВМЦЋвЦЕФТГАєад
??ШчЯТЭМЫљЪО,зїепЛЙБШНЯСЫzero-shot CLIPгыЯжгаImageNetФЃаЭдкздШЛЗжВМЦЋвЦЩЯЕФадФмРДбщжЄЫќЕФТГАєадЁЃ
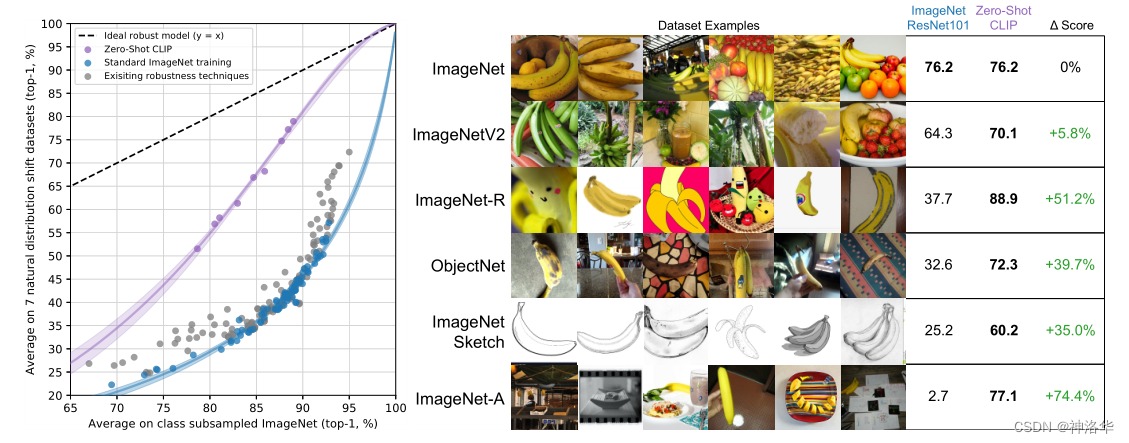
- зѓЭМЕФКсзнзјБъЪЧImageNetЕФЗжВМЦЋвЦЁЃКкЩЋащЯпЪЧРэЯыЕФТГАєФЃаЭ,ЪЧЯпадЕФЁЂе§БШР§ЕФЁЃЦеЭЈЕФФЃаЭЮоЗЈДяЕНетбљЕФРэЯыаЇЙћ,ЛГіРДЕФЧњЯпжЛЛсдкКкЩЋащЯпЕФЯТУцЁЃЕЋетРяПЩвдПДГі
zero-shot CLIPЕФТГАєадБШБъзМЕФImageNetбЕСЗЕФФЃаЭИќКУЁЃ ImageNetV2ЪЧДгImageNetЪ§ОнМЏжаЩИбЁГіаТЕФЪ§ОнМЏ,ЦфИќНгНќдРДЕФВтЪдМЏЁЃШЛЖјдкImageNetЩЯдЄбЕСЗЕФФЃаЭ,дкImageNetV2ЩЯЕФВтЪдадФмЯТНЕСЫВЛЩй(76.2Ёњ64.3)- гвЭМжа
ImageNet SketchЖМЪЧЫиУшЕФЭМЦЌЁЂImageNet-AАќКЌКмЖрЖдПЙбљБО
??CLIPКЭЛљгкImageNetЩЯгаМрЖНбЕСЗЕФResNet101,дкImageNetбщжЄМЏЖМФмДяЕН76.2%,ЕЋЪЧдкЪЃЯТЕФЮхИіЪ§ОнМЏЩЯ,ResNet101адФмЯТНЕЕУЗЧГЃРїКІ,ЕЋЪЧCLIPФмвРШЛБЃГжНЯДѓЕФзМШЗЖШЁЃБШШчдкImageNet-AЪ§ОнМЏЩЯ,ResNet101ОЋЖШжЛга2.7%,ЖјCLIPФмДяЕН77.1%ЁЃ
??етвВЫЕУїCLIPбЇЯАЕНЕФЪгОѕЬиеї,вбОКЭгябдВњЩњСЫКмЧПЕФСЊЯЕЁЃетвВВЛТлЪЧздШЛЕФЯуНЖЛЙЪЧЖЏТўРяЕФЯуНЖЁЂЫиУшЕФЯуНЖЁЂМгСЫЖдПЙбљБОЕФЯуНЖ,CLIPЖМжЊЕРЭМЦЌЪЧЖдгІЯуНЖетИіЕЅДЪЁЃ
1.1.3.2 StyleCLIP
??ЙЫУћЫМвх,етЪЧвЛЦЊCLIP+styleGANЕФЙЄзї,ПЩвдЭЈЙ§ЮФзжЕФИФБфв§ЕМЭМЯёЕФЩњГЩЁЃБШШчЯТУцР§згжа,ЪфШыЁАMohawk hairstyleЁБ,ОЭФмИФБфАТАЭТэЕФЗЂаЭ;ЪфШыЁАWithout makeupЁБ,ОЭПЩвдвЛМќаЖзАСЫ;ЪфШыЁАCute catЁБ(ПЩАЎЕФУЈ),УЈЕФблОІОЭеіДѓСЫЁЃCLIP вВФмРэНтИїжжГщЯѓзБШн,БШШчбЬбЌзБ,ЮќбЊЙэзБЁЃ

1.1.3.3 CLIPDraw
ТлЮФЁЖCLIPDraw: Exploring Text-to-Drawing Synthesis through Language-Image EncodersЁЗ

??етвВЪЧвЛИіРћгУCLIPдЄбЕСЗФЃаЭжИЕМЭМЦЌЕФЩњГЩЁЃ CLIPDrawВЛашвЊНјаабЕСЗ,ЭЈЙ§дквЛзщRGBA BЈІezierЧњЯпЩЯжДааЬнЖШЯТНЕ,ОЭПЩвдДгЮФБОКЯГЩвЛаЉМђБЪЛЭМЯёЁЃ(ФПБъЪЧзюаЁЛЏЩњГЩЭМЯёЕФCLIP encodingsгыЮФБОЬсЪОжЎМфЕФгрЯвОрРы)ЁЃ
дкЦеЭЈGPUЩЯЩњГЩвЛеХМђБЪЛЭЈГЃВЛашвЊвЛЗжжгЁЃзюКѓвЛеХЭМЕФselfБэЪОздХФее
1.1.3.4 zero-shotМьВт
ТлЮФЁЖOpen-vocabulary Object Detection via Vision and Language Knowledge DistillationЁЗ(ICLR 2022)
??CLIPПЩвдгІгУдкФПБъМьВтШЮЮёЩЯ,ЪЕЯжzero-shotМьВт,МДМьВтбЕСЗЪ§ОнМЏУЛгаАќКЌЕФРрБ№ЁЃБШШчдкCLIPГіЯжЕФвЛИіАыдТжЎКѓ,ЙШИшЬсГіЕФViLD(МћБОЮФ3.1еТНк)ЛљгкCLIPЪЕЯжСЫOpen-vocabularyЕФЮяЬхМьВт,ЦфжїЬхМмЙЙШчЯТЫљЪО,ЦфЛљБОЫМТЗКЭzero-shotЗжРрЯрЫЦ,жЛВЛЙ§етРяЪЧгУЮФБОЬиеїКЭROIЬиеїРДМЦЫуЯрЫЦЖШЁЃ
??ЯТУцЕФР§згжа,ШчЙћгУДЋЭГЕФФПБъМьВтЫуЗЈЕФЛА,ФЃаЭжЛЛсХаЖЯетаЉЮяЬхЖМЪЧЭцОп,вВОЭЪЧЭМжаРЖЩЋЕФЛљДЁРрЁЃЪЙгУCLIPжЎКѓ,ОЭПЩвдАкЭбЛљДЁРрЕФЯожЦ(Open-vocabulary Object),ПЩвдМьВтГіаТЕФРр(ЭМжаКьЩЋБъЪЖ),БШШчбеЩЋКЭЖЏЮяРрБ№ЁЃ
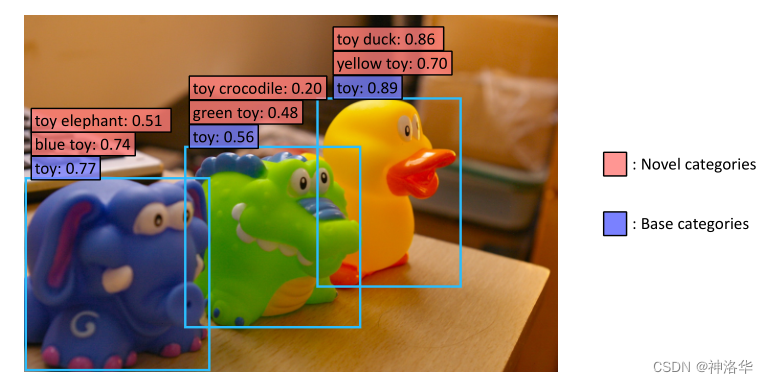
Meta AIЕФзюаТЙЄзїDeticПЩвдМьВт2000ИіРр,БГКѓвВгУЕНСЫCLIPЁЃ
1.1.3.5 CLIPЪгЦЕМьЫї
??githubЩЯjohanmodin/clifsВжПт,еЙЪОСЫЪЙгУCLIPЪгЦЕМьЫїЕФЙЄзїЁЃПЩвдЭЈЙ§ЪфШыЮФБОжБНгевЕНЪгЦЕжаГіЯжЕФЖдгІЮяЬхЁЃБШШчЪфШыЁАвЛСОгЁгаodwallaЕФПЈГЕЁБ,ОЭецЕФдкЪгЦЕжаевЕНСЫетСОПЈГЕ(CLIPАбетОфЛАБфГЩЮФБОЬиеї,ШЛКѓНЋЪгЦЕжаУПвЛжЁЖМЕБГЩЪгОѕЬиеї,ШЛКѓвЛжЁжЁЕФШЅКЭЮФБОЬиеїзіЖдБШ,ШЛКѓЬєГіЯрЫЦадзюИпЕФФЧвЛжЁ)ЁЃ

1.1.4 ЕМбд
??ЯжгаЕФCVФЃаЭЛљБОЖМЪЧЛљгкШЫЙЄБъзЂЕФЪ§ОнМЏНјаабЕСЗЕФ,ШЛКѓгУРДдЄВтвЛзщЬсЧАЖЈвхКУЕФЮяЬхРрБ№ЁЃетжжЬсЧАЖЈвхКУЕФБъЧЉМЏКЯ,ЛсДѓДѓМђЛЏЮЪЬтБОЩэ(БШШчImageNetЙЬЖЈЕФ1000ИіРр,COCOЪ§ОнМЏЙЬЖЈ80ИіРрЕШЕШ)ЁЃЕЋе§вђШчДЫ,етжжЪмЯоЕФМрЖНаХКХЯожЦСЫФЃаЭЕФЗКЛЏадКЭПЩгУадЁЃБШШчДѓЖрЪ§ФЃаЭЖМжЛФмдЄВтвбжЊЕФЭМЯёРрБ№ЁЃЖдгкУЛгаМћЙ§ЕФЭМЯёРрБ№,ашвЊЖюЭтЕФаХЯЂВХФмЪЖБ№ЁЃетбљУПДЮаТдівЛаЉРрБ№,ЖМашвЊжиаТЪеМЏЪ§Он,бЕСЗвЛИіаТЕФФЃаЭЁЃ
??ЖјЧвЮоТлЪЧгаМрЖНЛЙЪЧздМрЖНЗНЗЈ(ЛљгкЖдБШбЇЯАЕФЗНЗЈШчMoCoКЭSimCLR,КЭЛљгкЭМЯёбкТыЕФЗНЗЈШчMAEКЭBeiT),дкФЃаЭЧЈвЦЪБЖМашвЊашвЊНјаагаМрЖНЮЂЕї,БШШчЮЂЕїЙЬЖЈРрБ№ЕФsoftmaxЗжРрЦї,ЖјЮоЗЈЪЕЯжzero-shotЁЃ
??зїепШЯЮЊ,жБНгДгздШЛгябджаЕУЕНМрЖНаХЯЂЪЧвЛИіКмгаЧАЭОЕФбЁдё,вђЮЊЦфКИЧЕФЗЖЮЇИќЙу(жЛвЊЪЧгябдУшЪіЙ§ЕФЮяЬх,ЖМгаПЩФмШУЪгОѕФЃаЭШЅЪЖБ№)ЁЃCLIPРћгУЖрФЃЬЌЕФЖдБШбЇЯА,ЪЙЕУздШЛгябдПЩвдв§ЕМФЃаЭбЇЯАЕНЪгОѕИХФю,ДгЖјЪЕЯжЗЧГЃСщЛюЕФzero-shotЧЈвЦ(АбЗжРрЮЪЬтзЊЛЏЮЊСЫПчФЃЬЌМьЫїЮЪЬт)ЁЃ
??ЪЙгУздШЛгябдМрЖННјааЭМЯёБэЪОбЇЯАЕФЙЄзїКмЩй,ВЂЧваЇЙћЭљЭљВЛШчгаМрЖНФЃаЭ,жївЊгаСНИідвђ:
- дчЦкnlpФЃаЭВЛЬЋКУбЇЁЃ
БШШчдчЦкЕФn-gramФЃаЭЗЧГЃИДдг,ВЛКУПчФЃЬЌбЕСЗЁЃЕЋЪЧЫцзХtransformerЕФаЫЦ№,ЯёBERTКЭGPTетжжОпгаЩЯЯТЮФБэЪОЕФздМрЖНбЕСЗФЃаЭзіЕФдНРДдНКУ,nlpФЃаЭвВжегкгаСЫШЁжЎВЛОЁЕФЮФБОМрЖНаХКХ,ЖјЧвЪЙгУМђЕЅ,ЗКЛЏадКУ,ЮЊЖрФЃЬЌбЕСЗЦЬЦНСЫЕРТЗЁЃ - Ъ§ОнМЏЛђФЃаЭЕФЙцФЃВЛЙЛЁЃ
БШШчVirTexКЭICMLMЖМжЛбЕСЗСЫЪЎМИЭђЕФЭМЦЌ;ConVIRTЗЧГЃРрЫЦCLIP,ЕЋжЛдквНСЦЭМЯёЩЯзіСЫдЄбЕСЗЁЃДгБОжЪЩЯРДНВ,CLIPЦфЪЕВЂУЛгаЬЋДѓЕФДДаТ,ЫќжЛЪЧНЋConVIRTЗНЗЈНјааМђЛЏ,ВЂВЩгУИќДѓЙцФЃЕФЮФБО-ЭМЯёЖдЪ§ОнМЏРДбЕСЗЁЃвВПЩвдЫЕ,ЯрЖдгкжЎЧАЕФЖдБШбЇЯА,CLIPжЛЪЧНЋЕЅФЃЬЌЕФбљБО,ЛЛГЩСЫЖрФЃЬЌЕФбљБОЁЃ
1.2 ЗНЗЈ
1.2.1 здШЛгябдМрЖНЕФгХЪЦ
ЪЙгУздШЛгябдМрЖНаХКХРДбЕСЗЪгОѕФЃаЭ,гаСНИізюживЊЕФгХЪЦ:
-
ВЛашвЊВЩгУЬиБ№ЕФБъзЂЪ§Он,РЉеЙадИќЧПЁЃ
БШШчImageNetашвЊЯШЖЈвхКУ1000ИіРр,ШЛКѓИљОнетаЉРрШЅЯТдиЭМЦЌ,ЧхРэЪ§ОнМЏ,дйШЅБъзЂЫљгаЭМЦЌ,Й§ГЬКмИДдгЁЃЖјCLIPВЛвЊЧѓетжжОЕфЕФЁАЁБЛњЦїбЇЯАМцШнЁАЁБЕФБъзЂИёЪН,жЛашвЊЯТдиЮФзж-ЭМЦЌЖд;ЧвУЛгаnбЁ1ЕФБъЧЉжЎКѓ,ФЃаЭЕФЪфШыЪфГіздгЩЖШДѓСЫКмЖрЁЃ -
CLIPбЇЯАЕНЕФЪЧЭМЯёНсКЯЮФзжЕФЖрФЃЬЌЬиеї,ДгЖјЪЕЯжСщЛюЕФzero-shotЧЈвЦЁЃШчЙћжЛЪЧЕЅФЃЬЌЕФЬиеї,ЮоТлЪЧРрЫЦMOCOЛЙЪЧMAE,ЖМКмФбзіЕНетвЛЕу(zero-shotБиаывЊМгШыЮФзжЬиеїВХФмзіЕН)ЁЃ
1.2.2 дЄбЕСЗЗНЗЈ(бЕСЗаЇТЪжСЙиживЊ)
??CVСьгђЕФФЃаЭЖМКмДѓ,бЕСЗЦ№РДвВКмЙѓЁЃБШШчnoise studentжЎЧАдкImageNetвЛжБАдАё,ЕЋЪЧетИіФЃаЭашвЊдквЛИі TPUv3ЩЯбЕСЗ33Фъ,етЛЙжЛЪЧдкАќКЌ1000РрЕФImageNetЩЯдЄбЕСЗЕФ,ЖјЧвжЛбЕСЗЪгОѕЬиеїЁЃ
??гЩгкбЕСЗЪ§ОнСПКЭФЃаЭМЦЫуСПЖМКмДѓ,бЕСЗаЇТЪГЩЮЊвЛИіжСЙиживЊЕФвђЫиЁЃзїепзіСЫКмЖрГЂЪд,зюжебЁдёСЫЖдБШбЇЯА:
VirTexФЃаЭ:дЄВтЮФБО,ЖдгІЯТЭМРЖЩЋЯпTransformer Language ModelImage EncoderЪЙгУCNNФЃаЭ,Text EncoderЪЙгУtransformerФЃаЭ,СНИіФЃаЭвЛЦ№ДгЭЗбЕСЗ,ШЮЮёЪЧдЄВтЭМЦЌЖдгІЕФЮФБО(image caption)ЁЃ- етжжЗНЗЈЕФбЕСЗаЇТЪЬЋТ§,вђЮЊИљОнЭМЦЌНјааЮФБОУшЪі,ПЩФмадЬЋЖрСЫ,ФуПЩвдДгИїИіНЧЖШШЅУшЪівЛеХЭМЦЌЁЃ
Bag of Words Prediction(щйЩЋЯп):ВЛвЊЧѓУПИіДЪЖМЪЧАДЫГађЕФНјаадЄВт,ЫљгаДЪЖМдЄВтГіРДОЭааЁЃетбљЗХПэСЫдМЪј,бЕСЗЫйЖШЬсИпСЫШ§БЖЁЃCLIP:МђЛЏАцЕФConVIRT,ЛљгкЖдБШбЇЯАЁЃ- жЛашвЊХаЖЯЭМЮФЪЧЗёХфЖд,НјвЛВНМђЛЏСЫбЕСЗШЮЮё,бЕСЗаЇТЪвЛЯТзгЬсЩ§4БЖ(ТЬЩЋЯп)
- бЕСЗШЮЮёИќМгКЯРэЁЃвђЮЊбЕСЗЪ§ОнЫљАќКЌЕФЮФБО-ЭМЯёЖдЪЧДгЛЅСЊЭјЪеМЏРДЕФ,ЫќУЧДцдквЛЖЈЕФдывє,ЖўепВЂВЛЭъШЋЦЅХфЁЃЪЪЕБЕФНЕЕЭбЕСЗФПБъ,ЗДЖјФмШЁЕУИќКУЕФЪеСВЁЃ

??OpenAIЪЧвЛМвGPTЛЏЕФЙЋЫО,ДгGPTЯЕСаЁЂDALL-EЕНImage-GPTЕШЕШЖМЪЧЛљгкGPTзіЕФ,ЮЈга
CLIPвђЮЊаЇТЪЕФдвђ,бЁдёСЫЖдБШбЇЯАНјаабЕСЗЁЃ
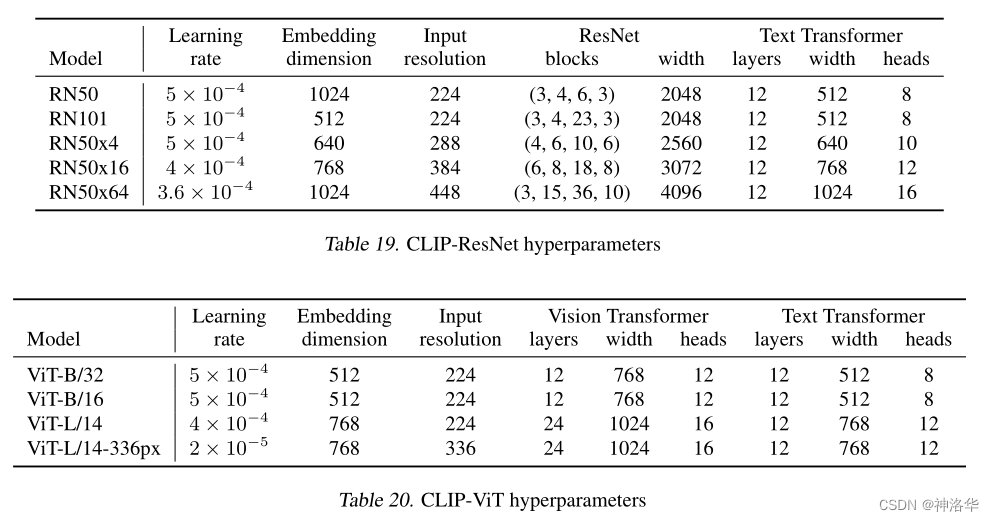
??зюжеText EncoderЙЬЖЈбЁдёвЛИіАќКЌ63MВЮЪ§ЕФtext transformerФЃаЭ,ЖјImage EncoderВЩгУСЫСНжжЕФВЛЭЌЕФМмЙЙЁЃвђЮЊCLIPЫфШЛЪЧЖрФЃЬЌФЃаЭ,ЕЋЫќжївЊЪЧгУРДбЕСЗПЩЧЈвЦЕФЪгОѕФЃаЭЁЃ
Image EncoderМмЙЙ- ResNet:ResNet50,ResNet101,RN50x4,RN50x16КЭRNx64(КѓУцШ§ИіФЃаЭЪЧАДееEfficientNetЫѕЗХЙцдђЖдResNetЗжБ№діДѓ4x,16xКЭ64xЕУЕН)
- ViT:ViT-B/32,ViT-B/16КЭViT-L/14ЁЃ
- ЫљгаЕФФЃаЭЖМбЕСЗ32Иіepochs,ВЩгУAdamWгХЛЏЦї,batch size=32768ЁЃ
- жЛдкResNet50ЩЯбЕСЗвЛИіepochНјааГЌВЮЫбЫї,УЛгаНјааНјвЛВНЕФЕїВЮ
- СНИізюДѓЕФФЃаЭRN50x64ашвЊдк592ИіV100ПЈЩЯбЕСЗ18Ьь,ViT-L/14ашвЊдк256еХV100ПЈЩЯбЕСЗ12Ьь
- ViT-L/14аЇЙћзюКУ,ЫљвдзїепЛЙНЋЦфдк336ЕФЗжБцТЪЯТЖюЭтfinetuneСЫвЛИіepochРДдіЧПадФм,МЧЮЊ
ViT-L/14@336pxЁЃКѓУцТлЮФжаУЛгаЬиБ№ЫЕУїЕФЧщПіЯТ,НјааЖдБШЪЕбщЕФCLIPФЃаЭЖМЪЧжИетИіЁЃ
- бЕСЗЯИНк
- Ъ§ОнМЏЗЧГЃДѓ,МИКѕВЛЛсГіЯжЙ§ФтКЯ,Ыљвд
Image EncoderКЭText EncoderВЛашвЊЬсЧАНјаадЄбЕСЗЁЃ - жЛЪЙгУЯпадЭЖЩфВу(ЯпадЗЧЯпадгАЯьВЛДѓ)ЁЃ
- Ъ§ОндіЧПжЛЪЙгУЭМЦЌЕФЫцЛњМєВУ,етЪЧвђЮЊЪ§ОнМЏЗЧГЃДѓЁЃ
- ЖдБШбЇЯАФПБъКЏЪ§жаЕФГЌВЮЪ§
Іг,ЩшжУГЩПЩбЇЯАЕФБъСП,дкбЕСЗжаздЖЏгХЛЏ,ЖјВЛгУТ§Т§ЕїВЮ(ЛЙЪЧвђЮЊЪ§ОнМЏЬЋДѓ,бЕСЗКмЙѓ)ЁЃ
- Ъ§ОнМЏЗЧГЃДѓ,МИКѕВЛЛсГіЯжЙ§ФтКЯ,Ыљвд
??СэЭтЛЙгаКмЖрЕФбЕСЗЯИНк,ВХЪЙЕУCLIPеце§ФмБЛбЕСЗГіРДЁЃбЕСЗГЌДѓФЃаЭ,ПЩвдВЮПМРДздOpenAIЕФВЉЮФ:ЁЖHow to Train Really Large Models on Many GPUs?ЁЗМАЖдгІЕФCSDNЗвыЁЃ
1.2.3 ЮБДњТы
# image_encoder - ResNet or Vision Transformer
# text_encoder - CBOW or Text Transformer
# I[n, h, w, c] - ЪфШыЭМЦЌЮЌЖШ
# T[n, l] - ЪфШыЮФБОЮЌЖШ,lБэЪОађСаГЄЖШ
# W_i[d_i, d_e] - learned proj of image to embed
# W_t[d_t, d_e] - learned proj of text to embed
# t - learned temperature parameter
# ЗжБ№ЬсШЁЭМЯёЬиеїКЭЮФБОЬиеї
I_f = image_encoder(I) #[n, d_i]
T_f = text_encoder(T) #[n, d_t]
# ЖдСНИіЬиеїНјааЯпадЭЖЩф,ЕУЕНЯрЭЌЮЌЖШЕФЬиеїd_e,ВЂНјааl2ЙщвЛЛЏ,БЃГжЪ§ОнГпЖШЕФвЛжТад
# ЖрФЃЬЌembedding [n, d_e]
I_e = l2_normalize(np.dot(I_f, W_i), axis=1)
T_e = l2_normalize(np.dot(T_f, W_t), axis=1)
# МЦЫуЫѕЗХЕФгрЯвЯрЫЦЖШ:[n, n]
logits = np.dot(I_e, T_e.T) * np.exp(t)
# symmetric loss function
labels = np.arange(n) # ЖдНЧЯпдЊЫиЕФlabels
loss_i = cross_entropy_loss(logits, labels, axis=0) # image loss
loss_t = cross_entropy_loss(logits, labels, axis=1) # text loss
loss = (loss_i + loss_t)/2 # ЖдГЦЪНЕФФПБъКЏЪ§
??дкMOCOжа,ецЪЕБъЧЉЖМЪЧ0,вђЮЊЦфе§бљБОЖМЪЧЗХдкЕквЛЮЛ,Ыљвде§бљБОЖдгІЕФЫїв§гРдЖЪЧ0;ЕЋЪЧдкCLIPжа,е§бљБОЖМЪЧдкЖдНЧЯпЩЯ,МД(
I
1
,
T
1
I_1,T_1
I1?,T1?,
I
2
,
T
2
I_2,T_2
I2?,T2?,Ё),ЫљвдецЪЕБъЧЉЮЊnp.arange(n)ЁЃ
1.3 ЪЕбщ
1.3.1 zero-shot ЧЈвЦ
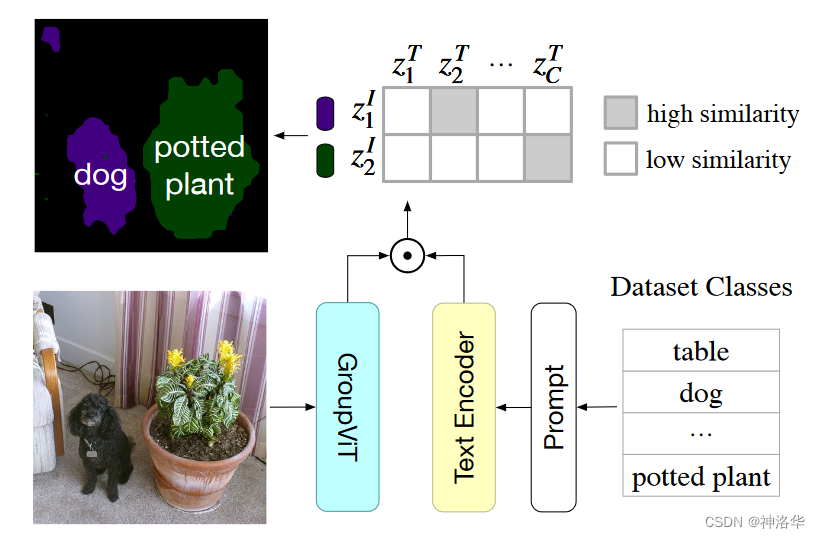
??баОПzero-shotЕФЖЏЛњ:жЎЧАЕФздМрЖНЛђгаМрЖНбЕСЗЕФФЃаЭ(MOCOЁЂDINOЕШ),жївЊЪЧбЇЯАвЛжжЗКЛЏКУЕФЬиеї,ЫљвддкзіЯТгЮШЮЮёЕФЪБКђ,ЛЙЪЧашвЊгаМрЖНЕФЮЂЕї,ОЭвРШЛДцдкКмЖрЮЪЬтЁЃБШШчЯТгЮШЮЮёЕФЪ§ОнМЏВЛКУЪеМЏ,ДцдкЗжВМЦЎЦЋвЦ(distribution shift)ЕШЕШЁЃЖјЪЙгУЮФБОв§ЕМЪгОѕФЃаЭбЕСЗ,ОЭПЩвдКмКУЕФНјааzero-shotЧЈвЦ;ФЃаЭОЭПЩвдВЛдйбЕСЗ,ВЛдйЮЂЕїЁЃ
ШчКЮгУCLIPЪЕЯжzero-shotЗжРр?
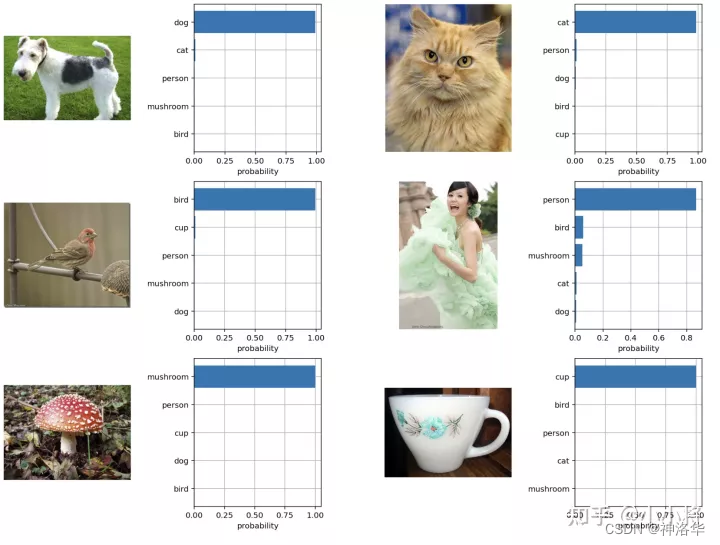
??етРяЮвУЧИјГіСЫвЛИіЛљгкCLIPЕФвЛИіЪЕР§(ВЮПМЙйЗНnotebook),етРяШЮЮёЙВга6ИіРрБ№:ЁАdogЁБ, ЁАcatЁБ, ЁАbirdЁБ, ЁАpersonЁБ, ЁАmushroomЁБ, ЁАcupЁБ,ЪзЯШЮвУЧДДНЈЮФБОУшЪі,ШЛКѓЬсШЁЮФБОЬиеї:
# ЪзЯШЩњГЩУПИіРрБ№ЕФЮФБОУшЪі
labels = ["dog", "cat", "bird", "person", "mushroom", "cup"]
text_descriptions = [f"A photo of a {label}" for label in labels]
text_tokens = clip.tokenize(text_descriptions).cuda()
# ЬсШЁЮФБОЬиеї
with torch.no_grad():
text_features = model.encode_text(text_tokens).float()
text_features /= text_features.norm(dim=-1, keepdim=True)
??ШЛКѓЮвУЧЖСШЁвЊдЄВтЕФЭМЯё,ЪфШыImage EncoderЬсШЁЭМЯёЬиеї,ВЂМЦЫугыЮФБОЬиеїЕФгрЯвЯрЫЦЖШ:
# ЖСШЁЭМЯё
original_images = []
images = []
texts = []
for label in labels:
image_file = os.path.join("images", label+".jpg")
name = os.path.basename(image_file).split('.')[0]
image = Image.open(image_file).convert("RGB")
original_images.append(image)
images.append(preprocess(image))
texts.append(name)
image_input = torch.tensor(np.stack(images)).cuda()
# ЬсШЁЭМЯёЬиеї
with torch.no_grad():
image_features = model.encode_image(image_input).float()
image_features /= image_features.norm(dim=-1, keepdim=True)
# МЦЫугрЯвЯрЫЦЖШ(ЮДЫѕЗХ)
similarity = text_features.cpu().numpy() @ image_features.cpu().numpy().T
??НјвЛВНЕи,ЮвУЧвВПЩвдЖдЕУЕНЕФгрЯвЯрЫЦЖШМЦЫуsoftmax,ЕУЕНУПИідЄВтРрБ№ЕФИХТЪжЕ,зЂвтетРявЊЖдЯрЫЦЖШНјааЫѕЗХ:
logit_scale = np.exp(model.logit_scale.data.item())
text_probs = (logit_scale * image_features @ text_features.T).softmax(dim=-1)
top_probs, top_labels = text_probs.cpu().topk(5, dim=-1)
??ЕУЕНЕФдЄВтИХТЪШчЯТЫљЪО,ПЩвдПДЕН6ИіЭМЯё,CLIPФЃаЭОљФмЙЛвдОјЖдЕФжУаХЖШИјГіе§ШЗЕФЗжРрНсЙћ:
1.3.2 Prompt Engineering and Ensembling
- Prompt Engineering
??зїепЛЙбщжЄСЫЮФБОУшЪіЪБВЩгУpromptЕФгааЇад(ОЋЖШЬсЩ§1.3%)ЁЃМђЕЅРДЫЕ,prompt learningЕФКЫаФЪЧЭЈЙ§ЙЙНЈКЯЪЪprompt(ЬсЪО)РДЪЙдЄбЕСЗФЃаЭФмЙЛжБНггІгУЕНЯТгЮШЮЮёжаЁЃ
ЭЦРэЪБ,жЛЪЙгУРрБ№БъЧЉзїЮЊЮФБОУшЪіаЇЙћВЂВЛЙЛКУ,двђгаЖў:
-
ДЪгяДцдкЦчвхад
ШчЙћЮвУЧжБНгВЩгУРрБ№БъЧЉзїЮЊЮФБОУшЪі,ФЧУДКмЖрЮФБООЭЪЧвЛИіЕЅДЪ,ШБЩйОпЬхЕФЩЯЯТЮФ,ВЂВЛФмКмКУЕФУшЪіЭМЦЌФкШнЁЃ-
БШШчдкзіЮяЬхМьВтЪБ,гавЛИіРрБ№ЪЧremote(вЃПиЦї)ЁЃЕЋШчЙћжБНгЮЙИјЮФБОБрТыЦї,КмПЩФмБЛФЃаЭШЯЮЊЪЧвЃдЖЕФвтЫМЁЃ
-
ЭЌвЛИіДЪгядкВЛЭЌЪ§ОнМЏжаЫљБэЪОЕФвтЫМПЩФмгаЫљВЛЭЌЁЃР§Шчдк Oxford-IIIT Pets Ъ§ОнМЏжа,boxerжИЕФЪЧЙЗЕФвЛИіжжРр,дкЦфЫћЪ§ОнМЏжажИЕФЪЧШЛїдЫЖЏдБЁЃ
-
Ыљвд CLIPдЄбЕСЗЪБ,гУРДУшЪіЭМЦЌФкШнЕФЮФБОЪЧвЛИіОфзг,БШШч
A photo of {label}ЁЃетРяЕФlabelОЭжЛФмЪЧУћДЪ,вЛЖЈГЬЖШЩЯЯћГ§СЫЦчвхадЁЃ
-
-
ЪЙЭЦРэКЭдЄбЕСЗЪББЃГжвЛжТ(ЯћГ§distribution gap)ЁЃ
??СэЭт,ЛЙПЩвдИљОнВЛЭЌЕФЪ§ОнМЏРДЕїећетИіФЃАх,НјЖјЬсЩ§zero-shotЕФадФмЁЃ
??Р§ШчЕБЪ§ОнМЏЪЧOxford-IIIT PetsЪ§ОнМЏЪБ(РрБ№ЖМЪЧЖЏЮя),ОЭПЩвдНЋФЃАхаДГЩ: A photo of a {label}, a type of pet. ;ЛђепдкзіOCRШЮЮёЪБ,дкЯыевЕФФЧИіЮФБОЛђепЪ§зжЩЯДђЩЯЫЋв§КХ,ФЃаЭОЭПЩФмжЊЕРФуЪЧЯыевЫЋв§КХРяУцЕФФкШнЁЃ
- prompt ensembling
??зїепГЂЪдСЫМЏГЩЖрИіФЃАхЕФаЇЙћ,МДдкЖрИіzero-shotЗжРрЦїЩЯНјааМЏГЩ,етаЉЗжРрЦїЪЙгУВЛЭЌЕФЬсЪОФЃАхРДЙЙдьВЛЭЌЕФЮФБОЁЃгЩгкЪЧдкЧЖШыПеМф(embedding space)ЖјВЛЪЧИХТЪПеМф(probability space)ЩЯМЏГЩЕФ,вђДЫНкдМСЫМЦЫуГЩБОЁЃдкДѓЖрЪ§Ъ§ОнМЏЩЯ,prompt ensemblingЖМФмЙЛЬсЩ§ФЃаЭадФмЁЃ
??зюжезїепЪЙгУСЫ80жжФЃАхРДНјааМЏГЩ,УПжжФЃАхЪЙгУСЫВЛЭЌЕФаЮШнДЪ,РД,УшЪіВЛЭЌЕФЧщОГЁЃ
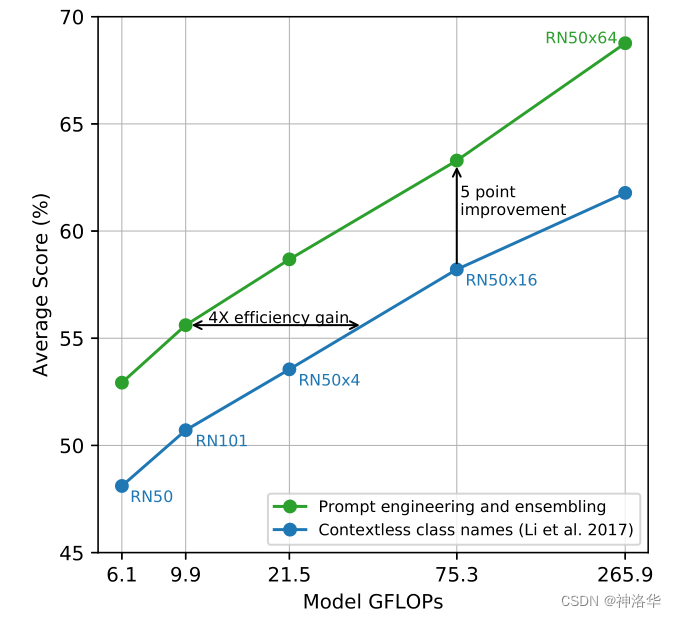
??ЩЯЭМКсзјБъБэЪОФЃаЭЫуСІ,знзјБъБэЪОдкЖрИіЪ§ОнМЏЩЯЕФЦНОљЗжЪ§ЁЃТЬЩЋЧњЯпБэЪОБОЮФжаЪЙгУPrompt engineering and ensemblingЕФНсЙћ,РЖЩЋЧњЯпБэЪОжБНгЪЙгУЮоЬсЪОЩЯЯТЮФЕФРрУћЕФНсЙћЁЃ
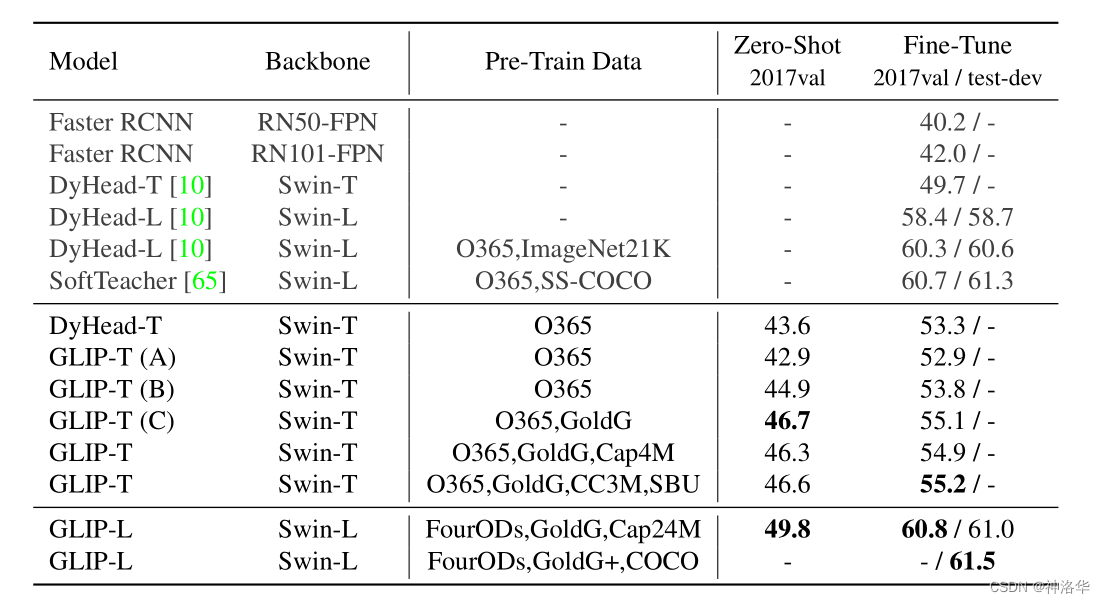
3.3.3 zero-shotЗжРраЇЙћЖдБШ(ResNet-50)
??ЮЊСЫВтЪдCLIPЕФzero-shotЗжРрЕФаЇЙћдѕУДбљ,зїепНЋдк27ИіЪ§ОнМЏЩЯЕФЗжРраЇЙћзіГЩСЫЖдБШЭМ,ЯТЭМОЭЪЧCLIPгыЛљгкResNet-50зіLinear ProbeЕФЖдБШЁЃ
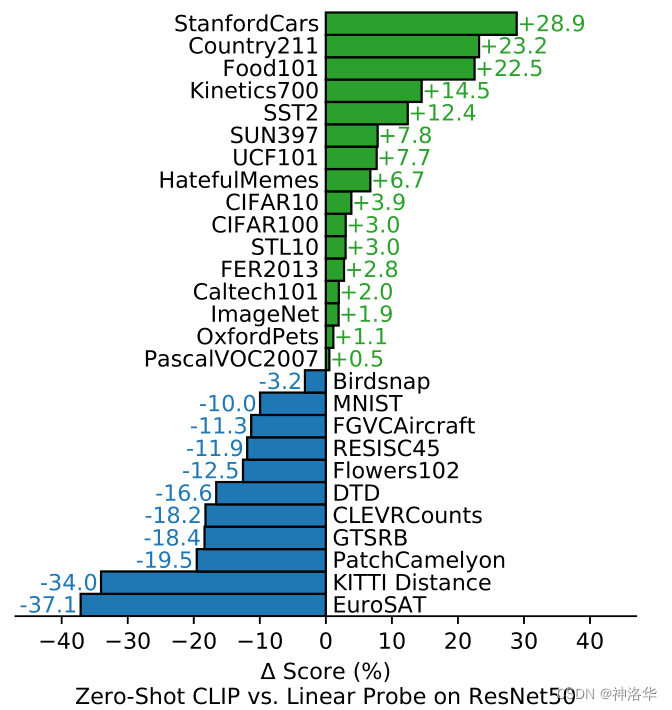
- Linear Probe on ResNet-50:
- Linear ProbeОЭЪЧЖГзЁдЄбЕСЗКУЕФФЃаЭ,жЛбЕСЗзюКѓвЛВуЕФЗжРрЦї,ЯрЕБгкНЋдЄбЕСЗФЃаЭзіЬиеїЬсШЁЦїЁЃ
- ResNet50ЪЧдкImageNetЩЯгУгаМрЖНЕФЗНЪНдЄбЕСЗКУЕФ
- ЖдБШНсЙћ:
-
ТЬЩЋ + БэЪОЯрБШResNet-50ЬсЩ§СЫЖрЩй,РЖЩЋ - БэЪОЯрБШResNet-50НЕЕЭСЫЖрЩйЁЃ
-
зюжедк27ИіЪ§ОнМЏжа,CLIPдк16ИіЪ§ОнМЏЩЯЖМГЌдНСЫгаМрЖНбЕСЗКУЕФResNet-50ЁЃ
-
ЖдгкЦеЭЈЕФЮяЬхЗжРрШЮЮё,CLIPПЩвдКмКУЕФзіzero-shotЧЈвЦ,Р§ШчГЕЁЂЪГЮяЁЂCIFAR10ЕШЪ§ОнМЏ,вђЮЊЭМЯёжагаПЩвдУшЪіГіРДЕФЮяЬх,ФЧЖдгІЕФЮФБОжавВОЭгаетжжУшЪі,вђДЫПЩвдКмКУЕФЦЅХф;
-
ЕЋCLIPЖдгкИќМгИДдгЛђГщЯѓЕФШЮЮёОЭБэЯжБШНЯШѕ,Р§ШчЮРаЧЭМЯёЗжРрЁЂСмАЭНсжзСіМьВтЕШашвЊЬиЖЈСьгђжЊЪЖЕФЗжРрШЮЮё,CLIPВЂУЛгадЄбЕСЗЕНетаЉБъЧЉаХЯЂЁЃ
-
1.3.4 few-shotЗжРраЇЙћЖдБШ
??зїепШЯЮЊ,етжжЬиБ№ФбЕФШЮЮё,ЭъШЋВЛИјШЮКЮБъЧЉаХЯЂ,гаЕуЧПШЫЫљФбСЫ,ВЛЪЧКмКЯРэЁЃЫљвдТлЮФЛЙЖдБШfew-shotадФм,МДжЛгУЩйСПЕФбљБОРДЮЂЕїФЃаЭ,етРяЖдБШСЫ3ИіФЃаЭ:
- дкImageNet21KЩЯбЕСЗЕФ
BiT-M(big transfer),ЪЧвЛИіКмЧПЕФbaselineЁЃ - ЛљгкSimCLRv2бЕСЗЕФResNet50,
- гаМрЖНбЕСЗЕФResNet50ЁЃ

- КсзјБъ:УПИіЪ§ОнМЏУПИіРрБ№Ря,гУСЫЖрЩйИіБъзЂбљБОНјааLinear ProbeЕФЗжРрЦїбЕСЗЁЃ0ОЭЯрЕБгк
zero-shotСЫЁЃ - знзјБъБэЪОдк20ИіЪ§ОнМЏЩЯЕФЦНОљЗжРрзМШЗЖШ(га7ИіЪ§ОнМЏУПИіРрБ№ВЛЙЛ16Иі)
- ЕБУПРрга16ИібЕСЗбљБОЪБ,
BiT-MФЃаЭЕФадФмВХКЭzero-shot CLIPДђГЩЦНЪжЁЃ - зЯЩЋЧњЯпЫЕУї:УПРрЕФбЕСЗбљБОжЛга1ИіЛђ2ИіЕФЪБКђ,аЇЙћЛЙВЛШчzero-shot CLIP;ЕЋЕБУПРрЕФбЕСЗбљБОдіМгЕН8ИіЛђ16ИіЕФЪБКђ,аЇЙћдђГЌдНСЫzero-shot CLIPЁЃетЫЕУїЖдгквЛаЉФбЕФЪ§ОнМЏРДЫЕ,гавЛаЉбЕСЗбљБОЛЙЪЧЗЧГЃгаБивЊЕФЁЃ
??CLIPдкзі
Linear ProbeЕФЪБКђ,ашвЊШгЕєЮФБОБрТыЦїВПЗж,НгзХдкЭМЯёБрТыЦїжЎКѓМгвЛВуЯпадЗжРрЦї,ЫљвдЗжРрЗНЪНВЛдйЪЧПДЭМЯёЬиеїгыЮФБОЬиеїзюЯрНќ,ЖјЪЧжиаТбЕСЗвЛИіЯпадЗжРрЦї.
??аТМгЕФвЛВуЯпадЗжРрЦїЪЧЫцЛњГѕЪМЛЏЕФ,ЫљвдУПРрга1ИіБъзЂбљБОЪЧВЛЙЛЕФЁЃетвВЪЧЮЊЪВУДвЛПЊЪМадФмЛсБШНЯВю,ЕЋЫцзХбЕСЗбљБОЕФдіЖр,ФЃаЭЕФЗжРрадФмЛсж№НЅЬсЩ§ЁЃ
1.3.5 Linear probe CLIPЖдБШ
??ЖдБШЭъСЫzeroЈCshotКЭfew-shot,ЯТУцздШЛОЭЪЧФУЯТгЮШЮЮёЕФЫљгабЕСЗМЏРДбЕСЗ,НјаааЇЙћЖдБШСЫЁЃзїепдкетРябЁдёLinear probe CLIPЕФЗНЪНЁЃ
??жЎЫљвдбЁдёLinear probeЖјВЛЪЧЮЂЕї,вђЮЊLinear probeжЛгазюКѓвЛВуFCЪЧПЩвдбЕСЗЕФ,ПЩбЇЯАЕФПеМфБШНЯаЁ,ЯрБШЮЂЕїУЛФЧУДСщЛюЁЃШчЙћдЄбЕСЗФЃаЭУЛгабЕСЗКУЕФЛА,дкЯТгЮШЮЮёЩЯбЕСЗдйОУвВКмФбгХЛЏЕНвЛИіЬиБ№КУЕФНсЙћ,ЫљвдгУLinear probeФмИќзМШЗЕФЗДгГдЄбЕСЗФЃаЭЕФКУЛЕЁЃСэвЛИідвђОЭЪЧLinear probeВЛашвЊдѕУДЕїВЮ(вђЮЊЮЂЕїЕФЛА,ВЛЭЌЪ§ОнМЏПЩЕїЕФВЮЪ§ОЭЬЋЖрСЫ)ЁЃ
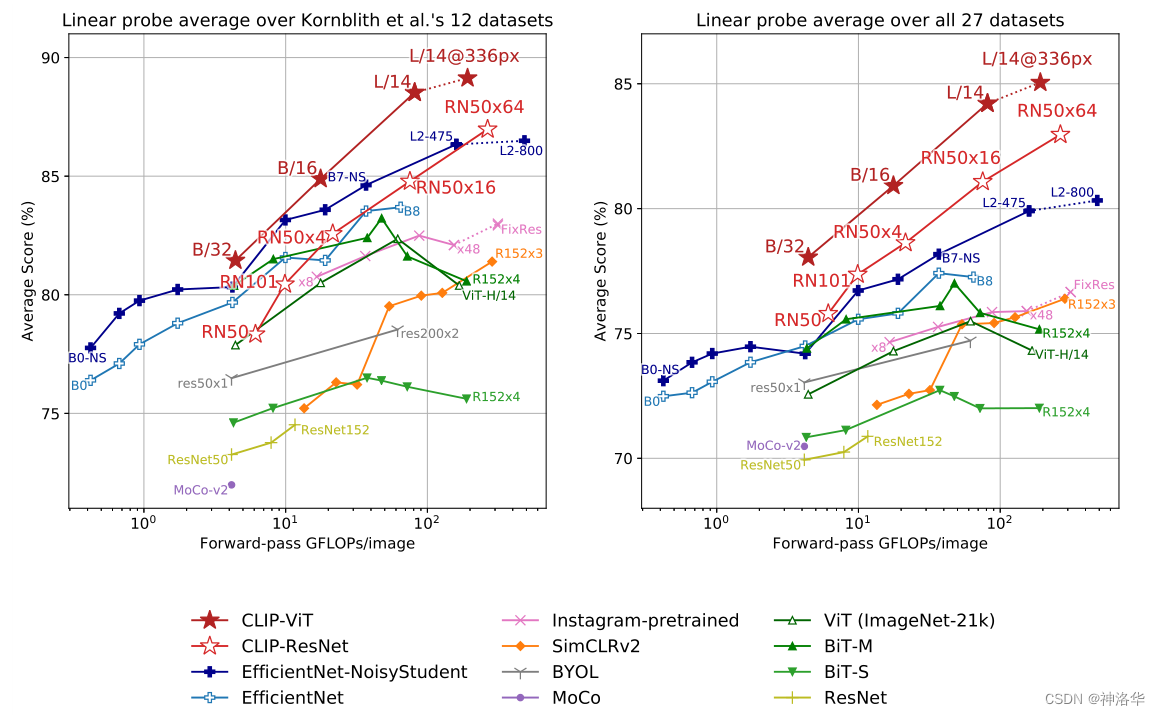
- КсзјБъБэЪОЖдгквЛеХЭМЯёРДЫЕ,зівЛБщЧАЯђЙ§ГЬгУЖрЩйЕФМЦЫуСП
- знзјБъБэЪОдкЖрИіЪ§ОнМЏЩЯЕФЦНОљзМШЗТЪЁЃ
- ЖдБШФЃаЭгагаМрЖНЕФEfficientNetЁЂгУСЫЮББъЧЉЕФEfficientNetЁЂШѕМрЖНЕФдкInstagramЩЯбЕСЗЕФФЃаЭЁЂздМрЖНЕФЖдБШбЇЯАФЃаЭЁЂвдМАвЛаЉОЕфЕФгаМрЖНЕФbaselineФЃаЭЁЃ
- НсЙћдНППНќзѓЩЯНЧ,ФЃаЭЕФадФмдНКУЁЃ
- зѓЭМЪЧдк12ИіЪ§ОнМЏЩЯЕФЦНОљНсЙћ,ет12ИіЪ§ОнМЏКЭImageNetЪЧРрЫЦЕФЁЃЫљвдгаМрЖНЕФдкImageNetЩЯдЄбЕСЗЕФФЃаЭ,аЇЙћБШCLIPКУЪЧПЩвддЄМћЕФ
- гвЭМЪЧдк27ИіЪ§ОнМЏЩЯЕФЦНОљНсЙћЁЃ
??ДгЭМжаПЩвдПДЕН,дк12ИіЪ§ОнМЏЩЯ,гУViTНсЙЙЕФCLIPаЇЙћзюКУ,гУResNetЕФаЇЙћвВБШДѓЖрЪ§ФЃаЭвЊКУ;дк27ИіЪ§ОнМЏЩЯ,CLIPЕФаЇЙћОЭЕѕДђЦфЫћЫљгаФЃаЭСЫЁЃетИіНсЙћОЭжЄУїСЫCLIPФЃаЭЕФЧПДѓЁЃ
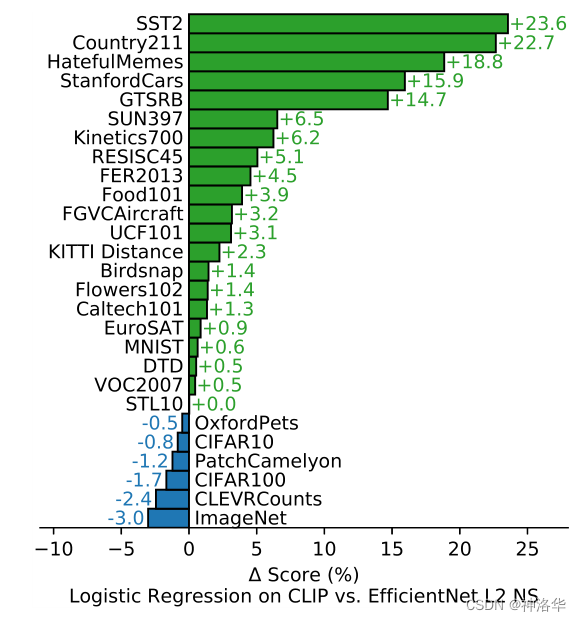
1.3.6 гыNoisy Student EfficientNet-L2 ЖдБШ
??зїепЛЙдк27ИіЪ§ОнМЏЩЯПЩЪгЛЏСЫCLIPФЃаЭКЭгУЮББъЧЉбЕСЗЕФEfficientNetЕФадФмВювь(ImageNetЩЯБэЯжзюКУ)ЁЃ
??ДгЭМжаПЩвдПДЕН,CLIPдк21ИіЪ§ОнМЏЩЯЕФадФмЖМГЌЙ§СЫEfficientNet,ВЂЧвКмЖрЪ§ОнМЏЖМЪЧДѓБШЗжГЌЙ§ЁЃдкЦфгр6ИіБэЯжВЛШчEfficientNetЕФЪ§ОнМЏЩЯ,CLIPвВжЛБШEfficientNetЩдЮЂЕЭвЛЕу,ВюОрВЂВЛДѓЁЃ
1.4 гыШЫРрЕФВювь(Тд)
1.5 Ъ§ОнжиЕўЗжЮі
??CLIPФмЪЕЯжетУДКУЕФzero-shotадФм,ДѓМвКмПЩФмжЪвЩCLIPЕФбЕСЗЪ§ОнМЏПЩФмАќКЌвЛаЉВтЪдЪ§ОнМЏжаЕФбљР§,МДЫљЮНЕФЪ§ОнаЙТЉЁЃЙигкетЕу,ТлЮФвВВЩгУвЛИіжиИДМьВтЦїЖдЦРВтЕФЪ§ОнМЏжиКЯзіСЫМьВщ,ЗЂЯжжиКЯТЪЕФжаЮЛЪ§ЮЊ2.2%,ЖјЦНОљжЕдк3.2%,ШЅжиЧАКѓДѓВПЗжЪ§ОнМЏЕФадФмУЛгаЬЋДѓЕФБфЛЏ,ШчЯТЫљЪО:
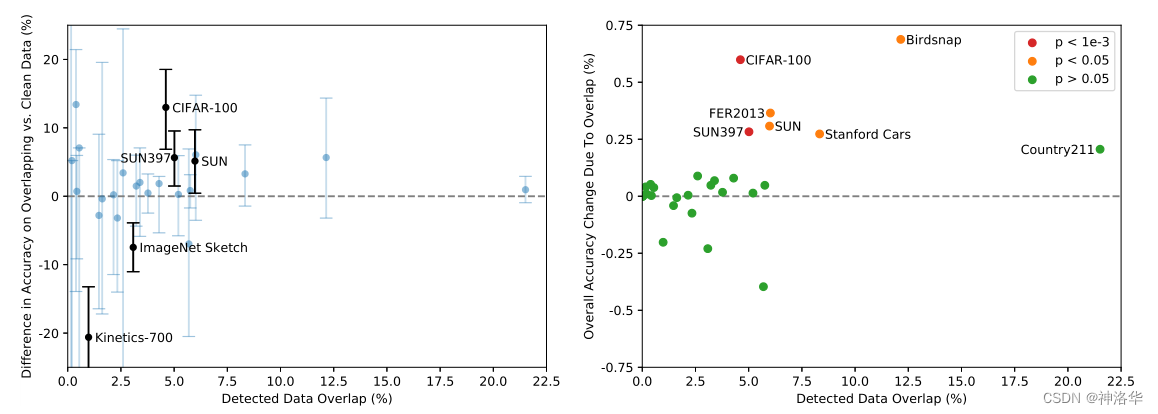
- зѓ:ЫфШЛМИИіЪ§ОнМЏдкМьВтЕНЕФжиЕўКЭИЩОЛЪОР§ЩЯЕФzero-shotзМШЗЖШгаИпДяЁР20%ЕФУїЯдВювь,ЕЋдк35ИіЪ§ОнМЏжажЛга5ИіОпга99.5%ЕФClopper-PearsonжУаХЧјМф,ХХГ§СЫ0%ЕФзМШЗЖШВювьЁЃЦфжа2ИіЪ§ОнМЏдкжиЕўЪ§ОнЩЯБэЯжИќВюЁЃ
- гв:гЩгкМьВтЕНЕФжиЕўЪОР§ЕФАйЗжБШМИКѕзмЪЧИіЮЛЪ§,вђДЫгЩгкжиЕўЕМжТЕФећЬхВтЪдзМШЗЖШдівцвЊаЁЕУЖр,BirdsnapЕФзюДѓдіЗљНіЮЊ0.6%ЁЃЭЌбљ,ЕБЪЙгУЕЅБпЖўЯюЪНМьбщМЦЫуЪБ,жЛга6ИіЪ§ОнМЏЕФзМШЗадЬсИпОпгаЭГМЦбЇвтвхЁЃ
гЩДЫПЩвдЕУГіНсТл,етбљЕФЪ§ОнжиЕўВЛЛсДјРДУїЯдЕФзМШЗТЪЬсЩ§ЁЃ
1.6 ОжЯоад
-
адФмгаД§ЬсИп
CLIPдкКмЖрЪ§ОнМЏЩЯ,ЦНОљЯТРДПДПЩвдКЭResNet-50ДђГЩЦНЪж(ImageNetОЋЖШЮЊ76.2),ЕЋгыЯждкзюКУЕФФЃаЭ(VIT-H/14,MAEЕШОЋЖШПЩвдЩЯ90)ЛЙДцдкЪЎМИИіЕуЕФВюОрЁЃдЄВтДѓИХЛЙашвЊЕБЧА1000БЖЕФЙцФЃВХПЩвдУжВЙЩЯЪЎМИИіЕуЕФетИіВюОр,ЯжгаЕФгВМўЬѕМўвВЮоЗЈЭъГЩЁЃЫљвдРЉДѓЪ§ОнЙцФЃЪЧВЛааСЫ,ашвЊдкЪ§ОнМЦЫуКЭИпаЇадЩЯашвЊНјвЛВНЬсИпЁЃ -
ФбвдРэНтГщЯѓ/ИДдгИХФю
CLIPдквЛаЉИќГщЯѓЛђИќИДдгЕФШЮЮёЩЯzero-shotБэЯжВЂВЛКУЁЃР§ШчЪ§вЛЪ§ЭМЦЌжагаЖрЩйИіЮяЬх,ЛђепдкМрПиЪгЦЕРяЧјЗжЕБЧАетвЛжЁЪЧвьГЃЛЙЪЧЗЧвьГЃ,вђЮЊCLIPЮоЗЈРэНтЪВУДЪЧвьГЃЁЂАВШЋЁЃЫљвддкКмЖрЧщПіЯТ,CLIPЖМВЛааЁЃ -
out-of-distributionЗКЛЏВю
ЖдгкздШЛЭМЯёЕФЗжВМЦЋвЦ,CLIPЛЙЪЧЯрЖдЮШНЁЕФЁЃЕЋШчЙћдкзіЭЦРэЪБ,Ъ§ОнКЭбЕСЗЪБЕФЪ§ОнЯрВюЬЋдЖ(out-of-distribution),CLIPЗКЛЏЛсКмВюЁЃР§ШчCLIPдкMNISTЪ§ОнМЏЩЯОЋЖШжЛга88%,ЫцБувЛИіЗжРрЦїЖМЖМФмзіЕН99%,ПЩМћCLIPЛЙЪЧКмДрШѕЕФЁЃ(зїепбаОПЗЂЯж,4вкИібљБОУЛгаКЭMNISTКмЯёЕФбљБО) -
ЫфШЛCLIPПЩвдзіzero-shotЕФЗжРрШЮЮё,ЕЋЫќЛЙЪЧДгИјЖЈЕФФЧаЉРрБ№РяШЅзібЁдё,ЮоЗЈжБНгЩњГЩЭМЯёЕФБъЬтЁЃзїепЫЕвдКѓПЩвдНЋЖдБШбЇЯАФПБъКЏЪ§КЭЩњГЩЪНФПБъКЏЪ§НсКЯ,ЪЙФЃаЭЭЌЪБОпгаЖдБШбЇЯАЕФИпаЇадКЭЩњГЩЪНбЇЯАЕФСщЛюадЁЃ
-
Ъ§ОнЕФРћгУВЛЙЛИпаЇ
дкБОЮФЕФбЕСЗЙ§ГЬжа,4вкИібљБОХмСЫ32Иіepoch,етЯрЕБгкЙ§СЫ128вкеХЭМЦЌЁЃПЩвдПМТЧЪЙгУЪ§ОндіЧПЁЂздМрЖНЁЂЮББъЧЉЕШЗНЪНМѕЩйЪ§ОнгУСПЁЃ -
в§ШыЦЋМћ
БОЮФдкбаЗЂCLIPЪБвЛжБгУImageNetВтЪдМЏзіжИЕМ,ЛЙЖрДЮЪЙгУФЧ27ИіЪ§ОнМЏНјааВтЪд,ЫљвдЪЧЕїСЫКмЖрВЮЪ§ВХЖЈЯТРДЭјТчНсЙЙКЭГЌВЮЪ§ЁЃетВЂЗЧеце§ЕФzero-shot,ЖјЧвЮоаЮжав§ШыСЫЦЋМћЁЃ -
ЩчЛсЦЋМћ
OpenAIздНЈЕФЪ§ОнМЏУЛгаЧхЯД,вђЮЊЪЧДгЭјЩЯХРШЁЕФ,УЛгаОЙ§Й§ТЫКЭЩѓВщ,бЕСЗЕФCLIPФЃаЭКмгаПЩФмДјгавЛаЉЩчЛсЦЋМћ,Р§ШчадБ№ЁЂЗєЩЋЁЃ -
ашвЊЬсИпfew-shotЕФадФм
КмЖрИДдгЕФШЮЮёЛђИХФюЮоЗЈгУЮФБОзМШЗУшЪі,етЪБОЭашвЊЬсЙЉИјФЃаЭвЛаЉбЕСЗбљБОЁЃЕЋЕБИјCLIPЬсЙЉЩйСПбЕСЗбљБОЪБ,НсЙћЗДЖјВЛШчжБНггУzero-shotЁЃР§Шч3.1.4жаCLIPЕФfew-shotЗжРрЁЃКѓајЙЄзїПМТЧШчКЮЬсИпfew-shotЕФадФм
1.7 demo
ЯТУцЪЧИДжЦздCLIPЙйЭјЕФвЛЖЮДњТы,ЪЙгУКьАќЭМЦЌ(ВЛдкImageNetФЧ1000ИіРрРяУц)НјаавЛЯТМђЕЅЕФВтЪд:

import numpy as np
import torch
import clip
from PIL import Image
device = "cuda" if torch.cuda.is_available() else "cpu"
model, preprocess = clip.load("ViT-B/32", device=device) # МгдиbaseФЃаЭ
image = preprocess(Image.open("red_envelogp.png")).unsqueeze(0).to(device)
text = clip.tokenize(["plane", "dog", "a cat","bird"]).to(device)
with torch.no_grad():
image_features = model.encode_image(image)
text_features = model.encode_text(text)
logits_per_image, logits_per_text = model(image, text) # МЦЫуЭМЮФЬиеїЯрЫЦад
probs = logits_per_image.softmax(dim=-1).cpu().numpy() # КЭЭМЦЌзюЯрЫЦЕФЮФБООЭЪЧЭМЦЌЕФРрБ№
print("Label probs:", probs)
Label probs: [[0.3131486 0.3174914 0.08763372 0.28172636]]
??ПЩвдПДЕНЖдгкtextИјГіЭъШЋВЛЯрЙиЕФРрБ№,ФЃаЭКмРЇЛѓЁЃ
??ЯТУцЬэМгКьАќетИіРрБ№,ФЃаЭзіГіе§ШЗЕФМьВтЁЃ
text = clip.tokenize(["plane", "dog", "a cat","bird","red_envelogp"]).to(device)
Label probs: [[0.00437422 0.00443489 0.00122411 0.0039353 0.98603153]]
??ЯТУцЮвУЧЪЕбщвЛЯТ,ФЃаЭЕНЕзЪЧЭЈЙ§ЪВУДЗНЪНжЊЕРетеХЭМЦЌЪЧКьАќФи?ЪЧбеЩЋЛЙЪЧаХЗт(envelogp)?ЯТУцЬэМгетСНИіРр:(ВЛжЊЕРЮЊЩЖ,КЭРЯЪІбнЪОЕФВЛвЛбљ)
text = clip.tokenize(["plane", "red", "envelogp","bird","red_envelogp"]).to(device)
Label probs: [[0.00259908 0.39436376 0.01481757 0.00233828 0.5858813 ]]
??зюКѓПДПДCLIPФмВЛФмбЇЕНЯрЙиЕФгявхЁЃКьАќвЛАуЪЧжаЙњЬигаЕФ,аТФъЕФЪБКђЖМЛсдкРяУцШћЧЎЁЃЯТУцИФГЩетМИИіДЪЪдЪд:
text = clip.tokenize(["money", "new year","red","envelogp","china"]).to(device)
Label probs: [[0.01408994 0.015231 0.05491581 0.00206337 0.91369987]]
??ПЩвдПДЕНФЃаЭУЛгабЁдёКьЩЋЛђепЪЧаХЗт,ЖјЪЧбЁдёСЫКЭКьАќНєУмНсКЯЕФchinaетИіИХФю,ПЩМћФЃаЭЕФЯрЙигявхЛЙЪЧбЇЕФКмКУЁЃЕЋЪЧЙтДгЗжРрНЧЖШ,ЪЧЗёгІИУЗжРрЮЊаХЗтФи?
ЖўЁЂCLIPгявхЗжИю
ВЮПМ:
- РюухТлЮФОЋЖШЯЕСажЎЁЖCLIP ИФНјЙЄзїДЎНВЁЗ
- ВЉЮФЁЖCLIPИФНјЙЄзїДЎНВ(ЩЯ)ЁЗ
??CLIPЪЧOpenAIгк2021Фъ2дТЗЂБэЕФ,дкЙ§ШЅЕФвЛФъЖрЪБМфРя,вбОБЛгУЕНИїИіЗНУц:
- гявхЗжИю:LsegЁЂGroupViT
- ФПБъМьВт:ViLDЁЂGLIP v1/v2
- ЪгЦЕРэНт:VideoCLIPЁЂCLIP4clipЁЂActionCLIP
- ЭМЯёЩњГЩ:VQGAN-CLIPЁЂCLIPassoЁЂCLIP Draw
- ЖрФЃЬЌ:VL Downstream
- ЦфЫћ:depthCLIPЁЂpointCLIPЁЂaudioCLIP(гявє)ЁЂCLIPasso
2.1 LSeg
??гявхЗжИюПЩвдПДзіЪЧЯёЫиМЖЕФЗжРр,вђДЫЗжРрЕФаТММЪѕЁЂаТЫМТЗ,вЛАуПЩвджБНггУЙ§РДЁЃLSegЪЧ2022Фъ1дТ10КХЗЂБэдкICLRЕФЮФеТЁЃгы CLIP ЪЕЯж zero-shot ЕФЗНЪНРрЫЦ,LSegЭЈЙ§РрБ№ prompt зїЮЊЮФБОЪфШы,ШЛКѓМЦЫуЯрЫЦЖШ,вВЪЕЯжСЫzero-shot гявхЗжИюЁЃ
??LSegЕФвтвхдкгкНЋЮФБОЕФЗжжЇМгШыЕНДЋЭГЕФгаМрЖНЗжИюЕФpipelineФЃаЭжа,ЭЈЙ§ОиеѓЯрГЫНЋЮФБОКЭЭМЯёНсКЯЦ№РДСЫЁЃбЕСЗЪБПЩвдбЇЕНlanguage aware(гябдЮФБОвтЪЖ)ЕФЪгОѕЬиеї,ДгЖјдкзюКѓЭЦРэЕФЪБКђФмЪЙгУЮФБОpromptЕУЕНШЮвтФуЯывЊЕФЗжИюНсЙћЁЃ
2.1.1 ФЃаЭаЇЙћ
??ЯТЭМеЙЪОСЫLSegЕФМьВтаЇЙћЁЃИјЖЈвЛеХЭМЦЌ,ШЛКѓЭЈЙ§ЮФБОЬсЪО,ИјГіашвЊМьВтЕФРрБ№,ОЭПЩвдЪЕЯжЖдгІЕФгявхЗжИюЁЃ
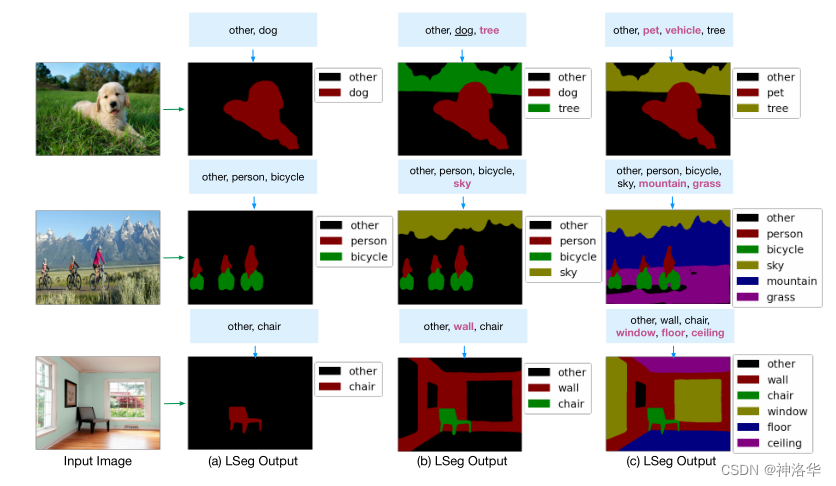
- ЕквЛеХЭМжа,ИјГі
dog,tree,others,ОЭПЩвдАбЙЗКЭЪїМьВтГіРД,ЦфЫќЮЊБГОАЩЋ - ЮЊСЫбщжЄФЃаЭЕФШнДэФмСІ,МгвЛИіЦћГЕ
vehicleЕФБъЧЉ,ФЃаЭжавВВЂУЛгаГіЯжЦћГЕЕФТжРЊ - ФЃаЭвВФмЧјЗжзгРрИИРр,БъЧЉжаВЛдйИјГі
dogЖјЪЧИјГіpet,dogЕФТжРЊЭЌбљПЩвдБЛЗжИюПЊРД - ЕкШ§еХЭМжа,вЮзгЁЂЧНБкЩѕжСЕиАхКЭЬьЛЈАхетжжМЋЮЊЯрЫЦЕФФПБъвВБЛЭъУРЕФЗжИюПЊРД
??жЕЕУвЛЬсЕФЪЧ,гЩгк CLIP РрЕФФЃаЭЪЕжЪЩЯЖМЪЧЭЈЙ§МЦЫуЭМЮФЯрЫЦЖШРДЪЕЯжЗжРрЛђЗжИюЕФ,вђДЫ ЁЎotherЁЏ РрЕФРрБ№ prompt ЮФБОЪЕМЪПЩвдЪЧШЮКЮЮовтвхЕФЮФБО,Шч ЁЎmeЁЏ,ЁЎaЁЏ,ЁЎanЁЏ ЕШ,жЛвЊгыФПБъРрБ№ВЛвЊЬЋНгНќМДПЩЁЃ
2.1.2 ФЃаЭПђМм
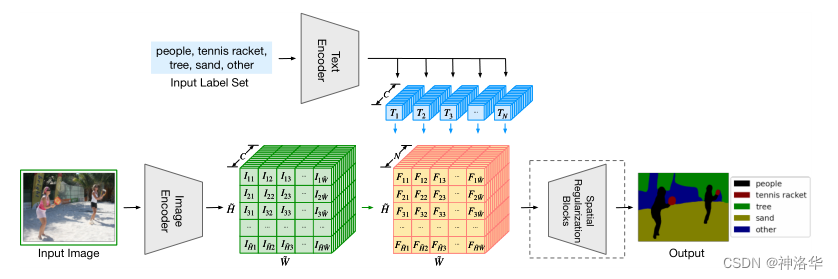
??ШчЩЯЭМ 4 ЫљЪО,ФЃаЭећЬхПДРДгы CLIP ФЃаЭЗЧГЃЯрЫЦ,жЛЪЧНЋЕЅИіЕФЭМЯёЮФБОЬиеїЛЛГЩгявхЗжИюжаж№ЯёЫиЕФУмМЏЬиеїЁЃ
??СэЭтГ§СЫЩЯЗНЕФЮФБОБрТыЦїЬсШЁЕФЮФБОЬиеї,вЊгыУмМЏЭМЯёЬиеїЯрГЫРДМЦЫуЯёЫиМЖЕФЭМЮФЯрЫЦЖШжЎЭт,ећИіЭјТчгыДЋЭГЕФгаМрЖНЭјТчЭъШЋвЛжТЁЃ
- ЮФБОБрТыЦїЬсШЁ
N
ЁС
C
N\times C
NЁСCЕФЮФБОЬиеї,ЭМЯёБрТыЦїЬсШЁ
H
~
ЁС
W
~
ЁС
C
\tilde{H}\times\tilde{W}\times C
H~ЁСW~ЁСC ЕФУмМЏЭМЯёЬиеї,ЖўепЯрГЫЕУЕН
H
~
ЁС
W
~
ЁС
N
\tilde{H}\times\tilde{W}\times N
H~ЁСW~ЁСN ЕФЬиеї,дйОЙ§
Spatial Regularization BlocksЩЯВЩбљЛидЭМГпДчЁЃзюКѓМЦЫуФЃаЭЕФЪфГігыground truthМрЖНаХКХЕФНЛВцьиЫ№ЪЇНјаабЕСЗЁЃ - N , C , H ~ , W ~ N,C,\tilde{H},\tilde{W} N,C,H~,W~ ЗжБ№ЪЧРрБ№ ИіЪ§(ПЩБф)ЁЂЭЈЕРЪ§КЭЬиеїЭМЕФИпПэ,CвЛАуШЁ512Лђеп768ЁЃ
Text Encoder: жБНггУЕФЪЧCLIP ЮФБОБрТыЦїЕФФЃаЭКЭШЈжи,ВЂЧвбЕСЗЁЂЭЦРэШЋГЬжаЖМЪЧЖГНсЕФЁЃвђЮЊЗжИюШЮЮёЕФЪ§ОнМЏЖМБШНЯаЁ(10-20Эђ),бЕСЗЕФЛАНсЙћЛсВЛКУЁЃImage Encoder:DPTНсЙЙ(ЪЙгУСЫViTНјаагаМрЖНбЕСЗЕФгявхЗжИюФЃаЭ,НсЙЙОЭЪЧViT+decoder),backboneПЩвдЪЧResNetЛђепViTЁЃШчЙћЪЙгУКѓеп,ЦфВЮЪ§гУЕФЪЧVit/DEitЕФдЄбЕСЗШЈжи,жБНгЪЙгУCLIPЕФдЄбЕСЗШЈжиаЇЙћВЛЬЋКУЁЃSpatial Regularization BlocksЪЧБОЮФЬсГіЕФвЛИіФЃПщЁЃдкМЦЫуЭъЯёЫиМЖЭМЮФЯрЫЦЖШКѓМЬајбЇЯАвЛаЉВЮЪ§,ПЩвдНјвЛВНбЇЯАЮФБОЭМЯёШкКЯКѓЕФЬиеїЁЃФЃПщгЩвЛаЉОэЛ§КЭDWОэЛ§зщГЩ(ЕБМгСЫСНИіФЃПщЪБаЇЙћЬсЩ§,МгСЫЫФИіФЃПщКѓаЇЙћБРРЃ,зїепЮДНтЪЭ):
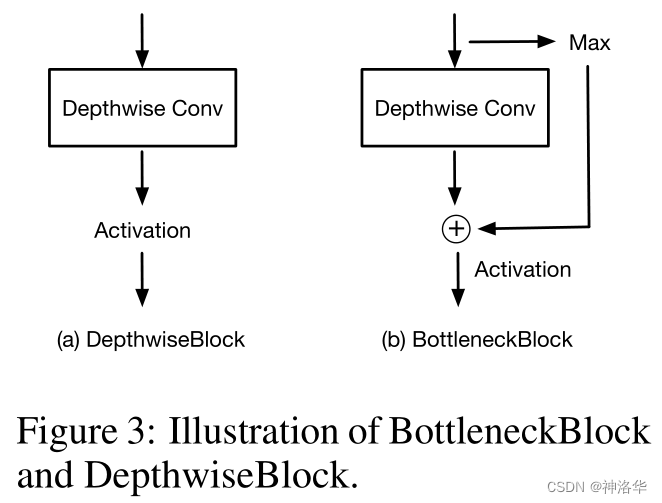
??ФЃаЭдк 7 ИіЗжИюЪ§ОнМЏЩЯНјаабЕСЗ,етаЉЪ§ОнМЏЖМЪЧгЩгаБъзЂЕФЗжИюЭМзщГЩ,ЫљвдФЃаЭЪЧвдгаМрЖНЕФЗНЪННјаабЕСЗЕФ(Ы№ЪЇКЏЪ§ЪЧНЛВцьиЫ№ЪЇЖјЗЧЮоМрЖНЕФЖдБШбЇЯАФПБъКЏЪ§)ЁЃЭЦРэЪБ,ПЩвджИЖЈШЮвтИіЪ§ЁЂШЮвтФкШнЕФРрБ№ prompt РДНјаа zero-shot ЕФгявхЗжИюЁЃ
2.1.3 ЪЕбщНсЙћ
??зїепНЋPascalVOCЪ§ОнМЏКЭCOCOЪ§ОнМЏ,ЖМАДееРрБ№ЗжГЩЫФЗнЁЃБШШчCOCOга80ИіРр,ЧА20РрзїЮЊЕБЧАвбжЊРр,Кѓ60РрЮЊЮДжЊРр,ШЛКѓОЭПЩвдзіzero-shot КЭfew-shot СЫЁЃ
??ЖдБШzero-shotЭЦРэЕФЛА,LSegЕФаЇЙћШЗЪЕКУКмЖр;ЕЋЪЧгы few-shot ФФХТЪЧ one-shot ЯрБШ,ЛЙЪЧгаКмДѓЕФОрРыЁЃдйПМТЧЕНLSegгУЕФЪЧViTНсЙЙ,ПЩМћLSegашвЊЬсЩ§ЕФПеМфЛЙЪЧЗЧГЃДѓЕФЁЃ
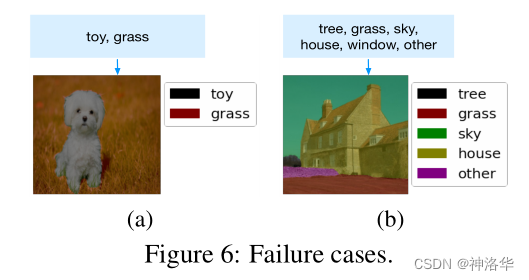
Failure cases
??БШШчЯТЭМзѓВр,БъЧЉИјЖЈЪЧtoy, grass,дкЧЖШыПеМфжа(embedding space),ЙЗЕФЪгОѕЬиеїУїЯдИќНгНќЁАЭцОпЁБЖјВЛЪЧЁАВнЁБ,ВЂЧвУЛгаЦфЫћБъЧЉПЩвдНтЪЭЪгОѕЬиеї,ЫљвдЙЗБЛМьВтЮЊtoyЁЃШчЙћБъЧЉЪЧface,grass,ЙЗЛсБЛМьВтЮЊfaceЁЃ
??вВОЭЪЧЫљгаЪЙгУCLIPФЃаЭЕФЙЄзї,ЖМЪЧдкМЦЫуЭМЯёКЭЮФБОжЎМфЕФЬиеїЯрЫЦЖШ,ЫЯрЫЦОЭбЁЫ,ЖјВЛЪЧецЕФдкзіЗжРрЁЃ
2.2 GroupViT
2.2.1 ЧАбд
??ЩЯвЛНкНВЕФLSeg ЫфШЛФмЙЛЪЕЯж zero-shot ЕФгявхЗжИю,ЕЋЪЧбЕСЗЗНЪНВЂВЛЪЧЖдБШбЇЯА(ЮоМрЖНбЕСЗ),УЛгаНЋЮФБОзїЮЊМрЖНаХКХРДЪЙгУЁЃвђДЫLSegЛЙЪЧашвЊЪжЙЄБъзЂЕФЗжИюбкФЃ(segmentation mask)НјаабЕСЗЁЃЦфЪЙгУЕФ 7 ИіЪ§ОнМЏМгЦ№РДПЩФмвВОЭвЛЖўЪЎЭђИібљБО,ИњБ№ЕФгаМрЖНЮоМрЖНбЕСЗЪЧдЖдЖВЛФмБШЕФЁЃ
??GroupViTЪЧ2022Фъ2дТ22ЗЂБэдкCVPRЕФЮФеТЁЃДгБъЬтПЩвдПДГі,ЦфМрЖНаХКХРДздЮФБОЖјЗЧsegmentation maskЁЃGroupViTЭЈЙ§ЮФБОздМрЖНЕФЗНЪННјаабЕСЗ,ДгЖјЪЕЯжМђЕЅЕФЗжИюШЮЮё(ВЛдйвРРЕsegmentation mask)ЁЃ
2.2.2 ФЃаЭНсЙЙ
??GroupViT ЕФКЫаФЫМЯы,ЪЧРћгУСЫжЎЧАЮоМрЖНЗжИюЙЄзїжаЕФЕФ groupingЁЃМђЕЅЫЕШчЙћгавЛаЉОлРрЕФжааФЕу,ДгетаЉжааФЕуПЊЪМЗЂЩЂ,АбжмЮЇЯрЫЦЕФЕуж№НЅРЉЩЂГЩвЛИіgroup,зюКѓетИіgroupМДЯрЕБгквЛИіSegmentation mask(ИаОѕРрЫЦDBSCAN)ЁЃ
??Group ViTЕФЙБЯзОЭЪЧдкЯжгаЕФViTФЃаЭжаМгШыМЦЫуЕЅдЊGrouping Block,ЭЌЪБМгШыСЫПЩбЇЯАЕФGroup TokensЁЃетбљФЃаЭдкГѕЦкбЇЯАЕФЪБКђОЭФмТ§Т§вЛЕуЕуЕФНЋЯрСкЕФдЊЫиgroupЦ№РД,зюКѓБфГЩвЛИіИіsegmentation maskЁЃ
??БШШчЯТЭМ,ЧГВуЕФЪБКђбЇЯАЕНЕФЛЙЪЧвЛаЉЮхбеСљЩЋЕФПщ,ЕНЩюВуДѓЯѓЁЂЗПзгЁЂВнЕиЕШЖМвбОЗжИюГіРДСЫ
??ЯТУцРДПДвЛЯТ GroupViT ФЃаЭПђМмКЭОпЬхЕФбЕСЗЙ§ГЬ:
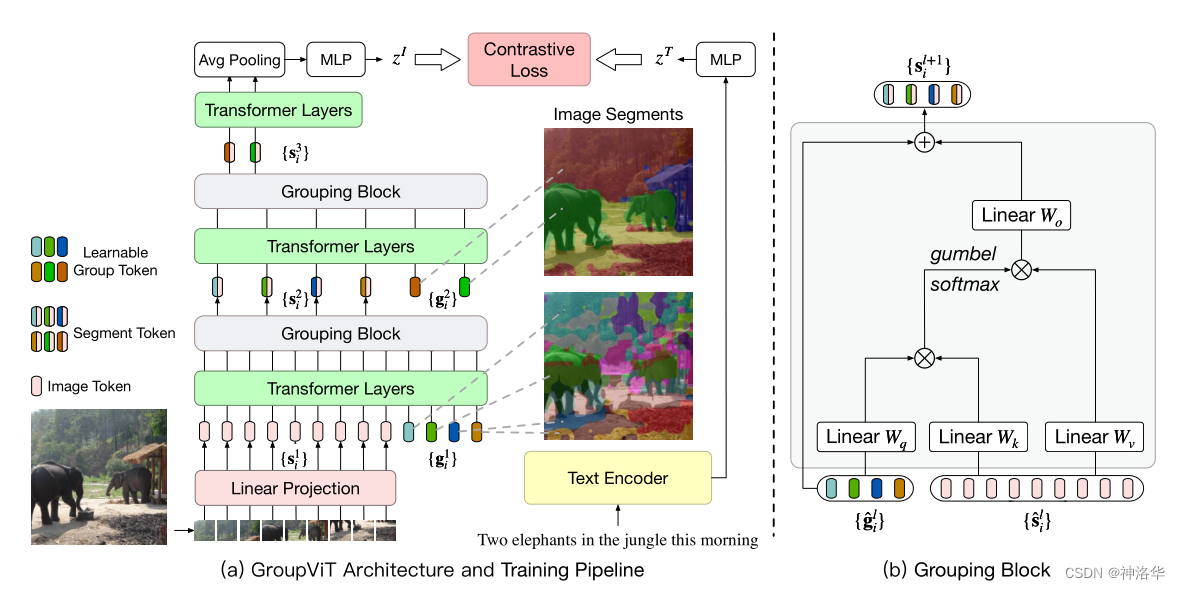
Image Encoder:- НсЙЙОЭЪЧVision Transformer,вЛЙВЪЧ12Ву Transformer Layer,ЦфЪфШыГ§СЫдЪМЭМЯёЕФPacth embeddings,ЛЙгаПЩбЇЯАЕФ group token ЁЃ
- МйЩшЪфШыЭМЯёГпДчЪЧ224,ЁС224,бЁдёЕФ
Image EncoderЪЧViT-Small/16,дђЪфГіPacth embeddingsГпДчЪЧ196ЁС384,вВОЭЪЧЭМжаЕФtoken s i 1 \mathbf{s}_i^1 si1? ЁЃЖдгІgroup token g i 1 \mathbf{g}_i^1 gi1?ЕФГпДчЪЧ64ЁС384ЁЃ - етРяЕФ group tokens ОЭЯрЕБгкЗжРрШЮЮёжаЕФ cls tokenЁЃШЛКѓЭЈЙ§Transformer LayerЕФздзЂвтСІРДбЇЯАЕНЕзФФаЉpatchЪєгкФФаЉgroup tokenЁЃ
гЩгкЗжРрШЮЮёвЛеХЭМЯёжЛашвЊвЛИіШЋЭМЕФЬиеї,вђДЫжЛгУвЛИі token МДПЩЁЃЖјгявхЗжИюжавЛеХЭМгаЖрИіФПБъ,ЫљвдашвЊЖрИіЬиеї,вВОЭЪЧЖрИі group tokensЁЃзюГѕЪЧбЁдё64Иі group tokens(ОлРржааФ),ВЛДѓВЛаЁ,КѓЦкПЩвдКЯВЂЁЃ
-
бЕСЗ:
- ОЙ§СљВу Transformer Layers ЕФжЎКѓ,бЇЕФВюВЛЖрСЫЁЃМгШывЛИі
Grouping BlockРДЭъГЩ grouping ,НЋЭМЯёПщ token ЗжХфЕНИїИі group token ЩЯ,КЯВЂГЩЮЊИќДѓЕФЁЂИќОпгаИпВугявхаХЯЂЕФ group,МДSegment Token(ЮЌЖШ64ЁС384,ЯрЕБгквЛДЮОлРрЕФЗжХф)ЁЃ Grouping BlockНсЙЙШчЩЯЭМгвВрЫљЪО,ЦфgroupingзіЗЈгыздзЂвтСІЛњжЦРрЫЦЁЃМЦЫу grouping token (64ЁС384)гыЭМЯёПщ token (196ЁС384)ЕФЯрЫЦЖШОиеѓ(64ЁС196),НЋtokenЗжХфЕНЯрЫЦЖШзюДѓЕФgrouping tokenЩЯУц(ОлРржааФЕФЗжХф)ЁЃетРяЮЊСЫПЫЗў argmax ЕФВЛПЩЕМад,ЪЙгУСЫ ПЩЕМЕФgumbel softmaxЁЃКЯВЂЭъГЩКѓЕУЕН s i 2 \mathbf{s}_i^2 si2?(64ЁС384) ЁЃ- жиИДЩЯЪіЙ§ГЬ:ЬэМгаТЕФ Group tokens g i 2 \mathbf{g}_i^2 gi2?(8ЁС384),ОЙ§ 3 Ву Transformer Layers ЕФбЇЯАжЎКѓ,дйДЮОЙ§grouping block ЗжХф,ЕУЕН s i 3 \mathbf{s}_i^3 si3?(8ЁС384) ЁЃ
- ЮЊСЫКЭЮФБОЬиеїНјааЖдБШбЇЯА,НЋзюКѓвЛВуTransformer LayersЪфГіЕФађСаЬиеї(8ЁС384)НјааШЋОжЦНОљГиЛЏAvg Pooling,ЕУЕН1ЁС384ЕФЭМЦЌЬиеїЁЃдйОЙ§вЛИіMLPВуБфГЩ z I \mathbf{z}^I zIЮЌЕФЭМЦЌЬиеїЁЃзюКѓгыЮФБОЬиеї z T \mathbf{z}^T zT МЦЫуЖдБШЫ№ЪЇЁЃ
- ОЙ§СљВу Transformer Layers ЕФжЎКѓ,бЇЕФВюВЛЖрСЫЁЃМгШывЛИі
-
ЭЦРэ
ЮФБОКЭЭМЯёЗжБ№ОЙ§ИїздЕФБрТыЦїЕУЕНЮФБОЬиеїКЭЭМЯёЬиеї,ШЛКѓМЦЫуЯрЫЦЖШ,ЕУЕНзюЦЅХфЕФЭМЯёЮФБОЖд,ОЭПЩвджЊЕРУПИіgroup embeddingЖдгІЪВУДclassЁЃОжЯоаддкгкзюКѓЕФОлРржааФ(Group Tokens)жЛга8Рр,ЫљвдвЛеХЭМЯёжазюЖрЗжИюГіАЫИіФПБъЁЃ
змНс:GroupViT УЛгадкViTЛљДЁЩЯМгКмИДдгЕФФЃПщ,ФПБъКЏЪ§вВКЭCLIPБЃЛЄвЛжТ,ЫљвдЦфscaleадФмКмКУЁЃМДИќДѓФЃаЭИќЖрЪ§Он,ЦфадФмЛсИќКУЁЃ
ЦфЫћЯИНк:
-
ТлЮФжабЁгУЕФЪЧViT-Small,Ъ§ОнМЏЪЧ2900ЭђЭМЮФЖдЁЃ
-
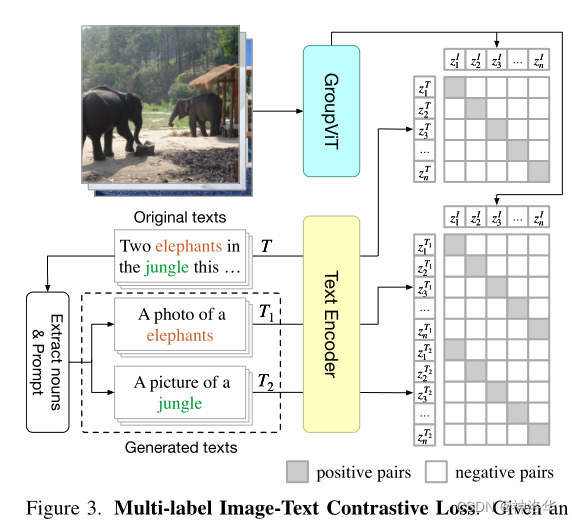
Г§СЫгыЭМаЮХфЖдЕФЮФБОБОЩэ,ЛЙНЋЮФБОжаЕФУћДЪЬсШЁГіРД,АДееРрЫЦ CLIP жаЕФЗНЗЈЩњГЩ prompt (Шч ЁАA photo of a {tree}.ЁБ),гыФГИіЭМЯёЬиеїМЦЫуЖдБШЫ№ЪЇ,МћдЮФ Figure 3;
-
ЯћШкЪЕбщжаGroup tokensИіЪ§бЁдё64,8ЕФзщКЯаЇЙћзюКУ
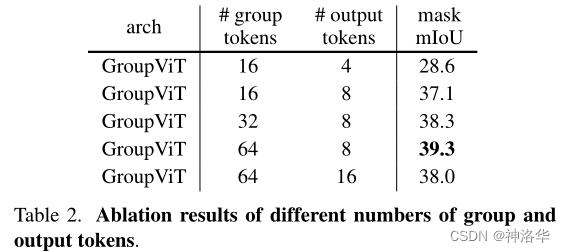
2.2.3 Group tokensПЩЪгЛЏ
??ЮЊСЫбщжЄМгШыЕФGroup tokensЁЂ Grouping BlockЕНЕзгаУЛгаЙЄзї,Group tokensгаУЛгаГЩЮЊОлРржааФ,гжЪЧЗёЖдгІСЫФГвЛИіРрБ№;зїепНЋВЛЭЌНзЖЮВЛЭЌ group token ЖдгІЕФзЂвтСІЧјгђНјааПЩЪгЛЏ,НсЙћШчЯТЫљЪО:

- дкЕквЛНзЖЮ,УПИі token ЖМзЂвтЕНвЛаЉгявхУїШЗЕФЧјгђ,Шчgroup5БэЪОЕФЪЧблОІ,group36БэЪОЕФЪЧЫФжЋ,ВЂЧвЖМЪЧаЉЯрЖдНЯаЁЕФЧјгђ;
- дкЕкЖўНзЖЮ,УПИі token зЂвтЕНЕФгявхЧјгђдђЯрЖдНЯДѓ,ШчСГЁЂЩэЬхЁЃете§ЗћКЯСЫзїепЯывЊЕФ group ЗжзщКЯВЂЕФаЇЙћЁЃ
2.2.4 ЪЕбщ
- Comparison with Zero-Shot Baselines
ЯТБэЪЧКЭЦфЫќЕФвЛаЉ Zero-Shot ЭЦРэФЃаЭаЇЙћЖдБШ:

- Comparison with Fully-Supervised Transfer
- дкPASCAL VOC 2012Ъ§ОнМЏЩЯ ,Zero-Shot GroupViT(ЮоЮЂЕї)гХгкЫљгаздМрЖНдЄбЕСЗЕФViTБфЬх(гаМрЖНЕФЮЂЕї)
- дк PASCAL ContextЪ§ОнМЏЩЯ,Zero-Shot GroupViTЕФаЇЙћвВКЭЫќУЧЯрЕБЁЃ
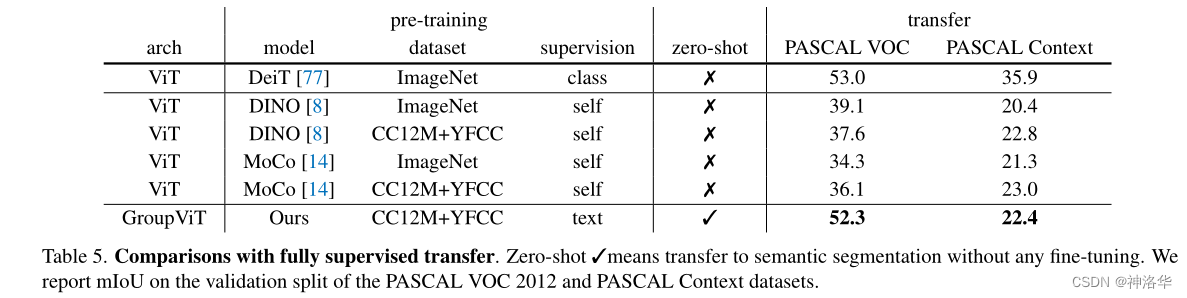
??GroupViT ЪЧЕквЛИіЪЕЯж zero-shot гявхЗжИюЕФЙЄзї,ЯрНЯгкЦфЫћздМрЖНгявхЗжИюЗНЗЈЬсЩ§ЯджјЁЃЕЋЪЧИњгаМрЖНбЕСЗЕФФЃаЭЩЯЯоБШЦ№РД,ЛЙЪЧВюСЫЗЧГЃЖрЁЃ
??
DeepLabv3+(Xception-65-JFT) дкPASCAL VOCЩЯMean IoUвбОДяЕНСЫ89,
ViT-Adapter-L(Mask2Former, BEiT pretrain)дкPASCAL ContextЩЯMean IoUДяЕНСЫ68.2ЁЃ
2.2.5 ОжЯоад
ЯждкЕФЮоМрЖНгявхЗжИюЛЙЪЧКмФбзіЕФ,зїепвВСаГіСЫGroupViT ЕФСНИіОжЯоад:
- GroupViTИќЦЋЯђгкЪЧвЛИіЭМЦЌБрТыЦї,УЛгаЪЙгУdense predictionЕФЬиад,ШчПеЖДОэЛ§ЁЂН№зжЫўГиЛЏвдМАU-NetЕФНсЙЙ,ДгЖјЛёШЁИќЖрЕФЩЯЯТЮФаХЯЂКЭЖрЖрГпЖШаХЯЂ;
- БГОАРрИЩШХЮЪЬтФбвдДІРэЁЃ
ЭЦРэЙ§ГЬжа,зюДѓЯрЫЦЖШвВПЩФмКмЕЭ,БШШч0.2;ЮЊСЫЬсИпЧАОАРрЕФЗжИюадФм,зїепЩшЖЈСЫЯрЫЦЖШуажЕ,ЕЋЪЧвђЮЊБГОАРрИЩШХЮЪЬт,етИіуажЕКмФбЩшЖЈКУЁЃ
??БШШч
PASCAL VOCжаЯрЫЦЖШуажЕЪЧ0.9Лђ0.95,ЭМЦЌКЭЮФБОЕФЯрЫЦЖШШЁзюДѓжЕЧвзюДѓжЕДѓгк0.9ЪБ,ВХЛсШЯЮЊЮяЬхЪЧетИіРр;ЗёдђШЯЮЊЪЧБГОАРрЁЃ
??PASCAL VOCжаРрБ№Щй,ЧвЮяЬхЖМгаУїШЗЕФгявх,ЫљвдБГОАРрИЩШХЩй;ЕЋЪЧPASCAL ContextЛђепCOCOЪ§ОнМЏ,РрБ№КмЖр,ЧАОАЕФЯрЫЦЖШвЛАуЖМКмЕЭ,КЭБГОАРрВюБ№ВЛДѓЁЃШчЙћуажЕЩшЕФИп,КмЖрЮяЬхЖМЛсБЛМьВтЮЊБГОАРр;ШчЙћЩшЕФЕЭ,ШнвзЮѓЗжРр,МДЯрЫЦЖШзюИпЕФФЧвЛРр,ВЂВЛЪЧецЪЕРрБ№ЁЃ
??вђЮЊБГОАРрИЩШХЮЪЬт,зїепЗЂЯжGroup tokensЦфЪЕвбОбЇЕФКмКУСЫ,ЕЋЪЧзюКѓЗжИюЪБШнвзЗжРрДэСЫЁЃЮЊСЫбщжЄетвЛЕу,зїепзіСЫ oracle ЖдБШЕФЪЕбщЁЃ
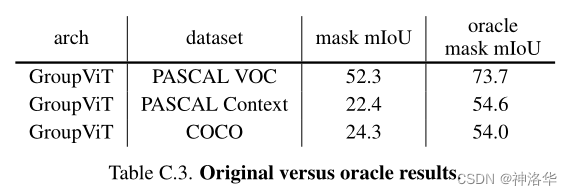
??oracle mask mIoU:ФЃаЭдкЭъГЩЗжИюжЎКѓ,ВЛгУФЃаЭдЄВтЕФРрБ№НсЙћ,ЖјЪЧНЋУПИі mask гы GT mask МЦЫу IoU,жБНгШЁзюДѓЕФРрБ№БъЧЉзїЮЊРрБ№НсЙћЁЃетЯрЕБгк,ФЃаЭжЛвЊЗжИюЕФзМОЭааСЫ,гявхРрБ№ЕФдЄВтЪЧПЯЖЈзМЕФЁЃ
??ЩЯЭМ ПЩвдПДЕН,oracle НсЙћЯрБШгкдНсЙћгаЖрДяЖўШ§ЪЎИіЕуЕФОоДѓЬсЩ§;етЫЕУї,гявхРрБ№дЄВтДэЮѓЪЧ GroupViT ФЃаЭЕФвЛДѓЦПОБЁЃ
??НсТл: GroupViT ЭМЦЌЗжИюзіЕУКУ(segmentation maskЩњГЩЕФКУ),ЕЋЪЧгявхЗжИюзіЕФВЛЙЛКУ,етЪЧгЩгкCLIPетжжЖдБШбЇЯАЕФбЕСЗЗНЪН,ЖдгкУїШЗгявхЮяЬхаХЯЂФмбЇЕФКмКУ;ЕЋЪЧЖдгкБГОАетжжгявхБШНЯФЃК§РрБ№КмФбЪЖБ№,вђЮЊБГОАПЩвдДњБэКмЖрРрЁЃКѓајИФНјПЩвдЪЧУПИіРрЩшжУВЛЭЌуажЕ,ЛђепЪЙгУПЩбЇЯАЕФуажЕ,ЛђепЪЧИќИФ Zero-Shot ЭЦРэЙ§ГЬЁЂбЕСЗЪБМгШыдМЪј,ШкШыБГОАРрИХФюЕШЕШЁЃ
2.3 змНс
??LsegЪЙгУCLIPЕФдЄбЕСЗФЃаЭКЭДѓИХПђМм,ШкКЯСЫЮФБОКЭЭМЦЌЬиеїШЅзіЗжИю,ЕЋвРОЩЪЧвЛИігаМрЖНЕФбЇЯАЙ§ГЬ,ЛЙЪЧашвЊЪжЙЄБъзЂЕФЪ§ОнМЏ;GroupViT ДгЭЗбЕСЗСЫвЛИіЗжИюФЃаЭ,ЕЋЪЧгУЕФФПБъКЏЪ§КЭCLIPЕФЖдБШбЇЯАФПБъКЏЪ§вЛбљ,ОжЯожЎвЛОЭЪЧБГОАРрДІРэЕУВЛЙЛКУЁЃ
Ш§ЁЂCLIPФПБъМьВт
РюухТлЮФОЋЖШЯЕСажЎЁЖCLIP ИФНјЙЄзїДЎНВЁЗ
3.1 ViLD
ТлЮФЁЖOpen-vocabulary Object Detection via Vision and Language Knowledge DistillationЁЗЁЂtensorflowДњТы
3.1.1 МђНщ
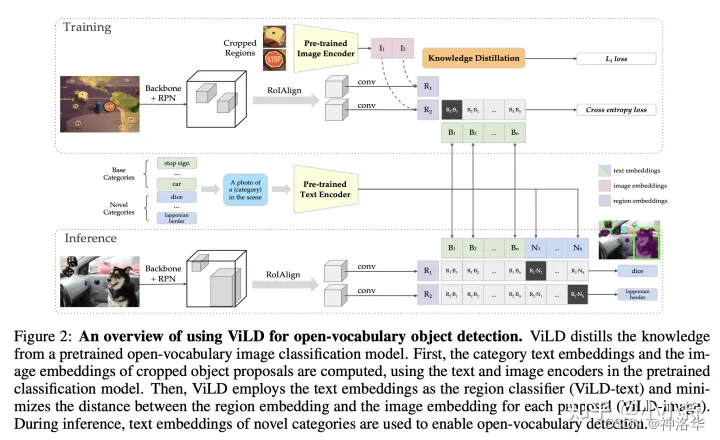
??ViLDЪЧ21Фъ4дТ28ЩЯДЋЕНArxivЩЯЕФ,вВОЭЪЧCLIPЗЂБэНіНіСНИідТжЎКѓ,ЖјЧвбЕСЗСЫдМ460epoch,ЫљвдЫйЖШЪЧКмПьЕФЁЃViLDМДVision and Knowledge Language Distillation,МДгУCLIPЕБзіteacherеєСѓЭјТч,ДгЖјФмДяЕНZero-ShotМьВтЁЃМђЕЅРДЫЕ,ViLD ЯывЊзіЕНЕФЪТЧщЪЧ:дкбЕСЗЪБжЛашвЊбЕСЗЛљДЁРр,ШЛКѓЭЈЙ§жЊЪЖеєСѓДг CLIP ФЃаЭжабЇЯА,ДгЖјдкЭЦРэЪБФмЙЛМьВтЕНШЮвтЕФаТЕФЮяЬхРрБ№(Open-vocabulary Object)ЁЃ
??ЯТУцЕФР§згжа,ШчЙћгУДЋЭГЕФФПБъМьВтЫуЗЈЕФЛА,ФЃаЭжЛЛсХаЖЯетаЉЮяЬхЖМЪЧЭцОп,вВОЭЪЧЭМжаРЖЩЋЕФЛљДЁРр,ЖјЮоЗЈМьВтЕНИќЯИжТЕФРрБ№ЁЃЪЙгУCLIPжЎКѓ,дкЯжгаМьВтПђЩЯ,ВЛашвЊЖюЭтБъзЂ,ОЭПЩвдМьВтГіаТЕФРр(ЭМжаКьЩЋБъЪЖРр)ЁЃ
3.1.2 ФЃаЭНсЙЙ
??ViLD ЗНЗЈЕФбаОПжиЕудкСННзЖЮФПБъМьВтЗНЗЈЕФЕкЖўНзЖЮ,МДЕУЕНЬсвщПђ(proposal)жЎКѓЁЃЦфЫМЯыЛЙЪЧзюМђЕЅЕФЗжБ№ГщШЁЮФБОКЭЭМЦЌЬиеї,ШЛКѓЭЈЙ§ЕуЛ§МЦЫуЯрЫЦЖШЁЃЦфФЃаЭНсЙЙШчЯТЭМЫљЪОЁЃ
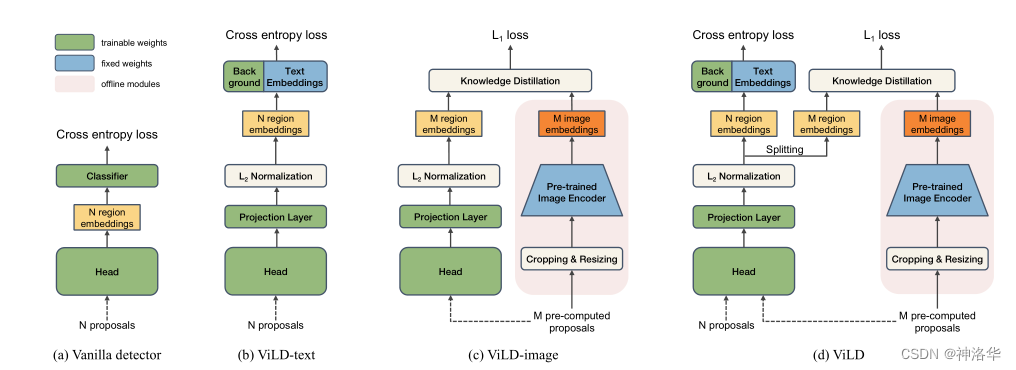
- (a):Mask R-CNNПђМмЁЃ
вЛНзЖЮЕУЕНЕФКђбЁПђproposalsОЙ§МьВтЭЗЕУЕНregion embeddings,ШЛКѓОЙ§ЗжРрЭЗЕУЕНдЄВтЕФbounding boxвдМАЖдгІЕФРрБ№ЁЃЫ№ЪЇЗжЮЊЖЈЮЛЫ№ЪЇ(ЛиЙщЫ№ЪЇ)КЭЗжРрЫ№ЪЇЁЃ - (b) :
ViLD-textЗжжЇ- NИі
proposalsОЙ§вЛаЉДІРэЕУЕНРрЫЦЭМaжаЕФNИіregion embeddings(ЭМЦЌЬиеї)ЁЃ - НЋЮяЬхРрБ№(ЛљДЁРр)ДІРэЮЊprompt ОфзгОЭЕУЕНСЫЮФБО,ШЛКѓНЋетаЉЮФБОШгИјЮФБОБрТыЦїЕУЕНText Embeddings(ЮФБОЬиеї)ЁЃКЭLsegРрЫЦ,етаЉText EmbeddingsвВЪЧЖГзЁШЈжиЕФ,ВЛВЮгыбЕСЗЁЃ
- ЩЯУцЮяЬхРрБ№ОЭЪЧ
Base categories(вВНаCB,Class Base),КЭMask R-CNNгаМрЖНбЕСЗЕФЛљДЁРрвЛбљ,ЫљвдViLD-textзіЕФЛЙЪЧгаМрЖНбЕСЗЁЃ - вђЮЊЪЧгаМрЖНбЕСЗ,ЫљвдашвЊЖюЭтЬэМгвЛИіБГОАРрНјаабЕСЗ,МДПЩбЇЯАЕФBackground embedding(ЛљДЁРржЎЭтЕФРрБ№ШЋВПЙщЮЊБГОАРр)ЁЃ
- Text EmbeddingsМгЩЯЗжБ№КЭПЩбЇЯАЕФБГОА embeddingвдМА
region embeddingsНјааЕуЛ§РДМЦЫуЭМЮФЯрЫЦЖШЕУЕНlogics,ШЛКѓМЦЫуlogicsКЭGTЕФНЛВцьиЫ№ЪЇРДНјаабЕСЗЁЃ - дк
ViLD-textФЃаЭжа,жЛЪЧНЋЮФБОЬиеїКЭЭМЯёЬиеїзіСЫЙиСЊ(ИаОѕЕНетРяжЛЪЧРрЫЦLseg),ФЃаЭПЩвдзіЮФБОВщбЏЕФ zero-shot МьВтЁЃЕЋЪЧгЩгкФЃаЭЛЙВЛСЫНтЛљДЁРрCBжЎЭтЕФЦфЫћгявхФкШн(XаТРрБ№CN),вђДЫжБНгзі zero-shot ЕФаЇЙћВЛЛсКмКУЁЃ
- NИі
ViLD-textЕуЛ§МЦЫуЙЋЪН:
IБэЪОЭМЦЌ,Іе(I)БэЪОГщШЁЭМЦЌЬиеї,rЮЊproposalsЁЃІе(I)КЭrвЛЦ№НјааRМЦЫуЕУЕН e r e_r er?(region embeddings,ЭМЦЌЬиеї)- e b g e_{bg} ebg?БэЪОБГОАembedding,t_1ЕН t ЈO C B ЈO t_{\left | CB \right |} tЈOCBЈO?БэЪОЛљДЁРрCBЕФЮФБОЬиеї
Text EmbeddingsЁЃ- ЭМЯёЬиеї e r e_r er?ЗжБ№КЭБГОАЬиеї e b g e_{bg} ebg?КЭЮФБОЬиеїзіЕуЛ§МЦЫуЯрЫЦЖШ,зюКѓЕУЕН
ViLD-textФЃаЭЪфГіz(r)(logics)ЁЃz(r)зіsoftmaxКѓКЭgroud truthМЦЫуНЛВцьиЕУЕНетВПЗжЕФЫ№ЪЇЁЃProjectionВуЕФв§ШыЪЧЮЊСЫЭГвЛЭМЯёЮФБОЬиеїЕФГпДчЁЃ
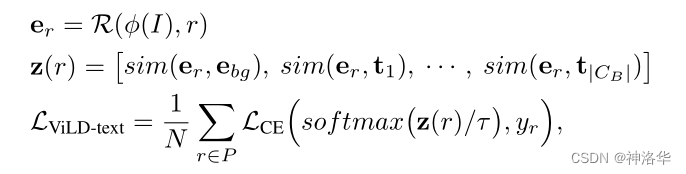
- (/c) :
ViLD-imageЗжжЇ:в§ШыCLIPЬиад,етВПЗжжЛдкбЕСЗЪБНјааеєСѓ,ЭЦРэЪБВЛеєСѓЁЃ
ПМТЧЕНCLIPЕФЭМЦЌБрТыЦїбЕСЗЕФКмКУ,ЖјЧвКЭЮФБОНєУмЙиСЊ,ЫљвдЯЃЭћViLD-image-encoderЪфГіЕФregion embeddingsКЭCLIPЪфГіЕФimage embeddingОЁПЩФмЕФНгНќ,етбљОЭПЩвдбЇЯАЕНCLIPЭМЯёБрТыЦїжаПЊЗХЪРНчЕФЭМЯёЬиеїЬсШЁФмСІЁЃзіЕНетвЛЕуЕФзюМђЕЅЗНЪНОЭЪЧжЊЪЖеєСѓ(Knowledge Distillation)ЁЃ- гвВр
teacherЗжжЇ:НЋMИіproposalsresizeЕНБШШч224ЁС224ЕФГпДч,ШЛКѓЪфШыдЄбЕСЗКУЕФCLIP-image-encoder(ЖГНс,ВЛВЮгыбЕСЗ,БЃжЄГщГіРДЕФЬиеїКЭCLIPвЛбљКУ)ЕУЕНM image embeddings - зѓВр
studentЗжжЇ:КЭViLD-textЗжжЇЧАУцЕФНсЙЙвЛбљ,ЪфШыMИіproposalsЕУЕНMИіregion embeddings - МЦЫу
region embeddingsКЭimage embeddingsЕФL1 lossРДНјаажЊЪЖеєСѓ,ШУМьВтЦїбЇЯА CLIP ЬсШЁЕФЬиеїЁЃ - ЮЊСЫМгЫйФЃаЭбЕСЗ,дкбЕСЗ ViLD-image ЪБЯШгУ CLIP ФЃаЭЬсШЁКУЭМЯёЧјгђЬиеї,БЃДцдкгВХЬжа,дкбЕСЗЪБжБНгДггВХЬЖСШЁМДПЩЁЃ
- ДЫЗжжЇМрЖНаХКХВЛдйЪЧШЫЙЄБъзЂЕФЪ§Он,ЖјЪЧCLIPЕФЭМЯёБрТы,ЫљвдОЭВЛдйЪмЛљДЁРрCBЕФЯожЦСЫ,ЖдгкШЮКЮЕФгявхЧјгђЖМПЩвдгЩ CLIP ГщШЁЭМЯёЬиеїЁЃРћгУ
ViLD-image,ДѓДѓМгЧПСЫзіOpen-vocabularyМьВтЕФФмСІ
- гвВр
ViLD-imageЗжжЇЕФБзЖЫ:дЄМгдибЕСЗКУЕФproposals,ЖјВЛЪЧЫцЪБПЩвдБфЕФN proposals
ДЫЗжжЇЪфШыЪЧ
M pre-complete proposals,етЪЧЮЊСЫбЕСЗМгЫйЁЃРэТлЩЯЕквЛНзЖЮЪфГіЕФ
N proposalsгІИУЪфШыtextКЭimageСНИіЗжжЇНјаабЕСЗ,ЕЋШчЙћУПДЮбЕСЗЪБдйШЅГщШЁCLIPЬиеїОЭЬЋТ§СЫЁЃвђЮЊViLDбЁгУЕФCLIP-LФЃаЭЗЧГЃДѓ,зівЛДЮЧАЯђЙ§ГЬЗЧГЃЙѓЁЃБШШчM=1000ЪБЕШгкУПвЛДЮЕќДњЖМашвЊЧАЯђ1000ДЮВХФмЕУЕНЫљгаЭМЯёЬиеї,етбљбЕСЗЪБМфЛсРЕНЮоЯоГЄЁЃзїепдкетРяЕФзіЗЈОЭЪЧдк
ViLD-imageПЊЪМбЕСЗжЎЧА,РћгУRPNЭјТчдЄЯШГщШЁM pre-complete proposals,ШЛКѓАДееЭМжаЫГађЫуКУM image embeddingsЁЃViLD-imageбЕСЗЪБ,жЛашвЊНЋЦфloadНјРД,етбљlossЫуЦ№РДОЭКмПь,еєСѓЙ§ГЬвВОЭбЕСЗЕФКмПьЁЃ
- (d) :ViLD-text КЭ ViLD-imageЕФКЯЬх
ЮЊСЫбЕСЗМђЕЅ,НЋM pre-complete proposalsКЭN proposalsвЛЦ№ЪфШыМьВтЭЗHeadЕУЕНn+mИіembedding,ШЛКѓВ№ЗжЮЊN region embeddingsКЭM region embeddingsЁЃЧАепЫуViLD-textЗжжЇЕФНЛВцьиЫ№ЪЇ,КѓепЫуViLD-imageЕФеєСѓL1Ы№ЪЇЁЃ
3.1.3 ФЃаЭзмРР
ЯТУцПьЫйЙ§вЛЯТФЃаЭзмРРЭМ:
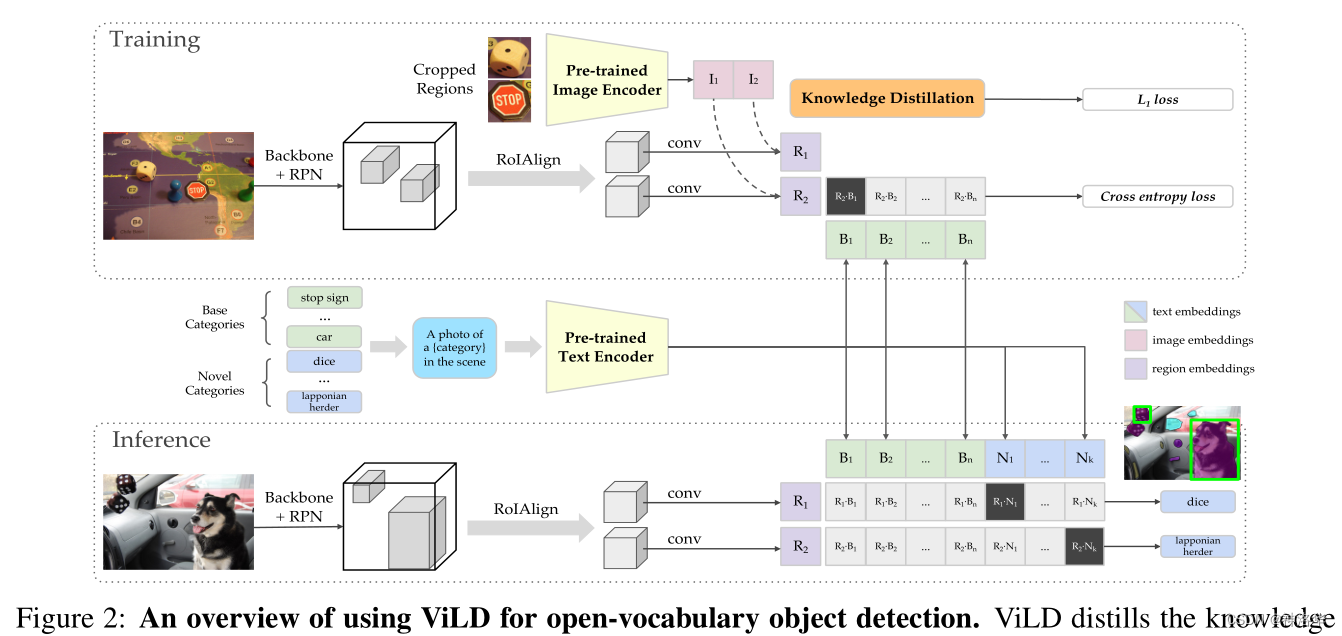
-
бЕСЗ:
- ЭМЦЌЭЈЙ§RPNЭјТчЕУЕН
proposalsЁЃШЛКѓОЙ§RoIAlignКЭвЛаЉОэЛ§ВуЕУЕНN region embeddings,вВОЭЪЧЭМжа R 1 R_1 R1?КЭ R 2 R_2 R2?ЁЃ - ЛљДЁРрЭЈЙ§promptЕУЕНЮФБО,ОЙ§ЮФБОБрТыЦїЕУЕНЮФБОБрТы B 1 B_1 B1?ЕН B n B_n Bn?ЁЃШЛКѓКЭ R 1 R_1 R1?ЁЂ R 2 R_2 R2?вЛЦ№МЦЫуНЛВцьиЁЃ
- НЋвбОГщШЁКУЕФ
M image embeddings(ЭМжаЕФїЛзгЁЂЭЃГЕБъЪЖЕШЕШ)ЪфШыCLIPЭМЯёБрТыЦїЕУЕНЬиеї I 1 I_1 I1?ЁЂ I 2 I_2 I2?,гУЫќУЧЖд R 1 R_1 R1?ЁЂ R 2 R_2 R2?НјааеєСѓ(МЦЫуL1Ы№ЪЇ)
- ЭМЦЌЭЈЙ§RPNЭјТчЕУЕН
-
ЭЦРэ:
- i m a g e Ёњ b a c k b o n e + R P N p r o p o s a l s Ёњ R o I A l i g n + C o n v r e g i o n ? e m b e d d i n g s image\overset{backbone+RPN}{\rightarrow}proposals\overset{RoIAlign+Conv}{\rightarrow}region-embeddings imageЁњbackbone+RPNproposalsЁњRoIAlign+Convregion?embeddings
- C N + C B Ёњ p r o m p t T e x t Ёњ T e x t ? E n c o d e r t e x t ? e m b e d d i n g ( B 1 . . B n + N 1 . . . N k ) CN+CB\overset{prompt}{\rightarrow}Text\overset{Text-Encoder}{\rightarrow}text-embedding(B_1..B_n+N_{1}...N_{k}) CN+CBЁњpromptTextЁњText?Encodertext?embedding(B1?..Bn?+N1?...Nk?)
- c l a s s = a r g m a x ( r e g i o n ? e m b e d d i n g s ? t e x t ? e m b e d d i n g ) class=argmax(region-embeddings\cdot text-embedding) class=argmax(region?embeddings?text?embedding)
3.1.4 ЪЕбщ
- LVis Ъ§ОнМЏ zero-shot аЇЙћЖдБШ
??LVis Ъ§ОнМЏЭМЦЌВЩбљздCOCOЪ§ОнМЏ,ЕЋШДЪЧвЛИіЪЎЗжГЄЮВЕФЪ§ОнМЏЁЃдкБъзЂСЫЕФ1203 Рржа,гаКмЖрРржЛБъзЂСЫМИДЮ,МДКБМћРр,ЫљвдНЋИїИіРрБ№ЗжЮЊ fequentЁЂcommonЁЂrare,БъзЂЪ§вРДЮЕнМѕ,вВОЭЪЧЯТЭМжаЕФ
A
P
f
,
A
P
c
,
A
P
r
AP_f,AP_c,AP_r
APf?,APc?,APr?ЁЃ
??дкБОЮФЕФЪЕбщжа,НЋ
A
P
f
,
A
P
c
AP_f,AP_c
APf?,APc?зїЮЊФЃаЭМћЙ§ЕФЛљДЁРр(ЙВ 886 Рр),
A
P
r
AP_r
APr? зїЮЊаТРр(ЙВ 337 Рр,ФЃаЭУЛгаМћЙ§,ЫљвдПЩвдзіzero-shotМьВт)

??ПЩвдПДЕН ViLD ФЃаЭдкаТРрЩЯЕФ AP ДѓЗљСьЯШЛљЯпФЃаЭSupervised-RFS(RFSЪЧОЁСПВЩбљЮВВПЕФРр,гУгкНтОіГЄЮВЮЪЬт,ЫљвдетЪЧвЛИіКмЧПЕФМЋЯоФЃаЭ),ВЂЧвЪЧзіЕФzero-shotМьВтЁЃЕЋетЪЧПЩвддЄМћЕФ,вђЮЊЖдгкгаМрЖНбЕСЗ,жЛгавЛСНИібљБОПЩФмдНбЕСЗдНВю,ЛЙВЛШчжБНгzero-shotЁЃ
- ЦфЫќЪ§ОнМЏzero-shotаЇЙћ
ЯТЭМЪЧLVis Ъ§ОнМЏЩЯдЄбЕСЗЕФViLDдкPASCAL VOCКЭCOCOЪ§ОнМЏЩЯzero-shotЧЈвЦаЇЙћ,ЖдБШгаМрЖНбЕСЗЕФФЃаЭЛЙЪЧгавЛаЉВюОрЁЃ
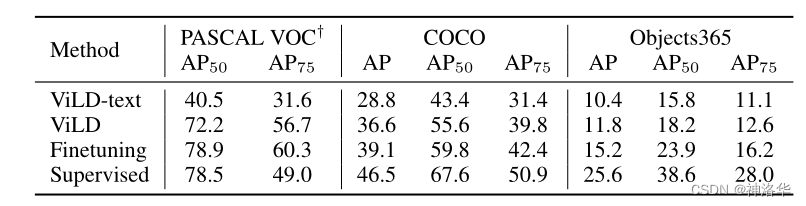

- ЕквЛаа:ViLDФмЙЛе§ШЗЖЈЮЛ,ВЂЪЖБ№аТЕФРрБ№ЁЃЮЊСЫЧхГўЦ№Мћ,ЮвУЧжЛЯдЪОМьВтЕНЕФаТРрЁЃ
- ЕкЖўаа:ViLDЭЌЪБМьВтЛљДЁРрКЭаТРр,ВЂВЛЛсНЕЕЭЛљБОРрБ№ЕФМьВтадФмЁЃ
- КѓСНаа:ViLDПЩвджБНгЧЈвЦCOCOКЭObjects365,ЮоашНјвЛВНЮЂЕїЁЃ
3.1.5 НсТл
??ViLDЪЧЕквЛИідкLVisетУДФбЕФЪ§ОнМЏЩЯзіOpen-vocabularyФПБъМьВтЕФФЃаЭ,ЪЧвЛИіРяГЬБЎЪНЕФЙЄзїЁЃViLDНшМјСЫCLIPЕФЫМЯы,вВНшМјСЫCLIPЕФдЄбЕСЗВЮЪ§,зюКѓЕФНсЙћвВВЛДэЁЃ
3.2 GLIP v1
- ТлЮФЁЖGrounded Language-Image Pre-trainingЁЗЁЂЙйЭјДњТы
GLIPЙтЬ§УћзжКЭCLIPКмЯё,жЛЪЧАбContrastive Language-Image Pre-training(ЛљгкЖдБШЮФБО-ЭМЯёЖдЕФдЄбЕСЗЗНЗЈ)жаЕФContrastiveЛЛГЩСЫGroundedЁЃ
3.2.1 ЧАбд
1. баОПЖЏЛњ:Open-vocabulary Object DetectionЪЧБивЊЕФ
??ФПБъМьВтКЭЗжИювЛбљ,БъзЂЪ§ОнМЏЖМКмЙѓ,ЖдгкБпБпНЧНЧЕФРрКЭВуГіВЛЧюЕФаТРр,ЮвУЧУЛгаАьЗЈбЕСЗвЛИіФЃаЭАбетаЉЖММьВтЕФКмКУЁЃЮвУЧжЛФмвРРЕгкOpen-vocabularyЕФФПБъМьВтФЃаЭ,РДАбетаЉcorner caseЖМДІРэЕФКмКУЁЃ
??ЖјШчЙћЯыбЕСЗвЛИіКмЧПЕФOpen-vocabularyЕФФПБъМьВтФЃаЭ,ОЭжЛФмЯёCLIPвЛбљ,ПЩвдРћгУЩЯвкЙцФЃЕФЕФЪ§ОнМЏ,ЖјЧвЛЙвЊАбЭМЦЌ-ЮФБОЖдгІЙиЯЕКЭЖЈЮЛЖМбЇЕФКмКУЁЃФЧУД жиЕуОЭЪЧЪЙгУЭМЦЌ-ЮФБОЖдЪ§ОнМЏЕФИпаЇЪЙгУ ,вђЮЊКмКУЪеМЏЁЃ
2. НтОіАьЗЈ:phrase grounding+Object Detection+ЮББъЧЉбЕСЗ
??Vision LanguageШЮЮё(ЭМЦЌ-ЮФБОЖрФЃЬЌШЮЮё)РягавЛРрЖЈЮЛШЮЮёVision grounding,жївЊОЭЪЧИљОнЮФБОЖЈЮЛГіЭМЦЌжаЖдгІЕФЮяЬх(ЖЬгяЖЈЮЛphrase grounding),етгыФПБъМьВтШЮЮёЗЧГЃРрЫЦ,ЖМЪЧШЅЭМжаевФПБъЮяЬхЕФЮЛжУЁЃ
??GLIP ЕФЮФеТЕФГіЗЂЕу,ОЭЪЧНЋМьВтЮЪЬтзЊЛЛЮЊЖЬгяЖЈЮЛ(phrase grounding)ЮЪЬт,етбљGLIP ФЃаЭОЭЭГвЛСЫФПБъМьВтКЭЖЈЮЛСНИіШЮЮё,ПЩвдЪЙгУИќЖрЕФЪ§ОнМЏЁЃдйХфКЯЮББъЧЉЕФММЪѕРДРЉдіЪ§Он,ЪЙЕУбЕСЗЕФЪ§ОнСПДяЕНСЫЧАЫљЮДгаЕФЙцФЃ(3MШЫЙЄБъзЂЪ§ОнКЭ24MЭМЮФЖдЪ§Он)ЁЃзюКѓбЕСЗГіРДЕФФЃаЭGLIP-L,жБНгвд zero-shot ЕФЗНЪНдкCOCO КЭLVIS ЩЯНјааЭЦРэ,mAPЗжБ№ДяЕНСЫ 49.8 КЭ26.9,ПЩМћЦфадФмЗЧГЃЕФЧПЁЃ
groudningФЃаЭЕФЪфШыЪЧЖЬгяЁЂЖЬгяжаУћДЪЖдгІЕФПђКЭЭМЦЌЁЃ- ФПБъМьВтзЊЮЊ
phrase grounding:ЭЈЙ§promptЕФЗНЪННЋБъЧЉУћзЊЛЏЮЊЖЬгяЁЃР§Шчcocoга80ИіРрБ№БъЧЉ,НЋ80ИіБъЧЉгУЖККХСЌНг,ВЂдкЖЬгяЧАМгЁАDetect:ЁБРДзщГЩЖЬОфЁЃетбљзігаСНИіКУДІ:
- ФПБъМьВтКЭ
phrase groundingЕФЪ§ОнМЏОЭЖМПЩвдФУРДбЕСЗ- ЖдгкЛљДЁРр КЭЦфЫќИїжжРр,ПЩвдЖМЙЙНЈЕН prompt ЖЬгяжавЛЦ№МьВт,ИќМгЕФСщЛю,ПЩвдЗНБуЕФНЋШЮЮёЧЈвЦЕНПЊЗХЪНФПБъМьВтШЮЮёЕБжаЁЃ
- ЮББъЧЉбЕСЗ(self training):
- НЋЫљгаФПБъМьВтШЮЮёКЭ
phrase groundingШЮЮёЕФЪ§ОнМЏ(вЛЙВ3M)ШЋВПФУРДзігаМрЖНбЕСЗ,ЕУЕНGLIP-T(C)ФЃаЭЁЃ- НЋетИіФЃаЭЖдЭјЩЯХРШЁЕНЕФ
24MЭМЯё-ЮФБОЖдЪ§ОнНјааЭЦРэ,ЕУЕНbounding boxЁЃШЛКѓНЋетаЉbounding boxШЋВПзїЮЊGroundTruth(ЮББъЧЉ),етбљОЭЕУЕНСЫ24MЕФгаМрЖНЪ§ОнЁЃ- зюдкет
24MЕФгаМрЖНЪ§ОнЩЯМЬајбЕСЗ,ЕУЕНзюжеФЃаЭGLIP-LЁЃгЩДЫПЩМћећИіGLIPЖМЪЧгУгаМрЖНЕФЗНЗЈНјаабЕСЗЕФЁЃ
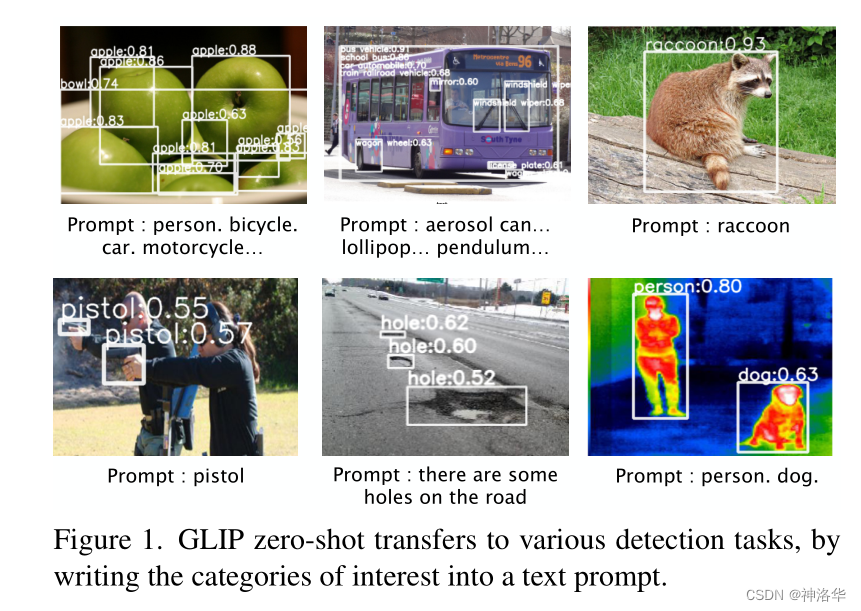
3. zero-shotЭЦРэаЇЙћеЙЪО
??жБНгЯёViLDвЛбљИјГіЮяЬхРрБ№ЩњГЩвЛОфЛА(Prompt : person. bicycle.car. motorcycleЁ)ЛђепЪЧЯёphrase groundingШЮЮёвЛбљЩњГЩЖЬгяЁАТэТЗЩЯгаКмЖрПгЁБ(Prompt : there are some holes on the road),ЖМПЩвдНЋЮяЬхМьВтГіРДЁЃ
3.2.2 Ы№ЪЇМЦЫу
??ФПБъМьВтЕФЫ№ЪЇКЏЪ§гЩЗжРрЫ№ЪЇКЭЖЈЮЛЫ№ЪЇзщГЩЁЃЖдгкФПБъМьВтКЭVision groundingЖјбд,ЖЈЮЛВПЗжЖМВюВЛЖр,ЖўепЕФЧјБ№жївЊдкгкШчКЮМЦЫуЗжРрlossЁЃвђЮЊ detectionЕФБъЧЉЪЧone-hotЕФРрБ№ЕЅДЪ,ЖјVision groundingЕФБъЧЉЪЧвЛИіОфзгЁЃЫљвдашвЊАбЖўепЕФЗжРрlossЭГвЛЕНвЛИіПђМмЯТУц,вВОЭЪЧ:
L
=
L
c
l
s
+
L
l
o
c
.
L = L _{cls}+ L_{loc} .
L=Lcls?+Lloc?.
-
detectionЗжРрЫ№ЪЇМЦЫу:
O = E n c I ( I m g ) , S c l s = O W T , L c l s = l o s s ( S c l s ; T ) . O=Enc_{I}(Img),S_{cls}=OW^{T},L_{cls}=loss(S_{cls};T). O=EncI?(Img),Scls?=OWT,Lcls?=loss(Scls?;T).-
E
n
c
I
Enc_{I}
EncI?БэЪОЭМЦЌБрТыЦї(Р§Шчswin transformer),ДІРэimgжЎКѓЕУЕН
N region embeddings,МД O ЁЪ R N ЁС d O\in \mathbb{R}^{N\times d} OЁЪRNЁСd(nИіbounding box,УПвЛИіЕФЮЌЖШЪЧd); N region embeddingsЁњ c l s ? H e a d S c l s \overset{cls-Head}{\rightarrow}S_{cls} Ёњcls?HeadScls?ЁЃЦфжаЗжРрЭЗcls-HeadгЩОиеѓ W ЁЪ c N ЁС d W\in \mathbb{c}^{N\times d} WЁЪcNЁСdБэЪО,КЭN region embeddingsЯрГЫКѓЕУЕН S c l s ЁЪ R N ЁС c S_{cls}\in \mathbb{R}^{N\times c} Scls?ЁЪRNЁСc;- L c l s = l o s s ( S c l s ; T ) . L_{cls}=loss(S_{cls};T). Lcls?=loss(Scls?;T).:ЪЙгУnmsЩИбЁетаЉbounding box,ШЛКѓКЭGroundTruthМЦЫуНЛВцьи,ЕУЕНЗжРрЫ№ЪЇЁЃ
-
E
n
c
I
Enc_{I}
EncI?БэЪОЭМЦЌБрТыЦї(Р§Шчswin transformer),ДІРэimgжЎКѓЕУЕН
-
Vision groundingЗжРрЫ№ЪЇМЦЫу:(ЦфЪЕКЭViLD textЗжжЇвЛФЃвЛбљ)
O = E n c I ( I m g ) , P = E n c L ( P r o m p t ) , S g r o u n d = O P T O=Enc_{I}(Img),P=Enc_{L}(Prompt),S_{ground}=OP^{T} O=EncI?(Img),P=EncL?(Prompt),Sground?=OPT
- БэЪОЭМЦЌБрТыЦї
E
n
c
I
Enc_{I}
EncI?ДІРэimgжЎКѓЕУЕН
N region embeddings,МД O ЁЪ R N ЁС d O\in \mathbb{R}^{N\times d} OЁЪRNЁСd; - ЮФБОБрТыЦї
E
n
c
L
Enc_{L}
EncL?(БШШчBERT)ДІРэPromptЕУЕН
text embedding,МД P ЁЪ R M ЁС d P\in \mathbb{R}^{M\times d} PЁЪRMЁСd; - ЭМЯёЬиеїOКЭЮФБОЬиеїPЯрГЫЕУЕНЯрЫЦЖШНсЙћ S g r o u n d ЁЪ R N ЁС M S_{ground}\in \mathbb{R}^{N\times M} Sground?ЁЪRNЁСM,МДТлЮФжаЫЕЕФregion-word aligment scoresЁЃ
ЩЯЪНжа,M((sub-word tokensЪ§СП)змЪЧДѓгкЖЬгяЪ§c,двђгаЫФ:
- вЛИіЖЬгязмЪЧАќКЌКмЖрЕЅДЪ
- вЛИіЕЅДЪПЩвдЗжГЩМИИізгДЪ,БШШчtoothbrushЗжГЩСЫ tooth#, #brush
- ЛЙгавЛаЉЬэМгДЪadded tokens,ЯёЪЧЁАDetect:ЁБ,ЖККХЕШ,ЛђепЪЧгябдФЃаЭжаЕФЬиЪтtoken
- tokenizedађСаФЉЮВЛсМгШыtoken
[NoObj]
??дкбЕСЗЕФЪБКђ,ШчЙћЖЬгяphraseЖМЪЧе§Р§( positive match)ВЂЧвadded tokensЖМЪЧИКР§negative match(added tokensКЭШЮКЮЭМЦЌЕФЮяЬхЖМЮоЗЈЦЅХф),ФЧОЭЪЙгУsubwords(subwordsвВЖМЪЧе§Р§,ДЫЪББъЧЉОиеѓгЩ
T
ЁЪ
[
0
,
1
]
N
ЁС
c
T\in [0,1]^{N\times c}
TЁЪ[0,1]NЁСcРЉеЙЮЊ
T
ЁЪ
[
0
,
1
]
N
ЁС
M
T\in [0,1]^{N\times M}
TЁЪ[0,1]NЁСM)ЁЃВтЪдЪБЖрИіtokenЕФЦНОљproзїЮЊЖЬгяЕФprobabilityЁЃ
??ЪЙгУЩЯУцЕФЗНЪНЭГвЛЫ№ЪЇжЎКѓ,ОЭПЩвдгУgroundingФЃаЭЗНЗЈРДдЄбЕСЗМьВтШЮЮё,ДгЖјЪЙGLIPФЃаЭПЩвдзіzero-shotМьВтЁЃжЎКѓзїепЪЙгУЭГвЛЙ§КѓЕФПђМмбщжЄСЫдк COCO Ъ§ОнМЏЩЯЕФжИБъ,ЗЂЯжЪЧЭъШЋЦЅХфЕФ ,вђДЫДгЪЕбщЩЯвВбщжЄСЫздМКЕФЯыЗЈЁЃ
3.2.3 бЕСЗЪ§ОнМЏ
- ЩЯУцШ§ааA,B,CеЙЪОЕФЪЧ
GLIPФЃаЭПЩвдЭЌЪБЪЙгУФПБъМьВтЕФЪ§ОнМЏ,Р§ШчObjects365КЭGroundingЕФЪ§ОнМЏGoldG(МИИіЪ§ОнМЏЕФКЯВЂ,ЛЙЪЧКмДѓЕФ)ЁЃ GLIP-L:backboneЮЊSwin-LФЃаЭ,ШЛКѓЭЌЪБЪЙгУFourODs(ФПБъМьВтгаМрЖНбЕСЗжаФмгУЕФЫљгаЕФЪ§ОнМЏ)ЁЂGoldGКЭЭМЦЌЮФБОЖдCap24MЪ§ОнМЏвЛЦ№бЕСЗ,ДЫЪБЪ§ОнМЏвбОЗЧГЃДѓСЫ,зувдбЕСЗГівЛИіКмЧПЕФФЃаЭЁЃ
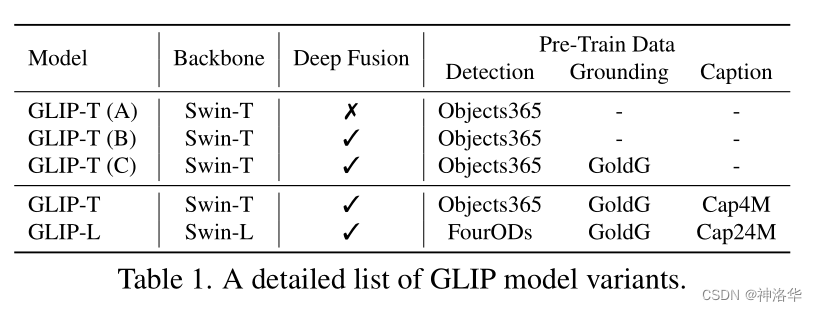
??
Cap24MОЭЪЧ24MЮББъЧЉЪ§ОнЁЃЩњГЩЕФЮББъЧЉПЯЖЈгаДэЮѓ,ЕЋЪЧЪЕбщБэУї,ОЙ§РЉГфДѓСПЮББъЧЉЪ§ОнбЕСЗЕУЕНЕФ GLIP-L ФЃаЭШдШЛЛсгаадФмЬсИпЁЃ
3.2.4 ФЃаЭПђМм
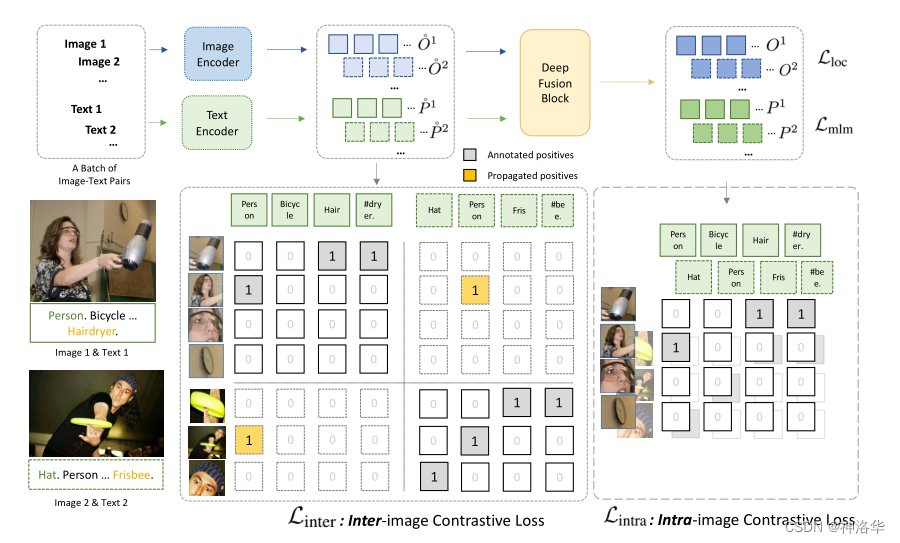
1. змЬхПђМм
??ШчЯТЭМЫљЪО,гЩгкЫљгаЪ§ОнМЏЖМЪЧгаБъзЂЕФ,ЫљвдФЃаЭЪЧвдгаМрЖНЕФЗНЪННјаабЕСЗЁЃМЦЫуЕУЕНЮФБОЬиеїгыЭМЯёЬиеїЕФЯрЫЦЖШжЎКѓ,жБНггы GT boxМЦЫуЖдЦыЫ№ЪЇalignment lossМДПЩ(КЭViLD-textЗжжЇвЛбљ)ЁЃетбљОЭЭъГЩСЫЮФБОКЭЭМЯёЕФЬиеїШкКЯ,ОЭПЩвдНјааzero-shotМьВтСЫЁЃЖјЖЈЮЛЫ№ЪЇвВЪЧжБНггыGT boxМЦЫуL1 Ы№ЪЇЁЃ
??ФЃаЭжаМфЕФШкКЯВу(Deep Fusion)КЭLSegЕФзіЗЈвЛбљ,ЖМЪЧЮЊСЫЪЙЭМЯёЬиеїКЭЮФБОЬиеїНјвЛВННЛЛЅ,ЪЙзюжеЕФЭМЯё-ЮФБОСЊКЯЬиеїПеМф(joined embedding space)бЕСЗЕУИќКУ(ЯрЫЦЕФembeddingРНќ,ВЛЯрЫЦЕФРдЖ),ЭМЯёЬиеїКЭЮФБОЬиеїБЛбЕСЗЕФИќЧПИќгаЙиСЊад,етбљКѓУцМЦЫуЯрЫЦЖШОиеѓЕФаЇЙћПЯЖЈОЭИќКУЁЃ
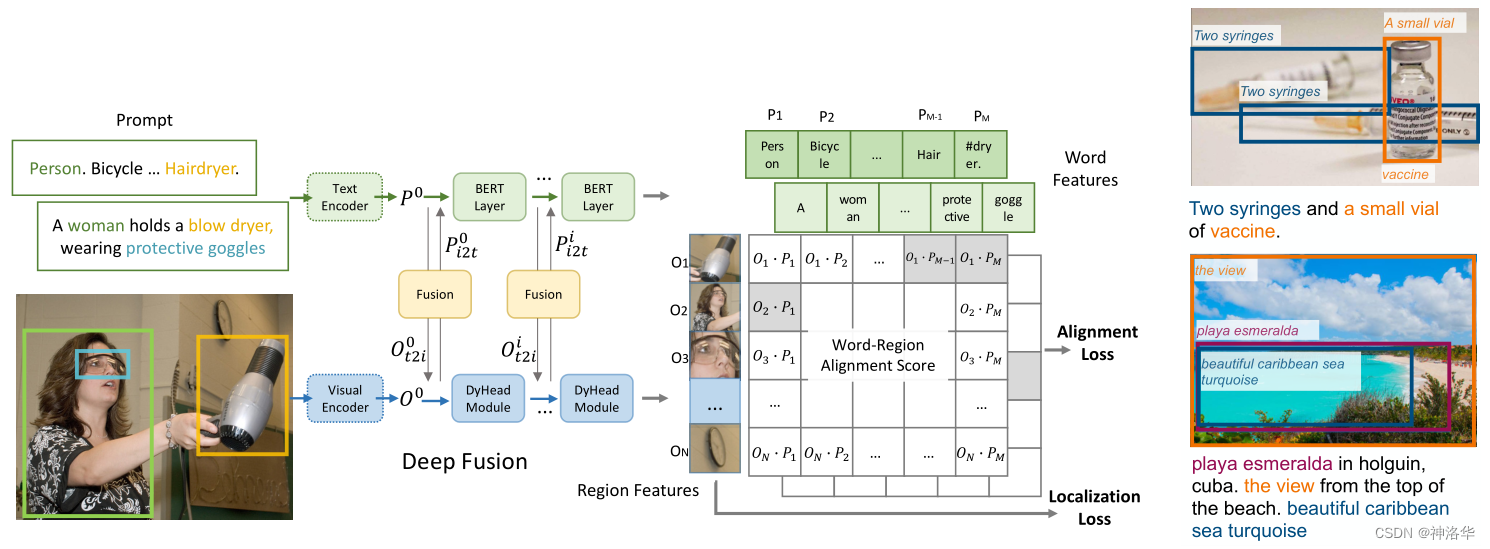
2. Deep FusionВу
- ЭМЦЌБрТыЦїЪЧ
DyHead(LВу),ЕквЛВуЪфГіЭМЦЌЬиеїБэЪОЮЊ O 0 O^0 O0 - ЮФБОБрТыЦїЪЧдЄбЕСЗКУЕФ
BERT(LВу),ЕквЛВуЪфГіЮФБОЬиеїБэЪОЮЊ P 0 P^0 P0 X-MHAБэЪОПчФЃЬЌЖрЭЗзЂвтСІФЃПщЁЃ- ДгНсЙЙЭМКЭЙЋЪНПЩвдПДГі,УПвЛВуЪфГіЕФЭМЮФЬиеї
O
i
,
P
i
O^i,P^i
Oi,PiЖМЛсдк
X-MHAжаНјааНЛЛЅ,НЛЛЅКѓЕФЬиеїКЭдЬиеїЯрМгжЎКѓвЛЦ№ЪфШыЕНЯТвЛВуНјааБрТы,ЕУЕНЯТвЛВуЕФЬиеї O i + 1 , P i + 1 O^{i+1},P^{i+1} Oi+1,Pi+1ЁЃ
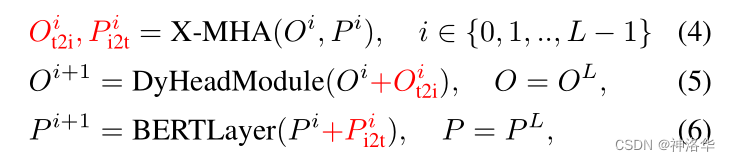
дкX-MHAФЃПщжа,ЭМЯёЬиеїКЭЮФБОЬиеїНЛЛЅЪЙгУЕФЪЧCross Attention:
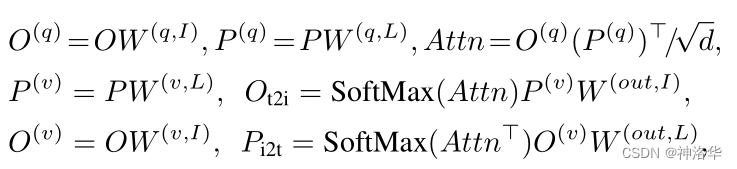
- ЗжИюКЭМьВтЖМЪєгкГэУмадШЮЮё(dence prediction)ЕФвЛжж,ЖМашвЊЭЌЪБЗжРрКЭЖЈЮЛ,ЫљвдКмЖрЗНЗЈЪЧПЩвдЛЅЯрНшМјЕФ,Ыљвд
Deep FusionвВПЩвдгУЕНЗжИюСьгђ,БШШчGroupViTЁЃGroupViTжЛгадкЭМЯёЗжжЇКЭЮФБОЗжжЇЕФзюКѓзіСЫвЛЯТЖдБШбЇЯА,ШчЙћдкДЫжЎЧАзіСЫвЛаЉDeep Fusion,ПЩФмаЇЙћИќКУЁЃ
3. ЭЦРэеЙЪО
ЩЯЭМгвВрзїепеЙЪОСЫСНИіЗЧГЃФбЕФШЮЮё:
- МьВтСНИіеыЙмКЭвЛЦПвпУчЁЃЯжгаЕФЪ§ОнМЏжаЫЦКѕУЛгаеыЙмКЭвпУчетжжРрБ№ЁЃЕЋЪЧGLIPздМКзіГіРДЖдЮФБОЕФРэНт,ИјГіСЫвпУчКЭеыЙмЕФМьВтНсЙћЁЃ
- ИјГіСЫвЛеХЭМЦЌЕФУшЪі:ЁАдкЙХАЭЕФplaya esmeralda,ДгЩЯЭљЯТИЉюЋКЃЬВ,ПДЕНСЫЦЏССЕФКЃТЬЩЋМгРеБШКЃЁБЁЃетаЉУшЪіЖМЪЧвЛаЉБШНЯГщЯѓЕФИХФю,вбОВЛЬЋЯёЪЧЮяЬхСЫ,ЕЋЪЧGLIPвРОЩзіЕУКмКУЁЃ
3.2.5 ЖдБШЪЕбщ
- COCOЪ§ОнМЏНсЙћЖдБШЁЃ
ПЩвдПДЕНGLIPФЃаЭжБНгзі zero-shot МьВтЕФmAPвбОДяЕНСЫ 49.8 ,ШчЙћдйдк COCO ЩЯНјааЮЂЕї,GLIPЕФ НсЙћФмЙЛГЌЙ§ЕБЧАзюКУЕФвЛаЉгаМрЖНЗНЗЈЁЃЕБШЛGLIPКЭЦфЫќФЃаЭЕФдЄбЕСЗЪ§ОнМЏЙцФЃКЭвЛаЉtrickЪЧВЛвЛбљЕФ,ЕЋвВзувдПДГіGLIPЕФЧПДѓжЎДІЁЃ
- LVISЪ§ОнМЏНсЙћЖдБШ
3.3 GLIPv2
ТлЮФЁЖGLIPv2: Unifying Localization and Vision-Language UnderstandingЁЗЁЂДњТы
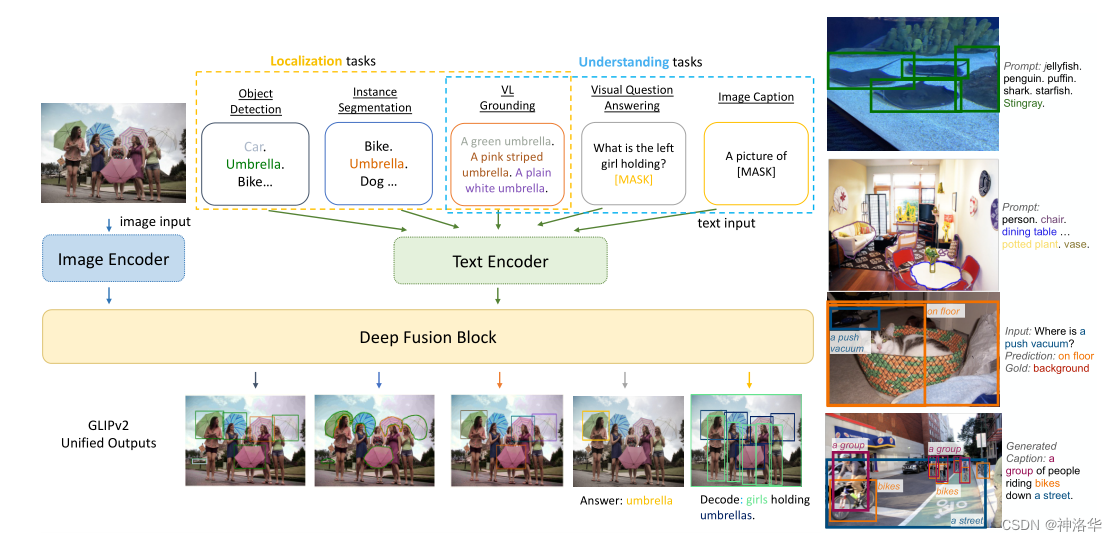
3.3.1МђНщ
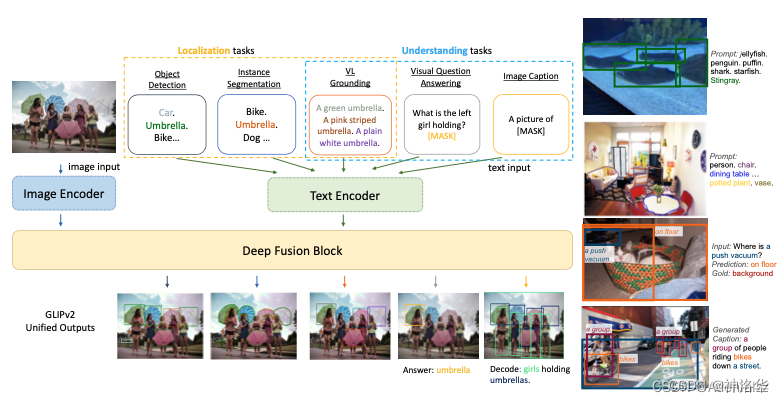
??GLIPv2КЭGLIPv1МмЙЙЛљБОвЛбљ,жЛЪЧШкКЯСЫИќЖрЕФШЮЮёКЭЪ§ОнМЏЁЃДгТлЮФЬтФП Unifying Localization and Vision-Language UnderstandingПЩвдПДГі,ЦфЭГвЛСЫЫљгаЕФЖЈЮЛШЮЮё(БШШчЗжИюКЭМьВт)КЭVision-LanguageШЮЮёЁЃ
Vision-Language:гябд-ЪгОѕШЮЮё,АќРЈ:
vision Caption:ЭМЯёУшЪіЩњГЩ,ИљОнвЛеХЭМЦЌЩњГЩУшЪіадЮФБО;VQA:ИјЖЈвЛеХЭМЦЌКЭвЛИігыИУЭМЦЌЯрЙиЕФздШЛгябдЮЪЬт,МЦЫуЛњФмВњЩњвЛИіе§ШЗЕФЛиД№ЁЃЮФБОQAМДДПЮФБОЕФЛиД№,гыжЎЯрБШ,VQAАбВФСЯЛЛГЩСЫЭМЦЌаЮЪН,ЫљвдетЪЧвЛИіЕфаЭЕФЖрФЃЬЌЮЪЬт;Vision grounding:ИљОнЖЬгяЖЈЮЛЭМЦЌжаЖдгІЕФЮяЬхЁЃ
??ЭЈЙ§ЯТЭМПЩвдПДЕН,БШЦ№GLIPv1,GLIPv2МгСЫвЛаЉtext encoderЕФбЕСЗШЮЮё,ЪЙЦфБэеїИќМгЗсИЛЁЃБШШчЖЈЮЛШЮЮёВЛЙтгаФПБъМьВтЛЙгаЪЕР§ЗжИю,UnderstandingШЮЮёАќКЌСЫVision groundingЁЂvision CaptionКЭVQAШЮЮёЁЃ
??ШЛКѓОЭЪЧЭМЦЌЬиеїКЭЮФБОЬиеїзіDeep Fusion,КѓУцОЭЪЧвЛбљЕФДІРэСЫЁЃЯёетбљдкЭГвЛПђМмЯТФвРЈИќЖрШЮЮёИќЖрЪ§ОнМЏИќЖрФЃЬЌвВЪЧЕБЧАЕФвЛжжЧїЪЦ,БШШчШЅФъЕФOFAЁЂНёФъЕФUnified-IOЕШЕШЁЃ
3.3.2Ы№ЪЇКЏЪ§
дкGLIPv2 ЕБжаЖдЫ№ЪЇКЏЪ§зіСЫИФНј,дкдгаgroundЫ№ЪЇЕФЛљДЁЩЯМгШыСНжжЫ№ЪЇ:
L
G
L
I
P
v
2
=
L
l
o
c
+
L
i
n
t
r
a
?
L
g
r
o
u
n
d
+
L
i
n
t
e
r
+
L
m
l
m
{L_{GLIPv2}=\underset{L_{ground}}{\underbrace {L_{loc}+L_{intra}}}+L_{inter}+L_{mlm}}
LGLIPv2?=Lground?
Lloc?+Lintra???+Linter?+Lmlm?
-
ЬэМг
MLMЫ№ЪЇ:ЬэМгетвЛЫ№ЪЇПЩвдЧПЛЏФЃаЭЕФгябдЬиадЁЃФмЙЛЪЙЕУбЕСЗГіРДЕФФЃаЭФмЙЛРЉеЙЕН VQA / ImageCaption ШЮЮёЩЯЁЃ -
ЭМЦЌМфЕФЖдБШбЇЯАЫ№ЪЇ L i n t e r L_{inter} Linter?ЁЃ
дЯШЕФimage-text pair,жЛФмПДЕНpairФкВПЕФаХЯЂЁЃБШШчвЛЖдЪ§ОнЪЧвЛИіШЫБЇзХУЈЕФееЦЌКЭЖдгІЕФЮФБОУшЪіЁЃАДеедЯШЕФ loss ЩшМЦ,ЭМЦЌжаЕФШЫжЛФмЙЛзіЕНКЭ ЁЎpersonЁЏ ЯрЫЦ, КЭ ЁЎcatЁБ ВЛЯрЫЦ,ЕЋЪЧУЛгаАьЗЈКЭЫљгаЦфЫќЭМЦЌжаИїжжИїбљЕФЪЕЬхНјааЧјЗжЁЃЫљвддкДЫПМТЧМгШыЭМЦЌМфЕФЖдБШЫ№ЪЇЁЃ
ЖдБШЫ№ЪЇЕФМЦЫуЗНЗЈ:
- ЖдвЛИіbatch ЕБжаЫљгаЕФpair ,ГщШЁЦфЮДНЛЛЅЕФЭМЦЌЬиеїКЭЮФБОЬиеї O Ёу = E n c V ( I m g ) , P Ёу = E n c L ( T e x t ) \overset{{\circ }}{O}=Enc_{V}(Img),\overset{{\circ }}{P}=Enc_{L}(Text) OЁу=EncV?(Img),PЁу=EncL?(Text)
- МЦЫувЛИіbatchФк,ЫљгаЭМЦЌЬиеїКЭЮФБОЬиеїЕФЯрЫЦЖШ S g r o u n d b a t c h [ i , j ] = O Ёу i ( P Ёу j ) T S_{ground}^{batch}[i,j]=\overset{{\circ }}{O}{_{}}^{i}(\overset{{\circ }}{P}{_{}}^{j})^{T} Sgroundbatch?[i,j]=OЁу?i(PЁу?j)T,етбљОЭПЩвдЭЈЙ§ПчЭМЯёЦЅХфЕФЗНЪН,ЪЙЕУУПвЛИіobject/token ЖМФмЙЛПДЕНИќЖрЕФИКбљБОЁЃЫљвдЮвУЧВЛНіНіЖдЭМЦЌКЭЮФзжНЛЛЅКѓЕФЬиеїНЈФЃ,вВвЊЖдгкЭМЦЌКЭЮФБОНЛЛЅЧАЕФЬиеїНЈФЃ,РрЫЦloopiterЁЃ
- ПчбљБОЦЅХфЕФЪБКђ,ЭМЦЌA ЕБжаЕФЁЎШЫЁЏетИіЮяЬх,КЭЭМЦЌB ЖдгІЕФprompt ЕБжаЕФ ЁЎpersonЁЏРрБ№,вВгІИУЪЧЦЅХфЕФ
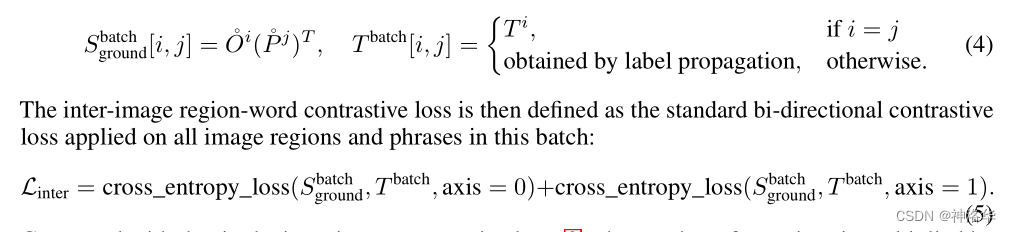
3.3.3 ФЃаЭНсЙЙ
ФЃаЭзмРРЭМШчЯТ:
3.3.4 ФЃаЭаЇЙћ
- ЮвУЧНЋ
GLIPv2КЭЯТБэжаЕБЧАЕФФПБъМьВтКЭvision-languageдЄбЕСЗФЃаЭ,дк8ИіЯТгЮШЮЮёЩЯНјааЖдБШЁЃ
ЪЕбщНсЙћБэУї,ЕЅИі GLIPv2 ФЃаЭ(ЫљгаФЃаЭШЈжиЙВЯэ)дкИїжжЖЈЮЛКЭРэНтШЮЮёЩЯЪЕЯжСЫНгНќ SoTA ЕФадФмЁЃИУФЃаЭЛЙеЙЪОСЫдкПЊЗХДЪЛуФПБъМьВтШЮЮёЩЯЕФЧПДѓЕФzero-shotКЭfew-shotадФмвдМАдк VL РэНтШЮЮёЩЯЕФГіЩЋЕФgroundingФмСІЁЃ

SOTA:state-of-the-art ,ЕБЧАзюКУ/зюЯШНјЕФФЃаЭ
- ЯТУцЪЧВЛЭЌЙцИёЕФ
GLIPv1/GLIPv2ФЃаЭ,дкжБНгЭЦРэКЭ prompt tuningЪБЕФЖдБШНсЙћ:(ЛвЩЋБэЪОбЕСЗЪБгУСЫетИіЪ§ОнМЏ,ЫљвдЮоЗЈНјааzero-shotЭЦРэ)
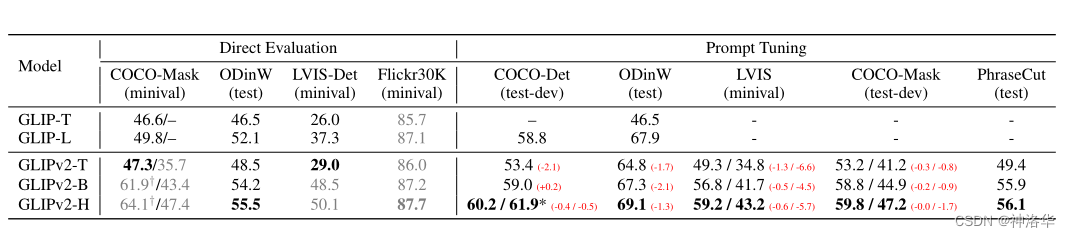
- ЯћШкЪдбщ
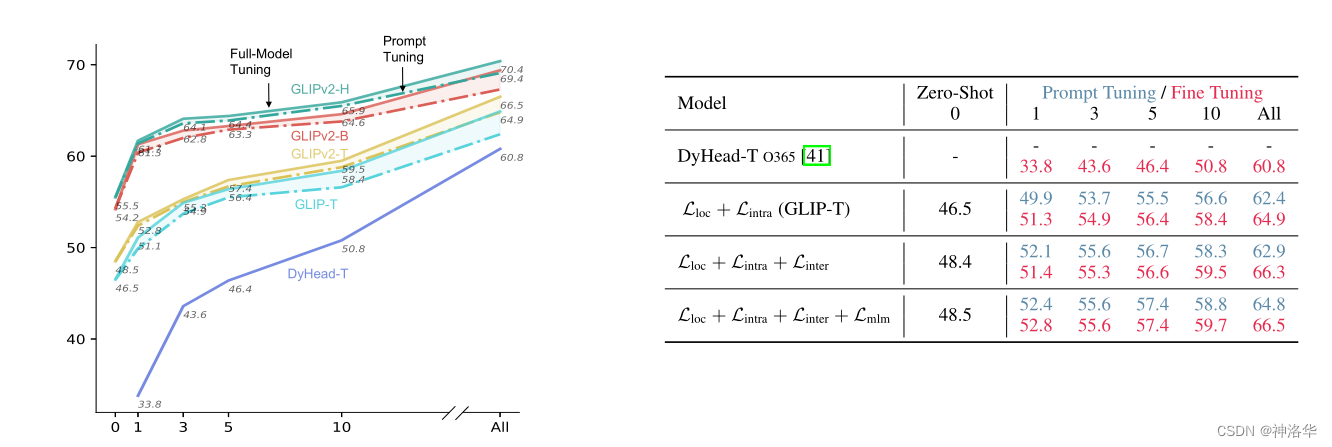
- зѓВрxжсБэЪОЪЙгУВЛЭЌЪ§СПЕФЯТгЮШЮЮёбљБО,yжсЪЧ13ИіЪ§ОнМЏЩЯЕФЦНОљAP;
- гвВрЪЧЪЙгУВЛЭЌНсЙЙЕФlossЪБдк
ODinWЪ§ОнМЏЩЯЕФЕФЯћШкЪдбщНсЙћ; zero-shot GLIPv2-T(48.5) ГЌЙ§СЫ5-shot DyHead-T (46.4)one-shot GLIPv2-H(61.3) ГЌЙ§СЫгУЫљгаЪ§Он(ALL)НјаагаМрЖНЮЂЕїЕФDyHead-T (60.8).
ЫФЁЂCLIPЭМЯёЩњГЩ
4.1 CLIPassoЩњГЩМЋМђЛ
- ТлЮФ:CLIPasso: Semantically-Aware Object SketchingЁЂДњТы
- РюухТлЮФОЋЖСЯЕСажЎЁЖCLIP ИФНјЙЄзїДЎНВ(ЯТ)ЁЗЁЂБЪМЧЁЖCLIP ИФНјЙЄзїДЎНВ(ЯТ)ЁЗ
4.1.1 ЧАбд:ЮЊКЮгжЪЧ CLIP?
??CLIPassoЛёЕУСЫ2022ФъЕФSIGGRAPHзюМбТлЮФНБ,ЦфТлЮФЬтФПSemantically-Aware Object Sketching,втЫМОЭЪЧгявхИажЊЕФЮяЬхЫиУшЁЃДгЯТУцАќКЌгаБЯМгЫї(Picasso)УћЛЕФетеХЭМ,ПЩвдПДГіCLIPassoОЭЪЧCLIPКЭБЯМгЫїЕФЫѕаД,етаЉЖМБэУїСЫетЪЧвЛЦЊбаОПДгЭМЦЌЩњГЩМђБЪЛЕФЮФеТЁЃ

БОЮФЮЊЪВУДгжбЁдёСЫCLIP?
- БЃГж
Semantically-Aware(гявхИажЊ)ЁЃ
??вђЮЊзїепЯызіЕФОЭЪЧгУзюМђЕЅЕФЫиУш,МИБЪОЭАбЮяЬхУшЪіГіРД,ЭЌЪБДѓМвгжФмШЯГіРД,етбљОЭБиаыБЃжЄгявхЩЯКЭНсЙЙЩЯЖМФмБЛЪЖБ№ВХааЁЃПЩвдПДГіетжжЫиУшЪЧКмФбЕФ,БиаызЅзЁЮяЬхзюЙиМќЕФЬиеїВХаа,вВОЭЪЧеЊвЊЬсЕНЕФвЊгаЖдЮяЬхГщЯѓЕФФмСІЁЃ
??ЯТЭМЪЧБЯМгЫїЕФУћЛвЛЭЗЙЋХЃ,етИіЯЕСаДгЕквЛеХЭМЛЕНзюКѓ,ЛЈСЫДѓИХвЛФъЁЃзїепеЙЪОЕФОЭЪЧЯыЪфШывЛеХЭМ,ЪфГізюКѓЕФМђБЪЛ,ПЩМћетЦфжаГщЯѓЪЧКмживЊЕФ,вВЪЧКмФбЕФЁЃ

- АкЭбгаМрЖНбЕСЗЕФЪ§ОнМЏ
??жЎЧАвВгавЛаЉЯрЙиЙЄзї,ЕЋЖМЪЧЪеМЏвЛаЉЫиУшЪ§ОнМЏ(sketch datasets)НјаабЕСЗ,ЖјЧвГщЯѓГЬЖШвВЪЧБЛЙЬЖЈЕФЁЃетжжdata-driven(Ъ§ОнЧ§ЖЏ)ЕФЗНЪН,гаЪВУДЪ§ОнМЏОЭбЇГіЪВУДФЃаЭ,ЫљвдзюКѓЩњГЩЕФЫиУшЕФаЮЪНКЭЗчИёЗЧГЃЪмЯо,ЮЅБГСЫЭМЯёЩњГЩЕФГѕждСЫЁЃ
??ЫиУшЪ§ОнМЏКмЩй,бЇЕНЕФжжРрКЭЗчИёВЛЙЛЗсИЛЁЃБШШчЯТЭММИИіЫиУшЪ§ОнМЏ,SketchyCOCOжЛга9РрЮяЬх,ЖМЪЧГЃМћЕФЖЏЮяЁЃзюаТЕФgoogleЪеМЏЕФQuickDraw(РДздгкДѓМвдкЭјЩЯЕФЭПбЛ),ЫфШЛга5000ЭђЭМЯё,ЕЋЪЧжЛга300ЖрИіРрБ№ЁЃбЕСЗЭъЕФФЃаЭХіЕНетаЉРрБ№жЎЭтЕФЮяЬхПЩФмЪЧЮоЗЈЩњГЩзМШЗЕФЫиУшЕФ,ЛЙашвЊЪеМЏЯргІЕФЪ§ОнНјааЮЂЕїЁЃ
??ЫљвдзіЕНетСНЕузюжБНгЕФД№АИОЭЪЧCLIPЁЃCLIPЭМЮФХфЖдбЇЯАЕФЗНЪН,ЪЙЦфЖдЮяЬхЬиБ№УєИа,ЖдЮяЬхЕФгявхаХЯЂзЅШЁЕФЗЧГЃКУ;ЖјЧвЛЙгаГіЩЋЕФzero-shotФмСІ,ЭъШЋВЛгУдкЯТгЮШЮЮёЩЯНјааШЮКЮЕФЮЂЕї,ФУЙ§РДОЭПЩвджБНггУ,ЫљвдОЭгаСЫCLIPassoЁЃ
??дкПЩЪгЛЏЦкПЏ
distillЩЯЗЂБэЕФВЉПЭЁЖMultimodal Neurons in Artificial Neural NetworksЁЗжа,зїепЖдCLIPФЃаЭЕФЖдПЙадЙЅЛїЁЂOCRЙЅЛїЁЂЮШНЁадЕШЕШЖМЗжЮіЕФЗЧГЃЭИГЙ,ЗЧГЃжЕЕУвЛЖС,етЦфжаОЭАќРЈCLIPЖдМђБЪЛЕФЧЈвЦЮЪЬтЁЃвђЮЊжЎЧАCLIPЖМЪЧДІРэЕФздШЛЭМЯё,ЫљвдЧЈвЦЕНМьВтЗжИюаЇЙћЖМКмКУЁЃЕЋЪЧМђБЪЛКЭздШЛЭМЯёЗжВМЭъШЋВЛЭЌ,ЮоЗЈХаЖЯCLIPЪЧЗёФмКмКУЕФЙЄзїЁЃ
??дкЮФеТжа,зїепЙлВьЕНВЛЙмЭМЦЌЗчИёШчКЮ,CLIPЖМФмАбЮяЬхЕФЪгОѕЬиеїГщШЁЕФКмКУ ,вВОЭЪЧЗЧГЃЕФЮШНЁ,гЩДЫВХЕьЖЈСЫCLIPassoЕФЙЄзїЛљДЁЁЃ(ЦфЪЕБОЮФвВНшМјСЫCLIPDraw)
4.1.2 еЊвЊ
??гЩгкЯпУшОпгаМђЕЅКЭзюаЁЛЏЕФЬиад,вђДЫ ГщЯѓЪЧЫйаДЭМЕФКЫаФЁЃГщЯѓашвЊЪЖБ№вЛИіЮяЬхЛђГЁОАЕФЛљБОЪгОѕЪєад,ашвЊгявхРэНтКЭЖдИпМЖИХФюЕФЯШбщжЊЪЖ ЁЃвђДЫ,ГщЯѓУшЛцЖдвеЪѕМвРДЫЕЪЧвЛжжЬєеН,ЖдЛњЦїРДЫЕИќЪЧШчДЫЁЃ
??БОЮФЬсГіЕФCLIPasso,ЪЧвЛжжПЩвддкМИКЮМђЛЏКЭгявхМђЛЏЕФжИЕМЯТЪЕЯжВЛЭЌГЬЖШГщЯѓЕФЮяЬхЫйаДЗНЗЈЁЃЫфШЛЫйаДЩњГЩЗНЗЈЭљЭљвРРЕУїШЗЕФЫиУшЪ§ОнМЏНјаабЕСЗ,ЕЋЪЧБОЮФРћгУCLIPЕФЧПДѓФмСІ,ДгЫйаДКЭЭМЯёжаЬсСЖгявхИХФю ,НЋЫйаДЖЈвхЮЊвЛзщБДШћЖћЧњЯпЁЃШЛКѓгУвЛИіПЩЮЂЕїЙтеЄЛЏЦїжБНгеыЖдЛљгкCLIPЕФИажЊЫ№ЪЇ,гХЛЏЧњЯпВЮЪ§ЁЃ
??МђБЪЛЕФГщЯѓГЬЖШПЩвдЭЈЙ§ИФБфБЪЛЪ§СПРДПижЦ,ЦфЩњГЩЕФВнЭМеЙЪОСЫЖрВуЕФДЮГщЯѓад,ЭЌЪББЃГжСЫПЩЪЖБ№адЁЂЛљБОНсЙЙКЭЫљЛЖдЯѓЕФЛљБОЪгОѕГЩЗжЁЃИУЗНЗЈПЩЭЦЙуЕНИїжжРрБ№,ВЂгІЖдОпгаЬєеНадЕФГщЯѓЫЎЦН,ЭЌЪББЃГжгявхЩЯЕФЪгОѕЯпЫї,вдЪЕЯжЪЕР§МЖКЭРрБ№МЖЕФЪЖБ№ЁЃ
4.1.3 ФЃаЭНсЙЙ
??зїепЖдбЕСЗЗНЪНЁЂlossбЁдёКЭМђБЪЛГѕЪМЩшжУЖМгаЫљИФНј,ВХДяЕНзюжеЗЧГЃКУЕФаЇЙћЁЃБШШчЯТЭМ,ЭЈЙ§ЩшжУВЛЭЌЕФБЪЛЪ§,ПЩвдЖдЭМЯёНјааВЛЭЌВуДЮЕФГщЯѓ:

1. бЕСЗЙ§ГЬ
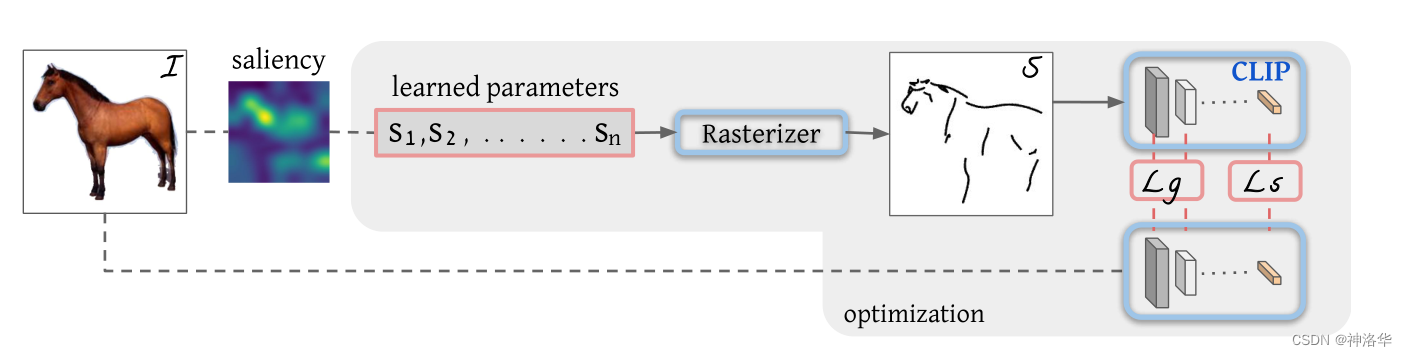
??ЩњГЩМђБЪЛЕФЗНЗЈВЛЪЧжБНгзіЭМЕНЭМЕФЩњГЩ,ЖјЪЧЪЙгУЭМаЮбЇжаЕФБДШћЖћ(БДзШ)ЧњЯпРДЭъГЩМђБЪЛцЛЁЃБДШћЖћЧњЯпОЭЪЧЭЈЙ§дкЦНУцЩЯЖЈвхЕФМИИіЕуРДШЗЖЈвЛЬѕЧњЯпЁЃБОЮФжа,УПЬѕЧњЯпЪЧЭЈЙ§ЫФИіЕуРДШЗЖЈ,УПИіЕуЖМгаЦфx,yзјБъ,МД s i = { p i j } j = 1 4 = { ( x i , y i ) j } j = 1 4 s_{i}=\left \{ p_{i}^{j} \right \}_{j=1}^{4}=\left \{(x_{i},y_{i})^{j}\right \}_{j=1}^{4} si?={pij?}j=14?={(xi?,yi?)j}j=14?ЁЃЦфжаsЪЧБЪЛStrokeЕФЫѕаД,jДг1ЕН4БэЪОЦфгЩ4ИіЕуПижЦЁЃ
??ЫљвдБОЮФЕФЗНЗЈОЭЪЧЫцЛњГѕЪМЛЏвЛаЉБДШћЖћЧњЯп,ШЛКѓОЙ§ВЛЭЃЕФбЕСЗ,ИќИФетаЉЕуЕФЮЛжУ,ДгЖјИќИФБДШћЖћЧњЯп,ЕУЕНзюжеЕФМђБЪЛЁЃбЕСЗЙ§ГЬШчЯТЭМЫљЪО:
Rasterizer:ЙтеЄЛЏЦї,ЭМаЮбЇЗНЯђИљОнВЮЪ§ЛцжЦБДШћЖћЧњЯпЕФвЛжжЗНЗЈ,ПЩЕМЁЃЫљвдетВПЗжЪЧЪЧвдЧАОЭгаЕФЗНЗЈ,ВЛзіШЮКЮИФЖЏЁЃ- БОЮФбаОПЕФжиЕу:ШчКЮбЁдёвЛИіИќКУЕФГѕЪМЛЏ;вдМАШчКЮбЁдёКЯЪЪЕФlossНјаабЕСЗЁЃ
- ГѕЪМЖЈвхвЛаЉБДШћЖћЧњЯп
s
1
s_1
s1?ЕН
s
n
s_n
sn?,ШЛКѓШгИјЙтеЄЛЏЦї
Rasterizer,ОЭПЩвддкЖўЮЌЛВМЩЯЛцжЦГіЮвУЧПДЕУЕНЕФЭМЯёЁЃ - ИљОнlossбЕСЗБЪЛВЮЪ§,ЕУЕНзюжеЕФФЃаЭЪфГіЁЃ
2. ФПБъКЏЪ§
??ЩњГЩЕФМђБЪЛгаСНИівЊЧѓ,МДдкгявхКЭНсЙЙЩЯКЭдЭМБЃГжвЛжТЁЃБШШчТэЛЙЪЧТэЁЂХЃЛЙЪЧХЃ;ЖјЧвВЛФмЩњГЩСЫТэ,ЕЋЪЧТэЭЗЕФГЏЯђЗДСЫ,ЛђепТэДгеОзХБфГЩХПзХЁЃдк CLIPasso жа,етСНИівЊЧѓЗжБ№гЩСНИіЫ№ЪЇКЏЪ§ЁЊЁЊгявхЫ№ЪЇ
L
s
L_s
Ls?КЭМИКЮОрРыЫ№ЪЇ
L
g
L_g
Lg?РДБЃжЄЁЃ
-
L
s
L_s
Ls?:semantics loss,МЦЫудЭМЬиеїКЭМђБЪЛЬиеї,ЪЙЖўепОЁПЩФмЯрЫЦЁЃ
??ЪЙгУCLIPеєСѓCLIPassoФЃаЭ(РрЫЦViLD),ПЩвдШУФЃаЭЬсШЁЕНЕФЭМЯёЬиеїКЭ CLIP ЭМЯёБрТыЦїЬсШЁЕФЬиеїНгНќЁЃетбљОЭНшжњСЫИеИеЬсЕНЕФCLIPЕФЮШНЁад,МДЮоТлдкдЪМздШЛЭМЯёЩЯЛЙЪЧМђБЪЛЩЯЖМФмКмКУЕФГщШЁЬиеїЁЃШчЙћЖўепУшЪіЕФЪЧЭЌвЛЮяЬх,ФЧУДБрТыКѓЕФЬиеїЖМЪЧЭЌвЛгявх,ЦфЬиеїБиШЛЯрНќЁЃ -
L
g
L_g
Lg?:geometric distance loss,МЦЫудЭМКЭМђБЪЛЕФЧГВуБрТыЬиеїЕФlossЁЃ
??НшМјСЫвЛаЉLowerLevelЕФЪгОѕШЮЮёЁЃвђЮЊдкФЃаЭЕФЧАМИВу,бЇЯАЕНЕФЛЙЪЧЯрЖдЕЭМЖЕФМИКЮЮЦРэаХЯЂ,ЖјЗЧИпВугявхаХЯЂ,ЫљвдЦфАќКЌСЫвЛаЉГЄПэАЁетаЉаХЯЂ,ЖдМИКЮЮЛжУБШНЯУєИаЁЃвђДЫдМЪјЧГВуЬиеїПЩвдБЃжЄдЭМКЭМђБЪЛЕФМИКЮТжРЊИќНгНќЁЃ(БШШчCLIPдЄбЕСЗФЃаЭbackboneЪЧResNet50,ОЭНЋResNet50ЕФstage2,3,4ВуЕФЪфГіЬиеїГщГіРДМЦЫуloss,ЖјЗЧГиЛЏКѓЕФ2048ЮЌЬиеїШЅМЦЫу)
3. ГѕЪМЛЏ
??зїепЗЂЯж,ШчЙћЭъШЋЫцЛњГѕЪМЛЏБДШћЖћЧњЯпЕФВЮЪ§,ЛсЪЙЕУФЃаЭбЕСЗКмВЛЮШЖЈЁЃЩњГЩЕФМђБЪЛгаЕФМШМђЕЅгжКУПД,гаЕФдѕУДбЕСЗЖМЛжИДВЛСЫгявх,ЩѕжСОЭЪЧвЛЭХду,ЫљвдашвЊевЕНвЛжжИќЮШЖЈЕФГѕЪМЛЏЗНЪНЁЃ
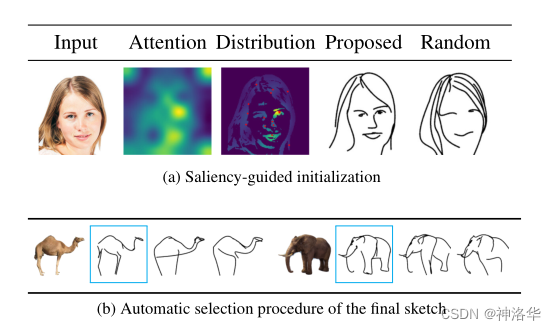
??Лљгкsaliency(Яджјад)ЕФГѕЪМЛЏ:НЋЭМЯёЪфШыViTФЃаЭ,ЖдзюКѓЕФЖрЭЗздзЂвтСІШЁМгШЈЦНОљ,ЕУЕНsaliency mapЁЃШЛКѓдкsaliency mapЩЯИќЯджјЕФЧјгђВЩЕуЭъГЩБДШћЖћЧњЯпВЮЪ§ЕФГѕЪМЛЏ,етбљбЕСЗЮШЖЈСЫКмЖр,аЇЙћвВЦеБщКУСЫКмЖрЁЃ
??дкЯджјадЧјгђВЩЕу,ЯрЕБгкФувбОжЊЕРетРягаИіЮяЬх(гявхИќУїШЗ),ЛђепвбОЯрЕБгкбизХЮяЬхЕФБпНчШЅЛцжЦБДШћЖћЧњЯпСЫЁЃетбљГѕЪМЛЏЧњЯпКЭзюжеМђБЪЛЧњЯпвбОБШНЯНгНќСЫЁЃ
??ЯТЭМaеЙЪОСЫЯджјадГѕЪМЛЏЩњГЩНсЙћ(Proposed )КЭЫцЛњГѕЪМЛЏЕФЩњГЩНсЙћ(Random)ЕФаЇЙћЖдБШ,ПЩвдПДЕНProposedЕФСГВПЬиеїИќНгНќдЭМ,ЖјЧвЭЗЗЂИќМгМђдМЁЃ
??етРязїепЛЙАбздзЂвтСІЕФЭМКЭзюКѓЕФВЩЕуЗжВМЭМПЩЪгЛЏСЫГіРДЁЃПЩвдПДЕНВЩЕуЗжВМЭМвбОКЭзюжеЕФМђБЪЛЭМЯёЗЧГЃНгНќСЫЁЃ
??ЭМbЪЧБОЮФЕФвЛжжКѓДІРэВйзїЁЃCLIPassoЖдУПеХЭМЩњГЩШ§еХМђБЪЛ,зюКѓМЦЫуУПеХМђБЪЛКЭдЭМЕФloss(
L
s
+
L
g
L_s+L_g
Ls?+Lg?),ЕїГіlossзюЕЭЕФвЛеХзїЮЊзюжеНсЙћ(РЖЩЋПђ)ЁЃ
??етжжКѓДІРэдкЮФЩњЭМжаКмГЃМћ,БШШч
DALL-EЁЃИљОнЮФБОЩњГЩКмЖрЭМЯё,ШЛКѓНЋетаЉЩњГЩЕФЭМЦЌдкCLIPжагжШЅМЦЫуСЫвЛЯТКЭдЮФБОЕФЯрЫЦад,ЬєГіЯрЫЦадзюИпЕФеЙЯжГіРД,ЭљЭљПЩвдДяЕНзюКУЕФаЇЙћЁЃ
4. бЕСЗПЩЪгЛЏ
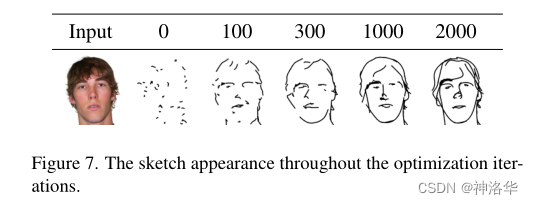
??бЕСЗвЛАуашвЊ2000ДЮЕќДњ,ЕЋвЛАуЕќДњ100ДЮОЭФмПДГіДѓИХТжРЊСЫЁЃЖјЧвзїепдкИНТМРяЫЕ,CLIPassoЕФбЕСЗКмПьЁЃдквЛеХV100ЕФПЈЩЯ,гУ6minОЭПЩвдЭъГЩет2000ДЮЕќДњЁЃЫљвддкМЦЫузЪдДВЛзуЕФЪБКђПЩвдЪдЪдетжжПчНчбаОПЁЃ
4.1.4 ЪЕбщНсЙћ
-
НшжњCLIPЕФ
zero-shotФмСІ,CLIPassoЖдВЛГЃМћЮяЬхвВФмЩњГЩМђБЪЛ
жЎЧАЕФЗНЗЈжЛФмЖдЪ§ОнМЏжагаЕФЮяЬхЩњГЩМђБЪЛ,ЖјКмФбзіЕНЖдКБМћЮяЬхЕФЩњГЩЁЃ

-
ШЮвтПижЦГщЯѓГЬЖШ
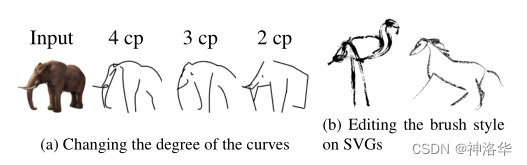
-
ЖдБШЦфЫќЗНЗЈ
4.1.5 ОжЯоад
- ЪфШыЭМЦЌгаБГОАЪБ,ЩњГЩЕФаЇЙћДѓДђелПлЁЃ
??ЪфШыЭМЦЌБиаыЪЧвЛИіЮяЬх,ЧвдкДПАзЩЋЕФБГОАЩЯ,ЩњГЩЕФаЇЙћВХзюКУЁЃвђЮЊжЛгаетбљ,здзЂвтСІЭМВХИќзМ,ГѕЪМЛЏаЇЙћВХЛсКУ,ЖјгаСЫБГОА,здзЂвтСІОЭЛсИДдгКмЖрЁЃ
??ЫљвдзїепЪЧЯШНЋЭМЦЌЪфШыU2Net,ДгБГОАжаПйГіЮяЬх,ШЛКѓдйзіЩњГЩЁЃетбљОЭЪЧСННзЖЮЕФЙ§ГЬ,ВЛЪЧЖЫЕНЖЫ,ЫљвдВЛЪЧзюгХЕФНсЙЙЁЃШчКЮФмШкКЯСНИіНзЖЮЕНвЛИіПђМм,ЩѕжСЪЧдкЩшМЦlossжаШЅГ§БГОАЕФгАЯь,ФЃаЭЪЪгУОЭИќЙуСЫЁЃ - МђБЪЛЪЧЭЌЪБЩњГЩЖјЗЧађСаЩњГЩЁЃ
ШчЙћФЃаЭФмзіЕНЯёШЫРрзїЛвЛбљ,вЛБЪвЛЛ,УПДЮИљОнЧАвЛБЪШЗЖЈЯТвЛБЪЕФзїЛЮЛжУ,ВЛЖЯгХЛЏ,ЩњГЩаЇЙћПЩФмИќКУ - ИДдгГЬЖШВЛЭЌЮяЬх,ашвЊГщЯѓФуЕФГЬЖШВЛЭЌЁЃ
CLIPassoПижЦГщЯѓГЬЖШЕФБЪЛЪ§БиаыЬсЧАжИЖЈ,ЫљвдзюКУЪЧНЋБЪЛЪ§вВЩшМЦГЩПЩбЇЯАЕФВЮЪ§ЁЃетбљЖдВЛЭЌЕФЭМЦЌЩЯВЛЭЌИДдгГЬЖШЕФЮяЬх,ЖМФмКмКУЕФздЖЏГщЯѓЁЃФПЧАгУЛЇУПДЮЪфШыЭМЦЌ,ЛЙЕУПМТЧгУМИБЪШЅГщЯѓЁЃ
4.1.6 НсТл
??CLIPassoПЩвдЪЪгІШЮвтгявхРрБ№ЕФЪфШыЭМЯё,ЖјВЛдйОжЯогкЪ§ОнМЏжаЙЬгаЕФМИИіРрБ№;ВЂЧвПЩвдзіЕНЖдЮяЬхВЛЭЌГЬЖШЕФГщЯѓ,ЭЌЪББЃГжКЭдЭМЕФгявхКЭНсЙЙЕФвЛжТадЁЃ
4.2 DALL-E2(ЗХЕНСэвЛЦЊ,КѓајВЙ)
ЮхЁЂCLIPЪгЦЕРэНт(Тд)
??етВПЗжАќРЈCLIP4clipКЭActionCLIP,дкЁЖCLIP ИФНјЙЄзїДЎНВ(ЯТ)ЁЗжагаНВНт,ЮвЖдетвЛПщднЪБВЛИааЫШЄ,ОЭВЛаДСЫЁЃ
СљЁЂЦфЫќЗНЯђ
- ЖрФЃЬЌ CLIP-ViL:
- ТлЮФHow Much Can CLIP Benefit Vision-and-Language Tasks?ЁЂCode
- зїепНЋ CLIP ЕФдЄбЕСЗВЮЪ§гУРДГѕЪМЛЏ ViL ФЃаЭ,ШЛКѓдйИїжжЪгОѕ-ЮФБОЖрФЃЬЌШЮЮёЩЯНјааЮЂЕї,ВтЪдНсЙћЁЃ
- гявє AudioCLIP:днВЛИааЫШЄ
- 3D PointCLIP:
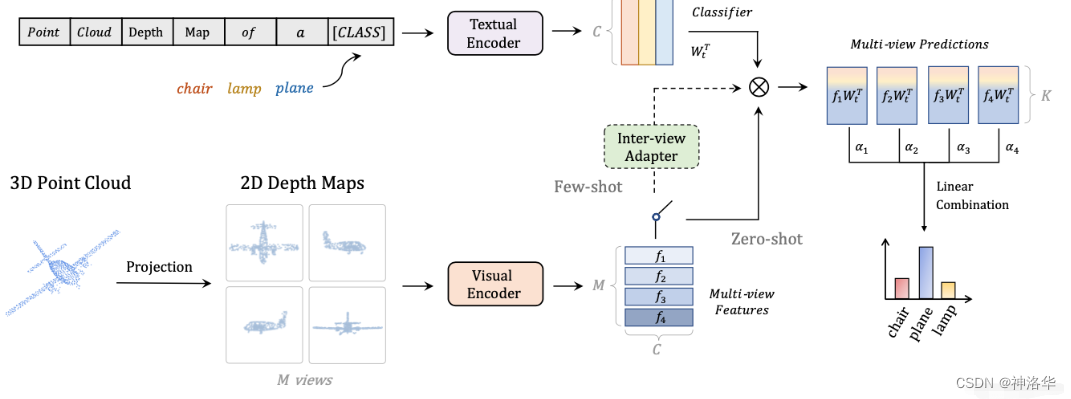
- ТлЮФ: PointCLIP: Point Cloud Understanding by CLIPЁЂДњТы
- зїепЭЈЙ§ЯжНЋ 3D ЕудЦЭЖЩфЮЊЖреХ 2D ЕФЩюЖШЭМ,ЪЕЯжСЫдк3DЭМЩЯРћгУ 2D ЭМЯёЪ§ОнбЕСЗ ЕФCLIP ФЃаЭЁЃ