? ? ? ? 相信大家都知道,这是一篇首次将Transformer应用在了目标检测领域中的论文。虽然效果不是最好,尤其是小目标检测效果,其中有一部分原因是输入的图片太小了,但是输入过大的图片又会给网络带来非常大的计算量,但是确实是给卷积神经络的瓶颈期带来了一个新的方向。它是一种真正基于端到端的目标检测算法,为什么这么说呢?因为yolov2之后的算法一般都是需要锚框、非极大值抑制等方法来进行检测,所以说一般的单阶段检测算法只能算作是准端到端的目标检测算法。而DETR则不需要这样的操作就可以完成一张图片的目标检测。
???????DETR?提出了一种新的方法,将对象检测视为直接集合(论文中给出了100个预测框)预测问题。简化了检测模型,有效地消除了对许多手工设计组件的需求,如非最大抑制程序或锚生成,这些组件明确编码了我们对任务的先验知识。它是一种基于集合的全局损失,通过二部分匹配强制进行唯一预测,以及一种变压器编码器-解码器架构。给定一组固定的学习对象查询,DETR对对象和全局图像上下文的关系进行推理,以直接并行输出最终预测集(最优的框框)。至于最终的结果对比图,如下图所示。

? ? ? ? ?该论文提出的方法是基于以下四点来完成的:集合预测的二部分匹配损失、基于变换器的编码器-解码器架构、并行解码和对象检测方法。为什么突出并行两个字,因为有一篇很早发表的论文用的是RNN,这样就显得自己的论文不错啦。首先我们来看看这篇文章的主要架构图,DETR通过将通用CNN与Transformer架构相结合,直接(并行)预测最终检测集。在训练过程中,二部匹配将预测与地面真值框唯一地匹配。没有匹配的预测应该产生“无对象”(?) 类别预测。
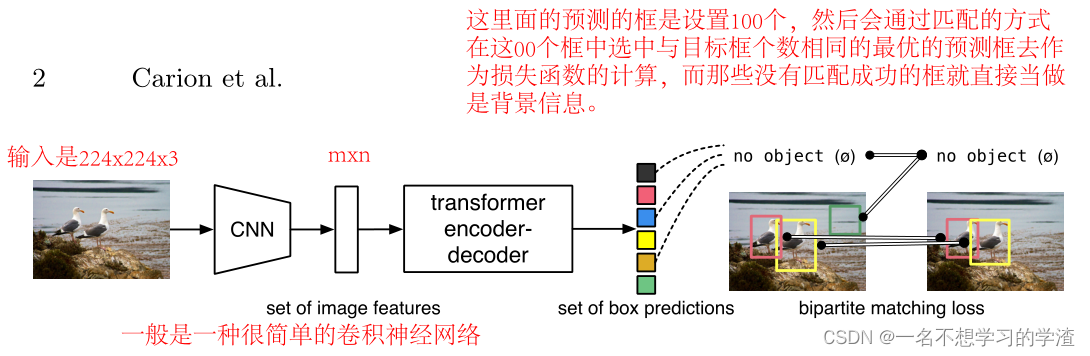
??????DETR使用传统的CNN主干来学习输入图像的2D表示。模型将其展平,并在将其传递到变换器编码器之前用位置编码对其进行补充。然后,变换器解码器将少量固定数量(100个query)的学习位置嵌入(我们称之为对象查询)作为输入,并额外处理编码器输出。我们将解码器的每个输出嵌入传递到共享前馈网络(FFN),该网络预测检测(类和边界框)或“无对象”类。?
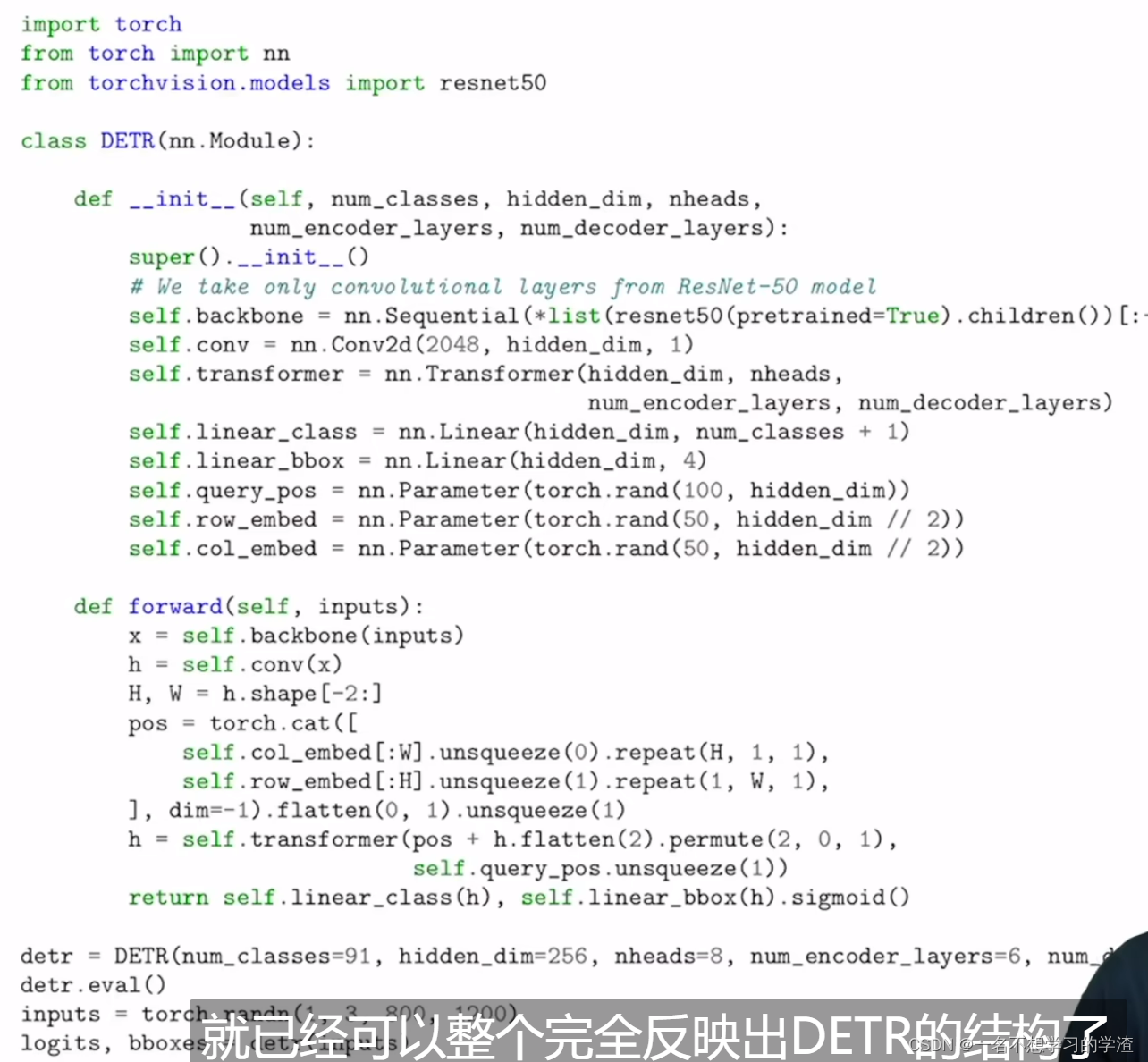
????????我们可以根据上面的框架图来看看它的伪代码,首先输入图片会通过CNN网络(训练完成的ResNet50)得到2048xWxH的特征图,但是此时它的维度太高了,这样输入到Transformer中计算量会很大,所以再通过1x1卷积进行降维操作,然后将这样的特征图在转成向量加上位置编码输入到Transformer中去,但是要注意在Transformer的解码器中增加了query,如果我没记错的话,在解码器中也增加了位置编码部分,然后在Transformer的解码器后增加了线性网网络用于进行输出预测结果(分类+回归),那么我们可以根据代码看到最后分类是类别数+1(1代表的是背景)。
 ?解码器中增加了位置编码
?解码器中增加了位置编码
? ? ? ? 对于损失函数的学习,?DETR首先采用二分图匹配的方式来选择最好的预测框来进行损失函数的计算,即通过匈牙利算法来进行预测结果和 ground-truth 之间的一一匹配用于计算损失,至于怎么弄得呢?
? ? ? ? 首先对于真实框y我们也将它变成100个,即使用100-y个“no object”来填充(论文中说预测出100个框,所以将真实框也先设定100个),然后将真实框和预测框分别变成下图的样式,横着的为预测框的索引,竖着的为 真实框的索引,然后就变成正方形了,其实这里面的某些知识还得去看源码。那么100x100个格子里填啥呢,作者说我们既要对类别进行考虑,也要对预测框与真实框的匹配程度进行考虑,所以作者使用下面的公式来进行计算,从而得到最终的损失值cost填入100x100个格子里。此时我们就可以选择最好的预测框来进行损失计算,这里的损失计算又有些不同,因为不能有负数,作者又对公式进行了调整。如下图所示。
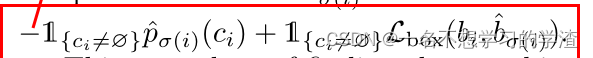
匹配时需要的公式?

计算最终的损失值的公式?

最优匹配的方式?
? ? ? ? ?下面再给大家分享一下DETR的结果图吧,我们可以看到该算法对于全局的掌控能力还是非常好的,因为即使重合度比较高的物体也能够检测出来。

 ?????????这就是DETR的主要内容了,至于后面的语义分割等应用拓展,大家可以自己看吧。我自己也得去学习学习源码了,感觉深度学习难得很!!!!!!!!
?????????这就是DETR的主要内容了,至于后面的语义分割等应用拓展,大家可以自己看吧。我自己也得去学习学习源码了,感觉深度学习难得很!!!!!!!!