文章目录
一、什么是强化学习?
1、强化学习的定义
??强化学习是机器学习的一种。强化学习实质上是一种机器学习范式,适用于多阶段序贯决策以获得较好的长期回报的场景。反复实验(trial and error)和延迟奖励(delayed reward)是强化学习最重要的两个特征。
??生活中常见的强化学习过程:

2、强化学习和监督学习的区别
??一般我们在图片分类的实验中,先有一大堆标定的数据,比如车、飞机等图片,然后训练一个分类器,网络在训练时已经把真实的Label给到网络了,如果预测错误,比如把车预测成飞机,就直接说预测是错误的,把错误的写成一个loss函数。所以在监督学习中,输入的数据都是没有关联的,如果有关联,网络就会不好学习。监督学习告诉了learner,正确的标签是什么,使用正确的标签来修正自己的预测。
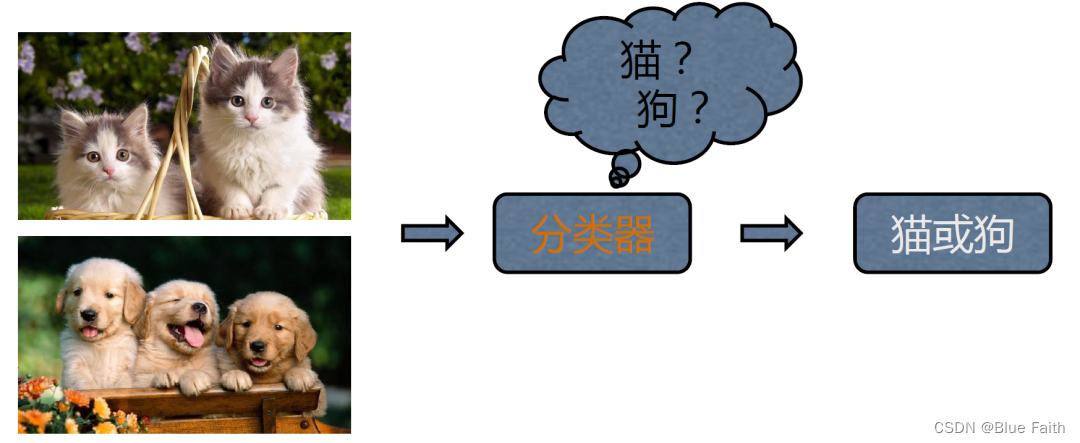
图来自于:https://cdn.modb.pro/db/245201
??但是在强化学习中,这两点都不满足,强化学习的训练数据就是玩游戏的一个过程,数据就是游戏中的这样一个过程序列,比如游戏走在第三步的时候,将这个learner放入到网络,希望网络在当前的状态下输出一个决策,但是我们并没有标签告诉我们这个决策动作是正确的还是错误的,得等到游戏结束才行。面临一个奖励延迟,训练网络就是比较困难的。
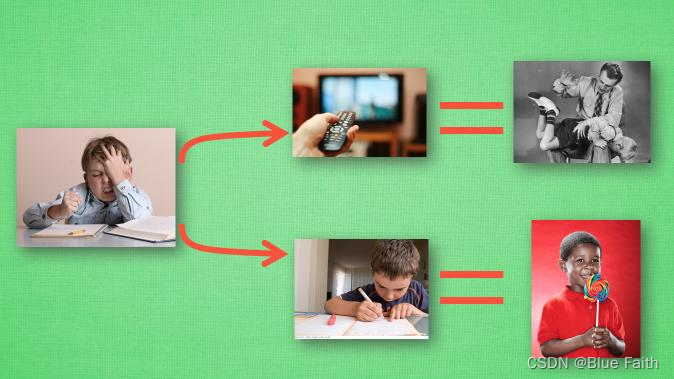
图来自于莫烦教程
监督学习和强化学习的不同点有:
- 强化学习的序列数据不像监督学习中的样本都是i.i.d数据,即满足独立同分布。
- 并没有告诉learner哪一个是正确的,哪一步是错误的,learner必须自己去发现,只能通过自己不断地去尝试哪些是最有利的行为。
- 强化学习在获得自己能力的过程中,不断地试错。
- 强化学习中是无监督的,它只有一个奖励信号,环境会在很久以后会告诉你之前采取的行为是不是有效的。强化学习中的学习是比较困难的,正确的行为是不被立刻告知的。
3、强化学习的特点
- 通过不断的探索来获取对环境的理解。 agent在环境中获得延迟的奖励。
- 强化学习中的时间非常重要,因为数据都是有时间关联的(机器学习中,数据越有关联,训练就会非常的不稳定)。所以在强化学习中,希望数据之间也是有较少的关联性,即是i.i.d数据,也叫独立同分布数据。
- agent的行为会影响他稍后得到的数据,agent的行为会改变环境。所以强化学习中的一个很重要的问题就是如何让agent的行为得到一个稳定的提升。
二、强化学习的主要概念
??在这个图中展示了强化学习的一些关键要素:
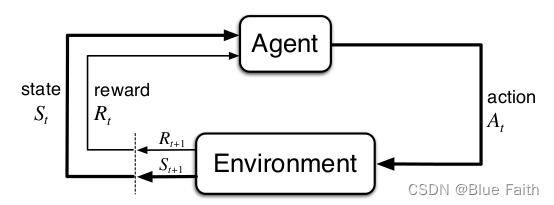
1、Agent是需要去做决策的智能体;
2、Environment是智能体所处的环境;
3、环境会向智能体提供一定的可观测的信息,也就是智能体所处的State;
4、并且处于特定State的智能体会得到一定的Reward,智能体根据State可以采取相应的Action,从而实现最大化长期收益的目的。
1、Agent
??在强化学习的环境中,agent的目的就是选取一系列的动作,从而使得自己的奖励可以最大化。强化学习的最大课题就是如何让agent获得一个长期的奖励。
- agent在采取当前动作的时候,会依赖于之前的历史,可以把游戏的状态看成是关于这个历史的函数。
- agent内部也有一个函数来更新状态。
- agent状态和环境的状态等价的时候,就叫这个环境为full observability,即全部可观测的。
??根据强化学习agent学习的不同,可以对agent进行归类:
- 第一种是基于价值函数的agent,这一类agent学习的就是价值函数,隐式的学习了策略。
- 第二种是基于策略导向的agent,直接学习的就是策略。
- 第三种是策略和价值结合的函数。把价值函数和策略函数都进行了学习。通过两者的交互得到一个最佳的行为。
还可以依据agent有没有学习环境模型而进行分类,分为:
- 有模型
- 无模型
2、State
状态转移需从旧状态转移到新状态。
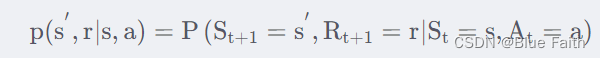
- 状态转移可以是确定的,也可以是随机的,通常都是随机的。
- 状态转移的随机性来源于环境内部。游戏中,当前状态执行一个动作后,下一个状态是由游戏内部机制所决定的。
3、Reward
Reward表示每个时刻采取动作后得到的是即时奖励。
Return表示在时刻采取某个动作后,到游戏结束可以得到的总的奖励。
我们将奖励的特点总结为以下三点:
- 奖励是一个标量的反馈信号
- 它能表征在某一步智能体的表现如何
- 智能体的任务就是使得一个时段内积累的总奖励值最大
4、Action
不同的环境允许不同种类的动作。在给定的环境中,有效动作的集合经常被称为 动作空间(action space) 。
有离散动作空间(discrete action spaces) ,在这个动作空间里,agent 的动作数量是有限的。
有连续动作空间(continuous action spaces) 。在连续空间中,动作是实值的向量。
区分动作空间的连续与离散对具体问题需要具体分析,这可能会影响到算法的选择。
5、强化学习方法分类
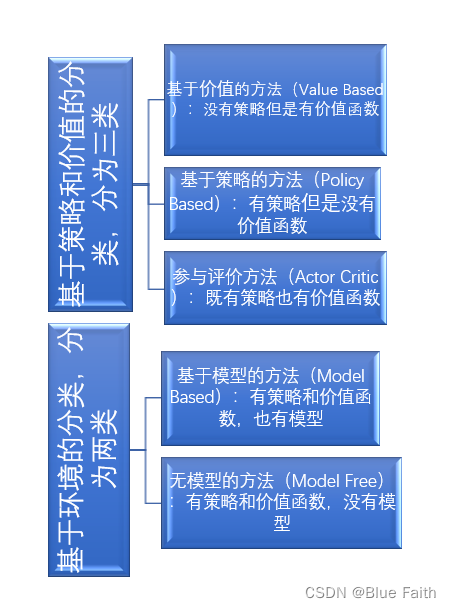
6、马尔科夫决策
??马尔科夫决策过程是强化学习中的一个基本框架。马尔科夫决策过程的环境是fully observable,即全部可观测的。但是很多时候,很多量是不可观测的,但是这样也可以使用马尔科夫决策过程来解决。马尔科夫的重要特征:一个状态的下一个状态只取决于当前状态,而跟之前的状态无关。这个特征是所有马尔科夫过程的基础。
??为什么在强化学习中会用到马尔科夫决策过程呢?
??在强化学习中,agent与environment一直在互动。在每个时刻t,agent会接收到来自环境的状态s,基于这个状态s,agent会做出动作a,然后这个动作作用在环境上,于是agent可以接收到一个奖赏Rt+1Rt+1,并且agent就会到达新的状态。所以,其实agent与environment之间的交互就是产生了一个序列。
??马尔科夫过程的定义:马尔科夫过程是一个二元组(S,P),且满足S是有限状态集合,P是状态转移矩阵。状态转移概率矩阵为:
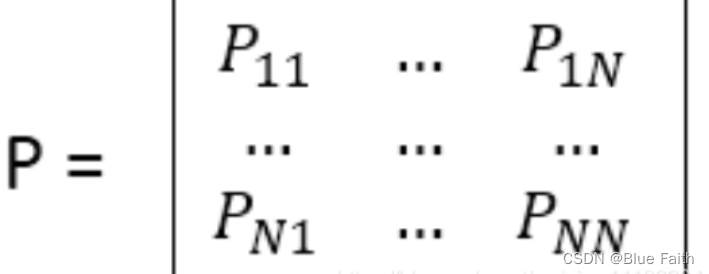
下图所示,一个学生的7种状态{娱乐,课程1,课程2,课程3,考过,睡觉,论文}:
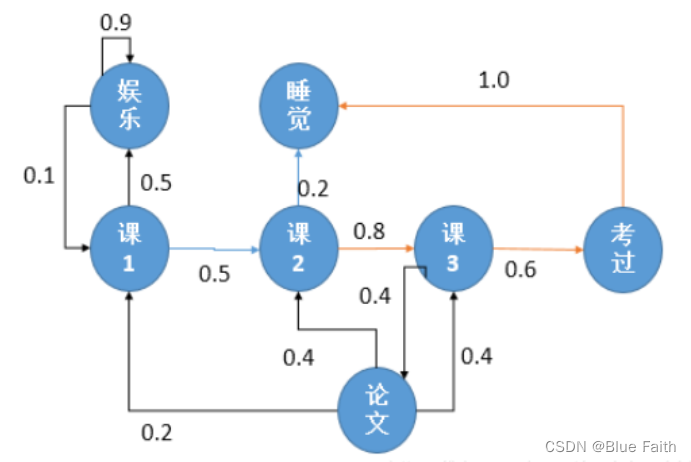
每种状态的转换概率如下图所示。则该生从课程1开始一天可能的状态序列为:
- 课1-课2-课3-考过-睡觉
- 课1-课2-睡觉
将动作和回报考虑在内的马尔科夫过程称为马尔科夫决策过程。
三、强化学习的应用场景
??强化学习采用一种更接近人类和动物习得技能的方式,在探索与利用中学到更优的策略规划与控制,能够最大化序列决策任务中的长期收益。强化学习在复杂环境中可以探索更多的状态空间和同时处理更多样化的动作组合,达到甚至超越人类能探索到的决策能力。因此强化学习的应用非常广泛,可应用于游戏、机器人控制、推荐、交通、能源、金融等等。
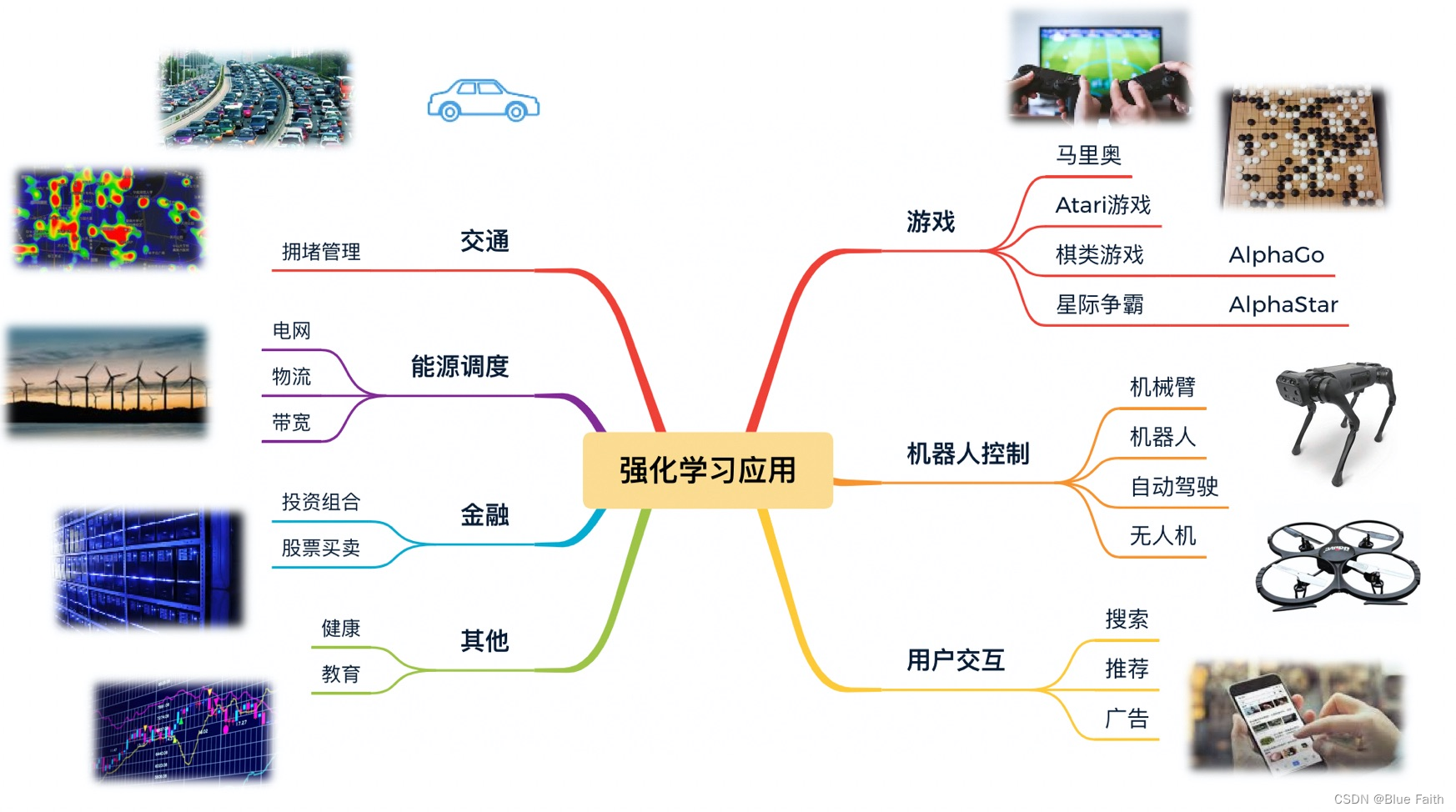
图来自于:http://www.mysecretrainbow.com/ai/21730.html
四、强化学习算法分类
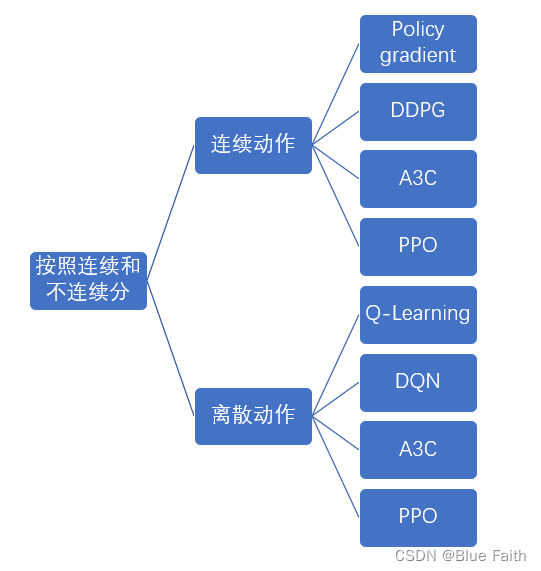
??常见的强化学习算法可以按照动作是否连续进行分类如下:
强化学习项目实战
见百度网盘地址:https://pan.baidu.com/s/1PmvLQ1PZN5ZMyDClx9evZQ
提取码:b8fd
大家感兴趣可以自行下载学习,里面涵盖多个强化学习实战项目,比较完整。