Learning a Generative Model for Fusing Infrared and Visible Images via Conditional Generative Adversarial Network with Dual Discriminators
(ͨ������˫�ؼ��������������ɶԿ�����ѧϰ�ںϺ���Ϳɼ���ͼ�������ģ��)
�ڱ�����,���������һ���µĶ˵���ģ��,��Ϊ˫�������������ɶԿ����� (DDcGAN),�����ںϲ�ͬ�ֱ��ʵĺ���Ϳɼ�ͼ�������ؼ����������еĻ������ѧϰ�ķ�����ͬ,�ں�������ͨ��������������������֮��ĶԿ���������ɵ�,����ר����Ƶ����ݶ�ʧ֮�⡣����������ѵ��,����������ʵ���ں�ͼ��,����Ū��������ѵ�������������ֱ�����²����ں�ͼ��ͺ���ͼ��ĸ��ʷֲ�֮���JSɢ��,�Լ��ں�ͼ����ݶȺͿɼ�ͼ����ݶȵĸ��ʷֲ�֮���JSɢ�������,�ں�ͼ����Բ������ܵ���������ʧԼ�������������,����ͬʱ���ں�ͼ���б���������ǿ����ͼ������Ŀ���ͻ���ȺͿɼ�ͼ���е�����ϸ�ڡ�����,ͨ��Լ���������²������ں�ͼ��͵ͷֱ��ʺ���ͼ��,DDcGAN������ѡ��Ӧ���ڲ�ͬ�ֱ���ͼ����ںϡ�
����
�ɼ�ͼ�����ͨ���ɼ�����������ķ���⽫����ϸ�ڱ�ʾΪ������ݡ���Ϊ����,�������������ȷ�����Ը���ijЩӳ���ϵ�ں���ͼ���б�ʾ����Ϊ,��ʹ�ڶ��ӵ�����������,��Ŀ��Ҳ����ͨ���߶Աȶ���ͻ����ʾ�����,�ںϵ�ͼ����г��ּ������й��������Ը����Ӿ������DZ��,�����ھ��º�����Ӧ���з�����Ҫ���á�
�ִ淽����һЩȱ��:
i) �ڴ�ͳ������,�ֹ���ƵĹ���ʹ�������Խ��Խ���Ӻ��ӡ�
ii) �������ѧϰ���к���Ϳɼ���ͼ���ںϵİ���ʯ��ȱ����ʵ�Ļ��������з���ͨ�����������ʧ�����������Ȼ��,���ǿ��ܻ������µ����⡣����,ŷ����þ���Ľ��ģ�������,�������һ��ȫ��ġ�����Ӧ����ʧ������ָ��һ����ˮƽ��Ŀ�ꡣ
iii) ��Ϊһ������,����רע����ȡ�ͱ�������,����������Ҫ��������ǿ,��ʵ�ָ������ĺ���������Ӧ�á�
iv) ����Ӳ��������,����ͼ�������ܵ��ϵͷֱ��ʵ�Ӱ�졣�Կɼ�ͼ������²�����Ժ���ͼ������ϲ����ķ����ᵼ���ȷ�����Ϣģ��������ϸ�ڶ�ʧ��
���,�ںϲ�ͬ�ֱ��ʵ�ͼ����Ȼ��һ�������ս�Ե�����
Ϊ�˽��������ս,���������һ��ͨ��˫�ؼ������������ɶԿ����� (DDcGAN) ѧϰ����ģ�͵ķ������ں�������ͨ��������������������֮��ĶԿ���������ɵġ���ͳ��GAN�����ھ���˫�ؼ�������GAN,�Ա����������͵�Դͼ���е����������ڼ�����,���Ƿֱɼ�ͼ��ĺ���ͼ��/�ݶ���Ϊ��ʵ�������ں�ͼ����²����ں�ͼ��/�ݶ�Ӧ�����������͵���ʵ����������,��˲���Ҫ���������ں�ͼ�����������Ƕ˵���ģ��,��������ںϹ�����,���ǵ�ģ�������ڲ�ͬ�ֱ���ͼ����ںϡ����ԺͶ��������ʾ�����ǵ�DDcGAN������������ȵ����ơ�
ʹ�ö���ļ�����,�ںϵ�ͼ������ڸ���̶���ͻ����Ŀ�ꡣ����,ʹ���б�����������ʷֲ�֮��IJ���,���������ؼ�����,���������п��ܲ���ؼ���������ǿ���ǡ�����ͼ��,����ʾΪ��Ŀ��ͱ���֮��ĶԱȶȡ������ͼ���ж����ӳ���ϵ����ʾ���ȷ�����Ϣ���,�������ǵĽ�����Ը��ߵĶԱȶȱ�ʾ,��ʵ�ָ��õ�Ŀ��ʶ��ͬʱ,�ɼ�ͼ���еĸ���ϸ�� (����,���Ӻ�ľ��) ���������ǵĽ���С�

����
? ����Ӧ�����ѧϰ��ܽ���ͼ���ںϷ��������˹��ס�һ����,��ͻ���˴��������ֻ����ijЩ�Ӳ���Ӧ�����ѧϰ��ܵ����ơ���һ����,���ǵĹ�����������Ӧ�����ѧϰ�����̶ȵؼ������ؼ�����ʧ������������ʧ��,���ǻ�ͨ�����ʷֲ��ĽǶȻ���minmax������Ϸ���������
? ˫�ؼ���������ϵ�ṹ���Ա�����������һ�����͵�Դͼ������������������µ�һ�����͵�Դͼ���е���Ϣ��ʧ��
? ������ͨ�����ʷֲ��ĽǶ��������ʱ,DDcGAN����������ȡ,�ںϺ��ؽ�����,���һ�������ǿԴͼ���е���Ҫ����,����Ŀ���뱳��֮��ĶԱȶȡ�
? ƾ��Di֮ǰ���²���������ר����Ƶ����,���ǵķ���չʾ�˲�ͬ�ֱ���ͼ���ںϵij�ɫ���ܡ�
��ع���
Deep Learning-based Fusion Methods
��
Generative Adversarial Networks
GAN�����Ϊѧϰ���ʷֲ���Ϊ��ʵ�ֲ�Pdata (x) �Ĺ��ơ���ͨ��ͬʱѵ��������G�ͼ�����D��ͨ���Կ����̽�������� ��G����ͨ����DZ�ռ����������������������G���Ż���ʽ���Զ���Ϊ:
�������ͼ���������Ϊ������������͵�һЩ������ϢΪ����, ��GAN������չ������ģ��,���Ҹ�ģ�ͱ�����Ϊ�������ɶԿ����� (cGAN)��
����
��Ϊ���������ڽ����ͬ�ֱ���ͼ���ںϵĸ�����ս�Ե�����,���ֲ�ʧȥͨ����,�������Ǽ���ɼ���ͼ��ͺ���ͼ��ķֱ���֮��ı�������Ϊ4�����仰˵,����ɼ�ͼ��ijߴ�Ϊm �� n,����Ӧ�ĺ���ͼ��ijߴ�Ϊm/4 �� n/4��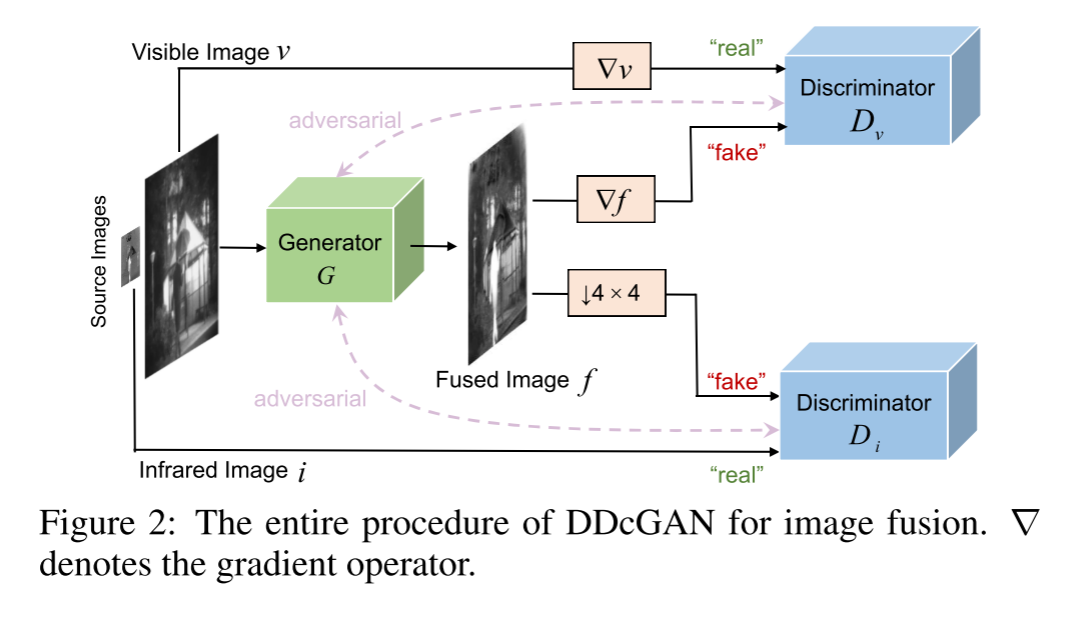
�����ɼ�ͼ��v�ͺ���ͼ��i,DDcGAN��������������ͼ��ʾ�����Ƿ���������Ŀ����ѧϰ��v��iΪ����������������G��Ȼ�������G���ɵ��ں�ͼ��f = G(v,i) �����㹻����ʵ�Ժ���Ϣ��,����ƭ��������ͬʱ,����������������������,Dv��Di�����Ƿֱ�����һ������,�ñ�������������ʵ���ݶ�����G��������ʡ���ͬ����,Dv��Di����ʵ���������ڲ�ͬ��,��ʹ�Dz�ͬ�����͡�������˵,Dvּ���������ɵ�ͼ����ݶ�?f��ɼ�ͼ����ݶ�?v, ��Di��ѵ��������ԭʼ�ͷֱ��ʺ���ͼ��i���²���������/�ں�ͼ�� �� f �o ���� ? ���ݶ����� , �� �� ���²������ӡ�
�봫ͳcGAN��ȵ�һ�����Ա仯��,Ϊ���������ͼ�����֮���ƽ��,���Dz��� ?v��i��ΪDv��Di�ĸ�������㡣�����,Dv��Di����ʵ����������������Ϣ��ͬ�����,Dv��Di��ѵ������������ͼ���Ƿ���ͬ����Ϊ������������˵,����һ���㹻������,���ҿ���ͨ������������ʵ�֡�Ȼ��,������������˵,��Ū����������һ�����������,�Կ���ϵ��������,������������������������ɡ����,��ģ�ͽ�ʧȥ��ԭʼ���塣���,G��ѵ��Ŀ����Ա��ƶ�Ϊ��С�����¶Կ�Ŀ��: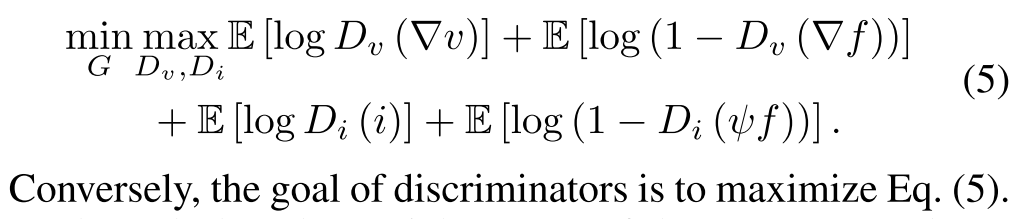
ͨ���������������б����ĶԿ��Թ���,�����ֲ�֮���divergence,��P?F and P?V,�Լ�P��F and PI ֮���divergence��ͬʱ��С��P?F�����ɵ��������ݶȵĸ��ʷֲ�,P��F���²����������������ݶȵĸ��ʷֲ���P?V�ǿɼ�ͼ���ݶȵĸ��ʷֲ�,PI�Ǻ���ͼ���ݶȵĸ��ʷֲ���
Loss Function
���,GANs�ijɹ�������,��Ϊ��֪���Ƕ�ѵ�����ȶ�,���ҿ��ܵ����˹���Ʒ�����ӻ���������Ľ�� ��һ�ֿ��ܵĽ���������������ݶ�ʧ�Խ�һ��Լ�������������С����,�ڱ�����,������������ѵ��Ϊ��Ū������,���һ������������������ɵ�ͼ���Դͼ��֮��������ԡ� ���,����������ʧ������һ���Կ�����ʧLadv G��һ��������ʧLcon���,Ȩ�� �� ����Ȩ��:
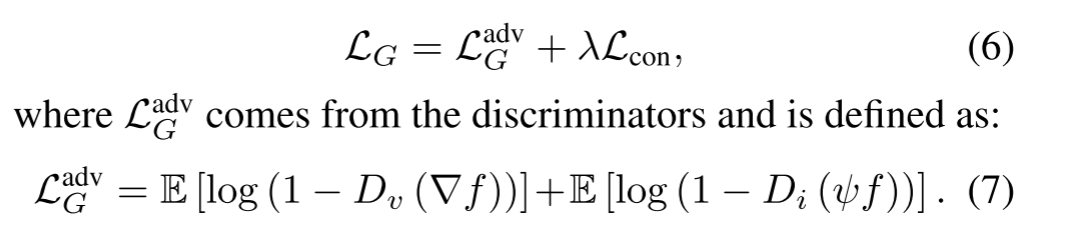
һ����,���ں���ͼ���е��ȷ�����Ϣ��������ǿ�ȵ�����,������Dz���Frobenius������Լ���²������ں�ͼ��,ʹ����������ͼ�����Ƶ�����ǿ�ȡ� �²��������������ŷ�ֹ����ǿ���ϲ��������µ�ѹ����ģ�������µ�������Ϣ��ʧ����һ����,�ɼ�ͼ���е�����ϸ����Ҫ���ݶȱ仯Ϊ��������һ����,�ɼ�ͼ���е�����ϸ����Ҫ���ݶȱ仯Ϊ���������,Ӧ��TV������Լ���ں�ͼ���Ա��ֳ���ɼ�ͼ�����Ƶ��ݶȱ仯����һ��Ȩ�� �� ������Ȩ��,���ǿ��Եõ��������:
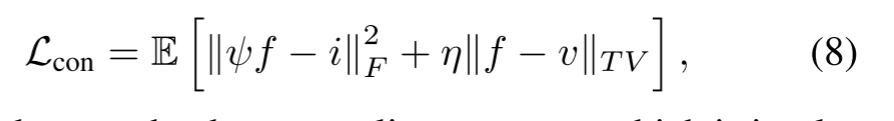
���� �� ��ʾ�²�������,���ڱ�����Ƶ��Ϣ,��������ƽ���ػ���ʵ�֡�
�Լ�����������ѵ��,��������ʵ���ݺ����ɵ����ݡ��б����ĶԿ�����ʧ���Լ���ֲ�֮���JSɢ��,�Ӷ�ȷ������ǿ�Ȼ�������Ϣ�Ƿ���ʵ���б��ߵĶԿ�����ʧ��������:
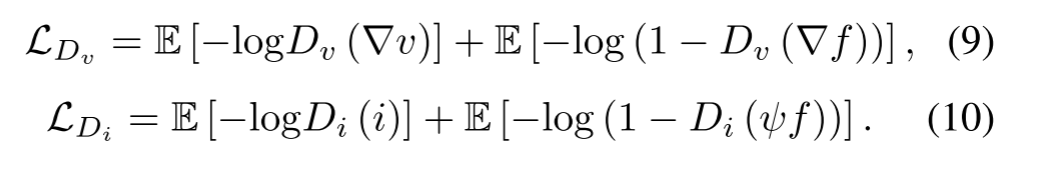
Network Architecture
Generator Architecture
�����������DZ�����-����������,�ڱ�����֮ǰ����2���ϲ�����,����ͼ��ʾ�����ں���ͼ����нϵ͵ķֱ���,�����������ͨ������ڲ�ֵ���������ϲ��������������ֱ���֮�����ת������2���������ϲ����ĺ���ͼ���ϲ����ĺ���ͼ���ԭʼ�ɼ�ͼ���������͵����������ڱ�������ִ��������ȡ���ںϵĹ���,�������ںϵ�����ͼ��Ȼ����Щ��ͼ���͵������������ؽ������ɵ��ں�ͼ����ɼ�ͼ�������ͬ�ķֱ��ʡ�
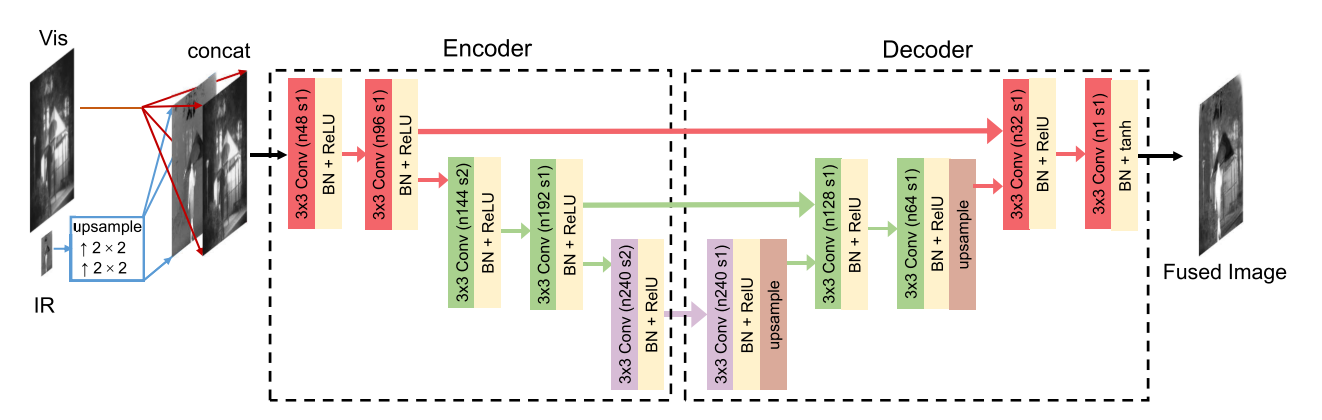
��������5����������ɡ��������ͼ��������ÿ��������IJ�����ͼ3��ʾ�������ɫ������ͼ��СΪW �� h,����ɫ����ɫ������ͼ�ֱ�ΪW/2 �� h/2��W/4 �� h/4�����ǵ��ڱ������ĵڶ���͵��IJ�������Ϊ2�IJ�����������,�ڷ�������ϵ�ṹ��Ӧ����U-net ���������еĵڶ���͵��IJ��õ�����ͼ�����䵽�������е���Ӧ�㡣��Щ����ͼ�������������õ�����ͼ��������,�������ľ������ϲ�����������������5��CNN,ÿ���������ͼ3��ʾ�����о�����IJ�����Ϊ1��ͬ��,ͨ������ڲ�ֵ���ɵ�һ�͵����������õ�����ͼ�����ϲ�����Ϊ�˱����ݶȱ�ը/��ʧ���ӿ�ѵ���������ٶ�,Ӧ��������һ�� (BN) ��ReLU�������
PS:U-net������Ϣ
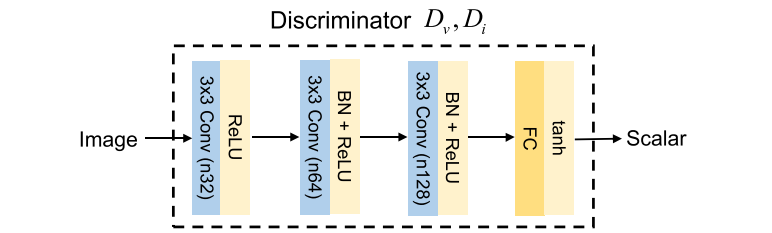
Discriminator Architecture
������ּ�ڶ����������ӶԿ����á��ر��,Dvּ�ڽ����ɵ�ͼ����ݶ���ɼ�ͼ����ݶ����ֿ���,����Dvּ�ڷֱ����ɵ�ͼ�������ͼ�����ֿ���������,���������͵�Դͼ���Dz�ͬ����ı�����ʽ,��˾������Բ�ͬ�ķֲ���Ҳ����˵,Dv��Di��G�ϵ��������ڳ�ͻ�������ǵ�������,���Dz���Ҫ�����������ͼ�����֮��ĶԿ���ϵ,��Ҫ����Dv��Di��ƽ�⡣����,����ѵ���Ľ���,һ����������ǿ�����ս�������һ����������Ч�ʵ��¡������ǵĹ�����,ƽ����ͨ����ϵ�ṹ����ѵ���Ե������ʵ�ֵġ�Dv��Di������ͬ����ϵ�ṹ,��ͼ��ͼ��ʾ�����о�����IJ�������Ϊ2�������һ����,����ʹ��tanh���������һ������,�ñ�����������Դͼ�������G������ͼ��ĸ��ʡ�