基于生成对抗网络的知识蒸馏数据增强
期刊:计算机工程 C
时间:2022
研究院:武汉工程大学
关键词:数据增强 ;神经网络分类器 ;工业视觉 ;生成对抗网络 ;知识蒸馏
方法简介
思想来源:
仅对原标签做简单的线性变化或直接使用原标签作为新样本标签的方法是无法表示标签中离散信息的 ,这会导致网络模型无法将离散信息也作为一种特征进行学习。
针对上述问题,在区域丢弃算法的基础上,提出一种基于生成对抗网络的知识蒸馏数据增强算法。使用补丁对丢弃区域进行填补,减少区域丢弃产生的非信息噪声。 在补丁生成网络中,保留生成对抗网络的编码器-解码器结构,利用编码器卷积层提取特征,通过解码器对特征图上采样生成补丁。在样本标签生成过程中,采用知识蒸馏算法中的教师-学生训练模式,按照交叉检验方式训练教师模型, 根据教师模型生成的软标签对学生模型的训练进行指导,提高学生模型对特征的学习能力
对区域丢弃算法中的丢弃运算进行改进 ,在生成对抗网络[23]的基础上 ,对其生成器和判别器结构进行优化 ,设计一种 补丁生网络 。 补丁生成网络通过 学习原样本的像素分布生成填充补丁 ,以减少随机噪声 。
同时 ,在区域丢弃算法中引入基于知识蒸馏的标签生成算法 ,通过教师网络获得 Soft-lable 并辅助学生网络进行训练[24]。 Soft-lable 比普通的 One-Hot 标签具有更高的信息熵,能有效辅助学生网络学习不同类别间的类间差距 ,减少错误标签对模型的影响 ,提高分类器的精度 。
具体方法
区域丢弃算法
区域丢弃算法作为一种正则化方法被广泛应用 于 防 止 神 经 网 络 过 拟 合 ,通 过 在 网 络 的 前 向 传 播 过 程中按照一定比例舍弃节点的激活值的方式增强网 络 分 类 器 的 训 练 效 率 。 与 全 连 接 层 相 比 ,区 域 丢 弃 算 法 在 卷 积 层 中 的 效 果 较 差 ,这 是 由 于 卷 积 层 使 用 了 卷 积 核 ,使 得 卷 积 层 的 参 数 量 远 少 于 全 连 接 层 ,因 此 在 解 空 间 中 对 正 则 化 的 要 求 更 少 ,并 且 在 卷 积 层 中 特 征 图 的 相 邻 像 素 信 息 相 似 ,舍 弃 掉 的 像 素 信 息 又 存 在 于 其 他 的 像 素 中 ,继 续 向 后 传 递 。
提高区域丢弃策略在卷积层中的正则化效 果 ,将 卷 积 层 中 的 丢 弃 操 作 设 置 到 输 入 层 。 通 过 直 接移除输入图像的连续区域迫使网络去学习全局信 息 ,而 不 仅 关 注 于 局 部 区 域 。 在 许 多 视 觉 任 务 中 常 常 存 在 目 标 物 体 被 遮 挡 的 情 况 ,区 域 丢 弃 算 法 也 可 以 看 作 是 对 遮 挡 的 模 拟 ,定 义 如 下 :
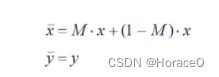
其 中 :x ∈ RW × H × C 表 示 原 始 样 本 ,W 表 示 原 始 图 像 的 宽 度 、H 为 图 像 高 度 、C 为 图 像 通 道 数 ;xˉ 表 示 生 成 的 新样本,采用原始样本标签 y 作为新样本 xˉ 的标签 yˉ; M ∈{0,1}W × H 表 示 一 个 尺 寸 为 ssize×ssize 的 矩 形 二 值 掩 模 。 掩 模 M 的 中 心 位 置 是 随 机 生 成 的 ,像 素 坐 标 (x,y)范 围 如 式(2)所 示
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Eq7ryHFG-1666801157820)(基于生成对抗网络的知识蒸馏数据增强.assets/image-20221026224832358.png)]](https://img-blog.csdnimg.cn/1341db73cd41464bbed6abaf217b043a.png)
掩 模 左 上 角(x1,y1)、左 下 角(x1,y2)、右 上 角(x2, y 1)、右 下 角(x2,y2)这 4 个 角 点 坐 标 与 中 心 坐 标 的 关 系 如 式(3)所 示 :
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-FgnpDV0f-1666801157821)(基于生成对抗网络的知识蒸馏数据增强.assets/image-20221026224917872.png)]](https://img-blog.csdnimg.cn/9f9c62bf9fd842c69941aebe07671d83.png)
- 问题
1)在使用二值掩 模对原样本进行遮挡时,会引入二值噪声,需要对所有 样本的所有像素值进行归一化操作,这会增加额外的 计算量;
2)使用原样本的标签进行网络损失计算,这对 于图像分类任务和语义分割任务都是不合适的,在图 像分类任务中每张图像仅对应一个标签,原标签无法 体现出不同类别之间的差异信息,在语义分割任务中 每一个像素点都对应一个 One-Hot 标签,丢弃的像素 点被二值填充,此时仍采用像素点的原始标签是不合 理的
基于 GAN 的知识蒸馏数据增强算法
本文主要从非监督单样本数据增强方式和新标 签生成方式 2个方面对区域丢弃算法进行改进
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-uBbmZ3ss-1666801157822)(基于生成对抗网络的知识蒸馏数据增强.assets/image-20221026225755718.png)]](https://img-blog.csdnimg.cn/a47aaa8e6953401785b548bb6e2a5859.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-VZgbeFGm-1666801157822)(基于生成对抗网络的知识蒸馏数据增强.assets/image-20221026225841390.png)]](https://img-blog.csdnimg.cn/78cd2e3367e34070a9033262cc6b1170.png)
改进的数据增强算法
补丁填充算法被使用在 CutMix 算 法 中 ,能 减 少 丢 弃 像 素 导 致 的 信 息 缺 失 、训 练 困 难 问 题 。 受 补 丁 填 充 算 法 的 启 发 ,构 造 一 种 补 丁 生 成 网 络 ,并 将 其 应 用 在 区 域 丢 弃 算 法 中 。
对 于 生 成 器 G 输 入 一 张 512×512 大 小 的 三 通 道 图 片 ,设 置 区 域 丢 弃 使 用 的 掩 模 尺 寸 为 128×128,即 生 成器需要生成一个 128×128 大小的补丁。输入图片 经过 4 次卷积池化下采样为 32×32 大小的 512 维特 征 ,再 经 过 2 次 上 采 样(UpSampling)恢 复 尺 寸 得 到 最终的三通道 128×128 的填充补丁
从图 2 可以看出,与常规 GAN 生成器相比,补丁 生 成 网 络 将 编 码 器 中 的 全 连 接 层 替 换 为 卷 积 层 ,在 解码器中增加了上采样层以控制最终获得的补丁尺 寸 。 同 时 ,在 激 活 函 数 选 择 上 ,改 用 系 数 为 0.2 的 LeakyReLu 激 活 函 数 替 代 tanh 激 活 函 数 ,以 防 止 在 训练过程中的梯度震荡问题。 在生成器中的编码器 Encoder 设计为一个典型 的 卷 积 结 构 ,共 使 用 4 层 卷 积 层 ,这 4 个 卷 积 层 分 别 使 用 32 个 步 长 为 2 的 3×3 卷 积 核 、64 个 步 长 为 2 的 3×3 卷积核、128 个步长为 2 的 3×3 卷积核和 512 个步 长为 2 的 1×1 卷积核。输入图像经过 4 次卷积层后, 特征图的尺寸缩小为原图的 1/16。生成器中的解码 器 Decoder 通过两次上采样恢复特征图尺寸。在上 采 样 的 具 体 实 现 中 ,直 接 采 用 反 卷 积(Deconv)层 虽 然 更 简 单 ,但 其 存 在 棋 盘 效 应 ,必 须 人 为 设 计 卷 积 核 尺 寸 才 能 整 除 步 长 。 为 了 减 少 网 络 设 计 的 难 度 ,通 过 2次叠加使用上采样层和卷积层实现上采样操 作。第 1 次使用上采样层与 128 个步长为 1 的 3×3 卷 积 层 将 32×32×512 的 特 征 图 扩 大 为 64×64×128, 第 2 次使用上采样层与 64 个步长为 1 的 3×3 卷积层 将 64×64×128 的 特 征 图 继 续 扩 大 为 128×128×64,之 后 通 过 一 个 卷 积 层 将 特 征 图 的 尺 寸 调 整 为 128× 128×3。 仅 进 行 两 次 上 采 样 操 作 的 原 因 为 :与 常 规 GAN 的解码器需要将特征图尺寸还原到原图大小不 同 ,补 丁 生 成 网 络 仅 需 要 将 特 征 图 尺 寸 还 原 到 与 补丁相同的大小(原图大小的 1/4)。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-rC3bFv6X-1666801157822)(基于生成对抗网络的知识蒸馏数据增强.assets/image-20221026230459926.png)]](https://img-blog.csdnimg.cn/c5b45346e1304db68c8895794282eac6.png)
从 图 3 可 以 看 出 ,补 丁 生 成 网 络 判 别 器 的 设 计 参考常规 GAN 判别器的结构,但在卷积层后没有再 使 用 最 大 池 化 层 ,而 是 将 这 些 信 息 最 后 直 接 平 化 (Flatten)输 入 到 全 连 接 层 中 。 在 经 过 激 活 函 数 后 , 补丁生成网络判别器还加入了 BN 层加快收敛速度。 判别器的输入为生成器生成的 128×128×3 尺寸的 补丁,经过 3 个卷积层和 1 个平化层,最后输出 1 个一 维概率值。3 个卷积层分别使用 64 个步长为 2 的 3×3 卷积核、128 个步长为 2 的 3×3 卷积核和 256 个步长为 1 的 3×3 卷积核。加入平化层是将 32×32×256 的特征 一维化成 26 244 个一维向量,使卷积层与全连接(Dense) 层进行过度。最终通过 sigmoid 激活函数输出一个表 示该补丁是否为真的一维概率值。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-qYT5RRjt-1666801157823)(基于生成对抗网络的知识蒸馏数据增强.assets/image-20221026230803575.png)]](https://img-blog.csdnimg.cn/871985600e8b451aad6c299e33451081.png)
改进的标签生成算法
引入知识蒸馏算法生成数据增强样本的标签,将其 与标签平滑方法相融合,提出一种基于知识蒸馏的标签 生成算法。基于知识蒸馏的标签生成算法流程见图 5。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-fBrigLHp-1666801157823)(基于生成对抗网络的知识蒸馏数据增强.assets/image-20221026235552464.png)]](https://img-blog.csdnimg.cn/a27241f64454462486dfacb9e574c2f1.png)
就是简单的KD