目录
?transform.py:用于语义分割训练集的数据准备函数的类,辅助训练集的
?TaskFusion_dataset.py:融合网络获取数据的方式
代码结构:
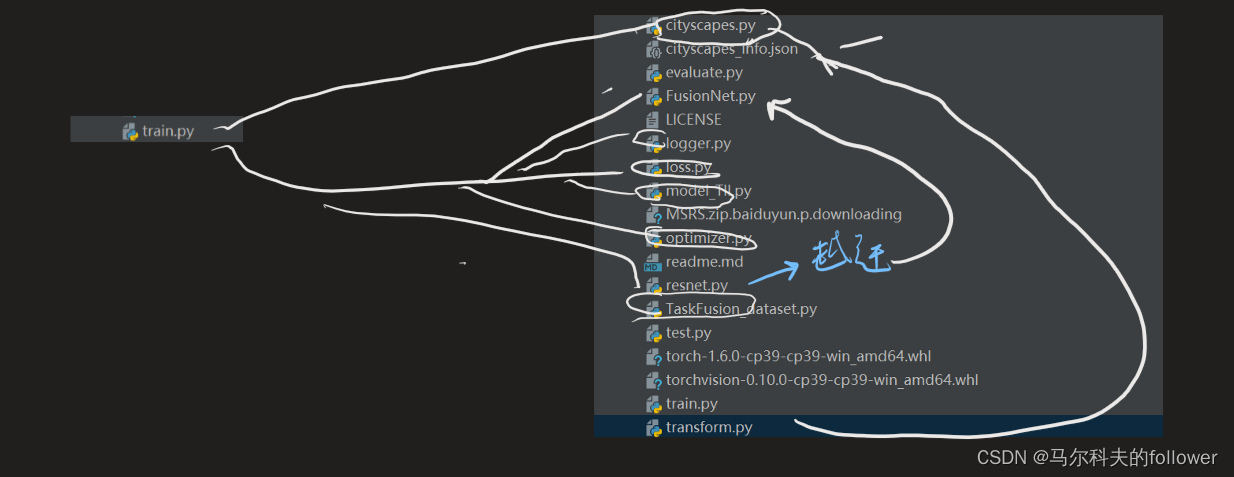
进一步细化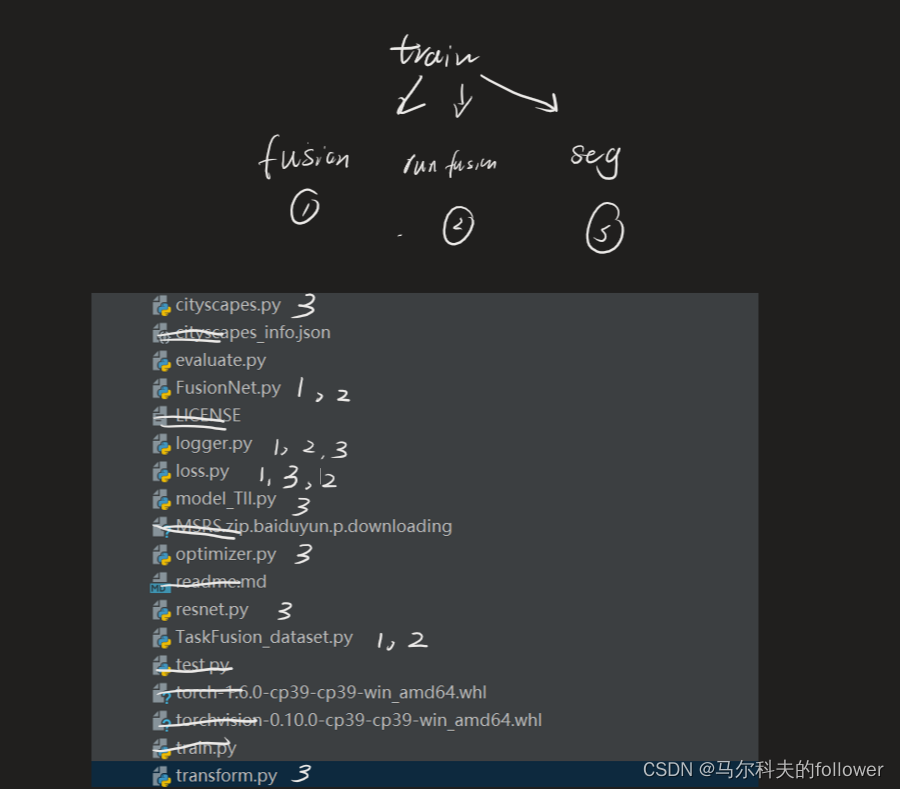
就是整个代码分为融合训练,融合detect,分割训练。
训练流程
其中,流程示意图可以这样看
其中,这样的轮回要走4遍
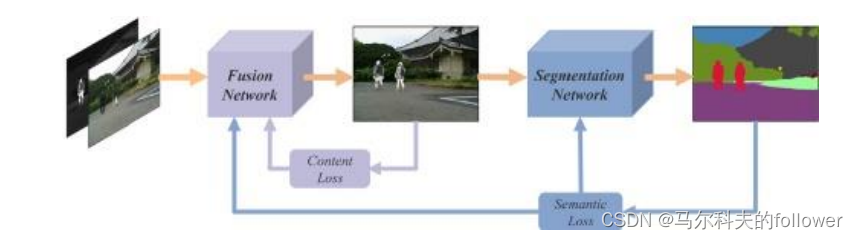
 也就对应论文中的这个图,具体的两个loss如何可以看论文或代码?
也就对应论文中的这个图,具体的两个loss如何可以看论文或代码?
β随着M的增大而增大,m=β,越到后期越重视高级任务

?
?
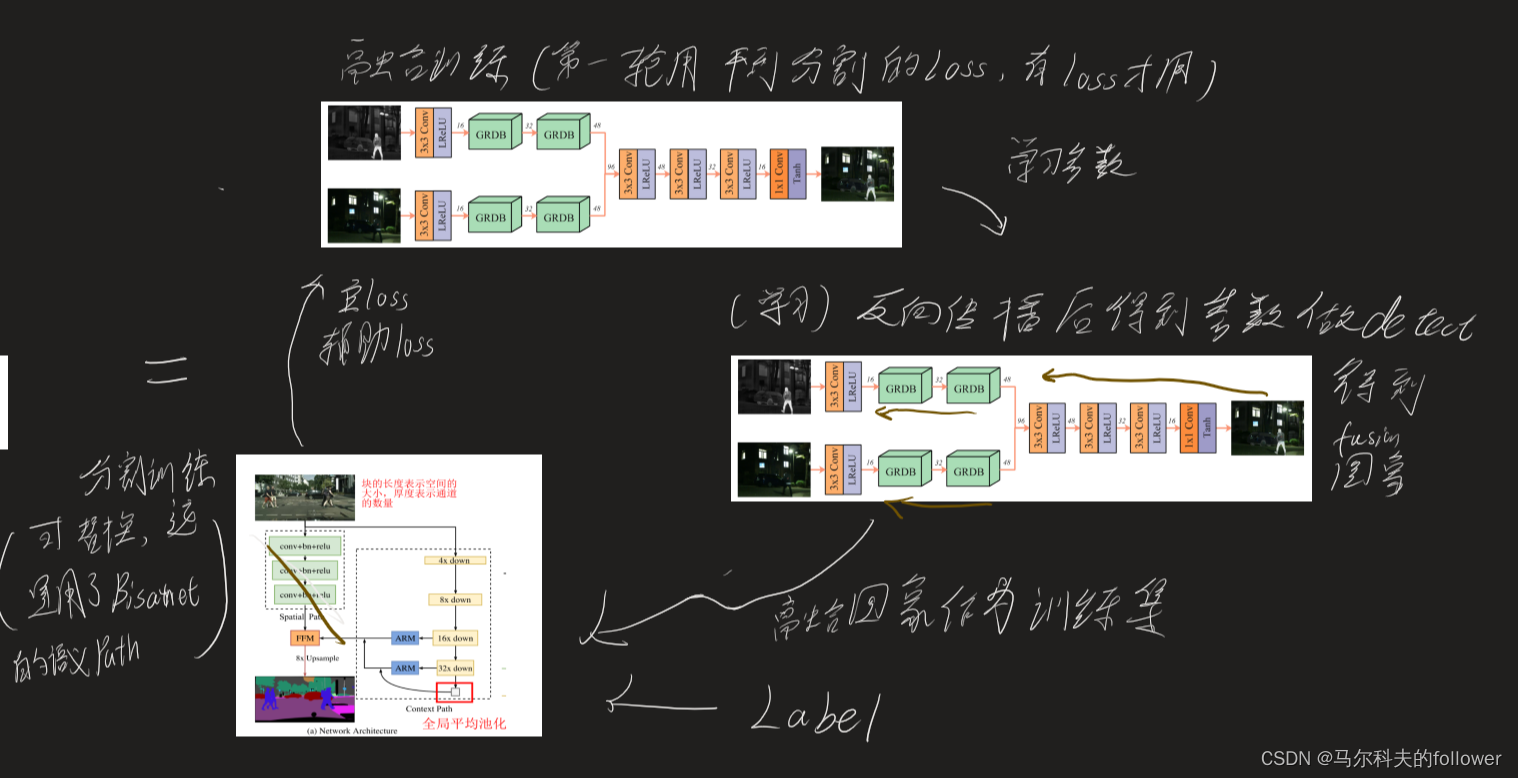
?融合模块
由于重点在融合模块,论文创新的地方也在这个地方,重点介绍一下融合模块
总结来说第一部分数据载入与训练器载入,使用了Adam的方法,batch为8,一轮epoch要走135个epoch,因为有1080张图片。?这里才10轮epoch训练,论文中采用的是2700轮训练。
训练模块
?这里segloss一开始会是0,因为第一轮没有分割。
然后就是看seafusion了,在fusionmodel这个函数里面。
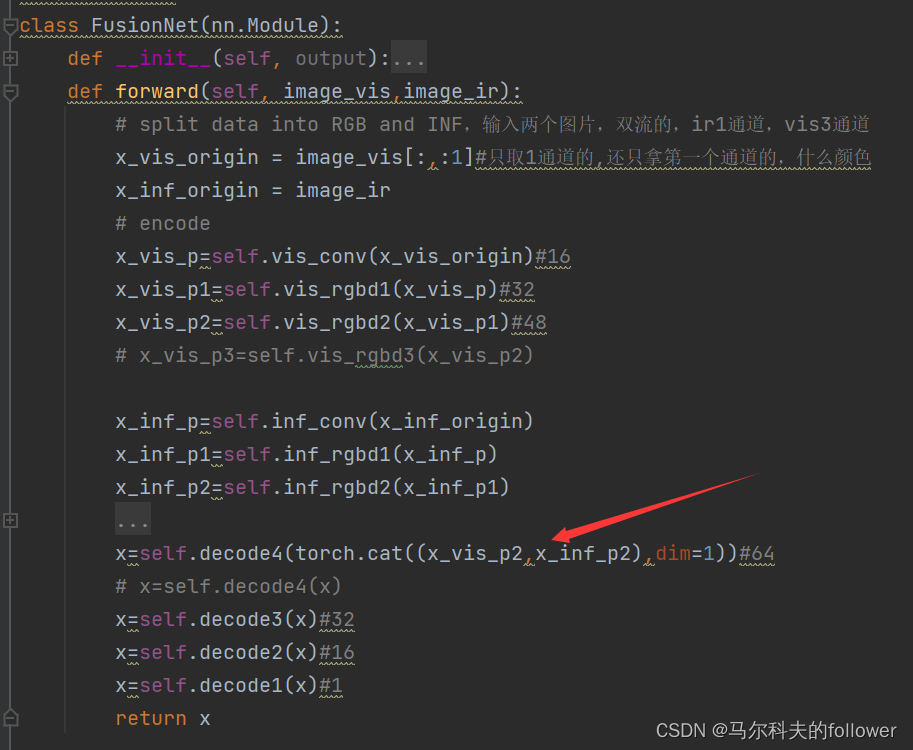
其中,两个图片融合只是简单的将图片重叠,就是在通道数上做增加,做了padding所以大兄没改变,没看出是属于什么级别的图片融合。维度1上做cat就是一个简单通道数上叠加,真的产生关联性应该后面三成cnn做运算才产生联系。
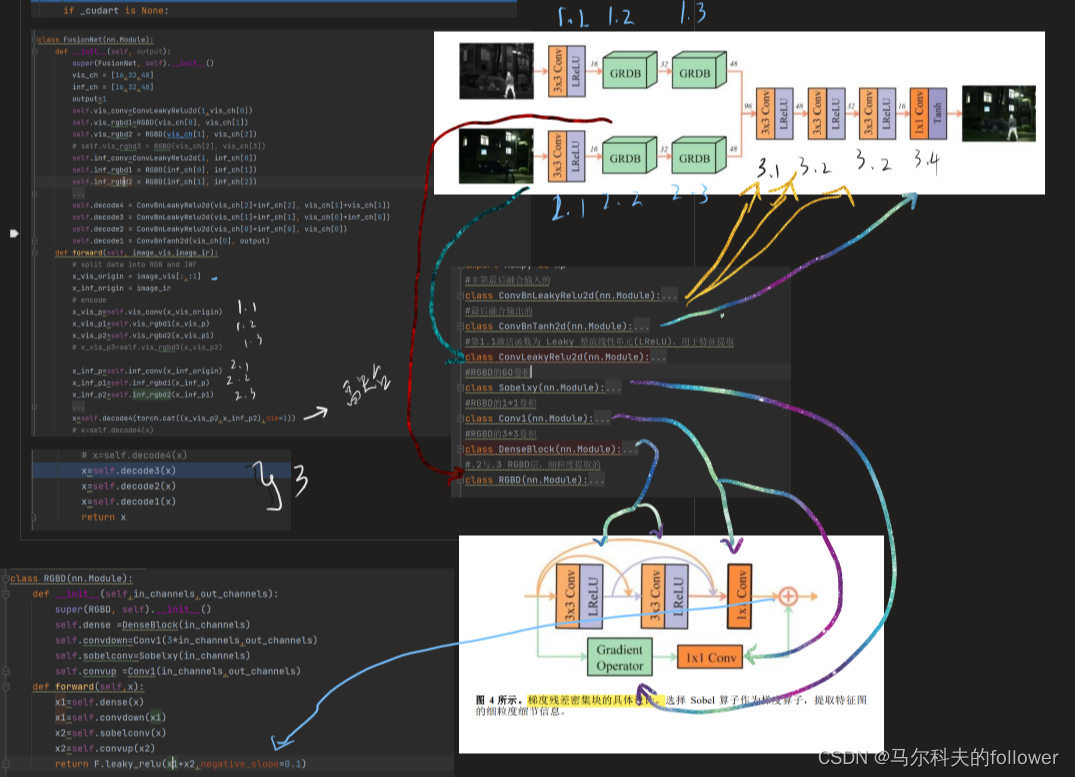
采用这样的设计首先是基于fcn的思想,全卷积的设计。
然后多层的非GRDB的模块,一方面是增加目标函数的非线性,增强拟合能力。另一方面是黑盒第抽取图片的特征。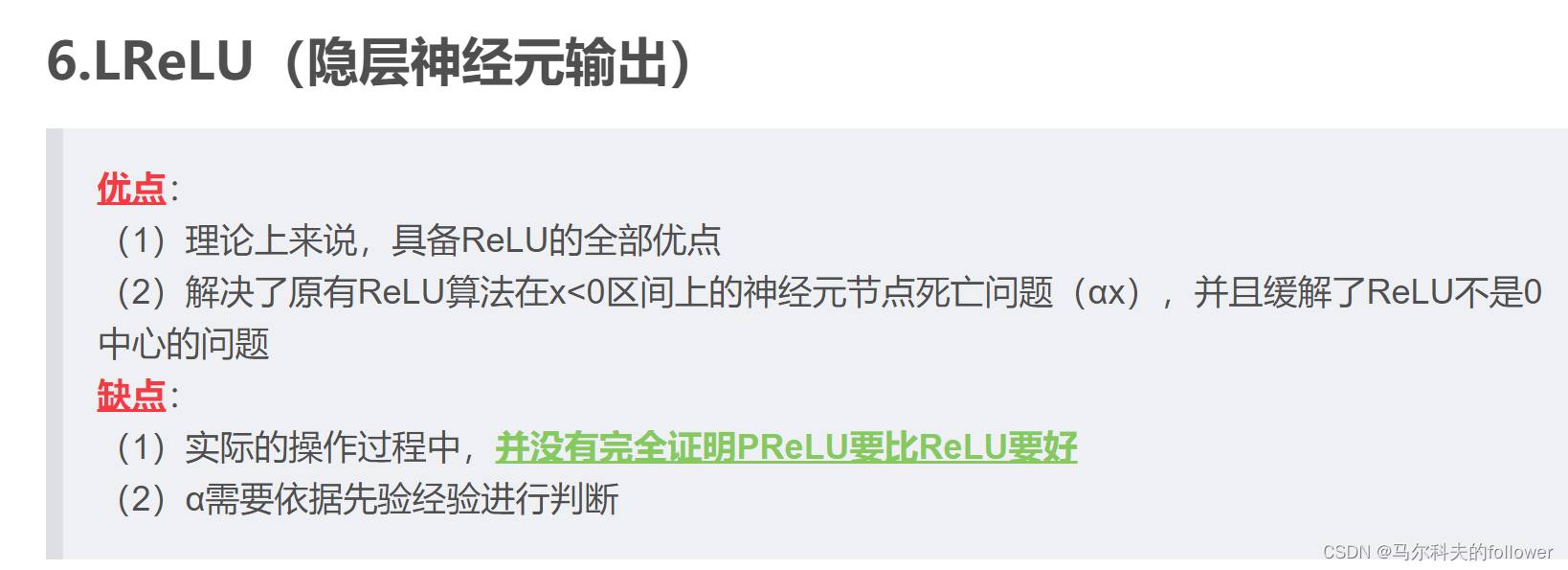
其中3*3卷积模块relu是cnn层常用的激活函数,采用lrelu的原因是在sgd模块中可以快速收敛,虽然融合模块采用了adam算法,但是adam也延承了sgd的部分做法。
采用卷积的原因也是因为保留图片的空间特征。

3.4中采用tanh的原因是防止梯度爆炸,因为relu存在正向的梯度爆炸,当relu的负参数取值不当时。主要是防止梯度消失,但是同时要求速度快。


?GRDB模块
这个模块文中说是

?

细粒度特征提取的意思是对某个对象更加细致的划分,但不知道在这里若想用于语义分割是不是对像素更加细致的划分。
做了一点消融实验,去掉这些层观察到的图片效果,实验比较粗糙,去一层grdb也去一层relu。

?

可以看出的是越来越模糊了,从上到下分别是去0,1,2层grdb层。
所以grdb的作用可以总结为将图片更加细化,renet层与密度层的作用也可以看作是在渐层的空间信息与深层的语义信息结合,可能融合一开始语义并不是他的目标,目标可能是其它的。
loss

目标是拟合出某个像素上图片最突出的地方,谁大就拟合谁,所以这里训练集即是label也是train。?

纹理的话,就是Sobel 梯度算子大的为那个目标,因为红外Sobel 梯度算子普遍低,所以可以区分出目标。?Sobel边缘检测 - 梯度算子介绍_Henry Read的博客-CSDN博客_sobel梯度算子
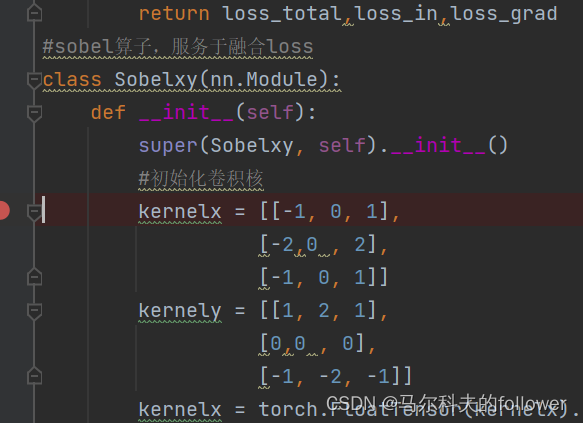
?计算方式比较奇怪,并没有细究
语义分割
这里语义分割一开始以为是Bisanet的网络,但是文中在loss引用的文章却是另一个编码器网络,叫Bilateral attention decoder A lightweight decoder for real-time semantic segmentation。
但是看代码时却用的是Bisanet的架构,所以这里猜是语义分割网络是可以灵活替换的,只要导出mainloss与辅助loss就行。
辅助loss就是输出前一层的loss,可以快速backward的作用。
这里不细究了
检测
将这个做法分别与yolo与语义分割联合,当然高级任务的loss也要重新定义
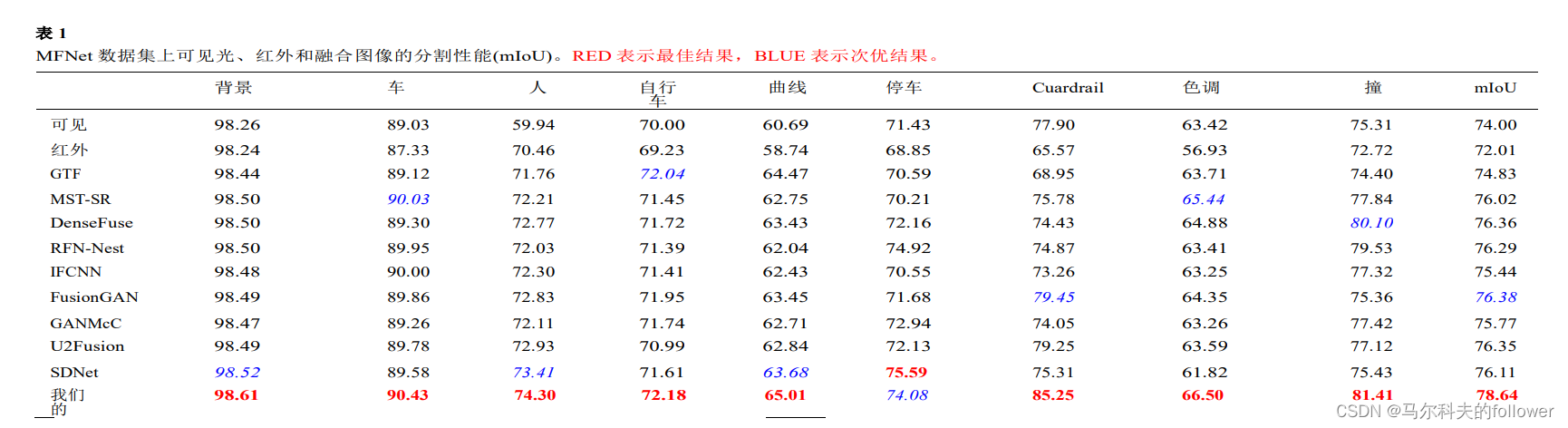
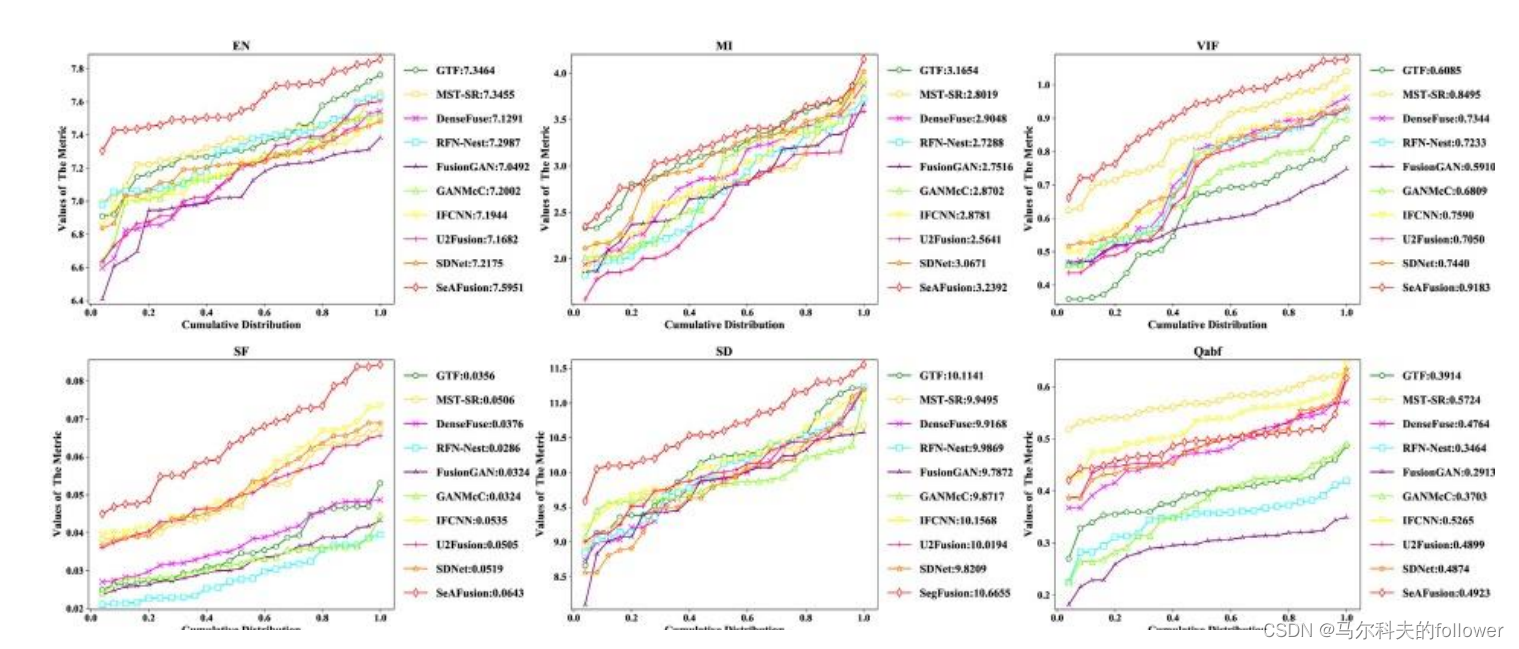
?
?
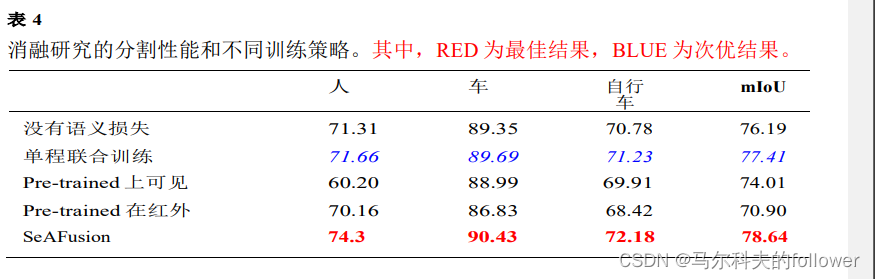
消融实验
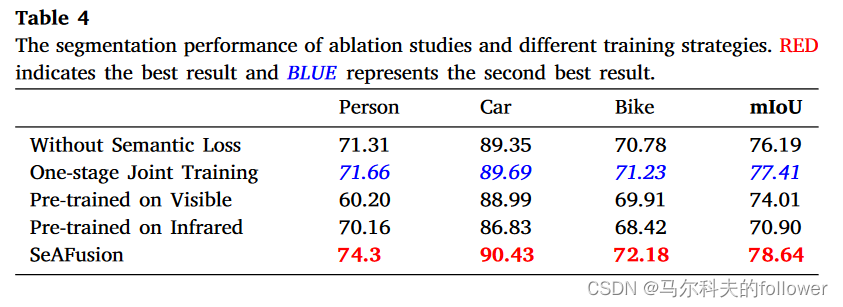
?
?
注释
test
# coding:utf-8
import os
import argparse
import time
import numpy as np
# os.environ['CUDA_VISIBLE_DEVICES'] = '2'
import torch
import torch.nn.functional as F
from torch.autograd import Variable
from torch.utils.data import DataLoader
from model_TII import BiSeNet
from TaskFusion_dataset import Fusion_dataset
from FusionNet import FusionNet
from tqdm import tqdm
from torch.autograd import Variable
from PIL import Image
#这个是只做图像融合的
# To run, set the fused_dir, and the val path in the TaskFusionDataset.py
def main():
fusion_model_path = './model/Fusion/fusionmodel_final.pth'#载入权重用于预测
fusionmodel = eval('FusionNet')(output=1)#载入模型用于预测
device = torch.device("cuda:{}".format(args.gpu) if torch.cuda.is_available() else "cpu")#载入计算机
if args.gpu >= 0:
fusionmodel.to(device)
fusionmodel.load_state_dict(torch.load(fusion_model_path))#载入权重用于预测
print('fusionmodel load done!')
ir_path = './test_imgs/ir'
vi_path = './test_imgs/vi'
test_dataset = Fusion_dataset('val', ir_path=ir_path, vi_path=vi_path)
# test_dataset = Fusion_dataset('val'),以上都是做成数据集来用
#这里分号了哪些batch,便于预测为什么要一个batch一个来,因为这样节省代码,一般为1
test_loader = DataLoader(
dataset=test_dataset,
batch_size=args.batch_size,
shuffle=False,
num_workers=args.num_workers,
pin_memory=True,
drop_last=False,
)
test_loader.n_iter = len(test_loader)#12,刚好是数据集合的长度
#以下开始预测,不带梯度的,节省时间,节省代码
with torch.no_grad():#输入进来的是标准化图片,就是没有了255那些的,都是0.几的
for it, (images_vis, images_ir,name) in enumerate(test_loader):#dataloader可以得到一个迭代器,在自定义的dataset设置return就行,根据顺序返回
images_vis = Variable(images_vis)
images_ir = Variable(images_ir)
if args.gpu >= 0:
images_vis = images_vis.to(device)
images_ir = images_ir.to(device)
images_vis_ycrcb = RGB2YCrCb(images_vis)
logits = fusionmodel(images_vis_ycrcb, images_ir)#自动调用forward,因为这里重载了,然后输出的灰度图
#分离出vis的1~2通道,分离出2通道,根据融合图像得到,连接第2个维度(dim从0开始),就是本是三个1通道,结果变3通道了
fusion_ycrcb = torch.cat(#做的是将非灰度的颜色输入到原来的地方,变成彩色
(logits, images_vis_ycrcb[:, 1:2, :, :], images_vis_ycrcb[:, 2:, :, :]),
dim=1,
)
#这里开始融合完毕,下面都是处理
fusion_image = YCrCb2RGB(fusion_ycrcb)#将结果也做一个变换ycrcb
#实验证明,以下的步骤对融合图像没有很大影响,现在就可以拿去用了
ones = torch.ones_like(fusion_image)
zeros = torch.zeros_like(fusion_image)
#形成两个1与0矩阵,便于后序处理
fusion_image = torch.where(fusion_image > ones, ones, fusion_image)
fusion_image = torch.where(fusion_image < zeros, zeros, fusion_image)
fused_image = fusion_image.cpu().numpy()#转为array格式
fused_image = fused_image.transpose((0, 2, 3, 1))#就是从(1, 3, 480, 640)变为(1, 480, 640, 3),标准以下array的转换
#标准化,实验表明,注释没有发生太大变化,但一开始输入进来就是标准化图片,
fused_image = (fused_image - np.min(fused_image)) / (
np.max(fused_image) - np.min(fused_image)
)
#只有test采用,因为在训练的时候需要输出,255因为正则化了,所以?255,因为原图像经过了正则化,不?255会全黑
fused_image = np.uint8(255.0 * fused_image)
#下面都是输出融合结果的
for k in range(len(name)):#名字?应该是后期批处理用的,在这里k=1恒为
image = fused_image[k, :, :, :]#删第一维度的东西,k=0
image = Image.fromarray(image)#array――》image
save_path = os.path.join(fused_dir, name[k])
image.save(save_path)
print('Fusion {0} Sucessfully!'.format(save_path))
def YCrCb2RGB(input_im):
device = torch.device("cuda:{}".format(args.gpu) if torch.cuda.is_available() else "cpu")
im_flat = input_im.transpose(1, 3).transpose(1, 2).reshape(-1, 3)
mat = torch.tensor(
[[1.0, 1.0, 1.0], [1.403, -0.714, 0.0], [0.0, -0.344, 1.773]]
).to(device)
bias = torch.tensor([0.0 / 255, -0.5, -0.5]).to(device)
temp = (im_flat + bias).mm(mat).to(device)
out = (
temp.reshape(
list(input_im.size())[0],
list(input_im.size())[2],
list(input_im.size())[3],
3,
)
.transpose(1, 3)
.transpose(2, 3)
)
return out
def RGB2YCrCb(input_im):
device = torch.device("cuda:{}".format(args.gpu) if torch.cuda.is_available() else "cpu")
im_flat = input_im.transpose(1, 3).transpose(1, 2).reshape(-1, 3) # (nhw,c)
R = im_flat[:, 0]
G = im_flat[:, 1]
B = im_flat[:, 2]
Y = 0.299 * R + 0.587 * G + 0.114 * B
Cr = (R - Y) * 0.713 + 0.5
Cb = (B - Y) * 0.564 + 0.5
Y = torch.unsqueeze(Y, 1)
Cr = torch.unsqueeze(Cr, 1)
Cb = torch.unsqueeze(Cb, 1)
temp = torch.cat((Y, Cr, Cb), dim=1).to(device)
out = (
temp.reshape(
list(input_im.size())[0],
list(input_im.size())[2],
list(input_im.size())[3],
3,
)
.transpose(1, 3)
.transpose(2, 3)
)
return out
if __name__ == '__main__':
parser = argparse.ArgumentParser(description='Run SeAFusiuon with pytorch')
parser.add_argument('--model_name', '-M', type=str, default='SeAFusion')
parser.add_argument('--batch_size', '-B', type=int, default=1)
parser.add_argument('--gpu', '-G', type=int, default=-1)
parser.add_argument('--num_workers', '-j', type=int, default=8)
args = parser.parse_args()
#以上都是参数的获取过程,都存在args中
n_class = 9
seg_model_path = './model/Fusion/model_final.pth'
fusion_model_path = './model/Fusion/fusionmodel_final.pth'
fused_dir = './Fusion_results'
os.makedirs(fused_dir, mode=0o777, exist_ok=True)
print('| testing %s on GPU #%d with pytorch' % (args.model_name, args.gpu))
main()
FusionNet:存着融合网络的结构
# coding:utf-8
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
#本库是融合模型用的
#非第最后融合输入的
class ConvBnLeakyRelu2d(nn.Module):
# convolution
# batch normalization
# leaky relu
def __init__(self, in_channels, out_channels, kernel_size=3, padding=1, stride=1, dilation=1, groups=1):
super(ConvBnLeakyRelu2d, self).__init__()
#64 32
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size=kernel_size, padding=padding, stride=stride, dilation=dilation, groups=groups)
self.bn = nn.BatchNorm2d(out_channels)
def forward(self, x):
return F.leaky_relu(self.conv(x), negative_slope=0.2)
#最后融合输出的
class ConvBnTanh2d(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size=3, padding=1, stride=1, dilation=1, groups=1):
super(ConvBnTanh2d, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size=kernel_size, padding=padding, stride=stride, dilation=dilation, groups=groups)
self.bn = nn.BatchNorm2d(out_channels)
def forward(self,x):
return torch.tanh(self.conv(x))/2+0.5
#第1.1激活函数为 Leaky 整流线性单元(LReLU),用于特征提取
class ConvLeakyRelu2d(nn.Module):
# convolution
# leaky relu
def __init__(self, in_channels, out_channels, kernel_size=3, padding=1, stride=1, dilation=1, groups=1):
super(ConvLeakyRelu2d, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size=kernel_size, padding=padding, stride=stride, dilation=dilation, groups=groups)
# self.bn = nn.BatchNorm2d(out_channels)
def forward(self,x):
# print(x.size())
return F.leaky_relu(self.conv(x), negative_slope=0.2)
#RGBD的GO卷积
class Sobelxy(nn.Module):
def __init__(self,channels, kernel_size=3, padding=1, stride=1, dilation=1, groups=1):
super(Sobelxy, self).__init__()
sobel_filter = np.array([[1, 0, -1],
[2, 0, -2],
[1, 0, -1]])
self.convx=nn.Conv2d(channels, channels, kernel_size=kernel_size, padding=padding, stride=stride, dilation=dilation, groups=channels,bias=False)
self.convx.weight.data.copy_(torch.from_numpy(sobel_filter))
self.convy=nn.Conv2d(channels, channels, kernel_size=kernel_size, padding=padding, stride=stride, dilation=dilation, groups=channels,bias=False)
self.convy.weight.data.copy_(torch.from_numpy(sobel_filter.T))
def forward(self, x):
sobelx = self.convx(x)
sobely = self.convy(x)
x=torch.abs(sobelx) + torch.abs(sobely)
return x
#RGBD的1*1卷积
class Conv1(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size=1, padding=0, stride=1, dilation=1, groups=1):
super(Conv1, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size=kernel_size, padding=padding, stride=stride, dilation=dilation, groups=groups)
def forward(self,x):
return self.conv(x)
#RGBD的3*3卷积
class DenseBlock(nn.Module):
def __init__(self,channels):
super(DenseBlock, self).__init__()
self.conv1 = ConvLeakyRelu2d(channels, channels)
self.conv2 = ConvLeakyRelu2d(2*channels, channels)
# self.conv3 = ConvLeakyRelu2d(3*channels, channels)
def forward(self,x):#跳跃连接,用cat函数
x=torch.cat((x,self.conv1(x)),dim=1)
x = torch.cat((x, self.conv2(x)), dim=1)
# x = torch.cat((x, self.conv3(x)), dim=1)
return x
#.2与.3 RGBD层,细粒度提取的
class RGBD(nn.Module):
def __init__(self,in_channels,out_channels):
super(RGBD, self).__init__()
self.dense =DenseBlock(in_channels)
self.convdown=Conv1(3*in_channels,out_channels)
self.sobelconv=Sobelxy(in_channels)
self.convup =Conv1(in_channels,out_channels)
def forward(self,x):
x1=self.dense(x)
x1=self.convdown(x1)
x2=self.sobelconv(x)
x2=self.convup(x2)
return F.leaky_relu(x1+x2,negative_slope=0.1)
#继承nn.module
class FusionNet(nn.Module):
def __init__(self, output):
super(FusionNet, self).__init__()#返回的FusionNet的直接父类
vis_ch = [16,32,48]
inf_ch = [16,32,48]
output=1
self.vis_conv=ConvLeakyRelu2d(1,vis_ch[0])
self.vis_rgbd1=RGBD(vis_ch[0], vis_ch[1])
self.vis_rgbd2 = RGBD(vis_ch[1], vis_ch[2])
# self.vis_rgbd3 = RGBD(vis_ch[2], vis_ch[3])
self.inf_conv=ConvLeakyRelu2d(1, inf_ch[0])
self.inf_rgbd1 = RGBD(inf_ch[0], inf_ch[1])
self.inf_rgbd2 = RGBD(inf_ch[1], inf_ch[2])
# self.inf_rgbd3 = RGBD(inf_ch[2], inf_ch[3])
# self.decode5 = ConvBnLeakyRelu2d(vis_ch[3]+inf_ch[3], vis_ch[2]+inf_ch[2])
self.decode4 = ConvBnLeakyRelu2d(vis_ch[2]+inf_ch[2], vis_ch[1]+vis_ch[1])
self.decode3 = ConvBnLeakyRelu2d(vis_ch[1]+inf_ch[1], vis_ch[0]+inf_ch[0])#64,32
self.decode2 = ConvBnLeakyRelu2d(vis_ch[0]+inf_ch[0], vis_ch[0])
self.decode1 = ConvBnTanh2d(vis_ch[0], output)
def forward(self, image_vis,image_ir):
# split data into RGB and INF,输入两个图片,双流的,ir1通道,vis3通道
x_vis_origin = image_vis[:,:1]#只取1通道的,还只拿第一个通道的,什么颜色
x_inf_origin = image_ir
# encode
x_vis_p=self.vis_conv(x_vis_origin)#16
x_vis_p1=self.vis_rgbd1(x_vis_p)#32
x_vis_p2=self.vis_rgbd2(x_vis_p1)#48
# x_vis_p3=self.vis_rgbd3(x_vis_p2)
x_inf_p=self.inf_conv(x_inf_origin)
x_inf_p1=self.inf_rgbd1(x_inf_p)
x_inf_p2=self.inf_rgbd2(x_inf_p1)
# x_inf_p3=self.inf_rgbd3(x_inf_p2)
# decode,融合将其维度1都剪切到一起,48+48=96
x=self.decode4(torch.cat((x_vis_p2,x_inf_p2),dim=1))#96-》64
# x=self.decode4(x)
x=self.decode3(x)#64-》32
x=self.decode2(x)#32-》16
x=self.decode1(x)#1
return x
def unit_test():#做测试的,看看融合模块有没有问题
import numpy as np
x = torch.tensor(np.random.rand(2,4,480,640).astype(np.float32))
model = FusionNet(output=1)
y = model(x)
print('output shape:', y.shape)
assert y.shape == (2,1,480,640), 'output shape (2,1,480,640) is expected!'
print('test ok!')
if __name__ == '__main__':
unit_test()
loss:存着融合与分割网络的计算方式?
#!/usr/bin/python
# -*- encoding: utf-8 -*-
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
class OhemCELoss(nn.Module):
def __init__(self, thresh, n_min, ignore_lb=255, *args, **kwargs):
super(OhemCELoss, self).__init__()
self.thresh = -torch.log(torch.tensor(thresh, dtype=torch.float)).cuda()#阈值,0,7
self.n_min = n_min
self.ignore_lb = ignore_lb
self.criteria = nn.CrossEntropyLoss(ignore_index=ignore_lb, reduction='none')
def forward(self, logits, labels):
N, C, H, W = logits.size()
loss = self.criteria(logits, labels).view(-1)
loss, _ = torch.sort(loss, descending=True)
if loss[self.n_min] > self.thresh:
loss = loss[loss>self.thresh]#大取大
else:
loss = loss[:self.n_min]#否则取小
return torch.mean(loss)#返回平均值
#0
class SoftmaxFocalLoss(nn.Module):
def __init__(self, gamma, ignore_lb=255, *args, **kwargs):
super(FocalLoss, self).__init__()
self.gamma = gamma
self.nll = nn.NLLLoss(ignore_index=ignore_lb)
def forward(self, logits, labels):
scores = F.softmax(logits, dim=1)
factor = torch.pow(1.-scores, self.gamma)
log_score = F.log_softmax(logits, dim=1)
log_score = factor * log_score
loss = self.nll(log_score, labels)
return loss
#0
class NormalLoss(nn.Module):
def __init__(self,ignore_lb=255, *args, **kwargs):
super( NormalLoss, self).__init__()
self.criteria = nn.CrossEntropyLoss(ignore_index=ignore_lb, reduction='none')
def forward(self, logits, labels):
N, C, H, W = logits.size()
loss = self.criteria(logits, labels)
return torch.mean(loss)
#融合的loss
class Fusionloss(nn.Module):
def __init__(self):
super(Fusionloss, self).__init__()
self.sobelconv=Sobelxy()
#考虑到了label
def forward(self,image_vis,image_ir,labels,generate_img,i):
image_y=image_vis[:,:1,:,:]
x_in_max=torch.max(image_y,image_ir)
loss_in=F.l1_loss(x_in_max,generate_img)
#以上是强度损失
y_grad=self.sobelconv(image_y)
ir_grad=self.sobelconv(image_ir)
generate_img_grad=self.sobelconv(generate_img)
x_grad_joint=torch.max(y_grad,ir_grad)
loss_grad=F.l1_loss(x_grad_joint,generate_img_grad)
loss_total=loss_in+10*loss_grad
return loss_total,loss_in,loss_grad
#sobel算子,服务于融合loss
class Sobelxy(nn.Module):
def __init__(self):
super(Sobelxy, self).__init__()
#初始化卷积核
kernelx = [[-1, 0, 1],
[-2,0 , 2],
[-1, 0, 1]]
kernely = [[1, 2, 1],
[0,0 , 0],
[-1, -2, -1]]
kernelx = torch.FloatTensor(kernelx).unsqueeze(0).unsqueeze(0)
kernely = torch.FloatTensor(kernely).unsqueeze(0).unsqueeze(0)
self.weightx = nn.Parameter(data=kernelx, requires_grad=False).cuda()
self.weighty = nn.Parameter(data=kernely, requires_grad=False).cuda()
def forward(self,x):
sobelx=F.conv2d(x, self.weightx, padding=1)
sobely=F.conv2d(x, self.weighty, padding=1)
return torch.abs(sobelx)+torch.abs(sobely)#绝对值
if __name__ == '__main__':
pass
model_TII.py:存着分割网络的?
#!/usr/bin/python
# -*- encoding: utf-8 -*-
import torch
import torch.nn as nn
import torch.nn.functional as F
#import torchvision
from resnet import Resnet18
# from modules.bn import InPlaceABNSync as BatchNorm2d
#怀疑是v2版的,因为没用到FFM
#relu模块
class ConvBNReLU(nn.Module):
def __init__(self, in_chan, out_chan, ks=3, stride=1, padding=1, *args, **kwargs):
super(ConvBNReLU, self).__init__()
self.conv = nn.Conv2d(in_chan,
out_chan,
kernel_size = ks,
stride = stride,
padding = padding,
bias = False)
self.bn = nn.BatchNorm2d(out_chan)
self.init_weight()
def forward(self, x):
x = self.conv(x)#3*3
x = self.bn(x)
x = F.leaky_relu(x)
return x
def init_weight(self):
for ly in self.children():
if isinstance(ly, nn.Conv2d):
nn.init.kaiming_normal_(ly.weight, a=1)
if not ly.bias is None: nn.init.constant_(ly.bias, 0)
#arm层的上部分
class ConvBNSig(nn.Module):
def __init__(self, in_chan, out_chan, ks=3, stride=1, padding=1, *args, **kwargs):
super(ConvBNSig, self).__init__()
self.conv = nn.Conv2d(in_chan,
out_chan,
kernel_size = ks,
stride = stride,
padding = padding,
bias = False)
self.bn = nn.BatchNorm2d(out_chan)
self.sigmoid_atten = nn.Sigmoid()
self.init_weight()
def forward(self, x):
x = self.conv(x)
x = self.bn(x)
x = self.sigmoid_atten(x)
return x
def init_weight(self):
for ly in self.children():
if isinstance(ly, nn.Conv2d):
nn.init.kaiming_normal_(ly.weight, a=1)
if not ly.bias is None: nn.init.constant_(ly.bias, 0)
#输出层的使用
class BiSeNetOutput(nn.Module):
def __init__(self, in_chan, mid_chan, n_classes, *args, **kwargs):
super(BiSeNetOutput, self).__init__()
self.conv = ConvBNReLU(in_chan, mid_chan, ks=3, stride=1, padding=1)#3*3
self.conv_out = nn.Conv2d(mid_chan, n_classes, kernel_size=1, bias=False)
self.init_weight()
def forward(self, x):
x = self.conv(x)#relu操作
x = self.conv_out(x)#1*1卷积,改变大小
return x
def init_weight(self):
for ly in self.children():
if isinstance(ly, nn.Conv2d):
nn.init.kaiming_normal_(ly.weight, a=1)
if not ly.bias is None: nn.init.constant_(ly.bias, 0)
def get_params(self):
wd_params, nowd_params = [], []
for name, module in self.named_modules():
if isinstance(module, nn.Linear) or isinstance(module, nn.Conv2d):
wd_params.append(module.weight)
if not module.bias is None:
nowd_params.append(module.bias)
elif isinstance(module, nn.BatchNorm2d):
nowd_params += list(module.parameters())
return wd_params, nowd_params
#没用到
class Attentionout(nn.Module):
def __init__(self, out_chan, *args, **kwargs):
super(Attentionout, self).__init__()
self.conv_atten = nn.Conv2d(out_chan, out_chan, kernel_size= 1,bias=False)
self.bn_atten = nn.BatchNorm2d(out_chan)
self.sigmoid_atten = nn.Sigmoid()
self.init_weight()
def forward(self, x):
atten = self.conv_atten(x)
atten = self.bn_atten(atten)
atten = self.sigmoid_atten(atten)
out = torch.mul(x, atten)
x = x+out
return out
def init_weight(self):
for ly in self.children():
if isinstance(ly, nn.Conv2d):
nn.init.kaiming_normal_(ly.weight, a=1)
if not ly.bias is None: nn.init.constant_(ly.bias, 0)
#arm
class AttentionRefinementModule(nn.Module):
def __init__(self, in_chan, out_chan, *args, **kwargs):
super(AttentionRefinementModule, self).__init__()
self.conv = ConvBNReLU(in_chan, out_chan, ks=3, stride=1, padding=1)
self.conv_atten = nn.Conv2d(out_chan, out_chan, kernel_size= 1, bias=False)
self.bn_atten = nn.BatchNorm2d(out_chan)
self.sigmoid_atten = nn.Sigmoid()
self.init_weight()
def forward(self, x):
feat = self.conv(x)
atten = F.avg_pool2d(feat, feat.size()[2:])
atten = self.conv_atten(atten)
atten = self.bn_atten(atten)
atten = self.sigmoid_atten(atten)
out = torch.mul(feat, atten)
return out
def init_weight(self):
for ly in self.children():
if isinstance(ly, nn.Conv2d):
nn.init.kaiming_normal_(ly.weight, a=1)
if not ly.bias is None: nn.init.constant_(ly.bias, 0)
#没用到
class SAR(nn.Module):
def __init__(self, in_chan, mid, out_chan, *args, **kwargs):
super(SAR, self).__init__()
self.conv1 = ConvBNReLU(in_chan, out_chan, 3, 1, 1)
self.conv_reduce = ConvBNReLU(in_chan,mid,1,1,0)
self.conv_atten = nn.Conv2d(2, 1, kernel_size= 3, padding=1,bias=False)
self.bn_atten = nn.BatchNorm2d(1)
self.sigmoid_atten = nn.Sigmoid()
def forward(self, x):
x_att = self.conv_reduce(x)
low_attention_mean = torch.mean(x_att,1,True)
low_attention_max = torch.max(x_att,1,True)[0]
low_attention = torch.cat([low_attention_mean,low_attention_max],dim=1)
spatial_attention = self.conv_atten(low_attention)
spatial_attention = self.bn_atten(spatial_attention)
spatial_attention = self.sigmoid_atten(spatial_attention)
x = x*spatial_attention
x = self.conv1(x)
#channel attention
# low_refine = self.conv_ca_rf(low_refine)
return x
def init_weight(self):
for ly in self.children():
if isinstance(ly, nn.Conv2d):
nn.init.kaiming_normal_(ly.weight, a=1)
if not ly.bias is None: nn.init.constant_(ly.bias, 0)
#没用到
class SeparableConvBnRelu(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size=1, stride=1,
padding=0, dilation=1):
super(SeparableConvBnRelu, self).__init__()
self.conv1 = nn.Conv2d(in_channels, in_channels, kernel_size, stride,
padding, dilation, groups=in_channels,
bias=False)
self.point_wise_cbr = ConvBNReLU(in_channels, out_channels, 1, 1, 0)
self.init_weight()
def forward(self, x):
x = self.conv1(x)
x = self.point_wise_cbr(x)
return x
def init_weight(self):
for ly in self.children():
if isinstance(ly, nn.Conv2d):
nn.init.kaiming_normal_(ly.weight, a=1)
if not ly.bias is None: nn.init.constant_(ly.bias, 0)
#语义路径
class ContextPath(nn.Module):
def __init__(self, *args, **kwargs):
super(ContextPath, self).__init__()
self.resnet = Resnet18()
# self.conv_32 = ConvBNReLU(512, 128, ks=3, stride=1, padding=1)
# self.conv_16 = ConvBNReLU(256, 128, ks=3, stride=1, padding=1)
# self.conv_8 = ConvBNReLU(128, 128, ks=3, stride=1, padding=1)
self.arm32 = AttentionRefinementModule(512, 128)
self.arm16 = AttentionRefinementModule(256, 128)
self.arm8 = AttentionRefinementModule(128, 128)
self.sp16 = ConvBNReLU(256, 128, ks=1, stride=1, padding=0)
self.sp8 = ConvBNReLU(256, 128, ks=1, stride=1, padding=0)
self.conv_head32 = ConvBNReLU(128, 128, ks=3, stride=1, padding=1)
self.conv_head16 = ConvBNReLU(128, 128, ks=3, stride=1, padding=1)
# self.conv_avg = ConvBNReLU(512, 128, ks=1, stride=1, padding=0)
# self.conv_context = ConvBNReLU(512, 128, ks=1, stride=1, padding=0)
self.conv_fuse1 = ConvBNSig(128,128,ks=1,stride=1, padding=0)
self.conv_fuse2 = ConvBNSig(128,128,ks=1,stride=1, padding=0)
self.conv_fuse = ConvBNReLU(128, 128, ks=1, stride=1, padding=0)
self.init_weight()
def forward(self, x):
H0, W0 = x.size()[2:]
_, feat8, feat16, feat32 = self.resnet(x)#x本身、1/8,1/16,1/32
H8, W8 = feat8.size()[2:]
H16, W16 = feat16.size()[2:]
H32, W32 = feat32.size()[2:]
# avg = F.avg_pool2d(feat32, feat32.size()[2:])
# avg = self.conv_avg(avg)
# avg_up = F.interpolate(avg, (H8, W8), mode='nearest')
feat32_arm = self.arm32(feat32)#32的arm取feature
feat32_cat = F.interpolate(feat32_arm, (H8, W8), mode='bilinear')
# feat32_sum = feat32_arm + avg_up
feat32_up = F.interpolate(feat32_arm, (H16, W16), mode='bilinear')
feat32_up = self.conv_head32(feat32_up)
feat16_arm = self.arm16(feat16)#16的arm取feature
feat16_cat = torch.cat([feat32_up,feat16_arm], dim=1)
feat16_cat = self.sp16(feat16_cat)
feat16_cat = F.interpolate(feat16_cat, (H8, W8), mode='bilinear')
feat16_up = F.interpolate(feat16_arm, (H8, W8), mode='bilinear')
feat16_up = self.conv_head16(feat16_up)
feat8_arm = self.arm8(feat8)#8的arm取feature
feat8_cat = torch.cat([feat16_up,feat8_arm], dim=1)
feat8_cat = self.sp8(feat8_cat)
feat16_atten = self.conv_fuse1(feat32_cat)
feat16_cat = feat16_atten*feat16_cat#16层的arm输出
feat8_atten = self.conv_fuse2(feat16_cat)
feat8_out = feat8_cat*feat8_atten#8层的arm输出
# feat8_out = torch.cat([feat8_cat,feat16_cat,feat32_cat], dim=1)
feat8_out = self.conv_fuse(feat8_out)#做了一个空间的操作
return feat8_out, feat16_arm, feat32_arm # x8, x8, x16
def init_weight(self):
for ly in self.children():
if isinstance(ly, nn.Conv2d):
nn.init.kaiming_normal_(ly.weight, a=1)
if not ly.bias is None: nn.init.constant_(ly.bias, 0)
def get_params(self):
wd_params, nowd_params = [], []
for name, module in self.named_modules():
if isinstance(module, (nn.Linear, nn.Conv2d)):
wd_params.append(module.weight)
if not module.bias is None:
nowd_params.append(module.bias)
elif isinstance(module, nn.BatchNorm2d):
nowd_params += list(module.parameters())
return wd_params, nowd_params
'''
### This is not used, since I replace this with the resnet feature with the same size
class SpatialPath(nn.Module):
def __init__(self, *args, **kwargs):
super(SpatialPath, self).__init__()
self.conv1 = ConvBNReLU(3, 64, ks=7, stride=2, padding=3)
self.conv2 = ConvBNReLU(64, 64, ks=3, stride=2, padding=1)
self.conv3 = ConvBNReLU(64, 64, ks=3, stride=2, padding=1)
self.conv_out = ConvBNReLU(64, 128, ks=1, stride=1, padding=0)
self.init_weight()
def forward(self, x):
feat = self.conv1(x)
feat = self.conv2(feat)
feat = self.conv3(feat)
feat = self.conv_out(feat)
return feat
def init_weight(self):
for ly in self.children():
if isinstance(ly, nn.Conv2d):
nn.init.kaiming_normal_(ly.weight, a=1)
if not ly.bias is None: nn.init.constant_(ly.bias, 0)
def get_params(self):
wd_params, nowd_params = [], []
for name, module in self.named_modules():
if isinstance(module, nn.Linear) or isinstance(module, nn.Conv2d):
wd_params.append(module.weight)
if not module.bias is None:
nowd_params.append(module.bias)
elif isinstance(module, BatchNorm2d):
nowd_params += list(module.parameters())
return wd_params, nowd_params
'''
#FFM融合层,也没用到
class FeatureFusionModule(nn.Module):
def __init__(self, in_chan, out_chan, *args, **kwargs):
super(FeatureFusionModule, self).__init__()
self.convblk = ConvBNReLU(in_chan, out_chan, ks=1, stride=1, padding=0)
self.conv1 = nn.Conv2d(out_chan,
out_chan//4,
kernel_size = 1,
stride = 1,
padding = 0,
bias = False)
self.conv2 = nn.Conv2d(out_chan//4,
out_chan,
kernel_size = 1,
stride = 1,
padding = 0,
bias = False)
self.relu = nn.ReLU(inplace=True)
self.sigmoid = nn.Sigmoid()
self.init_weight()
def forward(self, fsp, fcp):
fcat = torch.cat([fsp, fcp], dim=1)
feat = self.convblk(fcat)
atten = F.avg_pool2d(feat, feat.size()[2:])
atten = self.conv1(atten)
atten = self.relu(atten)
atten = self.conv2(atten)
atten = self.sigmoid(atten)
feat_atten = torch.mul(feat, atten)
feat_out = feat_atten + feat
return feat_out
def init_weight(self):
for ly in self.children():
if isinstance(ly, nn.Conv2d):
nn.init.kaiming_normal_(ly.weight, a=1)
if not ly.bias is None: nn.init.constant_(ly.bias, 0)
def get_params(self):
wd_params, nowd_params = [], []
for name, module in self.named_modules():
if isinstance(module, nn.Linear) or isinstance(module, nn.Conv2d):
wd_params.append(module.weight)
if not module.bias is None:
nowd_params.append(module.bias)
#没机会用了
#elif isinstance(module, BatchNorm2d):
# nowd_params += list(module.parameters())
return wd_params, nowd_params
class BiSeNet(nn.Module):
def __init__(self, n_classes, *args, **kwargs):
super(BiSeNet, self).__init__()
self.cp = ContextPath()
## here self.sp is deleted
# self.ffm = FeatureFusionModule(256, 256)
self.conv_out = BiSeNetOutput(128, 128, n_classes)
self.conv_out16 = BiSeNetOutput(128, 64, n_classes)
# self.conv_out32 = BiSeNetOutput(128, 64, n_classes)
self.init_weight()
#正向传播,x是输入的融合图像
def forward(self, x):
H, W = x.size()[2:]
#返回多个ARM,16没用到,几乎就是在语义上做处理,估计是因为论文目的只需要语义那一层
feat_res8, feat_cp8, feat_cp16 = self.cp(x) # here return res3b1 feature
# feat_sp = feat_res8 # use res3b1 feature to replace spatial path feature
# feat_fuse = self.ffm(feat_sp, feat_cp8)
feat_out = self.conv_out(feat_res8)#都是只做了进入ffm的操作
feat_out16 = self.conv_out16(feat_cp8)
# feat_out32 = self.conv_out32(feat_cp16)
#F是是算loss的
feat_out = F.interpolate(feat_out, (H, W), mode='bilinear', align_corners=True)
feat_out16 = F.interpolate(feat_out16, (H, W), mode='bilinear', align_corners=True)
# feat_out32 = F.interpolate(feat_out32, (H, W), mode='bilinear', align_corners=True)
return feat_out, feat_out16
def init_weight(self):
for ly in self.children():
if isinstance(ly, nn.Conv2d):
nn.init.kaiming_normal_(ly.weight, a=1)
if not ly.bias is None: nn.init.constant_(ly.bias, 0)
def get_params(self):
wd_params, nowd_params, lr_mul_wd_params, lr_mul_nowd_params = [], [], [], []
for name, child in self.named_children():
child_wd_params, child_nowd_params = child.get_params()
if isinstance(child, FeatureFusionModule) or isinstance(child, BiSeNetOutput):
lr_mul_wd_params += child_wd_params
lr_mul_nowd_params += child_nowd_params
else:
wd_params += child_wd_params
nowd_params += child_nowd_params
return wd_params, nowd_params, lr_mul_wd_params, lr_mul_nowd_params
if __name__ == "__main__":
net = BiSeNet(19)
net.cuda()
net.eval()
in_ten = torch.randn(16, 3, 640, 480).cuda()
out, out16 = net(in_ten)
print(out.shape)
net.get_params()
?transform.py:用于语义分割训练集的数据准备函数的类,辅助训练集的
#!/usr/bin/python
# -*- encoding: utf-8 -*-
from PIL import Image
import PIL.ImageEnhance as ImageEnhance
import random
class RandomCrop(object):
def __init__(self, size, *args, **kwargs):
self.size = size
def __call__(self, im_lb):
im = im_lb['im']
lb = im_lb['lb']
assert im.size == lb.size
W, H = self.size
w, h = im.size
if (W, H) == (w, h): return dict(im=im, lb=lb)
if w < W or h < H:
scale = float(W) / w if w < h else float(H) / h
w, h = int(scale * w + 1), int(scale * h + 1)
im = im.resize((w, h), Image.BILINEAR)
lb = lb.resize((w, h), Image.NEAREST)
sw, sh = random.random() * (w - W), random.random() * (h - H)
crop = int(sw), int(sh), int(sw) + W, int(sh) + H
return dict(
im = im.crop(crop),
lb = lb.crop(crop)
)
class HorizontalFlip(object):
def __init__(self, p=0.5, *args, **kwargs):
self.p = p
def __call__(self, im_lb):
if random.random() > self.p:
return im_lb
else:
im = im_lb['im']
lb = im_lb['lb']
return dict(im = im.transpose(Image.FLIP_LEFT_RIGHT),
lb = lb.transpose(Image.FLIP_LEFT_RIGHT),
)
class RandomScale(object):
def __init__(self, scales=(1, ), *args, **kwargs):
self.scales = scales
def __call__(self, im_lb):
im = im_lb['im']
lb = im_lb['lb']
W, H = im.size
scale = random.choice(self.scales)
w, h = int(W * scale), int(H * scale)
return dict(im = im.resize((w, h), Image.BILINEAR),
lb = lb.resize((w, h), Image.NEAREST),
)
class ColorJitter(object):
def __init__(self, brightness=None, contrast=None, saturation=None, *args, **kwargs):
if not brightness is None and brightness>0:
self.brightness = [max(1-brightness, 0), 1+brightness]
if not contrast is None and contrast>0:
self.contrast = [max(1-contrast, 0), 1+contrast]
if not saturation is None and saturation>0:
self.saturation = [max(1-saturation, 0), 1+saturation]
def __call__(self, im_lb):
im = im_lb['im']
lb = im_lb['lb']
r_brightness = random.uniform(self.brightness[0], self.brightness[1])
r_contrast = random.uniform(self.contrast[0], self.contrast[1])
r_saturation = random.uniform(self.saturation[0], self.saturation[1])
im = ImageEnhance.Brightness(im).enhance(r_brightness)
im = ImageEnhance.Contrast(im).enhance(r_contrast)
im = ImageEnhance.Color(im).enhance(r_saturation)
return dict(im = im,
lb = lb,
)
class MultiScale(object):
def __init__(self, scales):
self.scales = scales
def __call__(self, img):
W, H = img.size
sizes = [(int(W*ratio), int(H*ratio)) for ratio in self.scales]
imgs = []
[imgs.append(img.resize(size, Image.BILINEAR)) for size in sizes]
return imgs
class Compose(object):
def __init__(self, do_list):
self.do_list = do_list
def __call__(self, im_lb):
for comp in self.do_list:
im_lb = comp(im_lb)
return im_lb
if __name__ == '__main__':
flip = HorizontalFlip(p = 1)
crop = RandomCrop((321, 321))
rscales = RandomScale((0.75, 1.0, 1.5, 1.75, 2.0))
img = Image.open('data/img.jpg')
lb = Image.open('data/label.png')
?cityscapes.py:语义分割训练集的使用
#!/usr/bin/python
# -*- encoding: utf-8 -*-
import torch
from torch.utils.data import Dataset
import torchvision.transforms as transforms
import os.path as osp
import os
from PIL import Image
import numpy as np
import json
from transform import *
#只是分割的数据集载入
class CityScapes(Dataset):
def __init__(
self,
rootpth,#/MSRS/
cropsize=(640, 480),
mode='train',
Method='Fusion',
*args,
**kwargs
):
super(CityScapes, self).__init__(*args, **kwargs)
assert mode in ('train', 'val', 'test')
self.mode = mode
self.ignore_lb = 255
with open('./cityscapes_info.json', 'r') as fr:
labels_info = json.load(fr)
self.lb_map = {el['id']: el['trainId'] for el in labels_info}
## parse img directory
self.imgs = {}
imgnames = []
# impth = osp.join(rootpth, Method, mode)
impth = osp.join(rootpth, Method, mode)#'./MSRS/Fusion'+train
print(impth)
folders = os.listdir(impth)#'./MSRS/Fusion'+train里的所有图片的地址
for fd in folders:
fdpth = osp.join(impth, fd)#某个图片的地址
print(fdpth)
im_names = os.listdir(fdpth)
names = [el.replace('.png', '') for el in im_names]
impths = [osp.join(fdpth, el) for el in im_names]
imgnames.extend(names)
self.imgs.update(dict(zip(names, impths)))
## parse gt directory
self.labels = {}
gtnames = []
gtpth = osp.join(rootpth, 'Label', mode)#'./MSRS/Label'+train
folders = os.listdir(gtpth)
for fd in folders:
fdpth = osp.join(gtpth, fd)
print(fdpth)
lbnames = os.listdir(fdpth)
# lbnames = [el for el in lbnames if 'labelIds' in el]
names = [el.replace('.png', '') for el in lbnames]
lbpths = [osp.join(fdpth, el) for el in lbnames]
gtnames.extend(names)
self.labels.update(dict(zip(names, lbpths)))
self.imnames = imgnames
self.len = len(self.imnames)
assert set(imgnames) == set(gtnames)
assert set(self.imnames) == set(self.imgs.keys())
assert set(self.imnames) == set(self.labels.keys())
## pre-processing
self.to_tensor = transforms.Compose(
[
transforms.ToTensor(),
# transforms.Normalize(
# (0.2254, 0.2585, 0.2225), (0.0521, 0.0529, 0.0546)
# ),
]
)
self.trans_train = Compose(
[
ColorJitter(brightness=0.5, contrast=0.5, saturation=0.5),
HorizontalFlip(),
RandomScale((0.75, 1.0, 1.25, 1.5, 1.75, 2.0)),
RandomCrop(cropsize),
]
)
def __getitem__(self, idx):
fn = self.imnames[idx]#融合图像输入
impth = self.imgs[fn]#图像
lbpth = self.labels[fn]#标签
img = Image.open(impth)
label = Image.open(lbpth)
if self.mode == 'train':
im_lb = dict(im=img, lb=label)
im_lb = self.trans_train(im_lb)
img, label = im_lb['im'], im_lb['lb']
# test_image = np.array(img)
img = self.to_tensor(img)
label = np.array(label).astype(np.int64)[np.newaxis, :]
return img, label, fn
def __len__(self):
return self.len
def convert_labels(self, label):
for k, v in self.lb_map.items():
label[label == k] = v
return label
if __name__ == "__main__":
from tqdm import tqdm
ds = CityScapes('./data/', n_classes=9, mode='val')
uni = []
for im, lb in tqdm(ds):
lb_uni = np.unique(lb).tolist()
uni.extend(lb_uni)
print(uni)
print(set(uni))
?TaskFusion_dataset.py:融合网络获取数据的方式
# coding:utf-8
import os
import torch
from torch.utils.data.dataset import Dataset#生成数据集
from torch.utils.data import DataLoader
import numpy as np
from PIL import Image
import cv2
import glob
import os
def prepare_data_path(dataset_path):
filenames = os.listdir(dataset_path)
data_dir = dataset_path
data = glob.glob(os.path.join(data_dir, "*.bmp"))
data.extend(glob.glob(os.path.join(data_dir, "*.tif")))
data.extend(glob.glob((os.path.join(data_dir, "*.jpg"))))
data.extend(glob.glob((os.path.join(data_dir, "*.png"))))
data.sort()
filenames.sort()
return data, filenames
#融合train只行驶这一步
class Fusion_dataset(Dataset):
def __init__(self, split, ir_path=None, vi_path=None):
super(Fusion_dataset, self).__init__()
assert split in ['train', 'val', 'test'], 'split must be "train"|"val"|"test"'
#断言,在初始化的时候选择模式,val一般是test才用,train是训练用
if split == 'train':
data_dir_vis = './MSRS/Visible/train/MSRS/'
data_dir_ir = './MSRS/Infrared/train/MSRS/'
data_dir_label = './MSRS/Label/train/MSRS/'
self.filepath_vis, self.filenames_vis = prepare_data_path(data_dir_vis)
self.filepath_ir, self.filenames_ir = prepare_data_path(data_dir_ir)
self.filepath_label, self.filenames_label = prepare_data_path(data_dir_label)
self.split = split
self.length = min(len(self.filenames_vis), len(self.filenames_ir))
elif split == 'val':
data_dir_vis = vi_path
data_dir_ir = ir_path
self.filepath_vis, self.filenames_vis = prepare_data_path(data_dir_vis)
self.filepath_ir, self.filenames_ir = prepare_data_path(data_dir_ir)
self.split = split
self.length = min(len(self.filenames_vis), len(self.filenames_ir))
#自定义数据集子类
def __getitem__(self, index):
if self.split=='train':
vis_path = self.filepath_vis[index]
ir_path = self.filepath_ir[index]
label_path = self.filepath_label[index]
image_vis = np.array(Image.open(vis_path))
image_inf = cv2.imread(ir_path, 0)
label = np.array(Image.open(label_path))
image_vis = (
np.asarray(Image.fromarray(image_vis), dtype=np.float32).transpose(
(2, 0, 1)
)
/ 255.0
)
image_ir = np.asarray(Image.fromarray(image_inf), dtype=np.float32) / 255.0
image_ir = np.expand_dims(image_ir, axis=0)
label = np.asarray(Image.fromarray(label), dtype=np.int64)
name = self.filenames_vis[index]
return (
torch.tensor(image_vis),
torch.tensor(image_ir),
torch.tensor(label),
name,
)
elif self.split=='val':
vis_path = self.filepath_vis[index]
ir_path = self.filepath_ir[index]
image_vis = np.array(Image.open(vis_path))
image_inf = cv2.imread(ir_path, 0)
image_vis = (
np.asarray(Image.fromarray(image_vis), dtype=np.float32).transpose(
(2, 0, 1)
)
/ 255.0
)
image_ir = np.asarray(Image.fromarray(image_inf), dtype=np.float32) / 255.0
image_ir = np.expand_dims(image_ir, axis=0)
name = self.filenames_vis[index]
return (
torch.tensor(image_vis),
torch.tensor(image_ir),
name,
)
#数据集路径列表的长度。因为模式不同,所以会有不同结果
def __len__(self):
return self.length
# if __name__ == '__main__':
# data_dir = '/data1/yjt/MFFusion/dataset/'
# train_dataset = MF_dataset(data_dir, 'train', have_label=True)
# print("the training dataset is length:{}".format(train_dataset.length))
# train_loader = DataLoader(
# dataset=train_dataset,
# batch_size=2,
# shuffle=True,
# num_workers=2,
# pin_memory=True,
# drop_last=True,
# )
# train_loader.n_iter = len(train_loader)
# for it, (image_vis, image_ir, label) in enumerate(train_loader):
# if it == 5:
# image_vis.numpy()
# print(image_vis.shape)
# image_ir.numpy()
# print(image_ir.shape)
# break
?resent:也是在分割网络中的跃迁学习用的
#!/usr/bin/python
# -*- encoding: utf-8 -*-
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.utils.model_zoo as modelzoo
resnet18_url = 'https://download.pytorch.org/models/resnet18-5c106cde.pth'
#该类是做语义层的跃迁学习
from torch.nn import BatchNorm2d
def conv3x3(in_planes, out_planes, stride=1):
"""3x3 convolution with padding"""
return nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride,
padding=1, bias=False)
class BasicBlock(nn.Module):
def __init__(self, in_chan, out_chan, stride=1):
super(BasicBlock, self).__init__()
self.conv1 = conv3x3(in_chan, out_chan, stride)
self.bn1 = BatchNorm2d(out_chan)
self.conv2 = conv3x3(out_chan, out_chan)
self.bn2 = BatchNorm2d(out_chan)
self.relu = nn.ReLU(inplace=True)
self.downsample = None
if in_chan != out_chan or stride != 1:
self.downsample = nn.Sequential(
nn.Conv2d(in_chan, out_chan,
kernel_size=1, stride=stride, bias=False),
BatchNorm2d(out_chan),
)
def forward(self, x):
residual = self.conv1(x)#3*3
residual = self.bn1(residual)
residual = self.relu(residual)
residual = self.conv2(residual)#3*3
residual = self.bn2(residual)
shortcut = x
if self.downsample is not None:
shortcut = self.downsample(x)
out = shortcut + residual#跃迁加法
out = self.relu(out)#然后就经过一次relu再输出
return out
def create_layer_basic(in_chan, out_chan, bnum, stride=1):
layers = [BasicBlock(in_chan, out_chan, stride=stride)]
for i in range(bnum-1):
layers.append(BasicBlock(out_chan, out_chan, stride=1))
return nn.Sequential(*layers)
class Resnet18(nn.Module):
def __init__(self):
super(Resnet18, self).__init__()
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3,
bias=False)
self.bn1 = BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = create_layer_basic(64, 64, bnum=2, stride=1)
self.layer2 = create_layer_basic(64, 128, bnum=2, stride=2)
self.layer3 = create_layer_basic(128, 256, bnum=2, stride=2)
self.layer4 = create_layer_basic(256, 512, bnum=2, stride=2)
self.init_weight()
def forward(self, x):
x = self.conv1(x)#7*7
x = self.bn1(x)#bn
x = self.relu(x)
x = self.maxpool(x)#下采样
x = self.layer1(x)#第一层是1/4,做跃迁学习保留初始的图像下面也是一样
feat8 = self.layer2(x) # 1/8
feat16 = self.layer3(feat8) # 1/16
feat32 = self.layer4(feat16) # 1/32
return x, feat8, feat16, feat32
def init_weight(self):
state_dict = modelzoo.load_url(resnet18_url)
self_state_dict = self.state_dict()
for k, v in state_dict.items():
if 'fc' in k: continue
self_state_dict.update({k: v})
self.load_state_dict(self_state_dict)
def get_params(self):
wd_params, nowd_params = [], []
for name, module in self.named_modules():
if isinstance(module, (nn.Linear, nn.Conv2d)):
wd_params.append(module.weight)
if not module.bias is None:
nowd_params.append(module.bias)
elif isinstance(module, nn.modules.batchnorm._BatchNorm):
nowd_params += list(module.parameters())
return wd_params, nowd_params
if __name__ == "__main__":
net = Resnet18()
x = torch.randn(16, 3, 224, 224)
out = net(x)
print(out[0].size())
print(out[1].size())
print(out[2].size())
net.get_params()Optimizer:分割网络的训练方式
#!/usr/bin/python
# -*- encoding: utf-8 -*-
import torch
import logging
logger = logging.getLogger()
#分割模型的训练器,有poly策略在里面
class Optimizer(object):
def __init__(self,
model,
lr0,
momentum,
wd,
warmup_steps,
warmup_start_lr,
max_iter,
power,
it,
*args, **kwargs):
self.warmup_steps = warmup_steps
self.warmup_start_lr = warmup_start_lr
self.lr0 = lr0
self.lr = self.lr0
self.max_iter = float(max_iter)
self.power = power
self.it = it
wd_params, nowd_params, lr_mul_wd_params, lr_mul_nowd_params = model.get_params()
param_list = [
{'params': wd_params},
{'params': nowd_params, 'weight_decay': 0},
{'params': lr_mul_wd_params, 'lr_mul': True},
{'params': lr_mul_nowd_params, 'weight_decay': 0, 'lr_mul': True}]
#SGD训练方式,但是动量法
self.optim = torch.optim.SGD(
param_list,
lr = lr0,
momentum = momentum,
weight_decay = wd)
self.warmup_factor = (self.lr0/self.warmup_start_lr)**(1./self.warmup_steps)
def get_lr(self):
if self.it <= self.warmup_steps:
lr = self.warmup_start_lr*(self.warmup_factor**self.it)
else:
#poly策略(1 ? iter/max_iter )power.
factor = (1-(self.it-self.warmup_steps)/(self.max_iter-self.warmup_steps))**self.power
#(self.it-self.warmup_steps)=iter
#(self.max_iter-self.warmup_steps)=max_iter
lr = self.lr0 * factor
return lr
def step(self):
self.lr = self.get_lr()
for pg in self.optim.param_groups:
if pg.get('lr_mul', False):
pg['lr'] = self.lr * 10
else:
pg['lr'] = self.lr
if self.optim.defaults.get('lr_mul', False):
self.optim.defaults['lr'] = self.lr * 10
else:
self.optim.defaults['lr'] = self.lr
self.it += 1
self.optim.step()
if self.it == self.warmup_steps+2:
logger.info('==> warmup done, start to implement poly lr strategy')
def zero_grad(self):
self.optim.zero_grad()
train
#!/usr/bin/python
# -*- encoding: utf-8 -*-
from PIL import Image
import numpy as np
from torch.autograd import Variable
from FusionNet import FusionNet
from TaskFusion_dataset import Fusion_dataset#自己
import argparse
import datetime
import time
import logging
import os.path as osp
import os
from logger import setup_logger#自己
from model_TII import BiSeNet#自己
from cityscapes import CityScapes#自己
from loss import OhemCELoss, Fusionloss#自己
from optimizer import Optimizer#自己
import torch
from torch.utils.data import DataLoader
import warnings
warnings.filterwarnings('ignore')
def parse_args():
parse = argparse.ArgumentParser()
return parse.parse_args()
def RGB2YCrCb(input_im):
im_flat = input_im.transpose(1, 3).transpose(
1, 2).reshape(-1, 3) # (nhw,c)
R = im_flat[:, 0]
G = im_flat[:, 1]
B = im_flat[:, 2]
Y = 0.299 * R + 0.587 * G + 0.114 * B
Cr = (R - Y) * 0.713 + 0.5
Cb = (B - Y) * 0.564 + 0.5
Y = torch.unsqueeze(Y, 1)
Cr = torch.unsqueeze(Cr, 1)
Cb = torch.unsqueeze(Cb, 1)
temp = torch.cat((Y, Cr, Cb), dim=1).cuda()
out = (
temp.reshape(
list(input_im.size())[0],
list(input_im.size())[2],
list(input_im.size())[3],
3,
)
.transpose(1, 3)
.transpose(2, 3)
)
return out
def YCrCb2RGB(input_im):
im_flat = input_im.transpose(1, 3).transpose(1, 2).reshape(-1, 3)
mat = torch.tensor(
[[1.0, 1.0, 1.0], [1.403, -0.714, 0.0], [0.0, -0.344, 1.773]]
).cuda()
bias = torch.tensor([0.0 / 255, -0.5, -0.5]).cuda()
temp = (im_flat + bias).mm(mat).cuda()
out = (
temp.reshape(
list(input_im.size())[0],
list(input_im.size())[2],
list(input_im.size())[3],
3,
)
.transpose(1, 3)
.transpose(2, 3)
)
return out
#以上都是封装号的图片处理方式
#这分割主是优化,并不会调用train的各种loss,但融合却要计算分割的loss去优化参数,因为是联合训练
def train_seg(i=0, logger=None):
load_path = './model/Fusion/model_final.pth'
modelpth = './model'
Method = 'Fusion'
modelpth = os.path.join(modelpth, Method)
os.makedirs(modelpth, mode=0o777, exist_ok=True)
#以上与融合网络部分的参数使用一样
# if logger == None:
# logger = logging.getLogger()
# setup_logger(modelpth)
# dataset
n_classes = 9#9类
n_img_per_gpu = 16#批次大小为16
n_workers = 4#4子进程训练
cropsize = [640, 480]#图片大小
ds = CityScapes('./MSRS/', cropsize=cropsize, mode='train', Method=Method)
dl = DataLoader(#与融合网络的参数定义一样
ds,
batch_size=n_img_per_gpu,
shuffle=False,
num_workers=n_workers,
pin_memory=True,
drop_last=True,
)
# model
ignore_idx = 255#loss的时候算交叉熵函数
net = BiSeNet(n_classes=n_classes)#初始化分割网络
if i>0:#基于过去的参数训练模型
net.load_state_dict(torch.load(load_path))
net.cuda()
net.train()#训练模式
print('Load Pre-trained Segmentation Model:{}!'.format(load_path))
score_thres = 0.7#在loss做一个阈值
n_min = n_img_per_gpu * cropsize[0] * cropsize[1] // 16#loss中用整除640*480
#两个loss载入,图像分割损失函数OhemCELoss
criteria_p = OhemCELoss(
thresh=score_thres, n_min=n_min, ignore_lb=ignore_idx)
criteria_16 = OhemCELoss(
thresh=score_thres, n_min=n_min, ignore_lb=ignore_idx)
# optimizer,以下都是SGR的参数,训练方式是poly策略(1 ? iter/max_iter )power.
momentum = 0.9#动量?v=momentum*v-n梯度,W=W+v,可以维持一点原来的下降趋势,有惯性
weight_decay = 5e-4#衰减权重?L2范式的λ,防止过拟合
lr_start = 1e-2#初始学习率
max_iter = 80000#学习率跟新的幂
power = 0.9#学习率跟新的幂
warmup_steps = 1000#
warmup_start_lr = 1e-5#
it_start = i*20000
iter_nums=20000#训练q=20000论
#SGR训练方式,自己写的去看,但这里用到了动量,应该是动量法了,因为是内写的新训练方法,去看这个类
optim = Optimizer(
model=net,
lr0=lr_start,
momentum=momentum,
wd=weight_decay,
warmup_steps=warmup_steps,
warmup_start_lr=warmup_start_lr,
max_iter=max_iter,
power=power,
it=it_start,
)
#以上都是训练器的设置
# train loop
msg_iter = 10
loss_avg = []
st = glob_st = time.time()#开始时间
diter = iter(dl)#dataloador中取得迭代的数据集
epoch = 0#使epoch一开始为0
#开始分割训练,与融合唯一有关的就只有label与原图像,其余权重是不被影响的,训练200000轮
for it in range(iter_nums):#每个batch是67大小,一共16个batch
try:
im, lb, _ = next(diter)#lb就是取标签训练,
if not im.size()[0] == n_img_per_gpu:
raise StopIteration
except StopIteration:
epoch += 1
# sampler.set_epoch(epoch)
diter = iter(dl)
im, lb, _ = next(diter)
im = im.cuda()
lb = lb.cuda()
lb = torch.squeeze(lb, 1)#去掉张量维度为1且大小为1的维度
optim.zero_grad()#清除过去的梯度
out, mid = net(im)#得到forward结果,双结果,分别是8层的与16层的语义分割结果,没有上采样前的
#
lossp = criteria_p(out, lb)#主语义损失,lb目标
loss2 = criteria_16(mid, lb)#辅助语义损失,lb目标,可以题号mlou与pix acc
loss = lossp + 0.75 * loss2#语义损失,0,75可以加重loss2的
loss.backward()#计算梯度
optim.step()#梯度下降
loss_avg.append(loss.item())#在这个list中加入
# print training log message,打印到日志中去
if (it + 1) % msg_iter == 0:#每10个batch输出一次loss
loss_avg = sum(loss_avg) / len(loss_avg)#平均loss
lr = optim.lr
ed = time.time()#结束时间
#算时间的一下
t_intv, glob_t_intv = ed - st, ed - glob_st
eta = int(( max_iter - it) * (glob_t_intv / it))
eta = str(datetime.timedelta(seconds=eta))
#log信息
msg = ', '.join(
[
'it: {it}/{max_it}',
'lr: {lr:4f}',
'loss: {loss:.4f}',
'eta: {eta}',
'time: {time:.4f}',
]
).format(
it=it_start+it + 1, max_it= max_iter, lr=lr, loss=loss_avg, time=t_intv, eta=eta
)
#载入log
logger.info(msg)
#清空均值
loss_avg = []
#恢复时间
st = ed
# dump the final model,保存分割的权重,到日志里面
save_pth = osp.join(modelpth, 'model_final.pth')
net.cpu()
state = net.module.state_dict() if hasattr(net, 'module') else net.state_dict()
torch.save(state, save_pth)
logger.info(
'Segmentation Model Training done~, The Model is saved to: {}'.format(
save_pth)
)
logger.info('\n')
def train_fusion(num=0, logger=None):
# num: control the segmodel
lr_start = 0.001#用于Adam的
modelpth = './model'
Method = 'Fusion'
modelpth = os.path.join(modelpth, Method)
#初步载入模型,一个类的对象
fusionmodel = eval('FusionNet')(output=1)
#fusionmodel.cuda()#要gpu才能运行
fusionmodel.train()
# 优化方式为Adam,自动载入{'lr': 0.001, 'betas': (0.9, 0.999), 'eps': 1e-08, 'weight_decay': 0, 'amsgrad': False}
#optimizer:优化程序
optimizer = torch.optim.Adam(fusionmodel.parameters(), lr=lr_start)#将模型的参数输入到训练器中,应该这里做到了引用
# 如果num大于0,要载入模型,用于联合loss
if num>0:
n_classes = 9
segmodel = BiSeNet(n_classes=n_classes)#载入融合模型
save_pth = osp.join(modelpth, 'model_final.pth')#用上一次分割的权重作为初始权重
if logger == None:#又建立一个日志,如果没日志的话
logger = logging.getLogger()
setup_logger(modelpth)
segmodel.load_state_dict(torch.load(save_pth))#导入过往的权重
segmodel.cuda()
segmodel.eval()#切换到预测模式,有什么dropout的啥的
for p in segmodel.parameters():
p.requires_grad = False#将是否需要梯度都关了节省计算
print('Load Segmentation Model {} Sucessfully~'.format(save_pth))
train_dataset = Fusion_dataset('train')#取训练集到dataloader,训练模式
print("the training dataset is length:{}".format(train_dataset.length))
#这里就可以将所有的图片给载入号,batch的输入,还有是否要混乱什么的
train_loader = DataLoader(
dataset=train_dataset,#由torch.utils.data.Dataset的子类产生。
batch_size=8,
shuffle=True,
num_workers=4,
pin_memory=True,
drop_last=True,
#如果数据集大小不能被batch size整除,则设置为True后可删除最后一个不完整的batch。如果设为False并且数据集的大小不能被batch size整除,则最后一个batch将更小。(默认: False)
)
train_loader.n_iter = len(train_loader)#135为数据集合的长度,1080/8=135,分成了135个batch
# 这里开始初始化分割损失
if num>0:
score_thres = 0.7
ignore_idx = 255
n_min = 8 * 640 * 480 // 8
#下面是分割的两个loss
criteria_p = OhemCELoss(
thresh=score_thres, n_min=n_min, ignore_lb=ignore_idx)
criteria_16 = OhemCELoss(
thresh=score_thres, n_min=n_min, ignore_lb=ignore_idx)
criteria_fusion = Fusionloss()#标准融合损失
epoch = 10#为什么是10?10轮训练?
st = glob_st = time.time()#开始时间计时器
logger.info('Training Fusion Model start~')
#开始训练
for epo in range(0, epoch):
# print('\n| epo #%s begin...' % epo)
lr_start = 0.001#初始学习率
lr_decay = 0.75
lr_this_epo = lr_start * lr_decay ** (epo - 1)#lrs*lrd^(epo-1),学习率的变化方式
for param_group in optimizer.param_groups:
param_group['lr'] = lr_this_epo
#往复处理一个batch里面的训练集,怀疑loss在此模型与数据进行了连接
for it, (image_vis, image_ir, label, name) in enumerate(train_loader):
#如何知道返回的是什么呢?由dataset的__getitem函数完成,it为迭代次数
#去看自定义的数据集就行
#通过torch.utils.data.DataLoader,我们可以定义一个数据加载器,它是可迭代的,通过enumerate(DataLoader的返回)可以获得一个迭代器,逐步遍历批量数据。
fusionmodel.train()#防冻结参数
image_vis = Variable(image_vis).cuda()#用gpu去初始化rbg图片
image_vis_ycrcb = RGB2YCrCb(image_vis)#转为YCRCB
image_ir = Variable(image_ir).cuda()#红外图片
label = Variable(label).cuda()#分割标签的处理
logits = fusionmodel(image_vis_ycrcb, image_ir)#开始融合,具体与test相同无差别
fusion_ycrcb = torch.cat(
(logits, image_vis_ycrcb[:, 1:2, :, :],
image_vis_ycrcb[:, 2:, :, :]),
dim=1,
)#将每个图像变为彩色
fusion_image = YCrCb2RGB(fusion_ycrcb)
#实验证明以下处理对图像没有很大影响,就是保证没有很大的偏差而异,归一化
ones = torch.ones_like(fusion_image)
zeros = torch.zeros_like(fusion_image)
fusion_image = torch.where(fusion_image > ones, ones, fusion_image)
fusion_image = torch.where(
fusion_image < zeros, zeros, fusion_image)
#图像的处理以上,以下开始训练
lb = torch.squeeze(label, 1)#删除语义分割维度为1且大小为1的部分,什么情况出现呢?原来的label是1,3,。。。就删
optimizer.zero_grad()#0梯度下降,清零过去的参数数据,对模型进行操作
# seg loss 分割语义的loss训练,因为只有大于0才有分割结果
if num>0:
out, mid = segmodel(fusion_image)#融合后的图像输入,到segmodel
lossp = criteria_p(out, lb)#主语义损失
loss2 = criteria_16(mid, lb)#辅助语义损失
seg_loss = lossp + 0.1 * loss2#语义损失,0.1为超参数
# fusion loss,算出融合loss,criteria_fusion为标准融合损失,image_vis_ycrcb, image_ir为rgb与红外,label一开始没有的话就为0,
loss_fusion, loss_in, loss_grad = criteria_fusion(#看loss去,自动可以算梯度,存在fusionmodel.parameters()
image_vis_ycrcb, image_ir, label, logits,num
)
if num>0:#𝛽=num根据联合低、高适应性训练策略逐步增加。其实是M,但𝛽=r(m-1),这里r取1,所以就直接去m-1了
loss_total = loss_fusion + (num) * seg_loss#融合参数与分割参数同时进行
else:#非i为0时
loss_total = loss_fusion
loss_total.backward()#向后传播,算出梯度,但如何进去的?梯度存放在输入数据中?不,是放在model里面
optimizer.step()#步长的改变,adam模式更新参数,直接对model的参数做梯度下降
#以下都是算时间的了
ed = time.time()#结束时间计时
t_intv, glob_t_intv = ed - st, ed - glob_st#计算花了多少时间
#135(batch总数)*epo(轮数)+batch序数+1
now_it = train_loader.n_iter * epo + it + 1#应该是轮数还是什么的,it是数据的轮数。epo=1~10,n_iter=135
eta = int((train_loader.n_iter * epoch - now_it)
* (glob_t_intv / (now_it)))
eta = str(datetime.timedelta(seconds=eta))
#每次都输入到日志里面,每10轮给一次log
if now_it % 10 == 0:
if num>0:
loss_seg=seg_loss.item()
else:
loss_seg=0
#下面是将结果导入log中
msg = ', '.join(
[
'step: {it}/{max_it}',
'loss_total: {loss_total:.4f}',
'loss_in: {loss_in:.4f}',
'loss_grad: {loss_grad:.4f}',
'loss_seg: {loss_seg:.4f}',
'eta: {eta}',
'time: {time:.4f}',
]
).format(
it=now_it,
max_it=train_loader.n_iter * epoch,
loss_total=loss_total.item(),
loss_in=loss_in.item(),
loss_grad=loss_grad.item(),
loss_seg=loss_seg,
time=t_intv,
eta=eta,
)
logger.info(msg)
st = ed
#一下都是输出权重的事情了,以便于下一次训练,数据与程序分离
fusion_model_file = os.path.join(modelpth, 'fusion_model.pth')
torch.save(fusionmodel.state_dict(), fusion_model_file)#把权重存到这里
logger.info("Fusion Model Save to: {}".format(fusion_model_file))
logger.info('\n')
#一开始的arg只在下面有,与test一样的操作
def run_fusion(type='train'):
fusion_model_path = './model/Fusion/fusion_model.pth'
fused_dir = os.path.join('./MSRS/Fusion', type, 'MSRS')#保存的文件地址为#'./MSRS/Fusion'+train+‘msrs’
os.makedirs(fused_dir, mode=0o777, exist_ok=True)
fusionmodel = eval('FusionNet')(output=1)
fusionmodel.eval()
if args.gpu >= 0:#参数输入
fusionmodel.cuda(args.gpu)
fusionmodel.load_state_dict(torch.load(fusion_model_path))
print('done!')
test_dataset = Fusion_dataset(type)
test_loader = DataLoader(
dataset=test_dataset,
batch_size=args.batch_size,#参数输入
shuffle=False,
num_workers=args.num_workers,
pin_memory=True,
drop_last=False,
)
test_loader.n_iter = len(test_loader)
with torch.no_grad():
for it, (images_vis, images_ir, labels, name) in enumerate(test_loader):
images_vis = Variable(images_vis)
images_ir = Variable(images_ir)
labels = Variable(labels)
if args.gpu >= 0:
images_vis = images_vis.cuda(args.gpu)
images_ir = images_ir.cuda(args.gpu)
labels = labels.cuda(args.gpu)
images_vis_ycrcb = RGB2YCrCb(images_vis)
logits = fusionmodel(images_vis_ycrcb, images_ir)
fusion_ycrcb = torch.cat(
(logits, images_vis_ycrcb[:, 1:2, :,
:], images_vis_ycrcb[:, 2:, :, :]),
dim=1,
)
fusion_image = YCrCb2RGB(fusion_ycrcb)
ones = torch.ones_like(fusion_image)
zeros = torch.zeros_like(fusion_image)
fusion_image = torch.where(fusion_image > ones, ones, fusion_image)
fusion_image = torch.where(
fusion_image < zeros, zeros, fusion_image)
fused_image = fusion_image.cpu().numpy()
fused_image = fused_image.transpose((0, 2, 3, 1))
fused_image = (fused_image - np.min(fused_image)) / (
np.max(fused_image) - np.min(fused_image)
)
fused_image = np.uint8(255.0 * fused_image)
for k in range(len(name)):
image = fused_image[k, :, :, :]
image = image.squeeze()
image = Image.fromarray(image)
save_path = os.path.join(fused_dir, name[k])
image.save(save_path)
print('Fusion {0} Sucessfully!'.format(save_path))
if __name__ == "__main__":
parser = argparse.ArgumentParser(description='Train with pytorch')
parser.add_argument('--model_name', '-M', type=str, default='SeAFusion')
parser.add_argument('--batch_size', '-B', type=int, default=16)
parser.add_argument('--gpu', '-G', type=int, default=0)
parser.add_argument('--num_workers', '-j', type=int, default=8)
args = parser.parse_args()
# modelpth = './model'
# Method = 'Fusion'
# modelpth = os.path.join(modelpth, Method)
logpath='./logs'
logger = logging.getLogger()
setup_logger(logpath)#建立日志
for i in range(4):
train_fusion(i, logger) #融合训练,一开始是不用语义分割的,后面才联合训练
print("|{0} Train Fusion Model Sucessfully~!".format(i + 1))
run_fusion('train') #融合图像
print("|{0} Fusion Image Sucessfully~!".format(i + 1))
train_seg(i, logger)#分割训练
print("|{0} Train Segmentation Model Sucessfully~!".format(i + 1))
print("training Done!")