**### 2019-MobileNetV2
MobileNetV2: Inverted Residuals and Linear Bottlenecks
MobileNetV2: ���òв������ƿ��
- ����:Mark Sandler, Andrew Howard, Menglong Zhu, Andrey Zhmoginov, Liang-Chieh Chen
- ��λ:Google
ժҪ
�ڱ�����,������һ���µ��ƶ��˼ܹ�,MobileNetV2,��������ƶ���ģ���ڶ������ͻ������Լ��粻ͬģ�ͳߴ緶Χ�ڵ�������ܡ����������һ����ΪSSDLite���¿��,����Щ�ƶ�ģ��Ӧ���ڶ��������Ч����������,����ʾ�����ͨ��DeepLabv3�ļ���ʽ,��֮Ϊ�ƶ�DeepLabv3�������ƶ�����ָ�ģ�͡�
MobileNetV2�ǻ������òв�(inverted residual )�ṹ,�����������(shortcut connections)��խ��ƿ��(1x1)��֮�����м���չ��ʹ������������Ⱦ�����������Ϊ��������Դ������������,������,Ϊ�˱��־��д����Ե�����,ȥ��խ���еķ������Ǻ���Ҫ���������ʾ�������������,���ṩ�˵���������Ƶ�ֱ����
���,���ǵķ�������������/�������ת���ı����Խ���,��Ϊ��һ���ķ����ṩ��һ������Ŀ�ܡ�������ImageNet[1]���ࡢCOCOĿ����[2]��VOCͼ��ָ�[3]���ݼ��ϲ�����ģ�͵����ܡ������������ھ��Ⱥͳ˼�(multiply-adds, MAdd)��������֮���Ȩ��,�Լ�ʵ�ʵ��ӳٺͲ�������֮���Ȩ����
1 ���
�������Ѿ����ı��˻������ܵ���������,ʹ������ս�Ե�ͼ��ʶ���������˳������˵�ȷ�ԡ�Ȼ��,���ȷ�Ե�Ŭ��������Ҫ��������:�ִ��Ƚ�������Ҫ���������ƶ���Ƕ��ʽӦ������֮��ĸ�����Դ��
���Ľ�����һ��ר������ƶ�����Դ�����������Ƶ��µ�������ܹ������ǵ�����ͨ��������������IJ����������ڴ�,ͬʱ������ͬ��ȷ��,�ƶ����ƶ����Ƽ�����Ӿ�ģ�͵����Ƚ�ˮƽ��
���ǵ���Ҫ������һ���µIJ�ģ��:��������ƿ���ĵ��òв�����ģ�齫һ����άѹ����ʾ��Ϊ����,������չ����ά,��ʹ������������Ⱦ������й������������ͶӰ��һ���������Ծ����ĵ�ά��ʾ��ʽ���ٷ�ʵ�ֿ���Ϊ[4]��TensorFlow-Slimģ�Ϳ��һ���֡�
���ģ��������κ��ִ������ʹ�ñ�������Ч��ʵ��,��������ģ��ʹ�ñ����ڶ�����ܵ��ϻ������µ�״̬������,�������ģ���ر��������ƶ����,��Ϊ������ͨ���Ӳ���ȫʵ�ִ����м�����,�������������ڼ�������ڴ�ռ���������������Ƕ��ʽӲ������ж����ڴ���ʵ�����,��ЩӲ������ṩ�������dz�����������ƻ����ڴ档
2 ��ع���
��������ṹ�Դﵽȷ�Ժ�����֮������ƽ��һֱ��һ����Ծ���о��������������Ŷӽ��е��˹��ܹ�������ѵ���㷨�ĸĽ�,�������˶�������Ƶľ�Ľ�,��AlexNet[5],VGGNet[6],GoogLeNet[7]��ResNet[8]��������㷨�ܹ�̽������ȡ���˺ܶ��չ,�����������Ż�[9,10,11]����������������[12,13,14,15,16,17]������ѧϰ[18,19]�� Ҳ�д����Ĺ��������ڸı��ڲ�����������ӽṹ��ShuffleNet[20]������ϡ����[21]������[22]��
���,[23,24,25,26]������һ�����Ŵ��㷨��ǿ��ѧϰ���Ż���������ܹ��������·���Ȼ��,���е�һ��ȱ����,�ɴ˲������������ջ�dz����ӡ��ڱ�����,���Ŀ���Ƿ�չ���õĹ�����������β�����ֱ��,��ʹ������ָ����Ŀ��ܵ�������������ǵķ���Ӧ�ñ���Ϊ��[23]����ع����������ķ����Ļ��������ⷽ��,���ǵķ���������[20,22]����ȡ�ķ���,��������һ���������,ͬʱ����һ�����ڲ������С���������ǻ���MobileNetV1[27]�������������ļ���,����Ҫ�κ�����IJ�����,ͬʱ����������侫��,ʵ���˶��ƶ�Ӧ�õĶ���ͼ�����ͼ����������Ƚ�ˮƽ��
3 ǰ��������,���ۺ�ֱ��
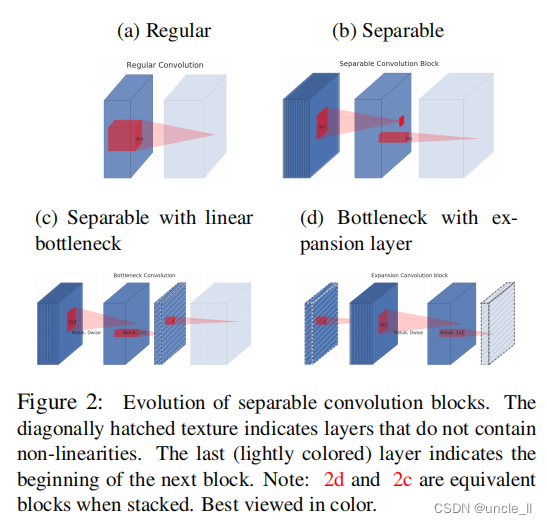
3.1 ��ȿɷ������|Depthwise Separable Convolutions
��ȿɷ�������������Ч��������ܹ�[27,28,20]�Ĺؼ���ɲ���,������Ŀǰ�Ĺ�����Ҳʹ�������ǡ�������˼������һ���ֽ�İ汾�滻һ�������ľ�������,���������ָ�����������IJ�����һ���Ϊ��Ⱦ���,��ͨ����ÿ������ͨ����Ӧ��һ�������˲�����ִ���������˲����ڶ�����һ��1��1�ľ���,��Ϊ������,������ͨ����������ͨ������������������µ�������
������ʹ��KaTeX parse error: Expected 'EOF', got '}' at position 12: h_ixw_jxd_i}? ���������� L i L_i Li?,������Ӧ�þ����� K �� R k �� k �� d i �� d j K��R^{k��k��d_i��d_j} K��Rk��k��di?��dj?������ h i �� w i �� d j h_i��w_i��d_j hi?��wi?��dj?ά��������� L j L_j Lj?����������ļ������Ϊ h i ? w i ? d i ? d j ? k ? k h_i?w_i?d_i?d_j?k?k hi??wi??di??dj??k?k��
��ȿɷ�������DZ����������������ݾ���,���ǵĹ���ԭ�������ͳ������һ����,����ɱ�:
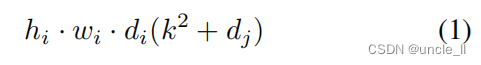
������Ⱦ�����1��1���������ܺ͡��봫ͳ�����,**��Ч����ȿɷ�����������˼��� k 2 k^2 k2���ļ�������**MobileNetV2ʹ����k=3(3��3��ȿɷ������),��˼���ɱ��DZ�������8��9��,�����Ƚ����н���[27]��
3.2 ����ƿ��|Linear Bottlenecks
����һ����n����ɵ����������,ÿ���㶼��һ�� h i x w i x d i h_ixw_ixd_i hi?xwi?xdi?ά���ļ����������ڱ�����,��������Щ���������Ļ�������,��������Ϊ���� d i d_i di?ά�� h i x w i h_ixw_i hi?xwi?�����ء�������������ʽ��,���������һ����ʵͼ��,����˵�ò㼤���(�����κβ� L i L_i Li?)�γ���һ��������Ȥ�����Ρ�����������,����һֱ��Ϊ�������е����ο���Ƕ�뵽��ά�ӿռ��С����仰˵,���鿴������������е�����dͨ������ʱ,����Щֵ�б������Ϣʵ����λ��ij��������,�ⷴ�����ֿ�Ƕ�뵽��ά�ӿռ��С�
էһ��,ʵ������ͨ���ؼ��ٲ��ά�������������,�Ӷ����Ͳ����ռ��ά�ȡ����ѱ�MobileNetV1[27]�ɹ�������,ͨ��һ�����ȳ���������Ч���ڼ���;���֮�����Ȩ��,���ѱ�������������[20]�ĸ�Чģ������С���������ֱ��,**���ȳ˷������������ͼ���ռ��ά��,ֱ������Ȥ�����ο�Խ�������ռ�Ϊֹ��**Ȼ��,�����뵽��Ⱦ���������ʵ���Ͼ���ÿ������ķ����Ա任ʱ(ReLU),����ֱ����ʧЧ������,��1ά�ռ��е�һ��Ӧ��ReLU�����һ��ray, ��
R
n
R^n
Rn�ռ���,ͨ�������һ������n���ؽڵķֶ��������ߡ�
��������,�����任ReLU(Bx)�Ľ�����з�������S,ӳ�䵽�ڲ�S�ĵ�ͨ��ͨ����������Ա任B���,��˱�����ȫά��������Ӧ������ռ��һ�������������Ա任�����仰˵,�������ֻ�������ķ���������־������Է������������� ���ǽ��ڲ�������н��и���ʽ��˵����
��һ����,��ReLU�ƻ���ͨ��ʱ,�����ɱ���ػᶪʧ��ͨ���е���Ϣ��Ȼ��,��������кܶ�ͨ��,�����ڼ�����������һ���ṹ,��ô��Ϣ������Ȼ������������ͨ���С��ڲ��������,֤��������������ο���Ƕ�뵽����ռ��������ά�ӿռ���,��ôReLU�任�ܱ�����Ϣ��ͬʱ,������ĸ��������뵽�ɱ���ĺ������С�
��֮,����ǿ������������,���DZ����˸���Ȥ������Ӧ��λ�ڸ�ά����ռ�ĵ�ά�ӿռ���:
- 1.�������Ȥ��������ReLUת���ַ������,�����Ӧ������ת��;
- 2.ֻ�е���������λ������ռ�ĵ�ά�ӿռ�ʱ,ReLU�ܹ���������������ε�������Ϣ;
����������Ϊ����Ϊ�Ż����е��ṹ�ṩ�˾�����ʾ:�������Ȥ�������ǵ�ά��,����ͨ���ھ������в�������ƿ������������һ����ʵ��֤�ݱ���,ʹ�����Բ���������Ҫ��,��Ϊ�����Է�ֹ�������ƻ�̫�����Ϣ���ڵ�6����,ͨ���������,��ƿ����ʹ�÷����Բ�ȷʵ��ʹ���ܽ��ͼ����ٷֵ�,��һ��֤ʵ�����ǵļ��衣����ע�[29]��Ҳ�����˷����Ե����Ʊ���,�����Ӵ�ͳ�в���������ȥ��������,�Ӷ������CIFAR���ݼ������ܡ�
���ڱ��ĵ����ಿ��,������ƿ�����������ǽ�������ƿ���Ĵ�С���ڲ���С֮��ı��ʳ�Ϊ��չ����(expansion ratio)��

ע:�����ǰ����ռ�����Ȥ���������Ƚϸ�,����ReLU,���ܻ��ü���ռ�̮��,���ɱ���Ļᶪʧ��Ϣ,����������������ʱ��,��Ҫ����������,����Ҫ�����ܽ�����ά����Ƶĵ�һЩ����ά������͵Ļ�,����任ReLU�������ܻ��˳��ܶ�������Ϣ��Ȼ�����Ǿ��뵽��,����ReLU����һ���־���һ������ӳ��,��ô�������ȫ�����Է�����,���Ͳ��ᶪʧһЩά����Ϣ,ͬʱ������Ƴ�ά�Ƚϵ͵IJ���?
������������������ʹ��Linear Bottleneck(����ʹ��ReLU����,�������Ա任)��������ԭ���ķ����Լ���任������,�Ż�����ܹ���˼��Ҳ������:ͨ���ھ���ģ���к����linear bottleneck��������Ȥ���Ρ�ʵ��֤��,ʹ��linear bottleneck ���Է�ֹ�������ƻ�̫����Ϣ��
��linear bottleneck ����Ⱦ���֮���ά�ȱȳ�ΪExpansion factor(��չϵ��),��ϵ������������block ��ͨ������
3.3 ���òв�| Inverted residuals
ƿ��ģ����в�ģ������,����ÿ��ģ�����һ������,Ȼ���Ǽ���ƿ��,Ȼ������չ[8]��Ȼ��,��ֱ��������,ƿ��ʵ���ϰ��������б�Ҫ����Ϣ,����չ��ֻ����Ϊһ�������������ķ����Ա任��ʵ��ϸ��,����ֱ����ƿ��֮��ʹ�ÿ��������
ͼ3�ṩ����Ʋ����ʾ��ͼ�������ݷ�ʽ�Ķ��������ھ���IJв�����:����ϣ������ݶ��ڳ�����֮�䴫����������Ȼ��,������Ƶ��ڴ�Ч��Ҫ�ߵö�(�����5��),���������ǵ�ʵ����Ч���Ժá�
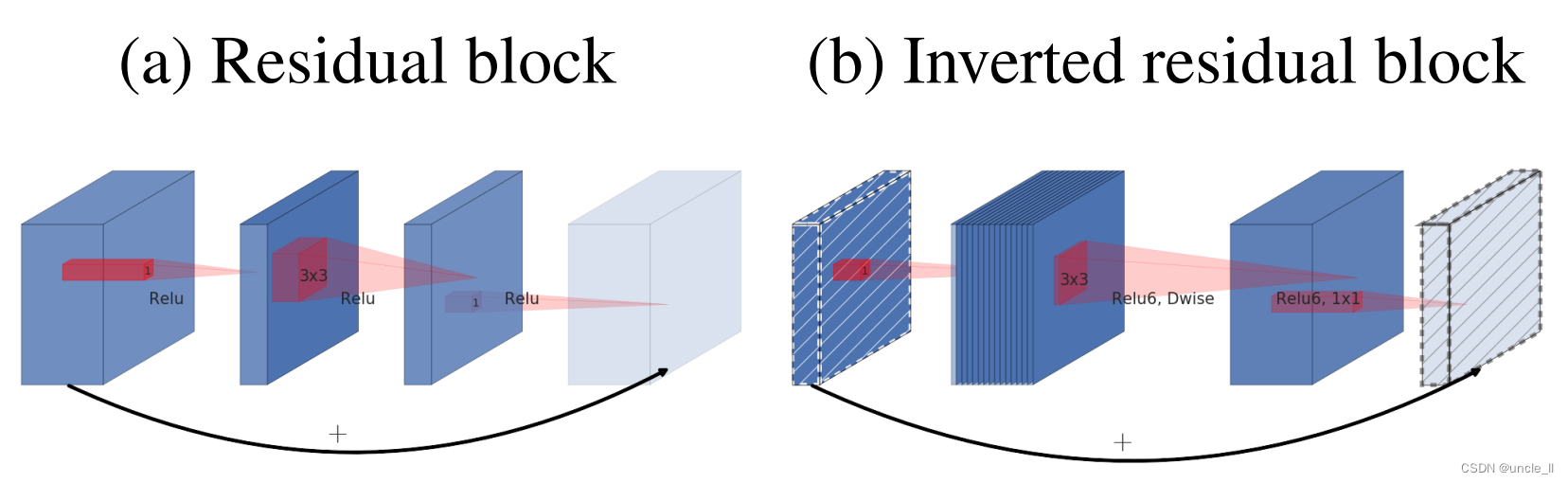
ͼ3:�в��[8,30]�͵��òв�֮��IJ��졣�Խ���Ӱ�߲㲻ʹ�÷���������ÿ����ĺ�������������������ͨ����ע������в�����ν�ͨ�������϶�IJ�����������(1x1 3x3 1x1),�����òв���������ƿ��(1x1 3x3depth 1x1)�����ͨ����ɫ����
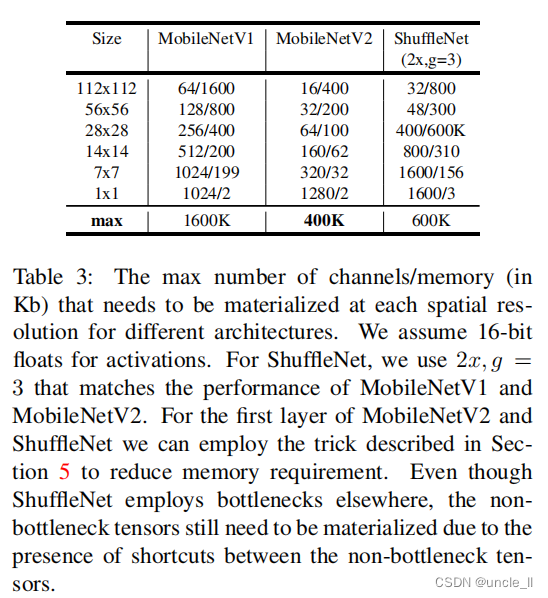
ƿ������������ʱ��Ͳ���������������ʵ�ֽṹ���1��ʾ,���ڴ�СΪ h �� w h��w h��w����չ���� t t t�;����˴�С k k k�Լ�KaTeX parse error: Expected group after '^' at position 2: d^?'ά������ͨ����KaTeX parse error: Expected group after '^' at position 2: d^?''���ͨ��,����ij˼Ӳ�����ΪKaTeX parse error: Expected group after '^' at position 6: h��w��d^?'��t��(d^'+k^2+d'������(1)���,�������ʽ��һ���������,��Ϊȷʵ��һ�������1��1����,�������ǵ�����ı�����������ʹ�ø�С����������ά�����ڱ�3��,�Ƚ���MobileNetV1��MobileNetV2��ShuffleNet֮���ÿ���ֱ�������ijߴ硣

MobileNet V2 ������ģ����ʽ,����ʽ����(��������,����������������ҳ��ͼ):
MobileNetV1 ������Ҫ˼�������ȿɷ���ľ����Ķѵ�����V2�����������,���dz��˼���ʹ����ȿɷ���(�м��Ǹ�)�ṹ֮��,��ʹ����Expansion layer ��Projection layer�����projection layer Ҳʹ��1*1 ������ṹ����ά�ռ�ӳ�䵽��ά�ռ�����,��Щʱ������Ҳ�����֮ΪBottleneck layer��
��Expansion layer �Ĺ��������෴,ʹ��1*1 ������ṹ,Ŀ���ǽ���ά�ռ�ӳ�䵽��ά�ռ䡣����Expansion ��һ����������ά����չ���������Ը���ʵ���������������,Ĭ����6,Ҳ������չ6����
��ͼҲ������ϸ��չʾ������ģ��Ľṹ������������24ά,������Ҳ��24ά�������������,������չ��6��,Ȼ��Ӧ����ȿɷ���������д����������������м���,��ͷխ,��һ���Ĵ��͡���ResNet��bottleneck residual block ����ͷ���м�խ,��MobileNet V2�������෴,��������MobileNet V2�г�Ϊinverted rediduals������,residual connection �������������IJ��ֽ������ӡ���linear bottleneck �����projection conv ����,���Dz���ʹ��ReLU���������ʹ�����Լ������
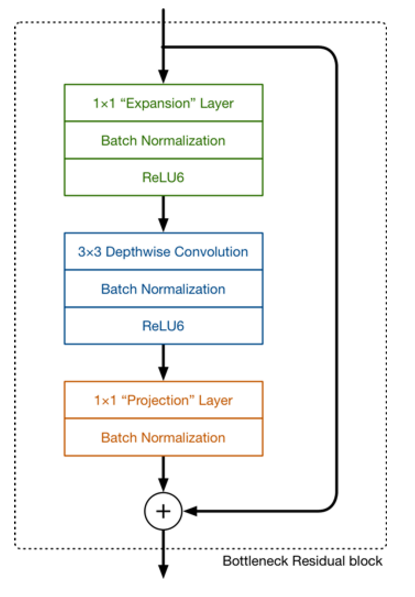
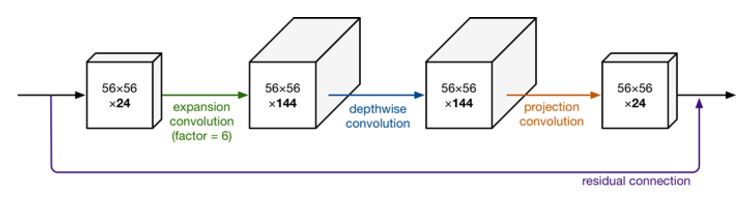
3.4 ��Ϣ������|Information flflow interpretation
���ǵ���ϵ�ṹ��һ����Ȥ��������,���ṩ�˹�����(ƿ����)������/�����Ͳ�ת��֮�����Ȼ���롪������һ��������ת��Ϊ����ķ����Ժ�����ǰ�߿��Կ�����������ÿһ�������,�����߿��Կ����DZ������������봫ͳ�ľ���ģ��(�����ǹ���Ļ��ǿɷ����)�γ��˶Ա�,���б�������������������һ�������������ȵĺ�����
�ر���,�����ǵ�������,���ڲ����Ϊ0ʱ,���ڿ������,���������Ǻ�Ⱥ�������չ����С��1ʱ,����һ������IJв����ģ��[8,30]������,�����ǵ�Ŀ�Ķ���,���DZ���������ʴ���1�������õġ�
���ֽ���ʹ�����ܹ�������ı����������������ֿ������о�,��������,��һ��̽�����ַ������б�Ҫ��,�Ա���õ�������������ԡ�
4 ģ�ͼܹ�
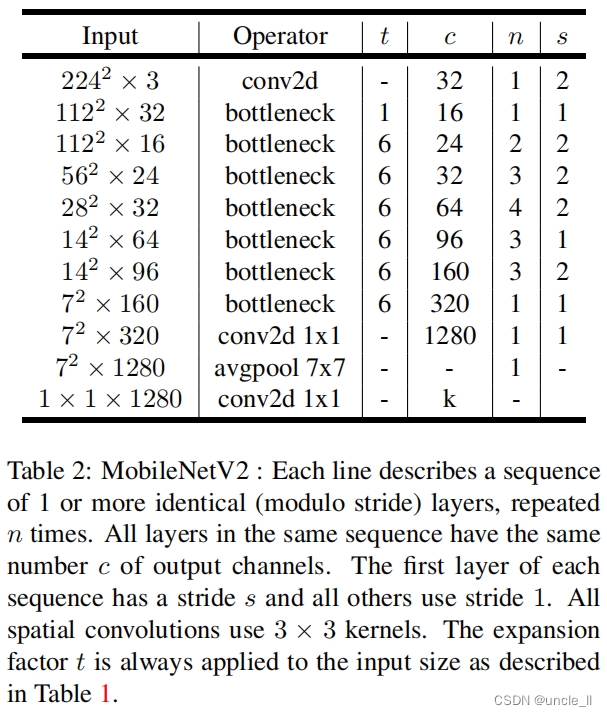
����,����ϸ���������ǵ���ϵ�ṹ������ǰһ�������۵�����,������������һ��ƿ����ȿɷ���IJв��������ģ�����ϸ�ṹ���1��ʾ��MobileNetV2�ļܹ�����32���˲����ij�ʼȫ������,Ȼ���DZ�2��������19���в�ƿ����,����t����չ��,c��block�����������channel��С,n��block���ظ�����,s��stride������ʹ��ReLU6��Ϊ������,��Ϊ���ڵ;��ȼ���ʱ����³����[27]������ʹ���ִ������еı��˳ߴ�3��3,����ѵ��������ʹ��dropout��Batch normalization��
4.1 ģ��ѡ��
����,չʾ������ȿɷ��������MobileNet�������ȫ������ģ����ȵĽ�����ڱ�4��,���Կ���,����ȫ�������,ʹ����ȿɷ��������ImageNet��ֻ�����1%��ȷ�ʵ�����ؽ�ʡ�˴�����mult-adds�����Ͳ�����������,չʾ**ʹ�ÿ��ȳ����Ľ���ģ�ͺ�ʹ�ý��ٲ�Ľ�dzģ�͵ıȽϽ����**Ϊ��ʹMobileNet��dz,ȥ���˱�1�������ߴ�Ϊ14��14��512��5��ɷ����˲�������5��ʾ,�����Ƶļ���Ͳ���������,ʹMobileNets���ݱ�ʹ���dzҪ��3%
���˵�һ��֮��,������������ʹ�ú㶨����չ������������ʵ����,����5��10֮�����չ�ʵ��¼�����ͬ����������,��С�������Խ�С����չ���ʸ���,���ϴ�������ڽϴ���չ����ʱ���������õ����ܡ�
���������е���Ҫʵ����,ʹ����������6Ӧ�������������Ĵ�С������,���ڲ���64ͨ����������������128ͨ��������ƿ����,�м���չ��Ϊ$64��6=384ͨ����
Ȩ�ⳬ������ ��[27]һ��,����ͨ��ʹ������ͼ��ֱ��ʺͿ��ȱ�����Ϊ�ɵ����������������ǵļܹ�����Ӧ��ͬ�����ܵ�,��Щ�������Ը��������ľ���/����Ȩ����е�������Ҫ����(���ȳ���1,224��224)�ļ���ɱ�Ϊ3�ڴγ˷�,��ʹ����340��������������о�������Ȩ��,����ֱ��ʴ�96��224,���ȳ�����0.35��1.4���������ɱ���Χ��7�γ˷����ӵ�585����γ˼Ӳ���,��ģ�ʹ�С��1.7M��������6.9M������֮��仯��
��[27]��һ��С��ʵ�ֲ�����,����С��1�ij���,���ǽ����ȳ���Ӧ���ڳ����һ����������������в㡣�������߸�Сģ�͵����ܡ�
5 ʵ��˵��
5.1 �ڴ���Ч�ƶ�
���õIJв�������ض����ڴ���Ч��ʵ��,������ƶ�Ӧ�÷dz���Ҫ��ʹ��TensorFlow[31]��Caffe[32]�ȱ���Ч���ƶ�ʵ��,������һ�����������㳬ͼG,�ɱ�ʾ����ıߺͱ�ʾ�м���������Ľڵ���ɡ�Ԥ��������Ϊ����С����Ҫ�洢���ڴ��е���������������һ��������,�����������к����ļ���˳�� �� ( G ) ��(G) ��(G),��ѡ����С����
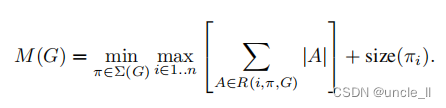
���� R ( i , �� , G ) R(i, \pi, G) R(i,��,G)�����ӵ��κ� �� i �� �� n \pi_{i}\dots \pi_{n} ��i?����n?�ڵ���м������б�, �O A �O |A| �OA�O��ʾ���� A A A�Ĵ�С, s i z e ( i ) size(i) size(i)�Dz��� i i i�ڼ��ڲ��洢��������ڴ�����
���ڽ�����ƽ�����нṹ(����в�����)��ͼ,ֻ��һ����ƽ���Ŀ��м���˳��,��˿��Լ���ͼG�ƶ�������ڴ������ͽ���:
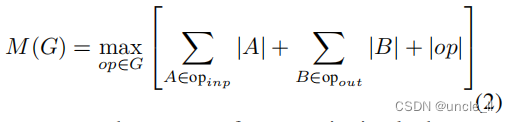
����,�ڴ���ֻ�����в����������������������ܴ�С����������,���ǽ�չʾ�����ƿ���в�ģ����Ϊ��һ����(�����ڲ�������Ϊһ��������),�����ڴ�������ƿ�������Ĵ�С����,������ƿ�����ڲ������Ĵ�С(����)��
ƿ���в�� ͼ3b����ʾ��F(x)���Ա�ʾΪ�������������� F ( x ) = [ A �� N �� B ] x F(x)=[A��N��B]x F(x)=[A��N��B]x,����AA�����Ա任 A : R s �� s �� k �� R s �� s �� n A:R^{s��s��k}��R^{s��s��n} A:Rs��s��k��Rs��s��n,N��һ�������Ե�ÿ��ͨ����ת��: N : R s �� s �� n �� R s �� �� s �� �� n , B ������������ת��: N:R^{s��s��n}��R^{s���s���n},B������������ת��: N:Rs��s��n��Rs����s����n,B������������ת��:B:R{s���s���n}��R{s���s���k��}$��
�������ǵ�����, N = R e L U 6 �� d w i s e �� R e L U 6 N=ReLU6 �� dwise �� ReLU6 N=ReLU6��dwise��ReLU6 ,������������κεİ�ͨ��ת��������������Ĵ�С�� �O x �O |x| �Ox�O���������Ĵ�С�� �O y �O |y| �Oy�O,��ô���� F ( X ) F(X) F(X) (X)������ڴ���Ե���$|s2k|+|s{��2}k��|+O(max(s2,s^{��2}))��
���㷨����������ʵ:�ڲ����� I \cal I I���Ա�ʾΪ t t t����������,ÿ����СΪ n / t n/t n/t,�����ǵĺ������Ա�ʾΪ
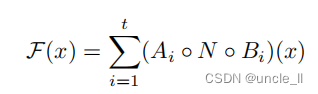
ͨ���ۼӺ�,����ֻ��Ҫ��һ����СΪ n / t n/t n/t���м��ʼ�ձ������ڴ��С�ʹ�� n = t n=t n=t,����ֻ��Ҫ�����м��ʾ�ĵ���ͨ����ʹ�����ܹ�ʹ����һ���ɵ�����Լ����(a)�ڲ��任(���������Ժ����)��ÿ��ͨ������ʵ,�Լ�(b)�����ķǰ�ͨ��������������������������С�ȡ����ڴ������ͳ��������,���ּ��ɲ�����������ĸ��ơ�
����ע�,ʹ��t·�ָ����F(X)����ij˼����������Ŀ�Ƕ�����t��,Ȼ��,�����е�ʵ����,���Ƿ����ü�����С�ľ���˷��滻һ������˷���������ʱ����,������������Ļ���δ���� �����Ƿ������ַ���������,t��2��5֮���һ��С�������������������ڴ�����,����Ȼ�����������ѧϰ����ṩ�ĸ߶��Ż��ľ���˷��;�����������õĴ�Ч�ʡ��������Ŀ�ܼ��Ż����ܵ��½�һ��������ʱ�Ľ�,����������д��۲졣
6 ʵ��
6.1 ͼ�����
ѵ������������ʹ��TensorFlow[31]��ѵ����ģ��,ʹ������RMSProp�Ż���,˥���Ͷ���������Ϊ0.9����ÿһ��֮��ʹ������һ��(batch normalization),��Ȩ��˥������Ϊ0.00004����MobileNetV1[27]������ͬ,ʹ�õij�ʼѧϰ��Ϊ0.045,ÿ��epoch��ѧϰ��˥����Ϊ0.98, ʹ��16��GPU�첽����worker,batch size����Ϊ96��
��������ǽ����ǵ�������MobileNetV1��ShuffleNet��NASNet-Aģ�ͽ����˱Ƚ�,ͳ���������4��ʾ,����������ͼ��ͼ5��ʾ
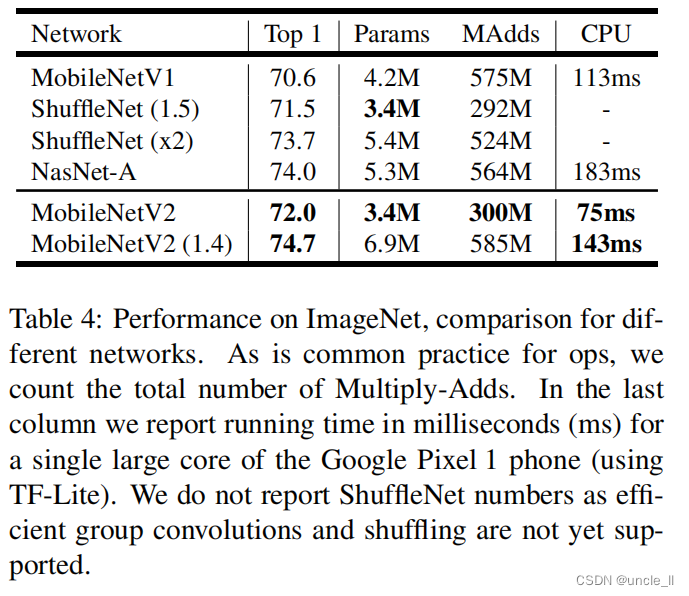
��4:�Ƚϲ�ͬ������ImageNet�ϵ����ܡ�����������ij�������һ��,����Multiply-Adds�������������һ����,������Google Pixel 1�ֻ��ϵ�һ�����ͺ���(ʹ��TF-Lite)������ʱ��,�Ժ���(ms)Ϊ��λ��û�б���ShuffleNet�Ľ��,��Ϊ��Ч��Ⱥ������ͻ�����δ֧�֡�
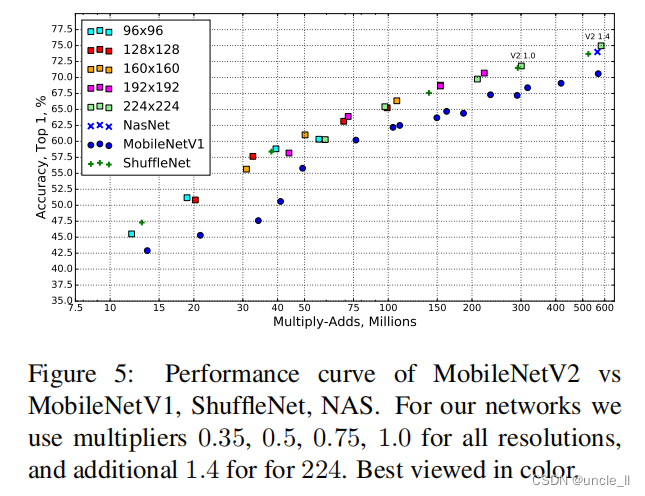
ͼ5:MobileNetV2��MobileNetV1,ShuffleNet,NAS���������ߡ��������ǵ�����,�����зֱ���ʹ�ó���0.35,0.5,0.75,1.0,���ڷֱ���Ϊ224,ʹ�ó���1.4��
6.2 Ŀ����
���ǻ���SSD�㷨(Single Shot Detector)[34]�ܹ������ͱȽ���MobileNetV2��MobileNetV1��ΪĿ����������ȡ��[33]������,ʹ�õ����ݼ���COCO���ݼ�[2]�����ǻ���YOLOv2[35]��ԭʼSSD(��VGG-16[6]Ϊbackbone)��Ϊ�����бȽϡ�����רע���ƶ�/ʵʱģ��,��˲�����Faster-RCNN[36]��RFCN[37]�������ܹ����бȽϡ�
SSDLite,�ڱ�����,���ǽ����˳���SSD���ƶ��Ѻ��ͱ��֡���SSDԤ������ÿɷ������(��Ⱦ������1��1 ������)�滻���г��������������Ʒ���MobileNets���������,�����ڼ�����Ч�ʸ��������ǽ����֮Ϊ�İ汾��SSDLite���볣��SSD���,SSDLite���������˲��������ͼ���ɱ�,���5��ʾ��
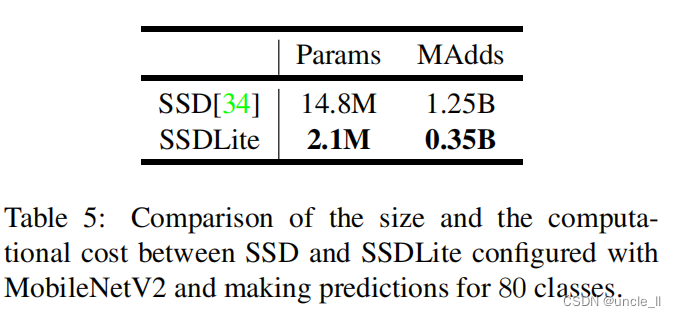
��5:ʹ��MobileNetV2���õ�SSDLite�ͳ���SSD֮��Ĵ�С�ͼ���ɱ���
����MobileNetV1,����[33]�е����ý��С�����MobileNetV2,SSDLite�ĵ�һ�㱻���ӵ���15����չ(�������Ϊ16)��SSDLite��ĵڶ������������������һ��Ķ���(�������Ϊ32)����������MobileNetV1һ��,��Ϊ���в㶼���ӵ���ͬ�������������ͼ�ϡ�
MobileNetģ�Ͷ������˿�ԴTensorFlowĿ����API��ѵ��������[38]�� ����ģ�͵�����ֱ���Ϊ320��320�������������Բ��Ƚ���mAP(COCO��ս������),����������Multiply-Adds������������6��ʾ��MobileNetV2 SSDLite���������Ч��ģ��,����Ҳ����������ȷ��ģ�͡�ֵ��ע�����,MobileNetV2 SSDLiteЧ�ʸ�20��,ģ��ҪС10��,��������COCO���ݼ��ϵ�YOLOv2��
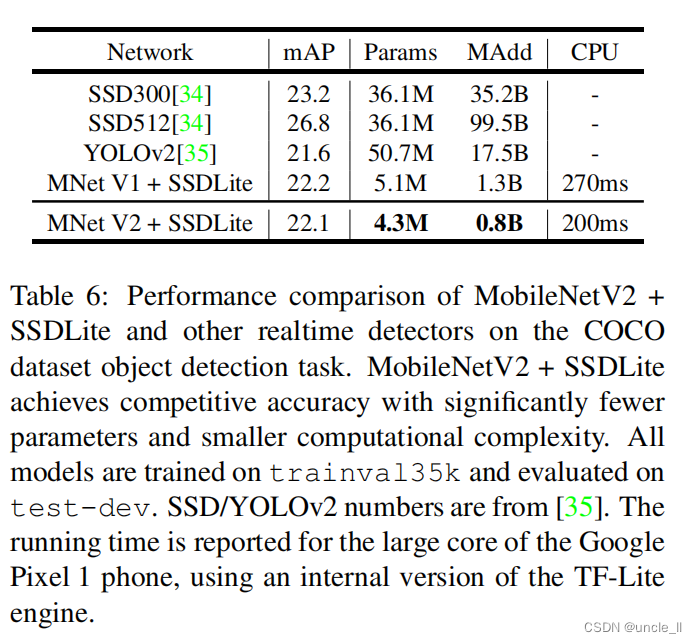
��6:MobileNetV2+SSDLite������ʵʱ�������COCO���ݼ�Ŀ���������е����ܱȽϡ�MobileNetV2+SSDLite�Ը��ٵIJ�����С�ļ��㸴����ʵ���˾��о������ľ���������ģ�Ͷ���trainval35k�Ͻ���ѵ��,����test-dev�Ͻ���������SSD/YOLOv2������������[35]��ʹ���ڲ��汾��TF-Lite����,����¼����Google Pixel 1�ֻ���CPU����������ʱ�䡣
6.3 ����ָ�
�ڱ�����,����ʹ��MobileNetV1��MobileNetV2������Ϊ������ȡ����DeepLabv3[39]���ƶ�����ָ������Ͻ��бȽ���DeepLabv3�����˿ն�����[40,41,42],����һ����ʽ���Ƽ�������ӳ��ֱ��ʵ�ǿ��,�����������ƽ��ͷ��,����(a)�����������в�ͬ�ն��ʵ� 3 �� 3 3��3 3��3������Atrous Spatial Pyramid Poolingģ��(ASPP)[43],(b)1��1����ͷ��,�Լ�(c)ͼ������[44]�����ڷֱ���,�������������ʾ����ͼ��ռ�ֱ�������������ֱ��ʵı�ֵ,�÷ֱ���ͨ���ʵ���Ӧ�ÿն���������������������ָ�,ͨ��ʹ�����stride=16��8����ȡ���ܼ�������ӳ������PASCAL VOC 2012���ݼ�[3]�Ͻ���ʵ��,ʹ��[45]�еĶ����עͼ�������ָ��mIOU��
Ϊ�˹����ƶ�ģ��,���dz�����������Ʊ���:(1)��ͬ��������ȡ��,(2)��DeepLabv3ͷ���Լӿ�����ٶ�,�Լ�(3)������ܵIJ�ͬ�ƶϲ���������ܽ��ڱ�7�С����Թ۲쵽:
- (a)������߶�������������ҷ�תͼ����ƶϲ������������˳˼Ӳ�������,��˲��ʺ������豸��Ӧ��
- (b)ʹ����������16��ʹ���������8����Ч��
- (c)MobileNetV1�Ѿ���һ��ǿ���������ȡ��,����ֻ��Ҫ��ResNet-101��Լ4.9-5.7����MAdd[8](����,mIOU:78.56 vs 82.70 �� MAdds:941.9B vs 4870.6B)
- (d)��MobileNetV2�ĵ����ڶ�������ӳ��Ķ�������DeepLabv3ͷ������ԭʼ�����һ������ӳ���ϸ���Ч,��Ϊ�����ڶ�������ӳ�����320��ͨ��������1280��ͨ��,�����Ϳ��Դﵽ���Ƶ�����,����Ҫ��MobileNetV1��ͨ����2.5��
- (e)DeepLabv3ͷ���ļ���ɱ��ܸ�,�Ƴ�ASPPģ�����������MAdd����ֻ�����������ܡ�
- �ڱ�7ĩβ,������һ���豸�ϵ�DZ�ں�ѡӦ��,��Ӧ�ÿ��Դﵽ75.32%mIOU����ֻ��Ҫ2.75B MAdds��
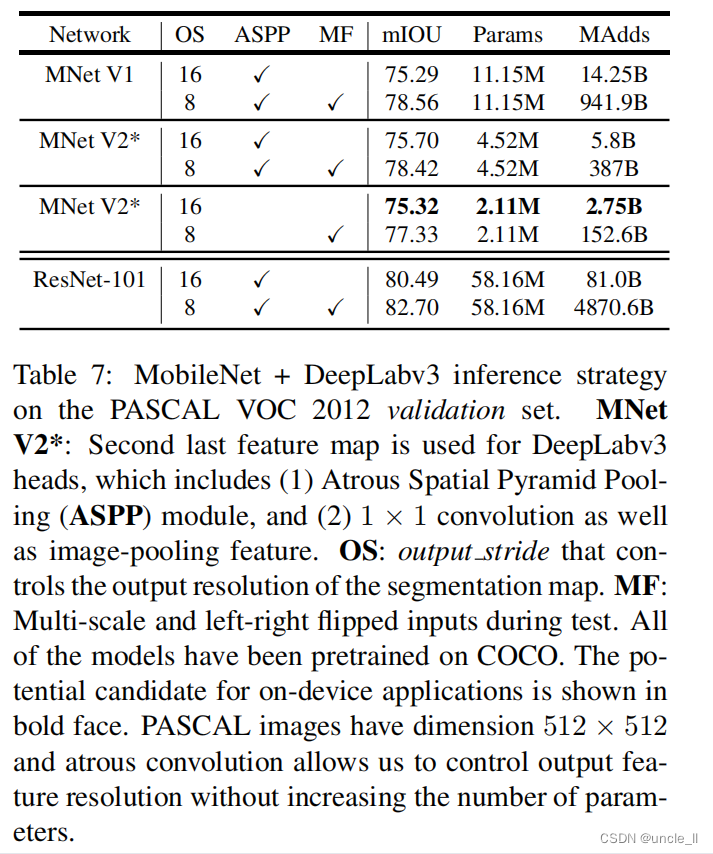
��7:PASCAL VOC 2012��֤���ϵ�MobileNet+DeepLabv3�ƶϲ��ԡ�MNet V2*:����DeepLabv3ͷ���ĵ����ڶ�������ӳ��,���а���(1)Atrous Spatial Pyramid Pooling(ASPP)ģ���(2)1��1�����Լ�ͼ��ػ����ܡ�OS:���Ʒָ�ӳ������ֱ��ʵ����������MF:�����ڼ��߶Ⱥ����ҷ�ת���롣���е�ģ�Ͷ���COCO�Ͻ���Ԥѵ�����豸�ϵ�DZ�ں�ѡӦ���Դ�����ʾ��PASCALͼ��ijߴ�Ϊ 512 x 512 512x512 512x512,���ն�����ʹ�����ǿ����ڲ����Ӳ�������������¿�����������ֱ��ʡ�

6.4 ����ʵ��
���òв��������в����ӵ���Ҫ���ѱ��㷺�о�[8,30,46]�����ı�����½��������ƿ���Ŀ��������������������չ��ĵĿ������(��μ�ͼ6b�Թ��Ƚ�)��
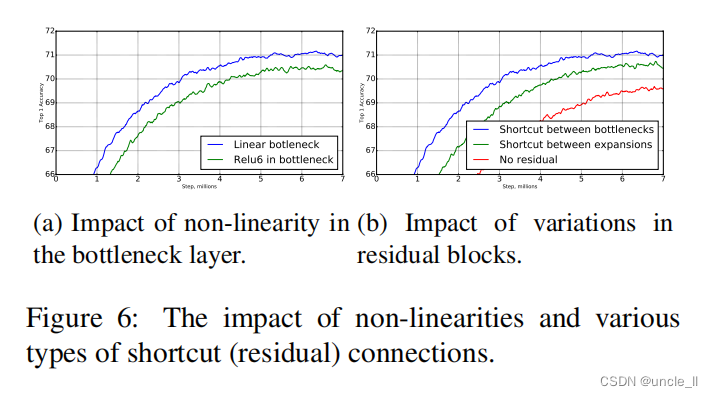
����ƿ������Ҫ�ԡ�����ƿ��ģ�͵��ϸ���˵�ȷ�����ģ��Ҫ��һЩ,��Ϊ�������ǿ���������״̬�½���,����ƫ������Ž����ʵ����ġ�Ȼ��,��ͼ6a��չʾ��ʵ�����,����ƿ������������,Ϊ�������ƻ���ά�ռ��е���Ϣ�ṩ��֧�֡�
7 �ܽἰ��������
����������һ���dz�������ܹ�,���������ǽ���һ����Ч���ƶ�ģ�ͼ��塣����Ļ������쵥Ԫ,�м�������,ʹ���ر��ʺ��ƶ�Ӧ�ó����������dz���Ч������,��������������������еı�������
����ImageNet���ݼ�,��������ļܹ��������������ܵ�����¼���ˮƽ������Ŀ��������,���ǵ������ھ��Ⱥ�ģ���Ӷȷ��涼����COCO���ݼ��ϵ�����ʵʱ�������ֵ��ע�����,����MobileNetV2�����ܹ���SSDLite���ģ�����YOLOv2,��������20��,������10����
������:������ľ�������ж��ص�����,���������������(����չ�����)��������(��ƿ���������)�ֿ���̽�������δ���о�����Ҫ����
�����
-
Olga Russakovsky, Jia Deng, Hao Su, Jonathan Krause, Sanjeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy, Aditya Khosla, Michael Bernstein, Alexander C. Berg, and Li Fei-Fei. Imagenet large scale visual recognition challenge. Int. J. Comput. Vision, 115(3):211�C252, December 2015.
-
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dolla?r, and C Lawrence Zitnick. Microsoft COCO: Common objects in context. In ECCV, 2014.
-
Mark Everingham, S. M. Ali Eslami, Luc Van Gool, Christopher K. I. Williams, John Winn, and Andrew Zisserma. The pascal visual object classes challenge a retrospective. IJCV, 2014.
-
Mobilenetv2 source code. Available from https://github.com/tensorflow/models/tree/master/research/slim/nets/mobilenet.
-
Alex Krizhevsky, Ilya Sutskever, and Geoffrey E. Hinton. Imagenet classification with deep convolutional neural networks. In Bartlett et al. [48], pages 1106�C1114.
-
Karen Simonyan and Andrew Zisserman. Very deep convolutional networks for large-scale image recognition. CoRR, abs/1409.1556, 2014.
-
Christian Szegedy, Wei Liu, Yangqing Jia, Pierre Sermanet, Scott E. Reed, Dragomir Anguelov, Dumitru Erhan, Vincent Vanhoucke, and Andrew Rabinovich. Going deeper with convolutions. In IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2015, Boston, MA, USA, June 7-12, 2015, pages 1�C9. IEEE Computer Society, 2015.
-
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. CoRR, abs/1512.03385, 2015.
-
James Bergstra and Yoshua Bengio. Random search for hyper-parameter optimization. Journal of Machine Learning Research, 13:281�C305, 2012.
-
Jasper Snoek, Hugo Larochelle, and Ryan P. Adams. Practical bayesian optimization of machine learning algorithms. In Bartlett et al. [48], pages 2960�C2968.
-
Jasper Snoek, Oren Rippel, Kevin Swersky, Ryan Kiros, Nadathur Satish, Narayanan Sundaram, Md. Mostofa Ali Patwary, Prabhat, and Ryan P. Adams. Scalable bayesian optimization using deep neural networks. In Francis R. Bach and David M. Blei, editors, Proceedings of the 32nd International Conference on Machine Learning, ICML 2015, Lille, France, 6-11 July 2015, volume 37 of JMLR Workshop and Conference Proceedings, pages 2171�C2180. JMLR.org, 2015.
-
Babak Hassibi and David G. Stork. Second order derivatives for network pruning: Optimal brain surgeon. In Stephen Jose Hanson, Jack D. Cowan, and C. Lee Giles, editors, Advances in Neural Information Processing Systems 5, [NIPS Conference, Denver, Colorado, USA, November 30 - December 3, 1992], pages 164�C171. Morgan Kaufmann, 1992.
-
Yann LeCun, John S. Denker, and Sara A. Solla. Optimal brain damage. In David S. Touretzky, editor, Advances in Neural Information Processing Systems 2, [NIPS Conference, Denver, Colorado, USA, November 27-30, 1989], pages 598�C605. Morgan Kaufmann, 1989.
-
Song Han, Jeff Pool, John Tran, and William J. Dally. Learning both weights and connections for efficient neural network. In Corinna Cortes, Neil D. Lawrence, Daniel D. Lee, Masashi Sugiyama, and Roman Garnett, editors, Advances in Neural Information Processing Systems 28: Annual Conference on Neural Information Processing Systems 2015, December 7-12, 2015, Montreal, Quebec, Canada, pages 1135�C1143, 2015.
-
Song Han, Jeff Pool, Sharan Narang, Huizi Mao, Shijian Tang, Erich Elsen, Bryan Catanzaro, John Tran, and William J. Dally. DSD: regularizing deep neural networks with dense-sparse-dense training flow. CoRR, abs/1607.04381, 2016.
-
Yiwen Guo, Anbang Yao, and Yurong Chen. Dynamic network surgery for efficient dnns. In Daniel D. Lee, Masashi Sugiyama, Ulrike von Luxburg, Isabelle Guyon, and Roman Garnett, editors, Advances in Neural Information Processing Systems 29: Annual Conference on Neural Information Processing Systems 2016, December 5-10, 2016, Barcelona, Spain, pages 1379�C1387, 2016.
-
Hao Li, Asim Kadav, Igor Durdanovic, Hanan Samet, and Hans Peter Graf. Pruning filters for efficient convnets. CoRR, abs/1608.08710, 2016.
-
Karim Ahmed and Lorenzo Torresani. Connectivity learning in multi-branch networks. CoRR, abs/1709.09582, 2017.
-
Tom Veniat and Ludovic Denoyer. Learning time-efficient deep architectures with budgeted super networks. CoRR, abs/1706.00046, 2017.
-
Xiangyu Zhang, Xinyu Zhou, Mengxiao Lin, and Jian Sun. Shufflenet: An extremely efficient convolutional neural network for mobile devices. CoRR, abs/1707.01083, 2017.
-
Soravit Changpinyo, Mark Sandler, and Andrey Zhmoginov. The power of sparsity in convolutional neural networks. CoRR, abs/1702.06257, 2017.
-
Min Wang, Baoyuan Liu, and Hassan Foroosh. Design of efficient convolutional layers using single intra-channel convolution, topological subdivisioning and spatial ��bottleneck�� structure. CoRR, abs/1608.04337, 2016.
-
Barret Zoph, Vijay Vasudevan, Jonathon Shlens, and Quoc V. Le. Learning transferable architectures for scalable image recognition. CoRR, abs/1707.07012, 2017.
-
Lingxi Xie and Alan L. Yuille. Genetic CNN. CoRR, abs/1703.01513, 2017.
-
Esteban Real, Sherry Moore, Andrew Selle, Saurabh Saxena, Yutaka Leon Suematsu, Jie Tan, Quoc V. Le, and Alexey Kurakin. Large-scale evolution of image classifiers. In Doina Precup and Yee Whye Teh, editors, Proceedings of the 34th International Conference on Machine Learning, ICML 2017, Sydney, NSW, Australia, 6-11 August 2017, volume 70 of Proceedings of Machine Learning Research, pages 2902�C2911. PMLR, 2017.
-
Barret Zoph and Quoc V. Le. Neural architecture search with reinforcement learning. CoRR, abs/1611.01578, 2016.
-
Andrew G. Howard, Menglong Zhu, Bo Chen, Dmitry Kalenichenko, Weijun Wang, Tobias Weyand, Marco Andreetto, and Hartwig Adam.
Mobilenets: Efficient convolutional neural networks for mobile vision applications. CoRR, abs/1704.04861, 2017. -
Francois Chollet. Xception: Deep learning with depthwise separable convolutions. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), July 2017.
-
Dongyoon Han, Jiwhan Kim, and Junmo Kim. Deep pyramidal residual networks. CoRR, abs/1610.02915, 2016.
-
Saining Xie, Ross B. Girshick, Piotr Dolla ?r, Zhuowen Tu, and Kaiming He. Aggregated residual transformations for deep neural networks. CoRR, abs/1611.05431, 2016.
-
Mart?n Abadi, Ashish Agarwal, Paul Barham, Eugene Brevdo, Zhifeng Chen, Craig Citro, Greg S. Corrado, Andy Davis, Jeffrey Dean, Matthieu Devin, Sanjay Ghemawat, Ian Goodfellow, Andrew Harp, Geoffrey Irving, Michael Isard, Yangqing Jia, Rafal Jozefowicz, Lukasz Kaiser, Manjunath Kudlur, Josh Levenberg, Dan Mane?, Rajat Monga, Sherry Moore, Derek Murray, Chris Olah, Mike Schuster, Jonathon Shlens, Benoit Steiner, Ilya Sutskever, Kunal Talwar, Paul Tucker, Vincent Vanhoucke, Vijay Vasudevan, Fernanda Vie?gas, Oriol Vinyals, Pete Warden, Martin Wattenberg, Martin Wicke, Yuan Yu, and Xiaoqiang Zheng. TensorFlow: Large-scale machine learning on heterogeneous systems, 2015. Software available from tensorflow.org.
-
Yangqing Jia, Evan Shelhamer, Jeff Donahue, Sergey Karayev, Jonathan Long, Ross Girshick, Sergio Guadarrama, and Trevor Darrell. Caffe: Convolutional architecture for fast feature embed- ding. arXiv preprint arXiv:1408.5093, 2014.
-
Jonathan Huang, Vivek Rathod, Chen Sun, Men- glong Zhu, Anoop Korattikara, Alireza Fathi, Ian Fischer, Zbigniew Wojna, Yang Song, Sergio Guadarrama, et al. Speed/accuracy trade-offs for modern convolutional object detectors. In CVPR, 2017.
-
Wei Liu, Dragomir Anguelov, Dumitru Erhan, Christian Szegedy, Scott Reed, Cheng-Yang Fu, and Alexander C Berg. Ssd: Single shot multibox detector. In ECCV, 2016.
-
Joseph Redmon and Ali Farhadi. Yolo9000: Better, faster, stronger. arXiv preprint arXiv:1612.08242, 2016.
-
Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun. Faster r-cnn: Towards real-time object detection with region proposal networks. In Advances in neural information processing systems, pages 91�C99, 2015.
-
Jifeng Dai, Yi Li, Kaiming He, and Jian Sun. R-fcn: Object detection via region-based fully convolutional networks. In Advances in neural information processing systems, pages 379�C387, 2016.
-
Jonathan Huang, Vivek Rathod, Derek Chow, Chen Sun, and Menglong Zhu. Tensorflow object detection api, 2017.
-
Liang-Chieh Chen, George Papandreou, Florian Schroff, and Hartwig Adam. Rethinking atrous convolution for semantic image segmentation. CoRR, abs/1706.05587, 2017.
-
Matthias Holschneider, Richard Kronland-Martinet, Jean Morlet, and Ph Tchamitchian. A real-time algorithm for signal analysis with the help of the wavelet transform. In Wavelets: Time-Frequency Methods and Phase Space, pages 289�C297. 1989.
-
Pierre Sermanet, David Eigen, Xiang Zhang, Michae?l Mathieu, Rob Fergus, and Yann LeCun. Overfeat: Integrated recognition, localization and detection using convolutional networks. arXiv:1312.6229, 2013.
-
George Papandreou,Iasonas Kokkinos, and Pierre Andre Savalle. Modeling local and global deformations in deep learning: Epitomic convolution, multiple instance learning, and sliding window detection. In CVPR, 2015.
-
Liang-Chieh Chen, George Papandreou, Iasonas Kokkinos, Kevin Murphy, and Alan L Yuille. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. TPAMI, 2017.
-
Wei Liu, Andrew Rabinovich, and Alexander C. Berg. Parsenet: Looking wider to see better. CoRR, abs/1506.04579, 2015.
-
Bharath Hariharan, Pablo Arbela?ez, Lubomir Bourdev, Subhransu Maji, and Jitendra Malik. Semantic contours from inverse detectors. In ICCV, 2011.
-
Christian Szegedy, Sergey Ioffe, and Vincent Vanhoucke. Inception-v4, inception-resnet and the impact of residual connections on learning. CoRR, abs/1602.07261, 2016.
-
Guido Montu?far, Razvan Pascanu, Kyunghyun Cho, and Yoshua Bengio. On the number of linear regions of deep neural networks. In Proceedings of the 27th International Conference on Neural Information Processing Systems, NIPS��14, pages 2924�C2932, Cambridge, MA, USA, 2014. MIT Press.
-
Peter L. Bartlett, Fernando C. N. Pereira, Christopher J. C. Burges, Le?on Bottou, and Kilian Q. Weinberger, editors. Advances in Neural Information Processing Systems 25: 26th Annual Conference on Neural Information Processing Systems 2012. Proceedings of a meeting held December 3-6, 2012, Lake Tahoe, Nevada, United States, 2012.
ʵ��
����torch1.8�汾ʵ��
import os
import sys
import numpy as np
import pandas as pd
from matplotlib import pyplot as plt
from typing import Any
import torch
import torch.nn as nn
import torch.nn.init as init
import torch.nn.functional as f
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader
import torchvision
# ���������
os.environ['CUDA_VISIABLE_DIVICES'] = '0, 1'
# ������
batch_size = 64
lr = 1e-4
num_works = 8
epochs = 100
from torchvision import transforms
from torchvision import datasets
image_size = 224
data_transform = transforms.Compose(
[transforms.Resize(image_size), transforms.ToTensor()]
)
# load data
train_data = datasets.CIFAR10(root='../', train=True, download=True, transform=data_transform)
test_data = datasets.CIFAR10(root='../', train=False, download=True, transform=data_transform)
# data loader
train_loader = DataLoader(train_data, batch_size=batch_size, shuffle=True, num_workers=num_works, drop_last=True)
test_loader = DataLoader(test_data, batch_size=batch_size, shuffle=True, num_workers=num_works, drop_last=False)
# show a picture
image, label = next(iter(train_loader))
print(image.shape, label.shape)
# plt.imshow(image[0][0], cmap='gray')
from collections import OrderedDict
# ��channel��Ϊ8��������
def _make_divisible(ch, divisor=8, min_ch=None):
if min_ch is None:
min_ch = divisor
new_ch = max(min_ch, int(ch + divisor / 2) // divisor * divisor)
# Make sure that round down does not go down by more than 10%.
if new_ch < 0.9 * ch:
new_ch += divisor
return new_ch
# �������ConvBN+ReLU
class baseConv(nn.Module):
def __init__(self, in_channels, output_channels, kernel_size, groups=1, stride=1):
super(baseConv, self).__init__()
pad = kernel_size // 2
relu = nn.ReLU6(inplace=True)
if kernel_size == 1 and in_channels > output_channels:
relu = nn.Identity()
self.baseConv = nn.Sequential(
nn.Conv2d(
in_channels=in_channels, out_channels=output_channels, kernel_size=kernel_size,
stride=stride, padding=pad, groups=groups, bias=False),
nn.BatchNorm2d(output_channels),
relu
)
def forward(self, x):
out = self.baseConv(x)
return out
# ����в�ṹ
class Residual(nn.Module):
def __init__(self, in_channels, expand_rate, out_channels, stride): # ��������channel��Ҫ������8��������
super(Residual, self).__init__()
expand_channel = int(expand_rate * in_channels) # �����channel
conv1 = baseConv(in_channels, expand_channel, 1, stride=stride)
if expand_rate == 1:
# ��ʱû��1*1������ά
conv1 = nn.Identity()
# channel 1
self.block1 = nn.Sequential(
conv1,
baseConv(expand_channel, expand_channel, 3, groups=expand_channel, stride=stride),
baseConv(expand_channel, out_channels, 1)
)
if stride == 1 and in_channels==out_channels:
self.has_res = True
else:
self.has_res = False
def forward(self,x):
if self.has_res:
return self.block1(x) + x
else:
return self.block1(x)
# ����mobilenetv2
class MobileNetV2(nn.Module):
def __init__(self, theta=1, num_classes=10, init_weight=True):
super(MobileNetV2, self).__init__()
#[inchannel,t,out_channel,stride]
net_config = [[32, 1, 16, 1],
[16, 6, 24, 2],
[24, 6, 32, 2],
[32, 6, 64, 2],
[64, 6, 96, 1],
[96, 6, 160, 2],
[160, 6, 320, 1]]
repeat_num = [1, 2, 3, 4, 3, 3, 1]
module_dic = OrderedDict()
module_dic.update({'first_Conv': baseConv(3, _make_divisible(theta*32), 3, stride=2)})
for idx, num in enumerate(repeat_num):
parse = net_config[idx]
for i in range(num):
module_dic.update({'bottleneck{}_{}'.format(idx,i+1): Residual(
_make_divisible(parse[0]*theta), parse[1], _make_divisible(parse[2]*theta), parse[3])})
parse[0] = parse[2]
parse[-1] = 1
module_dic.update({'follow_Conv': baseConv(
_make_divisible(theta*parse[-2]), _make_divisible(1280*theta), 1)})
module_dic.update({'avg_pool': nn.AdaptiveAvgPool2d(1)})
self.module = nn.Sequential(module_dic)
self.linear = nn.Sequential(
nn.Dropout(p=0.5),
nn.Linear(_make_divisible(theta*1280), num_classes)
)
#��ʼ��Ȩ��
if init_weight:
self.init_weight()
def init_weight(self):
for w in self.modules():
if isinstance(w, nn.Conv2d):
nn.init.kaiming_normal_(w.weight, mode='fan_out')
if w.bias is not None:
nn.init.zeros_(w.bias)
elif isinstance(w, nn.BatchNorm2d):
nn.init.ones_(w.weight)
nn.init.zeros_(w.bias)
elif isinstance(w, nn.Linear):
nn.init.normal_(w.weight, 0, 0.01)
nn.init.zeros_(w.bias)
def forward(self,x):
out = self.module(x)
out = out.view(out.size(0),-1)
out = self.linear(out)
return out
model = MobileNetV2().cuda()
from torch.utils.tensorboard import SummaryWriter
writer1 = SummaryWriter('./runs/loss')
writer2 = SummaryWriter('./runs/acc')
def train(epoch):
model.train()
train_loss = 0
for data, label in train_loader:
data, label = data.cuda(), label.cuda()
optimizer.zero_grad()
output = model(data)
loss = criterion(output, label)
loss.backward()
optimizer.step()
train_loss += loss.item() * data.size(0)
train_loss = train_loss / len(train_loader.dataset)
writer1.add_scalar('loss', train_loss, epoch)
print('Epoch: {} \tTraining Loss: {:.6f}'.format(epoch, train_loss))
def val(epoch):
# ��������״̬
model.eval()
val_loss = 0
gt_labels = []
pred_labels = []
# �������ݶ�
with torch.no_grad():
for data, label in test_loader:
data, label = data.cuda(), label.cuda()
output = model(data)
preds = torch.argmax(output, 1)
gt_labels.append(label.cpu().data.numpy())
pred_labels.append(preds.cpu().data.numpy())
loss = criterion(output, label)
val_loss += loss.item()*data.size(0)
# ������֤����ƽ����ʧ
val_loss = val_loss /len(test_loader.dataset)
writer1.add_scalar('loss', val_loss, epoch)
gt_labels, pred_labels = np.concatenate(gt_labels), np.concatenate(pred_labels)
# ����ȷ��
acc = np.sum(gt_labels ==pred_labels)/len(pred_labels)
writer2.add_scalar('acc', acc, epoch)
print('Epoch: {} \tValidation Loss: {:.6f}, Accuracy: {:6f}'.format(epoch, val_loss, acc))
for epoch in range(1, epochs):
train(epoch)
val(epoch)
writer1.close()
writer2.close()
Epoch: 1 Training Loss: 1.810957
Epoch: 1 Validation Loss: 1.719430, Accuracy: 0.362200
Epoch: 2 Training Loss: 1.676903
Epoch: 2 Validation Loss: 1.608585, Accuracy: 0.402700
Epoch: 3 Training Loss: 1.576324
Epoch: 3 Validation Loss: 1.531075, Accuracy: 0.435100
Epoch: 4 Training Loss: 1.493314
Epoch: 4 Validation Loss: 1.467211, Accuracy: 0.462900
Epoch: 5 Training Loss: 1.416125
Epoch: 5 Validation Loss: 1.421887, Accuracy: 0.479000
Epoch: 6 Training Loss: 1.350971
Epoch: 6 Validation Loss: 1.374000, Accuracy: 0.502500
Epoch: 7 Training Loss: 1.295407
Epoch: 7 Validation Loss: 1.332756, Accuracy: 0.515400
Epoch: 8 Training Loss: 1.239381
Epoch: 8 Validation Loss: 1.299337, Accuracy: 0.533700
Epoch: 9 Training Loss: 1.196423
Epoch: 9 Validation Loss: 1.281068, Accuracy: 0.542300
Epoch: 10 Training Loss: 1.146194
Epoch: 10 Validation Loss: 1.272490, Accuracy: 0.541300
Epoch: 11 Training Loss: 1.104716
Epoch: 11 Validation Loss: 1.239548, Accuracy: 0.550400
Epoch: 12 Training Loss: 1.060632
Epoch: 12 Validation Loss: 1.229520, Accuracy: 0.557300
Epoch: 13 Training Loss: 1.021109
Epoch: 13 Validation Loss: 1.230691, Accuracy: 0.561600
Epoch: 14 Training Loss: 0.978715
Epoch: 14 Validation Loss: 1.227288, Accuracy: 0.567700
Epoch: 15 Training Loss: 0.946122
Epoch: 15 Validation Loss: 1.227637, Accuracy: 0.569300
Epoch: 16 Training Loss: 0.914712
Epoch: 16 Validation Loss: 1.233961, Accuracy: 0.567700
Epoch: 17 Training Loss: 0.881835
Epoch: 17 Validation Loss: 1.236654, Accuracy: 0.573900
Epoch: 18 Training Loss: 0.853574
Epoch: 18 Validation Loss: 1.241994, Accuracy: 0.567400
Epoch: 19 Training Loss: 0.815818
Epoch: 19 Validation Loss: 1.240301, Accuracy: 0.578300
Epoch: 20 Training Loss: 0.795989
Epoch: 20 Validation Loss: 1.246372, Accuracy: 0.577600
Epoch: 21 Training Loss: 0.762715
Epoch: 21 Validation Loss: 1.245699, Accuracy: 0.579200
Epoch: 22 Training Loss: 0.735654
Epoch: 22 Validation Loss: 1.256266, Accuracy: 0.579300
Epoch: 23 Training Loss: 0.706454
Epoch: 23 Validation Loss: 1.264054, Accuracy: 0.588900
Epoch: 24 Training Loss: 0.688257
Epoch: 24 Validation Loss: 1.277016, Accuracy: 0.586300
Epoch: 25 Training Loss: 0.664483
Epoch: 25 Validation Loss: 1.301662, Accuracy: 0.581400
Epoch: 26 Training Loss: 0.644624
Epoch: 26 Validation Loss: 1.305807, Accuracy: 0.585400
Epoch: 27 Training Loss: 0.622638
Epoch: 27 Validation Loss: 1.320582, Accuracy: 0.584700
Epoch: 28 Training Loss: 0.601053
Epoch: 28 Validation Loss: 1.332019, Accuracy: 0.582500
Epoch: 29 Training Loss: 0.576634
Epoch: 29 Validation Loss: 1.346888, Accuracy: 0.584400
Epoch: 30 Training Loss: 0.563225
Epoch: 30 Validation Loss: 1.338611, Accuracy: 0.590500
Epoch: 31 Training Loss: 0.536210
Epoch: 31 Validation Loss: 1.396149, Accuracy: 0.586900
Epoch: 32 Training Loss: 0.526350
Epoch: 32 Validation Loss: 1.393504, Accuracy: 0.584400
Epoch: 33 Training Loss: 0.510057
Epoch: 33 Validation Loss: 1.412067, Accuracy: 0.587700
Epoch: 34 Training Loss: 0.492913
Epoch: 34 Validation Loss: 1.411729, Accuracy: 0.589900
Epoch: 35 Training Loss: 0.474919
Epoch: 35 Validation Loss: 1.455104, Accuracy: 0.589100
Epoch: 36 Training Loss: 0.461658
Epoch: 36 Validation Loss: 1.490079, Accuracy: 0.578600
Epoch: 37 Training Loss: 0.451400
Epoch: 37 Validation Loss: 1.521622, Accuracy: 0.585800
Epoch: 38 Training Loss: 0.434309
Epoch: 38 Validation Loss: 1.481987, Accuracy: 0.600300
Epoch: 39 Training Loss: 0.420812
Epoch: 39 Validation Loss: 1.512111, Accuracy: 0.594100
Epoch: 40 Training Loss: 0.408870
Epoch: 40 Validation Loss: 1.492593, Accuracy: 0.590200
Epoch: 41 Training Loss: 0.400788
Epoch: 41 Validation Loss: 1.523888, Accuracy: 0.594500
Epoch: 42 Training Loss: 0.386415
Epoch: 42 Validation Loss: 1.580727, Accuracy: 0.586000
Epoch: 43 Training Loss: 0.381696
Epoch: 43 Validation Loss: 1.554854, Accuracy: 0.592400
Epoch: 44 Training Loss: 0.367677
Epoch: 44 Validation Loss: 1.630810, Accuracy: 0.584900
Epoch: 45 Training Loss: 0.359994
Epoch: 45 Validation Loss: 1.601435, Accuracy: 0.588500
Epoch: 46 Training Loss: 0.344085
Epoch: 46 Validation Loss: 1.606170, Accuracy: 0.590800
Epoch: 47 Training Loss: 0.334941
Epoch: 47 Validation Loss: 1.626990, Accuracy: 0.594400
Epoch: 48 Training Loss: 0.327167
Epoch: 48 Validation Loss: 1.674634, Accuracy: 0.587800
Epoch: 49 Training Loss: 0.330610
Epoch: 49 Validation Loss: 1.636740, Accuracy: 0.593300
Epoch: 50 Training Loss: 0.313765
Epoch: 50 Validation Loss: 1.644818, Accuracy: 0.587400
Epoch: 51 Training Loss: 0.308049
Epoch: 51 Validation Loss: 1.666548, Accuracy: 0.591200
Epoch: 52 Training Loss: 0.292868
Epoch: 52 Validation Loss: 1.737115, Accuracy: 0.585000
Epoch: 53 Training Loss: 0.290087
Epoch: 53 Validation Loss: 1.723058, Accuracy: 0.591900
Epoch: 54 Training Loss: 0.283930
Epoch: 54 Validation Loss: 1.745838, Accuracy: 0.592300
Epoch: 55 Training Loss: 0.289035
Epoch: 55 Validation Loss: 1.746200, Accuracy: 0.591200
Epoch: 56 Training Loss: 0.274887
Epoch: 56 Validation Loss: 1.702432, Accuracy: 0.595100
Epoch: 57 Training Loss: 0.265010
Epoch: 57 Validation Loss: 1.791876, Accuracy: 0.592700
Epoch: 58 Training Loss: 0.256690
Epoch: 58 Validation Loss: 1.809799, Accuracy: 0.592200
Epoch: 59 Training Loss: 0.256642
Epoch: 59 Validation Loss: 1.809049, Accuracy: 0.596700
Epoch: 60 Training Loss: 0.256684
Epoch: 60 Validation Loss: 1.794926, Accuracy: 0.599500
Epoch: 61 Training Loss: 0.247338
Epoch: 61 Validation Loss: 1.804069, Accuracy: 0.588100
Epoch: 62 Training Loss: 0.244381
Epoch: 62 Validation Loss: 1.832358, Accuracy: 0.592800
Epoch: 63 Training Loss: 0.233596
Epoch: 63 Validation Loss: 1.829341, Accuracy: 0.598300
Epoch: 64 Training Loss: 0.233288
Epoch: 64 Validation Loss: 1.823511, Accuracy: 0.597300
Epoch: 65 Training Loss: 0.236817
Epoch: 65 Validation Loss: 1.848694, Accuracy: 0.596200
Epoch: 66 Training Loss: 0.220656
Epoch: 66 Validation Loss: 1.866383, Accuracy: 0.592700
Epoch: 67 Training Loss: 0.219230
Epoch: 67 Validation Loss: 1.835766, Accuracy: 0.592400
Epoch: 68 Training Loss: 0.216084
Epoch: 68 Validation Loss: 1.876546, Accuracy: 0.589100
Epoch: 69 Training Loss: 0.210298
Epoch: 69 Validation Loss: 1.879462, Accuracy: 0.602100
Epoch: 70 Training Loss: 0.197480
Epoch: 70 Validation Loss: 1.916892, Accuracy: 0.595500
Epoch: 71 Training Loss: 0.209614
Epoch: 71 Validation Loss: 1.877901, Accuracy: 0.601600
Epoch: 72 Training Loss: 0.201937
Epoch: 72 Validation Loss: 1.869245, Accuracy: 0.598300
Epoch: 73 Training Loss: 0.192207
Epoch: 73 Validation Loss: 1.929820, Accuracy: 0.600200
Epoch: 74 Training Loss: 0.193890
Epoch: 74 Validation Loss: 1.905469, Accuracy: 0.601000
Epoch: 75 Training Loss: 0.194677
Epoch: 75 Validation Loss: 1.901946, Accuracy: 0.607300
Epoch: 76 Training Loss: 0.184587
Epoch: 76 Validation Loss: 1.948870, Accuracy: 0.596900
Epoch: 77 Training Loss: 0.187412
Epoch: 77 Validation Loss: 1.941691, Accuracy: 0.603100
Epoch: 78 Training Loss: 0.189762
Epoch: 78 Validation Loss: 1.912730, Accuracy: 0.602300
Epoch: 79 Training Loss: 0.180055
Epoch: 79 Validation Loss: 1.962166, Accuracy: 0.600800
Epoch: 80 Training Loss: 0.180275
Epoch: 80 Validation Loss: 1.942520, Accuracy: 0.596300
Epoch: 81 Training Loss: 0.171043
Epoch: 81 Validation Loss: 1.949362, Accuracy: 0.600800
Epoch: 82 Training Loss: 0.175670
Epoch: 82 Validation Loss: 1.946251, Accuracy: 0.603200
Epoch: 83 Training Loss: 0.172893
Epoch: 83 Validation Loss: 1.928012, Accuracy: 0.599400
Epoch: 84 Training Loss: 0.154137
Epoch: 84 Validation Loss: 2.012115, Accuracy: 0.595800
Epoch: 85 Training Loss: 0.168310
Epoch: 85 Validation Loss: 2.000640, Accuracy: 0.598800
Epoch: 86 Training Loss: 0.162197
Epoch: 86 Validation Loss: 1.978441, Accuracy: 0.604100
Epoch: 87 Training Loss: 0.166564
Epoch: 87 Validation Loss: 1.963371, Accuracy: 0.605500
Epoch: 88 Training Loss: 0.155635
Epoch: 88 Validation Loss: 2.043188, Accuracy: 0.603600
Epoch: 89 Training Loss: 0.162715
Epoch: 89 Validation Loss: 1.977750, Accuracy: 0.601400
Epoch: 90 Training Loss: 0.152931
Epoch: 90 Validation Loss: 2.027132, Accuracy: 0.604000
Epoch: 91 Training Loss: 0.151899
Epoch: 91 Validation Loss: 2.042946, Accuracy: 0.600300
Epoch: 92 Training Loss: 0.147288
Epoch: 92 Validation Loss: 2.039895, Accuracy: 0.601500
Epoch: 93 Training Loss: 0.155015
Epoch: 93 Validation Loss: 2.001631, Accuracy: 0.604000
Epoch: 94 Training Loss: 0.149201
Epoch: 94 Validation Loss: 2.011332, Accuracy: 0.604600
Epoch: 95 Training Loss: 0.143354
Epoch: 95 Validation Loss: 2.041944, Accuracy: 0.606400
Epoch: 96 Training Loss: 0.142200
Epoch: 96 Validation Loss: 2.047203, Accuracy: 0.605500
Epoch: 97 Training Loss: 0.144368
Epoch: 97 Validation Loss: 2.013619, Accuracy: 0.605800
Epoch: 98 Training Loss: 0.139549
Epoch: 98 Validation Loss: 2.079411, Accuracy: 0.602600
Epoch: 99 Training Loss: 0.137218
Epoch: 99 Validation Loss: 2.061809, Accuracy: 0.602000
ȷ�ʴﵽƽ��,ԭ������Ǵ�ͷ��ʼѵ��,ѵ�����������Լ�ģ�ͽṹ���Ǻ�ƥ�䡣