������VJ��������㷨����һ�ֻ���Adaboost�������ķ������ü������Paul Viola��Michael Jones��2001��� Robust Real-Time Face Detection ������ڵ����Ӳ��������VJ�㷨���Դﵽÿ��15֡ͼ��Ĵ����ٶ�,��������⼼����չ��һ����̱�����Ȼ���ܸ����ڻ������ѧϰ�ķ���û����,���϶�Ҳ��ֵ��ȥ�ݶ��ġ�
VJ�㷨���û���ͼ���ٷ�������ȡͼ�����Harr����,Ȼ��ʹ��Adaboost�㷨ѵ���õ����ɸ�ǿ������,��ɼ����ṹ,�������ͱ����������ķ��ࡣ���ĵ������ֱ�Ϊ:����ͼ���ٷ���ȡ��Harr����,����Adaboost��ѧϰ�㷨,ʹ�ü����ķ�ʽ���ǿ�����������Ƿֿ�������
1. ����ͼ���ٷ���ȡ��Harr����
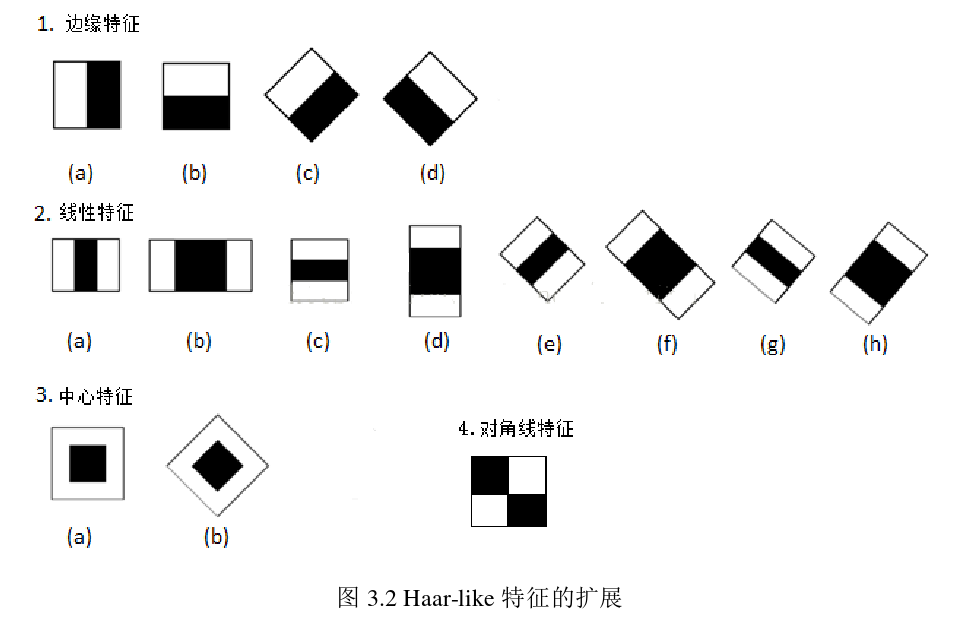

��Harr��������һ�־�������ģ��,�������䲶ͼ��ı�Ե���仯����Ϣ����������������ź��������Ŷ��ص����Ⱥͱ�Ե��Ϣ,�ܷ�����Harr�������ص㡣���ڶ����Harr����ģ����,Viola��Jonesѡȡ���ĸ�������ȡ��Ե����,���������Լ��Խ���������ģ�塣
��Harr����ֵ�����²����õ�:����Harr����ģ�����ͼ����֮��,�ð�ɫ���������ǵ�ͼ�����غͼ�ȥ��ɫ����������ͼ���е����غ�,����������ģ����,��Ժ�ɫ��������֮�ͳ���2,����Ϊ�˵����ڰ���������������������Ӱ�졣ͨ���ı���Haar����ģ���λ�ü���С,�����ڼ�ⴰ����ٳ����������**,��˼�������

??����Harr����ֵ�ļ�����̿��Կ���,�����漰�˴����������������,Ϊ�˸������ȡͼ�����Harr����,����ʹ����һ�ֳ�Ϊ����ͼ(Integral Image)�ķ�����������һ��ͼ��,������(x, y)���Ļ���ͼ���Զ���Ϊ:
I
(
x
,
y
)
=
��
x
��
��
x
��
y
��
��
y
f
(
x
��
,
y
��
)
I(x, y) = \sum_{x^{\prime} \leq x} \sum_{y^{\prime} \leq y} f\left(x^{\prime}, y^{\prime}\right)
I(x,y)=��x����x?��y����y?f(x��,y��)
����ȡ��Harr����֮ǰ,���ȼ��������ͼ��Ļ���ͼ����ô����ȡ����ʱ,ͼ�о���ABCD�����غͿ������û���ͼ��ʾ����:
S
a
b
c
d
=
I
(
D
)
?
I
(
B
)
?
I
(
C
)
+
I
(
A
)
S_{a b c d}=I(D)-I(B)-I(C)+I(A)
Sabcd?=I(D)?I(B)?I(C)+I(A)
����ͼ���ٷ��������������
2. Adaboostѧϰ�㷨
�ᵽ�˴�����Harr����ֵ֮��,��ʹ��Adaboost�㷨������ѵ����
����Adaboost�ĺ����Ƽ�:���AdaBoostԭ��, ������ֻ��¼�ؼ���ɡ�
Boosting��һ�ֽ�����������������γ�ǿ���������㷨��ܡ����֡�������Ƥ���������������˼·�������ۻ����ġ�
Boosting ����������˼��,ÿһ����ѧϰ���ص��עǰһ��ѵ��������ĵط�����ѵ��,ͨ����ȨͶƱ�ķ�ʽ,�ó�Ԥ������Boostingѧϰ�Ǵ��е�,��ѧϰ����ѧϰ���Ⱥ�˳��
��Adaboost�����е�һ��,������exponential loss function(��ʵ������ָ����Ȩ��),���ݲ�ͬ��loss function�������������㷨,����L2Boosting, logitboost��
2.1 Boosting
Boosting��ܹ�����ͼ:
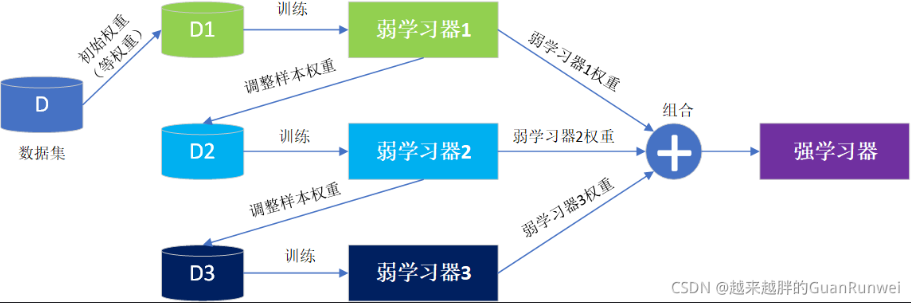
��Boosting�ĵ���ʽѵ��ʱ,ÿ��ѵ�������ij�ʼȨֵ����ͬ��,ѵ���и�����ѧϰ������������ѧϰ����Ȩ��,������������Ȩ�����ı������ķֲ�,ʹ��ǰ��ѧϰ���ѷֵ������ں���ѵ���еõ�����Ĺ�ע,ѭ���ù���,ֱ����ѧϰ������Ŀ�ﵽָ������(��һ������)�����ս�������ѧϰ��������ϼ�Ȩ,�õ����ɵ�ǿѧϰ����
��������:
һ����ⴰ�а�����������Harr����,���ڼ�ⴰx�еĵ�j������ֵ,����ѵ
��һ������ʽ��ʾ����������:
h
j
(
x
)
=
{
1
?���?
p
j
f
j
(
x
)
<
p
j
��
j
0
?����?
h_{j}(x)=\left\{\begin{array}{ll} 1 & \text { ��� } p_{j} f_{j}(x)<p_{j} \theta_{j} \\ 0 & \text { ���� } \end{array}\right.
hj?(x)={10??���?pj?fj?(x)<pj?��j??����??
����
f
j
(
x
)
f_{j}(x)
fj?(x)��ʾ��ⴰ��j������ֵ,
��
\theta
����ʾ��ֵ,p��ʾ���Ⱥŷ���,ѵ�������������ڵ�ǰ�ض������ֲ���,ȷ��
f
j
(
x
)
f_{j}(x)
fj?(x)��һ����ֵ,ʹ
h
j
(
x
)
h_{j}(x)
hj?(x)�ķ�������ʽ�����͡�
2.2 Adaboost(Adaptive Boosting)���㷨����
-
��ʼ��ѵ��������Ȩֵ�ֲ� D 1 D_{1} D1?��������N��ѵ����������,��ÿһ��ѵ�������ʼʱ,���ᱻ������ͬ��Ȩֵ: W 1 = 1 / N W_{1} = 1/N W1?=1/N��
-
(a) ѡȡһ����ǰ�������͵��������� h ��Ϊ�� t ������������ H t H_{t} Ht? , �� ������������ h t : X �� { ? 1 , 1 } h_{t}: X \rightarrow\{-1,1\} ht?:X��{?1,1}, �����������ڷֲ� D t D_{t} Dt? �ϵ����Ϊ:
e t = P ( H t ( x i ) �� y i ) = �� i = 1 N w t i I ( H t ( x i ) �� y i ) e_{t}=P\left(H_{t}\left(x_{i}\right) \neq y_{i}\right)=\sum_{i=1}^{N} w_{t i} I\left(H_{t}\left(x_{i}\right) \neq y_{i}\right) et?=P(Ht?(xi?)��=yi?)=��i=1N?wti?I(Ht?(xi?)��=yi?)��ô������ʽ�ӿ�֪, H f ( x ) H_{\mathrm{f}}(x) Hf?(x) ��ѵ�����ݼ��ϵ������ e w e_{\mathrm{w}} ew? ���DZ� H r ( x ) H_{\mathrm{r}}(x) Hr?(x) ����� ������Ȩֵ֮�͡�
(b) ����ÿ���������������շ������е�Ȩ�� (��������Ȩ���� �� \alpha �� ��ʾ):
�� t = 1 2 ln ? ( 1 ? e t e t ) \alpha_{t}=\frac{1}{2} \ln \left(\frac{1-e_{t}}{e_{t}}\right) ��t?=21?ln(et?1?et??)
��Ȼ,���ԽС,Ȩ��Խ��,����һ��ָ��������������Ȩֵ����ʽ��
(c) ����ѵ��������Ȩֵ�ֲ� D r + 1 D_{\mathrm{r}+1} Dr+1? :
D t + 1 ( x ) = D t ( x ) Z t �� { exp ? ( ? �� t ) , ?if? h t ( x ) = f ( x ) exp ? ( �� t ) , ?if? h t ( x ) �� f ( x ) = D t ( x ) exp ? ( ? �� t f ( x ) h t ( x ) ) Z t \begin{array}{l} \mathcal{D}_{t+1}(\boldsymbol{x})=\frac{\mathcal{D}_{t}(\boldsymbol{x})}{Z_{t}} \times\left\{\begin{array}{ll} \exp \left(-\alpha_{t}\right), & \text { if } h_{t}(\boldsymbol{x})=f(\boldsymbol{x}) \\ \exp \left(\alpha_{t}\right), & \text { if } h_{t}(\boldsymbol{x}) \neq f(\boldsymbol{x}) \end{array}\right.\\ =\frac{\mathcal{D}_{t}(\boldsymbol{x}) \exp \left(-\alpha_{t} f(\boldsymbol{x}) h_{t}(\boldsymbol{x})\right)}{Z_{t}} \end{array} Dt+1?(x)=Zt?Dt?(x)?��{exp(?��t?),exp(��t?),??if?ht?(x)=f(x)?if?ht?(x)��=f(x)?=Zt?Dt?(x)exp(?��t?f(x)ht?(x))??
���� �� t \alpha_{t} ��t? Ϊ����������Ȩ��, Z t Z_{t} Zt? Ϊ��һ������ ,��ȷ��D��һ���ֲ�, Z t = 2 e t ( 1 ? e t ) Z_{t}=2 \sqrt{e_{t}\left(1-e_{t}\right)} Zt?=2et?(1?et?)?
���Կ���,ѵ������Ȩֵ�ĸ�����Ȼ��ʹ��ָ����������ʽ,��Ϊ���0-1��ʧ����ָ�������и��õ���ѧ���ʡ� -
���, ����������Ȩ�� �� t \alpha_{t} ��t? ��ϸ�����������, ��
f ( x ) = �� i = 1 T �� i H t ( x ) f(x)=\sum_{i=1}^{T} \alpha_{i} H_{t}(x) f(x)=��i=1T?��i?Ht?(x)ͨ�����ź��� sign ? \operatorname{sign} sign ������, �õ�һ��ǿ������Ϊ:
H f i n a l = sig ? n ( f ( x ) ) = sign ? ( �� t = 1 T �� t H t ( x ) ) H_{f i n a l}=\operatorname{sig} n(f(x))=\operatorname{sign}\left(\sum_{t=1}^{T} \alpha_{t} H_{t}(x)\right) Hfinal?=sign(f(x))=sign(��t=1T?��t?Ht?(x))
�ڶ����е�ѵ������Ȩ�ظ���Դͷ�ǻ��������e��,���Կ����Ƶ���ֱ��ʹ��e����ѵ������Ȩֵ�Ĺ�ʽ:
�����������, Ȩֵ���� :
D
t
+
1
(
x
)
=
D
t
(
x
)
2
e
t
D_{t+1}(x)=\frac{D_{t}(x)}{2 e_{t}}
Dt+1?(x)=2et?Dt?(x)?
��ȷ��������, Ȩֵ���� :
D
t
+
1
(
x
)
=
D
t
(
x
)
2
(
1
?
e
t
)
D_{t+1}(x)=\frac{D_{t}(x)}{2\left(1-e_{t}\right)}
Dt+1?(x)=2(1?et?)Dt?(x)?
3. ǿ�������ļ���
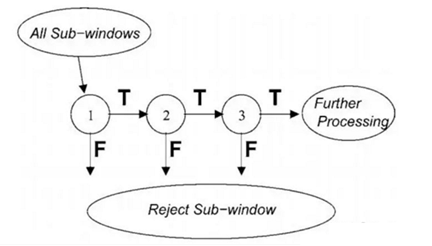
��VJ�����������,���յķ������������ɸ�Adaboostǿ�������������ɡ��ڼ����ṹ������ǰ���ǿ��������һЩ���ܹ������������������������������,�����ɿ��ٹ��˵��ַ��沿����,���ں����ǿ����������Խ��Խ����,�Լ���Ӵ���Ҫ��Խ��Խ�ϸ�,�����жϽ��ѱ�ʶ������
VJ�����������ǿ��������ɵ����ṹʾ��ͼ:
���ڿ�VJ�������Ǻܲ��,���ù�������̱�ʽ��,�����¼һ�¡�