2019论文:BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
BERT:用于语言理解的深度双向变换器的预训练
论文地址:https://arxiv.org/abs/1810.04805

1.BERT概述
BERT 是 Transformers 双向编码器表示的缩写,是一种用于自然语言处理的机器学习 (ML) 模型。它由 Google AI Language 的研究人员于 2018 年开发,是 11 种以上最常见语言任务的瑞士军刀解决方案,例如情感分析和命名实体识别。
从历史上看,计算机很难“理解”语言。当然,计算机可以收集、存储和读取文本输入,但它们缺乏基本的语言上下文。
因此,出现了自然语言处理 (NLP):人工智能领域,旨在让计算机从文本和口语中读取、分析、解释和获取含义。这种做法结合了语言学、统计学和机器学习,以帮助计算机“理解”人类语言。
传统上,单个 NLP 任务是通过为每个特定任务创建的单个模型来解决的。也就是说,直到―― BERT!
BERT 是一种深度双向、无监督的语言表示,使用纯文本语料库进行预训练。
2.BERT可以做什么?
BERT 可用于多种语言任务:
- 可以确定电影评论的正面或负面程度。(情绪分析)
- 帮助聊天机器人回答您的问题。(问题回答)
- 在编写电子邮件 (Gmail) 时预测您的文本。(文字预测)
- 只需几句输入,就可以写一篇关于任何主题的文章。(文本生成)
- 可以快速总结长的法律合同。(总结)
- 可以根据周围的文本区分具有多种含义的单词(例如“银行”)。(多义解析)
NLP 支持翻译、语音助手(Alexa、Siri 等)、聊天机器人、谷歌搜索、语音 GPS 等。?
3.BERT的原理
BERT 使用了 Transformer,下图是流行的transformer模型发布时间
这是一种学习文本中单词(或子词)之间上下文关系的注意力机制。在其普通形式中,Transformer 包括两个独立的机制――一个读取文本输入的编码器和一个为任务生成预测的解码器。由于 BERT 的目标是生成语言模型,因此只需要编码器机制。换句话说,BERT 将单词转换为数字。这个过程很重要,因为机器学习模型使用数字而不是单词作为输入。这使您可以在文本数据上训练机器学习模型。(BERT 模型用于转换文本数据,然后与其他类型的数据一起用于在 ML 模型中进行预测。)
下图是 Transformer 编码器的高级描述。输入是一系列标记,它们首先嵌入到向量中,然后在神经网络中进行处理。输出是一个大小为 H 的向量序列,其中每个向量对应一个具有相同索引的输入标记。
在训练语言模型时,定义预测目标是一个挑战。许多模型预测序列中的下一个单词(例如“孩子从___回家”),这种定向方法本质上限制了上下文学习。为了克服这一挑战,BERT 使用了两种训练策略:Masked LM,Next Sentence Prediction.
4.Masked LM(MLM)
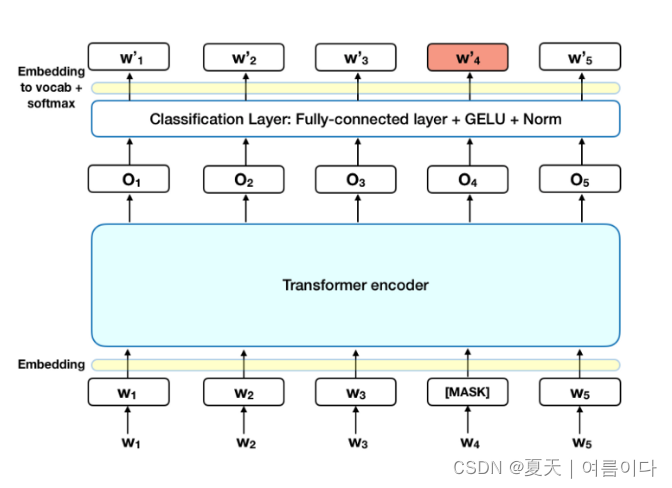
在将单词序列输入 BERT 之前,每个序列中 15% 的单词被替换为 [MASK] 标记。然后,该模型尝试根据序列中其他非掩码单词提供的上下文来预测掩码单词的原始值。,输出词的预测需要:
- 在编码器输出之上添加一个分类层。
- 将输出向量乘以嵌入矩阵,将它们转换为词汇维度。
- 用 softmax 计算词汇表中每个单词的概率
?
BERT 损失函数只考虑了对掩码值的预测,而忽略了对非掩码词的预测。因此,该模型的收敛速度比定向模型慢,这一特征被其增强的上下文感知所抵消。
注意:在深度学习框架中,BERT 的实现并不和论文一样,并没有取代所有 15% 的掩码词。
5.Next Sentence Prediction(NSP)
在 BERT 训练过程中,模型接收成对的句子作为输入,并学习预测该对中的第二个句子是否是原始文档中的后续句子。在训练期间,50% 的输入是一对,其中第二个句子是原始文档中的后续句子,而在另外 50% 的输入中,从语料库中随机选择一个句子作为第二个句子。假设是随机句子将与第一句断开连接。
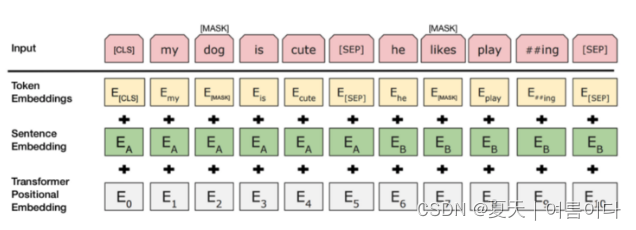
为了帮助模型在训练中区分两个句子,输入在进入模型之前按如下方式处理:
在第一句的开头插入一个 [CLS] 标记,在每个句子的结尾插入一个 [SEP] 标记。
将指示句子 A 或句子 B 的句子嵌入添加到每个标记中。句子嵌入在概念上类似于词汇表为 2 的标记嵌入。
位置嵌入被添加到每个标记以指示其在序列中的位置。Transformer 论文中介绍了位置嵌入的概念和实现。
为了预测第二个句子是否确实与第一个句子相关,执行以下步骤:
- 整个输入序列通过 Transformer 模型。
- 使用简单的分类层(权重和偏差的学习矩阵)将 [CLS] 标记的输出转换为 2×1 形状的向量。
- 用 softmax 计算 IsNextSequence 的概率。
在训练 BERT 模型时,Masked LM 和 Next Sentence Prediction 一起训练,目标是最小化这两种策略的组合损失函数。
BERT的输入表示由三个嵌入值的总和组成,如图上图所示。
token嵌入
Token Embeddings使用词片嵌入。Word Piece嵌入频繁出现,并将最长的子词组合成一个单元。
换句话说,一个频繁出现的词(子词)本身就成为一个单元,而一个频繁出现的词(稀有词)被分解成更小的子词。这可以通过将所有不常用的单词视为词汇表外(OOV)来解决先前降低建模性能的问题。每个接收到的句子的开头都会给出一个[CLS]?token?(特殊分类token) ,这个[CLS]?token经过模型的所有层后具有token序列的组合含义。如果在这里附加一个简单的分类器,可以对单个句子或一系列句子进行分类。
段嵌入
Segment Embeddings将划分为标记的单词再次转换为单个句子。通过创建一个掩码来分隔每个句子,该掩码在第一个[SEP] 令牌之前的值为0?,在[SEP]令牌之前的值为1 ,包括[SEP]令牌。
位置嵌入
Position Embeddings对标记的顺序进行编码。原因是?BERT使用了transformer的encoder ,而Transformer使用了Self-Attention模型。Self-Attention不考虑输入的位置,所以需要给出输入token的位置。因此,在 Transformer 中,使用了使用sigsoid函数的位置编码,BERT将其转换为使用Position Encodings?。每个标记添加所有上述嵌入,并将其用作BERT的输入向量。
6.BERT 模型大小和架构
?也可以看成

?
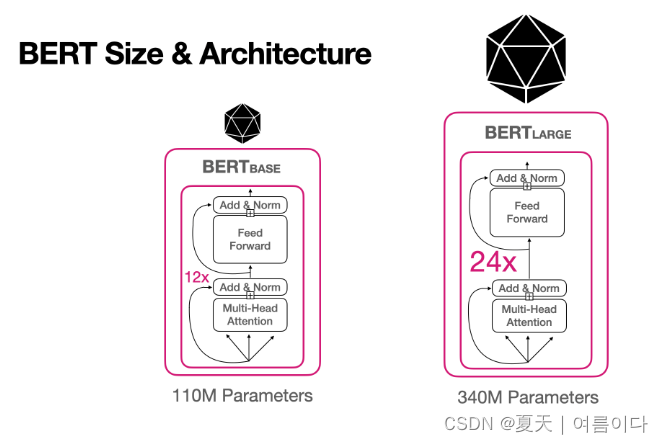
BERT有两种模型,base和large?,取决于架构的大小。
L = 变压器块
H =??隐藏层维数
A = self-attention的数量
它被定义为
基于BERT 的模型的超参数是L?= 12、H?= 768、A?= 12 和
BERT-large模型是L?= 24,?H?= 1024,?A?= 16
并使用区分大小写(cases)
您可以在将它们转换为全小写(uncased)后使用它们。
?7.BERT的使用
环境:win10,pytorch,pycharm
环境安装
pip install transformers
?使用代码
from transformers import pipeline
unmasker = pipeline('fill-mask', model='bert-base-uncased')
unmasker("Artificial Intelligence [MASK] take over the world.")参考文献
【1】02) ??(Bidirectional Encoder Representations from Transformers, BERT) - ? ??? ??? ??? ?? ??
【2】https://towardsdatascience.com/bert-explained-state-of-the-art-language-model-for-nlp-f8b21a9b6270
【3】?BERT 101 - State Of The Art NLP Model Explained
【4】BERT Basics: What It Is, Creation, and Uses in AI?
【5】图解 BERT - 知乎?