ǰ��
����д��һƪ���͡�22�°�����ʱ,�ж����������������۵�:��july����,����BERT��ͨ���������?��,�ҵ�ʱ���������ſ�����ʦ��BERT����,����û̫���⡣
ֱ����������,ˢ��CSDN��һƪ��BERT������,�ų�һ�Ķ���,�Ҷ�����֮��,�ٶ����dz�ѧ��,��������
����BERT�ıʼ�,��ʵһ����ǰ����д��,�ٳ�û���ʵ�ԭ���ǹ������Ѿ��кܶ��������,�����������Jay Alammar��һƪͼ��Transformer:The Illustrated Transformer,�ٱ�������ſ�����ʦ����ƪ��˵˵NLP�е�Ԥѵ��������չʷ:��Word Embedding��Bertģ������
���Ļ����Ͽ�����Ϊ�Ƕ��⼸ƪ�������ڵ�ѧϰ�ʼ�(��ͼҲ�����϶�������ĩ�IJο�����),����ƪ�ʼ������û���κ�NLPģ�ͱ������Ŀ���/��ѧ����д,�������κ�û�н��͵ĸ����Ϊ��ѧ�ߵ���,������֮ǰ,�ܶ������㿴����������ȥ,������֮��,����1/3ֵ�ÿ��������㶼���ö���������ȥ,���ĵ�Ŀ��֮һ�ʹﵽ��!
�Ͼ����ҹ۲�,���Ϲ���Transformer/BERT������������������⼸�����:
- �Ծ������������ֽ�������,����Χ��������ƪ��The Illustrated Transformer��,��Ȼ,�еķ��IJ��� �����dz,�еĻ������е���������ͨ˳/����(�ؼ��Ķ���������,һ�뵽��ѧ�ڼ䲻С�Ŀ��˺ܶ��÷����IT�����,�Ͷ���,Ȱ����˵�˻�,û��ˮƽ����),��Ȼ,�����Ѽ��ڸ�����ȥ�����
- ��BERTԭʼ���������ֽ����,�еĺų�һ�Ķ���BERT,���������о������ڿ������������������,���¿ɶ���ȡ����Google�����ˮƽ
- ���Լ����Խ���transformer��BERT��,����Щ�����и��Զ�����ȱ����,��������ˮƽ̧�ù���,���߾����Ե�����Ϊ���뵱Ȼ,���¸��ֱ���֪ʶ�����ָ�����������ĺ���
��д���ʹ�2010.10.11�����Ѿ�����11����,��11�껹��д���ܶ�ͨ�����ıʼ�,����svm xgboost cnn rnn lstm��Щ,�պ��ܽ�һ�°�����дͨ�ķ���,Ҳ���ǶԱ������ĵ�ָ��˼��:
- ��Ϊ��/����һ��Ҫ����,������������,û������û�пɶ���,ͨ�������ӿɶ���
- ���DZ���֪ʶ�ý���,��Ҫ�뵱Ȼ?��Ҫ����Ϊ����ʲô����,���Լ�������� �������Ǵ���,���Լ������� �ö��߱���� ������Ĵ���
- ��¥������?��100������100��,�����ֶϲ�,һ���ֶϲ�,�ʼǾͲ�������,���Ա�������ͷ��ʼд:NNLM?��?Word2Vec?��?Seq2Seq?��?Seq2Seq?with?Attention?��?Transformer?��?Elmo?��?GPT?��?BERT(�Ӳ�����Ū��������Щģ��,����������5�����켴2.5��,�����˱���,��Ӳ���������Щģ��,����ֻ��Ҫ5����Сʱ��2.5h,���DZ��ĵ�Ŀ��֮��)
- ��ʽ��չ��������չ��,��ϧ�����,ʮ����ͺù�һ������Ϊ��
- ����ͼ�������,��ʱһͼʤǧ��,��ʱһ���õ�����?���Ա���������ȥ
?��Ȼ?���涼����,����ս�Բ������һ�仰:�ó�ѧ��˼ά����ÿһ��ÿһ����
�����һֱ�ڿ���ѧ��ص���,��ѧ����һ�������еĹ۵���:��˼һ��˾�ռ��ߵ���������ʶ,��ȵ����д���µĻ�,������������������ĵ�ÿһ��ÿһ��ô�����뵱Ȼ,�������Ϊ��ѧ���ܿ�����д��ÿһ��ÿһ��ô��������Ϊ��
����ƪ���ϳ�,û�취,һ�� Ϊ�˴�һͳBERT��ص����и���/ģ��,ƪ�������ܶ�,���� ������Ϊ��ν��ƪ������Ĩɱ���ĵ�ͨ�����ԡ���,���Ĺ�����,�õ�����˾�������߲��ֽ�ʦ��ָ��,�Լ������̵�ȷ��/����,�к����� ��ӭ����ָ��,thanks��
��һ���� �����������:��NNLM��Word2Vec
�Ҳ�����֮ǰд��һƪword2vec�ʼ�,����ٿ� д�IJ���ͨ����,�ɵ���,д���Ŀ�ͷ��ƪͼ��transformer���µ�����,��Ҳ��дһƪͼ��word2vec,�������еĺ��IJ����ʹ���ͼ�����Դ��ġ�
Ϊ����ÿһ����ѧ�߿��Դ�ͷ����β,�����������Ĺ����е��κ�һ�仰�����ǿ�����ȥ,����ԭӢ�ĵĻ�����,���˴����Լ���ѧϰ�ĵá�˵������(�����ڿ����ܶ���ѧ����ѧ��,��ѧ���㷨,�����ı��пɡ����п�)��
1.1 ��������ʾ����Ƕ��
��֪�������˵����Ϊ������ְ��Ա���Ը����? ������Ի�����һϵ�е�����,Ȼ���ںܶ�ά�ȸ�����,����/�����������֮һ,Ȼ����0��100�ķ�Χ����ʾ���Ƕ�ô����/����(����0���������,100���������)

����һ����Jay����,������/����÷�Ϊ38/100,���������ͼ��ʾ����÷�:

Ϊ�˸��õı�������(�����һ������Ϊ�˸��ñ������ݵ�����),���ǰѷ�Χ������-1��1:

���ǵ����Ը���,����һ���˵�����ֻ��һ����Ϣ��Ȼ�Dz�����,Ϊ��,����������һ���Եĵ÷���Ϊһ���µĵڶ�ά��,��������ά�Ⱦ����Ա���Ϊͼ�ϵ�һ����(���Ϊ��ԭ�㵽�õ������)

Ȼ�����˵����������ֵش�����Jay���˸�����Ҫ��������������Jay���бȽ�ʱ,���ֱ�ʾ���������ˡ�����Jay��һ�ҹ�˾��CEO,ij�챻����������ײסԺ��,סԺ�ڼ���Ҫһ���Ը����Ƶ��˴���Jay��CEO֮��������ͼ��,������������һ������Jay��,���ʺ�������CEO��?

��������������֮�����ƶȵ÷ֵij��÷������������ƶ�,�������ǵüн����ҵļ��㹫ʽ?
ͨ���ü��㹫ʽ�ɵ�

�Ӷ���֪,person 1���Ը�����Jay�����ơ���ʵ,������ϵ��Ҳ���Կ���,person1������ָ����Jay������ָ������(��Ȼ,����Ҳ������),���������и��ߵ��������ƶȡ�
����һ��,����ά�Ȼ������Բ����йز�ͬ��Ⱥ���㹻��Ϣ��������˵�����������˸�,����������ѧҲ�о����������Ҫ�˸�����(�Լ�������������)��
Ϊ�Ӽ����,�Ͳ����߸�ά����,�������ά���ٶȱȽ�Jay��person1 2��������:

��ʹ�����ά��ʱ,����û���ڶ�άƽ���������С��ͷ��(�Ͼ����Ҷ�����������ά����ϵ)����ʵ��������,���Ǿ���Ҫ�ڸ���ά�ȵĿռ������о�(�е��˰��о�һ�ʱ����˼��,ʵ����,����û���ڸ�γ�ȿռ�˼��,����ѧ�о���Ա����������,�ʱ�����о���ȷ),�����������ƶ���Ȼ��Ч,������������ά��:

��Щ�÷ֱ��ϴεĵ÷ֿ�������ȷ(��,ĿǰΪֹ,��ֻ��˵��������ȷ,���ѧ��ѧ�������ĸ�����,���¿�,��Ҫ�����Ի�),�Ͼ������Ǹ��ݱ��Ƚ�����ĸ���ά������ġ�
С��һ��,������
1.���ǿ��Խ��˺������ʾΪ��������
2.���ǿ��Ժ����ؼ������������֮������ϵ��

��������,������ͬѧҪ����,Ϊ��Ҫ�Ѵ���������ʾ��,�䱳�����������?
������֪,���Ǿ�ס�ڸ������ҵ�����ͨ�����Ե����Խ��н���,��������ֱ���������������,������Ҫ�Ȱ���������ԡ����������,����α�ɼ�������������������?

�����������,���ǿ���һ���ܼ�����,������ڼ����,��������ж�һ���ʵĴ���,�Ƕ��ʻ������ʵ���?
�ٶ�������һϵ������(x,y),���ڼ������������ѧϰ����,����� x �Ǵ���,y �����ǵĴ���,����Ҫ���� f(x)->y ��ӳ��:
- ����,�����ѧģ�� f(���������硢SVM)ֻ������ֵ������;
- �� NLP ��Ĵ���,���������Եij����ܽ�,�Ƿ�����ʽ��(�������ġ�Ӣ�ġ������ĵȵ�);
- ���һ��,���DZ���Ҫ��NLP��Ĵ���ת������ֵ��ʽ,����Ƕ�뵽һ����ѧ�ռ���;
- ��һ��,�����ı���ɢǶ�뵽��һ����ɢ�ռ�,�����ֲ�ʽ��ʾ,�ֳ�Ϊ��Ƕ��(word embedding)���������
- �ڸ��ִ�������,��һ���Ĵ�������one-hot encoder����ν one-hot����,��˼������������ﴦ����������one-hot һ��,����������һ��ֻ��һ�� 1���������� 0 ��������Ψһ��ʾ�����Ȼ,�������еı��붼��01���롣

�������ν�Ĵ�Ƕ���ˡ�
�پ�һ������,����һ�����ʡ�king���Ĵ�Ƕ��(��ά���ٿ���ѵ����GloVe����):
[ 0.50451 , 0.68607 , -0.59517 , -0.022801, 0.60046 , -0.13498 , -0.08813 , 0.47377 , -0.61798 , -0.31012 , -0.076666, 1.493 , -0.034189, -0.98173 , 0.68229 , 0.81722 , -0.51874 , -0.31503 , -0.55809 , 0.66421 , 0.1961 , -0.13495 , -0.11476 , -0.30344 , 0.41177 , -2.223 , -1.0756 , -1.0783 , -0.34354 , 0.33505 , 1.9927 , -0.04234 , -0.64319 , 0.71125 , 0.49159 , 0.16754 , 0.34344 , -0.25663 , -0.8523 , 0.1661 , 0.40102 , 1.1685 , -1.0137 , -0.21585 , -0.15155 , 0.78321 , -0.91241 , -1.6106 , -0.64426 , -0.51042 ]
����һ������50�����ֵ��б���ͨ���۲���ֵ���ǿ�����ʲô,�������������������ӻ�,�Ա�Ƚ������������������ǰ�������Щ���ַ���һ��:
![]()
�����Ǹ������ǵ�ֵ�Ե�Ԫ�������ɫ����(������ǽӽ�2��Ϊ��ɫ,�ӽ�0��Ϊ��ɫ,�ӽ�-2��Ϊ��ɫ):

���ǽ��������ֲ����鿴��ɫ��ָʾ��Ԫ���ֵ�����������ǽ���king�����������ʽ��бȽ�(ע��,����������֮��,Ҳ������֮��):

��ᷢ�֡�Man������ʺ͡�Woman�����,���롰King����ȸ�����,����Щ����ͼʾ�ܺõ�չ������Щ���ʵĺ����������
������һ��ʾ���б�:

ͨ����ֱɨ���������Ҿ���������ɫ����,��������Կ��������⼸��
- ��woman���͡�girl���ںܶ�ط������Ƶ�,��man���͡�boy��Ҳ��һ��
- ��Ȼ,��boy���͡�girl��Ҳ�б˴����Ƶĵط�,����Щ�ط�ȴ�롰woman����man����ͬ,Ϊ����,�Ͼ�boy/girl��ָ�ഺ����,��woman/man����ָ����
- ����,��king���͡�queen���˴�֮������,�Ͼ�������ν�����ҳ�Ա
1.2 ��������ģ��NNLM��Word2Vec
���������Ѿ�����ѵ���õĴ�Ƕ��,�����������Ǹ�����˽�ѵ�����̡� �������ǿ�ʼʹ��word2vec֮ǰ,������Ҫ��һ�´�Ƕ��ĸ�����:������ģ��(NNLM)��
����ÿ�춼�����ֻ����ߵ���,�������Ǿ������õ������ֻ����뷨�е���һ����Ԥ���,�������ڵ�������Google����Ҳ���������Ƶ�����������ʾ(�������)��
���統������thou shaltʱ,ϵͳ��Ԥ��/��ʾ�����������һ�������Dz���not?
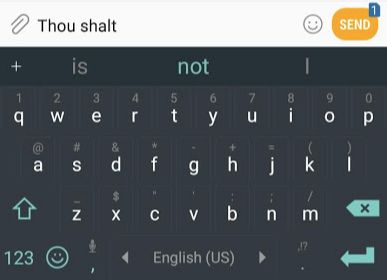
����������ֻ�������,��ģ�ͽ��յ�������ɫ����(thou shalt)��,�Ƽ���һ�鵥��(��Ȼ,��not�� ���������п��ܱ�ѡ�õ�һ��):

���ǿ������ģ������Ϊ����ں�:

����ʵ��,��ģ�Ͳ���ֻ���һ�����ʡ�ʵ����,����������֪���ĵ���(ģ�͵Ĵʿ�,�����м�ǧ�������������)�İ������Դ��,���뷨�����ѡ�����з�����ߵ��Ƽ����û�,����not

��Ȼ����ģ�͵��������ģ����֪���ʵĸ�������,����ͨ���Ѹ��ʰ��ٷֱȱ�ʾ,����ʵ����,40%�����ķ���������������DZ�ʾΪ0.4
��Ȼ����ģ��(��ο�Bengio 2003)�����ѵ����,�ᰴ��ͼ����ʾ�������������Ԥ��:

��һ�������������,��Ϊ�������۵ľ���Embedding��ģ���ھ���ѵ��֮�������һ��ӳ�䵥�ʱ����е��ʵľ���,Ҳ�ƴ�Ƕ������ڽ���Ԥ���ʱ��,���ǵ��㷨���������ӳ�����(��Ƕ�����)�в�ѯ����ĵ���(��Look up embeddings),Ȼ������Ԥ��ֵ:

���������ǽ��ص�ŵ�ģ��ѵ����,��ѧϰһ����ι������ӳ�����(��Ƕ�����)��
1.2.2 ����ģ��ѵ��:N-Gram����
����ͨ���ҳ�������ÿ�����ʸ����Ĵ�,���ܻ�����ǵ�ӳ���ϵ����������:
- ���ǻ�ȡ�����ı�����(��������ά���ٿ�����)
- Ȼ�����ǽ���һ���������ı������Ĵ�(����һ�����������������)
- ���������Ļ���������Ϊѵ��ģ�����ɴ����������ݡ�

��������������ı�����ʱ,���Ǿ���(��ʵ��)����һ������ģ��ѵ�������ݼ���
���ö��,���Ǿ��ܵõ�һ���ϴ�����ݼ�,�����ݼ��������ܿ����ڲ�ͬ�ĵ�����������ֵĵ���:

��ʵ��Ӧ����,ģ�����������ǻ�������ʱ�ͱ�ѵ���ġ�����ôѵ��ģ����?����ʹ�������罨ģ֮��,��һ�����һ����ΪN-Gram�ļ�������ģ��ѵ����
�ٸ�����,�������������仰ǰ�����Ϣ�������:
![]()
�ڿհ�ǰ��,���ṩ�ı������������(��������ἰ����bus��),���Կ϶�,������˶����bus����հ��С�����������ٸ���һ����Ϣ��������հ��һ������,�Ǵ𰸻��б���?

���¿հ״������������ȫ���ˡ���ʱ��red����������п����ʺ����λ�õĴ�֮һ����������������ǿ��Կ���,һ�����ʵ�ǰ�������ʵ�������м�ֵ����Ϣ,����Ҫ�����ܿ�����������ĵ���(Ŀ�굥�ʵ��������Ҳ��)��
1.2.3 Word2Vec�����ּܹ�:��CBOW��Skipgramģ��
?��ʵ��,���Dz���Ҫ����Ŀ�굥�ʵ�ǰ��������,��Ҫ��������������ʡ�

�����ô��,����ʵ���Ϲ�����ѵ����ģ�;�������ʾ:

���������֡��������Ĵʻ�Ԥ�ǰ�ʡ��ܹ�����Ϊ�����ʴ�(CBOW),��������������������������(���ԭ�Ļ�ο�����16):
?CBOW������������:
- �����:����context(w)��2c���ʵĴ�����
��
��
,����,v��ʾ���ʵ���������ʾ����,�൱�ڴ˺�����һ��������ת�����˶�Ӧ����������ʾ(����one-hot�����Ƶ�),2c��ʾ������ȡ���ܴ���,m��ʾ������ά��;
- ͶӰ��:��������2c���������ۼ����;
- �����:��������Ҫͨ��ȷ���������ľ���һ��������Ҫ�����Ĵ�wt,����ô������Ҫ�����Ĵʾ�����{w1 w2 .. wt .. wN}�е��ĸ���?ͨ����������������Ĵʵĸ��ʴ�С,ȡ�������Ĵʱ���������Ҫ�����Ĵ�,�൱�������һ��Nά������ж����,�����㸴�Ӷ�̫��,���������������һ��Huffman��,�������г��ֹ��Ĵʵ�Ҷ�ӽ��,Ȼ������ʳ��ֵ�Ƶ�ʴ�С��Ȩ��

������һ�ּܹ�,��������ǰ����(ǰ��)���²�Ŀ�굥��,���ּܹ�������ν��Skipgram�ܹ�:�Ʋǰ���ʿ��ܵ�ǰ����

˳����һ��,����ʲô�Ǹ�����,���Բμ������������,����ο�����1��
1.3 Word2vecѵ������:������Сerror(target - sigmoid_scores)
��ѵ�����̿�ʼ֮ǰ,����Ԥ�ȴ�����������ѵ��ģ�͵��ı���
��ѵ���εĿ�ʼ,���Ǵ�����������:��Ƕ��Embedding����������Context����,���������������ǵĴʻ����Ƕ����ÿ������,������������������ά��
- ��һ��ά��,�ʵ��С��vocab_size,�������10000,����һ�����
- �ڶ���ά��,ÿ������Ƕ��ij��ȼ�embedding_size,����300��һ������ֵ(��Ȼ,������ǰ��Ҳ����50������,��������1.1���������ڵ��ʡ�king���Ĵ�Ƕ�볤��)

��ѵ�����̿�ʼʱ,�����������ֵ��ʼ����Щ����,Ȼ�����ǿ�ʼѵ�����̡���ÿ��ѵ��������,���Dz�ȡһ�����ڵ����Ӽ�����صķ��������ӡ�
�����������:��Thou shalt not make a machine in the likeness of a human mind��,�������������ǵĵ�һ��(����not ��ǰ��������ھӵ��ʷֱ���:Thou?shalt ��make?a):

�����������ĸ�����:���뵥��not,�����/�����ĵ���:thou(ʵ���ھӴ�),aaron��taco(��������)��
���Ǽ����������ǵ�Ƕ��
- ���������not,���Dz鿴Embedding����
- ���������ĵ���,���Dz鿴Context����

Ȼ��,���Ǽ�������Ƕ����ÿ��������Ƕ��ĵ����
���ǵ�ʲô�е����?��ν���
��������a = [a1, a2,��, an]��b = [b1, b2,��, bn]�ĵ������Ϊ:a��b=a1b1+a2b2+����+anbn��
���������Ľ����ζ�������������������ĸ���Ƕ�����ĸ��������Գ̶�,���Խ�����Խ������

Ϊ�˽�����Щ����ת��Ϊ����������ʵĶ�������������Ҫ���Ƕ�����ֵ,���Ҵ���0��1֮��,�պÿ�������sigmoid��һ������ת���¡�

�Ӷ����ǿ��Խ�sigmoid�����������Ϊ��Щʾ����ģ������������Կ���taco�÷����,aaron���,������sigmoid����֮ǰ����֮��
��Ȼδ��ѵ����ģ��������Ԥ��,��������ȷʵӵ����ʵĿ���ǩ�����Ա�,��ô�����Ǽ���ģ��Ԥ���е����ɡ�Ϊ������ֻ���Ŀ���ǩ�м�ȥsigmoid������

error = target - sigmoid_scores
���ǡ�����ѧϰ���ġ�ѧϰ�����֡�����,���ǿ�����������������������not��thou��aaron��taco��Ƕ��,ʹ������һ��������һ����ʱ,�������ӽ�Ŀ�������

ѵ�����赽�˽��������Ǵ��еõ�����һ����ʹ�ô������һЩ��Ƕ��(not,thou,aaron��taco)���������ڽ�����һ��(��һ����������������صķ���������),���ٴ�ִ����ͬ�Ĺ��̡�

������ѭ�������������ݼ����ʱ,Ƕ�������õ��Ľ���Ȼ�����ǾͿ���ֹͣѵ������,����Context����,��ʹ��Embeddings������Ϊ��һ��������ѱ�ѵ���õ�Ƕ�롣
�ڶ�����? ��Seq2Seq��Seq2Seq with Attention
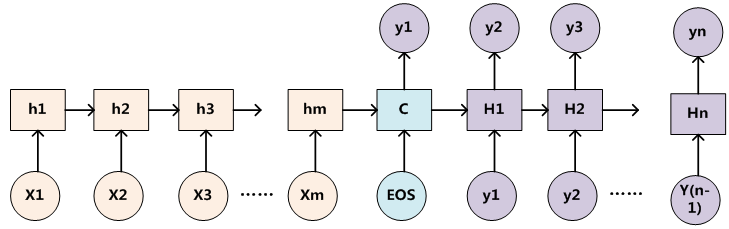
2.1 ��Seq2Seq���е�Encoder-Decoderģ��
2.1.1 ʲô��Seq2Seq:����һ������ ���һ������
Seq2Seq(�� Sequence-to-sequence ����д),����������˼,����һ������,�����һ������,��Ȼ,�����������к�������еij����ǿɱ�ġ�
�������Ƿ���Ӣ����������ѧ�Ҹ�����˹?�����һ�����ԡ�֪ʶ����������,����ͼ:

Seq2Seq(ǿ��Ŀ��)����ָ���巽��,���㡸�������С�������С���Ŀ��,������ͳ��Ϊ Seq2Seq���С�
2.1.2 ʲô��Encoder-Decoderģ��:RNN/LSTM��GRU
Ϊ�˽��Seq2Seq���е�����,���緭��һ�仰,���ǿ���ͨ��Encoder-Decoderģ���������
�����������Ѿ��Ӵ�������ĸ���,�б�������Ȼ�н���,�����ֱ��롢����Ŀ�ܿ��Գ�֮ΪEncoder-Decoder,�м�һ������C������Ϣ,��C�ij����ǹ̶��ġ�
������ͼ�����Դ�ڲο�����2��

û̫����?������ô����,����ͼ��,���ǿ��Ը��ݲ�ͬ���������ѡ��ͬ�ı������ͽ�����,���廯���ǿ�����һ��RNN��
?�ڲο�����3���δ�RNN��,һ��һ��ͨ������LSTM��,�����Ѿ���ϸ�˽���RNN��LSTM,�������,һ��Ҫ�ص㸴ϰ��(���Ǽ����������ĵ�����֮��)
Ϊ�˽�ģ��������,RNN��������״̬h(hidden state)�ĸ���,��״̬h���Զ������ε�������ȡ����,������ת��Ϊ�����
��ѧϰRNN֮ǰ,����Ҫ�˽�һ��������ĵ�������,���Ľṹ����ͼ��ʾ:
?������x,�����任Wx+b�ͼ����f,�õ����y�����Ŵ�Ҷ�����Ѿ��dz���Ϥ�ˡ�
��ʵ��Ӧ����,���ǻ��������ܶ������ε�����:
?��:
- ��Ȼ���Դ������⡣x1���Կ����ǵ�һ������,x2���Կ����ǵڶ�������,�������ơ�
- ������������ʱ,x1��x2��x3������ÿ֡�������źš�
- ʱ���������⡣����ÿ��Ĺ�Ʊ�۸�ȵȡ�
������,�����ε����ݾͲ�̫����ԭʼ�������紦���ˡ�
Ϊ�˽�ģ��������,RNN��������״̬h(hidden state)�ĸ���,��״̬h���Զ������ε�������ȡ����,������ת��Ϊ�����
�ȴ�
�ļ��㿪ʼ��:
RNN���Ա�����������ͬһ������Ķ�θ���,ÿ��������ģ������Ϣ���ݸ���һ��:
��Ȼ,����ͨ���������LSTM����GRU
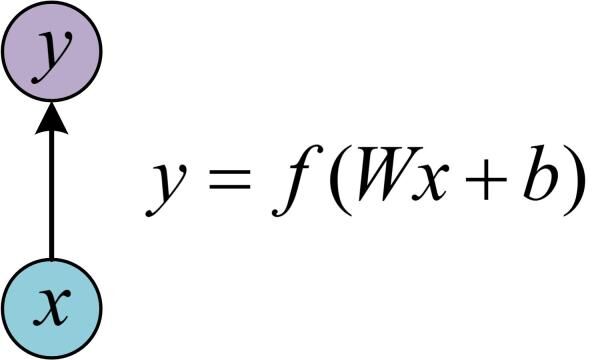

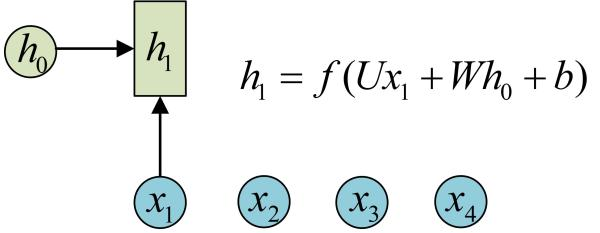


������������˰�,��ֻҪ�Ƿ������ƵĿ��,������ͳ��Ϊ Encoder-Decoder ģ�͡�
2.2 ��Seq2Seq��Seq2Seq with Attention
2.2.1?AttentionӦ�˶���:�����Ϣ����ʱ��Ϣ��ʧ������
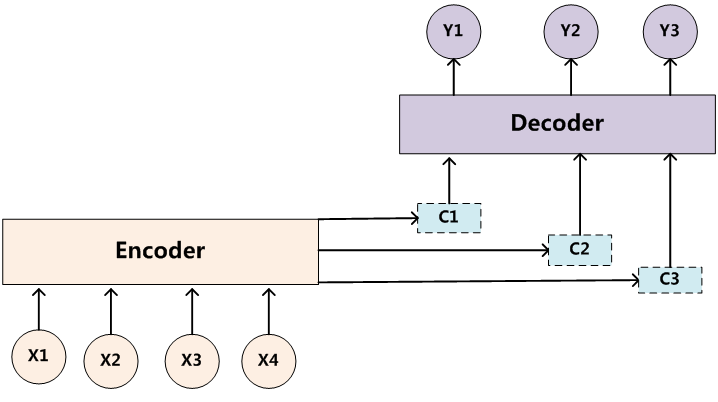
�����ᵽ:Encoder(������)�� Decoder(������)֮��ֻ��һ��������C����������Ϣ,��C�ij��ȹ̶���
���緭��һ�����,����ľ��Ӷ̻���,����һ����?��������ӱȽϳ�,��ʱ����������ȫת��Ϊһ���м���������C����ʾ,����ԭʼ����Ϣ�Ѿ���ʧ,�����֪�ᶪʧ�ܶ�ϸ����Ϣ��
����Encoder-Decoder����ȱ�ݵ�,��ȱ������:��������Ϣ̫��ʱ,�ᶪʧ��һЩ��Ϣ��
��Ϊ�˽������Ϣ����,��Ϣ��ʧ��������,Attention?���ƾ�Ӧ�˶����ˡ�
Attention?ģ�͵��ص���?Eecoder?���ٽ������������б���Ϊ�̶����ȵġ��м�����C��,���DZ����һ�����������С�������Attention��Encoder-Decoder?ģ������ͼ:

- ������ĽǶȽ�
ÿ������Ĵ�Y���ܵ�ÿ������X1��X2��X3��X4������Ӱ��,����ֻ��ijһ���ʵ�Ӱ��,�Ͼ������������������������,��ͬʱÿ������ʶ�ÿ�������Ӱ�����Dz�һ����,��ÿ�����Y������X1��X2��X3��X4��Ӱ��Ȩ�ز�һ��,�����Ȩ�ر�����Attention����,Ҳ������ν��ע��������ϵ��,����ÿһ����������Ȩ�ص�Ӱ���С - �ӱ���ĽǶȽ�
�ڸ��ݸ�������Ϣ���б���ʱ(���������ȡ),��ͬ��Ϣ����Ҫ�̶��Dz�һ����(����Ȩ�ر�ʾ),����Щ��Ϣ���ؽ�Ҫ��,����һЩ��������֮���,�������ʱ���ڱ���ʱ,�Ϳ����еķ�ʸ,���ݲ�ͬ����Ҫ�̶�����Լ�ȡ�����Ϣ
2.2.2 ͨ������Tom chase Jerry��ʾAttention���㷨����
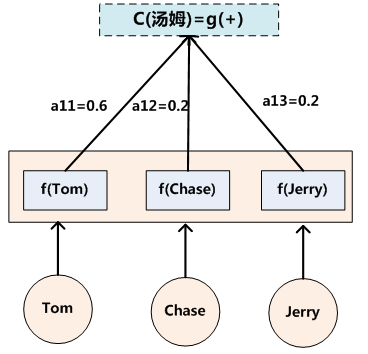
�پ�һ���������������(��è�������ӵ���ͼ�ͺ��IJ�������Դ�ڲο�����4),����Google������仰:Tom chase Jerry
-
�ڷ��롰���𡱵�ʱ��,����ע�������Ƶ�ģ�ͻ����ֳ�Ӣ�ĵ��ʶ��ڷ��뵱ǰ���ĵ��ʲ�ͬ��Ӱ��̶�,���������������һ�����ʷֲ�ֵ:(Tom,0.3)(Chase,0.2) (Jerry,0.5),ÿ��Ӣ�ĵ��ʵĸ��ʴ����˷��뵱ǰ���ʡ�����ʱ,ע��������ģ�ͷ������ͬӢ�ĵ��ʵ�ע������С(������˾�������߿����»�,��Ȼÿ���˶��з���Ȩ,���Բ�ͬ������о���ʱ,�����ԶԾ���������ó�����ӵ�и���ķ���Ȩ,���������Ȩ����Ȩ��һ��,��ͬ���˶����վ��߽���IJ������Ų�ͬ��С��Ӱ��)
-
Ŀ������е�ÿ�����ʶ�Ӧ��ѧ�����Ӧ��Դ������е��ʵ�ע�������������Ϣ������ζ��������ÿ������
��ʱ��,ԭ�ȶ�����ͬ���м������ʾC�ᱻ�滻�ɸ��ݵ�ǰ���ɵ��ʶ����ϱ仯��
(ע:�������Attentionģ�͵Ĺؼ�,���ɹ̶����м������ʾC�����˸��ݵ�ǰ��������������ɼ���ע����ģ�͵ı仯��
-
?����Ŀ����ӵ��ʵĹ��̳����������ʽ:
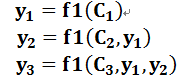
��ÿ��

����,f2��������Encoder������Ӣ�ĵ��ʵ�ij�ֱ任����,�������Encoder���õ�RNNģ�͵Ļ�,���f2�����Ľ��������ij��ʱ������
������ڵ��״ֵ̬;g����Encoder���ݵ��ʵ��м��ʾ�ϳ����������м������ʾ�ı任����,һ���������,g�������ǶԹ���Ԫ�ؼ�Ȩ���,�����й�ʽ:?
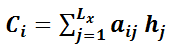
����,
�����������Source�ij���,
������Target�����i������ʱSource��������е�j�����ʵ�ע��������ϵ��,��
����Source��������е�j�����ʵ�������롣
-
����
������һ������:����Ŀ�����ij������,���硰��ķ����ʱ��,���֪��Attentionģ������Ҫ��������ӵ���ע����������ʷֲ�ֵ��?����˵����ķ����Ӧ���������Source�и������ʵĸ��ʷֲ�:(Tom,0.6)(Chase,0.2) (Jerry,0.2) ����εõ�����?Ϊ��˵��,�����òο�����4��Ӧ������,����
Ϊ�˱���˵��,���Ǽ���Է�Attentionģ�͵�Encoder-Decoder��ܽ���ϸ��,Encoder����RNNģ��,DecoderҲ����RNNģ��,���DZȽϳ�����һ��ģ������
��ô����ͼ����Խ�Ϊ��ݵ�˵��ע����������ʷֲ�ֵ��ͨ�ü�����̡�
���ڲ���RNN��Decoder��˵
- ��ʱ��i,���Ҫ����
��(����RNN�ṹ������,�������RNN�ṹ������ع˲ο�����3)
- �����ǵ�Ŀ����Ҫ��������
�����Ŀ�굥��
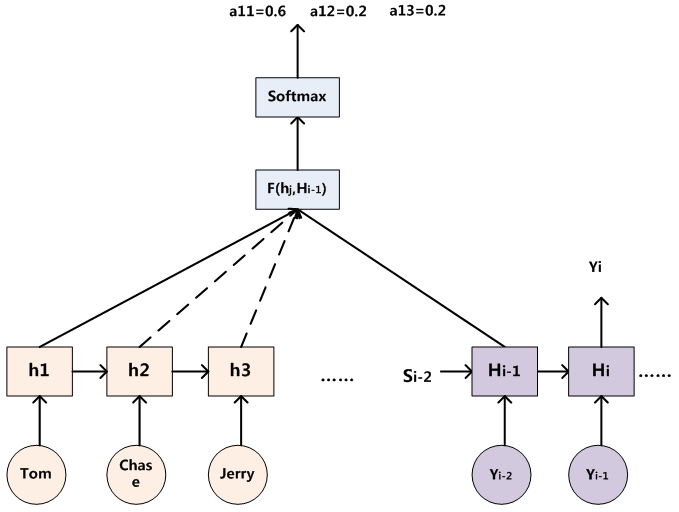
���������,�����б�Ҫ�ٺúý���һ��
- ����˾����������:�� ����ٵ��������� Tom chase Jerrry �õ� ��ķ�����,�������Ǽ���ҪԤ�����(�Ѿ�Ԥ�������ķ��),��ô���ʱ��,i �ͱ�ʾ���ǽ������ʱ��,i-1ʱ�̵�hidden�Ͱ�������ķ������Ϣ,���������i-1ʱ�̵�hidden��Tom��chase��Jerry�ĸ��Բ�ͬ��Attention��ֵ,�������õ�Ԥ���������� ��
- ����ע����������ʵķֲ���ֵ,�ж��ֲ�ͬ�ļ��㷽��,����μ�����:Attention? Attention!,���߲ο��ο�����14(33min��37min,�Լ�50min���н�)

2.2.3 Attention���㷨�����ܽ�:ͨ�����������Եó�Ȩ������Ȩ���
�ٱ���,ͼ���(source)���кܶ���(value),Ϊ�˷������,���Ǹ������˱��(key)����������Ҫ�˽�����(query)��ʱ��,���ǾͿ��Կ�����Щ��������Ӱ��������ս(�����ӳ�)��ص��鼮��

Ϊ�����Ч��,���������е��鶼����ϸ��,���������˵,����,��Ӱ��صĻῴ����ϸһЩ(Ȩ�ظ�),���Ƕ�ս�ľ�ֻ��Ҫ��ɨһ�¼���(Ȩ�ص�)��
������ȫ�������Ͷ�������һ��ȫ����˽��ˡ�
���Կ���,��Source�еĹ���Ԫ�����������һϵ�е�<Key,Value>���ݶԹ���,��ʱ����Target�е�ij��Ԫ��Query,ͨ������Query����Key�������Ի��������,�õ�ÿ��Key��ӦValue��Ȩ��ϵ��,Ȼ���Value���м�Ȩ���,���õ������յ�Attention��ֵ��
���Ա�����Attention�����Ƕ�Source��Ԫ�ص�Valueֵ���м�Ȩ���,��Query��Key���������ӦValue��Ȩ��ϵ���������Խ��䱾��˼���дΪ���¹�ʽ:
�������̾�������ͼ��ʾ:
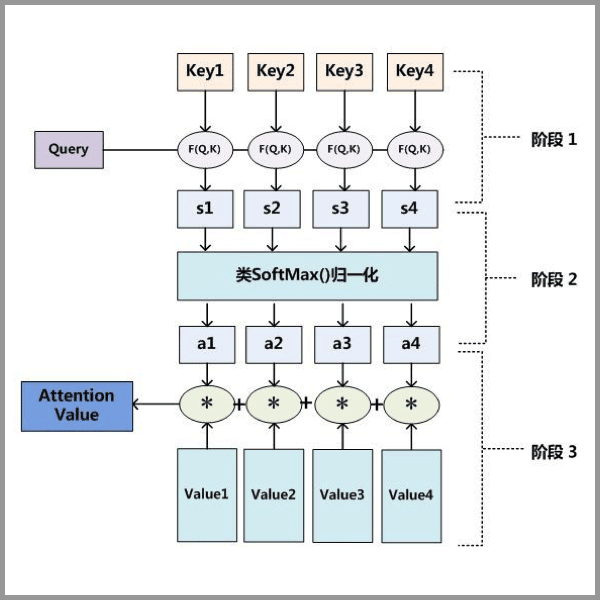
��������һ��,��Ϊ
- ��һ��:��������������query �� ����ij�����key �������ƶȼ���(�����ķ�������:�����ߵ���������������ߵ�����Cosine�����Ե�),�õ�Ȩֵ
- �ڶ���:��Ȩֵ���й�һ��(��ԭʼ�����ֵ����������Ԫ��Ȩ��֮��Ϊ1�ĸ��ʷֲ�,����˵ͨ��SoftMax�����ڻ��Ƹ���ͻ����ҪԪ�ص�Ȩ��),�õ�ֱ�ӿ��õ�Ȩ��
- ������:��Ȩ�غ� value ���м�Ȩ���
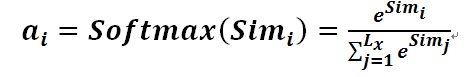
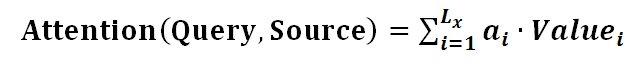
ֵ��һ�����,Attention ����һ��Ҫ�� Encoder-Decoder �����ʹ�õ�,���ǿ������� Encoder-Decoder ��ܵġ�

�˽���Attention�ı���˼��,������ν��Self-Attention��������,�������Ļ���ϸ�����������ȼ���һ�졣
��һ�������Encoder-Decoder�����,����Source�����Target�����Dz�һ����,�������Ӣ-�л���������˵,Source��Ӣ�ľ���,Target�Ƕ�Ӧ�ķ���������ľ���,Attention���Ʒ�����Target��Ԫ��Query��Source�е�����Ԫ��֮�䡣
��Self?Attention����˼��,ָ�IJ���Target��Source֮���Attention����,����Source�ڲ�Ԫ��֮�����Target�ڲ�Ԫ��֮�䷢����Attention����,Ҳ��������ΪTarget=Source������������µ�ע����������ơ��������������һ����,ֻ�Ǽ���������˱仯���ѡ�
�������� ͨ������Transformer:��������������BERT��һ��
�Դ�2017����ġ�Attention is All You Need�������Transformer��,�㿪���˴��ģԤѵ������ʱ��,Ҳ����ʷ�ij�����һ�ٴ�������BERT�����Ĵ�һͳģ�͡�
����Ȥ��,���Իع��¡�����2018��3�·ݻ�ʢ�ٴ�ѧ���ELMO��2018��6�·�OpenAI���GPT��2018��10�·�Google���BERT��2019��6�·�CMU+google brain���XLNet�ȵȡ�
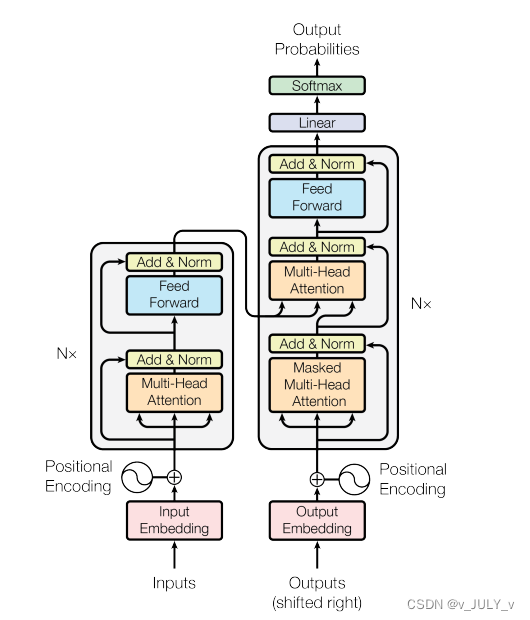
����,��Ŀǰ������������������,����Transformer�ȽϺö��Ļ��ǿ�ͷ�������ƪ��The Illustrated Transformer��,�������еĺ��IJ����ʹ���ͼ�����Դ��ġ�
������,���ڴ��ĵĻ����ϼ��Դ������͡�˵��,����֮��Ϊȫ����ͨ������Transformer���ۡ���Ϊ��Щ���͡�˵�����������������п�������,������Ϊ������Щ���͡�˵��,������������ÿһ����ѧ�߶��ܿ��������ʲô��Transformer��
3.1 Transformer֮����:��ע����/λ�ñ���/������һ��
3.1.1 �ӻ�������ģ�Ϳ�ʼ̸��
���ǿ����������Ѿ����ֹ��Ļ��������ģ�͡������Ǵ��ⲿ���������Ļ�,����������뼼��������һ���������:��������һ������,ϵͳ�����һ������:

�����Dz���������,���ǿ��Կ��������ɱ���������������������֮���������ɡ�

����
- �������������һ�ѱ�����/encoder����(����������Ե�)
- �����������Ҳ������ͬ����(���������Ӧ)�Ľ�����decoder��ɵ�

�����Dz�����������ᷢ��,���еı������ڽṹ�϶�����ͬ��,���Dz�����������,ÿ�������������Էֽ�������Ӳ㡣

�����ǰѱ������ͽ������������������������̾���
- �ӱ���������ľ������Ȼᾭ��һ����ע������(��self-attention,���Ļ�������),��������������ڶ�ÿ�����ʱ���ʱ��ע������ӵ��������ʡ�
- ��ע�����������ᴫ�ݵ�ǰ��(feed-forward)��������,ÿ��λ�õĵ��ʶ�Ӧ��ǰ��������Ľṹ����ȫһ��(ע��:���ṹ��ͬ,�����ԵIJ�����ͬ)��
- ��������Ҳ�б���������ע����(self-attention)���ǰ��(feed-forward)��,����֮��,��������֮�仹��һ��ע������,������ע������ӵ���ز���(��seq2seqģ�͵�ע������������)��

3.1.2 ����������ͼ��
�����Ѿ��˽���ģ�͵���Ҫ����,���������ǿ�һ�¸�������������(��ע:����������ʸ��������ƹ�,���Լ�����ʸ����һ�������������Ƕ�������)��������ģ�͵IJ�ͬ������,������ת��Ϊ����ġ�
���NLPӦ��һ��,�������Ƚ�ÿ�����뵥��ͨ����Ƕ���㷨ת��Ϊ��������

ÿ�����ʶ���Ƕ��Ϊ512ά������(512��transformerԭ�����趨��һ��ά��,���Ʊ�����/������������һ��,Ҳ�����ǿ������õij�������˳�����,ѵ����������ӵij���������Ҳ���õ�512),��Ϊ�������һϵ�е�ͼʾ,������4�����Ӵ���512ά,����Ȼ��ֻ����4ά,����Ҫ����ʵ�ʱ��������512ά��
���б���������һ��������Ϊ����,�����е�����������ά����512������µ��Ǹ����������յ���Ƕ������,֮��ı��������յ���ǰһ���������������
�����ǵ��������о�����Ƕ��֮��õ�������,������ͨ������������е������㡣

���������ǿ���Transformer��һ����������
- ����������������ÿ��λ�õĵ��ʶ����Ե�����·���������������֪�㷢��û��,����������ͬʱ����������е�,�����Ŷӽ���..
- ����ע����self-attention����,��Щ·������֮�����������,��ǰ����(feed-forward)��û����Щ������,������Щ·��������ǰ����(feed-forward)ʱ���Բ��м���
Ȼ�����ǽ���һ�����̵ľ���(Thinking Machine)Ϊ��,������������ÿ���Ӳ��з�����ʲô��
3.1.3 ��ʼ�����롱:����ע�������Ƶ���ͷע����
�������Ѿ��ᵽ��,һ������������һ��������Ϊ����,����������ͨ��һ����ע������,�پ���һ��ǰ��������,������������һ�������������

�������е�ÿ�����ʶ������Ա�����̡�Ȼ��,���Ǹ���ͨ��ǰ�������硪����ȫ��ͬ������,��ÿ���������ֱ�ͨ������
3.1.3֮0/7 ʲô����ע��������:�Ӻ���ӽǿ���ע��������
����ͨ��һ�������˽���ע�������ƵĹ���ԭ����
����,���о�����������Ҫ������������:
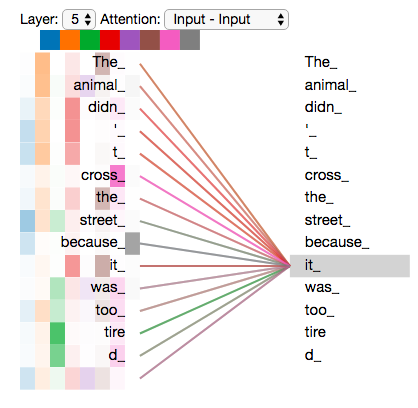
��The animal didn't cross the street because it was too tired��
�����it�������������ָʲô��?��ָ����street ������� animal ��?������˵�ܼ�����(��Ȼ��animal,��Ϊanimal�ſ���cross,�ſ���tired),���Ƕ��㷨���Բ�����,�㷨��һ��֪��itָ����animal����street��
��self-attention����զ����?һ������»���ô����:
��ģ�ʹ������ʡ�it��ʱ,self-attention��������it���͡�animal����ϵ��������ģ�ʹ���ÿ��λ�õĴ�ʱ,self-attention����ģ�Ϳ������ӵ�����λ����Ϣ���������������õر��뵱ǰ�ʡ�
����֮,��ע���������þ���:��һ���������������λ�õĵ���,��ͼѰ��һ�ֶԵ�ǰ���ʸ��õı��뷽ʽ��
���ǵ�RNN��?����һ��RNN������״̬�Ĵ���:��֮ǰ������״̬�뵱ǰλ�õ���������������Transformer��,��ע��������Ҳ���Խ�������ص��ʵġ����⡱���뵽���ǵ�ǰ�����ĵ����С�
���������Ƕλ����е���,Ϊͨ�����,˵��ֱ�����,�����Ҫ���õ��������ij���ض����ʵĺ���,��Ҫ�����ŵ������ᄈ֮��ȥ����,����ͨ���������ĵİ���������������Щ�ʶ�������ض��ʸ���Ҫ��?�����Ҫ�̶ȱ�����ν��Ȩ�ر�ʾ,���Բ����ÿ���ʶԡ��ôʡ���Ȩ��,Ȩ��Խ��ĵ��ʴ��������⡺�ôʡ�Խ��Ҫ,Ȼ��Ѹôʱ���Ϊ�����ô��������дʵļ�Ȩ�͡�

����,�Ż���ֵ������ڱ�����#5(ջ�����ϲ������)�б��롰it��������ʵ�ʱ,��Ϊ������ɫ����dz��ӳ��Ȩ�صĴ�С,�Ӷ����Կ������롰it��ʱ,Ȩ�������������ǡ�The Animal��,����ζ��ע�������Ƶ��ӽ�/��ע�Ȼ�������ڡ�The Animal��,��ʾ it ���������ʹ������,�����attention����������,���ĸ��ʹ����Ƚ�ǿ,�ͷűȽ϶��ע����������,�����ս��俼�ǽ�it�ı����С�
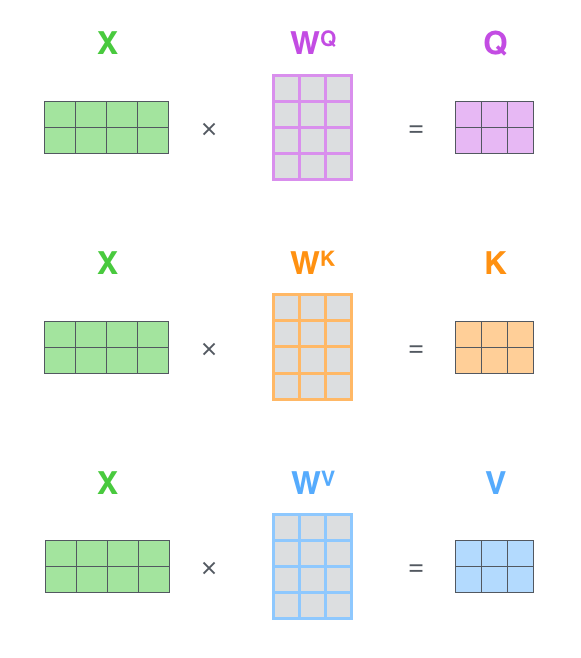
3.1.3֮1/7 ������ע������һ��:���ɲ�ѯ��������������ֵ��������
���������˽�һ�����ʹ��������������ע����,Ȼ��������������Ծ���ķ�ʽ�����㡣
������ע�����ĵ�һ��,���Ǵ�ÿ������������������(��ÿ�����ʵĴ�����)������������:��ѯ����query-vec��������key-vec��ֵ����value-vec��
�������ǵ����ɷ����ǰ�����������ֱ����������ͬ��Ȩ�ؾ�����
��
,�õ�Q��K��V,����ЩȨ�ؾ�������ģ��ѵ������ѵ�������ġ�
�������������ο��ܻ���ͬѧ��һЩϸ��������,���е����¿��ܶ�����ò��Զ���,��Ϊ���������ѧ��,�����Ұ����ϸ��һ��������:
- ����,��ѯ��������������ֵ����������������ά�������������õ���64,��ά���ϱȴ�Ƕ����������,��Ϊ��Ƕ��ͱ�����������/���������ά����512,��ֵ��ע�����Ҳ���DZ���ȱ��������������ά��С,��������Ҫ��Ϊ���ö�ͷע�����ļ�����ȶ�
(��������ῴ��,transformerͨ����ͷע��������multiheaded attention,��ÿ��512ά������������������8��ͷ,��ͬ��ͷ��עÿ������������ͬ�IJ���,���㷢��û��:512/8 = 64,���ٶ�˵һ��,Ҳ��������Ϊ2��ͷ,��һ���ǵ�����Ϊ8��ͷ) - ���,����Ȩ�ؾ���
/
/
���ѵ��������,��²�ʿ������ʦ���������ߵĽ�ʦ��˵,�������:�������ʼ��,Ȼ������ʧ�����б�ʾ����,���ͨ�����������Ż�ѧϰ�ó�������ʲô�Ƿ���,��μ��ο�����17)
����Ȩ�ؾ����,���ڵ�����
�ֱ����
��
��
��
- ���ڵ���
����,��������:
��������
��ֵ����

����ʹ���������е�ÿ�����ʸ��Դ���һ����ѯ������һ����������һ��ֵ������
�����еĶ�����������,����������������������ڻ��к����⡣ʵ����
- ���ڲ�ѯ����Query����:query�ǵ�ǰ���ʵı�ʾ��ʽ,���ڶ�������������(key)��������,����ֻ��Ҫ��ע��ǰ���ڴ�����token��query��
- ���ڼ�����Key����: Key���Կ��������������е��ʵı�ǩ,������������ص���ʱ��Ķ����
- ����ֵ����Value����:Value�ǵ��ʵ�ʵ�ʱ�ʾ,һ�����Ƕ�ÿ�����ʵ���ضȴ��֮��,���Ǿ�Ҫ��value������ӱ�ʾ��ǰ���ڴ����ĵ��ʵ�value��
3.1.3֮2/7 ������ע�����ڶ���:����÷�
������ע�����ĵڶ����Ǽ���÷֡�����������Ҫ�����������еĵ�һ�����ʡ�Thinking��(pos#1)����attention��ֵ,������ÿ���ʶԡ�Thinking���Ĵ��,����־����ű��롰Thinking��ʱ(ij���̶�λ��ʱ),Ӧ�ö�����λ���ϵĵ�������������ٹ�ע�ȡ�
����÷�ͨ����Thinking������Ӧ�IJ�ѯ����query�����дʵļ�����key,���γ˻��ó�����������������Ǵ���λ���ǰ�Ĵʵ�attention��ֵ�Ļ�,��һ��������q1��k1�ĵ��,�ڶ���������q1��k2�ĵ����

3.1.3֮3/7 ������ע�����������IJ�:��������8Ȼ��softmax��
�������͵��IJ��ǽ���������8(8��������ʹ�õļ�������ά��64��ƽ����,������ݶȸ��ȶ�������Ҳ����ʹ������ֵ,8ֻ��Ĭ��ֵ),Ȼ��ͨ��softmax���ݽ����softmax��������ʹ���е��ʵķ�����һ��,�õ��ķ���������ֵ�Һ�Ϊ1��

���softmax�����������ڱ��뵱��λ��(��Thinking��)ʱ,��������λ�õ���(��Thinking��)����ÿ�����ʵ�����õĹ�ע������Ȼ,�Ѿ������λ���ϵĵ��ʽ������ߵ�softmax����,����ʱ��ע�뵱ǰ������ص��������������õġ�������,��ǰ������,���ڿ���ij���ض����ʵĺ���ʱ,��Ҫ���������ᄈ�����������ġ�
3.1.3֮4/7 ������ע�������塢����:ֵ��������softmax������Լ�Ȩֵ�������
���岽�ǽ�softmax��ֵ����ÿ��ֵ����(����Ϊ����֮���������)������������������������������Ҫ��ע�ĵ��ʵ�value,������������صĵ��ʶ���(����,�����dz���0.001������С��)��
�������ǶԼ�Ȩֵ�������,������λ�õ�self-attention��������(�����ǵ��������Ƕ��ڵ�һ������)��

ͨ������һϵ�еļ���,���Կ���,����ÿ���ʵ��������z�������������ʵ���Ϣ,ÿ���ʶ������ǹ������ˡ����Ҵ���ʵ���س̶�,����ͨ��softmax�����Ȩ�ؽ��з�����
������ע�����ļ��������ˡ��õ��������Ϳ��Դ���ǰ�������硣Ȼ��ʵ����,��Щ�������Ծ�����ʽ��ɵ�,�Ա���ø��졣�����ǽ������Ϳ�������þ���ʵ�ֵġ�
3.1.3֮5/7 ͨ����������ʵ����ע��������
��һ���Ǽ����ѯ���������ֵ����Ϊ��,���ǽ�����������ϲ����������X(�����ÿһ�д�����������е�һ������,������������ʹ�����������),�����������ѵ����Ȩ�ؾ���(��
��
)��
�����ٴο�����Ƕ������ (512,��ͼ�е�4������),��q/k/v����(64,��ͼ�е�3������)�Ĵ�С���졣
���,�������Ǵ������Ǿ���,���ǿ��Խ�����2������6�ϲ�Ϊһ����ʽ��������ע����������,��ͼ����ע�����ľ���������ʽ:

3.1.3֮6/7 ��multi-headed�� attention:����ս��ͷ�֡�
ͨ������һ�ֽ�������ͷ��ע����(��multi-headed�� attention)�Ļ���,���Ľ�һ����������ע������,���������������ע�����������:
- ����չ��ģ��רע�ڲ�ͬλ�õ����������롰Thinking����ʱ��,��Ȼ���Z1�����ٰ���������λ�õ��ʵ���Ϣ,������ʵ�ʱ����л��DZ���Thinking�����ʱ�����֧�䡣������Ƿ���һ������,���硰The animal didn��t cross the street because it was too tired��,���ǻ���֪����it��ָ�����ĸ���,��ʱģ�͵ġ���ͷ��ע����ƻ������á�
- ��������ע������Ķ������ʾ�ӿռ䡱(representation subspaces)��
Julyע:��һ�ο������������,���ܻ�������,����֪����������(https://www.zhihu.com/question/341222779?sort=created ):ΪʲôTransformer ��Ҫ����Multi-head Attention,����ͷע��������?
��TniL�Ĵ��:�������CNN��ͬʱʹ�ö���˲���������,ֱ���Ͻ�,��ͷ��ע�������������粶�����ḻ������/��Ϣ��
����������ô˵��:Multi-head attention allows the model to jointly attend to information from different representation subspaces at different positions.
����different representation subspaces,��һ����һ������������:���������ҳ��ʱ��,���������ɫ������ӹ�ע��ɫ������,�������巽���ȥע���ġ���������֡��������ɫ���������������ͬ�ı�ʾ�ӿռ䡣ͬʱ��ע��ɫ������,������Ч��λ����ҳ��ǿ�������ݡ�ʹ�ö�ͷע����,Ҳ�����ۺ����ø��������Ϣ/����(�Ͼ�,��ͬ�ĽǶ����Ų�ͬ�Ĺ�ע��)��
��LooperXX������:��Transformer��ʹ�õĶ�ͷע��������ǰ,���ڸ��ֲ�εĸ���fancy��ע�������㷽ʽ,��������Transformer�Ķ�ͷע��������ȥ�ǽ����CNN��ͬһ��������ʹ�ö�������˵�˼��,ԭ����ʹ���� 8 �� scaled dot-product attention ,��ͬһ multi-head attention ����,�����Ϊ KQV ,ͬʱ����ע�����ļ���,�˴�֮ǰ����������,���ս����ƴ������,������������ģ���ڲ�ͬ�ı�ʾ�ӿռ���ѧϰ����ص���Ϣ,�ڴ�֮ǰ�� A Structured Self-attentive Sentence Embedding Ҳ�������Ƶ�˼�롣
�����֮,����ϣ��ÿ��ע����ͷ,ֻ��ע�������������һ���ӿռ�,��������������˼������,��ȡ�����ӷḻ��������Ϣ������,Multi-Head �Ķ��ͷ����һ����������������������ȥ��ע��ͬ�������Ϣ���� EMNLP 2018 �� Multi-Head Attention with Disagreement Regularization һ���в��������ֶ�����֤ÿ��ͷ��ע��ͬ���ӿռ䡣
ok,������,���ǽ��������ڡ���ͷ��ע�����,�����ж����ѯ/��/ֵȨ�ؾ���(Transformerʹ�ð˸�ע����ͷ,������Ƕ���ÿ��������/�������а˸�����)��ÿһ�鶼�������ʼ��,����ѵ��֮��,�����������Ա�ӳ�䵽��ͬ���ӱ���ռ��С�
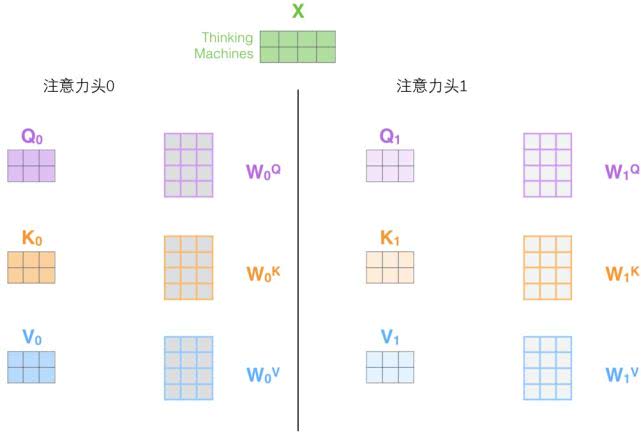
�ڡ���ͷ��ע�������,����Ϊÿ��ͷ���ֶ����IJ�ѯ/��/ֵȨ�ؾ���,�Ӷ�������ͬ�IJ�ѯ/��/ֵ����֮ǰһ��,������X����/
/
������������ѯ/��/ֵ����
�����������������ͬ����ע��������,ֻ��˴β�ͬ��Ȩ�ؾ�������,���Ǿͻ�õ��˸���ͬ��Z����
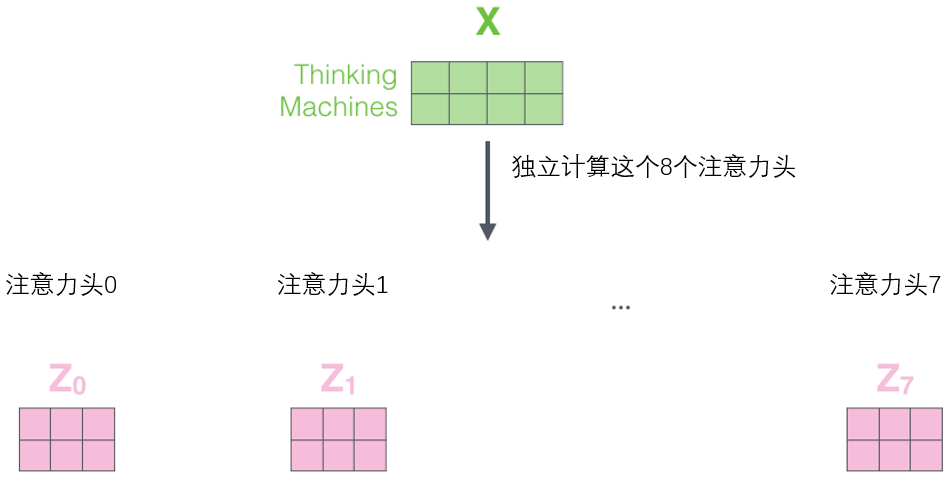
������Ǵ�����һ����ս��ǰ����û��һ���ӽ���8������,����Ҫһ����һ�ľ���(���������һ���������������X����,������ÿ������������Ӧһ������,�������ĵ�һ�ж�Ӧ����Thinking������ĵڶ��ж�Ӧ����Machines)������������Ҫһ�ַ�������8������ϲ���һ�������Ǹ���ô��?��ʵ����ֱ�Ӱ���Щ����ƴ����һ��,Ȼ�����һ�����ӵ�Ȩ�ؾ�����

�⼸�����Ƕ�ͷ��ע������ȫ������ȷʵ�кö����,�������Ű����Ǽ�����һ��ͼƬ��,��������һ�ۿ��塣
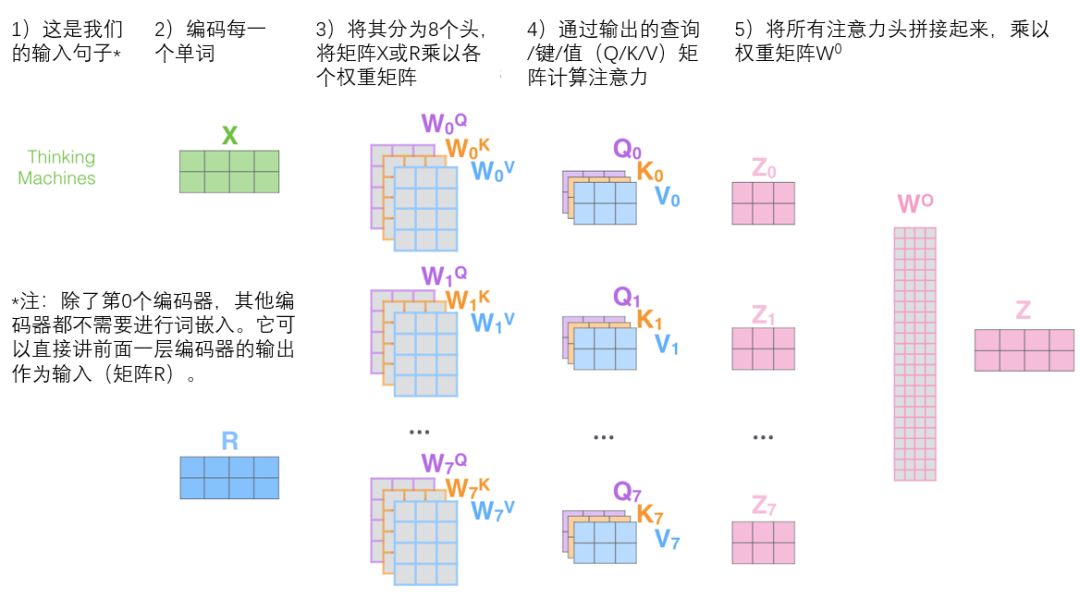
3.1.3֮7/7 �������������϶�ͷע������
���������Ѿ�����ʲô�Ƕ�ͷע������,�����ǻع�һ��֮ǰ��һ������,�ٿ�һ�±��롰it����ʱ��ÿ��ͷ�Ĺ�ע�㶼������:

����it,������head��ʱ��:����һ������עthe animal(ע�⿴ͼ�л��ߵ�ָ��),��һ������עtired(ע�⿴ͼ�����ߵ�ָ��)��
�൱�ڴ�ʱ��ģ�Ͷ�it �ı���,ʹ��it����ֻ��it ����,ͬʱ��������the animal��tired�������Ϣ��
������ǰ����е�ͷ��ע���������ӻ�һ��,������ͼ������
3.2 Transformer���CNN/RNN��������λ�ñ���
����,CNN��ȡ���Ǿֲ�����,���Ƕ����ı�����,�����˳����������,CNN���ı��еı�����������RNN��
��RNN��������������?��ο�����8��˵,������������h4ʱ,�õ���:����x4����һ���������������h3,h3������ǰ�����нڵ����Ϣ��

- h4�а���������Ϣ�ǵ�ǰ������x4,Խ��ǰ������,���ž��������,��Ϣ˥����Խ�ࡣ����ÿһ�����������h�������,������Ϣ�����ǵ�ǰ������,���ž�����Զ,����ǰ���������ϢԽ��Խ�١�����Transformer����ṹ�Ͳ������������,���ܵ�ǰ�ʺ������ʵĿռ�����ж�Զ,���������ʵ���Ϣ��ȡ���ھ���,����ȡ�������ߵ������,����Transformer�ĵ�һ������
- �ڶ�����������,����Transformer��˵,�ڶԵ�ǰ�ʽ��м����ʱ��,���������õ�ǰ��Ĵ�,Ҳ�����õ�����Ĵ�,��RNNֻ���õ�ǰ��Ĵʡ���Ȼ,����Ǹ��ж����ص�����,��Ϊ�����ͨ��˫��RNN�������
- ������,RNN��һ��˳��Ľṹ,����Ҫһ��һ���ؼ���,ֻ�м����h1,���ܼ���h2,�ټ���h3,��������ͬʱ���м���,����RNN�ļ���Ч�ʲ��ߡ�ͨ��ǰ�ĵĽ���,���Կ���Transformer������������⡣
�����и�ϸ��ֵ��ע����,��֪�ж��߷���û��,��RNN�Ľṹ���������е�ʱ����Ϣ,��Transformerȴ��ȫ��ʱ����Ϣ�������ˡ�
������Ƿ��100��,�͡���Ƿ��100��,���ߵ���˼ǧ�����,��Ϊ�˽��ʱ�������,Transformer����������һ������İ취:λ�ñ���(Positional Encoding)��λ�ñ����Ǻ�word embeddingͬ��ά�ȵ�����,��λ��embedding�ʹ�embedding����һ��,��Ϊ����embedding:
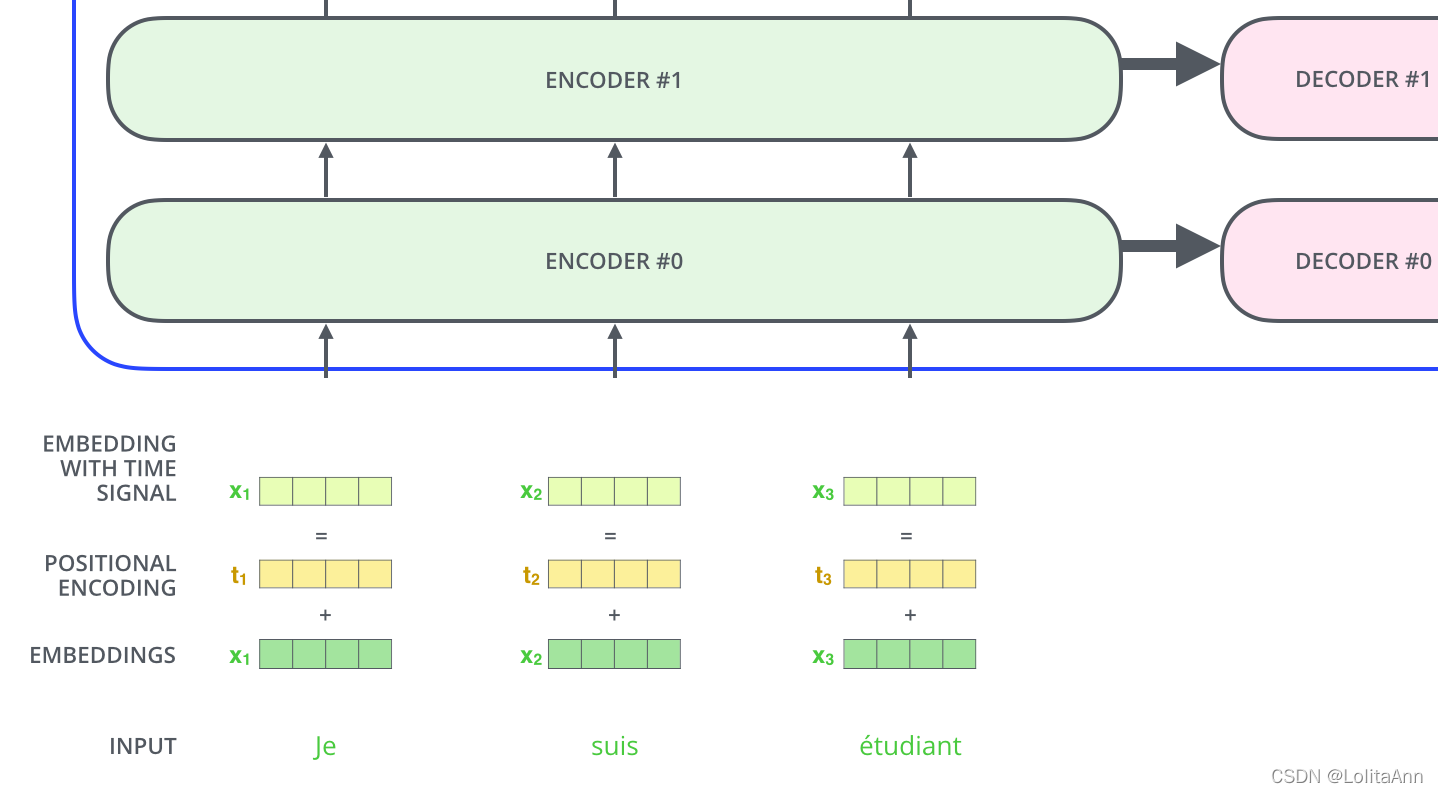
?���ڡ�ʹ��λ�ñ����ʾ���е�λ�á���ϸ����ο�Ӣ��ԭ�ġ�
3.3 ��������һЩϸ������
3.3.1 ������һ��
���,�ڻع�����Transformer�ܹ�֮ǰ,��������һ�±������е�һ��ϸ��:ÿ���������е�ÿ���Ӳ�(��ע�����㡢ǰ��������)����һ���в�����,֮��������һ�����һ��(layer-normalization)��

�������е�������Ӻ�layer-norm(��������һ��)��ʾ��ͼ������ʾ:

��Ȼ�ڽ������Ӳ���Ҳ��������,���������ڻ�һ���������������ͽ�������Transformer,�Ǿ�����ͼ������:
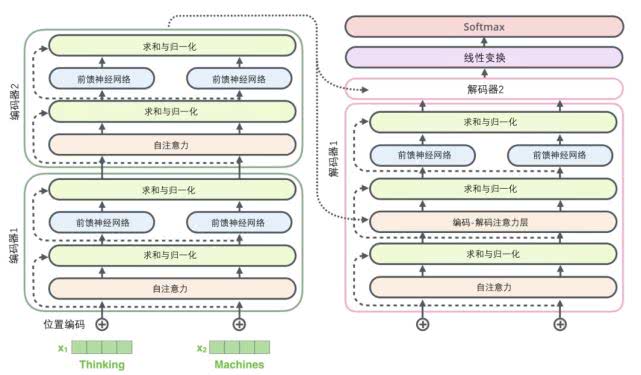
���������Ѿ������˱������Ĵָ���,����encoder��decoder������,����Ҳ�ͻ���֪���˽��������������ι����ġ����,��������ֱ�ӿ������������Эͬ������:
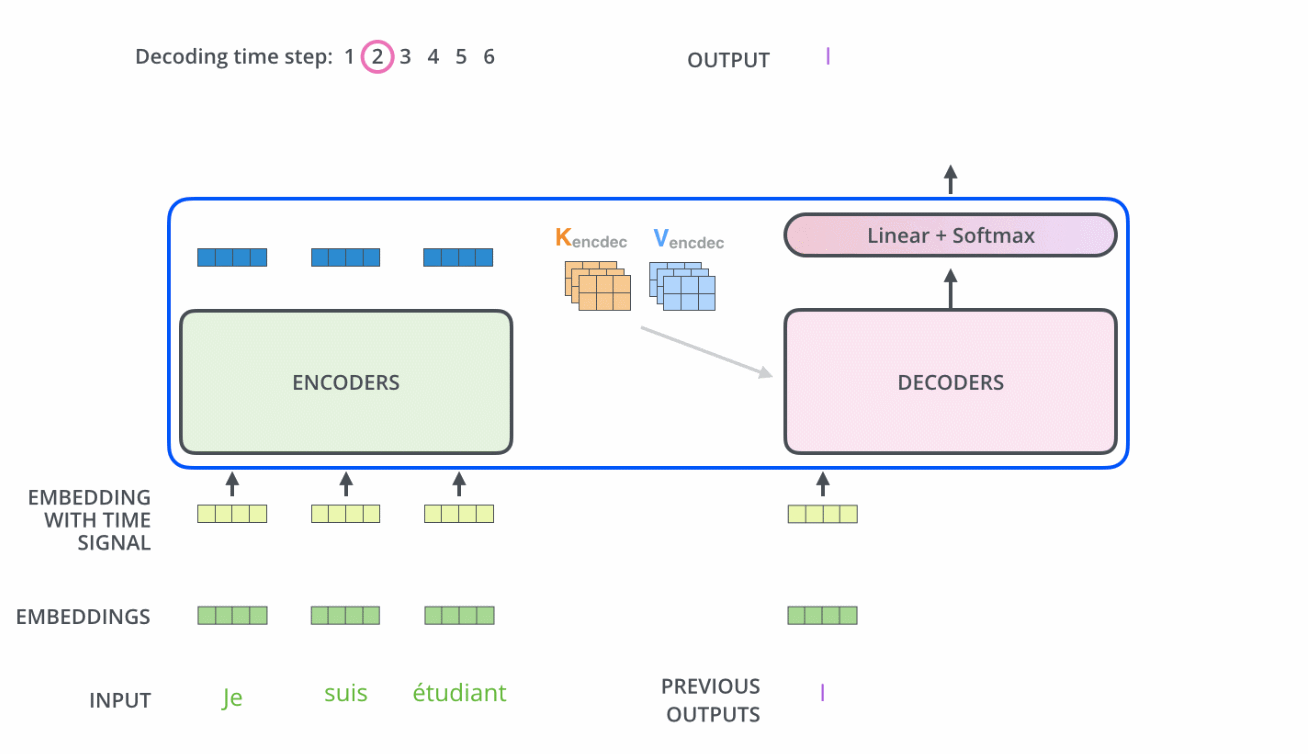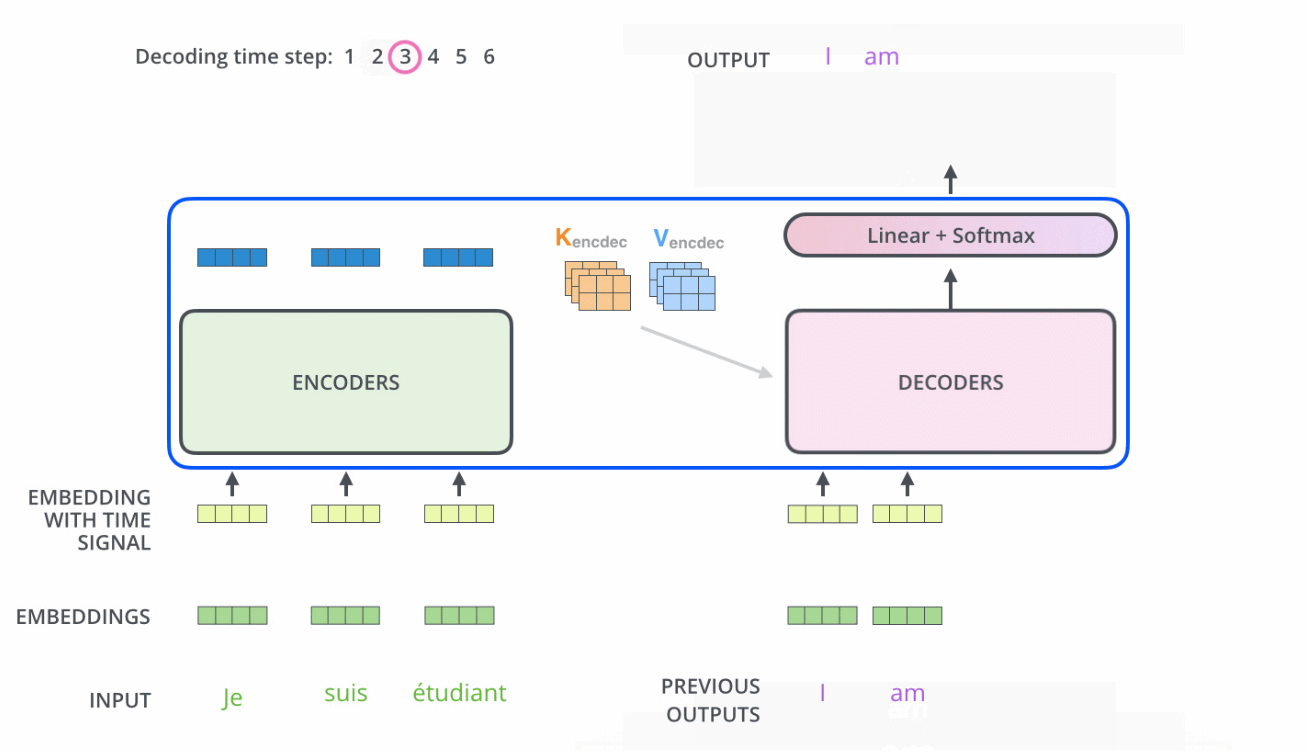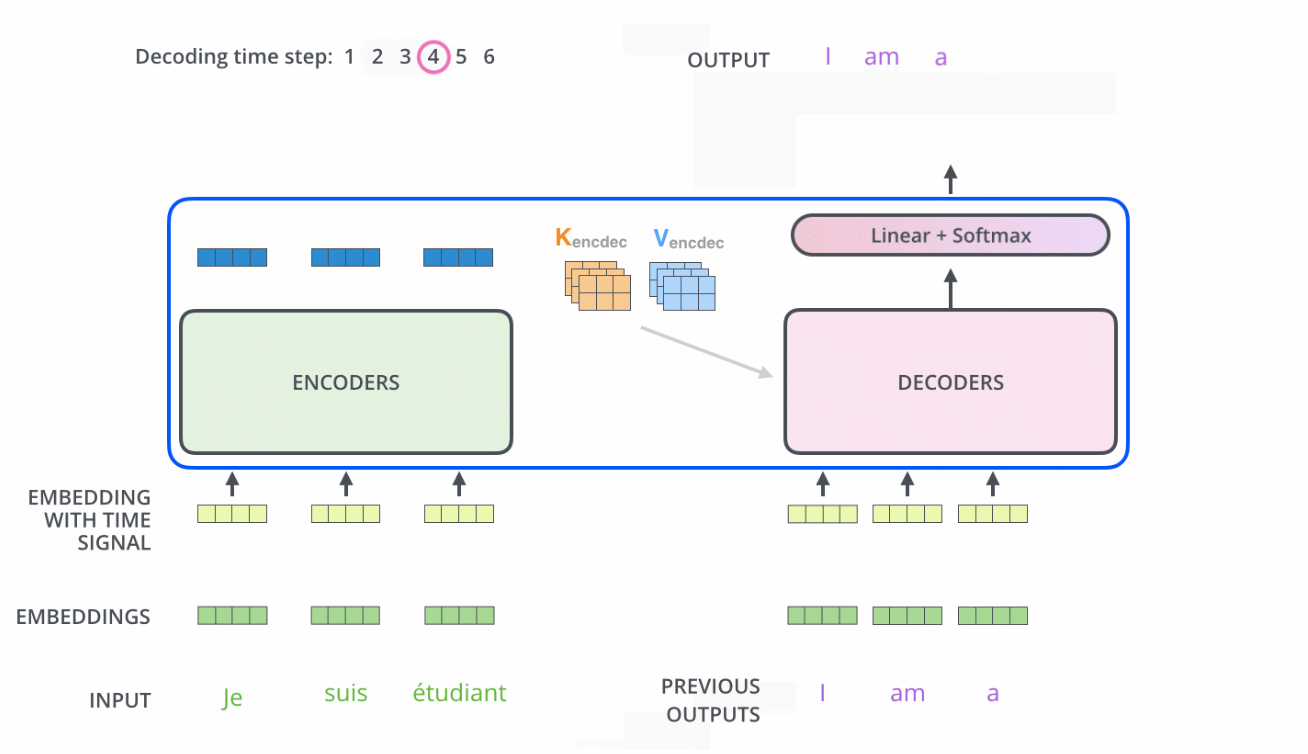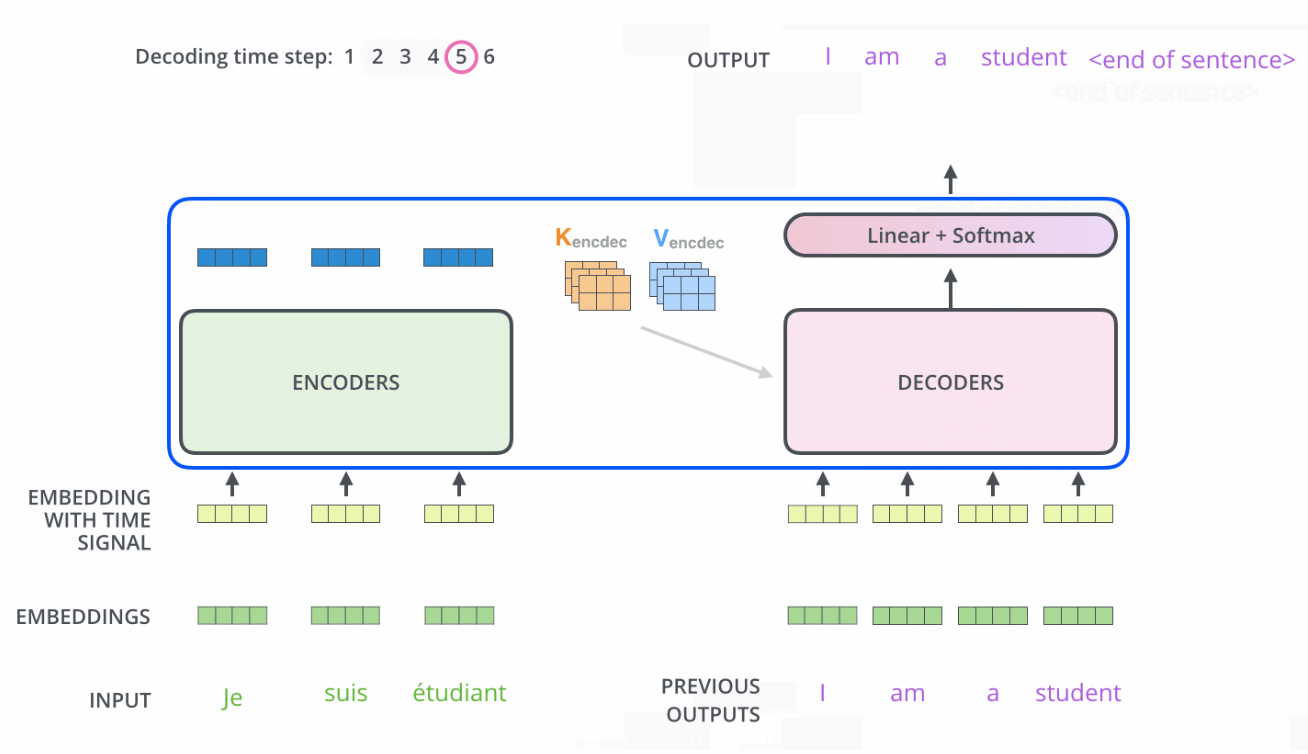
ֵ��һ�����,�������е���ע������ͱ������еIJ�̫һ��:
- Encoder�е�Q��K��Vȫ����������һ�㵥Ԫ�����
- ��Decoderֻ��Q��������һ��Decoder��Ԫ�����,K��V��������Encoder���һ��������Ҳ����˵,Decoder��Ҫͨ����ǰ״̬��Encoder��������Ȩ�غ�,��Encoder�ı����Ȩ�õ���һ���״̬����֮,����������,��ע������ֻ������ע�����λ�õ���Ϣ��ʵ�ַ���������ע�������softmax֮ǰ����mask,��δ���λ�õ���Ϣ��Ϊ��Сֵ��
3.3.2 �������Բ��softmax��
Decoder�������һ������������,��ΰ������һ����?��������һ�����Բ��softmaxҪ�������顣
���Բ����һ����ȫ����������,�������������ɵ�����ӳ�䵽logits�����С�
�������ǵ�ģ�ʹʻ����10000��Ӣ�ﵥ��,�����Ǵ�ѵ�����ݼ���ѧϰ�ġ���logits����ά��Ҳ��10000,ÿһά��Ӧһ�����ʵķ�����
Ȼ��,softmax�㽫��Щ����ת��Ϊ����(ȫ��Ϊ��ֵ,����������1.0),ѡ�����и�������λ�õĴʻ���Ϊ��ǰʱ�䲽�������

3.4 Transformer������ѵ������:Ԥ���������
���������Ѿ��˽���Transformer������ǰ���Ĺ���,�����Ǽ�����һ��ѵ�����̡�
��ѵ���ڼ�,δ��ѵ����ģ�ͻ������ͬ��ǰ�����̡��������������б�ǵ�ѵ�����ݼ���ѵ����,�������ǿ��Խ��������ʵ�ʵ�������бȽϡ�
3.4.1 Ԥ������:�����ʻ��
Ϊ�˱�������,���Ǽ���Ԥ�����εõ��Ĵʻ��ֻ������������(��a��, ��am��, ��i��, ��thanks��, ��student��, ��<eos>��)��
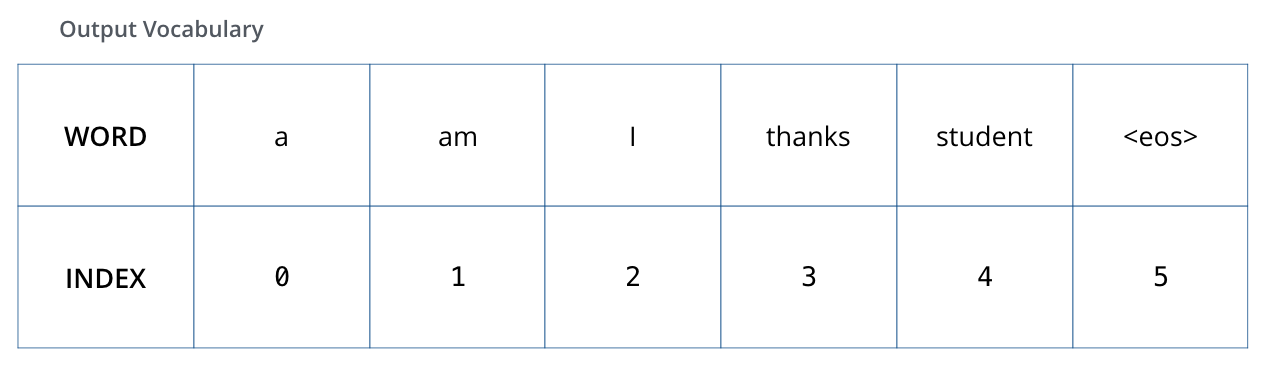
ע������ʻ������Ԥ�����ξʹ�����,��ѵ��֮ǰ���Ѿ��õ��ˡ�
һ�����Ƕ�����˴ʻ��,���ǾͿ���ʹ�ó�����ͬ������(������,one-hot ����)����ʾ�ʻ���е�ÿ�����ʡ�����,���ǿ���������������ʾ���ʡ�am��:
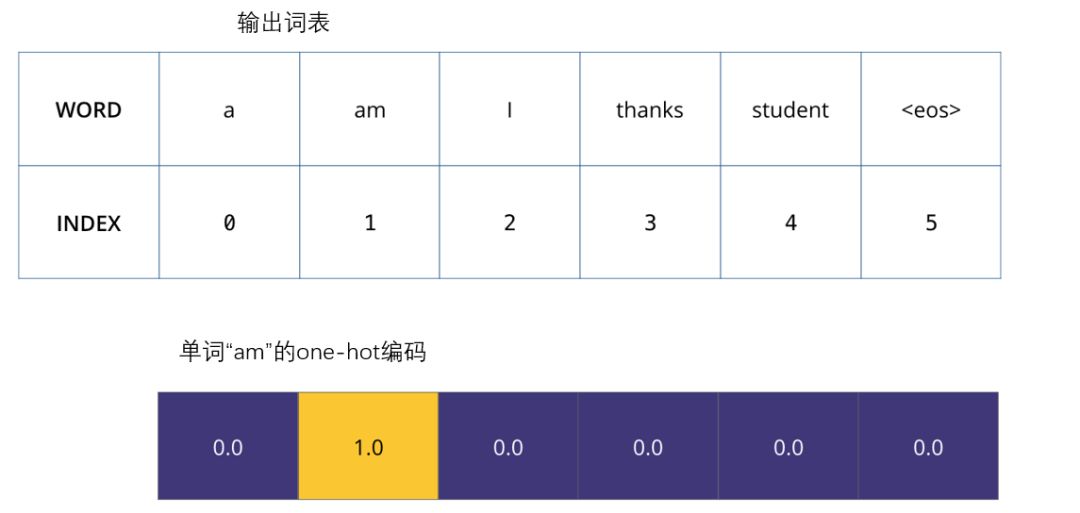
����������������һ��ģ�͵���ʧ����,��ʧ������������ѵ�����Ż�ģ�͵�ָ��,ͨ����ʧ����,���������ǻ��һ��ȷ�ġ�������Ҫ��ģ�͡�
3.4.2 ��ʧ����
����������ѵ���εĵ�һ��,������һ��������(һ�����Ӿ�һ����)��ѵ��ģ��:�ѷ��ĵ��ʡ�merci�������Ӣ�ĵ��ʡ�thanks����
����ζ��,����ϣ������DZ�ʾ��thanks���ĸ��ʷֲ������������ģ�ͻ�û�о���ѵ��,����Ŀǰ����̫����ʵ�֡�
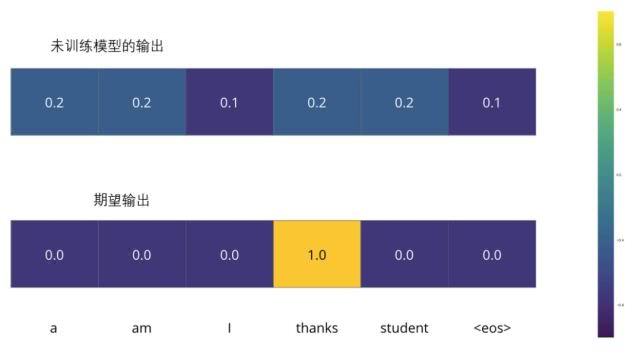
����ģ�͵IJ������������ʼ����,δ��ѵ����ģ��Ϊÿ��������������ĸ��ʷֲ���
���ǿ��Խ�����ʵ��������бȽ�,Ȼ��ʹ�÷�������ģ�͵�Ȩ��(���ڷ����Ľ���,��鿴����:������ⷴ���㷨BackPropagation),ʹ������ӽ���������Ҫ��ֵ��
��αȽ����ָ��ʷֲ�?���������������ֻ�ǽ����������ʵ��Ӧ���е���ʧ������鿴��������ʧ��Kullback�CLeiblerɢ�ȡ�
3.4.3 һ��ʾ��:���ķ����Ӣ��
����ֻ�������һ�����ӡ�����������ʹ��һ���̾���(һ���ʵľ����������������ʵľ�����),�������뷨�� ��je suis ��tudiant��,Ԥ�ڵ�Ӣ�ķ�����Ϊ: ��i am a student����
��������ϣ��ģ�Ͳ���һ�����һ���ʵĸ��ʷֲ���,�ܲ�������������ʷֲ�,��������±�Ҫ��:
- ÿ�����ʷֲ��������ȶ��ʹʻ������һ�������ǵ������дʻ��������6,ʵ�ʲ�����һ����30000��50000��
- �����ǵ������е�һ�����ʷֲ�Ӧ�����뵥�ʡ�i����ص�λ���Ͼ�����ߵĸ���
- �ڶ������ʷֲ����뵥�ʡ�am����صĵ�Ԫ��������ߵĸ���
- �Դ�����,ֱ���������ֲ�ָʾ��<eos>�����š����˵��ʱ���֮��,���ʱ���ҲӦ�ð������硰<eos>������Ϣ,����softmax֮��ָ��<eos>��λ��,��־���������������

��Ӧ����ĵ��ʱ�,���ǿ��Կ��������one-hot����������ѵ��֮����Ҫ�ﵽ��Ŀ�ꡣ
���㹻������ݼ���ѵ��ģ���㹻����ʱ���,����ϣ�����ɵĸ��ʷֲ�������ʾ:

���������ѵ��֮�����յõ��Ľ������Ȼ������ʲ����ܱ���ij�����Ƿ���ѵ����֮�еĴʻ㡣
����������Կ���softmax��һ������,���Ǽ�ʹ�������ʲ����DZ�ʱ�䲽�����,Ҳ����һ����ĸ��ʴ���,��һ���������ڰ���ģ�ͽ���ѵ����
ģ��һ�β���һ�����,����ô���ѡ��������λ��������Ҫ�������?���������ִ�������ķ���:
- һ����̰���㷨(greedy decoding):ģ��ÿ�ζ�ѡ��ֲ�������ߵ�λ��,������Ӧ�ĵ���
- ��һ�ַ�����������(beam search):�����������ǰ��������(����,��I���͡�a��),Ȼ������һ������ѡ������������ߵ�ֵ,�Դ�����,���������ǰ��������Ŀ�������Ϊ2,��Ȼ��Ҳ�����������������������ȡ�
���IJ��� ͨ������BERT: ��Elmo/GPT���������BERT
���������ݻ�����ο��������Ա��Ŀ�ͷ��˵���ſ�����ʦ������,����ĩ�ο�����6:��˵˵NLP�е�Ԥѵ��������չʷ:��Word Embedding��Bertģ����,����������,����Ҫ�㶼�С�
4.1?��Word Embedding��ELMO
4.1.1?Word?Embedding��ȱ��:���������������
�ڱ��ĵĵ�һ������,���ǽ�����word2vec,��ʵ������Ӧ����,word2vec��Ч����û���ر�á�����,Word?Embedding����ʲô����?
��Ƭ��Word?Embeddingͷ�������˺ü����������ʲô?�Ƕ�������⡣
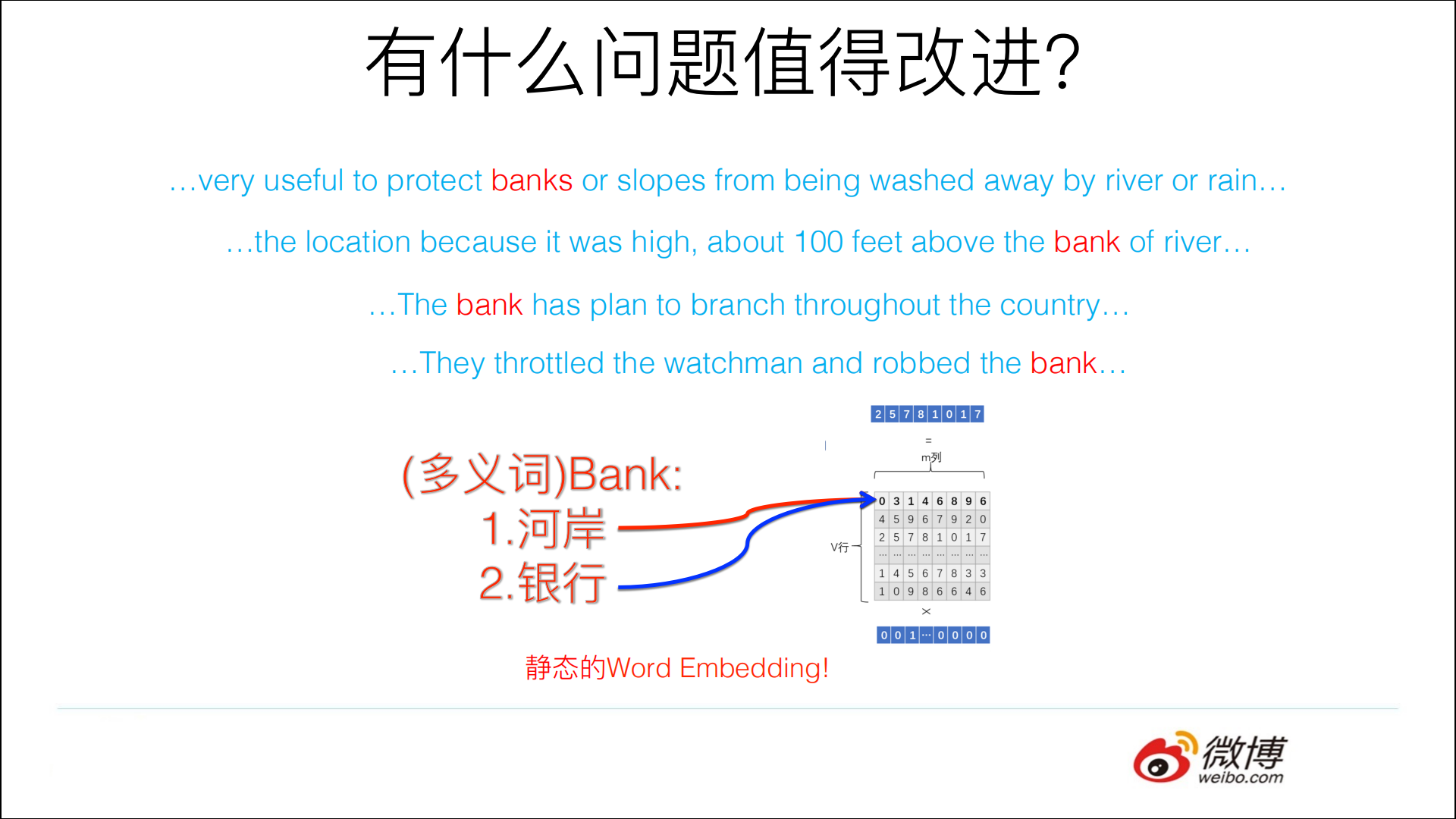
����ͼ��ʾ,��������Bank,���������ú���,����Word Embedding�ڶ�bank������ʽ��б����ʱ��,�����ֲ��������������,��Ϊ���Ǿ��������Ļ����г��ֵĵ��ʲ�ͬ,������������ģ��ѵ����ʱ��,����ʲô�����ĵľ��Ӿ���word2vec,����Ԥ����ͬ�ĵ���bank,��ͬһ������ռ����ͬһ�еIJ����ռ�,������ֲ�ͬ����������Ϣ������뵽��ͬ��word embedding�ռ���ȥ��
����word embedding�����ֶ���ʵIJ�ͬ����,����IJ�������������ƶ������ķ�չ,�ⲻELMO�����ˡ�
4.1.2 ���������Ķ�̬������ELMO:����������Pre-Training?+?˫��˫��LSTM
ELMO�ǡ�Embedding from Language Models���ļ��,���ELMO��������Ŀ:��Deep contextualized word representation�����������侫��,������������?��deep contextualized�������,һ����deep,һ����context,����context���ؼ���
����֮ǰ��wordvec�кα�������?
- �ڴ�֮ǰ��Word Embedding�������Ǹ���̬�ķ�ʽ,��ν��ָ̬����ѵ����֮��ÿ�����ʵı���̶�ס��,�Ժ�ʹ�õ�ʱ��,�����¾��������ĵ�����ʲô,������ʵ�Word Embedding������������ij����ı仯���ı�,���Զ��ڱ���Bank�����,������ѧ�õ�Word Embedding�л���˼������� ,��Ӧ�������˸��¾���,��ʹ����������(������Ӱ���money�ȴ�)���Կ��Կ������������ǡ����С��ĺ���,���Ƕ�Ӧ��Word Embedding����Ҳ�����,�����ǻ���˶������塣
- ��ELMO�ı���˼����:������������ģ��ѧ��һ�����ʵ�Word Embedding,Ȼ������ʵ��ʹ��Word Embedding��ʱ��,�����Ѿ��߱����ض�����������,���ʱ�������Ը��������ĵ��ʵ�����ȥ�������ʵ�Word Embedding��ʾ,���������������Word Embedding���ܱ���������������еľ��庬��,��ȻҲ�ͽ���˶���ʵ������ˡ�
����ELMO�����Ǹ����ݵ�ǰ�����Ķ�Word Embedding��̬������˼·��

�������,ELMO�����˵��͵����ι���:
- ��һ��������������ģ�ͽ���Ԥѵ��
��ͼ��˵�ǰ��˫��LSTM���������������,������Ǵ�����˳��ij���Ԥ�ⵥ���������Context-before,�Ҷ˵�����˫��LSTM���������������,������Ǵ��ҵ��������ľ�������Context-after
ͬʱ,ÿ������������ȶ�������LSTM���� - �ڶ�������������������ʱ,��Ԥѵ����������ȡ��Ӧ���ʵ���������Word Embedding��Ϊ���������䵽����������
��ͼչʾ������Ԥѵ������,��������ṹ������˫��˫��LSTM(����LSTM��ɶ����,����ͨ���ο�����3�ع���),˫��LSTM���Ը�ɶ?�������ݵ��ʵ�������ȥԤ�ⵥ��,�Ͼ����ֻͨ������ȥԤ�ⵥ�ʸ�ȷ��
��ʱ��ͬѧ��������,ELMO����˫��ṹ�����ܿ�����ҪԤ��ĵ�����ô,�㶼�ܿ����ο�����,����Ӱ������ģ��ѵ����Ч����ȷ��,��Ϊ��������ʱ���Ųο�������ġ�����,�ɾ�����ELMO���õ�˫��ṹ�ǻ���LSTM��,������LSTM֮���Ƕ�����,�Ӷ��������������!
ELMO�������ṹ��ʵ��NLP���Ǻܳ��õġ�ʹ���������ṹ���ô�������������ģ���������Ԥ��ѵ�����������,���ѵ������������,������һ���¾���,������ÿ�����ʶ��ܵõ���Ӧ������Embedding:
- ��ײ��ǵ��ʵ�Word Embedding;
- �������ǵ�һ��˫��LSTM�ж�Ӧ����λ�õ�Embedding,�����뵥�ʵľ䷨��Ϣ����һЩ;
- ���������ǵڶ���LSTM�ж�Ӧ����λ�õ�Embedding,�����뵥�ʵ�������Ϣ����һЩ��
Ҳ����˵,ELMO��Ԥѵ�����̲�����ѧ�ᵥ�ʵ�Word Embedding,��ѧ����һ��˫��˫���LSTM����ṹ,�������ߺ��涼���á�

Ԥѵ��������ṹ��,��θ���������ʹ����?��ͼչʾ�����������ʹ�ù���,�������ǵ�����������Ȼ��QA����,��ʱ�����ʾ�X
- �����Ƚ�����X��ΪԤѵ���õ�ELMO���������
- ��������X��ÿ��������ELMO�����ж��ܻ�ö�Ӧ������Embedding
- ֮�����������Embedding�е�ÿһ��Embeddingһ��Ȩ��a,���Ȩ�ؿ���ѧϰ����
- ���ݸ���Ȩ���ۼ����,������Embedding���ϳ�һ��
- Ȼ�����Ϻ�����Embedding��ΪX�����Լ�������Ǹ�����ṹ�ж�Ӧ���ʵ�����,�Դ���Ϊ���������������������ʹ��

������ͼ��ʾ��������QA�еĻش����Y��˵Ҳ����˴�������ΪELMO�������ṩ����ÿ�����ʵ�������ʽ,������һ��Ԥѵ���ķ�������Ϊ��Feature-based Pre-Training����
���������ij�������ͣЪ,��ôվ���������ʱ��ڵ㿴,ELMO��ʲôֵ�øĽ���ȱ����?
- ����,һ���dz����Ե�ȱ����������ȡ��ѡ����,ELMOʹ����LSTM�������¹�Transformer,�Ͼ��ܶ��о��Ѿ�֤����Transformer��ȡ������������ҪԶǿ��LSTM
- ����һ��,ELMO��ȡ˫��ƴ�������ں��������������ܱ�BERTһ�廯���ں�������ʽ��
�����ڶ���ָ���dz�����ELMOΪ���������ֻ��������ںϵ�Ԥѵ��������,NLP�ﻹ��һ�ֵ�������,һ�㽫���ַ�����Ϊ������Fine-tuning��ģʽ��,��GPT������һģʽ�ĵ��Ϳ����ߡ�
4.2 ��Word Embedding��GPT
4.2.1 ����ʽ��Ԥѵ��֮GPT:Ԥѵ�� +?Fine-tuning + ����Transformer
GPT�ǡ�Generative Pre-Training���ļ��,�����ֿ��京����ָ������ʽ��Ԥѵ����
GPTҲ�������ι���,��һ��������������ģ�ͽ���Ԥѵ��,�ڶ���ͨ��Fine-tuning��ģʽ�����������
��ͼչʾ��GPT��Ԥѵ������,��ʵ��ELMO�����Ƶ�,��Ҫ��ͬ��������:
- ����,������ȡ�������õ�LSTM,�����õ�Transformer,�Ͼ�����������ȡ����Ҫǿ��LSTM,���ѡ��������Ǻ����ǵ�;
- ���,GPT��Ԥѵ����Ȼ��Ȼ��������ģ����ΪĿ������,���Dz��õ��ǵ��������ģ��
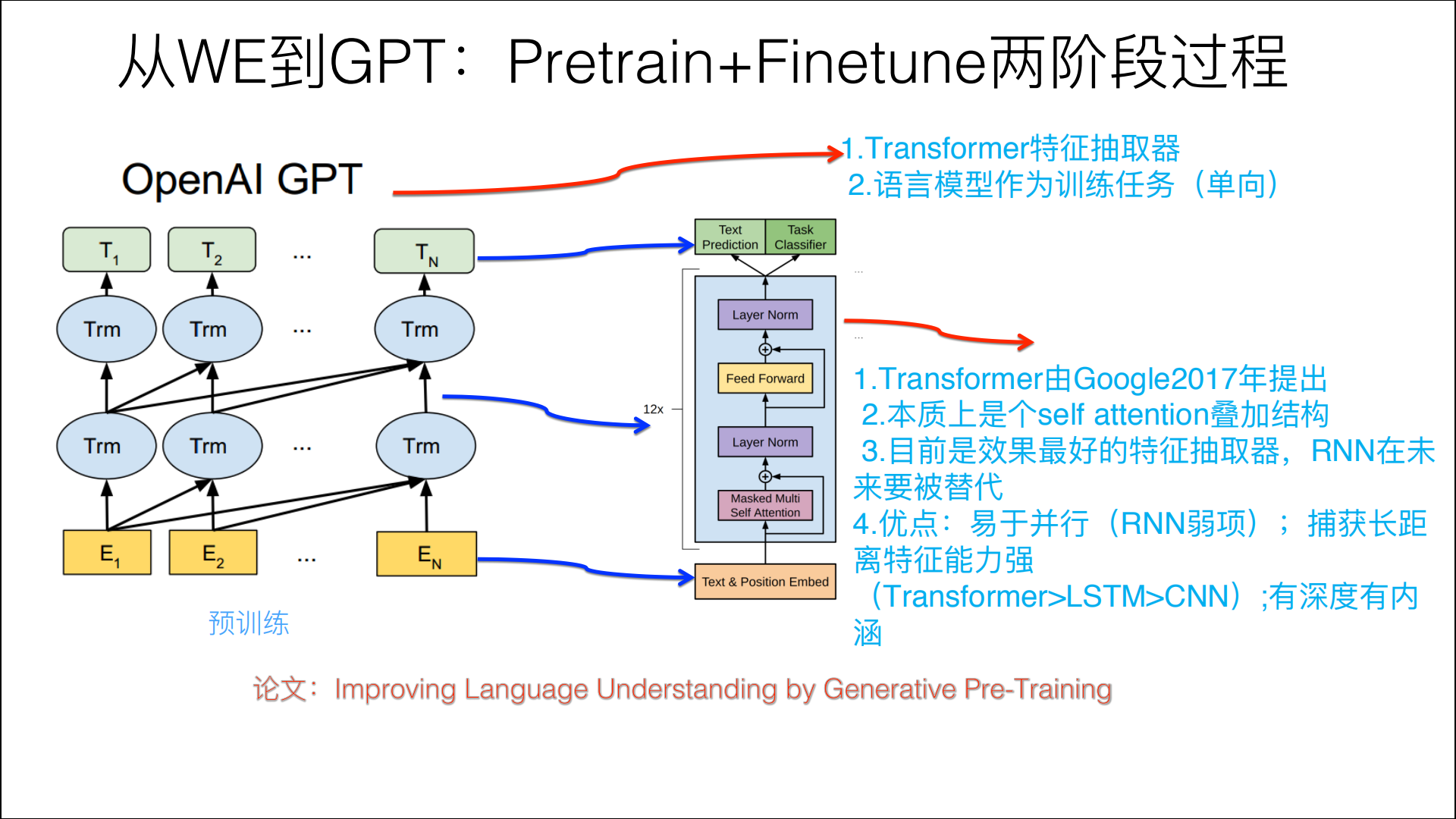
ELMO��������ģ��Ԥѵ����ʱ��,Ԥ�ⵥ�ʿ���ͬʱʹ�����ĺ�����,�õ�˫��LSTM�ṹ,��GPT��ֻ���õ��ʵ����������е���Ԥ��,���������ġ�˵�˻�,�������������ʾ���,������,�ǵ������
ʲô�ǵ���Transformer?��Transformer��������,�ᵽ��Encoder��Decoderʹ�õ�Transformer Block�Dz�ͬ�ġ���ô����ͬ?ͨ�����ĵ������ֶ�Transformer�Ľ��ܿɵ�֪:
- Encoder��ΪҪ������������,����ÿ���ʶ���Ҫ���������ĵĹ�ϵ������ÿ�����ڼ���Ĺ����ж��ǿ��Կ������������еĴʵ�;
- ����Decoder��Seq2Seq�еĽ���������,ÿ���ʶ�ֻ�ܿ���ǰ��ʵ�״̬,������һ�������Self-Attention�ṹ
����֮,�ڽ���Decoder Block��,ʹ����Masked Self-Attention,�������е�ÿ����,��ֻ�ܶ����Լ����ڵ�ǰ�����дʽ���Attention,����ǵ���Transformer��
��GPTʹ�õ�Transformer�ṹ���ǽ�Encoder�е�Self-Attention�滻����Masked Self-Attention,�Ӷ�ÿ��λ�õĴʿ���������Ĵ���
Julyд������,��ϲ����ϸ�� �������������,�ʰﱾ�ĵĶ��߷���������
�������˿���������������,��Ȼ�����Ѿ�ȷ��ͨ��������Ԥ�ⵥ�ʿ��Ը�ȷ,Ϊ��GPT����������ֻͨ������Ԥ�ⵥ����?
GPT���п��Ե�
- ����,GPT��������ȡ����LSTM�����˸�ǿ��transformer,�˾��Ѿ����Ǵ�����(GPT֮���ģ�Ͷ���ʼ��Transformer��������ȡ��)
- ����ʱ�����Transformer�Ľṹ��ȡ������ȥ������Ԥ��,�Ǿ��Ʊ�����Transformer˫��ṹ,��Transformer����ELMO��˫��LSTM�ṹ֮��˴˶���������see itself,��˫��Transformer�����see itself ��!
���������,��Ϊ����ԭ����Ҫѵ��ģ�͵�Ԥ������,�������ͨ��˫��Ƕ����Ľṹ���ܿ����м�Ҫ��Ԥ��ĵ��ʡ���������(���統����ǰ��Ĵ������Ԥ����һ���ʵ�ʱ��,��������һ������ÿ����,��Ʒ����ϸϸƷ,�ٸ�����,Ԥ��a b c d f,һ��ʼ�����������Ԥ��ڶ�λ�� ����λ�� ����λ�õĴ�:b c d,Ȼ�����������Ԥ��ʱ,���������:����λ�� ����λ�� �ڶ�λ�õĴ�:d c b),������ɶ��Ԥ��?- ��������Ȩ��,�ŵ���GPT����Transformer��˫��ṹ,����Transformer�ĵ���ṹ
���潲����GPT��ν��е�һ�ε�Ԥѵ��,��ô����Ԥѵ����������ģ��,��������������ô��?�����Լ��ĸ���,��ELMO�ķ�ʽ���в�ͬ��

��ͼչʾ��GPT�ڵڶ������ʹ��:
- ����,���ڲ�ͬ������������˵,�����������������Լ�������ṹ,���ڲ�����,��Ҫ��GPT������ṹ����,�����������ṹ����ɺ�GPT������ṹ��һ����
- Ȼ��,�������������ʱ��,���õ�һ��Ԥѵ���õIJ�����ʼ��GPT������ṹ,����ͨ��Ԥѵ��ѧ��������ѧ֪ʶ�ͱ����뵽����ͷ������������,���Ǹ��dz��õ�����
- �ٴ�,���������ͷ������ȥѵ���������,�������������Fine-tuning,ʹ�����������ʺϽ����ͷ������
��ȻGPT�������õ�Transformer�Ľṹ,���������,�ɹ����۲����������Dz�������������,��������Կ��²ο�����10�����ӡ�
4.3 �������֮BERT:˫��Transformer���GPT
4.3.1 BERTģ�͵ļܹ�:Ԥѵ�� + Fine-Tuning + ˫��Transformer
���Ǿ�����ɽ��ˮ,���ڵ���Ŀ�ĵ�BERTģ���ˡ�GPT-2��ʹ�á�Transformer���������Decoderģ�项������,�� BERT����ͨ����Transformer˫�������Encoder?ģ�项������:
- BERT���ú�GPT��ȫ��ͬ������ģ��,����������ģ��Ԥѵ��,�����ʹ��Fine-Tuningģʽ�����������
- ��GPT������Ҫ��ͬ������Ԥѵ���β���������ELMO��˫������ģ��,��Ȼ����һ��������ģ�͵����ݹ�ģҪ��GPT��
��������BERT��Ԥѵ�����̲��ضི�ˡ�

�ڶ���,Fine-Tuning��,����ε�������GPT��һ���ġ�
4.3.3 BERT��GPT��ELMO��Word2Vec���ߵ���ͬ

���������ǿ����������¼���ģ��֮����ݽ���ϵ������ͼ�ɼ�,BERT��ʵ��ELMO��GPT����ǧ˿���ƵĹ�ϵ:
- ����������ǰ�GPTԤѵ���λ���˫������ģ��,��ô�͵õ���BERT;
- ��������ǰ�ELMO��������ȡ������Transformer,��ô����Ҳ��õ�BERT
˵����,BERT�ۺ���ELMO��˫��������GPT��Transformer������ȡ����,���ؼ�������
- ��һ����������ȡ������Transformer
- �ڶ�����Ԥѵ����ʱ�����˫������ģ��

?4.3.4 BERT���������µ�:Masked����ģ����Next Sentence Prediction
ͨ��֮ǰ���ݵĶദʾ��,�������ѵ�֪,Ԥ��һ������ֻͨ������Ԥ�ⲻһ��ȷ,ֻ�н�ϸôʵ�������Ԥ��ôʲ��ܸ�ȷ��
��ô����������:����Transformer��˵,��������������ṹ����˫������ģ��������?

�ܼ�,�������Word2Vec��CBOW����:������ҪԤ�ⵥ�ʵ�����Context-Before������Context-afterȥԤ�ⵥ�ʡ�
�����������ܽᡢ�Ա���ELMO��GPT��BERTԤ���м�ʵIJ�ͬ:
- ������4.1.2����˵,ELMO����˫��LSTM�ṹ,��Ϊ����LSTM�ṹ֮���ǻ��������,���Կ��Ը���������Ԥ���м��
- ������4.2.1����˵,GPT������һ������:��������Ԥ����һ������ʱ,Ҫ��Pre-TrainingԤ����һ���ʵ�ʱ��ֻ�ܹ�������ǰ�Լ�֮ǰ�Ĵ�,��Ҳ��GPT����ԭ��Transformer��˫��ṹת�����õ���ṹ��ԭ�Ӷ��˾�Ҳ�;�����GPTֻ�ܸ�������Ԥ����һ������..
- ��BERTû����GPTһ����ȫ����������Ϣ,���Dz�����˫���Transformer����?!����������Ҫ����:��˫��Transformer�ṹ�Ļ�,���͵�������4.2.1��˵���ġ��������ο���,Ҳ���ǡ�see itself����������ô?
�����Ⱑ!BERTԭʼ������Ҳ�ᵽ�����:����Ϊ˫����������ÿ���ʼ�ӵ� �������Լ�/see itself��,�Ӷ�ģ���ڶ���������п���ʮ������Ԥ��Ŀ��ʡ�,��BERT�õ�˫��Transformer�ṹ,���DZ˴˶�����˫��LSTM�ṹ,��զ����?
���BERTֻ��һ�����ӻ�,û���κδ���,��ֻ��ע��BERTƽ��������,Ҳ�Ͳ�������Ŀǰ����֪��BERT�ˡ���BERTǿ��ǿ�ڳ��˼�������֮��,��������������:һ����������ָ����Masked ����ģ��,һ����Next Sentence Prediction��
����������һ�����µ�,��ʲô�ǡ�Masked Language Model(MLM)��?��νMLM��ָ��ѵ����ʱ���漴������Ԥ����mask��һЩ����,Ȼ��ͨ����������Ԥ��õ���,������dz���ѵ��һ����ѧ����������յ�������
Ҳ����˵
|
��!����,ֱ�ӽ������Ĵ��滻Ϊ<MASK>��ǩ���ܻ����һЩ����,ģ�Ϳ��ܻ���Ϊֻ��ҪԤ��<MASK>��Ӧ���������,����λ�õ����������ν��ͬʱFine-Tuning�ε����������в�û��<MASK>��ǩ,Ҳ�����ݷֲ���ͬ�����⡣
Ϊ�˼�������ѵ��������Ӱ��,BERT���������µķ�ʽ:�������������ѡ��15%�Ĵ�����Ԥ��,��15%�Ĵ���
- 80%�Ĵ���������ʱ���滻Ϊ<MASK>,����my dog is hairy -> my dog is [mask]
- 10%�ĴʵĴ�����������ʱ���滻Ϊ�����ʵĴ�����,����my dog is hairy -> my dog is apple
- ����10%���ֲ���,����my dog is hairy -> my dog is hairy
����һ�����൱�ڸ���ģ��,�ҿ��ܸ����,Ҳ���ܲ������,Ҳ���ܸ������Ĵ�,��<MASK>�ĵط��һ�����Ĵ�,û<MASK>�ĵط���Ҳ���ܼ����Ĵ�,����<MASK>��ǩ������˵û��ʲô��������,�����������,�㶼Ҫ�ú�Ԥ������λ�õ������
����BERT���ڶ������µ�:��Next Sentence Prediction��,���������жϾ���B�Ƿ��Ǿ���A������,����ǵĻ������IsNext��,���������NotNext��,�����ϵ������BERT�����ʾͼ�е�[CLS]�����С�

����ѵ�����ݵ����ɷ�ʽ�Ǵ�ƽ�������������ȡ�����仰:
- ����50%��ѡ�����Ͽ�������˳����������������,����IsNext��ϵ
- ����50%�ǵڶ������Ӵ����Ͽ������ѡ���һ��ƴ����һ�����Ӻ���,���ǵĹ�ϵ��NotNext
�൱������Ҫ��ģ�ͳ�����������Masked����ģ��������,�������������ӹ�ϵԤ��,�жϵڶ��������Dz�������ǵ�һ�����ӵĺ������ӡ�
֮������ô��,�ǿ��ǵ��ܶ�NLP�����Ǿ��ӹ�ϵ�ж�����,����Ԥ�����ȵ�ѵ�������˾��ӹ�ϵ����㼶,��������������������ξ��ӹ�ϵ�ж��������Կ��Կ���,����Ԥѵ���Ǹ����������,��Ҳ��BERT��һ�����¡�
��ͼ������ʦ�ŶӴ�ǰ���������ݺͿ�Դ��BERT��Ԥѵ��ʱ��������һ������ѵ��ʵ��,���п�����������潲��masked����ģ�ͺ��¾�Ԥ������,ѵ�����ݾͳ��������ӡ�

4.3.5 BERT�����롢������ֵĴ���
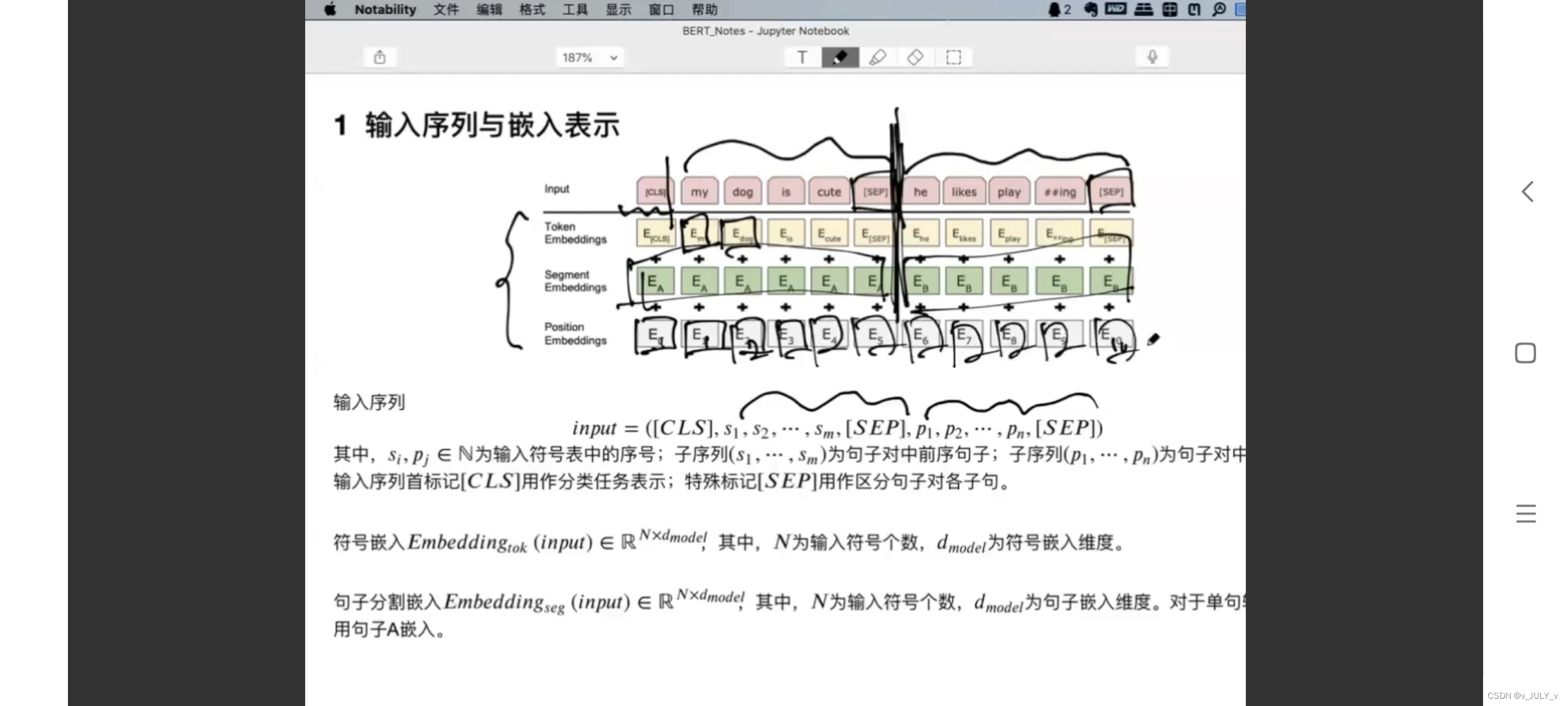
BERT�����벿���Ǹ���������,��������֮��ͨ���ָ�����SEP���ָ�,��ǰ������ʼ��ʶ��CLS��,ÿ������������embedding:
- ����embedding,�����������֮ǰһֱ�ᵽ�ĵ���embedding,ֵ��һ�����,�еĵ��ʻ��ֳ�һ�����Ĺ����Ӵʵ�Ԫ,������ͼʾ���С�playing������ֳ��ˡ�play���͡�ing��;
- ����embedding,����������������,����B�Ƿ���A������(�Ի�����,�ʴ���);
- λ����Ϣembedding,������ǰ��˳��,��ɾ��ӵĵ���Ҳ��ǰ��˳��,����ͨ˳�������¾�����ɢ���ʶ��������,���Ե���˳���Ǻ���Ҫ������,Ҫ��λ����Ϣ���б���

�ѵ��ʶ�Ӧ������embedding����(û��,ֱ�����),���γ���BERT�����롣

����BERT��Ԥѵ����������������֯,���Բο���ͼ��ע�͡�

����˵��BertЧ���ر��,��ô������ʲô������������?����ͼ��ʾ,�Ա��������֤��,��GPT���,˫������ģ����������Ҫ������,������Щ��Ҫ�������ĵ�������˵������ˡ���Ԥ���¸�������˵������������˵Ӱ�첻��̫��,��������������ȱȽϸߡ�
4.3.6 BERT�ܽ�������:������ģ����Ƶļ������
BERT�ĺ�ճ�������Ҳ��NLPģ�Ͳ��Ϸ�չ���ݱ�Ľ��,��ο�����7���ܽ��:
- ���ڵ�NLPģ�ͻ��ڹ���������,����ר��ϵͳ,���ַ�ʽ��չ�Բ�,��Ϊ��ͨ��������д���й���
- ֮������˻���ͳ��ѧ����Ȼ���Դ���,������Ҫ�ǻ���dz�����ѧϰ���NLP���⡣����,ͨ�������Ʒ�ģ�ͻ������ģ��,ͨ�����������CRF���д��Ա�ע�������ȥ��StandFord��NLP����,���洦����������ڷ���,�����������
- �����ѧϰ��ͼ��ʶ������õ����ٷ�չʱ,����Ҳ��ʼ�����ѧϰӦ����NLP����
������Word Embedding�������Կ����Ƕԡ�������������ȡ�õ��IJ���,��Ҳ�����ѧϰ�ĸ�������,�����������Word2Vec,GloVe������Ԥѵ���Ĵ�����,��Ϊ�Ե��ʵ���������,�������ѧϰģ�͡�
�����RNN��RNNʹ�����������ʱ�������,�������Էdz��ʺϽ��NLP���ִ����֮����˳������⡣����,���ѧϰ�����ݶ���ʧ����,����RNN����������,�������������LSTM/GRU�ȼ���,�Խ�������ݶ���ʧ���⡣��2018����ǰ,LSTM��GRU��NLP������ռ���˾���ͳ�ε�λ��
��ʱRNN�и�����������,����ѵ����,�����д���,���������䷢չ�����������뵽���Ƿ������CNN���RNN,�Խ��������⡣���������������1D CNN�����NLP���⡣�������ַ�ʽҲ�и���������,���Ƕ�����RNN��ʱ�����ơ�
����ʱ������,���ǻ����ò�������һ���ؼ�����,��ע����Attention��Attention��������ͼ��ʶ������,Ȼ���ٱ�����NLP����
����Attention����,���Ǽ����¼����ȿ��Ա�֤���д���,�ֿ��Խ��ʱ�����⡣����Transformer�ڿճ�������Ҳ��BERT�Ļ���֮һ��
����֮��,ELMO�����Ԥѵ��˫������ģ���Լ�GPT����ĵ���TranformerҲ������˫��Transformer��չ�Ļ���,�ڡ�Attention Is All You Need��һ��,Transformer����������һ���߶ȡ�
BERT�����ۺ�������Щ��������ķ���(Ԥѵ�� + Fine-Tuning + ˫��Transformer,�ټ������������µ�:Masked����ģ�͡�Next Sentence Prediction),���Խ��NLP�д����⡣
�������BERT��ϸ�ڿ��Բ鿴BERTԭʼ����(�ο�����12),�����BERTԭʼ���ĵĽ����BERT�ļ�ʵ��,��ο��ο�����13��
�����
- ����һţ��Jay Alammarд��?ͼ��Word2Vec(������Ӣ��ԭ��,�ɿ��������)..
- Encoder-Decoder �� Seq2Seq
- ����δ�RNN��,һ��һ��ͨ������LSTM��,July
- �����ѧϰ�е�ע��������(2017��)��,�ſ���
- ����Jay Alammarд��ͼ��transformer(������Ӣ��ԭ��,�ɿ���:�����1)
-
��The Illustrated GPT-2 (Visualizing Transformer Language Models)��(�����1?�����2)
-
BERTԭʼ���ļ���һ����汾�Ķ����Ķ�,ע�ⷭ����ЩС����,���Խ�������Ķ�
-
NLP�²�ʿ:Transformerͨ��������ȡ��,������������������ֵ����ϸѧϰ
- ������ⷴ���㷨BackPropagation
- ����������ģ��:��word2vec��glove��ELMo��BERT
���
��10.19����,�����ճ�������ȥ��У̸������,ÿ��1/3��ʱ�䶼��д��ƪBERT�ʼ�(����+����һ����Сʱ,ÿ�����)�����Ĺ�����,��Ϊ���ֲ�������,�Լ�֮ǰһЩ�Ƚ�ģ����ϸ����������
���ʼǵı�д�������Է�Ϊ�����:
- ��һ���,����ͨ��,Ϊ�˾����ܰѱ��ʼ�дͨ��,�ʲο������ϸ�������,����Ϊ��д�ij��ڶ����ģ�͵���������ر���̵�����ͨ��ȫ��������,��������ԽдԽ��,����3.6����;
- �ڶ���,��������,ͨ����˾��������������������Ƶ������������ģ�͵�Ҫ��(��Щ��Ƶ����ϸ���������и��ݽ��֮��,����ο�����13��14),�Űѱ���ƪ������ס��,���ս���3��������
��ֹ������10.24,���Ļ�ֻ�dz���,δ��һ����,���Ļ���ж��ִ���;δ��һ����,���Ļ���ж�������;δ��һ����,���Ļ���ж���С�ޡ������Ǿ仰,�߾�ȫ��,�ñ��ij�Ϊÿһ����ѧ�߶��ܿ���ȥ����ȫ������ͨ�ױʼ�,�����ڸ��ֿ��Ƕ��ж��Ķ���
��ɶ����,��ӭ��ʱ���Ի�ָ��,thanks��