����Ŀ¼
- Word2Vec
- ����ԭ��
- ����
- word2vec���Ż�,�����㼶softmax�ĸ��Ӷ�
- word2vector������ʱΪʲôҪ��Ƶ����3/4�η�?
- �������еĴ���ѡ�����?����ѡ��5,10,15����ʲô������?�Dz���Խ��Խ����?
- word2vector �����������?����ȫ�ֲ���?������batch����?���ʵ�ֶ�batch����?
- ��ôȷ����������ɵ�������?
- W2V�������������߸�����֮��,ģ����ԭģ�����,�ǵȼ۵Ļ������Ƶ�?
- ����1:����һ��word2vec?
- ����2:�Ա� Skip-gram �� CBOW
- ����3:�Ա� HS �� ������
- ���� 4:������ΪʲôҪ�ô�Ƶ������������?
- ���� 5:Ϊʲôѵ���������״�����,Ϊʲôһ��ֻ��ǰһ��?
- ���� 6:�Ա��������ʹ�����
- ���� 7:Ϊʲô������/�ֲ�softmax�ܼӿ�ѵ��
- ����8:word2vec��ȱ��
- ����9:hsΪʲô�û�����������������������?
- ����10:Ϊʲô�õ������Լ����?
- LSTM
- NLP �г��õ�������ǿ����?
Word2Vec
����ԭ��
1. CBOW(Continuous Bag-of-Words) �����ʴ�ģ��
CBOW ����˵,����ͨ��������,��Ԥ���м�Ĵʡ�
�������������Ĵ�Сȡ 4 ,�ض���������ǡ�learning��,������ʾ:
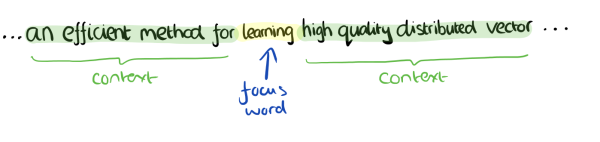
CBOW ʹ�õ��Ǵʴ�ģ��,�������İ˸��ʶ���ƽ�ȵ�,Ҳ���Dz���������ʺ�Ŀ���֮���λ��,ֻҪ������������֮�ڼ��ɡ�
������������Ż��Ļ�,��Ŀ��λ�õ�Ԥ��������֪���дʵĸ���
2. skip-gram ����ģ��
skip-gram ����˵����ͨ��һ����,��Ԥ�������ġ�
������һ����,�����Ż��Ļ�,��������Ĵʵĸ���
skip-gram �� CBOW ��һ�ֻ����Ĺ�ϵ,ѵ����ʱ���ѡһ���ɡ�
��ϵ����:
ȱ��:
�������ַ������� softmax ������ʵ�ʱ��,��ΪҪ��ÿһ���ʵĸ��ʽ���Ԥ��,����ʿ�����һ���м������,�������ܴ�,�dz���ʱ,������Ҫ�����Ż���
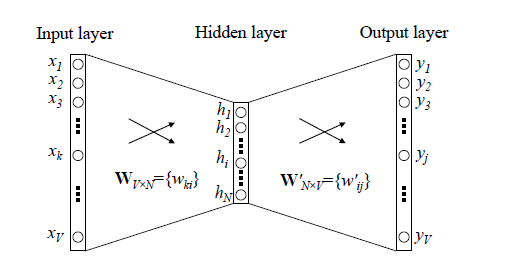
3. Hierachical softmax(�㼶 softmax)
��ͳ��������ģ��һ��������,�����(������),���ز�������(softmax),�ṹ����ͼ��ʾ���������������������ز㵽������softmax��ļ������ܴ�
word2vec�Դ�ͳ��������ģ�����˸Ľ�,����,���ڴ�����㵽���ز��ӳ��,û�в�ȡ����������Ա任�Ӽ�����ķ���,���Dz��üĶ����������������Ͳ�ȡƽ���ķ��������������������4ά������:(1,2,3,4),(9,6,11,8),(5,10,7,12)(1,2,3,4),(9,6,11,8),(5,10,7,12),��ô����word2vecӳ���Ĵ���������(5,6,7,8)(5,6,7,8)�����������ǴӶ�������������һ����������
�ڶ����Ľ����Ǵ����ز㵽�����softmax������ļ��������Ľ���Ϊ�˱���Ҫ�������дʵ�softmax����,word2vec�����˻�����������������ز㵽���softmax���ӳ�䡣
�������ǰ�֮ǰ���ж�Ҫ����Ĵ����softmax��ĸ��ʼ�������һ�Ŷ����������,��ô���ǵ�softmax���ʼ���ֻ��Ҫ�������νṹ���оͿ����ˡ�����ͼ��ʾ,���ǿ������Ż��������Ӹ��ڵ�һֱ�ߵ����ǵ�Ҷ�ӽڵ�Ĵ� w 2 w_2 w2?
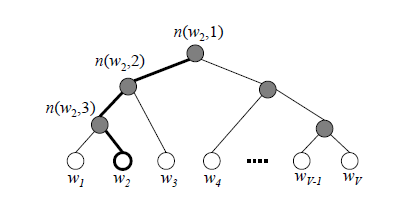
�����������ڲ��ڵ�����֮ǰ���������ز����Ԫ
���ڵ������������ȡƽ��
Ҷ�ӽڵ�������softmax��������Ԫ
Ҷ�ӽڵ�ĸ������Ǵʻ���Ĵ�С
�б��������ķ�����ʹ��sigmoid����,��:
p
(
+
)
=
��
(
x
w
T
��
)
=
1
1
+
e
?
x
w
T
��
p(+)=\sigma (x_{w}^{T}\theta )=\frac{1}{1+{{e}^{-x_{w}^{T}\theta }}}
p(+)=��(xwT?��)=1+e?xwT?��1?
�ο�����:word2vecԭ��(��) ����Hierarchical Softmax��ģ��
4. negative sampling(������)
������ǵ�ѵ������������Ĵ� w ��һ������Ƨ�Ĵ�,��ô�͵��ڻ�������������������ߺܾá�
ѵ������
�ö�Ԫ���ع�ķ��������Ӧ�Ķ�����Ȼ���� L��
������ݶ�������,ÿ��ֻ��һ�����������ݶ�,�����е�������������Ҫ�IJ��� x w , �� w x_w, ��^w xw?,��w��(��L��)
����������
������ѵ����һ�ֽ��������ϡ��Ŀ���ͨ�÷�����word2vec ѵ��ʱ,���´����ڵ�positive word �� �Ǵ�����negative words ��Ӧ�IJ����������ʹ�ø�����, negative words ��Ϊ�ʵ���,�����Ǵ��������еĴ�,�����Χ�ܴ�,ѵ���dz���ʱ�������������� �� negative words�����������,���� negative words ������
��������ij���̶�����������Ӧ k k k ��������,��ģ���ܹ������� k + 1 k + 1 k+1 ��binary classification���Ա�֮ǰ10000�������Ԫ��softmax����,negative samplingת��Ϊ������������,ÿ�ε���������ѵ��10000��,����ѵ������ k + 1 k + 1 k+1 ��,������ҪС�ܶ�,��������ģ�������ٶȡ�
���ַ����ͽ���������(Negative Sampling): ѡ��һ��������,������� k k k����������
ѡȡ��context֮��,���ѡȡ������:
- ͨ�����ʳ��ֵ�Ƶ�ʽ��в���:����һЩ���� a��the��of�ȴʵ�Ƶ�ʽϸ�
- ��������س�ȡ������:û�кܺõĴ�����
�������:
p
(
w
i
)
=
f
(
w
i
)
3
4
��
j
=
1
n
f
(
w
j
)
3
4
p({{w}_{i}})=\frac{f{{({{w}_{i}})}^{\frac{3}{4}}}}{\sum\limits_{j=1}^{n}{f{{({{w}_{j}})}^{\frac{3}{4}}}}}
p(wi?)=j=1��n?f(wj?)43?f(wi?)43??
���ַ��������������ּ��˲�������֮��,������Ƶ�ʷֲ�,Ҳ���þ��ȷֲ�,�����õ��ǶԴ�Ƶ�� 3 4 \frac{3}{4} 43?���������Ƶ�� 3 4 \frac{3}{4} 43?���в��������� f ( w j ) f(w_j) f(wj?) �����Ͽ��й۲쵽��ij���ʵĴ�Ƶ��
�ο�����:��������ƽPinard word2vecԭ��(��) ����Negative Sampling��ģ��
����
word2vec���Ż�,�����㼶softmax�ĸ��Ӷ�
Hierachical softmax �ĸ��Ӷȴ�ԭ���� x ��Ϊ logx
word2vector������ʱΪʲôҪ��Ƶ����3/4�η�?
���������ᵽ���ھ���,Ч���á�
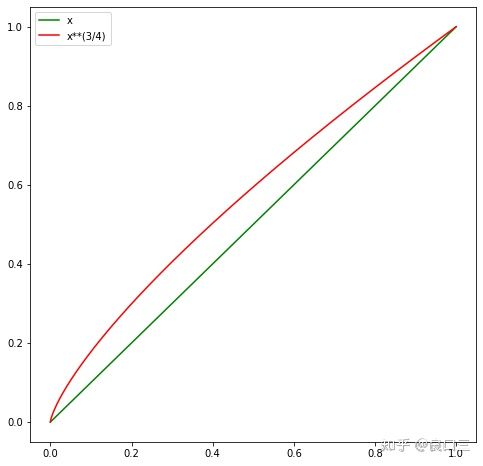
���Կ���,��0~1����, x 3 / 4 x^{3/4} x3/4 ����Ǵ��� x�����Ҷ���ԽС��ֵ,��������Խ��
�ӳ����ĽǶ�����,ͨ����Ȩ�ؿ� 3/4 ����,����������Ƶ�ʱ��鵽�ĸ��ʡ�
������Ϊ:�ڱ�֤��Ƶ�����ױ��鵽�Ĵ�����,ͨ��Ȩ��3/4���ݵķ�ʽ,�ʵ�������Ƶ�ʡ������ʱ��鵽�ĸ��ʡ��������ô��,��Ƶ��,�����ʺ��ѱ��鵽,�����ڲ������µ���Ӧ��Embedding��
�ο�����:ΪʲôWord2Vecѵ����, ��Ҫ�Ը�����Ȩ�ؿ�3/4����?
�������еĴ���ѡ�����?����ѡ��5,10,15����ʲô������?�Dz���Խ��Խ����?
word2vector �����������?����ȫ�ֲ���?������batch����?���ʵ�ֶ�batch����?
��ôȷ����������ɵ�������?
W2V�������������߸�����֮��,ģ����ԭģ�����,�ǵȼ۵Ļ������Ƶ�?
����ʮ������ο�����:
word2vec����(���漰ԭ��ϸ��)
����1:����һ��word2vec?
(1) ����ģ���� CBOW �� Skip-gram,�����ӿ�ѵ���ļ����� HS(Hierarchical Softmax )��������
(2) ����һ��ѵ���������ɺ��Ĵ� w ���������� context(w) ���,CBOW ������ context(w) ȥԤ�� w;�� Skip-gram ����,���� w ȥԤ�� context(w) ������дʡ�
(3) HS ����ͼ�ô�Ƶ����һ�ù�������,��ô�������ֵĴ�·����Ƚ϶̡�����Ҷ�ӽڵ��ʾ��,���ʵ��С���,����Ҷ�ӽ����ģ�͵IJ���,�ȴʵ������һ����ҪԤ��Ĵ�,ת����Ԥ��Ӹ��ڵ㵽�ô�����Ҷ�ӽڵ��·��,�Ƕ�����������⡣// ��̫����??
(4 ) ���ڸ�����,���ǰ�ԭ���� Softmax ���������,ֱ��ת����һ�������Ͷ�������Ķ��������⡣������Ԥ�� 1,����Ԥ�� 0,�����Ӹ��¾ֲ��IJ�����
����2:�Ա� Skip-gram �� CBOW
(1) ѵ���ٶ��� CBOW Ӧ�û����һ�㡣
��Ϊÿ�λ���� context(w) �Ĵ�����,�� Skip-gram ֻ���º��ĴʵĴ�������
���ߵ�Ԥ��ʱ�临�Ӷȷֱ��� O(V),O(KV)
(2) Skip-gram �Ե�Ƶ��Ч���� CBOW�á�
��Ϊ�dz����õ�ǰ��ȥԤ��������,��ǰ���ǵ�Ƶ�ʻ��Ǹ�Ƶ��û�����𡣵��� CBOW �൱�����������,��ѡ���������˵�������Ĵ�����ȫ,��˲�̫��ѡ���Ƶ�ʡ�(������ʦѧ�����Ǹ�����)
Skip-gram �ڴ�һ������ݼ�������ȡ�������Ϣ������� CBOW Ҫ��һЩ��
����3:�Ա� HS �� ������
(1)�Ż�Ŀ��:
��HS��ÿ����Ҷ�ӽڵ�ȥԤ��Ҫѡ���·��(ÿ���ڵ��Ǹ�����������),Ŀ�꺯�������·���ϵĶ�������ʡ�
p
(
w
�O
c
o
n
t
e
x
t
(
w
)
)
=
?
j
=
2
l
(
w
)
p
(
d
j
w
�O
x
w
,
��
j
?
1
w
)
p(w|context(w))=\coprod\limits_{j=2}^{l(w)}{p(d_{j}^{w}|{{x}_{w}},\theta _{j-1}^{w})}
p(w�Ocontext(w))=j=2?l(w)?p(djw?�Oxw?,��j?1w?)
p
(
d
j
w
�O
x
w
,
��
j
?
1
w
)
=
[
��
(
x
w
T
��
j
?
1
w
)
]
1
?
d
j
w
?
????
?
????
?
????
[
????
?1-
��
(
x
w
T
��
j
?
1
w
)
?
????
]
????
?
d
j
w
p(d_{j}^{w}|{{x}_{w}},\theta _{j-1}^{w})={{[\sigma (x_{w}^{T}\theta _{j-1}^{w})]}^{1-d_{j}^{w}}}\text{ }\!\!\cdot\!\!\text{ }\!\![\!\!\text{ 1-}\sigma (x_{w}^{T}\theta _{j-1}^{w}){{\text{ }\!\!]\!\!\text{ }}^{d_{j}^{w}}}
p(djw?�Oxw?,��j?1w?)=[��(xwT?��j?1w?)]1?djw????[?1-��(xwT?��j?1w?)?]?djw?
�ڸ��������������������ͬʱ��С�����������ʡ�
g
(
w
)
=
��
(
x
w
T
��
w
)
��
u
��
N
E
G
(
w
)
[
1
?
��
(
x
w
T
��
u
)
]
g(w)=\sigma (x_{w}^{T}{{\theta }^{w}})\prod\limits_{u\in NEG(w)}{[1-\sigma }(x_{w}^{T}{{\theta }^{u}})]
g(w)=��(xwT?��w)u��NEG(w)��?[1?��(xwT?��u)]
(2)����������һЩ,�ر��Ǵʱ��ܴ��ʱ����HS���,����������ʹ�û�������,����ʹ�����������,�ܴ����������ܡ�
���� 4:������ΪʲôҪ�ô�Ƶ������������?
��Ϊ����������Ƶ�ʸߵĴ���ѧϰ,Ȼ����������ʵ�ѧϰ��
���� 5:Ϊʲôѵ���������״�����,Ϊʲôһ��ֻ��ǰһ��?
(1) ���� Hierarchical Softmax ��˵,���������еIJ����Dz�����������������,��Ϊû�취�ʹʵ���Ĵʶ�Ӧ��
(2) �������еIJ�����ʵ���Կ�����������,��Ϊ�м��Ǻ�ǰһ�״��������ڻ�,Ӧ��Ҳ��������ġ����ǿ��Ǹ����������Ǹ��ݴ�Ƶ����,������Щ�ʻ�ɲ���,Ҳ��ѧ�IJ��á�
���� 6:�Ա��������ʹ�����
(1) ��������ʵ���Խ��һЩ����,����δ��½��,������һЩ�����ʱ���Ա���ִʴ�������
(2) ��������������ռ����,���ӷḻ,�����㹻�������,���������ܹ�ѧ�����������ġ�
���� 7:Ϊʲô������/�ֲ�softmax�ܼӿ�ѵ��
(1) ������ 1���Ż�������ʱ��,ֻ�����漰������������;2 ������softmax������sigmoid,ԭ���ķ�����softmax��Ҫ�������е��ʵĸ��ʵ÷֡�
(2) �ֲ�softmax:����� Softmax ÿ�κ�ȫ���Ĵ��������ڻ�,���Ӷ��� O(V),V �Ǵʵ��С��������ǰ�ÿ���ʶ��ŵ�����������Ҷ�ڵ���,��sigmoid��������,��ô���ӶȾͿ��Խ�Ϊ O(logV),�����ĸ߶�,��Ϊֻ��ҪԤ��Ӹ��ڵ㵽��ӦҶ�ڵ��·�����ɡ�
����8:word2vec��ȱ��
(1) �����˴���
����9:hsΪʲô�û�����������������������?
������ΪHuffman�����ڸ�Ƶ�ʻḳ����̵ı���,ʹ�ø�Ƶ������ڵ�������,�Ӷ�ʹ��ѵ���ٶȼӿ졣
����10:Ϊʲô�õ������Լ����?
word2vec����Ϊ��������ģ��,������ҪԤ��ø���
LSTM
�ṹ
LSTM �ṹ����:
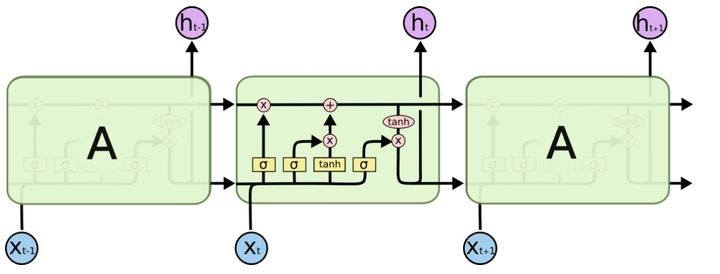
LSTM ��Ҫ���������Ź�ʽ
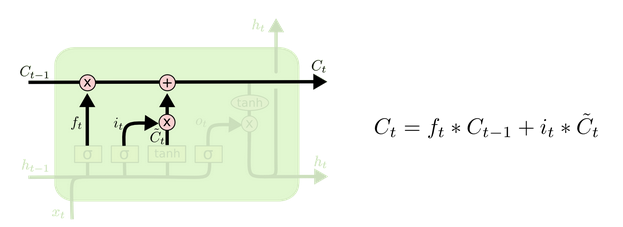
1. ������(forget gate)
�����ž�����һʱ��ϸ��״̬�еĶ�����Ϣ���Դ��ݵ���ǰʱ���С�
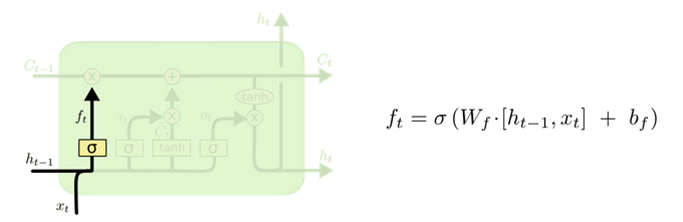
2. ������(input gate)
�������Ƶ�ǰ���������ɵ���Ϣ���ж�����Ϣ���Լ��뵽ϸ��״̬�С�
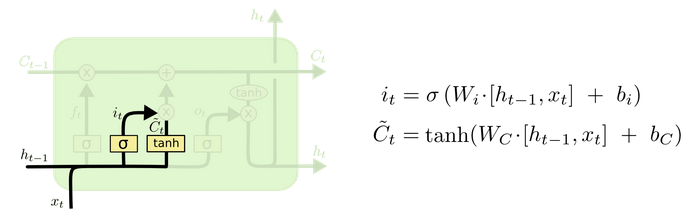
3. ����ϸ��״̬
ϸ��״̬�������ֹ���:
- ����һʱ�̾ɵ�ϸ��״̬��Ϣ;
- ��ǰ���������ɵ���Ϣ��
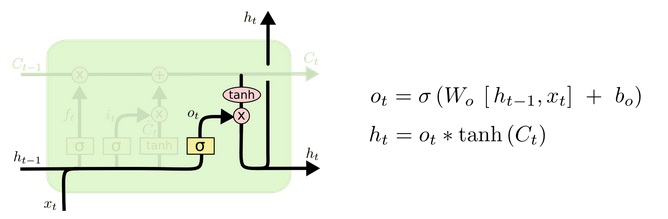
4. �����(output gate)
���,���ڸ��µ�ϸ��״̬,�������״̬��
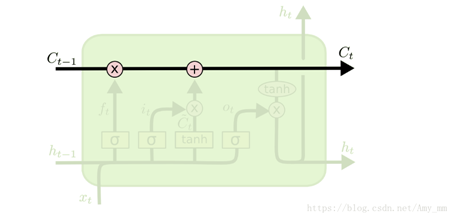
5. ����ϸ��(memory cell)
����ϸ������������Ԫ��ˮƽ����,������Ϣ���ʹ�������,ֻ�������м����Բ���,�ܹ���֤��������ʱ���ֲ��䡣
����
LSTM�����RNN��ʲô����?
RNN ����ʱ���ϵ�һ��ѭ��,ÿ��ѭ�������õ���һ�μ���Ľ��,��Ȼ RNN ÿ��ʱ�� t ���������,�������ʱ�̵����ʵ�����Ѿ�������֮ǰ����ʱ�̵���Ϣ,����һ������ֻ�������һ��ʱ�̵�������ˡ�
RNN ����ȱ��:
- �ŵ�:����a sequence����a timeseries of data pointsЧ������ͨ��DNNҪ�á��м�״̬������ά���˴ӿ�ͷ�����ڵ�������Ϣ;
- ȱ��:������ѧϰ��Զ�����������ϵ,ԭ�����ݶ���ʧ,���缸������ѵ��������Ҳֻ�������Ͽ��Լ������ⳤ�����С�
LSTM ������������(ʵ����Ҳû�н��) RNN ���ݶ���ʧ�����,�Ӷ����Դ��� long-term sequences��
LSTM ��λ����ݶ���ʧ?
����ע�, ���������ŵļ������ sigmoid, ��Ҳ����ζ���������ŵ����Ҫô�ӽ���0 , Ҫô�ӽ���1�����ʹ�� �� c t �� c t ? 1 = f t \frac{\delta c_t}{\delta c_{t-1}} = f_t ��ct?1?��ct??=ft?, �� h t �� h t ? 1 = o t \frac{\delta h_t}{\delta h_{t-1}} = o_t ��ht?1?��ht??=ot? �Ƿ�0��1��,����Ϊ1ʱ, �ݶ��ܹ��ܺõ���LSTM�д���,�ܴ�̶��ϼ������ݶ���ʧ�����ĸ���, ����Ϊ0ʱ,˵����һʱ�̵���Ϣ�Ե�ǰʱ��û��Ӱ��, ����Ҳ��û�б�Ҫ�����ݶȻ�ȥ�����²����ˡ�����, �����Ϊʲôͨ���Ż��ƾ��ܹ�����ݶȵ�ԭ��: ʹ�õ�Ԫ��Ĵ��� �� S j �� S j ? 1 \frac{\delta S_j}{\delta S_{j-1}} ��Sj?1?��Sj?? Ϊ 0 �� 1��
NLP �г��õ�������ǿ����?
ԭ��д��̫����,���������ر�ȫ
ԭ��:һ���˽�NLP�е�������ǿ����
1. �ʻ��滻
��һ��Ĺ���,����˵,����ȥ�滻ԭʼ�ı��е�ijһ����,�����ı���ӱ�������˼��
1.1 ����ͬ��ʵ���滻
���ǴӾ��������ȡ��һ������,�����滻�ɶ�Ӧ��ͬ��ʡ�����,���ǿ���ʹ��Ӣ�ĵ� WordNet ���ݿ�������ͬ���,Ȼ������滻��
1.2 ���� Word-Embedding ���滻
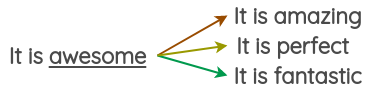
�����ַ�����,���Dz���Ԥѵ���õĴ�����,�� Word2Vec��Glove��FastText,�������ռ��������ĵ����滻ԭʼ�����еĵ��ʡ�

����,���������������ռ��о�������ĵ����滻ԭʼ�����еĵ���,���Եõ�ԭʼ���ӵ��������塣���ǿ���ʹ���� Gensim ������������IJ��������������������,����ͨ���� Tweet ������ѵ���Ĵ������ҵ��˵��� ��awesome�� ��ͬ��ʡ�
1.3 ���� Masked Language Model���滻
�� BERT��ROBERTA �� ALBERT �������� Transformer ��ģ���Ѿ�ʹ�� ��Masked Language Modeling�� �ķ�ʽ,��ģ��Ҫ������������Ԥ�ⱻ Mask �Ĵ���,ͨ�����ַ�ʽ�ڴ��ģ���ı��Ͻ���Ԥѵ����
1.4 ���� TF-IDF ���滻
����������ǿ������ Xie ������ ��Unsupervised Data Augmentation�� ������������ġ������˼����,TF-IDF �����ϵ͵ĵ��ʲ����ṩ��Ϣ,��˿����ڲ�Ӱ����ӵĻ�����ֵ��ǩ��������滻���ǡ�

2. ����(Back Translation)
�����ַ�����,����ʹ�û�������ķ�������������һ���µ��ı���Xie ����ʹ�����ַ���������δ��ע������,�� IMDB ���ݼ�������ֻʹ���� 20 ����ע����,�Ϳ���ѵ���õ�һ����ලģ��,�������ǵ�ģ������֮ǰ�� 25000 ����ע������ѵ���õ��� SOTA ģ�͡�
ʹ�û�������������ľ�����������:
��ʵ���ǰѾ��ӷ�����������,Ȼ���ٷ�����,����ҵ���ɵ�����(��
- ��һЩ����(��Ӣ��),�������һ������,�編�
- �ѷ�����ӷ����Ӣ����ӡ�
- ����¾����Ƿ���ԭ���ľ��Ӳ�ͬ�������,��ô����ʹ������¾�����Ϊԭʼ�ı��IJ���汾��
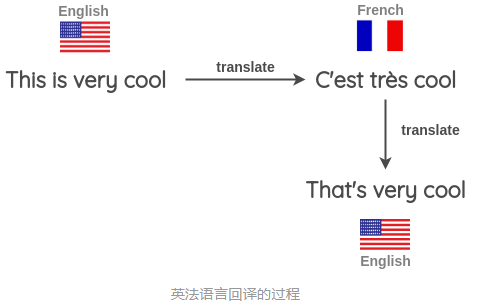
���ǻ�����ͬʱʹ�ö��ֲ�ͬ�����������л��������ɸ�����ı����塣����ͼ��ʾ,���ǽ�һ��Ӣ����ӷ����Ŀ������,Ȼ���ٽ��䷭�������Ŀ������:��������������
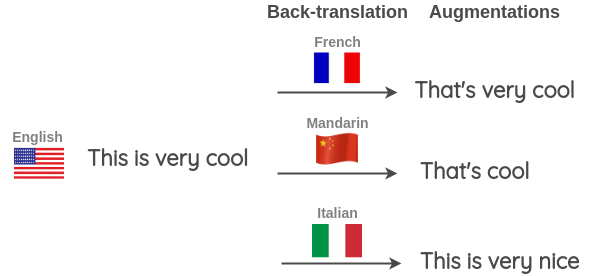
���ַ���Ҳ�� Kaggle �ϵ� ��Toxic Comment Classification Challenge�� �ĵ�һ�����������ʹ�á���ʤ�߽�������ѵ����������Ͳ���,��Ӧ���ڲ��Ե�ʱ��,��Ӣ����ӵ�Ԥ������Լ�ʹ����������(��������������)�ķ��������ƽ��,�Եõ����յ�Ԥ�⡣
�������ʵ�ֻ���,����ʹ�� TextBlob ���߹ȸ跭�롣
3. �ı�����ת��(Text Surface Transformation)
��Щ��ʹ���������ʽӦ�õļ�ģʽƥ��任,Claude Coulombe �����������н�������Щ�任�ķ�����
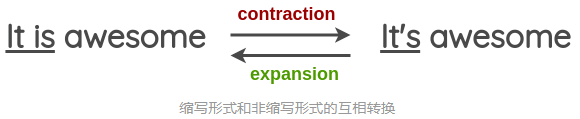
��������,��������һ������������д��ʽת��Ϊ����д��ʽ������,���ǿ���ͨ������ķ��������ı���������ǿ��
��Ҫע�����,��Ȼ������ת���ڴ�����²���ı����ԭ���ĺ���,����ʱ����չģ�����ɵĶ�����ʽʱ���ܻ�ʧ��,���������������:
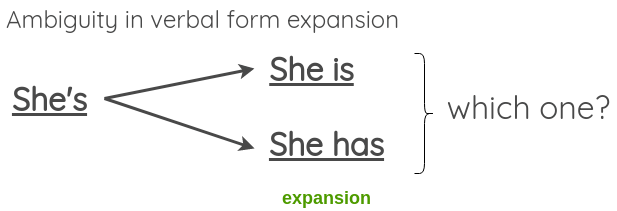
Ϊ�˽����һ����,������Ҳ�������ģ������ (����д��ʽת��д��ʽ),������ģ��չ���ķ��� (��д��ʽת����д��ʽ)��
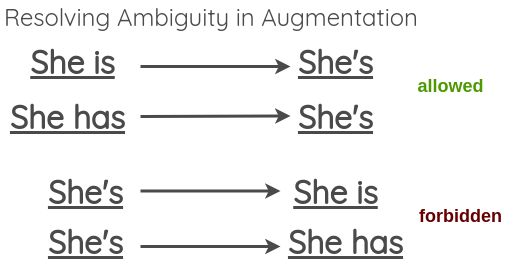
���ǿ����������ҵ�Ӣ����д���б�������չ��,����ʹ�� Python �е� contractions �⡣
4. �������ע��(Random Noise Injection)
��Щ������˼�������ı���ע������,�������µ��ı�,���ʹ��ѵ����ģ�Ͷ��Ŷ�����³���ԡ�
4.1 ƴд����ע��(Spelling error injection)
�����ַ�����,�����ھ���������һЩ������ʵ�ƴд������ͨ����̷�ʽ��ʹ�ó���ƴд�����ӳ����������Щƴд����,������Բο�������ӡ�

4.2 ���̴���ע��(QWERTY Keyboard Error Injection)
���ַ�����ͼģ���� QWERTY ���̲����ϴ���ʱ���ڼ�֮��dz��ӽ��������ij����������ִ���ͨ������ͨ�����������ı�ʱ�����ġ�

4.3 ��������(Unigram Noising)
Unigram ��ָ������ĸ,���ߵ�������,����һ���ʱ�ʾ�ĵ���
���ַ����Ѿ��� Xie ���˺� UDA ��������ʹ��,��˼����ʹ�ô� unigram Ƶ�ʷֲ��в����ĵ��ʽ����滻�����Ƶ�ʻ����Ͼ���ÿ��������ѵ�����Ͽ��г��ֵĴ�����
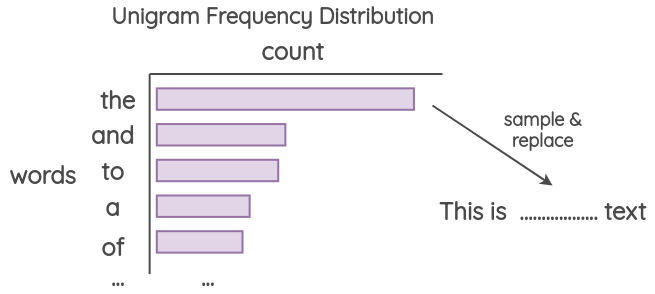
4.4 �հ�����(Blank Noising)
�÷����� Xie ���������ǵ����������,��˼������ռλ������滻һЩ������ʡ�����ʹ�� ��_�� ��Ϊռλ����ǡ���������,����ʹ������Ϊһ�ֱ������ض��������Ϲ�����ϵķ����Լ�����ģ��ƽ���Ļ���,�����������Ч��������ı��� Perplexity �� BLEU ֵ��
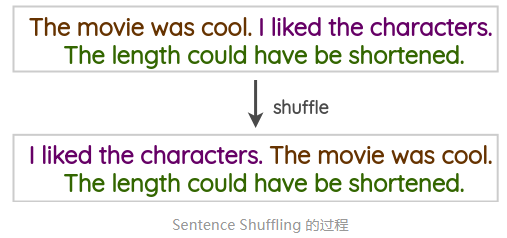
4.5 ���Ӵ���(Sentence Shuffling)
����һ�ֺܳ����ķ���,���ǽ�ѵ�������еľ��Ӵ���,������һ����Ӧ��������ǿ������
4.6 ���ע��(Random Insertion)
����������� Wei ������������ ��Easy Data Augmentation�� ������ġ��ڸ÷�����,�������ȴӾ��������ѡ��һ������ֹͣ�ʵĴʡ�Ȼ��,�����ҵ�����Ӧ��ͬ���,��������뵽�����е�һ�����λ�á�

4.7 �������(Random Swap)
�������Ҳ�� Wei ������������ ��Easy Data Augmentation�� ������ġ��÷������ھ�����������������������ʡ�

4.8 ���ɾ��(Random Deletion)
�÷���Ҳ�� Wei ������������ ��Easy Data Augmentation�� ������������������,�����Ը��� p ���ɾ�������е�ÿ�����ʡ�

5. ʵ��������ǿ(Instance Crossover Augmentation)
���ַ����� Luque ���� TASS 2019 �������н���,����������Ŵ�ѧ�е�Ⱦɫ�彻�������
�ڸ÷�����,һ�� tweet ���ֳ�����,Ȼ��������ͬ�������(��/��)�� tweets ���Խ���һ������ݡ���ô���ļ�����,��ʹ�������������ϲ���ȫ,�µ��ı��Խ�����ԭ�����������
���з�����ȷ��û��Ӱ��,������ F1-score �ϻ���������,�������������ģ���������ں�������ϵ��ж�����,���� tweet �н��ٵ��������

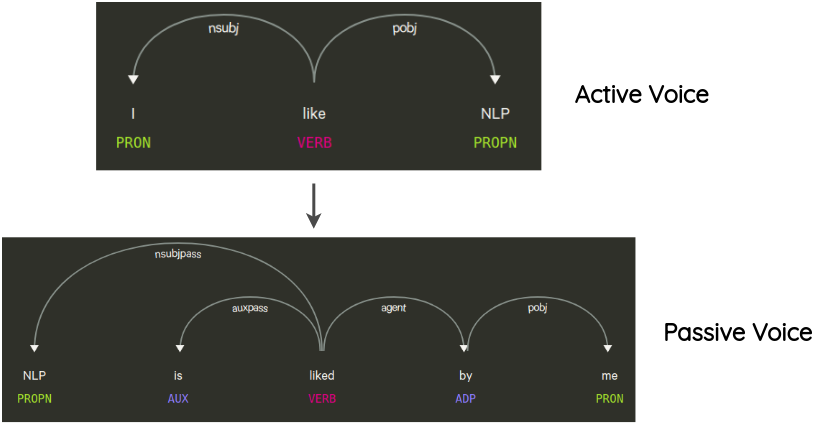
6. �������(Syntax-tree Manipulation)
���ַ����������� Coulombe �����,��˼���ǽ���������ԭʼ���ӵ�������,ʹ�ù���������ת������ԭ�������������ɡ�
����,һ������ı������˼��ת���Ǿ��ӵ�������̬�ͱ�����̬��ת����
7. �ı��ϳ�(MixUp for Text)
Mixup ��?Zhang?������ 2017 �������һ�ּ���Ч��ͼ����ǿ��������˼���ǽ��������ͼ��һ��������ϳ�,����������ѵ���ĺϳ����ݡ�����ͼ��,����ζ�źϲ�������ͬ���ͼ�����ء�����ģ��ѵ����ʱ�������Ϊ��һ�����ķ�ʽ��

Ϊ�˰�����뷨���� NLP ��,Guo �������� Mixup �������ı���������������ֽ� Mixup Ӧ�����ı��ķ���:
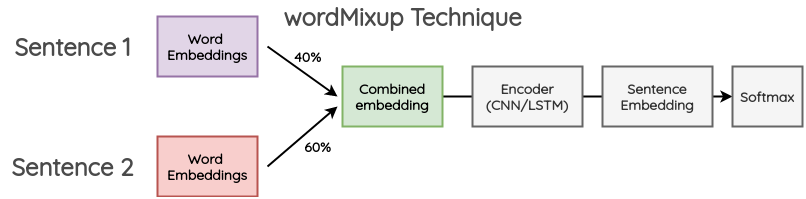
7.1 ���ʼ���ĺϳ�(wordMixup)
�����ַ�����,��һ��С����ȡ��������ľ���,���DZ�������ͬ�ij���;Ȼ��,���ǵ� word embeddings ��һ���������,�����µ� word embeddings Ȼ�����ε��ı���������,��������ʧ�Ǹ���ԭʼ�ı���������ǩ��һ����������õ��ġ�
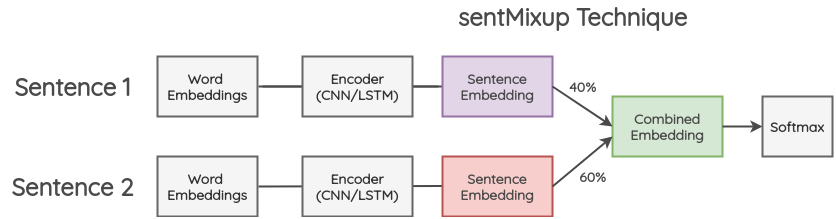
7.2 ���Ӽ���ĺϳ�(sentMixup)
�����ַ�����,������������Ҳ�DZ���䵽��ͬ�ij���;Ȼ��,ͨ�� LSTM/CNN �������������ǵ� word embeddings,���ǰ���������״̬��Ϊ sentence embedding����Щ embeddings ��һ���ı������,Ȼ�ݵ����յķ���㡣��������ʧ�Ǹ���ԭʼ�ı���������ǩ��һ����������õ��ġ�
8. ����ʽ�ķ���
��һ��Ĺ������������ɶ����ѵ�����ݵ�ͬʱ����ԭʼ���ı�ǩ��
Conditional Pre-trained Language Models
���ַ����������� Anaby-Tavor ���������ǵ����� ��Not Enough Data? Deep Learning to the Rescue!�� Kumar ���������һƪ�����ڶ������ Transformer ��Ԥѵ��ģ������֤����һ�뷨��
����ı�������:
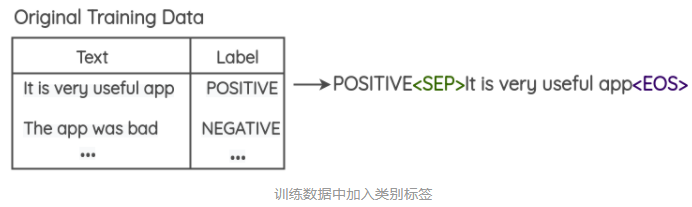
-
��ѵ��������Ԥ�ȼ�������ǩ,����ͼ��ʾ��
-
������Ĺ���ѵ�������� finetune һ�����͵�Ԥѵ������ģ�� (BERT/GPT2/BART) ������ GPT2,Ŀ����ȥ����������;������ BERT,Ŀ����ҪȥԤ�ⱻ Mask �Ĵ��

-
ʹ�þ��� finetune ������ģ��,����ʹ�����ǩ�ͼ�����ʼ������Ϊģ�͵���ʾ���������µ����ݡ�����ʹ��ÿ��ѵ�����ݵ�ǰ 3 ����ʼ����Ϊѵ��������������ǿ��
