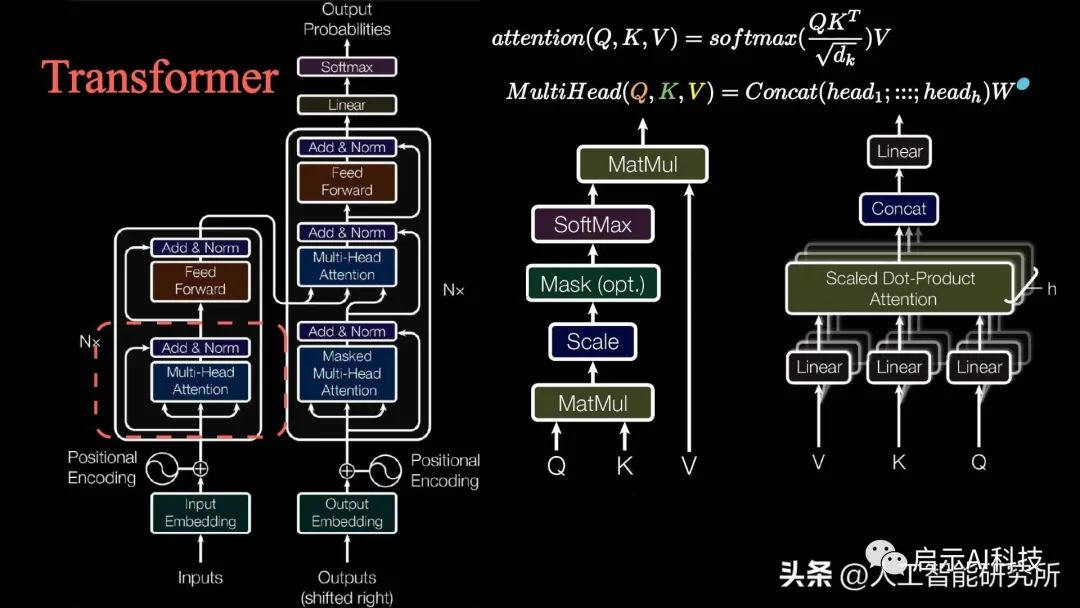
多头注意力机制
通过上一期的分享,我们了解了transformer模型中的多头注意力机制的概念,且通过7个attention注意力机制的变形,彻底了解了tranformer模型的多头注意力机制,哪里重点介绍了multi-head attention多头注意力机制中的Q K V 三矩阵。
――1――
Transformer模型注意力机制计算
其实QKV矩阵的来历比较简单,如下视频动画讲解了QKV三矩阵的来历

?这里我们的输入矩阵I分别乘以权重矩阵Wq,Wk,Wv三个矩阵,就得到了输入transformer模型的QKV三矩阵,QKV三矩阵用在transformer模型计算注意力,根据attention is all you need论文中计算注意力机制的公式,我们通过以上得到的QKV三矩阵来计算注意力机制。
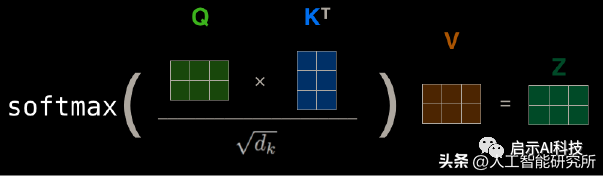
注意力机制计算公式
在如下视频中,演示了QKV矩阵的attention注意力机制的计算过程

注意力机制计算
首先,Q矩阵乘以K矩阵的转置,然后再除以一个缩放系数根号下dim,这样做是防止梯度消失问题,然后得到的attention矩阵再经过softmax层,最后再乘以V矩阵得到最终的注意力机制。
整个计算过程完全按照attention注意力机制的公式来计算,但是在NLP领域,我们输入模型的句子长度不完全一致,这就涉及到了pad mask矩阵,这也是为什么在多头注意力机制时,其transformer模型中的注意力是masked 的,因为我们需要把pad的地方mask掉,因此在做softmax前,我们需要添加mask,然后再进行softmax的计算,这样就避免pad的地方没有注意力。

mask矩阵
当然,解码器的输入还涉及到sequence mask矩阵,sequence mask矩阵为了屏蔽未来的句子信息。这是因为我们的模型在训练时若能提前看到未来的句子信息,那神经网络模型训练也没有什么意义了。
――2――
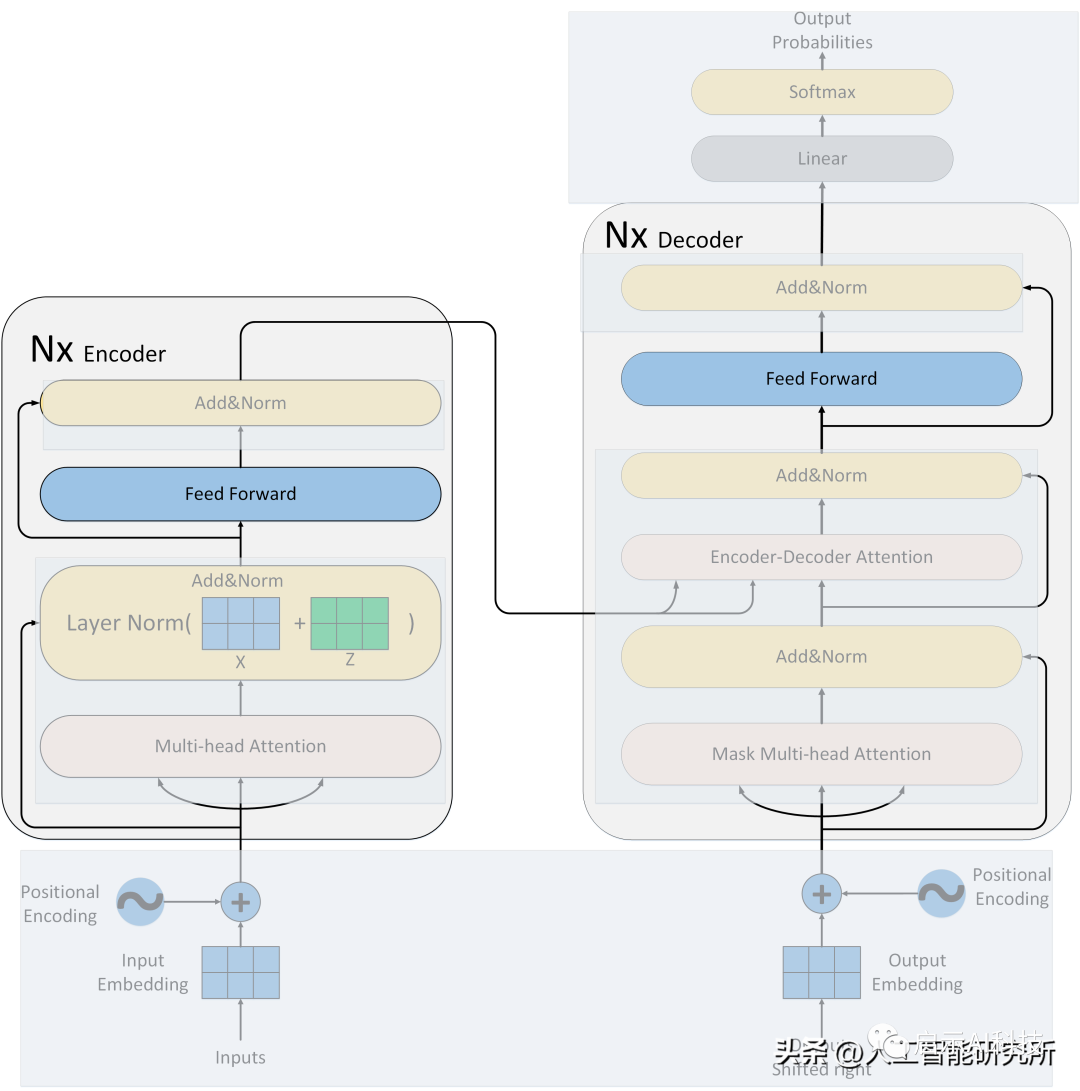
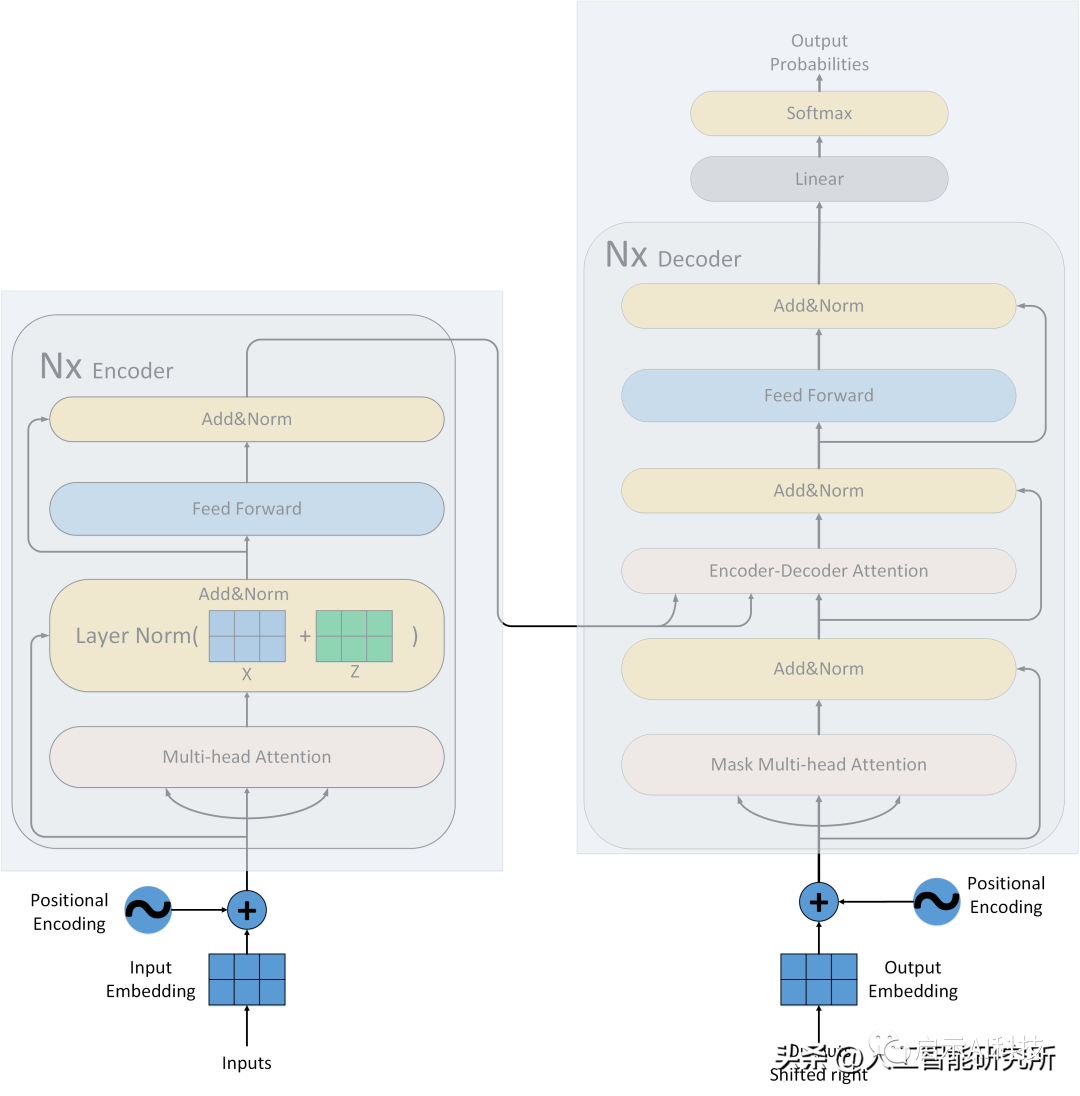
Transformer模型搭建
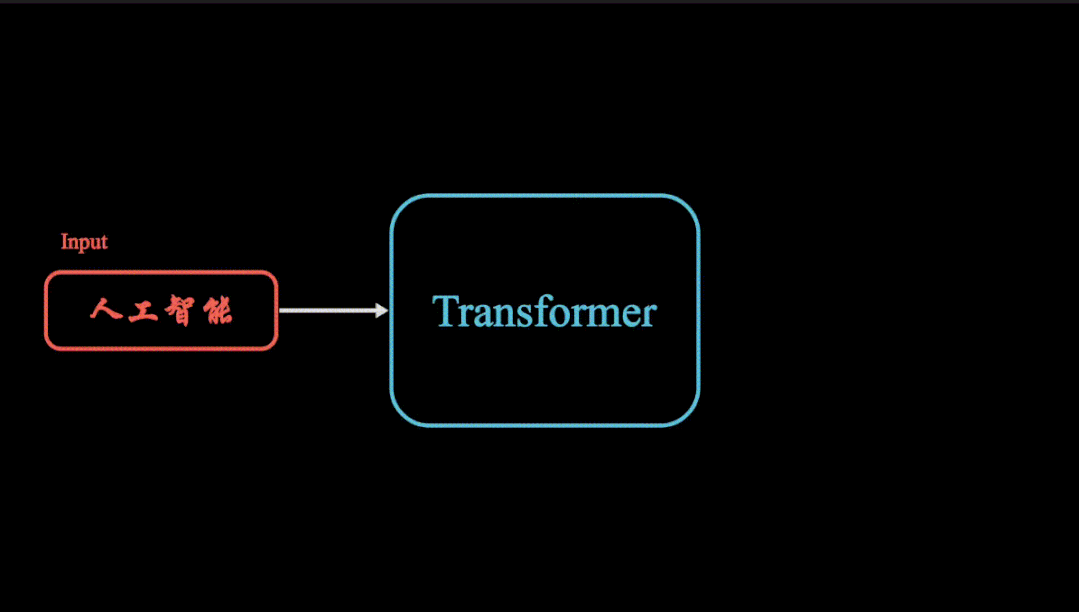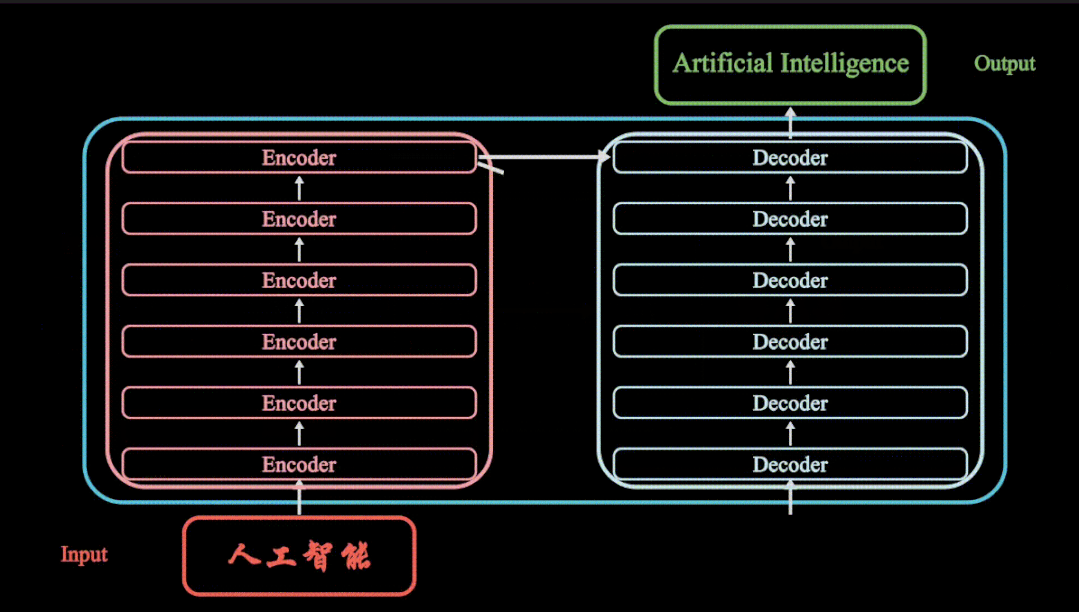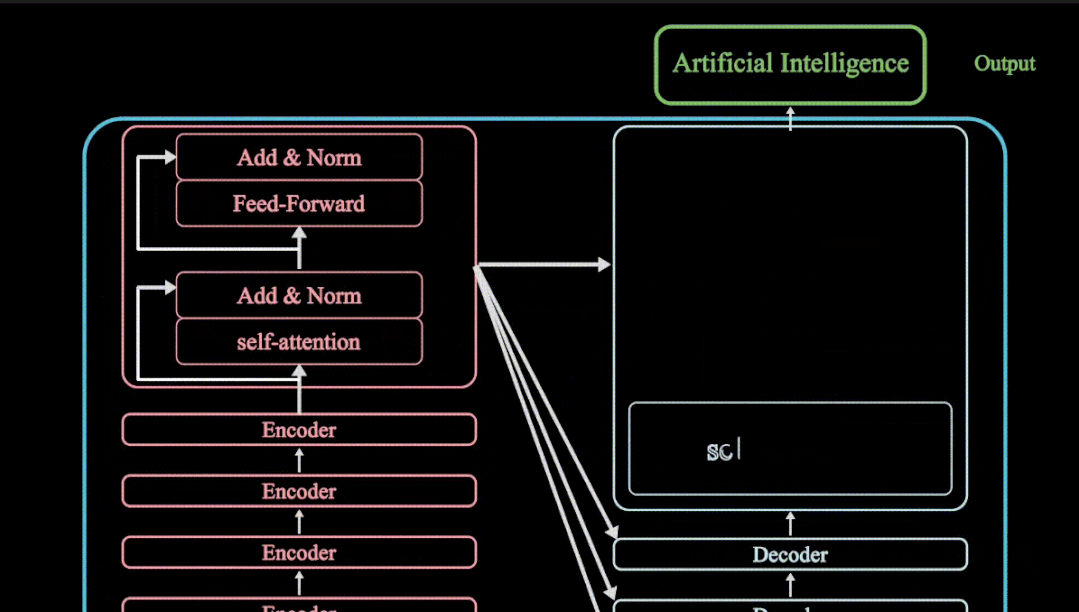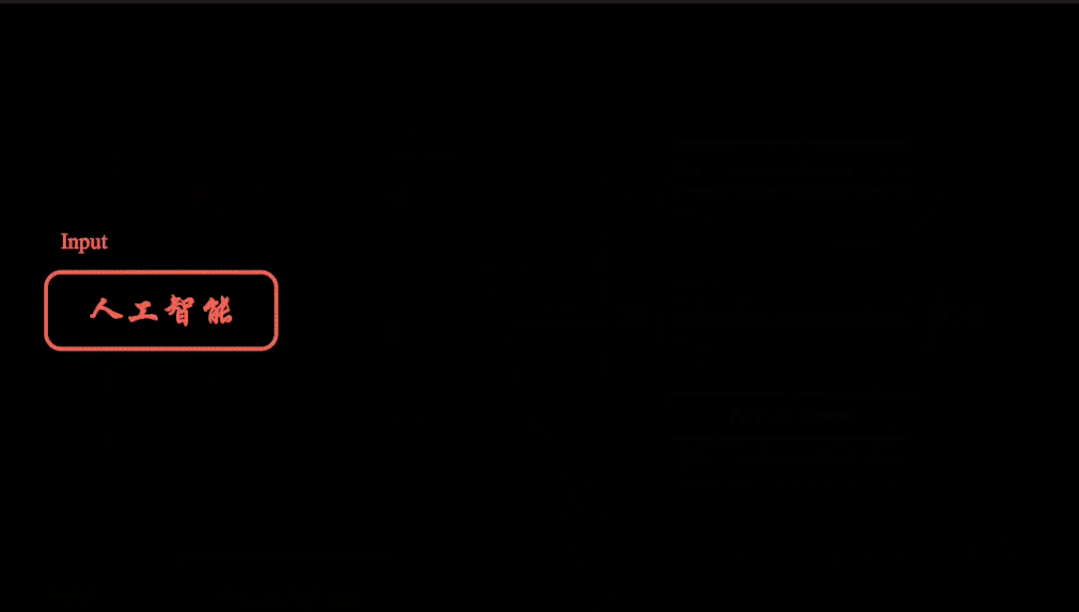
更多Transformer模型VIT 模型SWIN Transformer模型参考头条号:人工智能研究所
Attention注意力机制是transformer模型的核心,但是只有注意力无法完成整个模型的搭建,我们还需要其他子层来把模型整个串起来。
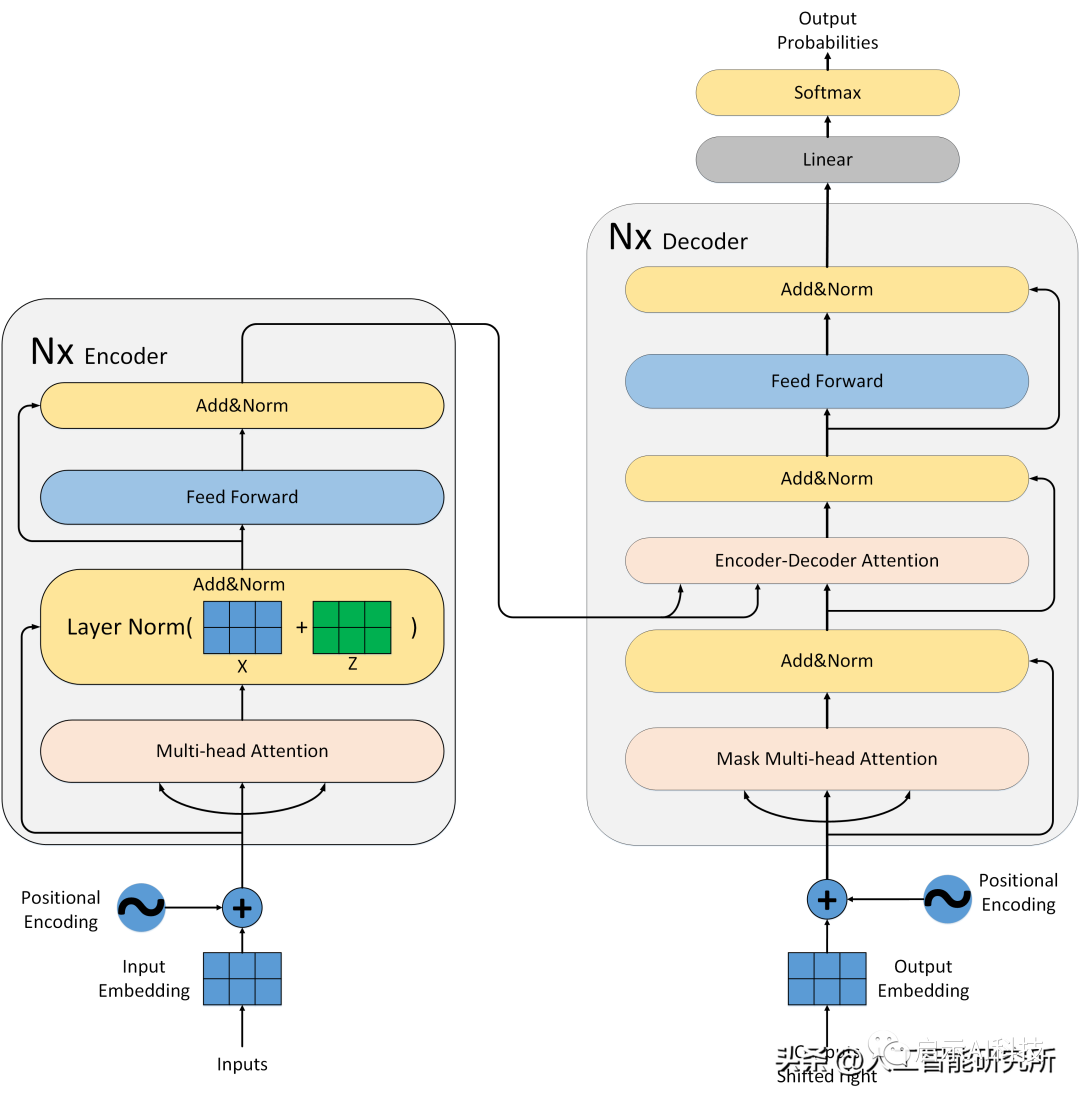
Transformer模型
除了attention注意力机制层,我们还有残差连接,归一化层,feed-forward前馈神经网络,位置编码,输出输入层等,且注意力机制还是多头注意力机制,且还有mask矩阵的存在。虽然attention注意力机制是Transformer模型的核心,但是缺少以上任何一层就不能构成Transformer模型,具体Transformer模型的多头注意力机制如何操作,模型如何搭建?
――3――
Transformer模型残差连接与归一化
残差连接让每次数据经过attention注意力后,都添加上原始的数据作为参考,避免原始信息的丢失,还有重要的点是经过attention后,会丢失位置信息,这样残差连接可以把位置信息传递给后端的模型数据
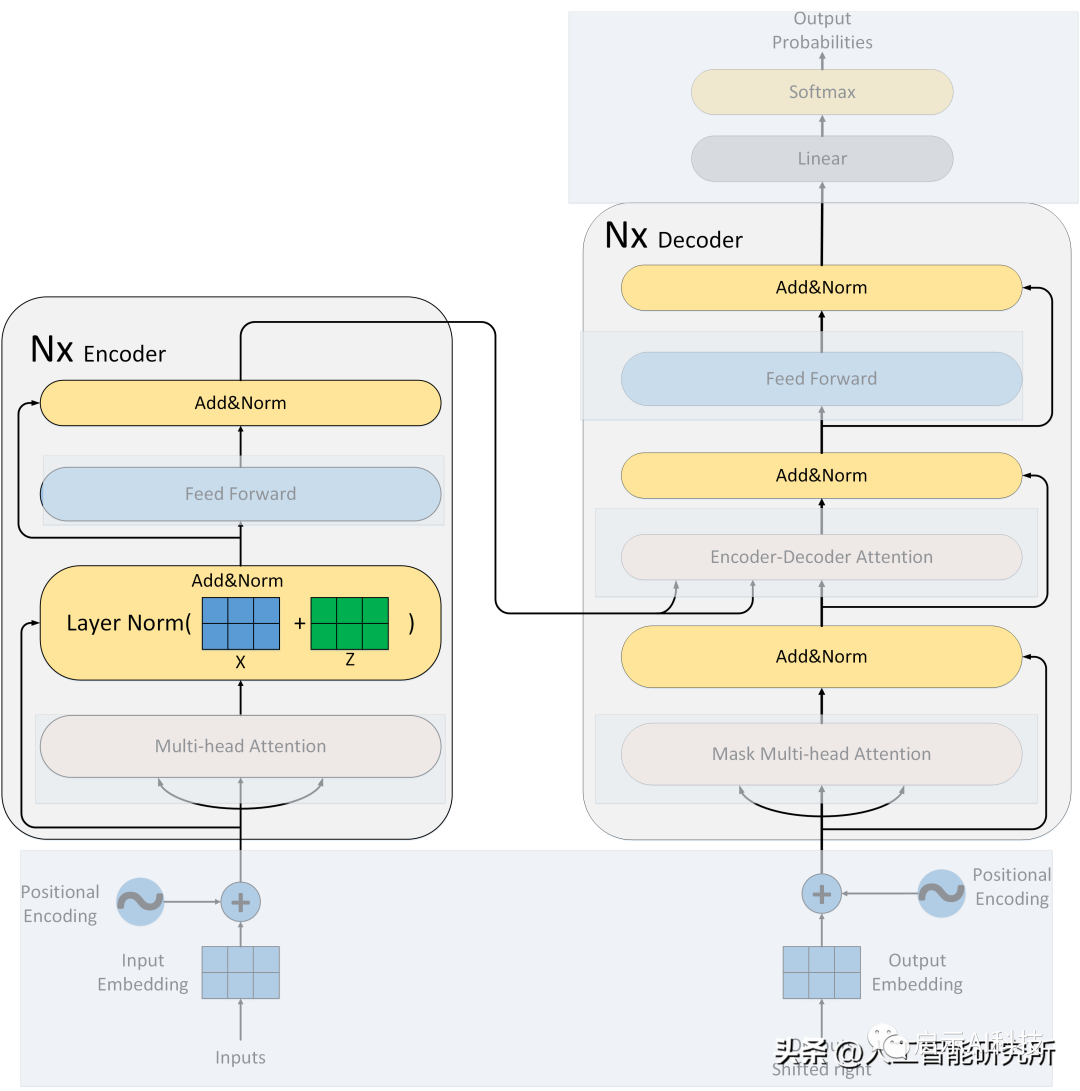
ADD&Norm操作
归一化层是NLP领域很重要的一个操作,当然在transformer模型中,作者采用了Layer Normalization 而不是BatchNormalization ,这是因为在transformer模型中,使用layer norm效果更好。从模型的架构图可以看出,每次经过注意力机制与feed forward前馈神经网络后,都会有add&Norm的操作。
――4――
前馈神经网络
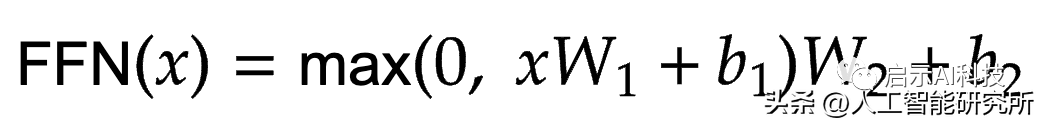
前馈神经网络公式
这个想法是将注意力机制的输出投影到更高维度的空间。这实质上意味着数据被拉伸到更高的维度,因此它们的细节被放大。这样就会让注意力机制更加注意需要注意的地方。
――5――
位置编码

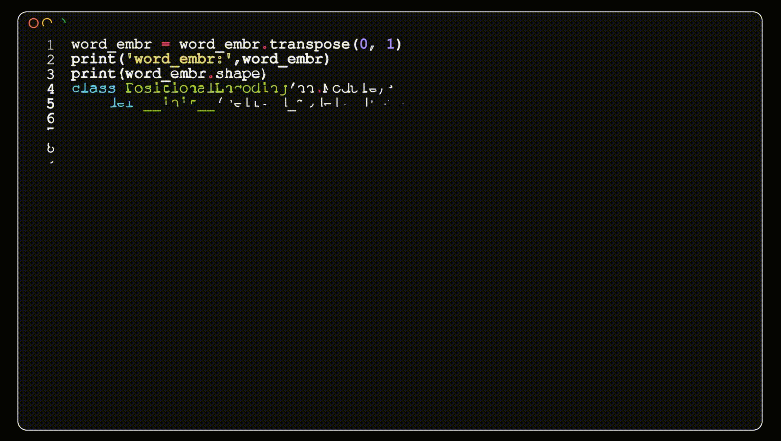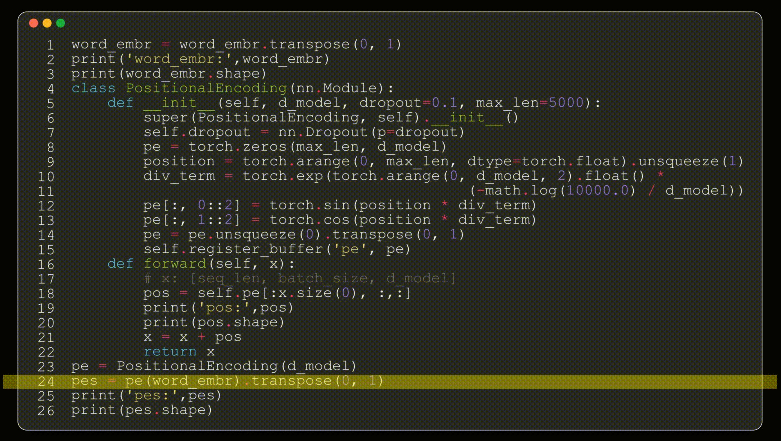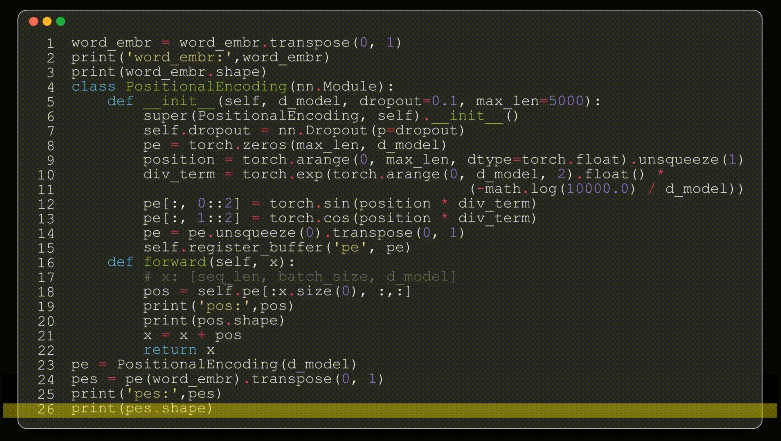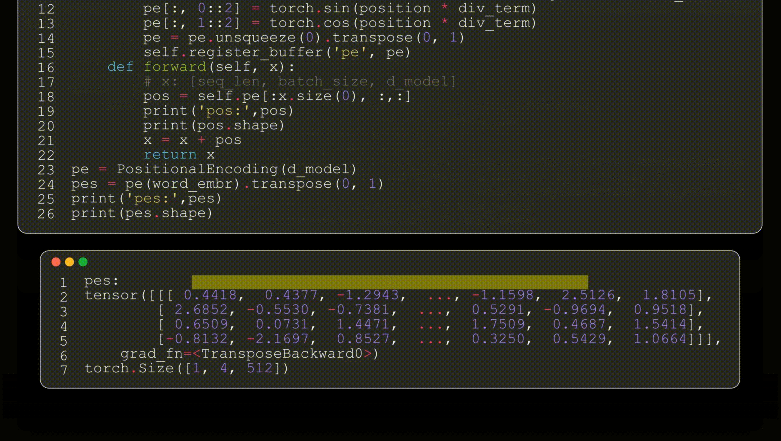
到目前位置,我们的模型并不知道输入矩阵的相对位置,这在NLP领域是至关重要的,我们的单词在不同的位置表达的意思肯定不一样,作者团队在模型输入部分加入了位置编码,且位置编码的公式采用了2个三角函数来表示。

位置编码计算公式
位置编码
transformer模型第一个比较难理解的就是其位置编码了,位置编码作为NLP的时间维度,提供句子单词的位置信息。模型提供了一个正余弦的数学公式来计算位置编码,其位置编码为绝对位置信息,且位置编码只计算一次,位置编码在transformer模型中为一个定值,模型训练时,不参与参数更新。
 ?
?
?
VX搜索小程序:AI人工智能工具,体验不一样的AI工具

?