БпдЕМЦЫу
ЫцзХжкЖрВњвЕЯђЪ§зжЛЏЕФзЊаЭ,ДѓСїСПЕФЪЙгУШУдЦМЦЫуЛёЕУСЫОоДѓЕФЗЂеЙ,МЦЫуЁЂДцДЂКЭИїжжЭјТчЙІФмвЛЦ№ЙмРэЕФЗНЪНЪЙМЦЫуОпгаМЋИпЕФГЩБОаЇвцКЭСщЛюадЁЃ
НќФъРД,вЦЖЏЩшБИКЭСЊЭјЩшБИЕФЪ§СПГЪБЌеЈЪНдіГЄ,ЩѕжСдЄВт,ЕН 2025 ФъШЋЧђНЋгаНќЧЇвкЬЈЮяСЊЭјЩшБИ,дЦМЦЫуе§дкХЌСІгІЖдЮяСЊЭјЩшБИВњЩњЕФКЃСПЪ§ОнКЭЮяСЊЭјЩшБИЫљашЕФЕЭбгГй,ЕЋдЦМЦЫуХфжУЕФИќаТЫйЖШдЖВЛМАЪ§ОндіГЄЕФЫйЖШ,етОЭМБашвЛжжПЩвдЗжЕЃдЦЖЫбЙСІЕФМЦЫуЫМЯыКЭДЋЪфЩшБИЁЃ
БпдЕМЦЫуБпдЕМЦЫузїЮЊвЛжжНЋМЦЫуШЮЮёКЭЗўЮёДгЭјТчКЫаФЭЦЯђЭјТчБпдЕЕФаТаЫЗЖЪН,БЛЙуЗКШЯЮЊЪЧвЛжжКмгаЧАЭОЕФНтОіЗНАИЁЃЖјЮяСЊЭјЕФПьЫйЗЂеЙ,вВЮЊБпдЕМЦЫуДјРДИќЖрЛњЛсЁЃЪ§ЪЎвкЕФвЦЖЏЩшБИКЭЮяСЊЭјЩшБИСЌНгЕНЛЅСЊЭј,дкЭјТчБпдЕВњЩњКЃСПзжНкЕФЪ§ОнЁЃдкетвЛЧїЪЦЕФЭЦЖЏЯТ,ЦШЧаашвЊНЋШЫЙЄжЧФмЧАбиЭЦЯђЭјТчБпдЕ,ГфЗжЪЭЗХБпдЕДѓЪ§ОнЕФЧБСІЁЃ
ЩюЖШбЇЯА
НќФъРД,ЛњЦїбЇЯАЦеБщгІгУгкИїИіСьгђЁЃЮвУЧвВБЛЛњЦїбЇЯАЕФгІгУЫљАќЮЇ,БШШч:дкМЦЫуЛњГЬађЁЂУНЬхЕШСьгђОГЃНгДЅЁЃБОжЪЩЯ,ЛњЦїбЇЯАЪЙгУЫуЗЈДгЪ§ОнжаЬсШЁгагУЕФаХЯЂ,ШЛКѓНЋЦфГЪЯждквЛИіФЃаЭжа,зюКѓЪЙгУИУФЃаЭдкЩњЛюжагІгУЪЕбщЛђЮДНЈФЃЕФЪ§ОнЁЃ

ЩёОЭјТчЪЧЛњЦїбЇЯАЕФФЃаЭжЎвЛ,вбОДцдкСЫЪ§ЪЎФъжЎОУЁЃетИіИХФюЪЧгЩбаОПВИШщЖЏЮяДѓФджаЩњЮяЩёОдЊЕФПЦбЇМвЖЈвхЕФЁЃЫцзХЪБМфЕФЭЦвЦ,ЩњЮяЬхДѓФджаЕФЩёОдЊНкЕуЛсНјЛЏ,ЖјЩёОЭјТчжаЩёОдЊНкЕужЎМфЕФСЌНгвВЛсЗЂеЙЁЃ
ЪЕЯжЖдШЫФдЕФНјвЛВНФЃФт,ЪЧИїжжЩюЖШбЇЯАЫуЗЈВЛЖЯНјВНЕФдвђЁЃФПЧА,жЛФмеыЖдВЛЭЌРраЭЕФбЇЯАНјааВЛЭЌЕФЫуЗЈФЃаЭбЁдёЁЃ
вЛЗНУц,ЩюЖШбЇЯАЪЧЛњЦїбЇЯАЕФбгеЙ,зїЮЊЯжШчНёжЇГХЯжДњММЪѕзюЮЊЛ№ШШЕФЩюЖШбЇЯА,ШчКЮКЯРэЕФгыЮяСЊЭјНсКЯ,ВЂгІгУдкХЉвЕСьгђ,ГЩЮЊЕБЯТЗЧГЃживЊЕФбаОПЗНЯђЁЃ
СэвЛЗНУц,ФПЧАЩюЖШбЇЯАЙуЗКгІгУгкИїжжХЉвЕГЁОА,АќРЈЮяСЊЭјЕФДЋИаЦїКЭЩуЯёЭЗЕШжеЖЫЩшБИе§дкЛёШЁЕФХЉзїЮяЪ§ОнЁЃетаЉЪ§ОнашвЊЪЙгУЩюЖШбЇЯАНјааЪЕЪБЗжЮі,ЛђгУгкбЕСЗЩюЖШбЇЯАФЃаЭЁЃ
ШЛЖј,ЩюЖШбЇЯАФЃаЭашвЊЯћКФДѓСПЕФМЦЫузЪдДЁЃДЫЪБ,БпдЕМЦЫуММЪѕФмЮЊвдИїРрЩёОЭјТчММЪѕЮЊжїЕФЩюЖШбЇЯАЬсЙЉГфзуЕФМЦЫузЪдД,гУБпдЕЖЫдкжеЖЫИННќЁЂгЕгавЛЖЈМЦЫуФмСІКЭЕЭбгГйЕФЬиЕу,НЋБпдЕМЦЫуКЭЩюЖШбЇЯАНсКЯдквЛЦ№ГЩЮЊвЛжжПЩааЕФЗНЗЈЁЃ
ЛЅЯрЯрНсКЯЪЕЯжЫМТЗ
- 1ЁЂЪзЯШЪЧНЋЮвУЧдкжеЖЫВЩМЏЕНЕФбЕСЗЪ§ОнДЋИјдЦЖЫМЦЫуЩшБИ,гЩдЦЖЫЩшБИбЕСЗЩёОЭјТчФЃаЭ;
- 2ЁЂЦфДЮНЋбЕСЗКУЕФФЃаЭДЋЕНБпдЕЩшБИ;
- 3ЁЂзюКѓНЋжеЖЫВтЪдЛђМЬајбЕСЗЕФЭМЦЌДЋИјБпдЕЖЫ,БпдЕЖЫЭЈЙ§ЧЈвЦбЇЯАРДЪЖБ№ЛђбЕСЗЭМЦЌЪ§ОнЁЃ
дкЩюЖШбЇЯАгыБпдЕМЦЫуЕФНсКЯЙ§ГЬжа,УПвЛДЮжиИДбЕСЗбЇЯАЖМашвЊЯћКФДѓСПЕФМЦЫузЪдД,етИіЪБКђОЭашвЊЭЈЙ§ЧЈвЦбЇЯАРДМЬајЪЙгУбЕСЗКУЕФФЃаЭЁЃ
ЭЈЙ§дЦЗўЮёЦїбЕСЗЭјТчФЃаЭ,ШЛКѓдЦЗўЮёЦїНЋбЕСЗКУЕФФЃаЭЗЂЫЭЕНБпдЕЖЫ,зюКѓгЩБпдЕЩшБИЭЈЙ§ЪЙгУЧЈвЦбЇЯАКЭбЕСЗКУЕФФЃаЭЖдаТЪ§ОнНјаадйбЕСЗЁЂЪЖБ№ЕШШЮЮё,ОЭПЩвдВЛгУПМТЧдЦЗўЮёЦїЕФИКдизДЬЌЁЃ вђДЫ,ЪЙгУдЦБпаЭЌЗНЪННјааЩюЖШбЇЯАЕФбЕСЗОЭФмЙЛМѕЧсдЦЖЫбЙСІ,ЬсИпдЫааЫйЖШ,НЕЕЭзмдЫааЪБМфЁЃ
ЧЈвЦбЇЯА
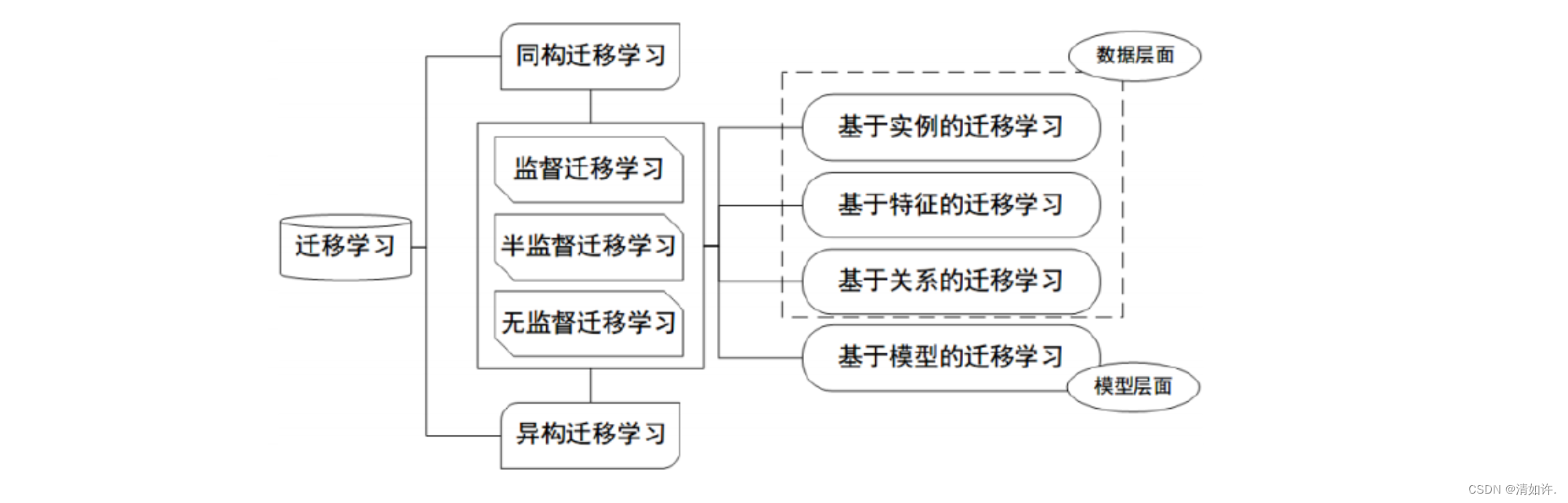
ЧЈвЦбЇЯА(Transfer Learning)ЪЧвЛжжОпгаЧПЭиеЙадЕФЯШНјЛњЦїбЇЯАЗНЗЈ,ЯрЖдгкЦфЫћДЋЭГЕФЛњЦїбЇЯАЫуЗЈ,ЧЈвЦбЇЯАВЩгУвбгаЕФЫуЗЈФЃаЭзїЮЊЛљДЁ,НјвЛВННЋДцдкЕФФЃаЭдкаТЕФШЮЮёжаЪЙгУЁЃЦфзюжївЊЬиЕудкгкЦфОпгаМЋЧПЕФЭЈгУад,ЯрБШЦфЫћЫуЗЈ,ЮоТлЪЧЩюЖШбЇЯАЛЙЪЧЛњЦїбЇЯА,ЖМашвЊеыЖдЪЕМЪЮЪЬтНјааБОЕиЛЏВйзїВХФмИќКУЪЕЯжМШЖЈФПБъ,ЕЋЧЈвЦбЇЯАОпгаЧПЭиеЙадЕФжѕФПЬиЕуЪЙНќФъРДЕФШЫЙЄжЧФмСьгђЖдЦфНјааСЫНЯЖрЕФЙизЂЁЃ
| ШЮЮё | ЧЈвЦбЇЯА | ДЋЭГЛњЦїбЇЯА |
|---|---|---|
| Ъ§ОнЗжВМ | бЕСЗКЭВтЪдЪ§ОнВЛашвЊЭЌЗжВМ | бЕСЗКЭВтЪдЪ§ОнЭЌЗжВМ |
| Ъ§ОнБъЧЉ | ВЛашвЊзуЙЛЕФЪ§ОнБъзЂ | зуЙЛЕФЪ§ОнБъзЂ |
| НЈФЃ | ПЩвджигУжЎЧАЕФФЃаЭ | УПИіШЮЮёЗжБ№НЈФЃ |
ЧЈвЦбЇЯАЕФЙиМќМДЪЙДгВЛЭЌЕФдЪМЪ§ОнМЏжаЬсШЁФПБъЕФЯрЫЦад,вдНЈСЂЦ№ДгвдЭљЕФбЇЯАФЃаЭжаЯђаТЕФНјЛЏФЃаЭжаЯрЛЅЧЈвЦНјааНјЛЏЕФПЩФмЫїв§ЁЃ
ДгЫуЗЈЕФбЕСЗМЏНЧЖШРДЫЕ,ЧЈвЦбЇЯАПЩвдЪЕЯжаЁбљБОЕФЧПгХЛЏадФмЁЃЭМЯёЪЖБ№ЪЧзюОЕфЕФРћгУВЛЖЯВЙГфбЕСЗМЏНјааДѓСПбЇЯАЕФСьгђжЎвЛ,ЦфЭЈЙ§ОоаЭЕФбЕСЗМЏбЕСЗПЩвдНЋжюЖрЕФаЮЬЌбЇЬиеїКЭЮЦРэЬиеїЕУвдбЇЯА,ШЛКѓЭЈЙ§ВЙГфЪ§ОнНјааНјвЛВНЕФИќе§ЁЃ
дкЧЈвЦбЇЯАжа,ЫуЗЈЛсИљОнЪ§ОнЛЏЕФбЕСЗМЏдкЭГвЛзжЖЮжаНјааСЌајбЕСЗКЭЪЖБ№,габЁдёЕиНјааЛљгкбљБОЧЈвЦКѓЬиеїЕФЧЈвЦ,зюжеЭъГЩФЃаЭЧЈвЦгыТпМЧЈвЦЁЃЦфжа,бљБОЧЈвЦЕФЛљБОЪЧашвЊНЋдДЪ§ОнКЭФПБъБъЧЉНјааБфЛЛзюжеНјШыЕНаТЕФЮЌЖШПеМф,ИУПеМфПЩФмКЭдЪМПеМфОпгаИДдгЕФБфЛЛЙиЯЕ,зюжедкБфЛЛжаЭЈЙ§ЖдИїРрОрРыЕФзюаЁЛЏдМЪјЭъГЩЬиеїЕФЧЈвЦ,ЖјОЙ§ОрРыгХЛЏЙ§ГЬжаЭЌЪБЭъГЩСЫФЃаЭЕФЧЈвЦЁЃећЬхЙ§ГЬжаВЛНіДцдкзХЖдгаБъЧЉЪ§ОнЕФМрЖНбЇЯА,вВФвРЈСЫдкЧЈвЦЙ§ГЬжаВЛПЩЩйЕФЮоМрЖНКЭАыМрЖНбЇЯА
БпдЕМЦЫугХЪЦ
гЩгкМЦЫуЩшБИКЭЪ§ОндДЕФОрРыгХЪЦ,ВЩгУБпдЕММЪѕЕФСьгђ,ПЩвдЪЕЪБЗДРЁКЭДІРэ,ЯрЖдгкдЦМЦЫу,РрБШгкЕчСІЯЕЭГЕФЙТЕККЭВЂЭјдЫаа,ИќОпгаЯШЬьЕФАВШЋадЁЃ
злЩЯЫљЪі,БпдЕМЦЫуОпгаШчЯТЕФЬиЕуЁЃ
(1)ЗжВМЪНКЭЕЭбгЪБЁЃБпдЕЫБЛПЩвдНЈСЂдкОрРыЪ§ОнНгЪедДКмНќЕФЮЛжУ,вђДЫетжжЩшБИПЩвдЪЕЪБЛёШЁЪ§ОнВЂНјааЗжЮі,ДгЖјПЩвдИќКУЕижЇГжБОЕиЦѓвЕЕФЪЕЪБжЧФмДІРэКЭжДааЁЃ
(2)жДаааЇТЪИпЁЃБпдЕМЦЫугЩгкЯШЬьОпгаНќЖЫЗжЮіЕФНсЙЙЬиад,ПЩвддкгУЛЇНкЕуОЭЖдД§ДІРэЪ§ОнНјааЯрЙиЗжЮі,ЯрБШДЋЭГЕФДЋЪфЕНКѓЗННјааМЏжаДІРэ,етжжЗжВМЪНЕФХфжУОпгаЯджјЕФИпаЇадЁЃ
(3)НкЪЁЭјТчзЪдДЁЃБпдЕМЦЫуЕФЪ§ОнДІРэШЮЮёПЩвддкдЦЖЫЪфЫЭЧАОЭЭъГЩвЛВПЗж,ДгЖјМѕЩйМЏжаДІРэЕФбЙСІ,ВЂгааЇМѕЩйЪЕМЪДЋЫЭЕФСїСПЁЃвЛЗНУцеыЖдгаЯоЭЬЭТСПЪБДѓЗљЖШЬсИпЪфЫЭЕФаХЯЂдиКЩ,СэвЛЗНУцвВМѕЩйСЫЗўЮёЦїЖЫЕФдЫЫуашЧѓЁЃ
(4)АВШЋадИќИпЁЃЕБДѓСПгУЛЇЪ§ОнЪфШыЕНдЦЖЫЪБ,ПЩФмЛсГіЯжФГаЉВЛСМШЫдБЕСШЁЪ§Он,дкгУЛЇВЛжЊЧщЕФЧщПіЯТЪЙгУгУЛЇЪ§Он,ЖјБпдЕМЦЫудкНгЪеЕНЪ§ОнжЎКѓ,ПЩвдЖдЪ§ОнМгУмЛђЗжЮіДІРэжЎКѓдйНјааДЋЪф,ЬсЩ§СЫЪ§ОнЕФАВШЋад,ВЂЧвБЃжЄСЫгУЛЇЕФвўЫНЁЃ
(5)авщБъзМЛЏЁЃЗжВМЪНдЫЫуашвЊаЕїИїЪ§ОнНкЕуЕФЭЈаХавщ,дкНјааЮеЪжЪБ,БмУтВњЩњЖюЭтЕФЪ§ОнЕФНтЮіМЦЫу,СэвЛЗНУцгЩгкЪ§ОнИёЪНЕФВювьад,вВБиаыБмУтдкЖрЗНазїЪБВњЩњДэЮѓЁЃвђДЫашвЊЖдећЬхЕФМЦЫуМЦЫуНјааавщЭГвЛКЭБъзМЭГвЛЁЃ
ФПЧА,БпдЕМЦЫувбОГЩЮЊдЦМЦЫуЕФживЊММЪѕжЎвЛЁЃЕЅвЛЕФИпадФмДѓШнСПМЦЫуЕЅдЊе§дкБЛЗжВМЪНЕФдЦМЦЫуазїШЁДњ,етбљЕФШЁДњОпгаИќИпЕФЫйЖШ,ВЂФмЭъГЩФГаЉЪЕЪБадЙЄзїЁЃ
вдЕчЩЬЮЊР§,дкгУЛЇВрНјааЙКЮяЭЦМіЫуЗЈЕФВПЗжМЦЫу,ПЩвдгааЇЛКНтЭјеОЩЯЕФМЦЫуЕЅдЊЕФИККЩ,ВЂПЩвдЪЕЯждкМЦЫуЪБМфФкНќКѕЪЕЪБадЕФИљОнгУЛЇЕФЯВКУЭъГЩЭЦМіШЮЮё,етОЭЪЧБпдЕМЦЫудкдЦМЦЫуДѓЛЗОГЯТЕФЪЕМЪгІгУЁЃ