��������
Selective Search: ��Ҫ˼�����Ȱ������ؽ�ͼ��ָ��С����,�ٲ鿴����С����,���պϲ�����ϲ���������ߵ�������������,�ظ�ֱ������ͼ��ϲ���һ������λ�á�
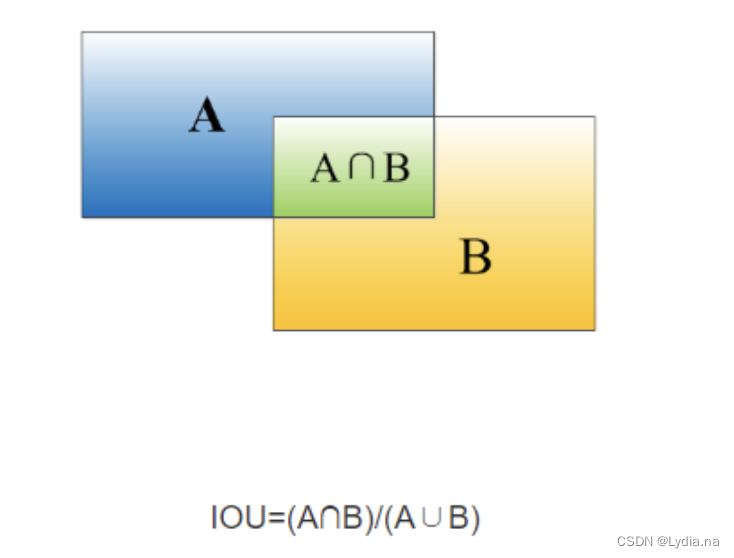
IoU(�ص���Intersection of Uint): ��������bounding box�Ķ�λ���ȡ����������ο���ص����ռ�������ο������������
�Ǽ���ֵ����(NMS): ���Ʋ��Ǽ���ֵ��Ԫ��,�����ֲ��ļ���ֵ��
�㷨����:
- �ڵ�ǰ���ĺ�ѡ�߽����Ѱ�ҵ÷���ߵı߽��;
- ���������߽����ñ߽���IOUֵ;
- ɾ������IOUֵ���ڸ�����ֵ��Ŀ�߽��;
mAP(mean Average Precision): ��ÿһ�����AP,Ȼ����ƽ����
һ��R-CNN
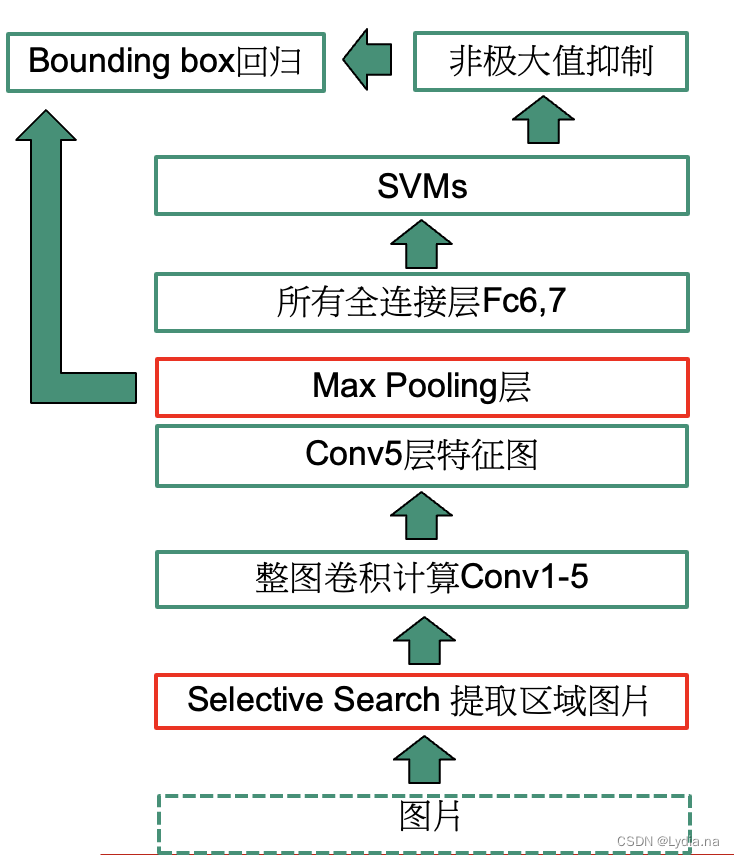
1. ����ṹ
���������:
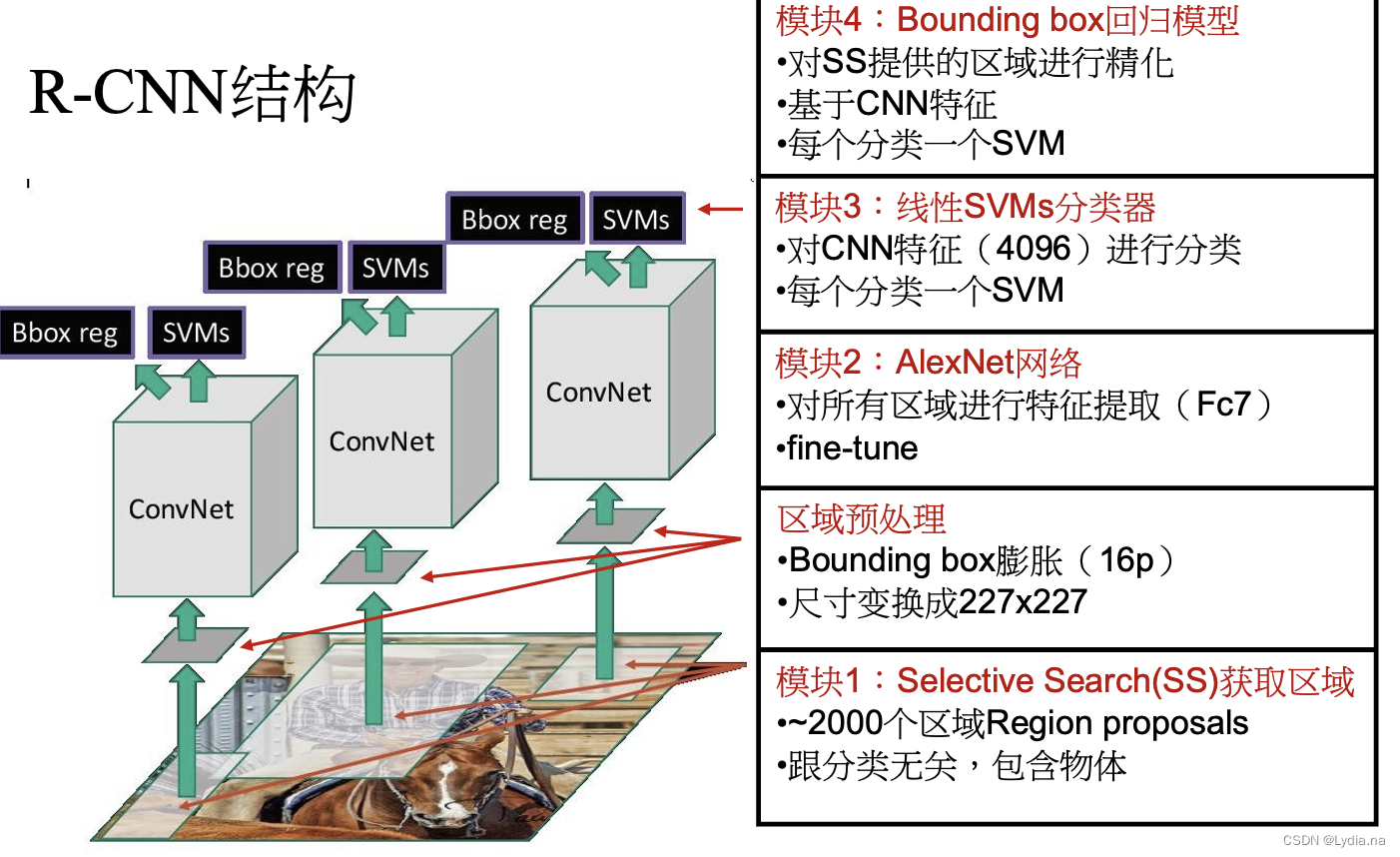
�㷨��Ҫ��Ϊ4������:
- ͨ��Selective Search������ȡԼ2000�ź�ѡ����;
Selective Search�㷨�������������� - ��ÿ����ѡ����ʹ��CNN��ȡ����;
ͨ������Ԥ����������ͼƬ��Bounding box��������16������,�任�� 227 �� 227 227\times 227 227��227��ͼƬ;֮�����Ԥѵ���õľ���������õ�����ͼ�� - ��
fc7��������ÿһ��SVM������,�жϸ������Ƿ����ڸ���;
�� 2000 �� 4096 2000\times 4096 2000��4096ά������20��SVM��������ɵ� 4096 �� 20 4096\times 20 4096��20ά��Ȩ�ؾ������,�õ� 2000 �� 20 2000\times 20 2000��20ά����,�þ����ʾ��ʾÿ���������ij��Ŀ��ĵ÷֡� - ��
conv5��������Bounding box�ع龫��Ԥ���ṹ
ͨ���Ǽ���ֵ����(NMS)�������ʣ��߽����н�һ��ɸѡ,����ʹ��20���ع�����20�����Ļع����лع����,���ҶԺ�ѡ����������õ����յı߽��
2. ѵ������
-
Ԥѵ��:ʹ��
ImageNet���ݼ���CNNģ�ͽ���Ԥѵ����ʼ�����������- ����Ŀ�����ѵ�����ݽ���,���Ҫֱ�Ӳ��������ʼ��CNN�����ķ���,��ôĿǰ��ѵ����������ԶԶ������,���Բ����мල��Ԥѵ������ֱ��ʹ��Alexnet,VGG�����������
-
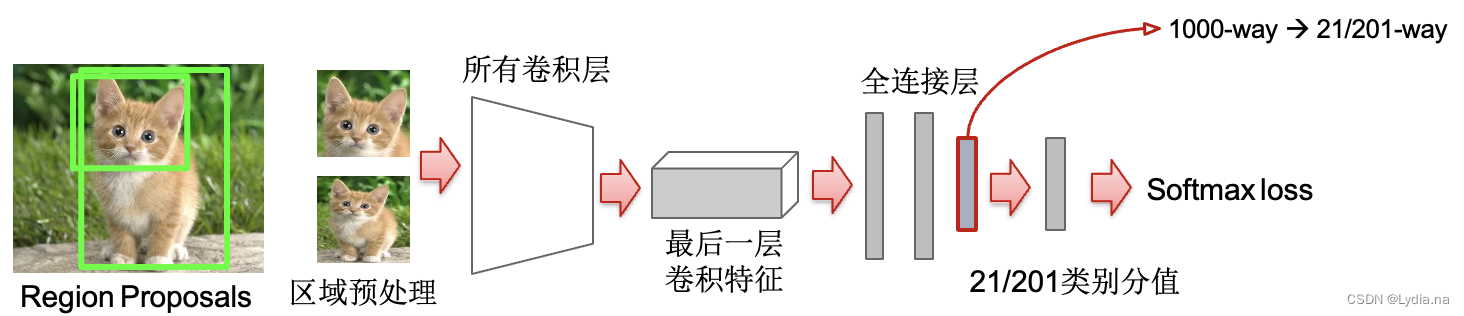
fine- tuning:ʹ��SS�㷨���ɵ����������Ԥѵ�����������������
- Log loss
- ���ǽ����������һ���滻��,�滻ΪN+1����Ԫ��softmax��(N��+1���),Ȼ����һ����ò��������ʼ���ķ���,���������IJ�������,������SGDѵ��:��ʼ��ʱ��,SGDѧϰ��ѡ��0.001,��ÿ��ѵ����ʱ��,����batch size��Сѡ��128,����32����������96����������
- ��SS�㷨��ѡ���ĺ�ѡ�����˹���ע���ο���ص�����IoU>0.5,��Ϊ������,��֮��Ϊ������(�������)
- ���������ض����������fine-tuning,���ǽ�����CNN����������ȡ��,������ѧ���ľ��ǻ����Ĺ���������ȡ��,����������ȡ����ͼƬ������,��f6,f7��ѧϰ������������������ض������������
��������ѧϰ����Ϊ��������,ȫ���Ӳ���ѧϰ�������ض������������
-
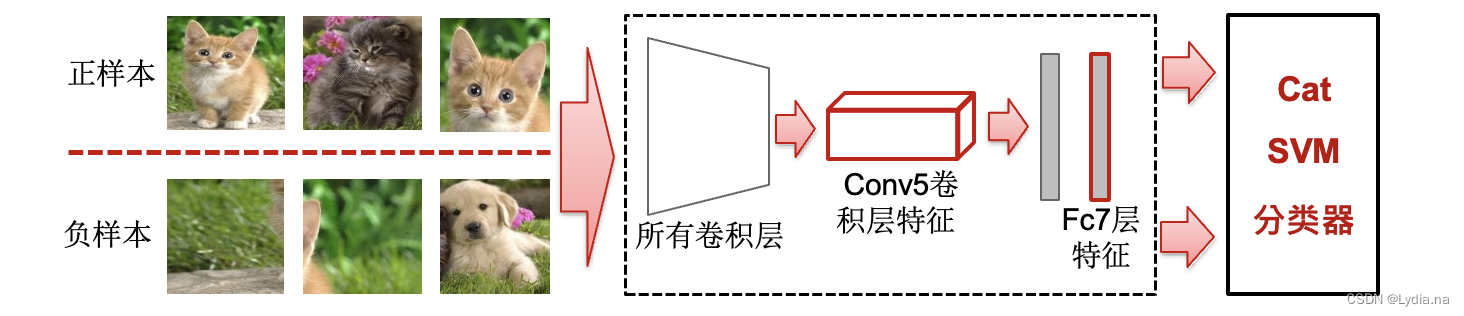
SVM����:ʹ������������е�
fc7ѵ��SVM���Է�������- Hinge Loss
- ÿ�����(N��)��Ӧһ��������
- IoU��ֵ����Ϊ0.3,���ص��ȴ���0.3ʱ����Ϊ������,��֮��
- һ��CNN fc7����������ȡ����,��ÿ��������ѵ��һ��svm������,ͨ�������ж�����Ҫ�����廹��backgound��
-
Bounding Box�ع�:ʹ������������е�
conv5ѵ��Bounding Box�ع�ģ�͡�-
Square Loss
-
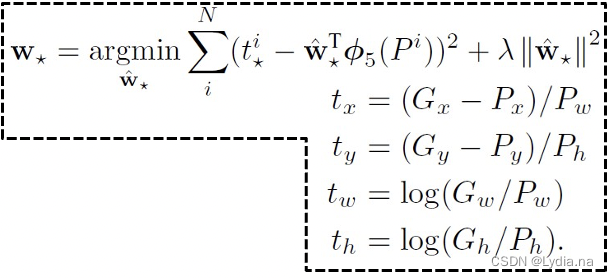
-
ÿ�����ѵ��(N��)ѵ��һ���ع�ģ��
-
IoU��ֵ����Ϊ0.3,���ص��ȴ���0.3ʱ����Ϊ������,��֮��
-
����Ŀ��������ĺ��������ص����:�����ȷ�ļ����,������Ϊ��ѡ��ȷ,�ص������С������һ��λ�þ�����:��ÿһ��Ŀ��ʹ��һ�����Իع�ģ�ͽ��о��ޡ������� �� = 1000 \lambda=1000 ��=1000������Ϊ
conv5��4096ά����,���Ϊxy��������ź�ƽ�ơ�
-
3. ���Խ�
- ʹ��SS�㷨��ȡ��2000������Ŀ��ͼ;
- ��ÿ������Ŀ��ͼͨ��Ԥ������һ����
227
��
227
227\times 227
227��227;
ʹ��fine-tune����CNN����2������ fc7-> SVM -> ����ֵ- NMS(IoU>=0.5)��ȡ������������Ӽ�
con5-> Bounding box -> Boxƫ��- ʹ��Bboxƫ�����������Ӽ�
4. RNN���ڵ�����
- �����ٶ���,����һ��ͼƬ��CPU����Ҫ53S,ʹ��Selective Search�㷨��ȡ��ѡ����Ҫ2S,һ��ͼ���ں�ѡ��֮����ڴ����ص�,��ȡ�����������ڴ�������;
- ѵ���ٶ���,���̼��䷱��,������Ҫѵ��ͼ���������,����Ҫѵ��SVM��������Bounding Box�ع���,ѵ�����̶����������;
- ѵ������ռ��,����SVM��Bounding Box�ع�ѵ��,��Ҫ��ÿ��ͼ���е�ÿ��Ŀ���ѡ����ȡ����,��д�����,���ڷdz��������,ѵ������5Kͼ������ȡ��������Ҫ����GB�Ĵ洢�ռ䡣
Q: Ϊʲôʹ��SVM���ֱ��ʹ��softmax�������?
A: svmѵ����cnnѵ�����̵������������巽ʽ���в�ͬ,����������CNN softmax����Ȳ���svm���Ȼ��͡�ѵ�������ж���ѵ�����ݵı�ע�ܿ���(bounding boxֻ����һ����)���Ϊ������,�������;svm����ѵ���������ݵ�iouҪ���ϸ�(bounding box������������)��
����SPP-Net
��R-CNN�Ļ���������������µ�:������������ͽ������ػ�(spatial pyramid pooling)��
- ������������: ��conv5�������ȡ���������������
- �������ػ�: Ϊ��ͬ�ߴ������,��Conv5�����ȡ����;ӳ�䵽�ߴ�̶���ȫ���Ӳ��ϡ�
1. ����ṹ

�㷨��Ҫ��Ϊ5����(����RCNN����):
- ͨ��Selective Search������ȡԼ2000�ź�ѡ����;
- ��ÿ����ѡ����ʹ��CNN��ȡ����;
- ��CNN��ȡ�������ͼ��ȡSPP����
- ��
fc7��������N��SVM������,�жϸ������Ƿ����ڸ���; - ��
conv5��������N��Bounding box�ع龫��Ԥ���ṹ
2. ����֪ʶ
������������
ֱ����������ͼƬ,����һ�ι�����������,��conv5��������������������
�������ػ� Spatial Pyramid Pooling
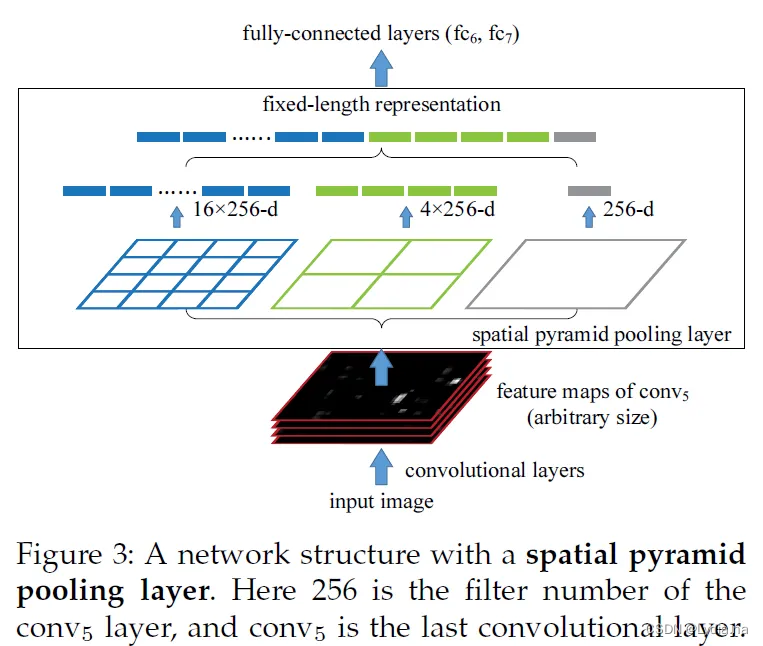
��R-CNN��,��Ҫ��ÿ����ѡ��ͳһ��С��ֱ���ΪCNN������,��Ч����ʱ��SPP���ֻ��ԭͼ����һ�ξ�������,�õ�����ͼ�ľ�������,Ȼ���ҵ�ÿ����ѡ��������ͼ�ϵ�ӳ��,��ӳ����Ϊ��ѡ��ľ����������뵽SPP����,�任����ͬ�߶ȡ�
�������:
��spp�滻conv5�е�pooling��,spp��˼·�Ƕ��������С��feature map���ȷֳ�3����ͬlevel���и�ͼ,�и�ߴ�ֱ�Ϊ
1
��
1
1\times 1
1��1��
2
��
2
2\times 2
2��2��
4
��
4
4\times 4
4��4,ÿ���и�ͼ�õ�1,4,16����,Ȼ����ÿ���������ػ�,�ػ��������ƴ�ӵõ�һ���̶�ά�ȵ������������ȫ���Ӳ����Ҫ��
3. ѵ������
- Ԥѵ��:ʹ��ImageNet���ݼ���CNNģ�ͽ���Ԥѵ����ʼ�����������
- SPP����:��������SS�����SPP������
- fine-tuning:ʹ��SPP������ȫ���Ӳ��������
- SVM����:ʹ���������
fc7������ÿһ�����svm���ࡣ - bounding box�ع�:ʹ��spp��������bounding box�ع顣
- R-CNN��ʹ��conv5����bounding box�ع�
- ֻ��ȫ���Ӳ����fine-tuning
4. ��������
�����ṹ��R-CNN����,��Ԥ��������ȥ��,��ͼƬ���й�����������,���õ���conv5������ͼ��SS�㷨��ȡ������ͼ����ӳ��õ�ԭͼ������ΪSPP�������,SPP�㽫��ͬ�ߴ��ӳ�䵽ԭͼ��������н������ػ������ɳߴ���ͬ������ͼ,�ٽ���ȫ���Ӳ�,���������R- CNN���ơ�
- ��R-CNN��ͬ����SPP��ͼƬ�����㲻��fine-tunning,ֻ��������ʱ����ʱ����fine-tunning��
5. ��������
- �̳���RCNNʣ������: ��Ҫ�洢�������������ӵĶ��ѵ����ѵ��ʱ���Գ�
- ������:SPP��ȡ����ǰMax pooling��,������ͼת��Ϊ224*224��,���� SPP��������(��Ϊ3���ߴ��bin)SPP��֮ǰ�����о������������finetune,ȱ��Ǩ�ƵĿ����ԡ�
���� Fast R-CNN
��SPP�Ļ��������3���Ľ�:
- ʵ��end-to-end����ѵ��,ͨ����������ʧ����ʵ��end-to-end.
- ���в�IJ���������finetune
- ����Ҫ���ߴ洢�����ļ�
Fast R-CNN��SPP Net�Ļ�������������Ż���:����Ȥ����ػ���(ROI pooling)����������ʧ����(Multi- task loss)��
1. ����ṹ
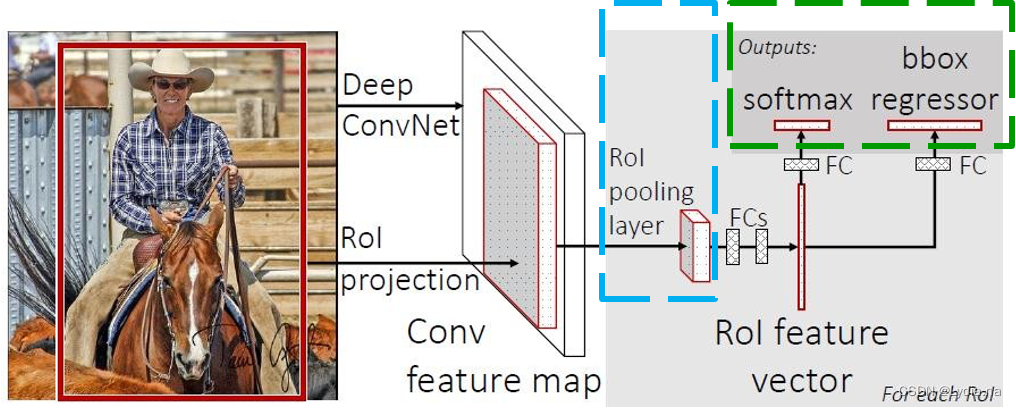
�㷨�����Ϊ5��:
- ͨ��Selective Search������ȡԼ2000�ź�ѡ����;
- ��ÿ����ѡ����ʹ��CNN��ȡ����;
- ��CNN��ȡ�������ͼ��ȡROI����
- ��
fc7��������N+1��softmax����,�жϸ������Ƿ���������; - ��
conv5��������N��Bounding box�ع龫��Ԥ���ṹ
��SPP����ṹ��ͬ��:
- ��ȡ������backbone��AlexNet�Ļ�ΪVGG,��ȡ����������ǿ
- SPP Pooling�滻ΪROI Pooling
- SVM����ͻع�����ʹ�ö�������ʧ�������,Ŀ��������Ͳ���Ҫ�ֽ�ѵ��
- ��ȡ��ROI������������������������֧��ʹ��softmax���SVM������(C+1��,����background)��FCȫ���ӱ߽��ع��������LR�ع�ģ��,�µı߽��ع��������Ӧ(C + 1)�����ĺ�ѡ��߽�ع����(dx, dy, dw, dh),�����(C + 1) * 4���ڵ�,����ͼÿ4��һ��,����ع�����ĺ�����RCNN����һ�¡�
2. ����֪ʶ
����Ȥ����ػ��� (ROI pooling)

ROI pooling��SPP pooling�ĵ���������ROI pooling�ǽ�ROI����ľ����������Ϊ H �� W H \times W H��W����,Ȼ���ÿ��Bin�ڵ�������������Max pooling��
��������ʧ(Multi-task loss)
��ʧ����Ϊ: L ( p , u , t u , v ) = L c l s ( p , u ) + �� [ u �� 1 ] L l o c ( t u , v ) L(p,u,t^u,v)=L_{cls}(p,u)+\lambda [u\ge 1]L_{loc}(t^u,v) L(p,u,tu,v)=Lcls?(p,u)+��[u��1]Lloc?(tu,v)
����ʧ������Ϊ������,��һ���ַ���������ʧ: L c l s ( p , u ) = ? l o g p u L_{cls}(p,u)=-logp_u Lcls?(p,u)=?logpu?,����pΪÿ��ROI�ĸ��ʷֲ�,uΪGround truth���
�ڶ�����Ϊ�ع�����ʧL1 loss:
L
l
o
c
(
t
u
,
v
)
=
��
i
=
{
x
,
y
,
w
,
h
}
s
m
o
o
t
h
L
1
(
t
i
u
?
v
i
)
L_{loc}(t^u,v)=\sum_{i=\{x,y,w,h\}}smooth_{L1}(t_i^u-v_i)
Lloc?(tu,v)=i={x,y,w,h}��?smoothL1?(tiu??vi?)
s
m
o
o
t
h
L
1
(
x
)
=
{
0.5
x
2
,
�O
x
�O
<
1
�O
x
�O
?
0.5
,
o
t
h
e
r
w
i
s
e
smooth_{L1}(x)=\left\{\begin{matrix} 0.5x^2 & ,\left | x \right |< 1 \\ \left | x \right |-0.5 &,otherwise \end{matrix}\right.
smoothL1?(x)={0.5x2�Ox�O?0.5?,�Ox�O<1,otherwise?
����
v
=
{
v
x
,
v
y
,
y
w
,
v
h
}
v=\{v_x,v_y,y_w,v_h\}
v={vx?,vy?,yw?,vh?}Ϊƫ��Ŀ��,
t
u
=
{
t
x
u
,
t
y
u
,
t
w
u
,
t
h
u
}
t^u=\{t_x^u,t_y^u,t_w^u,t_h^u\}
tu={txu?,tyu?,twu?,thu?}ΪԤ��ƫ��,
[
u
��
1
]
[u\ge1]
[u��1]Ϊָʾ����,����ֵΪ1��ʱ�����Ϊ�������,�лع�loss;��ֵΪ0ʱ,����Ϊ�������,û�лع�loss.
Ԥ��ƫ��ļ��㹫ʽ:
t
x
=
(
G
x
?
P
x
)
/
P
w
t
y
=
(
G
y
?
P
y
)
/
P
h
t
w
=
l
o
g
(
G
w
/
P
w
)
t
h
=
l
o
g
(
G
h
/
P
h
)
\begin{matrix} t_x=(G_x-P_x)/P_w\\ t_y=(G_y-P_y)/P_h\\ t_w=log(G_w/P_w)\\ t_h=log(G_h/P_h) \end{matrix}
tx?=(Gx??Px?)/Pw?ty?=(Gy??Py?)/Ph?tw?=log(Gw?/Pw?)th?=log(Gh?/Ph?)?
3.ѵ��&��������

ѵ������: ������ͼƬ���뵽CNN������,ͬʱ����ss�㷨��ȡ��ѡ��,��Conv5����ͼ��ӳ�䵽��ѡ�����������,��ROI Pooling,�������̶���С,Ȼ��ȫ���Ӳ�,�ֱ�ȫ���Ӳ����������뵽SoftMax��������Bounding box�ع�����(�������ά����Ҫ�ٽ�һ��FC),ʹ�ö����������ʧ�������м�����ݶȻش�,ʵ�ֶ˵��˵�����ѵ����
��pre-trainedģ������finetune����Fast R-CNNѵ��ʱ,����ݶ��½�(SGD)��С����(mini-batches)���÷ֲ����,���Ȳ���N��ͼ��,Ȼ�����ÿһ��ͼ�����R/N��RoI����
- batch_size=128
- Batch�ߴ�(128)=ÿ��batch��ͼƬ����(2)*ÿ��ͼƬROI����(64)
- һ��batch��������ͼƬ,ÿ��ͼƬ����ȡ64����ѡ����,����������Ϊ1:3,�������ж�����ΪIOUֵ����0.5,�������ж�������IOUҪ��0.1-0.5֮��,��һ�������ھ�IJ��ԡ�
��������: ��ѵ��������ͬ,Ϊÿһ����Ϻ���NMS�㷨���ɡ�
�ġ�Faster R-CNN
Ϊ���Fast RCNN�㷨��SSѡ���ʱʱ�䳤������,Faster RCNN���һ��RPN(Region Proposal Network)����,������������Fast RCNN��ͬ,��Faster RCNN = RPN + Fast RCNN,RPNȡ��������Selective Searchģ��,���������ƿ����ͬʱFaster RCNN��һ���������������,������Attention����,����
1. ����ṹ
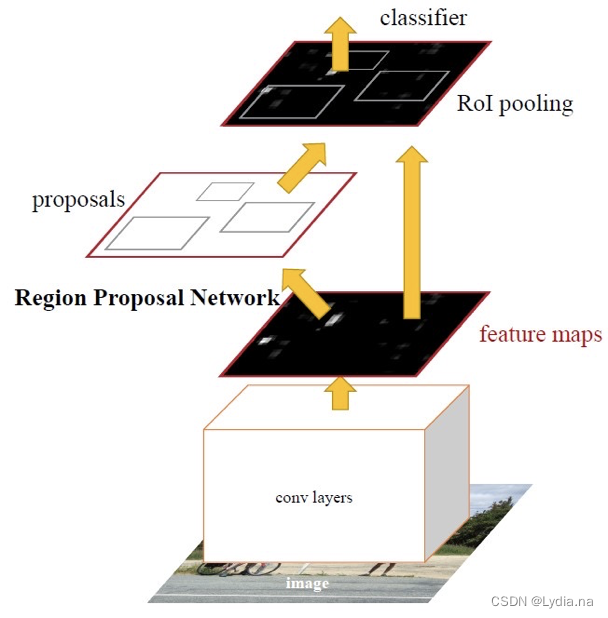
- ��ͼ�����뵽CNN����õ�����ͼ
- ʹ��RPN����ṹ���ɺ�ѡ��,Ȼ����ЩRPN���ɵĺ�ѡ��ͶӰ����һ���õ���Ӧ����������
- Ȼ��ÿ����������ͨ��ROI Pooling�����ŵ��̶��� 7 �� 7 7\times7 7��7��С������ͼ,�������ͼflatten��һϵ��ȫ���Ӳ�õ�����ͻع�Ľ����
2. RNP
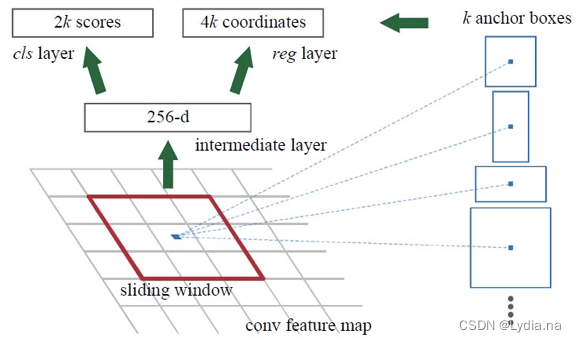
1.����ṹ
RNP�������ṹ����:
- ��RNP��������ͼƬ
Conv5�� 13 �� 13 �� 256 13\times13\times256 13��13��256������ͼ,���ξ��� 3 �� 3 �� 256 3\times3\times256 3��3��256�ľ����˺� 1 �� 1 �� 256 1\times 1\times256 1��1��256�ľ����˺�ReLu�����,�õ� 3 �� 3 �� 256 3\times3\times256 3��3��256���������� - ���õ����������������뵽������֧��,��һ����֧ c l s ? l a y e r cls \ layer cls?layer��2k�� 1 �� 1 �� 256 1\times 1\times256 1��1��256�����˽��о���,���2k����,��ʾij��������û������ķ�����
- �ڶ�����֧ r e g ? l a y e r reg \ layer reg?layer��4k�� 1 �� 1 �� 256 1\times 1\times256 1��1��256�����˽��о���,������4k����,��ʾx,y,w,h��ƫ������
2.Anchor
Anchor boxΪͼ���еIJο���,��Ӧ����ṹ�е�k,һ����˵k=9,�ֱ������3���߶Ⱥ�3��������ratio����ϡ�
- 3���߶�:[128,256,512]
- 3��ratio:1:1,1:2,2:1
- RPN��������������ͼ�����
3
��
3
3 \times 3
3��3�ľ���,����ͼλ�ú�ԭͼ��֮���ж�Ӧ��ϵ,����Anchor box�ο�������ľ��Ǿ����� ������,��
conv5����ÿ����һ�ξͻ��Զ���Ӧ9��Anchor box,������ϵı߽��ƫ��������Anchor box��ƫ������
3.Loss Function
L
(
{
p
i
}
,
{
t
i
}
)
=
1
N
c
l
s
��
i
L
c
l
s
(
p
i
,
p
i
?
)
+
��
1
N
r
e
g
��
i
p
i
?
L
r
e
g
(
t
i
,
t
i
?
)
L(\{p_i\},\{t_i\})=\frac{1}{N_{cls}\sum_{i}L_{cls}(p_i,p_i^*) }+\lambda \frac{1}{N_{reg}\sum_{i}p_i^*L_{reg}(t_i,t_i^*) }
L({pi?},{ti?})=Ncls?��i?Lcls?(pi?,pi??)1?+��Nreg?��i?pi??Lreg?(ti?,ti??)1?
- p i p_i pi?Ϊ��i��anchorԤ��Ϊ��ʵ��ǩ�ĸ���
- p i ? p_i^* pi??Ϊ������ʱΪ1,������Ϊ��(����������Faster RCNN�а���ɭ����)
- t i t_i ti?��ʾԤ���i��Anchor box�ı߽��ع����
- t i ? t_i^* ti??��ʾ��i��Anchor box��Ӧ��GT Box
- N c l s N_{cls} Ncls?��ʾһ��mini-batch����������������
- N r e g N_{reg} Nreg?��ʾAnchor boxλ�ø���
��һ����Ϊ������ʧ,��ʹ�ö�����Softmax��������ʧ,���ڷ������ֻ�б�����ǰ��,��˶���k��Anchor box����2k��ֵ����ʹ�õ��Ƕ�����Ľ�������ʧ,����ÿ��Anchor boxֻ����һ������,����k��Anchor box����k��ֵ��
�ڶ�����Ϊ�߽��ع���ʧ,��ʽ��Faster RCNN���ơ�
4.RPN Loss��Fast RCNN Loss����ѵ��
���岽������:
- ѵ��RPN����
ʹ��Image NetԤѵ������ģ�ͳ�ʼ�����������; - ѵ��Fast RCNN����
ʹ��Image NetԤѵ������ģ�ͳ�ʼ�����������;Region proposals�ɲ���1��RPN���� - ����RPN
ʹ��Fast RCNN���������������г�ʼ��;
�̶�������,finetuneʣ��� - ����Fast RCNN
�̶�������,finetuneʣ���;Region proposals�ɲ���3��RPN���ɡ�
�����
RCNN- ��CNN����Ŀ����Ŀ�ɽ֮��
��Rcnn��Ϊʲôʹ��IoU�Ǽ���ֵ����?
fast rcnn ���Ľ��(����������)
Fast R-CNN
RCNNϵ��(R-CNN��Fast-RCNN��Faster-RCNN��Mask-RCNN)
RCNN��Fast-RCNN��Faster-RCNN���㷨�����Լ����е��ѵ�
һ�Ķ���Ŀ����:R-CNN��Fast R-CNN��Faster R-CNN��YOLO��SSD
���ٵ�����������緽��(Fast R-CNN)