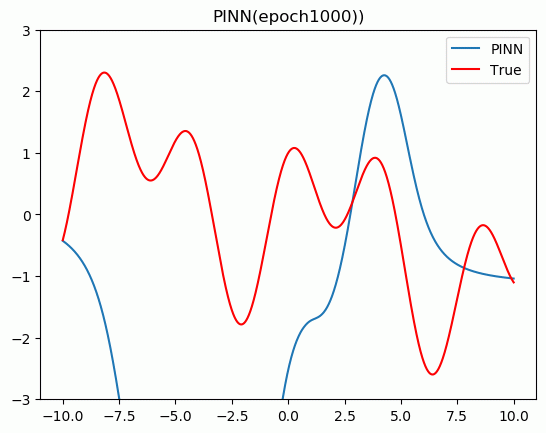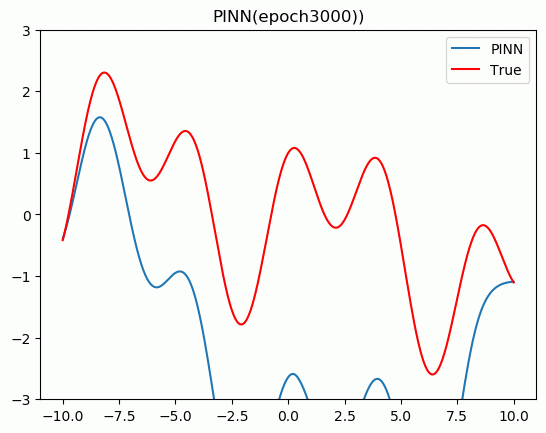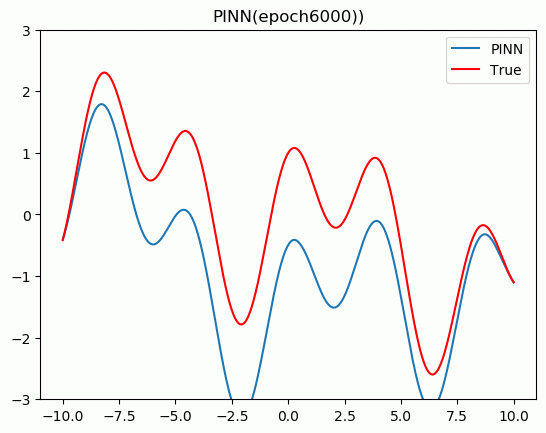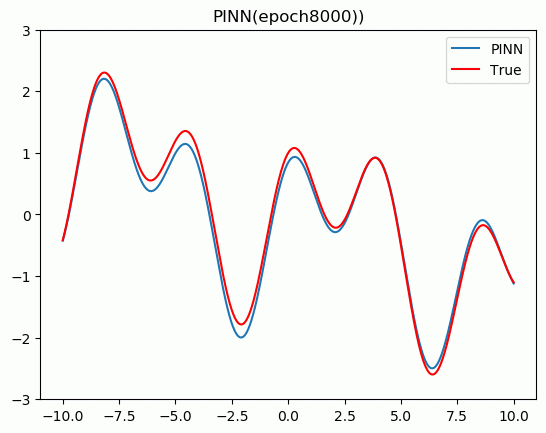
�����ҽ�������Ƕ����֪ʶ������(PINN)����ַ��̡����Ƚ���PINN��������,������Pytorch���ʵ�����һάPoisson���̡�
���ѧϰ����ַ���ϵ�ж�:PINN���burger����
��Ƕ����֪ʶ������(PINN)���ż������ܽ�
1.PINN���
��������Ϊһ��ǿ�����Ϣ���������ڼ�����Ӿ�������ҽѧ�� ������������õ��㷺Ӧ��, ���������������.�����ѧϰ������зdz�ǿ��ѧϰ����, �����ܷ�����������, �������ƫ�ַ���.��������,�������ѧϰ��ƫ�ַ�����������о����ȵ㡣��Ƕ����֪ʶ������(PINN)��һ�ֿ�ѧ�����ڴ�ͳ��ֵ�����Ӧ�÷���,�ܹ����ڽ����ƫ�ַ��� (PDE) ��صĸ�������,����������⡢�������ݡ�ģ�ͷ��֡��������Ż��ȡ�
2.PINN����
PINN����Ҫ˼����ͼ1,�ȹ���һ��������Ϊ
u
^
\hat{u}
u^��������,������ΪPDE��Ĵ���ģ��,��PDE��Ϣ��ΪԼ��,���뵽��������ʧ�����н���ѵ����
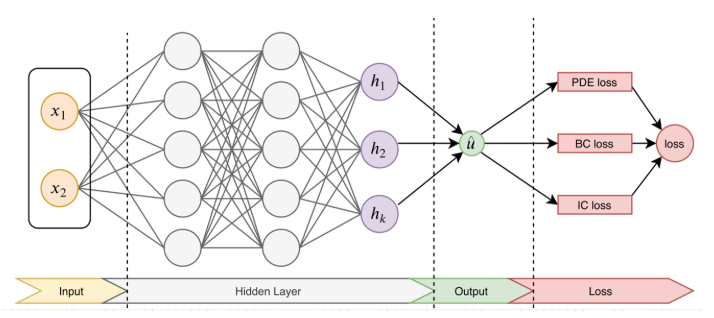
��ʧ������Ҫ����4����:ƫ�ֽṹ��ʧ(PDE loss),��ֵ������ʧ(BC loss)����ֵ������ʧ(IC loss)�Լ���ʵ����������ʧ(Data loss)���ر��,�������������PDE����,����PDE�Ľ�
u
(
x
)
u(x)
u(x)��
��
?
R
d
\Omega \subset \mathbb{R}^{d}
��?Rd����,����
x
=
(
x
1
,
��
,
x
d
)
\mathbf{x}=\left(x_{1}, \ldots, x_{d}\right)
x=(x1?,��,xd?):
f
(
x
;
?
u
?
x
1
,
��
,
?
u
?
x
d
;
?
2
u
?
x
1
?
x
1
,
��
,
?
2
u
?
x
1
?
x
d
)
=
0
,
x
��
��
f\left(\mathbf{x} ; \frac{\partial u}{\partial x_{1}}, \ldots, \frac{\partial u}{\partial x_{d}} ; \frac{\partial^{2} u}{\partial x_{1} \partial x_{1}}, \ldots, \frac{\partial^{2} u}{\partial x_{1} \partial x_{d}} \right)=0, \quad \mathbf{x} \in \Omega
f(x;?x1??u?,��,?xd??u?;?x1??x1??2u?,��,?x1??xd??2u?)=0,x����
ͬʱ,��������ı߽�
B
(
u
,
x
)
=
0
?on?
?
��
\mathcal{B}(u, \mathbf{x})=0 \quad \text { on } \quad \partial \Omega
B(u,x)=0?on??��
Ϊ�˺���������
u
^
\hat{u}
u^��Լ��֮��IJ���,������ʧ��������:
L
(
��
)
=
w
f
L
P
D
E
(
��
;
T
f
)
+
w
i
L
I
C
(
��
;
T
i
)
+
w
b
L
B
C
(
��
,
;
T
b
)
+
w
d
L
D
a
t
a
(
��
,
;
T
d
a
t
a
)
\mathcal{L}\left(\boldsymbol{\theta}\right)=w_{f} \mathcal{L}_{PDE}\left(\boldsymbol{\theta}; \mathcal{T}_{f}\right)+w_{i} \mathcal{L}_{IC}\left(\boldsymbol{\theta} ; \mathcal{T}_{i}\right)+w_{b} \mathcal{L}_{BC}\left(\boldsymbol{\theta},; \mathcal{T}_{b}\right)+w_{d} \mathcal{L}_{Data}\left(\boldsymbol{\theta},; \mathcal{T}_{data}\right)
L(��)=wf?LPDE?(��;Tf?)+wi?LIC?(��;Ti?)+wb?LBC?(��,;Tb?)+wd?LData?(��,;Tdata?)
ʽ��:
L
P
D
E
(
��
;
T
f
)
=
1
�O
T
f
�O
��
x
��
T
f
��
f
(
x
;
?
u
^
?
x
1
,
��
,
?
u
^
?
x
d
;
?
2
u
^
?
x
1
?
x
1
,
��
,
?
2
u
^
?
x
1
?
x
d
)
��
2
2
L
I
C
(
��
;
T
i
)
=
1
�O
T
i
�O
��
x
��
T
i
��
u
^
(
x
)
?
u
(
x
)
��
2
2
L
B
C
(
��
;
T
b
)
=
1
�O
T
b
�O
��
x
��
T
b
��
B
(
u
^
,
x
)
��
2
2
L
D
a
t
a
(
��
;
T
d
a
t
a
)
=
1
�O
T
d
a
t
a
�O
��
x
��
T
d
a
t
a
��
u
^
(
x
)
?
u
(
x
)
��
2
2
\begin{aligned} \mathcal{L}_{PDE}\left(\boldsymbol{\theta} ; \mathcal{T}_{f}\right) &=\frac{1}{\left|\mathcal{T}_{f}\right|} \sum_{\mathbf{x} \in \mathcal{T}_{f}}\left\|f\left(\mathbf{x} ; \frac{\partial \hat{u}}{\partial x_{1}}, \ldots, \frac{\partial \hat{u}}{\partial x_{d}} ; \frac{\partial^{2} \hat{u}}{\partial x_{1} \partial x_{1}}, \ldots, \frac{\partial^{2} \hat{u}}{\partial x_{1} \partial x_{d}} \right)\right\|_{2}^{2} \\ \mathcal{L}_{IC}\left(\boldsymbol{\theta}; \mathcal{T}_{i}\right) &=\frac{1}{\left|\mathcal{T}_{i}\right|} \sum_{\mathbf{x} \in \mathcal{T}_{i}}\|\hat{u}(\mathbf{x})-u(\mathbf{x})\|_{2}^{2} \\ \mathcal{L}_{BC}\left(\boldsymbol{\theta}; \mathcal{T}_{b}\right) &=\frac{1}{\left|\mathcal{T}_{b}\right|} \sum_{\mathbf{x} \in \mathcal{T}_{b}}\|\mathcal{B}(\hat{u}, \mathbf{x})\|_{2}^{2}\\ \mathcal{L}_{Data}\left(\boldsymbol{\theta}; \mathcal{T}_{data}\right) &=\frac{1}{\left|\mathcal{T}_{data}\right|} \sum_{\mathbf{x} \in \mathcal{T}_{data}}\|\hat{u}(\mathbf{x})-u(\mathbf{x})\|_{2}^{2} \end{aligned}
LPDE?(��;Tf?)LIC?(��;Ti?)LBC?(��;Tb?)LData?(��;Tdata?)?=�OTf?�O1?x��Tf?��?��
��?f(x;?x1??u^?,��,?xd??u^?;?x1??x1??2u^?,��,?x1??xd??2u^?)��
��?22?=�OTi?�O1?x��Ti?��?��u^(x)?u(x)��22?=�OTb?�O1?x��Tb?��?��B(u^,x)��22?=�OTdata?�O1?x��Tdata?��?��u^(x)?u(x)��22??
w
f
w_{f}
wf?,
w
i
w_{i}
wi?��
w
b
w_{b}
wb?��
w
d
w_{d}
wd?��Ȩ�ء�
T
f
\mathcal{T}_{f}
Tf?,
T
i
\mathcal{T}_{i}
Ti?��
T
b
\mathcal{T}_{b}
Tb?��
T
d
a
t
a
\mathcal{T}_{data}
Tdata?��ʾ����PDE,��ֵ����ֵ�Լ���ֵ��residual points�������
T
f
?
��
\mathcal{T}_{f} \subset \Omega
Tf??����һ��Ԥ����ĵ����������������
u
^
\hat{u}
u^��PDE��ƥ��̶ȡ�
3.������ⶨ��
d
2
u
?
d
x
2
=
?
0.49
?
sin
?
(
0.7
x
)
?
2.25
?
cos
?
(
1.5
x
)
u
(
?
10
)
=
?
sin
?
(
7
)
+
cos
?
(
15
)
+
1
u
(
10
)
=
sin
?
(
7
)
+
cos
?
(
15
)
?
1
\begin{aligned} \frac{\mathrm{d}^2 u}{\mathrm{~d} x^2} &=-0.49 \cdot \sin (0.7 x)-2.25 \cdot \cos (1.5 x) \\ u(-10) &=-\sin (7)+\cos (15)+1 \\ u(10) &=\sin (7)+\cos (15)-1 \end{aligned}
?dx2d2u?u(?10)u(10)?=?0.49?sin(0.7x)?2.25?cos(1.5x)=?sin(7)+cos(15)+1=sin(7)+cos(15)?1?
��ʵ��Ϊ
u
:
=
sin
?
(
0.7
x
)
+
cos
?
(
1.5
x
)
?
0.1
x
u:=\sin (0.7 x)+\cos (1.5 x)-0.1 x
u:=sin(0.7x)+cos(1.5x)?0.1x
4.Python������
��һ��,���ȶ���������
# torch version 1.4.0
import torch
import torch.optim
from collections import OrderedDict
import torch.nn as nn
class Net(nn.Module):
def __init__(self, seq_net, name='MLP', activation=torch.tanh):
super().__init__()
self.features = OrderedDict()
for i in range(len(seq_net) - 1):
self.features['{}_{}'.format(name, i)] = nn.Linear(seq_net[i], seq_net[i + 1], bias=True)
self.features = nn.ModuleDict(self.features)
self.active = activation
# initial_bias
for m in self.modules():
if isinstance(m, nn.Linear):
nn.init.constant_(m.bias, 0)
def forward(self, x):
length = len(self.features)
i = 0
for name, layer in self.features.items():
x = layer(x)
if i == length - 1: break
i += 1
x = self.active(x)
return x
�ڶ���,PINN�����
from net import Net
import os
import matplotlib.pyplot as plt
import torch
from torch.autograd import grad
def d(f, x):
return grad(f, x, grad_outputs=torch.ones_like(f), create_graph=True, only_inputs=True)[0]
def PDE(u, x):
return d(d(u, x), x) + 0.49 * torch.sin(0.7 * x) + 2.25 * torch.cos(1.5 * x)
def Ground_true(x):
return torch.sin(0.7 * x) + torch.cos(1.5 * x) - 0.1 * x
def train():
lr = 0.001
n_pred = 100
n_f = 200
epochs = 8000
os.environ['CUDA_VISIBLE_DEVICES'] = '0'
device = torch.device('cuda:0') if torch.cuda.is_available() else torch.cuda('cpu')
PINN = Net([1, 50, 50, 50, 1]).to(device)
x_left, x_right = -10, 10
optimizer = torch.optim.Adam(PINN.parameters(), lr)
criterion = torch.nn.MSELoss()
loss_history = []
for epoch in range(epochs):
optimizer.zero_grad()
# inside
x_f = ((x_left + x_right) / 2 + (x_right - x_left) *
(torch.rand(size=(n_f, 1), dtype=torch.float, device=device) - 0.5)
).requires_grad_(True)
u_f = PINN(x_f)
PDE_ = PDE(u_f, x_f)
mse_PDE = criterion(PDE_, torch.zeros_like(PDE_))
# boundary
x_b = torch.tensor([[-10.], [10.]]).requires_grad_(True).to(device)
u_b = PINN(x_b)
true_b = Ground_true(x_b)
mse_BC = criterion(u_b, true_b)
# predict
x_pred = ((x_left + x_right) / 2 + (x_right - x_left) *
(torch.rand(size=(n_pred, 1), dtype=torch.float, device=device) - 0.5)
).requires_grad_(True)
u_f = PINN(x_pred)
true_f = Ground_true(x_pred)
mse_pred = criterion(u_f, true_f)
loss = 1 * mse_PDE + 1 * mse_BC
loss_history.append([mse_PDE.item(), mse_BC, mse_pred])
if epoch % 100 == 0:
print(
'epoch:{:05d}, EoM: {:.08e}, BC: {:.08e}, loss: {:.08e}'.format(
epoch, mse_PDE.item(), mse_BC.item(), loss.item()
)
)
loss.backward()
optimizer.step()
xx = torch.linspace(-10, 10, 10000).reshape((-1, 1)).to(device)
if (epoch + 1) % 300 == 0:
yy = PINN(xx)
zz = Ground_true(xx)
xx = xx.reshape((-1)).data.detach().cpu().numpy()
yy = yy.reshape((-1)).data.detach().cpu().numpy()
zz = zz.reshape((-1)).data.detach().cpu().numpy()
plt.cla()
plt.plot(xx, yy, label='PINN')
plt.plot(xx, zz, label='True', color='r')
plt.legend()
plt.title('PINN(epoch{}))'.format(epoch + 1))
plt.show()
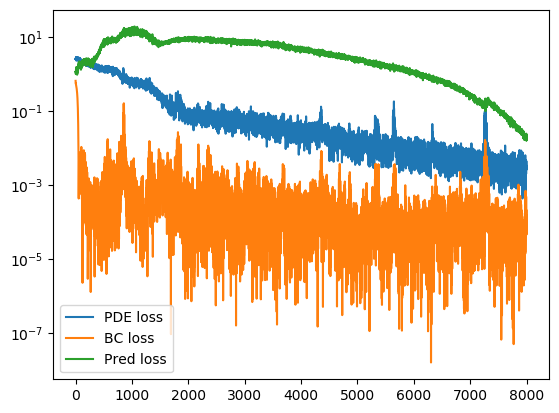
plt.plot(loss_history)
plt.legend(('PDE loss', 'BC loss', 'Pred loss'), loc='best')
plt.show()
if name == ��main��:
train()
5.���չʾ