1�� seaborn
����:����Ч�ػ�ͼ
#��װ
pip3 install seaborn
#����
import seaborn as sns
������:ֱ��ͼ����ܶ�����
˫����:ɢ��ͼ����άֱ��ͼ��
��Ҫ����:distplot()��joinplot()����
1.1 ��������ͼ
API
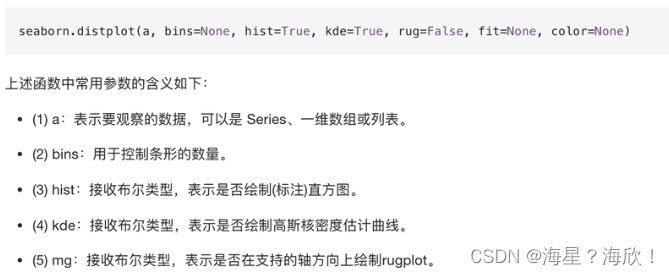
import seaborn as sns
import numpy as np
np.random.seed(0) #ȷ�����������
arr = np.random.rand(100)
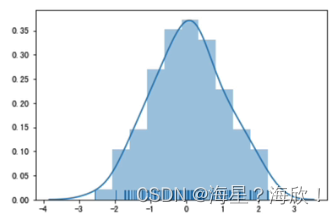
sns.distplot(arr,bins=10,hist=True,kde=True,rug=True)
1.2 ˫������ͼ
ɢ��ͼ-kind = ��scatter��
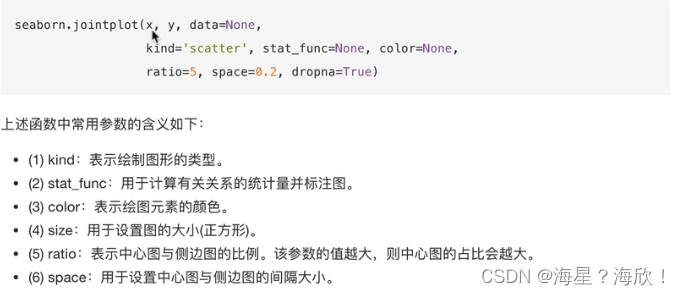
import pandas as pd
df = pd.DataFrame({'x':np.random.randn(500),'y':np.random.randn(500)})
df.head()
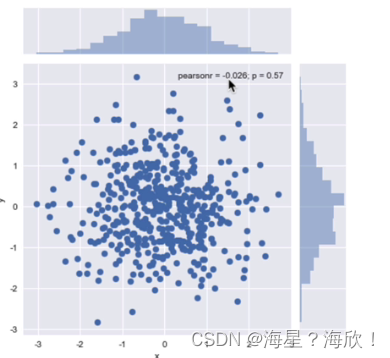
sns.joinplot('x','y',data = df)
���ܶȹ�������-kind = ��kde��
sns.joinplot('x','y',data = df,kind = 'kde')
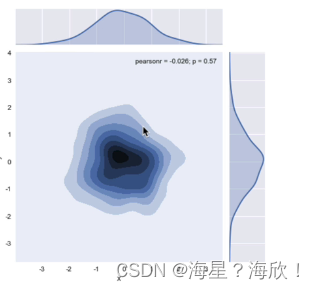
��ɫԽ��,��ʾ����Խ�ܼ�
��άֱ��ͼ-kind = ��hex��
sns.joinplot('x','y',data = df,kind = 'hex')
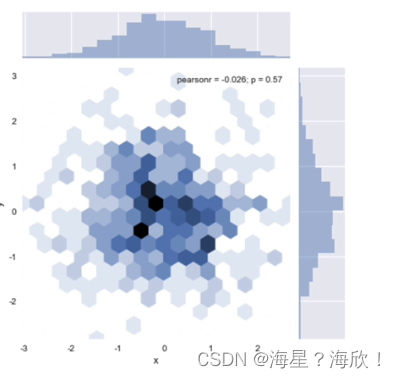
����ɶԵ�˫�����ֲ�
dataset = sns.load_dataset('iris')
sns.pairplot(dataset)
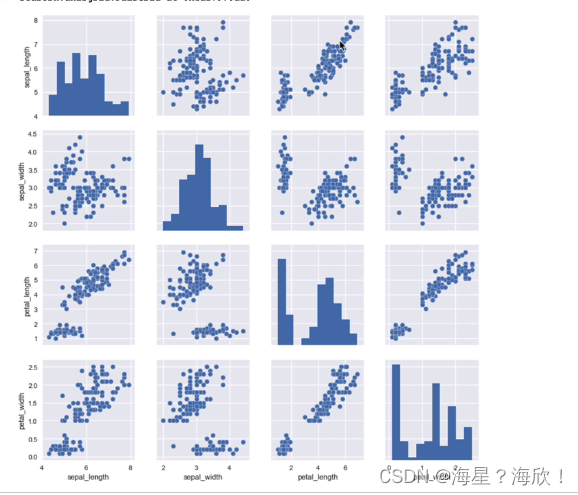
1.3 �ܽ�
- ���Ƶ������ֲ�ͼ��:seaborn.distplot()
- ����˫�����ֲ�ͼ��:seaborn.jointplot()
- ���ƳɶԵ�˫�����ֲ�ͼ��:seaborn.pairplot()
2���������ݻ�ͼ
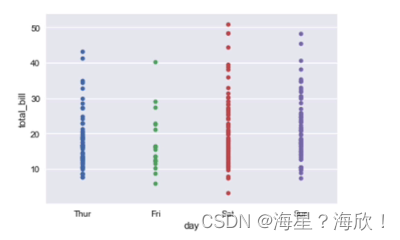
2.1 ���ɢ��ͼ

data = sns.load_dataset('tips')
data.load()
sns.stripplot(x='day',y='total_bill',data=data)
sns.stripplot(x='day',y='total_bill',data=data,hue='time')
#hue='time'��time������ɫ,����ֻ������

sns.stripplot(x='day',y='total_bill',data=data,hue='time',jitter=True)
#jitter=True���������ص�����
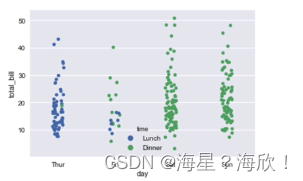
sns.swarmplot('day','total_bill',data=data)
#swarmplot-��ȫû���ص�
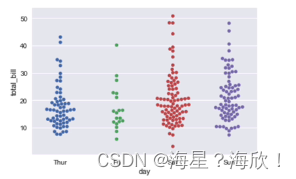
2.2 ����ڵ����ݷ���
����ͼ��С����ͼ
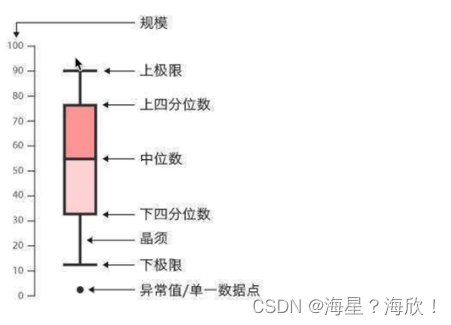
С����ͼ���������ͼ���ܶ�ͼ������,��Ҫ������ʾ���ݵķֲ�
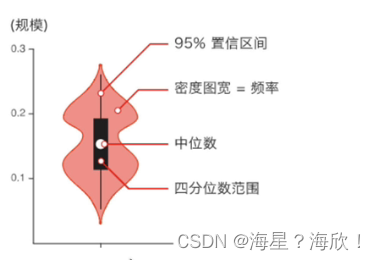
����ͼAPI
seaborn.boxplot(x=None,y=None,hue=None,data=None,orient=None,color=None,saturation=0.9)
#hue--����
#palette=['g','b','y',''b]������ɫ,�Ƕ�hue����������ɫ
#saturation��ɫ���õı��Ͷ�
#����
sns.boxplot('day','total_bill',data=data)
С����ͼ
#API
seaborn.violinplot(x=None,y=None,hue=None,data=None)
#����
sns.violinplot('day','total_bill',data=data)
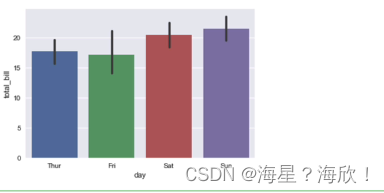
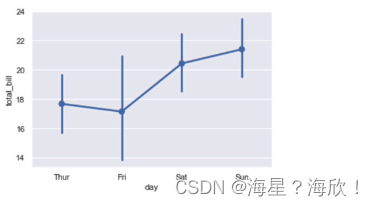
����ͼsns.barplot���ͼsns.pointplot
#����ͼ(������������)
sns.barplot(x='day',y='total_bill',data=tips)
#��ͼ(����Ƽ�����������)
sns.pointplot(x='day',y='total_bill',data=tips)
3������:NBA��Ա���ݷ���
NBA����
3.1��ȡ�����ҳ�ʶ����
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
#��ȡ�����ҳ�ʶ����
data = pd.read_csv('F:/�˹�����/nba_2017_nba_players_with_salary.csv')
data.head()
data.shape
data.describe()
3.2 ����ͼ
#���ݷ���
##���������
data_cor = data.loc[:,['RPM','AGE','SALARY_MILLIONS','ORB','DRB','TRB','AST','STL','BLK','TOV','PF','POINTS','GP','MPG','ORPM','DRPM']]
data_cor.head()
#����̫��,ֻ�Բ�������һ�������
corr = data_cor.corr()
corr.head()
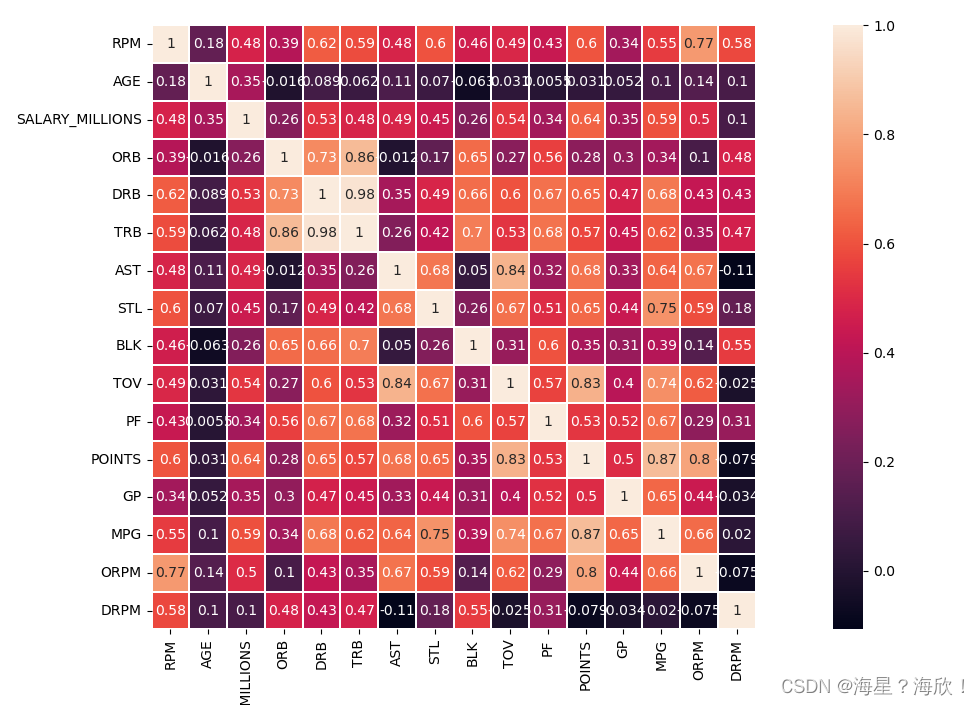
###����ͼ
plt.figure(figsize=(20,8),dpi=100)#����ͼ��С
sns.heatmap(corr,square=True,linewidths=0.1,annot=True)
#square=True��������,linewidths=0.1�м�ӿ���Ϊ0.1����,annot=True��ʾ����
3.3������������
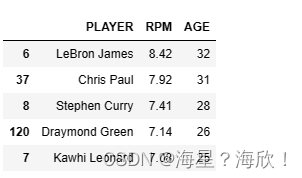
#����������������
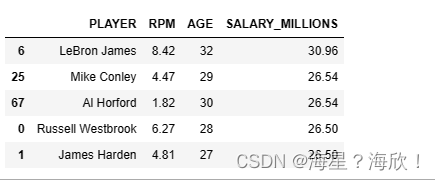
data.loc[:,['PLAYER','RPM','AGE']].sort_values(by='RPM',ascending=False).head()
#����RPM��������
#������Աн������
data.loc[:,['PLAYER','RPM','AGE','SALARY_MILLIONS']].sort_values(by='SALARY_MILLIONS',ascending=False).head()
3.4seaborn���õ��������ݿ��ӻ�����
3.4.1������
#seaborn���õ��������ݿ��ӻ�����
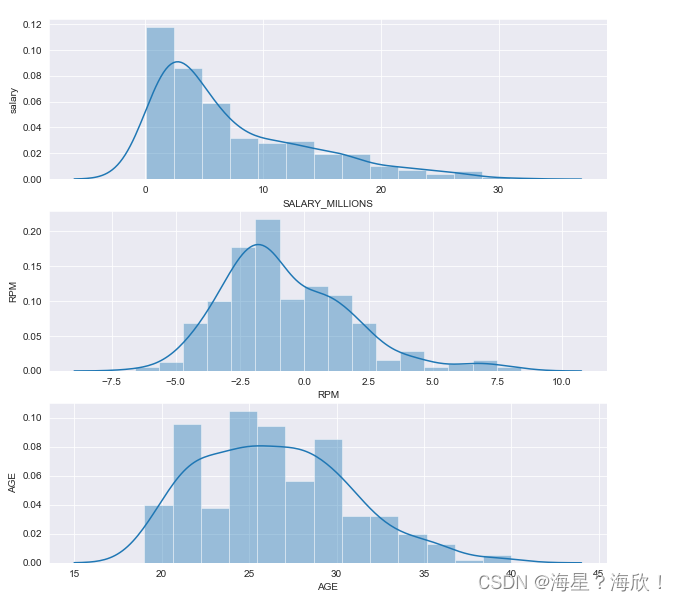
##������
#����seaborn�е�distplot��ͼ���ֱ�нˮ��Ч��ֵ������������Ϣ�ķֲ����
sns.set_style('darkgrid')#���û���ģʽ
plt.figure(figsize=(10,10))
plt.subplot(3,1,1)
sns.distplot(data['SALARY_MILLIONS'])
plt.ylabel('salary')
plt.subplot(3,1,2)
sns.distplot(data['RPM'])
plt.ylabel('RPM')
plt.subplot(3,1,3)
sns.distplot(data['AGE'])
plt.ylabel('AGE')
3.4.2˫����-ɢ��ͼ
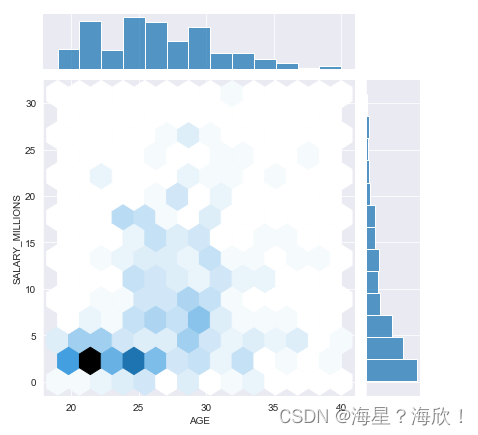
##˫����jointplot
#ʹ��jointplot�鿴�����нˮ֮��Ĺ�ϵ
sns.jointplot(data.AGE,data.SALARY_MILLIONS,kind='hex') #hex��ʾ��������ʽ
3.4.3�����
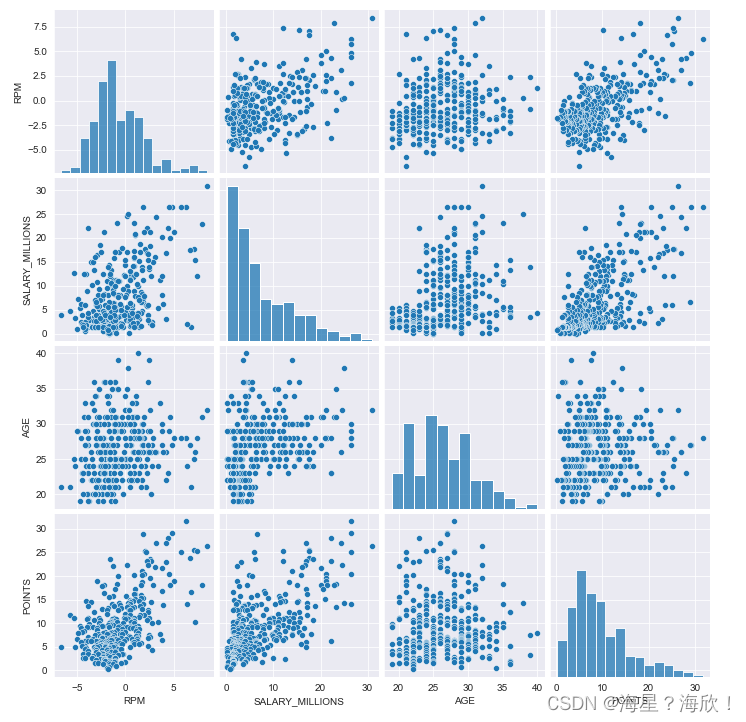
##�����
multi_data = data.loc[:,['RPM','SALARY_MILLIONS','AGE','POINTS']]
multi_data.head()
sns.pairplot(multi_data)
3.5 ����������һЩ���ӻ�ʵ��-������Ϊ��
�Զ�����һ������ֲ�
#���仮��
def age_cut(df):
if df.AGE <=24:
return 'young'
elif df.AGE >=30:
return 'old'
else:
return 'best'
#ʹ��apply��������л���
data['age_cut'] = data.apply(lambda x:age_cut(x),axis=1)
data.head()
�ֲ�ɢ��ͼ
#��������ټ�һ��cut��
data['cut'] = 1
data.loc[data.age_cut == 'best'].SALARY_MILLIONS.head()
#ͨ���������Աнˮ��Ч��ֵ���з���
sns.set_style('darkgrid')
plt.figure(figsize=(10,10),dpi=100)
plt.title('RPM and SALARY')
x1 = data.loc[data.age_cut == 'old'].SALARY_MILLIONS
y1 = data.loc[data.age_cut == 'old'].RPM
plt.plot(x1,y1,"^")#"^"��������ʽ
x2 = data.loc[data.age_cut == 'best'].SALARY_MILLIONS
y2 = data.loc[data.age_cut == 'best'].RPM
plt.plot(x2,y2,"^")
x3 = data.loc[data.age_cut == 'young'].SALARY_MILLIONS
y3 = data.loc[data.age_cut == 'young'].RPM
plt.plot(x3,y3,".")
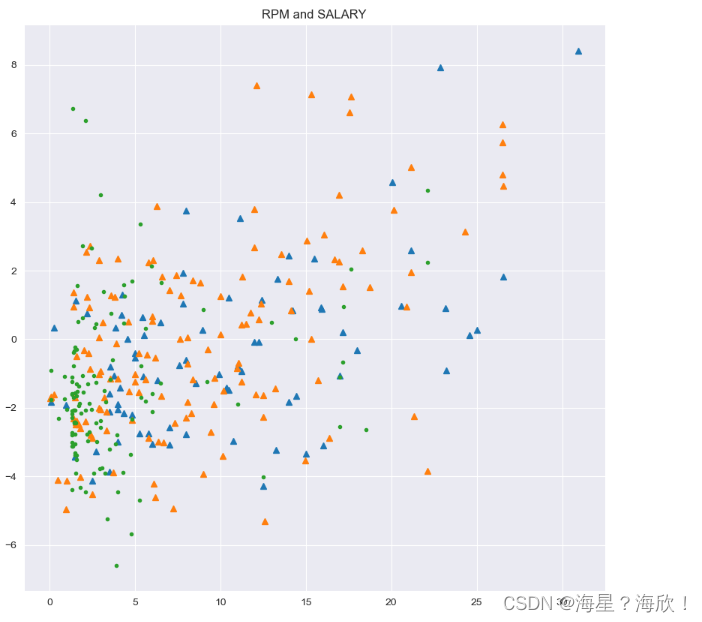
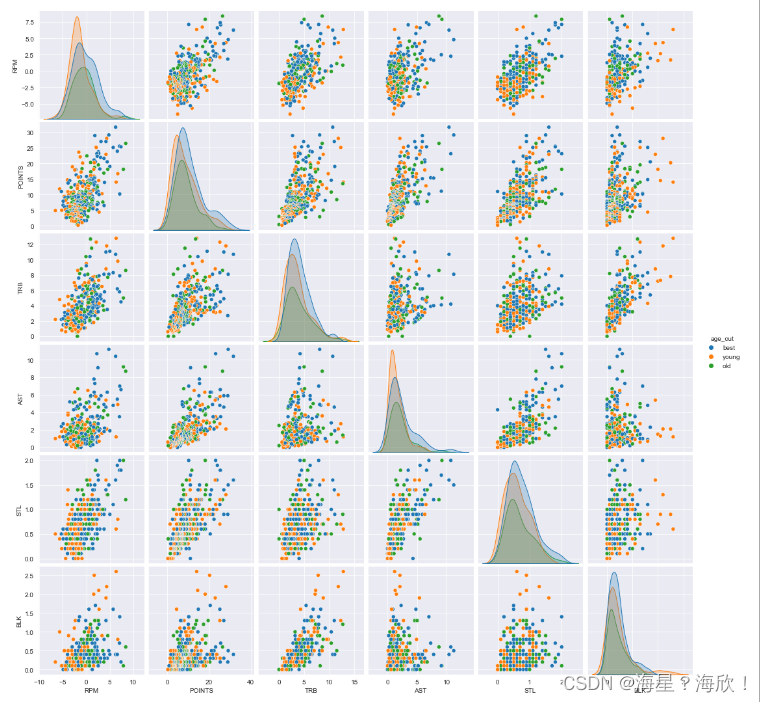
�ɶ�˫������ͼpairplot
dat2 = data.loc[:,['RPM','POINTS','TRB','AST','STL','BLK','age_cut']]
sns.pairplot(dat2,hue='age_cut')
3.6 ������ݷ���
�鿴��ͬ����µ����,���ֵ,��ֵ�ȡ�agg�ۺϺ���
����sort_values
data.groupby(by='age_cut').agg({"SALARY_MILLIONS":np.mean})
#����agg�������������ε�ƽ��н��
#������ӷ���,ƽ��нˮ��������
data_team = data.groupby(by='TEAM').agg({"SALARY_MILLIONS":np.mean}) #TEAM���
data_team.sort_values(by='SALARY_MILLIONS',ascending=False).head(10)
#���շ�����η����,�ϰ���Ա���������С����ϰ���Ա����ͬ,��Ч��ֵ��������
data_rpm = data.groupby(by=['TEAM','age_cut']).agg({"SALARY_MILLIONS":np.mean,"RPM":np.mean,"PLAYER":np.size})
data_rpm.sort_values(by=['PLAYER','RPM'],ascending=False).head()
��ͼ����չʾ����ӵ����
#��������ͼ��С����ͼ�������ݷ���
sns.set_style('whitegrid')
plt.figure(figsize=(20,10))
data_team2 = data[data.TEAM.isin(['GS','CLE','SA','LAC','OKC','UTAH','CHA','TOR','NO','BOS'])]#ֻȡ�˲��������
#��ͼ����ͼ
plt.subplot(3,1,1)
sns.boxplot(x='TEAM',y='SALARY_MILLIONS',data =data_team2) #������ӵ�н�ʷֲ�
plt.subplot(3,1,2)
sns.boxplot(x='TEAM',y='AGE',data =data_team2) #������ӵ�����ֲ�
plt.subplot(3,1,3)
sns.boxplot(x='TEAM',y='MPG',data =data_team2)#������ӵij���ʱ��ֲ�
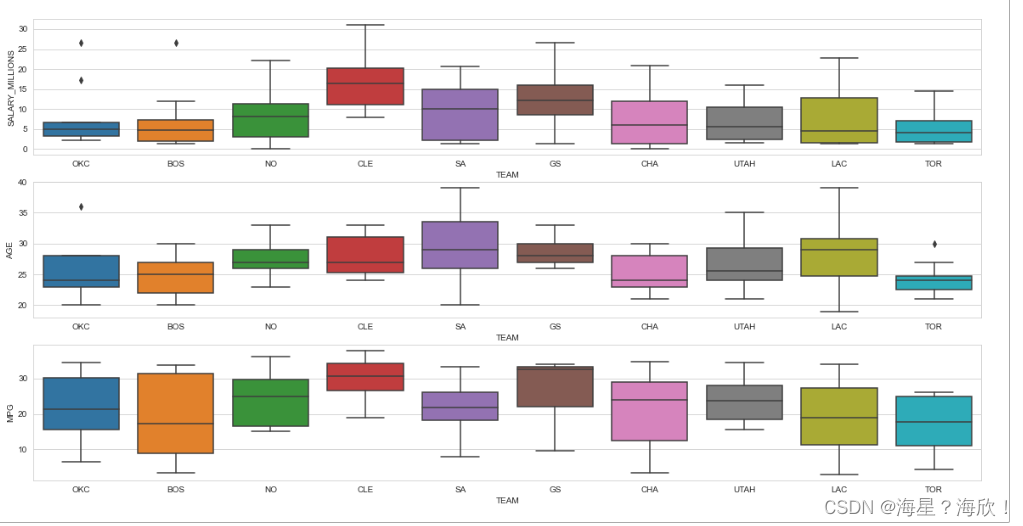
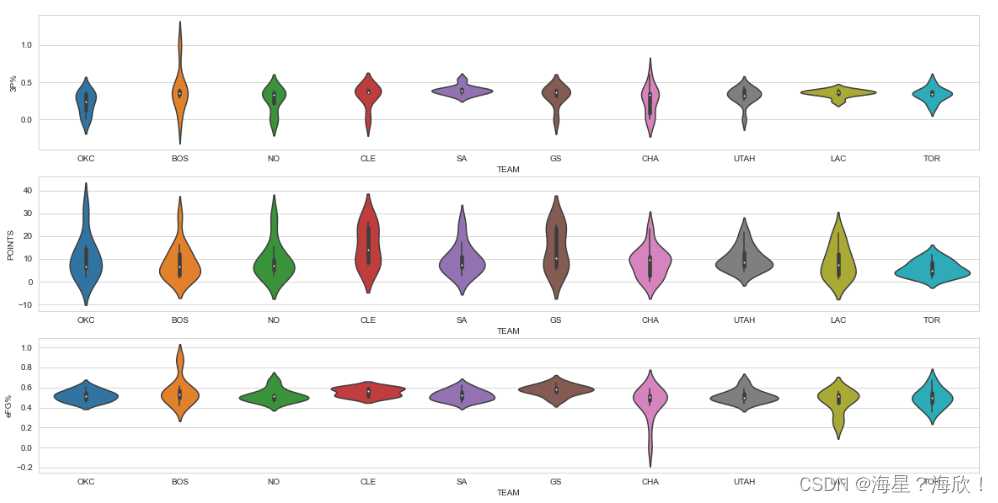
#С����ͼ
sns.set_style('whitegrid')
plt.figure(figsize=(20,10))
plt.subplot(3,1,1)
sns.violinplot(x='TEAM',y='3P%',data =data_team2) #������ӵ�3���������ʷֲ�
plt.subplot(3,1,2)
sns.violinplot(x='TEAM',y='POINTS',data =data_team2) #������ӵĵ÷ֲַ�
plt.subplot(3,1,3)
sns.violinplot(x='TEAM',y='eFG%',data =data_team2)#������ӵ���ʵ�����ʷֲ�
4������:�����ⷿ����ͳ�Ʒ���
����:

���ұ����ⷿ����
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
#��ȡ����
file_data = pd.read_csv('F:/�Ա�-�˹�����-�μ�/���ұ����ⷿ����.csv')
file_data
file_data.shape
file_data.info()
file_data.describe()#ֻ������ֵ�е�
���ݻ�������
4.1,�ظ�ֵ�Ϳ�ֵ����
file_data = file_data.drop_duplicates()#ɾ���ظ�ֵ,��һ�γ��ֲ�ɾ��,��������ظ��Ļᱻɾ��
file_data.shape
#��ֵ����
file_data = file_data.dropna()#ɾ����ֵ
file_data.shape
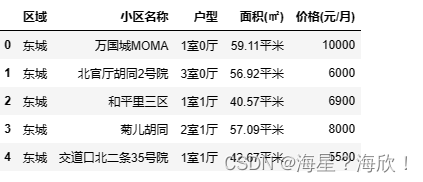
4.2 ��������ת��
��ѡ�����С�ת����float����
�����еı���,�С������伸�����ı���,�Ѹ���ͳһΪ�����Ҽ������ı���
#�����
file_data['���(�O)'].values
file_data['���(�O)'].values[0][:-2]
#����һ���յ�����,�����洢�ĸ�ʽ��������
data_new = np.array([])
data_area = file_data['���(�O)'].values
for i in data_area:
data_new = np.append(data_new,np.array(i[:-2]))
data_new
#ת��data_new����������
data_new = data_new.astype(np.float64)
data_new
file_data.loc[:,'���(�O)'] = data_new #�滻
file_data.head()
#���ͱ��﷽ʽ�滻
house_data = file_data['����']
temp_list=[]
for i in house_data:
new_info = i.replace('����','��')
temp_list.append(new_info)
file_data.loc[:,"����"] = temp_list
file_data
�����������
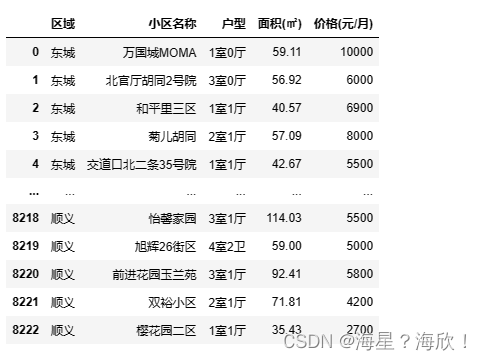
p0655