
�����������ճ������г�����������ʽ,���㷺Ӧ���ڹ�桢��Ӱ�Ͷ�ͯ�����ȶ������Ŀǰ,������������Ҫ�������ֹ�ʵ�֡�Ȼ��,�ֹ����������dz�����,��Ҫ�dz�רҵ���������ɡ����ڶ�����������˵,�����������Ķ�����Ʒ��Ҫ��ϸ������������������ɫ����Ӱ,����ζ�Ŵ��������������ֺ�ʱ�����,�ܹ�����ʵ�������Ƭ�Զ�ת��Ϊ�������������ͼ����Զ������Ƿdz��м�ֵ�ġ������������������Ǹ���רע�ڴ����ԵĹ���,Ҳ������ͨ�˸����״����Լ��Ķ�����Ʒ����������AnimeGAN�������������ģ�ͽ�������ϸ�Ľ���,�����������չ���˸��㷨������,������AnimeGAN�ڶ������Ǩ�Ʒ�������ƺʹ��ڵIJ��㡣����鿴��ϸ����,�ɵ���·��Ķ�ԭ����
ģ�ͼ��
AnimeGAN�������人��ѧ�ͺ�����ҵ��ѧ��һ���о�,���õ������Ǩ�� + ���ɶԿ�����(GAN)����ϡ�����Ŀ����ʵ�ֽ���ʵͼ������,��Jie Chen����������AnimeGAN: A Novel Lightweight GAN for Photo Animation�������������Ϊ�ԳƱ����ṹ,��Ҫ�ɱ���������ȿɷ������������в��(IRB)���ϲ������²���ģ����ɡ��б����ɱ�������ɡ�
�����ص�
���AnimeGAN,�Ľ�������Ҫ������4��:
1����������ɵ�ͼ���еĸ�ƵαӰ���⡣
2��������ѵ��,����ֱ�Ӵﵽ����������Ч����
3����һ����������������IJ���������(������������С 8.07Mb)
4�������ܶ��ʹ������BD��Ӱ�ĸ�����������ݡ�
������
���ݼ�����6656����ʵ�ķ羰ͼƬ,3�ֶ������:Hayao,Shinkai,Paprika,ÿһ�ֶ�������ǴӶ�Ӧ�ĵ�Ӱ��ͨ������Ƶ֡������ü����ɵ�,����֮�����ݼ���Ҳ�������ڲ��Եĸ��ֳߴ��С��ͼ�����ݼ���Ϣ����ͼ��ʾ:

���ݼ�ͼƬ����ͼ��ʾ:

���ݼ����ؽ�ѹ������ݼ�Ŀ¼�ṹ����:

��ģ��ʹ��vgg19��������ͼ��������ȡ����ʧ�����ļ���,�����Ҫ����Ԥѵ��������ģ�Ͳ�����
vgg19Ԥѵ��ģ��������ɺ�vgg.ckpt�ļ����ںͱ��ļ�ͬ����Ŀ¼�¡�
����Ԥ����
�����ڼ�����ʧ����ʱ��Ҫ�õ�����ͼ��ı�Եƽ��ͼ��,�������ᵽ�����ݼ����Ѿ�������ƽ�����ͼ��,����Լ������������ݼ���ͨ������Ĵ������ɱ�Եƽ��ͼ��
from?src.animeganv2_utils.edge_smooth?import?make_edge_smooth
#?����ͼ��Ŀ¼
style_dir?=?'./dataset/Sakura/style'
#?���ͼ��Ŀ¼
output_dir?=?'./dataset/Sakura/smooth'
#?���ͼ���С
size?=?256
#ƽ��ͼ��,��������smooth�ļ�����
make_edge_smooth(style_dir,?output_dir,?size)
ѵ�������ӻ�
import argparse
import matplotlib.pyplot as plt
from src.process_datasets.animeganv2_dataset import AnimeGANDataset
import numpy as np
# ���ز���
parser = argparse.ArgumentParser()
parser.add_argument('--dataset', default='Hayao', choices=['Hayao', 'Shinkai', 'Paprika'], type=str)
parser.add_argument('--data_dir', default='./dataset', type=str)
parser.add_argument('--batch_size', default=4, type=int)
parser.add_argument('--debug_samples', default=0, type=int)
parser.add_argument('--num_parallel_workers', default=1, type=int)
args = parser.parse_args(args=[])
plt.figure()
# �������ݼ�
data = AnimeGANDataset(args)
data = data.run()
iter = next(data.create_tuple_iterator())
# ѭ������
for i in range(1, 5):
plt.subplot(1, 4, i)
temp = np.clip(iter[i - 1][0].asnumpy().transpose(2, 1, 0), 0, 1)
plt.imshow(temp)
plt.axis("off")Mean(B, G, R) of Hayao are [-4.4346958 ?-8.66591597 13.10061177]
Dataset: real 6656 style 1792, smooth 1792

��������
���������ݺ��������Ĵ������AnimeGAN�����е�����,����ģ��Ȩ�ؾ�Ӧ����meanΪ0,sigmaΪ0.02����̬�ֲ������ʼ����
������
������G�Ĺ����ǽ�����ͼƬת��Ϊ���п�ͨ���ķ��ͼƬ����ʵ��������,�ù�����ͨ����������ȿɷ������������в�顢�ϲ������²���ģ������ɡ�����ṹ����ͼ��ʾ:
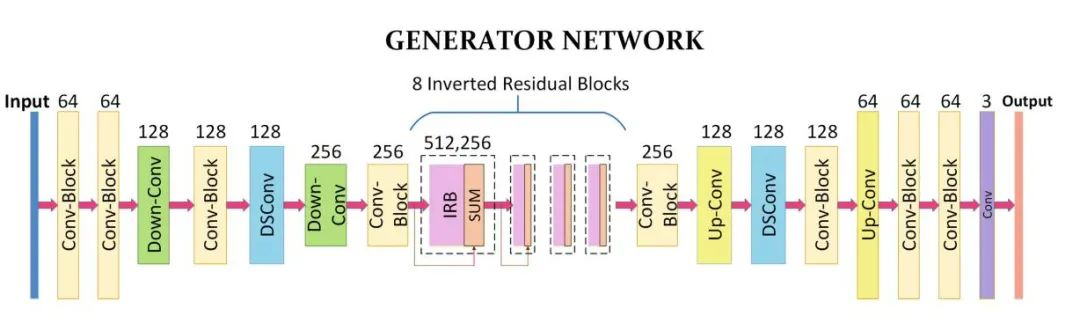
����Сģ��ṹ����:

import?os
import?mindspore.nn?as?nn
from?src.models.upsample?import?UpSample
from?src.models.conv2d_block?import?ConvBlock
from?src.models.inverted_residual_block?import?InvertedResBlock
class?Generator(nn.Cell):
????"""AnimeGAN����������"""
????def?__init__(self):
????????super(Generator,?self).__init__()
????????has_bias?=?False
????????self.generator?=?nn.SequentialCell()
????????self.generator.append(ConvBlock(3,?32,?kernel_size=7))
????????self.generator.append(ConvBlock(32,?64,?stride=2))
????????self.generator.append(ConvBlock(64,?128,?stride=2))
????????self.generator.append(ConvBlock(128,?128))
????????self.generator.append(ConvBlock(128,?128))
????????self.generator.append(InvertedResBlock(128,?256))
????????self.generator.append(InvertedResBlock(256,?256))
????????self.generator.append(InvertedResBlock(256,?256))
????????self.generator.append(InvertedResBlock(256,?256))
????????self.generator.append(ConvBlock(256,?128))
????????self.generator.append(UpSample(128,?128))
????????self.generator.append(ConvBlock(128,?128))
????????self.generator.append(UpSample(128,?64))
????????self.generator.append(ConvBlock(64,?64))
????????self.generator.append(ConvBlock(64,?32,?kernel_size=7))
????????self.generator.append(
????????????nn.Conv2d(32,?3,?kernel_size=1,?stride=1,?pad_mode='same',?padding=0,
??????????????????????weight_init=Normal(mean=0,?sigma=0.02),?has_bias=has_bias))
????????self.generator.append(nn.Tanh())
????def?construct(self,?x):
????????out1?=?self.generator(x)
????????return?out1���
�б���D��һ������������ģ��,����ж���ͼ��Ϊ��ʵͼ�ĸ��ʡ�ͨ��һЩ�е�Conv2d��LeakyRelu��InstanceNorm�������д���,���ͨ��һ��Conv2d��õ����յĸ��ʡ�
import?mindspore.nn?as?nn
from?mindspore.common.initializer?import?Normal
class?Discriminator(nn.Cell):
????"""AnimeGAN�������"""
????def?__init__(self,?args):
????????super(Discriminator,?self).__init__()
????????self.name?=?f'discriminator_{args.dataset}'
????????self.has_bias?=?False
????????channels?=?args.ch?//?2
????????layers?=?[
????????????nn.Conv2d(3,?channels,?kernel_size=3,?stride=1,?pad_mode='same',?padding=0,
??????????????????????weight_init=Normal(mean=0,?sigma=0.02),?has_bias=self.has_bias),
????????????nn.LeakyReLU(alpha=0.2)
????????]
????????for?_?in?range(1,?args.n_dis):
????????????layers?+=?[
????????????????nn.Conv2d(channels,?channels?*?2,?kernel_size=3,?stride=2,?pad_mode='same',?padding=0,
??????????????????????????weight_init=Normal(mean=0,?sigma=0.02),?has_bias=self.has_bias),
????????????????nn.LeakyReLU(alpha=0.2),
????????????????nn.Conv2d(channels?*?2,?channels?*?4,?kernel_size=3,?stride=1,?pad_mode='same',?padding=0,
??????????????????????????weight_init=Normal(mean=0,?sigma=0.02),?has_bias=self.has_bias),
????????????????nn.InstanceNorm2d(channels?*?4,?affine=False),
????????????????nn.LeakyReLU(alpha=0.2),
????????????]
????????????channels?*=?4
????????layers?+=?[
????????????nn.Conv2d(channels,?channels,?kernel_size=3,?stride=1,?pad_mode='same',?padding=0,
??????????????????????weight_init=Normal(mean=0,?sigma=0.02),?has_bias=self.has_bias),
????????????nn.InstanceNorm2d(channels,?affine=False),
????????????nn.LeakyReLU(alpha=0.2),
????????????nn.Conv2d(channels,?1,?kernel_size=3,?stride=1,?pad_mode='same',?padding=0,
??????????????????????weight_init=Normal(mean=0,?sigma=0.02),?has_bias=self.has_bias),
????????]
????????self.discriminate?=?nn.SequentialCell(layers)
????def?construct(self,?x):
????????return?self.discriminate(x)��ʧ����
��ʧ������Ҫ��Ϊ�Կ���ʧ��������ʧ���Ҷȷ����ʧ����ɫ�ؽ���ʧ�ĸ�����,��ͬ����ʧ�в�ͬ��Ȩ��ϵ��,�������ʧ������ʾΪ:


��������ʧ
import?mindspore
from?src.losses.gram_loss?import?GramLoss
from?src.losses.color_loss?import?ColorLoss
from?src.losses.vgg19?import?Vgg
def?vgg19(args,?num_classes=1000):
????"""����Ԥѵ����vgg19ģ�Ͳ���"""
????#?��������
????net?=?Vgg([64,?64,?'M',?128,?128,?'M',?256,?256,?256,?256,?'M',?512,?512,?512,?512],?num_classes=num_classes,
??????????????batch_norm=True)
????#?����ģ��
????param_dict?=?load_checkpoint(args.vgg19_path)
????load_param_into_net(net,?param_dict)
????net.requires_grad?=?False
????return?net
class?GeneratorLoss(nn.Cell):
????"""��������������ʧ"""
????def?__init__(self,?discriminator,?generator,?args):
????????super(GeneratorLoss,?self).__init__(auto_prefix=True)
????????self.discriminator?=?discriminator
????????self.generator?=?generator
????????self.content_loss?=?nn.L1Loss()
????????self.gram_loss?=?GramLoss()
????????self.color_loss?=?ColorLoss()
????????self.wadvg?=?args.wadvg
????????self.wadvd?=?args.wadvd
????????self.wcon?=?args.wcon
????????self.wgra?=?args.wgra
????????self.wcol?=?args.wcol
????????self.vgg19?=?vgg19(args)
????????self.adv_type?=?args.gan_loss
????????self.bce_loss?=?nn.BCELoss()
????????self.relu?=?nn.ReLU()
????????self.adv_type?=?args.gan_loss
????def?construct(self,?img,?anime_gray):
????????"""������������ʧ����ṹ"""
????????fake_img?=?self.generator(img)
????????fake_d?=?self.discriminator(fake_img)
????????fake_feat?=?self.vgg19(fake_img)
????????anime_feat?=?self.vgg19(anime_gray)
????????img_feat?=?self.vgg19(img)
????????result?=?self.wadvg?*?self.adv_loss_g(fake_d)?+?\
????????????self.wcon?*?self.content_loss(img_feat,?fake_feat)?+?\
????????????self.wgra?*?self.gram_loss(anime_feat,?fake_feat)?+?\
????????????self.wcol?*?self.color_loss(img,?fake_img)
????????return?result
????def?adv_loss_g(self,?pred):
????????"""ѡ����ʧ��������"""
????????if?self.adv_type?==?'hinge':
????????????return?-mindspore.numpy.mean(pred)
????????if?self.adv_type?==?'lsgan':
????????????return?mindspore.numpy.mean(mindspore.numpy.square(pred?-?1.0))
????????if?self.adv_type?==?'normal':
????????????return?self.bce_loss(pred,?mindspore.numpy.zeros_like(pred))
????????return?mindspore.numpy.mean(mindspore.numpy.square(pred?-?1.0))
�б�����ʧ
class?DiscriminatorLoss(nn.Cell):
????"""�����б�������ʧ"""
????def?__init__(self,?discriminator,?generator,?args):
????????nn.Cell.__init__(self,?auto_prefix=True)
????????self.discriminator?=?discriminator
????????self.generator?=?generator
????????self.content_loss?=?nn.L1Loss()
????????self.gram_loss?=?nn.L1Loss()
????????self.color_loss?=?ColorLoss()
????????self.wadvg?=?args.wadvg
????????self.wadvd?=?args.wadvd
????????self.wcon?=?args.wcon
????????self.wgra?=?args.wgra
????????self.wcol?=?args.wcol
????????self.vgg19?=?vgg19(args)
????????self.adv_type?=?args.gan_loss
????????self.bce_loss?=?nn.BCELoss()
????????self.relu?=?nn.ReLU()
????def?construct(self,?img,?anime,?anime_gray,?anime_smt_gray):
????????"""�����б�����ʧ����ṹ"""
????????fake_img?=?self.generator(img)
????????fake_d?=?self.discriminator(fake_img)
????????real_anime_d?=?self.discriminator(anime)
????????real_anime_gray_d?=?self.discriminator(anime_gray)
????????real_anime_smt_gray_d?=?self.discriminator(anime_smt_gray)
????????return?self.wadvd?*?(
????????????1.7?*?self.adv_loss_d_real(real_anime_d)?+
????????????1.7?*?self.adv_loss_d_fake(fake_d)?+
????????????1.7?*?self.adv_loss_d_fake(real_anime_gray_d)?+
????????????1.0?*?self.adv_loss_d_fake(real_anime_smt_gray_d)
????????)
????def?adv_loss_d_real(self,?pred):
????????"""��ʵ����ͼ����б���ʧ����"""
????????if?self.adv_type?==?'hinge':
????????????return?mindspore.numpy.mean(self.relu(1.0?-?pred))
????????if?self.adv_type?==?'lsgan':
????????????return?mindspore.numpy.mean(mindspore.numpy.square(pred?-?1.0))
????????if?self.adv_type?==?'normal':
????????????return?self.bce_loss(pred,?mindspore.numpy.ones_like(pred))
????????return?mindspore.numpy.mean(mindspore.numpy.square(pred?-?1.0))
????def?adv_loss_d_fake(self,?pred):
????????"""���ɶ���ͼ����б���ʧ����"""
????????if?self.adv_type?==?'hinge':
????????????return?mindspore.numpy.mean(self.relu(1.0?+?pred))
????????if?self.adv_type?==?'lsgan':
????????????return?mindspore.numpy.mean(mindspore.numpy.square(pred))
????????if?self.adv_type?==?'normal':
????????????return?self.bce_loss(pred,?mindspore.numpy.zeros_like(pred))
????????return?mindspore.numpy.mean(mindspore.numpy.square(pred))
ģ��ʵ��
����GAN����ṹ�ϵ�������,����ʧ���б������������Ķ������ʽ,��͵�������һ��ķ������粻ͬ��MindSporeҪ����ʧ�������Ż����Ȳ���Ҳ����nn.Cell������,�������ǿ����Զ���AnimeGAN��,�������loss����������
class?AnimeGAN(nn.Cell):
????"""����AnimeGAN����"""
????def?__init__(self,?my_train_one_step_cell_for_d,?my_train_one_step_cell_for_g):
????????super(AnimeGAN,?self).__init__(auto_prefix=True)
????????self.my_train_one_step_cell_for_g?=?my_train_one_step_cell_for_g
????????self.my_train_one_step_cell_for_d?=?my_train_one_step_cell_for_d
????def?construct(self,?img,?anime,?anime_gray,?anime_smt_gray):
????????output_d_loss?=?self.my_train_one_step_cell_for_d(img,?anime,?anime_gray,?anime_smt_gray)
????????output_g_loss?=?self.my_train_one_step_cell_for_g(img,?anime_gray)
????????return?output_d_loss,?output_g_loss
ģ��ѵ��
ѵ����Ϊ��������:ѵ���б�����ѵ����������ѵ���б�����Ŀ�������̶ȵ�����б�ͼ����α�ĸ��ʡ�ѵ���������������ɸ��õ���ٶ���ͼ������ͨ����С����ʧ�����ɴﵽ���š�
import?argparse
import?os
import?cv2
import?numpy?as?np
import?mindspore
from?mindspore?import?Tensor
from?mindspore?import?float32?as?dtype
from?mindspore?import?nn
from?tqdm?import?tqdm
from?src.models.generator?import?Generator
from?src.models.discriminator?import?Discriminator
from?src.models.animegan?import?AnimeGAN
from?src.animeganv2_utils.pre_process?import?denormalize_input
from?src.losses.loss?import?GeneratorLoss,?DiscriminatorLoss
from?src.process_datasets.animeganv2_dataset?import?AnimeGANDataset
#?���ز���
parser?=?argparse.ArgumentParser(description='train')
parser.add_argument('--device_target',?default='Ascend',?choices=['CPU',?'GPU',?'Ascend'],?type=str)
parser.add_argument('--device_id',?default=0,?type=int)
parser.add_argument('--dataset',?default='Paprika',?choices=['Hayao',?'Shinkai',?'Paprika'],?type=str)
parser.add_argument('--data_dir',?default='./dataset',?type=str)
parser.add_argument('--checkpoint_dir',?default='./checkpoints',?type=str)
parser.add_argument('--vgg19_path',?default='./vgg.ckpt',?type=str)
parser.add_argument('--save_image_dir',?default='./images',?type=str)
parser.add_argument('--resume',?default=False,?type=bool)
parser.add_argument('--phase',?default='train',?type=str)
parser.add_argument('--epochs',?default=2,?type=int)
parser.add_argument('--init_epochs',?default=5,?type=int)
parser.add_argument('--batch_size',?default=4,?type=int)
parser.add_argument('--num_parallel_workers',?default=1,?type=int)
parser.add_argument('--save_interval',?default=1,?type=int)
parser.add_argument('--debug_samples',?default=0,?type=int)
parser.add_argument('--lr_g',?default=2.0e-4,?type=float)
parser.add_argument('--lr_d',?default=4.0e-4,?type=float)
parser.add_argument('--init_lr',?default=1.0e-3,?type=float)
parser.add_argument('--gan_loss',?default='lsgan',?choices=['lsgan',?'hinge',?'bce'],?type=str)
parser.add_argument('--wadvg',?default=1.7,?type=float,?help='Adversarial?loss?weight?for?G')
parser.add_argument('--wadvd',?default=300,?type=float,?help='Adversarial?loss?weight?for?D')
parser.add_argument('--wcon',?default=1.8,?type=float,?help='Content?loss?weight')
parser.add_argument('--wgra',?default=3.0,?type=float,?help='Gram?loss?weight')
parser.add_argument('--wcol',?default=10.0,?type=float,?help='Color?loss?weight')
parser.add_argument('--img_ch',?default=3,?type=int,?help='The?size?of?image?channel')
parser.add_argument('--ch',?default=64,?type=int,?help='Base?channel?number?per?layer')
parser.add_argument('--n_dis',?default=3,?type=int,?help='The?number?of?discriminator?layer')
args?=?parser.parse_args(args=[])
#?ʵ�������������б���
generator?=?Generator()
discriminator?=?Discriminator(args.ch,?args.n_dis)
#?���������������Ż���,һ������D,��һ������G��
optimizer_g?=?nn.Adam(generator.trainable_params(),?learning_rate=args.lr_g,?beta1=0.5,?beta2=0.999)
optimizer_d?=?nn.Adam(discriminator.trainable_params(),?learning_rate=args.lr_d,?beta1=0.5,?beta2=0.999)
#?ʵ����WithLossCell
net_d_with_criterion?=?DiscriminatorLoss(discriminator,?generator,?args)
net_g_with_criterion?=?GeneratorLoss(discriminator,?generator,?args)
#?ʵ����TrainOneStepCell
my_train_one_step_cell_for_d?=?nn.TrainOneStepCell(net_d_with_criterion,?optimizer_d)
my_train_one_step_cell_for_g?=?nn.TrainOneStepCell(net_g_with_criterion,?optimizer_g)
animegan?=?AnimeGAN(my_train_one_step_cell_for_d,?my_train_one_step_cell_for_g)
animegan.set_train()
#?�������ݼ�
data?=?AnimeGANDataset(args)
data?=?data.run()
size?=?data.get_dataset_size()
for?epoch?in?range(args.epochs):
????iters?=?0
????#?Ϊÿ��ѵ����������
????for?img,?anime,?anime_gray,?anime_smt_gray?in?tqdm(data.create_tuple_iterator()):
????????img?=?Tensor(img,?dtype=dtype)
????????anime?=?Tensor(anime,?dtype=dtype)
????????anime_gray?=?Tensor(anime_gray,?dtype=dtype)
????????anime_smt_gray?=?Tensor(anime_smt_gray,?dtype=dtype)
????????net_d_loss,?net_g_loss?=?animegan(img,?anime,?anime_gray,?anime_smt_gray)
????????if?iters?%?50?==?0:
????????????#?���ѵ����¼
????????????print('[%d/%d][%d/%d]\tLoss_D:?%.4f\tLoss_G:?%.4f'?%?(
????????????????epoch?+?1,?args.epochs,?iters,?size,?net_d_loss.asnumpy().min(),?net_g_loss.asnumpy().min()))
????????#?ÿ��epoch������,ʹ������������һ��ͼƬ
????????if?(epoch?%?args.save_interval)?==?0?and?(iters?==?size?-?1):
????????????stylized?=?denormalize_input(generator(img)).asnumpy()
????????????no_stylized?=?denormalize_input(img).asnumpy()
????????????imgs?=?cv2.cvtColor(stylized[0,?:,?:,?:].transpose(1,?2,?0),?cv2.COLOR_RGB2BGR)
????????????imgs1?=?cv2.cvtColor(no_stylized[0,?:,?:,?:].transpose(1,?2,?0),?cv2.COLOR_RGB2BGR)
????????????for?i?in?range(1,?args.batch_size):
????????????????imgs?=?np.concatenate(
????????????????????(imgs,?cv2.cvtColor(stylized[i,?:,?:,?:].transpose(1,?2,?0),?cv2.COLOR_RGB2BGR)),?axis=1)
????????????????imgs1?=?np.concatenate(
????????????????????(imgs1,?cv2.cvtColor(no_stylized[i,?:,?:,?:].transpose(1,?2,?0),?cv2.COLOR_RGB2BGR)),?axis=1)
????????????cv2.imwrite(
????????????????os.path.join(args.save_image_dir,?args.dataset,?'epoch_'?+?str(epoch)?+?'.jpg'),
????????????????np.concatenate((imgs1,?imgs),?axis=0))
????????????#?��������ģ�Ͳ���Ϊckpt�ļ�
????????????mindspore.save_checkpoint(generator,?os.path.join(args.checkpoint_dir,?args.dataset,
??????????????????????????????????????????????????????????????'netG_'?+?str(epoch)?+?'.ckpt'))
????????iters?+=?1
Mean(B, G, R) of Paprika are [-22.43617309 ?-0.19372649 ?22.62989958] Dataset: real 6656 style 1553, smooth 1553


ģ������
�����������,��һ����ʵ�羰ͼ�����뵽������,�������ɶ�������ͼ��
import?argparse
import?os
import?cv2
from?mindspore?import?Tensor
from?mindspore?import?float32?as?dtype
from?mindspore?import?load_checkpoint,?load_param_into_net
from?mindspore.train.model?import?Model
from?tqdm?import?tqdm
from?src.models.generator?import?Generator
from?src.animeganv2_utils.pre_process?import?transform,?inverse_transform_infer
#?���ز���
parser?=?argparse.ArgumentParser(description='infer')
parser.add_argument('--device_target',?default='Ascend',?choices=['CPU',?'GPU',?'Ascend'],?type=str)
parser.add_argument('--device_id',?default=0,?type=int)
parser.add_argument('--infer_dir',?default='./dataset/test/real',?type=str)
parser.add_argument('--infer_output',?default='./dataset/output',?type=str)
parser.add_argument('--ckpt_file_name',?default='./checkpoints/Hayao/netG_30.ckpt',?type=str)
args?=?parser.parse_args(args=[])
#?ʵ����������
net?=?Generator()
#?���ļ��л�ȡģ�Ͳ��������ص�������
param_dict?=?load_checkpoint(args.ckpt_file_name)
load_param_into_net(net,?param_dict)
data?=?os.listdir(args.infer_dir)
bar?=?tqdm(data)
model?=?Model(net)
if?not?os.path.exists(args.infer_output):
????os.mkdir(args.infer_output)
#?ѭ����ȡ�ʹ���ͼ��
for?img_path?in?bar:
????img?=?transform(os.path.join(args.infer_dir,?img_path))
????img?=?Tensor(img,?dtype=dtype)
????output?=?model.predict(img)
????img?=?inverse_transform_infer(img)
????output?=?inverse_transform_infer(output)
????output?=?cv2.resize(output,?(img.shape[1],?img.shape[0]))
????#?�������ɵ�ͼ��
????cv2.imwrite(os.path.join(args.infer_output,?img_path),?output)
print('Successfully?output?images?in?'?+?args.infer_output)
�����ģ���������:

��Ƶ����
����ķ���������Ƶ�ļ��ĸ�ʽΪmp4,��Ƶ������֮���������ᱻ������
import?argparse
import?cv2
from?mindspore?import?Tensor
from?mindspore?import?float32?as?dtype
from?mindspore?import?load_checkpoint,?load_param_into_net
from?mindspore.train.model?import?Model
from?tqdm?import?tqdm
from?src.models.generator?import?Generator
from?src.animeganv2_utils.adjust_brightness?import?adjust_brightness_from_src_to_dst
from?src.animeganv2_utils.pre_process?import?preprocessing,?convert_image,?inverse_image
#?���ز���,video_input��video_output�������������Ƶ·��,video_ckpt_file_nameѡ������ģ��
parser?=?argparse.ArgumentParser(description='video2anime')
parser.add_argument('--device_target',?default='GPU',?choices=['CPU',?'GPU',?'Ascend'],?type=str)
parser.add_argument('--device_id',?default=0,?type=int)
parser.add_argument('--video_ckpt_file_name',?default='./checkpoints/Hayao/netG_30.ckpt',?type=str)
parser.add_argument('--video_input',?default='./video/test.mp4',?type=str)
parser.add_argument('--video_output',?default='./video/output.mp4',?type=str)
parser.add_argument('--output_format',?default='mp4v',?type=str)
parser.add_argument('--img_size',?default=[256,?256],?type=list,?help='The?size?of?image:?H?and?W')
args?=?parser.parse_args(args=[])
#?ʵ����������
net?=?Generator()
param_dict?=?load_checkpoint(args.video_ckpt_file_name)
#?��ȡ��Ƶ�ļ�
vid?=?cv2.VideoCapture(args.video_input)
total?=?int(vid.get(cv2.CAP_PROP_FRAME_COUNT))
fps?=?int(vid.get(cv2.CAP_PROP_FPS))
codec?=?cv2.VideoWriter_fourcc(*args.output_format)
#?���ļ��л�ȡģ�Ͳ��������ص�������
load_param_into_net(net,?param_dict)
model?=?Model(net)
ret,?img?=?vid.read()
img?=?preprocessing(img,?args.img_size)
height,?width?=?img.shape[:2]
#?���������Ƶ�ķֱ���
out?=?cv2.VideoWriter(args.video_output,?codec,?fps,?(width,?height))
pbar?=?tqdm(total=total)
vid.set(cv2.CAP_PROP_POS_FRAMES,?0)
#?������Ƶ֡
while?ret:
????ret,?frame?=?vid.read()
????if?frame?is?None:
????????print('Warning:?got?empty?frame.')
????????continue
????img?=?convert_image(frame,?args.img_size)
????img?=?Tensor(img,?dtype=dtype)
????fake_img?=?model.predict(img).asnumpy()
????fake_img?=?inverse_image(fake_img)
????fake_img?=?adjust_brightness_from_src_to_dst(fake_img,?cv2.cvtColor(frame,?cv2.COLOR_BGR2RGB))
????#?������Ƶ�ļ�
????out.write(cv2.cvtColor(fake_img,?cv2.COLOR_BGR2RGB))
????pbar.update(1)
pbar.close()
vid.release()
�㷨����

����
[1] Gatys, L. A., Ecker, A. S., & Bethge, M. (2016). Image style transfer using convolutional neural networks. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 2414-2423).
[2] Johnson, J., Alahi, A., & Fei-Fei, L. (2016, October). Perceptual losses for real-time style transfer and super-resolution. In European conference on computer vision (pp. 694-711). Springer, Cham.
[3] Li, Y., Fang, C., Yang, J., Wang, Z., Lu, X., & Yang, M. H. (2017). Diversified texture synthesis with feed-forward networks. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 3920-3928).
[4] Chen, Y., Lai, Y. K., & Liu, Y. J. (2018). Cartoongan: Generative adversarial networks for photo cartoonization. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 9465-9474).
[5] Li, Y., Liu, M. Y., Li, X., Yang, M. H., & Kautz, J. (2018). A closed-form solution to photorealistic image stylization. In Proceedings of the European Conference on Computer Vision (ECCV) (pp. 453-468).
�����N˼MindSporeӦ�ð�������ʹ��������߰���:https://www.mindspore.cn/resources/cases
