概述
- 说话人识别是一个序列总结(Sequence Summarization)任务,输入是音频(或者说,声学特征的序列),输出是说话人的嵌入码,有的神经网络可以输入一对音频,直接输出这对音频的相似度分数。
- 与之相对的,语音识别任务是一个序列转导(Sequence Transduction)任务。
- 上述两个任务都有一个共同的挑战:序列的长度是不定的。
说话人识别推理方式
对于说话人识别,前向传播的方式可以总结为四种:
- 各帧独立的逐帧推理
- 固定窗推理
- 全序列推理
- 滑动窗推理
其中,
- “帧”特指短时傅里叶变换(STFT)中,分帧得到的帧,关于STFT可参考深入理解傅里叶变换(四),通常一帧覆盖20ms~50ms
- “窗”特指一系列帧所组成的序列,不要与STFT中的窗函数混淆
各帧独立的逐帧推理
- 将一系列帧独立地输入到说话人编码器中,得到一系列独立的向量
- 对一系列独立的向量,做一个池化操作,通常是取平均,这样就得到了一个固定维度的向量,这个向量就作为这一系列帧的说话人嵌入码
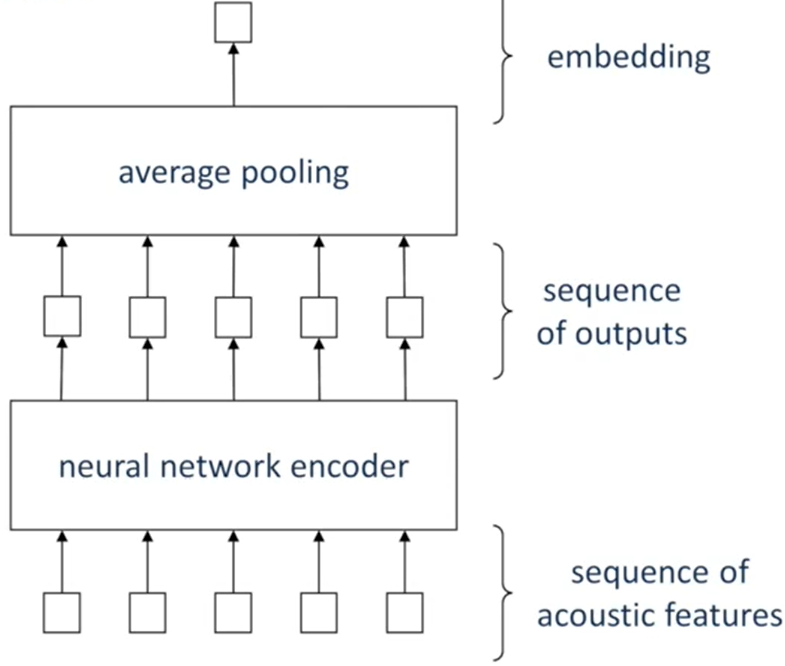
- 这是一种比较简单的推理方式,主要用于早期说话人识别神经网络,那时的神经网络还需要与其他机器学习方法合并才能超越i-vector
- 优点:
- 简单、直接、容易实现
- 每一帧数据维度较小,网络参数也可以较少
- 不需要神经网络具有记忆能力,使用MLP即可推理
- 训练时:可以把很多帧打包成一个batch,训练效率高
- 缺点
- 每次推理只用到了一帧,覆盖的时间段很短暂,信息较少
- 采用平均池化的方法生成嵌入码,使每一帧对嵌入码有同等的贡献,这并不合理,因为有的帧噪声大、有的帧噪声小
固定窗推理
-
在文本相关的说话人识别任务中,所需识别的帧序列长度是可以确定的,比如:在唤醒词检测中,“OK Google”、“Hey Siri”这样的唤醒词,覆盖时间段不会超过1s
-
因此可以采用一个固定长度的窗,从长序列中截取出固定长度的帧序列,至于这个帧序列的起始点和结束点,由唤醒词检测算法决定,如下图所示(图源:语音之家)
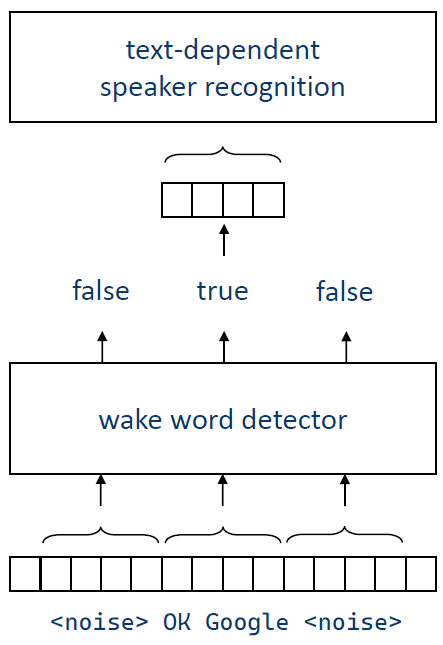
-
得到固定长度的帧序列后,将帧序列中的每一帧进行堆叠,称为“堆叠帧”,例如:帧序列长为50(即50个帧),对每一帧提取出40维的filterbank特征,那么堆叠帧的维度就是 50 × 40 = 2000 50 \times 40=2000 50×40=2000。可见,堆叠帧的维度是固定的,如下图所示(图源:语音之家)
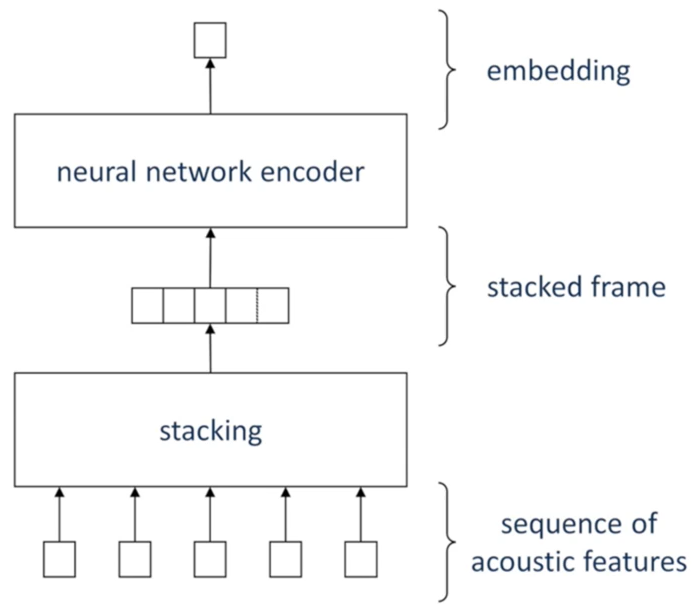
-
优点:
- 简单
- 不需要神经网络具有记忆能力,使用MLP即可推理
- 训练时:可以把很多堆叠帧打包成一个batch,训练效率高
-
缺点
- 只能用于文本相关的说话人识别任务
- 堆叠帧的维度容易过大,导致网络参数也较大,可以尝试降低参数:使用dropout/maxout;使用CNN/RNN共享权重
全序列推理
- 全序列推理旨在达到以下目标
- 可处理任意长度的序列
- 充分利用上下文信息
- 有两种神经网络,非常适合全序列推理,RNN和Attention(包含Self-attention)
- 基于RNN的全序列推理,RNN有如下特点:
- 输入和输出都是一个序列
- 对序列中的每个元素,都有一个输出
- 输出序列与输入序列长度相等
- 可处理任意长度的序列
- 具有记忆能力,每一个输出,都包含了当前和之前的输入的信息
- 输入序列中的每个元素并不是独立的,元素的顺序变化会影响整个输出序列
- 对于说话人识别而言,只需要一个输出,即该序列的嵌入码,因此可以有两种做法:
- 对输出序列进行池化(通常为平均池化),得到一个向量作为嵌入码;
- 只取输出序列的最后一个元素,作为嵌入码,因为RNN具有“记忆能力”,所以只有取最后一个元素,才能包含整个序列的信息。但对于双向RNN而言,输出序列的每一个元素都包含整个序列的信息,因此不限制使用最后一个元素
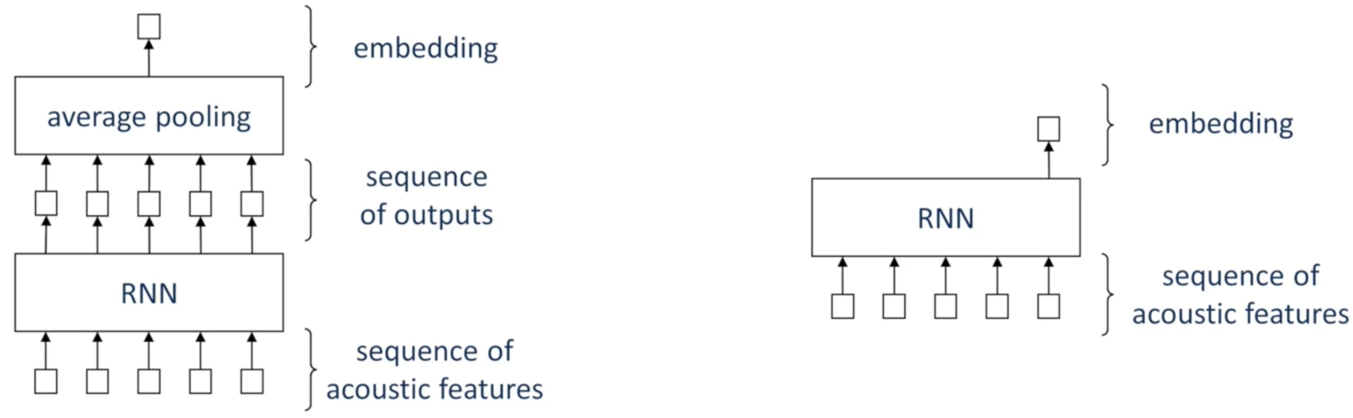
- 基于Attention的全序列推理:Attention在此主要发挥两个作用
- 序列标注(Sequence Labeling),也就是将帧序列转换成一个长度一样的序列,关于用Attention进行序列标注,可以参考深入理解Self-attention
- 序列总结,在完成序列标注,得到与输入序列长度相等的输出序列后,不同于RNN(对输出序列进行池化),而是使用Attention将序列总结为一个嵌入码,公式如下:
z = ∑ i = 1 T α i v i ∑ i = 1 T α i z=\frac{\sum_{i=1}^{T}\alpha_i v_i}{\sum_{i=1}^{T}\alpha_i} z=∑i=1T?αi?∑i=1T?αi?vi??
其中,- T T T是序列长度
- α i \alpha_i αi?是对序列的每一个元素计算的Attention分数
- v i v_i vi?是对序列的每一个元素提取的信息value
- RNN和Attention在全序列推理中可以搭配使用,比如第一层是RNN,第二层是Attention,如此交替堆叠,最后一层输出嵌入码
- 优点
- 能处理可变序列,能捕获全序列上下文信息,是比较理想的推理方式
- 对每段完整的话语,提取出声学特征后,能够直接输入到网络中
- 缺点
- 训练时:由于序列可变,所以无法将输入序列打包成batch用于训练,换言之,batch_size只能等于1,训练效率极低
- 训练优化
- 从完整的话语中,截取出片段(Segment),片段长度可自定义
- 将相同长度的片段,打包成同一个batch,不同的batch,片段长度可以不同
- 此时batch_size不再限制为1,训练变得高效
滑动窗推理
- 将完整的帧序列,用类似分帧的方法,进行分窗,每个窗之间可以重叠
- 各窗独立的逐窗推理
- 对每个窗的推理,可以采用全序列推理方式
- 训练时,各窗的输出,独立计算损失,独立更新参数
- 运行时,对每个窗的推理结果,进行池化(通常为平均池化)得到嵌入码,进行说话人识别
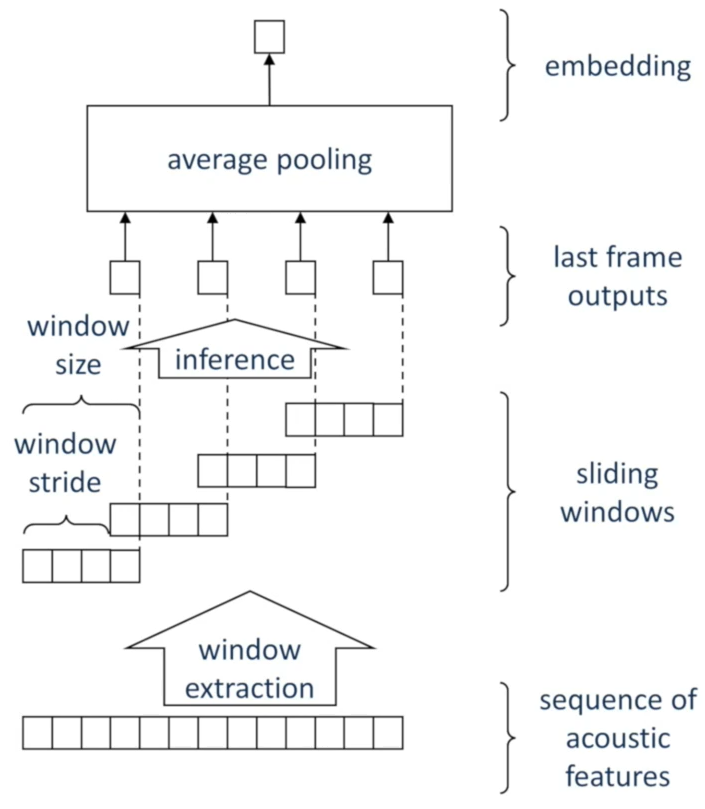
- 优点
- 训练时:不需要池化,各窗独立推理,同一大小的窗可以打包在同一个batch中,不同的batch,其窗大小可以不同
- 与全序列推理中基于片段的训练方式非常相似
- 缺点
- 运行时:需要逐窗推理,耗时较多
- 若相邻窗的重叠程度为 N % N\% N%,则帧序列中的每一帧,被同时包含在了 100 % 100 % ? N \frac{100\%}{100\%-N} 100%?N100%?个窗中,当N增大,耗时会显著增加
总结
| 推理方式 | 各帧独立的逐帧推理 | 固定窗推理 | 全序列推理 | 滑动窗推理 |
|---|---|---|---|---|
| 基本思想 | 逐帧独立推理 | 将窗中的所有帧堆叠在一起进行推理 | 利用RNN、Attention处理可变序列 | 每个床可视为全序列推理,逐窗独立推理 |
| 网络类型 | MLP | MLP、CNN | RNN、Attention | RNN、CNN、Attention |
| 优点 | 简易 | 简易 | 能利用全序列的上下文信息 | 能利用全序列的上下文信息 |
| 缺点 | 每个帧所包含的信息不足 | 仅限于文本相关的说话人识别 | 训练时,需要分片段打包成batch | 训练时,需要分片段打包成batch,窗口重叠导致额外计算复杂度 |
上述四种推理方式在实际中,可以合并,例如:
- 平均池化都可以用Attention替代
- 全序列推理可以堆叠帧,使用CNN推理
- 池化或者聚合之后,可以再添加一个MLP