���ĵ�ַ:https://arxiv.org/pdf/2103.05950.pdf
�����ַ:https://github.com/megvii-research/FSCE
�Ա�ѧϰhttps://zhuanlan.zhihu.com/p/346686467
Ŀ¼
1�����ڵ�����
С����Ŀ����ķ������ڵIJ�����:����������Իع�����Ĵ����ʸ��ߡ� Ŀ���λͨ����ȷ,����Ŀ������ʶ����������

��������,����ѧϰ��������������ȥ�ͻ����������Ŀ���������,������������ױ����Ϊ�������������ࡣ
�Ա�ѧϰ����ͨ�����Ͳ�ͬ���Ŀ�������������С���ڲ���,����������,�����Ϳ��Լ��ٶ��������������С�
�Ա�ѧϰ��Ŀ����ѧϰһ��������,�˱�������ͬ�����ݽ������Ƶı���,��ʹ��ͬ������ݵı����������ܵIJ�ͬ��
2���㷨���
��һ��������fine-tune�ķ����� ��һ�ν��Ա�ѧϰ���뵽��С����Ŀ����������
�����һ�� ���ڶԱȽ������(FSCE)��С����Ŀ���ⷽ�� ,��RoI ������ȡ��������һ���ͻع顢�����֧���е� �����Աȱ���(CPE)��֧��
ѵ������:
����,ʹ�÷ḻ�Ļ�������(Dtrain=Dbase)ѵ��Faster R-CNN���ģ�͡�
Ȼ��,��ѵ���õ�ģ��Ǩ�Ƶ�С���ݼ��ϡ�С���ݼ������������������Ļ�����ɵĻ�����ݼ�(
D
t
r
a
i
n
=
D
n
o
v
e
l
��
D
b
a
s
e
Dtrain=Dnovel\cup Dbase
Dtrain=Dnovel��Dbase)������������,����������ȡ���类����,�����Ż��ع���ʧ��������ʧ�ͶԱȽ�����ʧ��

3���㷨ϸ��
3.1��new-baseline
����,�ع�һ��ԭʼ����������TFA:
1���ڻ���ѵ����,���ô����Ļ�����������ͨ������Ŀ��������(��Faster-RCNN��)����ѵ������������ڻ���������ѵ������Ŀ������,����������ȡ����boxԤ������
2��������,�ڱ�������������ȡ������������,�����������ʼ����Ȩֵ�����boxԤ������,ֻ��box����ͻع�����,����������ȡ������������ˡ�
���,�����������ȫû�в��뵽�����ѵ��������,RPN,ROI������ȡ��ֻ�����ӻ�����ѧ����������Ϣ,����ʵ���Կ�����һ��������Ĺ����ѵ����
ͬʱ,���߷���,������,�������Ľ��������ֻ�л���ѵ��ʱ��1/4,��Ϊ������������Ľ��������ŶȺܵ�,�ᱻNMS���˵�,����ǰ������������Ҳ��֮����,����ѧϰ�����Ļ�����١�
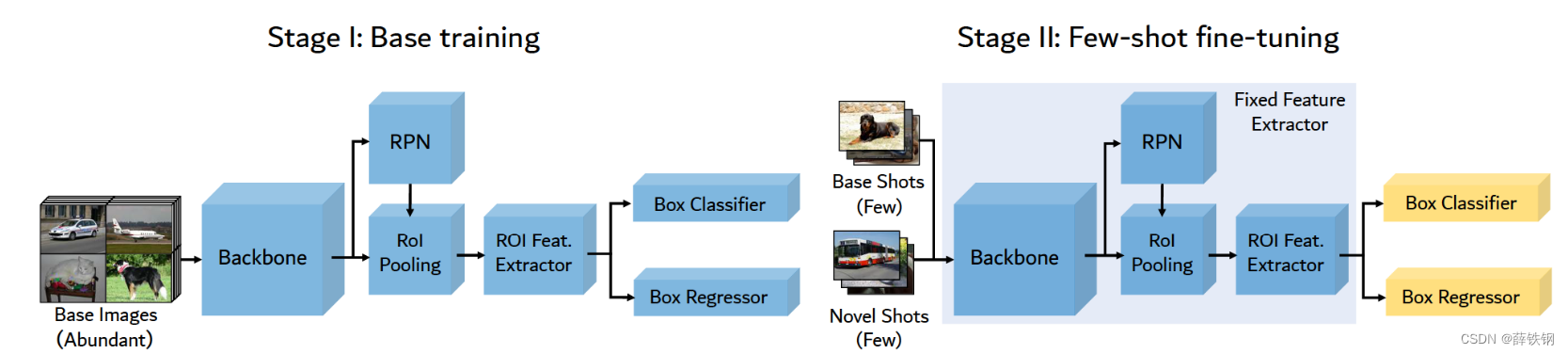
������TFA�Ļ����������һ��new-baseline��
new-baseline�ڽⶳRPN��ROIģ���ͬʱӦ�������µ���������:
1��������,ԭʼ��TFA��RPN�����������������, new-baselineʹ�þ���NMS�Ľ������������������������ ��ʹ����˸����ǰ��,�൱��������������������
2������ROI��batchsize��512,��ǰ��������������512��һ�뻹��,��� ��ROI head ��������ʧ����ij�����������������һ�롣 �൱��������ǰ������������,ʹ������ѧϰ���˸��������������
3.2���ԱȽ������
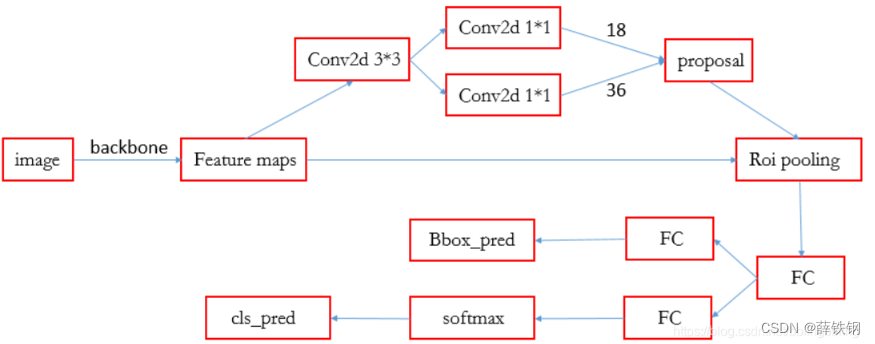
����,�����ع�һ��Faster R-CNN����������:
1��Backbone:conv+relu+pooling.
����:ͼ��
����:��ȡ����ͼ�������ͼ
���:����ͼ
2��RPN:
����:Backbone������ͼ
����:���ɽ����proposal
���:�����proposal
3��ROI Pooling:
����:�����proposal �� Backbone������ͼ
����:�������proposalӳ�䵽Backbone������ͼ�ϵõ�proposal feature maps,������ͬ��С��proposal feature maps������ͳһ��С
���:һ������(��������=���������,������С=CxWxH,����CΪͨ����,W=7,H=7)
4�������֧:
����:proposal feature maps
����:�õ������������
���:cls_prob��������(����������ڸ������ĸ���)
5���ع��֧:
����:proposal feature maps
����:ȷ��Ŀ�����ľ�ȷλ��
���:ÿ��proposal��λ��ƫ����bbox_pred
6��ROI head:
����ROI pooling,box_head�Լ�box_predictor�����һ���,��Faster R-CNN��,ROI head��RPN������proposal����pooling����1024ά����������,�ٶԸ������������з���,�Լ�bbox�ع顣
���dz���������Ϊ������������������Ƚ���������ʾ,��������������˵�Dz�����׳�ġ�
����ʵ��,���������������,���������������ܺܺõ��������ǡ�
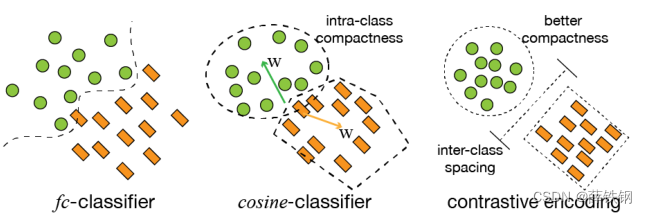
Ϊ�˸��õĴ�С������ѧ�������Ŀ��������ʾ,���������һ�� �����Ա�ѧϰ����(batch contrastive learning) �����õĶ� ���������� �� �������� �������н�ģ��
���������� ��ROI head�м�����һ���Աȷ�֧(contrastive branch),��ع�ͷ����֧����,���ڶ���������������
�Աȷ�֧ʹ��1�����֪��( 1��������),��1 * 1024��ROI����ת��Ϊ1 * 128ά���Ա��������� x i x_{i} xi?�����,����Ա��������������ƶȷ���,�����Աȷ�֧����ʧ���뵽�ܵ���ʧ�����н����Ż�,ʹ�ò�ͬ����������,��ͬ��������١�
���û����������ƶȵı߽�������,�����RoI ��������������Զ�������ʽ��ʾ�� i �� RoI ��� j �����������Զ���:
l
o
g
i
t
{
i
,
j
}
=
��
x
i
T
w
j
�O
�O
x
i
�O
�O
?
�O
�O
w
j
�O
�O
logit_{\{i,j\}} = \alpha\frac{x_{i}^Tw_{j}}{||x_{i}|| \cdot ||w_{j}||}
logit{i,j}?=���O�Oxi?�O�O?�O�Owj?�O�OxiT?wj??
��
\alpha
���������ݶȵij߶�Ԫ��,ʵ������Ϊ20,
x
i
x_{i}
xi?�ǵ� i ��ʵ����ROI����,
w
j
w_{j}
wj?�ǵ� j ������Ȩ�ء�
����������ͶӰ�ij��ռ���,�Ա���������ʹ�������ķ���ʹ�ô��ھ����С,�ؼ�������

3.3���ԱȽ���������ʧ
����ÿһ��mini-batch,��N��ROI������,
{
z
i
,
u
i
,
y
i
}
i
=
1
N
\{z_{i},u_{i},y_{i}\}_{i=1}^N
{zi?,ui?,yi?}i=1N?,
z
i
z_{i}
zi?��ʾROI head�Ե�
i
i
i���������������ɵ�128ά����;
u
i
u_{i}
ui?��ʾ��������ʵ���IOUֵ;
y
i
y_{i}
yi?��ʾ��ʵ��ı�ǩ��
����ƶԱȽ���������ʧΪ:
L
C
P
E
=
1
N
��
i
=
1
N
f
(
u
i
)
?
L
z
i
L_{CPE} = \frac{1}{N}\sum_{i=1}^{N}{f(u_i)}\cdot L_{z_{i}}
LCPE?=N1?i=1��N?f(ui?)?Lzi??
L
z
i
=
?
1
N
y
i
?
1
��
j
=
1
,
j
��
i
N
�O
�O
{
y
i
=
y
j
}
?
l
o
g
e
x
p
(
z
i
~
?
z
j
~
/
��
)
��
k
=
1
N
�O
�O
k
��
i
?
e
x
p
(
z
i
~
?
z
k
~
/
��
)
L_{z_{i}} = \frac{-1}{N_{y_{i}}-1}\sum_{j=1,j\ne i}^{N}{||\{ y_{i}=y_{j}\}\cdot log \frac{exp(\widetilde{z_{i}} \cdot \widetilde{z_{j}}/\tau)}{\sum_{k=1}^{N}{||_{k\ne i}\cdot exp(\widetilde{z_{i}} \cdot \widetilde{z_{k}}/\tau)}}}
Lzi??=Nyi???1?1?j=1,j��=i��N?�O�O{yi?=yj?}?log��k=1N?�O�Ok��=i??exp(zi?
??zk?
?/��)exp(zi?
??zj?
?/��)?
f
(
u
i
)
=
�O
�O
{
u
i
��
?
}
?
g
(
u
i
)
{f(u_i)}=||\{u_{i}\geq \phi\}\cdot g(u_{i})
f(ui?)=�O�O{ui?��?}?g(ui?)
������Ĺ�ʽ��,ʹ�� f ( u i ) {f(u_i)} f(ui?)������ƫ��Ŀ�����Ľ�������Ŀ,��ֹ IoU �÷ֹ���ʹ��proposal �а������ŵı�����Ϣ��(ͼ����������������Ϣ����������ͼƬ������Ŀ����������,���ڷ����������Ϣ������RPN�õ���region proposals,��ЩIOU�ϵ͵�proposal���ܺ��н϶�ķ�Ŀ����Ϣ��)
����,
z
j
~
=
z
i
�O
�O
z
i
�O
�O
\widetilde{z_{j}}=\frac{z_{i}}{||z_{i}||}
zj?
?=�O�Ozi?�O�Ozi??,��ʾ��һ������;
z
i
~
?
z
j
~
\widetilde{z_{i}} \cdot \widetilde{z_{j}}
zi?
??zj?
?��ʾ��
i
i
i���͵�
j
j
j�������֮����������ƶ�;
N
y
i
N_{y_{i}}
Nyi??�Ǿ�����ͬ��ǩ
y
i
y_{i}
yi?�Ľ���������;
��
\tau
���dz�����;
?
\phi
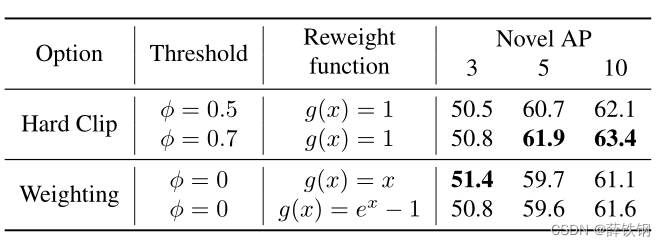
?ΪIOU��ֵ,ȡֵΪ0.7;
g
(
u
i
)
g(u_{i})
g(ui?)ΪȨ�ط��亯��,Ϊ��ͬ��IOU���費ͬ��Ȩ�ء�
���յ���ʧ����Ϊ:
L = L r p n + L c l s + L r e g + �� L C P E \mathbb{L}=L_{rpn}+L_{cls}+L_{reg}+\lambda L_{CPE} L=Lrpn?+Lcls?+Lreg?+��LCPE?
����,
L
r
p
n
L_{rpn}
Lrpn?�Ƕ�Ԫ��������ʧ,���ڴ��ڶ�anchor�еõ�ǰ��proposals��
L
c
l
s
L_{cls}
Lcls?�ǽ�������ʧ,����proposals����,
L
r
e
g
L_{reg}
Lreg?��smoothed-L1��ʧ,����box�ع顣
�������δ��䵽������ʱ,���Ƿ��ֶԱ���Ŀ����Զ�����ʽ���ӵ���ҪFaster RCNN�����,�������ƻ�ѵ��,
��
\lambda
������Ϊ0.5,��ƽ����ʧ��ģ��
ѵ������:
1������,ʹ�÷ḻ�Ļ�������(Dtrain=Dbase)ѵ��Faster R-CNN���ģ�͡�
2��Ȼ��,��ѵ���õ�ģ��Ǩ�Ƶ�С���ݼ��ϡ�С���ݼ������������������Ļ�����ɵĻ�����ݼ�( D t r a i n = D n o v e l �� D b a s e Dtrain=Dnovel\cup Dbase Dtrain=Dnovel��Dbase)������������,����������ȡ���类����,�����Ż��ع���ʧ��������ʧ��CPE��ʧ��
��ʵ���Ǽ���һ��ͬ������,��������ģ��,ʹ�þ���ķ��������������졣
4��ʵ��
ʵ���������
| ��Ŀ | Value |
|---|---|
| ���߷��� | Faster R-CNN |
| ������ȡ�� | ResNet-101+FPN |
| batch-size | 16 |
| ѵ������ | SGD�Ż��� |
| ���� | 0.9 |
| Ȩ��˥�� | 0.0001 |
| GPU���� | 8 |
��֤ʵ��
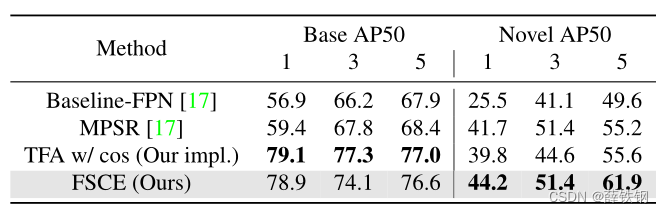
PASCAL VOC PASCAL VOC�е�20������Ϊ15�������5�����ࡣ��������PASCAL VOC 07+12 trainval���ϵĻ������ݶ�����Ϊ�ǿ��õ�,��ʵ����K-shot�Ǵ������������ȡ��,K=1��2��3��5��10��
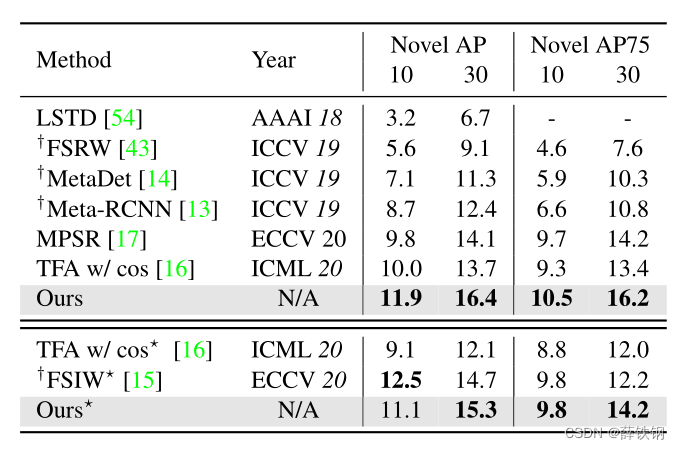
MS COCO ����COCO�е�80�����,��PASCAL VOC��ͬ��20�������Ϊ����,����60������������ࡣ��COCO 2014 val���ݼ���5Kͼ����������K=10��30��shot�ļ������,����ȡ�������COCOstyle AP��AP75��
����ʵ��
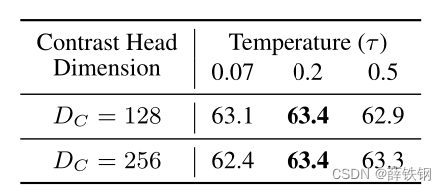
Ϊ��ȷ��ÿ��ģ������Ų���ֵ���е�����ʵ��:
1���Աȷ�֧�IJ�������
2���Աȱ�����ʧ�IJ�������
new-baseline
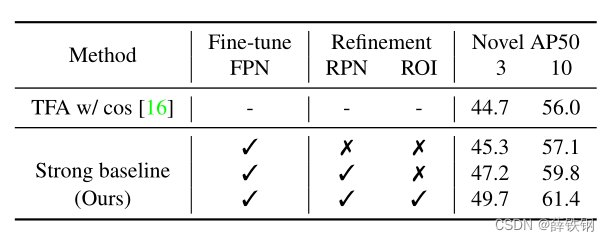
FSCE�������ģ�������
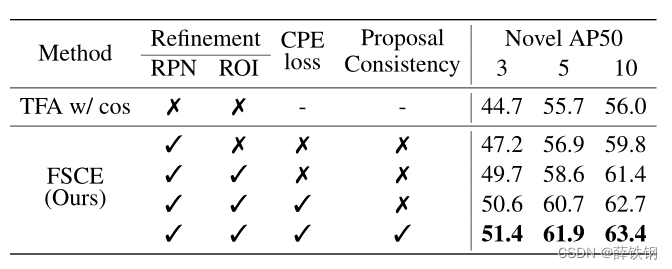
5������
����Ա�ѧϰ��˼��
��ʵ�����н�ģ�����Ƕ������н�ģ
�Աȷ�֧������Ϊ���������һ�����弴��ģ��