�������һƪ�����ģ�͵�����, �����õ���GAN, �����Լ����Ǻܶ�. �뷭��һ��һ������IJ���, ��һ�±ʼ�. ������ȫ�ķ���, ֻ����һ����.
ԭ�ĵ�ַ: from GAN to WGAN
1. K-L��J-Sɢ��
�ڽ���GAN֮ǰ, ���ȸ�ϰһ�º����������ʷֲ����ƶȵ�����ָ��.
(1) K-Lɢ��: KLɢ�Ⱥ�����ij�����ʷֲ� p p p��ȡ��(��ɢ��, ����)��һ��������(���۵�)���ʷֲ� q q q�ij̶�:
D K L ( p �O �O q ) = �� x p ( x ) log ? p ( x ) q ( x ) d x D_{KL}(p||q)=\int_xp(x)\log{\frac{p(x)}{q(x)}}dx DKL?(p�O�Oq)=��x?p(x)logq(x)p(x)?dx
�� p ( x ) p(x) p(x)�� q ( x ) q(x) q(x)�������ʱ, KLɢ��Ϊ0.
����Ҫע�KLɢ���ǷǶԳƵ�( D K L ( p �O �O q ) �� D K L ( q �O �O p ) D_{KL}(p||q) \ne D_{KL}(q||p) DKL?(p�O�Oq)��=DKL?(q�O�Op)), ���ҵ� p ( x ) p(x) p(x)�ӽ�0��ʱ��, q ( x ) q(x) q(x)�����þͱ�������. �������ʱ����ɺ�������Ľ��.
KLɢ�ȵı��ʾ��ǻ���Ϣ, �����������ʷֲ��IJ��.
(2) J-Sɢ��: JSɢ������һ�ֺ����������ʷֲ����ƶȵ�ָ��, ��Χ�� [ 0 , 1 ] [0,1] [0,1]֮��. JSɢ���ǶԳƵ�, ���Ҹ�ƽ��. ��������:
D J S ( p �O �O q ) = 1 2 D K L ( p �O �O p + q 2 ) + 1 2 D K L ( q �O �O p + q 2 ) D_{JS}(p||q)=\frac{1}{2}D_{KL}(p||\frac{p+q}{2})+\frac{1}{2}D_{KL}(q||\frac{p+q}{2}) DJS?(p�O�Oq)=21?DKL?(p�O�O2p+q?)+21?DKL?(q�O�O2p+q?)
���߲������ͼ��ʾ:
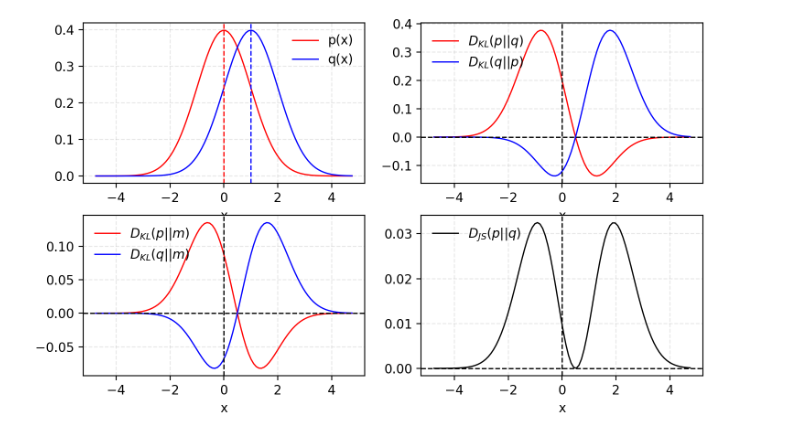
һЩ����ΪGANȡ���ش�ɹ���ԭ��֮һ�ǽ���ʧ�������ڼ�����Ȼ������ʹ�÷ǶԳƵ�KLɢ��ת��ʹ�öԳƵ�JSɢ��.
2. ���ɶԿ�����GAN
GAN��������ģ�����:
- һ��������D, ����������һ��������������������ʵ���ݼ��ĸ���. ���൱��һ��������, �����Ż���Ŀ��������ʵ�����������ֳ��ٵ�����.
- һ��������G, �������ٵ�����(�����Ϊ����������ʵ���ݼ�), ����������zΪ����(z������DZ�ڵ����������). ����ѵ����Ŀ���ǻ�ȡ��ʵ�����ݷֲ���ʹ�ò��������������ܽӽ�����ʵ�ķֲ�, ���仰˵, ������ƭ������, �ü������Ը߸�����Ϊ����ʵ������.
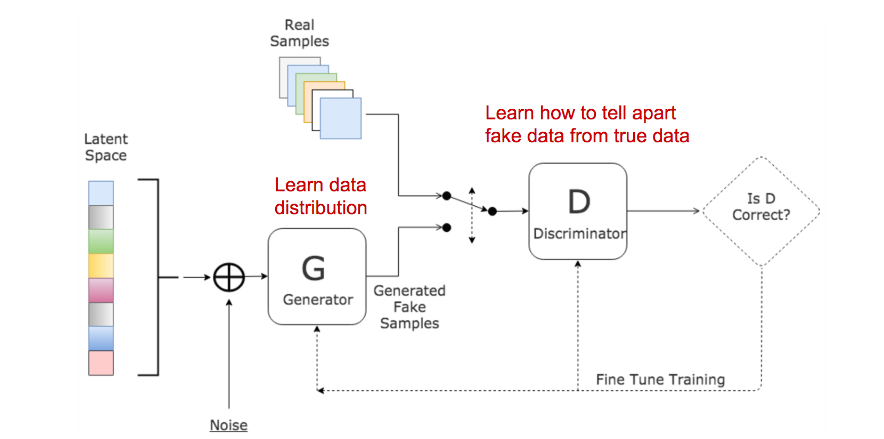
������ģ����ѵ�������л��ྺ��: ������GŬ��ȥ��ƭ������D, ��������ҲŬ��������ƭ. ������Ȥ����Ͳ��Ļ��ʹ������������Ǹ��ԵĹ���.
�ٶ����·���:
| p z p_z pz? | ��������z�����ݷֲ� |
| p g p_g pg? | ��������������x��(���)�ֲ� |
| p r p_r pr? | ��ʵ����x�ķֲ� |
һ����, ������ȷ��������D������ʵ�����ݵľ����Ƿdz���ȷ��, Ҳ������� E x �� p r ( x ) [ log ? D ( x ) ] E_{x\sim p_r(x)}[\log D(x)] Ex��pr?(x)?[logD(x)], Ҳ����˵, �� D ( x ) D(x) D(x)�����ܽӽ�1. ͬʱ, ����һ�������� G ( z ) G(z) G(z), �����������һ������ D ( G ( z ) ) D(G(z)) D(G(z)), ����Ҳϣ����������������ʽӽ�0, ��˵ȼ������ E z �� p z ( z ) [ log ? ( 1 ? D ( G ( z ) ) ] E_{z\sim p_z(z)}[\log (1-D(G(z))] Ez��pz?(z)?[log(1?D(G(z))].
��һ����, ��������Ŀ���������Լ�������������������ʶ��Ϊ��ʵ�����ĸ���, Ҳ������С�� E z �� p z ( z ) [ log ? ( 1 ? D ( G ( z ) ) ] E_{z\sim p_z(z)}[\log (1-D(G(z))] Ez��pz?(z)?[log(1?D(G(z))].
���ǰ��������涼���ǽ�ȥ, D��G��������һ�����-��С��Ϸ, ����Ӧ���Ż����µ���ʧ����:
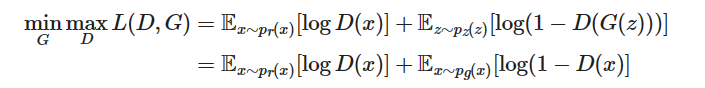
֮���Կ��Խ���һ��
E
x
��
p
r
(
x
)
[
log
?
D
(
x
)
]
E_{x\sim p_r(x)}[\log D(x)]
Ex��pr?(x)?[logD(x)]Ҳ�������������Ż�����, ����Ϊ���൱�ڳ�����, ��������Ӱ��.
D�����ֵ��ʲô?
������������һ���������õ���ʧ����. �������ǿ���D�����ֵ��ʲô.
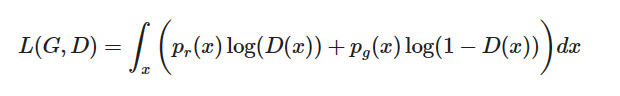
Ϊ�˱�ʾ����, ���Ǽ�
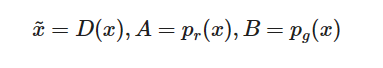
֮��, �ڻ����������Ϊ(���ǿ���ȫ�غ��Ի���, ��Ϊ
x
x
x�Ǵ����п���ȡֵ�в�����):
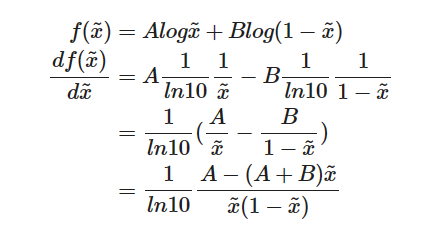
�������Ϊ0, ���ǿ��Եõ������������ֵ:
D ? ( x ) = x ~ ? = A A + B = p r ( x ) p r ( x ) + p g ( x ) D^*(x)=\tilde{x}^*=\frac{A}{A+B}=\frac{p_r(x)}{p_r(x)+p_g(x)} D?(x)=x~?=A+BA?=pr?(x)+pg?(x)pr?(x)?.
���ǵ�Ȼϣ������������ĸ��ʷֲ� p g ( x ) p_g(x) pg?(x)���� p r ( x ) p_r(x) pr?(x)ʮ�ֽӽ�, ��ʱ D ? ( x ) = 1 / 2 D^*(x)=1/2 D?(x)=1/2(�������൱����Ϲ��).
ȫ��������ʲô?
��G��D�����������ŵ�ֵ, Ҳ���� p g ( x ) = p r ( x ) p_g(x)=p_r(x) pg?(x)=pr?(x), D ? ( x ) = 1 / 2 D^*(x)=1/2 D?(x)=1/2, ��ʧ������Ϊ:
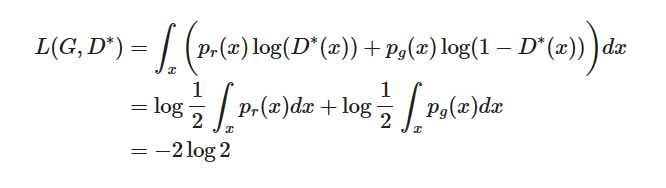
���GAN��ʧ�����������½�Ϊ
?
2
log
?
2
-2\log2
?2log2.
��ʧ����������ʲô?
����չ��J-Sɢ��:
D
J
S
(
p
�O
�O
q
)
=
1
2
D
K
L
(
p
�O
�O
p
+
q
2
)
+
1
2
D
K
L
(
q
�O
�O
p
+
q
2
)
=
1
2
[
��
x
p
(
x
)
log
?
p
(
x
)
(
p
(
x
)
+
q
(
x
)
)
/
2
d
x
+
��
x
q
(
x
)
log
?
q
(
x
)
(
p
(
x
)
+
q
(
x
)
)
/
2
d
x
]
D_{JS}(p||q)=\frac{1}{2}D_{KL}(p||\frac{p+q}{2})+\frac{1}{2}D_{KL}(q||\frac{p+q}{2}) \\ =\frac{1}{2}[\int_xp(x)\log{\frac{p(x)}{(p(x)+q(x))/2}}dx+\int_xq(x)\log{\frac{q(x)}{(p(x)+q(x))/2}}dx]\\
DJS?(p�O�Oq)=21?DKL?(p�O�O2p+q?)+21?DKL?(q�O�O2p+q?)=21?[��x?p(x)log(p(x)+q(x))/2p(x)?dx+��x?q(x)log(p(x)+q(x))/2q(x)?dx]
����
��
x
p
(
x
)
log
?
p
(
x
)
(
p
(
x
)
+
q
(
x
)
)
/
2
d
x
=
��
x
p
(
x
)
log
?
p
(
x
)
p
(
x
)
+
q
(
x
)
d
x
+
��
x
p
(
x
)
log
?
2
d
x
=
log
?
2
+
��
x
p
(
x
)
log
?
p
(
x
)
p
(
x
)
+
q
(
x
)
d
x
\int_xp(x)\log{\frac{p(x)}{(p(x)+q(x))/2}}dx=\int_xp(x)\log{\frac{p(x)}{p(x)+q(x)}}dx+\int_xp(x)\log{2}dx\\ =\log2 +\int_xp(x)\log{\frac{p(x)}{p(x)+q(x)}}dx
��x?p(x)log(p(x)+q(x))/2p(x)?dx=��x?p(x)logp(x)+q(x)p(x)?dx+��x?p(x)log2dx=log2+��x?p(x)logp(x)+q(x)p(x)?dx
��һ����ͬ��, �����
D
J
S
(
p
�O
�O
q
)
=
1
2
[
2
log
?
2
+
��
x
p
(
x
)
log
?
p
(
x
)
p
(
x
)
+
q
(
x
)
+
��
x
q
(
x
)
log
?
q
(
x
)
p
(
x
)
+
q
(
x
)
]
D_{JS}(p||q)=\frac{1}{2}[2\log2+\int_xp(x)\log{\frac{p(x)}{p(x)+q(x)}}+\int_xq(x)\log{\frac{q(x)}{p(x)+q(x)}}]
DJS?(p�O�Oq)=21?[2log2+��x?p(x)logp(x)+q(x)p(x)?+��x?q(x)logp(x)+q(x)q(x)?]
�� D D D�ﵽ����ֵ�� D ? ( x ) = p r ( x ) p r ( x ) + p g ( x ) D^*(x)=\frac{p_r(x)}{p_r(x)+p_g(x)} D?(x)=pr?(x)+pg?(x)pr?(x)?ʱ, ��ʧ����Ϊ
L ( G , D ? ) = �� x p r ( x ) log ? p r ( x ) p r ( x ) + p g ( x ) + �� x p g ( x ) log ? p g ( x ) p r ( x ) + p g ( x ) L(G,D^*)=\int_xp_r(x)\log{\frac{p_r(x)}{p_r(x)+p_g(x)}}+\int_xp_g(x)\log{\frac{p_g(x)}{p_r(x)+p_g(x)}} L(G,D?)=��x?pr?(x)logpr?(x)+pg?(x)pr?(x)?+��x?pg?(x)logpr?(x)+pg?(x)pg?(x)?
�� p = p r ( x ) , q = p g ( x ) p=p_r(x), q=p_g(x) p=pr?(x),q=pg?(x), �����
D
J
S
(
p
r
�O
�O
p
g
)
=
1
2
[
2
log
?
2
+
L
(
G
,
D
?
)
]
D_{JS}(p_r||p_g)=\frac{1}{2}[2\log 2+L(G,D^*)]
DJS?(pr?�O�Opg?)=21?[2log2+L(G,D?)]
����
L
(
G
,
D
?
)
=
2
D
J
S
(
p
r
�O
�O
p
g
)
?
2
log
?
2
L(G,D^*)=2D_{JS}(p_r||p_g)-2\log 2
L(G,D?)=2DJS?(pr?�O�Opg?)?2log2
���Ե�һ�дﵽ���ŵ�ʱ��, JSɢ����0, ��ʧ�������������½� ? 2 log ? 2 -2\log 2 ?2log2.
3. GAN�д��ڵ�����
���Դﵽ��ʲ����(Nash equilibrium)
ѵ������������ģ��(G��D)�ǷǺ�������, ���Դﵽ���Ե�ƽ���, ���ῼ����һ��ģ��. ��˲����ܱ�֤ģ�����տ�������.
��һ��������˵��Ϊʲô�ڷǺ��������к���Ѱ����ʲ����. ����һ����ҵ�Ŀ���� f 1 ( x ) = x y f_1(x)=xy f1?(x)=xy, ��һ����ҵ�Ŀ���� f 2 ( y ) = ? x y f_2(y)=-xy f2?(y)=?xy, ������ݶ��½���, ���1ÿ�εĸ��²���Ϊ x �� x ? �� y x\leftarrow x-\eta y x��x?��y, ���2�IJ���Ϊ y �� y + �� x y\leftarrow y+\eta x y��y+��x, ��˶��ߵķ������෴��. ���¹�������ͼ��ʾ.
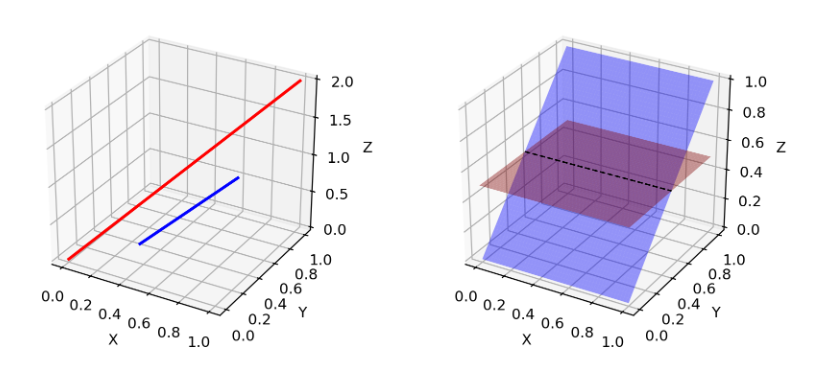
��ά�ȵ�֧��
������Ϊ������ʵ���ݼ���ά��ֻ����Ϊ���. ���纬�й���ͼƬ, ��������һ��β�Ϳ��Դ�����, ʵ���ϲ���Ҫ�ܶ����ɵĸ�ά��ʽ. Ҳ����˵���ӵĶ������Լ����ڵ�ά������.
p
g
p_g
pg?Ҳλ�ڵ�ά������, ����������100ά������, Ҫ��ȡ64x64��ͼ��, ��4096�����ϵ���ɫ�ֲ��Ѿ���100άС�������������,����������������ά�ռ�. ��Ϊ�����������������ڵ�ά������,���Ǽ����϶���ཻ(��ͼ, ��ά���κ����ڸ�ά�ռ����). �����Ǿ��в��ཻ��֧��ʱ,���������ܹ��ҵ�һ�������ļ�����,���� 100% ��ȷ�������������.
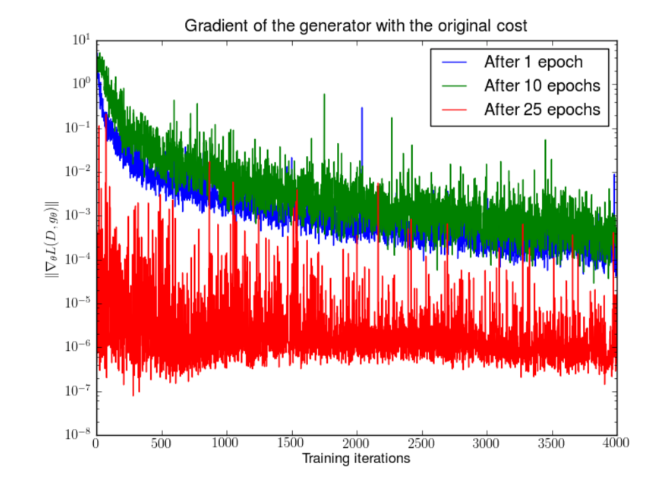
�ݶ���ʧ
����������dz�����, ����ÿ����ʵ�������������1, ÿ������������������0, ����ʧ�������Ϊ����0, �ݶȲ��ٸ���. ��ͼ�����˵���������õ�ʱ��, �ݶ�������ʧ.
����GAN��ѵ������������:
- ����������ܲ�, ��ô��������û�о�ȷ�ķ���, ��ʧ�������ܴ�����ʵ���
- ����������ܺ�, ��ô��ʧ�����ͻ�ܵ�, ѧϰ�ͻ����.
ģʽ����
��ѵ���ڼ�,���������ܻ��۵���ʼ�ղ�����ͬ��������á����� GAN �ij����������,ͨ����Ϊģʽ����. ���������������ܹ���ƭ��Ӧ�ļ�����,������ѧϰ��ʾ���ӵ���ʵ�������ݷֲ�,���ұ�����һ�����༫�͵�С�ռ�.
ȱ������ָ��
���ɶԿ����粢���������������õķ��Ժ���,����֪ͨ����ѵ������. ���û��һ���õ�����ָ��,�����ںڰ��й���һ��. û�кõļ�����Ը��ߺ�ʱֹͣ; û�кܺõ�ָ�����Ƚ϶��ģ�͵�����.
4. ����GAN��ѵ��
(1) ����ƥ��
����ƥ�佨�����Ż���������ʱ��, �ü��������������������Ƿ������ʵ����������ͳ����, Ҳ������ʧ������Ϊ
�O
E
x
��
p
r
(
x
)
[
f
(
x
)
]
?
E
z
��
p
z
(
z
)
[
f
(
G
(
z
)
]
�O
2
2
|E_{x\sim p_r(x)}[f(x)] - E_{z\sim p_z(z)}[f(G(z)]|_2^2
�OEx��pr?(x)?[f(x)]?Ez��pz?(z)?[f(G(z)]�O22?
���� f f f�������κε�������ͳ����, �����ֵ������λ��.
(2)minibatch�б�
ͨ��minibatch�б�,�������ܹ���һ��batch������ѵ�����ݵ�֮��Ĺ�ϵ, �����Ƕ�������ÿ����.
(3) ��ʷƽ��
��ģ�Ͳ�������ʷƽ���͵�ǰģ�Ͳ����IJ���뵽��ʧ����, ������ �O �� ? 1 t �� i �� i �O 2 |\Theta-\frac{1}{t}\sum_i \Theta_i|^2 �O��?t1?��i?��i?�O2, �� \Theta ��Ϊ����. ��������ƽ�������ı仯.
(4) ���߱�ǩƽ��
���ͼ�����ʱ,��Ҫ�ṩ 1 �� 0 ��ǩ,����ʹ�� 0.9 �� 0.1 ������ֵ. ����֤�����Լ�������Ĵ�����.
(5) ��������һ��
������ijһ���̶���batch(��Ϊ�ο�batch)������һ��, �����Dz���ÿ�ε�minibatch. �ο�batch�ڿ�ʼʱѡ��һ��,��������ѵ�������б��ֲ���.
(6) ����
����ǰ�������, ����֪�� p r p_r pr?�� p g p_g pg?�ڸ�ά�ռ䲻�ཻ, ��˿�����Ϊ����ʹ������"��ɢ".
(7) �Էֲ������ƶȲ��ø��õ�ָ��
�������ֲ����ཻʱ,��ͳ����ʧ�������ṩ�������ֵ��