Android实现戴口罩人脸检测和戴口罩识别(附Android源码)
目录
Android实现戴口罩人脸检测和戴口罩识别(附Android源码)
(5) 运行APP闪退:dlopen failed: library "libomp.so" not found
本篇博文是《Pytorch戴口罩人脸检测和戴口罩识别(含训练代码 戴口罩人脸数据集)》续作Android篇,主要分享将Python训练后的戴口罩识别模型移植到Android平台。我们将开发一个简易的、可实时运行的戴口罩人脸检测和戴口罩识别的Android Demo。目前项目开发的戴口罩识别(face-mask recognition)的准确率还挺高的,在resnet50,可以高达99%的准确率,采用轻量化版本MobileNet-v2,准确率也可以高达98.18%左右。
项目将手把手教你将训练好的戴口罩分类识别模型部署到Android平台中,包括如何转为ONNX,TNN模型,并移植到Android上进行部署,实现一个戴口罩识别的Android Demo APP 。APP在普通Android手机上可以达到实时的检测识别效果,CPU(4线程)约30ms左右,GPU约25ms左右 ,基本满足业务的性能需求。
【尊重原创,转载请注明出处】https://blog.csdn.net/guyuealian/article/details/128404379
先展示一下Android版本戴口罩识别Demo效果:?
| 图片测试 | 视频测试 |
 | 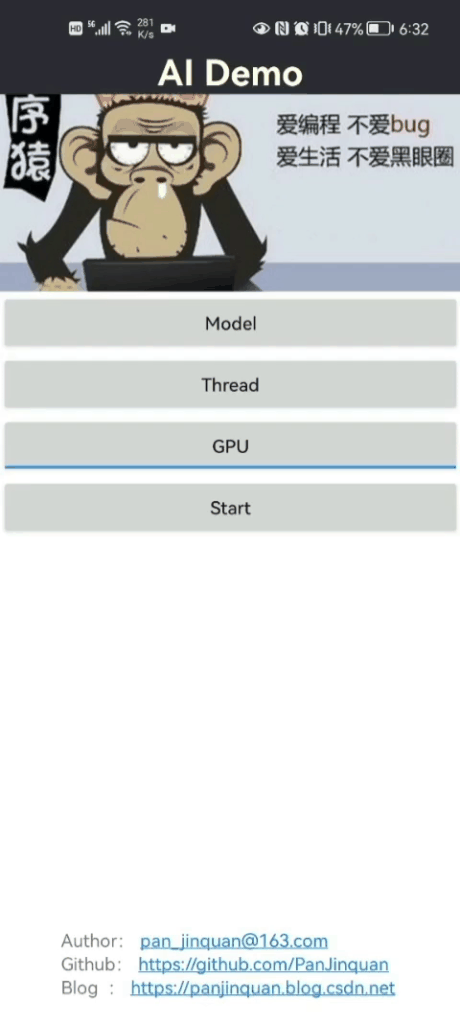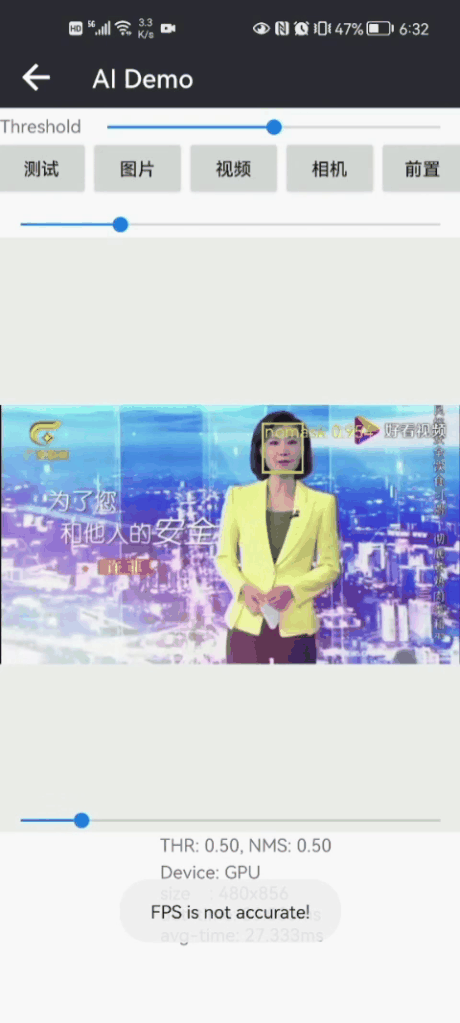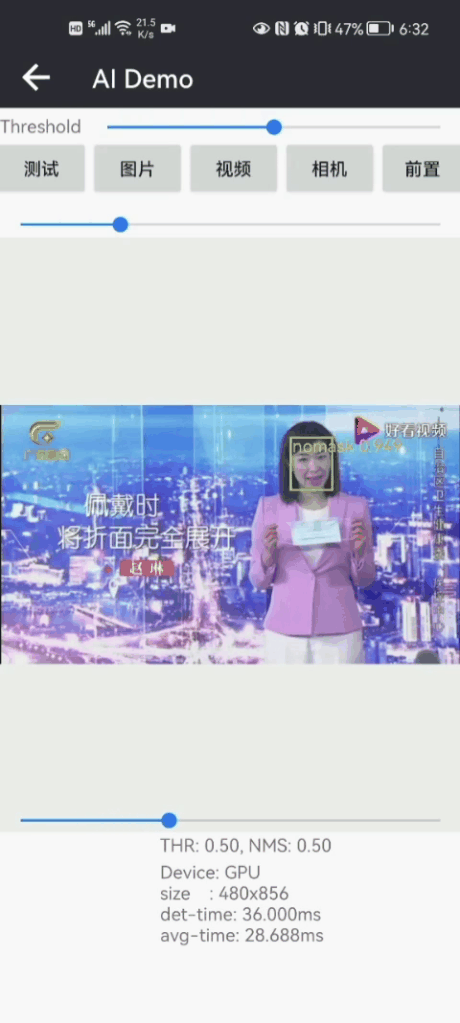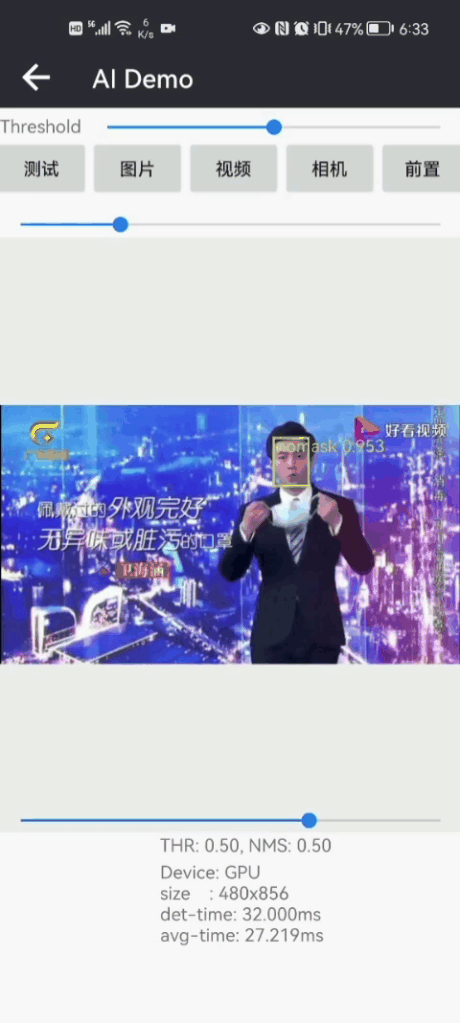 |
Android项目源码下载地址:Android实现戴口罩人脸检测和戴口罩识别(附Android源码)
整套Android项目,包含的资源内容主要有:
- 提供Android版本的人脸检测(支持戴口罩人脸检测)
- 提供戴口罩识别Android Demo源码
- Android Demo在普通手机CPU/GPU上可以实时检测和识别,约30ms左右
- Android Demo支持图片,视频,摄像头测试
戴口罩人脸检测和戴口罩识?别Android Demo APP体检: https://pan.baidu.com/s/1meGv_J6xZiDvXzvXBzNnHA 提取码: 73e5 或者戴口罩人脸检测和戴口罩识别AndroidDemoAPP_口罩识别论文及源代码-Android文档类资源-CSDN下载
1.戴口罩识别的方法
(1)基于多类别目标检测的戴口罩识别方法
基于多类别目标检测的戴口罩识别方法,一步到位,把未戴口罩(nomask)和戴口罩(mask)两个类别直接当成两个目标检测的类别进行训练
- 优点:直接端到端训练,任务简单,速度快
- 缺点:需要人工标注人脸框mask和nomask,时间花费比较大;训练数据不足的情况下,容易出现误检测的情况
(2)基于人脸检测+戴口罩分类识别方法
该方法,先采用通用的人脸检测模型,进行人脸检测,然后裁剪人脸区域,再训练一个戴口罩分类器,对人脸进行分类识别(未戴口罩和戴口罩)
- 优点:不需要标注人脸框数据,可以自己合成戴口罩人脸数据,人工成本低;精度高,可针对分类模型进行轻量化
- 缺点:需要部署两个模型(人脸检测模型和戴口罩分类模型),人脸越多,速度越慢
考虑到数据标注成本的问题,本项目采用第二种方法,即采用基于人脸检测+戴口罩分类识别方法
2.戴口罩人脸数据集
网上绝大部分人脸数据都是不戴口罩的人脸,不能直接用于戴口罩识别中。鉴于此,我们可以考虑自己合成/生成戴口罩的人脸数据,以下是鄙人收藏和整理的戴口罩人脸数据集和合成的数据集,总共约有50000+的数据:
| 原始图片 | 生成戴口罩人脸 |
|
|
|
 ?
? ?
??关于戴口罩人脸数据和生成方法,详细使用说明请参考我的一篇博客《戴口罩人脸数据集和戴口罩人脸生成方法》
| 数据集 | 说明 |
| facemask-train1 |
|
| facemask-train2 |
|
| facemask-train3 |
|
| synthetic-train1 |
|
| synthetic-train2 |
|
| facemask-test |
|
3.戴口罩人脸检测
通常我们理解的人脸检测是指没有遮挡或者只有少许遮挡情况下的人脸检测,当人脸戴有口罩,其检测效果势必会变得比较差,而大量标注带有人脸口罩的人脸数据集还是比较耗时费力的。所以我的方法是:
先在WiderFace人脸数据集上,训练人脸检测;然后在facemask-train1数据集finetune人脸检测模型,经过这个方法训练后,其戴口罩检测效果会好很多。
当然,即使使用开源的人脸检测算法,在带有口罩人脸检测,其实效果也不会太差,比如使用FaceBox,MTCNN检测带有口罩的图片,效果也可以的,只不过会经常出现人脸检测框不完整,存在缺少等问题,对后续的戴口罩的识别有一定的影响。
4.戴口罩识别模型训练
关于训练戴口罩识别模型的方法,请参考本人另一篇博文《Pytorch戴口罩人脸检测和戴口罩识别(含训练代码 戴口罩人脸数据集)》
5.戴口罩识别模型Android部署
(1) 将Pytorch模型转换ONNX模型
训练好Pytorch模型后,你可以将模型转换为ONNX模型,方便后续模型部署
python libs/convert/convert_torch_to_onnx.py"""
This code is used to convert the pytorch model into an onnx format model.
"""
import sys
import os
sys.path.insert(0, os.getcwd())
import torch.onnx
import onnx
from classifier.models.build_models import get_models
from basetrainer.utils import torch_tools
def build_net(model_file, net_type, input_size, num_classes, width_mult=1.0):
"""
:param model_file: 模型文件
:param net_type: 模型名称
:param input_size: 模型输入大小
:param num_classes: 类别数
:param width_mult:
:return:
"""
model = get_models(net_type, input_size, num_classes, width_mult=width_mult, is_train=False, pretrained=False)
state_dict = torch_tools.load_state_dict(model_file)
model.load_state_dict(state_dict)
return model
def convert2onnx(model_file, net_type, input_size, num_classes, width_mult=1.0, device="cpu", onnx_type="default"):
model = build_net(model_file, net_type, input_size, num_classes, width_mult=width_mult)
model = model.to(device)
model.eval()
model_name = os.path.basename(model_file)[:-len(".pth")] + ".onnx"
onnx_path = os.path.join(os.path.dirname(model_file), model_name)
# dummy_input = torch.randn(1, 3, 240, 320).to("cuda")
dummy_input = torch.randn(1, 3, input_size[1], input_size[0]).to(device)
# torch.onnx.export(model, dummy_input, onnx_path, verbose=False,
# input_names=['input'],output_names=['scores', 'boxes'])
do_constant_folding = True
if onnx_type == "default":
torch.onnx.export(model, dummy_input, onnx_path, verbose=False, export_params=True,
do_constant_folding=do_constant_folding,
input_names=['input'],
output_names=['output'])
elif onnx_type == "det":
torch.onnx.export(model,
dummy_input,
onnx_path,
do_constant_folding=do_constant_folding,
export_params=True,
verbose=False,
input_names=['input'],
output_names=['scores', 'boxes', 'ldmks'])
elif onnx_type == "kp":
torch.onnx.export(model,
dummy_input,
onnx_path,
do_constant_folding=do_constant_folding,
export_params=True,
verbose=False,
input_names=['input'],
output_names=['output'])
onnx_model = onnx.load(onnx_path)
onnx.checker.check_model(onnx_model)
print(onnx_path)
if __name__ == "__main__":
net_type = "mobilenet_v2"
width_mult = 1.0
input_size = [128, 128]
num_classes = 2
model_file = "work_space/mobilenet_v2_1.0_CrossEntropyLoss/model/best_model_022_98.1848.pth"
convert2onnx(model_file, net_type, input_size, num_classes, width_mult=width_mult)
(2) 将ONNX模型转换为TNN模型
目前CNN模型有多种部署方式,可以采用TNN,MNN,NCNN,以及TensorRT等部署工具,鄙人采用TNN进行Android端上部署:
- (1)将ONNX模型转换为TNN模型,请参考TNN官方说明:TNN/onnx2tnn.md at master ・ Tencent/TNN ・ GitHub
- (2)一键转换,懒人必备:一键转换 Caffe, ONNX, TensorFlow 到 NCNN, MNN, Tengine? ?(版本问题,这个工具转换的TNN模型可能不兼容,建议还是自己build源码进行转换)
(3) Android端上部署戴口罩识别
项目实现了Android版本的戴口罩识别Demo,部署框架采用TNN,支持多线程CPU和GPU加速推理,在普通手机上可以实时处理。戴口罩识别Android源码,核心算法均采用C++实现,上层通过JNI接口调用.
如果你想在这个Android Demo部署你自己训练的分类模型,你可将训练好的Pytorch模型转换ONNX ,再转换成TNN模型,然后把TNN模型代替你模型即可。
- 戴口罩人脸检测和戴口罩识别JNI接口 ,Java部分
package com.cv.tnn.model;
import android.graphics.Bitmap;
public class Detector {
static {
System.loadLibrary("tnn_wrapper");
}
/***
* 初始化人脸检测和戴口罩识别模型
* @param face_model: 人脸检测模型(不含后缀名)
* @param class_model:戴口罩识别模型(不含后缀名)
* @param root:模型文件的根目录,放在assets文件夹下
* @param model_type:模型类型
* @param num_thread:开启线程数
* @param useGPU:关键点的置信度,小于值的坐标会置-1
*/
public static native void init(String face_model, String class_model, String root, int model_type, int num_thread, boolean useGPU);
/***
* 人脸检测和戴口罩识别
* @param bitmap 图像(bitmap),ARGB_8888格式
* @param score_thresh:置信度阈值
* @param iou_thresh: IOU阈值
* @return
*/
public static native FrameInfo[] detect(Bitmap bitmap, float score_thresh, float iou_thresh);
}
- 戴口罩人脸检测和戴口罩识别JNI接口 ,C++部分
#include <jni.h>
#include <string>
#include <fstream>
#include "src/object_detection.h"
#include "src/classification.h"
#include "src/Types.h"
#include "debug.h"
#include "android_utils.h"
#include "opencv2/opencv.hpp"
#include "file_utils.h"
using namespace dm;
using namespace vision;
static ObjectDetection *detector = nullptr;
static Classification *classifier = nullptr;
JNIEXPORT jint JNI_OnLoad(JavaVM *vm, void *reserved) {
return JNI_VERSION_1_6;
}
JNIEXPORT void JNI_OnUnload(JavaVM *vm, void *reserved) {
}
extern "C"
JNIEXPORT void JNICALL
Java_com_cv_tnn_model_Detector_init(JNIEnv *env,
jclass clazz,
jstring face_model,
jstring class_model,
jstring root,
jint model_type,
jint num_thread,
jboolean use_gpu) {
if (detector != nullptr) {
delete detector;
detector = nullptr;
}
std::string parent = env->GetStringUTFChars(root, 0);
std::string face_model_ = env->GetStringUTFChars(face_model, 0);
std::string class_model_ = env->GetStringUTFChars(class_model, 0);
string face_model_file = path_joint(parent, face_model_ + ".tnnmodel");
string face_proto_file = path_joint(parent, face_model_ + ".tnnproto");
string class_model_file = path_joint(parent, class_model_ + ".tnnmodel");
string class_proto_file = path_joint(parent, class_model_ + ".tnnproto");
DeviceType device = use_gpu ? GPU : CPU;
LOGW("parent : %s", parent.c_str());
LOGW("useGPU : %d", use_gpu);
LOGW("device_type: %d", device);
LOGW("model_type : %d", model_type);
LOGW("num_thread : %d", num_thread);
ObjectDetectionParam model_param = FACE_MODEL;
detector = new ObjectDetection(face_model_file,
face_proto_file,
model_param,
num_thread,
device);
ClassificationParam ClassParam = FACE_MASK_MODEL;
ClassParam.input_width = 112;
ClassParam.input_height = 112;
ClassParam.use_rgb = true; //
classifier = new Classification(class_model_file,
class_proto_file,
ClassParam,
num_thread,
device);
}
extern "C"
JNIEXPORT jobjectArray JNICALL
Java_com_cv_tnn_model_Detector_detect(JNIEnv *env, jclass clazz, jobject bitmap,jfloat score_thresh, jfloat iou_thresh) {
cv::Mat bgr;
BitmapToMatrix(env, bitmap, bgr);
int src_h = bgr.rows;
int src_w = bgr.cols;
// 检测区域为整张图片的大小
FrameInfo resultInfo;
// 开始检测
if (detector != nullptr) {
detector->detect(bgr, &resultInfo, score_thresh, iou_thresh);
} else {
ObjectInfo objectInfo;
objectInfo.x1 = 0;
objectInfo.y1 = 0;
objectInfo.x2 = 84;
objectInfo.y2 = 84;
objectInfo.label = 0;
resultInfo.info.push_back(objectInfo);
}
int nums = resultInfo.info.size();
LOGW("object nums: %d\n", nums);
if (nums > 0) {
// 开始检测
classifier->detect(bgr, &resultInfo);
// 可视化代码
printf("sitting label:%d,score:%3.5f", resultInfo.label, resultInfo.score);
//classifier->visualizeResult(bgr, &resultInfo);
}
//cv::cvtColor(bgr, bgr, cv::COLOR_BGR2RGB);
//MatrixToBitmap(env, bgr, dst_bitmap);
auto BoxInfo = env->FindClass("com/cv/tnn/model/FrameInfo");
auto init_id = env->GetMethodID(BoxInfo, "<init>", "()V");
auto box_id = env->GetMethodID(BoxInfo, "addBox", "(FFFFIF)V");
auto ky_id = env->GetMethodID(BoxInfo, "addKeyPoint", "(FFF)V");
jobjectArray ret = env->NewObjectArray(resultInfo.info.size(), BoxInfo, nullptr);
for (int i = 0; i < nums; ++i) {
auto info = resultInfo.info[i];
env->PushLocalFrame(1);
//jobject obj = env->AllocObject(BoxInfo);
jobject obj = env->NewObject(BoxInfo, init_id);
// set bbox
//LOGW("rect:[%f,%f,%f,%f] label:%d,score:%f \n", info.rect.x,info.rect.y, info.rect.w, info.rect.h, 0, 1.0f);
env->CallVoidMethod(obj, box_id, info.x1, info.y1, info.x2 - info.x1, info.y2 - info.y1,
info.category.label, info.category.score);
// set keypoint
for (const auto &kps : info.landmarks) {
//LOGW("point:[%f,%f] score:%f \n", lm.point.x, lm.point.y, lm.score);
env->CallVoidMethod(obj, ky_id, (float) kps.x, (float) kps.y, 1.0f);
}
obj = env->PopLocalFrame(obj);
env->SetObjectArrayElement(ret, i, obj);
}
return ret;
}
(4) Android测试效果?
Android Demo在普通手机CPU/GPU上可以达到实时检测和识别效果;CPU(4线程)约30ms左右,GPU约25ms左右 ,基本满足业务的性能需求。
戴口罩人脸检测和戴口罩识别Android Demo APP体检:https://pan.baidu.com/s/1meGv_J6xZiDvXzvXBzNnHA 提取码: 73e5 或者戴口罩人脸检测和戴口罩识别AndroidDemoAPP_口罩识别论文及源代码-Android文档类资源-CSDN下载
| 图片测试 | 视频测试 |
| |
(5) 运行APP闪退:dlopen failed: library "libomp.so" not found
参考解决方法:
解决dlopen failed: library “libomp.so“ not found_PKing666666的博客-CSDN博客_dlopen failed
6.项目源码下载
Android项目源码下载地址:Android实现戴口罩人脸检测和戴口罩识别(附Android源码)
整套Android项目源码内容包含:
- 提供Android版本的人脸检测(支持戴口罩人脸检测)
- 提供戴口罩识别Android Demo源码
- Android Demo在普通手机CPU/GPU上可以实时检测和识别,约30ms左右
- Android Demo支持图片,视频,摄像头测试
戴口罩人脸检测和戴口罩识别Android Demo APP体检:https://pan.baidu.com/s/1meGv_J6xZiDvXzvXBzNnHA 提取码: 73e5 或者戴口罩人脸检测和戴口罩识别AndroidDemoAPP_口罩识别论文及源代码-Android文档类资源-CSDN下载