写在前面
笔者目前就读的专业是软件工程,并非人工智能专业,但是由于对人工智能有兴趣,于是课下进行了一些自学。正巧最近有些闲暇时间,就想着使用自学的内容做个小型的实战。这篇文章的主要目的也就是从一个入门者的角度,去记录一下这整个流程,顺便也分享一下自己的心得体会。(这里就假定读者都是有一定的深度学习基础了,一些简单的概念,例如k折交叉验证,就不再具体阐述了)
参考资料采用的是沐神的《动手深度学习》,谷歌一下就能找到这本书的pdf版本
需求分析
在b站上有很多视频,每个视频都会有一个封面,笔者希望能训练出一个模型,这个模型可以帮我们在一大堆视频中找到关于猫的视频。具体而言,就是将封面图片作为输入,将封面中含有猫的确信度作为输出,如果确信度大于50%就认为这个封面里面有猫,从而判断这个视频是和猫相关的。这就相当于一个另类的内容推荐系统了,从一大堆视频中找到自己感兴趣的视频,就是这个模型的实用价值。
准备数据集
数据集是深度学习实战中非常重要而且困难的一个环节,通常在教学中,我们都是使用现成的数据集,来进行模型的训练,例如在CNN教学中最经典的数据集Fashion-MNIST。真正开始自己DIY数据集的时候,摆在我们面前的难题就有2个:
-
如何选择负例数据?
这个问题确实困扰了作为入门者的笔者一段时间,因为正例非常好找,只需要找一大堆包含猫的图片即可,但是负例呢?只需要不包含猫的图片都行吗?如果是的话,那一大堆纯色图也可以作为负例吗?
在使用教学用的数据集,例如Fashion-MNIST时,我们并没有思考这个问题,因为Fashion-MNIST中的数据只有10个特征都很鲜明的类别,例如,如果我们想要判断一张图是不是衬衫,表面上我们做的事是训练模型来得出 这张图是衬衫 和 这张图不是衬衫 的可信度,但实际上我们做的事是,训练模型来得出 这张图是衬衫 和 这张图是大衣,凉鞋,…等另外9个类别物品 的可信度,但如果按照这样的思路,那我们在找负例的时候,是不是需要穷举所有图片中不包含猫的情况?例如一些包含狗的图片,一些包含汽车的图片…,如果是这样的话,那就不具备可操作性了,因为工作量太大了。
笔者翻了大量资料,也没有这方面的回答,如果读者对这个问题有所了解,还恳请在评论区赐教。
最终笔者采取了一个比较妥协的方法,就是在b站里面随机找视频,然后保存封面作为负例,在获取了一定量的封面后,笔者再进行人工筛选,剔除掉包含猫的图片。 -
如何获取到大量的图片?
这一点就比较简单了,只需要使用python爬虫,来爬取b站视频封面即可,具体代码由于可能涉及到版权问题,就不放出来了。
需要注意的一点是,这一步还需要在下载图片后对图片进行缩放,因为之后输入模型的图片的大小都是统一的大小,这里笔者设定的大小是240x240。
处理图片可以使用opencv-python库,安装方法为pip install opencv-python,图片的下载和缩放可以用下面的代码解决(可以稍微注意一下,opencv中读入的图片是以numpy中的ndarray的形式保存的)
def save_img(url,path):
#Download image
res = requests.get(url)
img = res.content
with open(path, "wb") as f:
f.write(img)
print("Downloaded " + path)
#Resize image
img = cv2.imread(path)
img = cv2.resize(img, dsize=(240, 240), fx=1, fy=1, interpolation=cv2.INTER_LINEAR)
cv2.imwrite(path, img, [cv2.IMWRITE_JPEG_QUALITY, 100])
print("Processed " + path)
搭建模型
接下来就正式的写深度学习代码了,笔者使用的框架是pytorch
最开始搭建的模型的网络结构参考了著名的LeNet,也就是最开始使用卷积神经网络进行手写数字识别的网络,具体网络结构如下
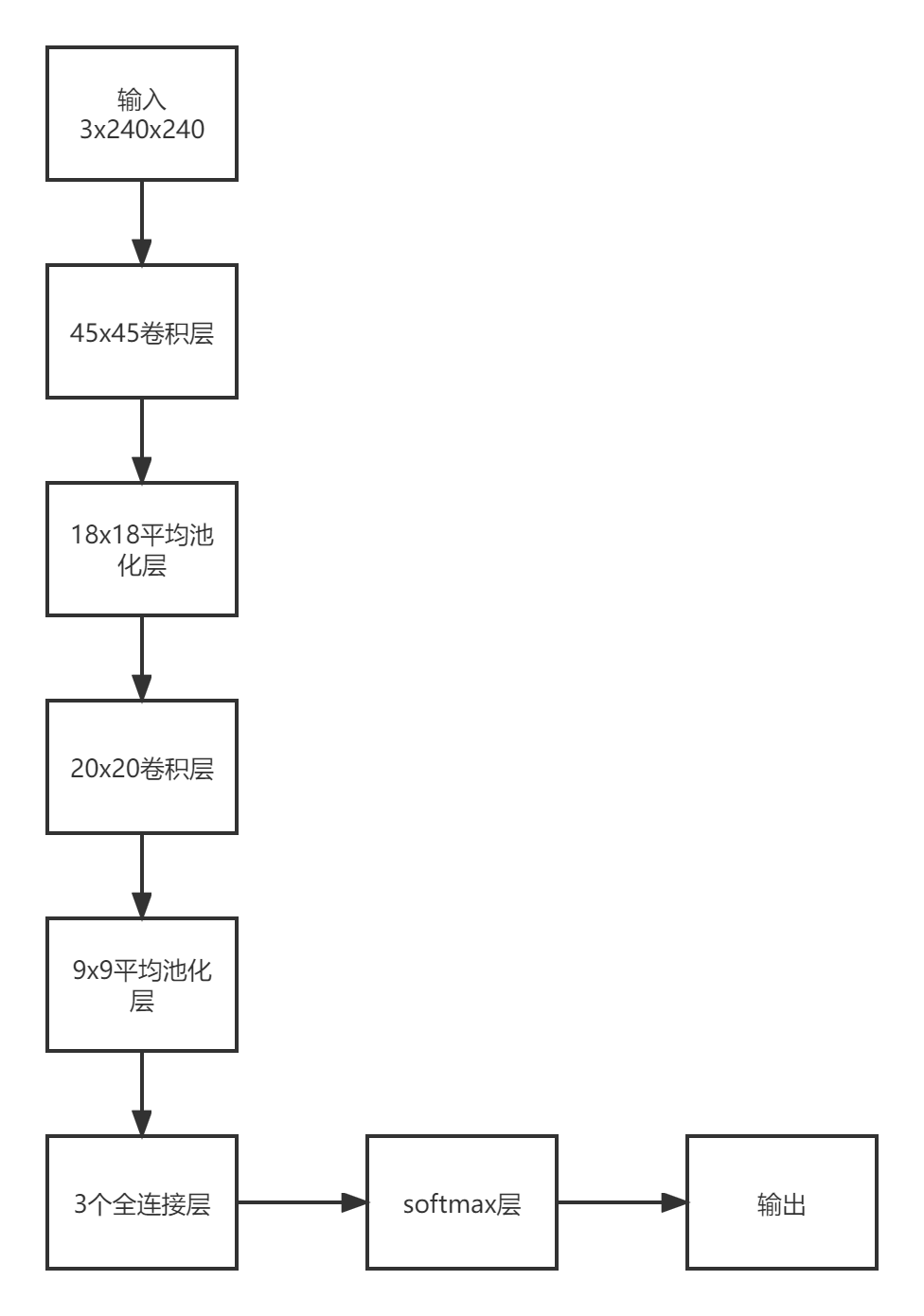
激活函数均使用的ReLU,代码表现为
def get_net():
return nn.Sequential(
nn.Conv2d(3, 6, kernel_size=45), nn.ReLU(),
nn.AvgPool2d(kernel_size=18, stride=2),
nn.Conv2d(6, 9, kernel_size=20), nn.ReLU(),
nn.AvgPool2d(kernel_size=9, stride=2),
nn.Flatten(),
nn.Linear(9216, 544), nn.ReLU(),
nn.Linear(544, 68),nn.ReLU(),
nn.Linear(68, 2), nn.Softmax()
).to(device)
整个项目的完整代码如下
import random
import torch
from torch import nn
from matplotlib import pyplot as plt
import numpy as np
import cv2
import os
from my_dataset import get_dataloader
device="cuda"
img_size=240
def read_img_to_numpy(img_path):
img = cv2.imread(img_path)/128 #为了进行归一化
img = np.concatenate(
(img[:, :, 0].reshape((1, img_size, img_size)), img[:, :, 1].reshape((1, img_size, img_size)), img[:, :, 2].reshape((1, img_size, img_size))),
axis=0)
return img
def read_all_img():
positive_dir="samples/positive/"
negative_dir="samples/negative/"
features=None
labels=[]
names=[positive_dir+name for name in os.listdir(positive_dir)]+[negative_dir+name for name in os.listdir(negative_dir)]
indexes=list(range(len(names)))
random.shuffle(indexes)
for index in indexes:
name=names[index]
if positive_dir in name:
label=1
else:
label=0
labels.append(label)
img = read_img_to_numpy(name).reshape(1, 3, img_size, img_size)
img = torch.tensor(img,dtype=torch.float32, device=device)
if features is None:
features=img
else:
features=torch.concat((features,img))
labels=torch.tensor(labels,dtype=torch.int64,device=device)
return features,labels
def get_net():
return nn.Sequential(
nn.Conv2d(3, 6, kernel_size=45), nn.ReLU(),
nn.AvgPool2d(kernel_size=18, stride=2),
nn.Conv2d(6, 9, kernel_size=20), nn.ReLU(),
nn.AvgPool2d(kernel_size=9, stride=2),
nn.Flatten(),
nn.Linear(9216, 544), nn.ReLU(),
nn.Linear(544, 68),nn.ReLU(),
nn.Linear(68, 2), nn.Softmax()
).to(device)
def eval_accuracy(net,test_iter):
total=0
accurate=0
for X,y in test_iter:
y_hat=net(X).argmax(axis=1)
e=(y==y_hat)
accurate+=e.sum()
total+=len(X)
return accurate/total
def train_for_k_fold(net,train_iter,test_iter,lr,epochs,fold):
def init_weights(m):
if type(m)==nn.Linear or type(m)==nn.Conv2d:
nn.init.xavier_uniform_(m.weight)
net.apply(init_weights)
optimizer=torch.optim.Adam(net.parameters(),lr=lr)
loss=nn.CrossEntropyLoss()
loss_record=[]
accuracy_record=[]
for epoch in range(epochs):
net.train()
for X,y in train_iter:
optimizer.zero_grad()
y_hat=net(X)
l=loss(y_hat,y)
l.backward()
optimizer.step()
loss_record.append(l.to("cpu").detach().numpy())
accuracy=eval_accuracy(net,test_iter)
accuracy_record.append(accuracy.to("cpu").detach().numpy())
print(f"Epoch {epoch}, loss {l}, accuracy {accuracy}")
#plot
print(f"Loss {loss_record}")
print(f"Accuracy {accuracy_record}")
epoch=np.arange(len(loss_record))
plt.title(f"fold {fold} lr {lr}, epochs {epochs}")
plt.plot(epoch,np.array(loss_record),label="Loss")
plt.plot(epoch,np.array(accuracy_record),label="Accuracy")
plt.legend()
plt.savefig(f"fold_{fold}_lr_{lr}_epochs_{epochs}.png")
def k_fold(k=4,lr=0.9,epochs=10,batch_size=3):
features, labels = read_all_img()
total_len = len(features)
fold_len = int(total_len / k)
for fold in range(k):
print(f"Start fold {fold}")
test_start = fold_len * fold
test_end = min((fold + 1) * fold_len, total_len)
test_features = features[test_start:test_end]
test_labels = labels[test_start:test_end]
train_features = torch.concat((features[:test_start], features[test_end:]))
train_labels = torch.concat((labels[:test_start], labels[test_end:]))
train_iter=get_dataloader(train_features,train_labels,batch_size)
test_iter=get_dataloader(test_features,test_labels,batch_size)
net = get_net()
train_for_k_fold(net, train_iter, test_iter, lr, epochs,fold)
#save net
torch.save(net.state_dict(),f"fold_{fold}.params")
k_fold(lr=1,epochs=100,batch_size=10)
其中,my_dataset.py这个工具文件的代码如下
import torch
from torch.utils import data
class ArrayDataset(data.Dataset):
def __init__(self,features,labels):
self.features=features
self.labels=labels
def __getitem__(self, item):
return self.features[item],self.labels[item]
def __len__(self):
return len(self.features)
def get_dataloader(features,labels,batch_size,device="cuda"):
if not torch.is_tensor(features):
features=torch.tensor(features,dtype=torch.float32,device=device)
labels=torch.tensor(labels,dtype=torch.int64,device=device)
return data.DataLoader(ArrayDataset(features,labels),batch_size,shuffle=True)
上面的代码实现的功能主要是做k折交叉验证来帮助我们寻找合适的超参数,正式的训练代码只需要在这基础上简单的改动即可,这里就不放出来了
训练模型
在训练模型阶段,笔者遇到了各种各样的问题,这也是整个过程中最折腾的部分
问题1:显卡显存不足
之前我们使用的模型和数据集都非常简单,所以2G的GTX1050完全能够胜任,但如今数据量是之前的几十倍,一运行起来,数据还没有全部加载完成,就报了显存不足,如下图所示

这个时候就只能去网上租借GPU服务器了,笔者找到个平台,注册就送10元代金券,目前总共花费了10.3元,其中10元还是平台提供的代金券抵扣的,而且这个平台的计费方式是按使用时长计费,也就是开机时计费,关机后数据会保留,但是不会计费,这对于我们这种只需要短时间使用GPU的学生是非常划算的。为了避免有打广告的嫌疑,平台具体的名字就不放出来了,如果大家有兴趣可以私信笔者
至此,显存不足的问题算是解决了,写到这里,有了一点感悟,这也是沐神在书中提到的一点,早期人工智能领域的发展速度没有当今快,有一个很大的原因就是硬件资源不足。在2000年左右,可能一块2GB显存的显卡都是很贵的硬件,但是后面跑AlexNet至少也需要20GB的显存,所以可见在早期时候,像AlexNet之类的网络,即使能够实现,也很难展开运算
问题2:模型对所有样本的输出相同
相信这是初学者都会碰到的情况,就是无论输入是什么,模型最终的输出都是一样的
具体回到我们这个实战,在训练过程中,我发现每一个epoch的准确率都是相等的,这显然很异常,所以我修改了一下代码,在eval_accuracy函数处做了如下修改
# y_hat=net(X).argmax(axis=1)
y_hat=net(X)
print(y_hat)
y_hat=y_hat.argmax(axis=1)
这段代码的目的就是为了打印出y_hat,也就是输入为正例和负例的确信度,也就是softmax层的输出
结果输出很奇怪,所有的输出都是一样的,就像下面这张图中的结果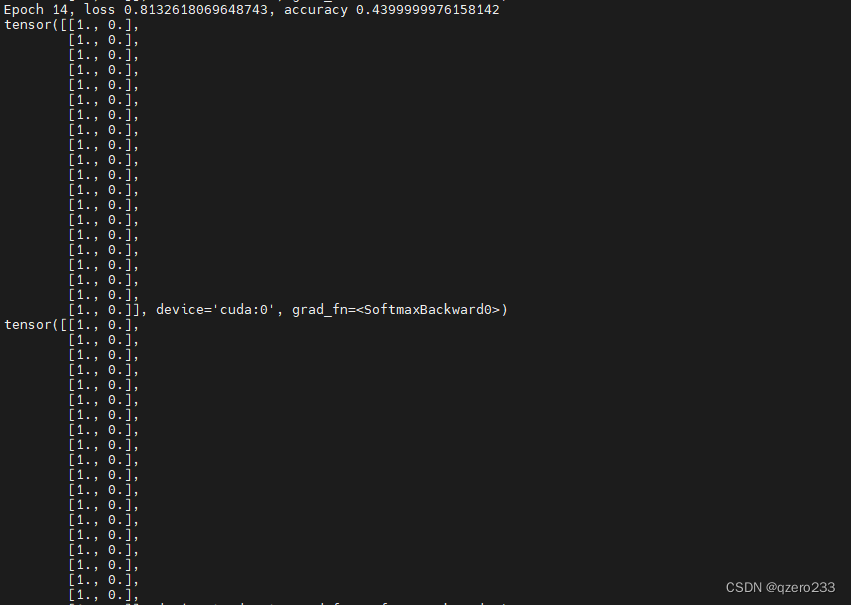
有了上次处理Dead ReLU的经验,这次可以基本确定是学习率太大了,所以尝试把学习率调到1e-3,但是还是一样的结果,最后把学习率调到1e-8,终于不再是清一色的0和1了,但是收敛速度还是略慢,所以继续调高学习率,最终确定为1e-5是个比较合适的值,可以看到,调为1e-5后,输出就正常了
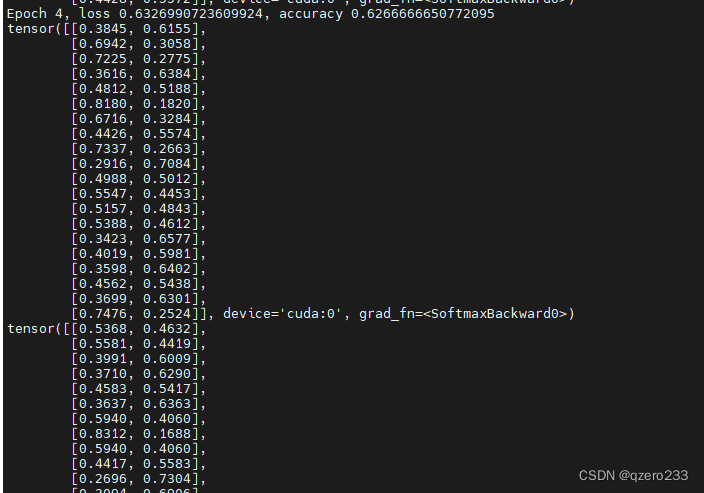
从这里可以总结出的一个经验就是,遇到输出全部一样的情况,尽管把学习率往小调,直到输出正常,然后再逐步往大调,来提高学习速率,同时需要先解决欠拟合,再考虑解决过拟合
训练结果
最终k折交叉验证的结果如下图(就只取第一个fold的结果展示了,另外3个fold也是类似的)
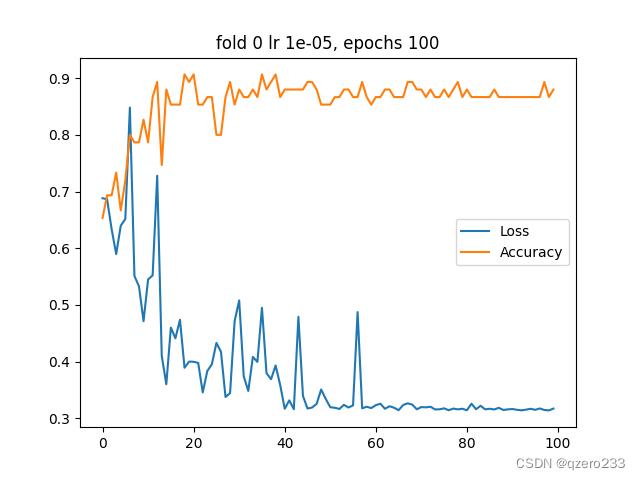
最终测试下来,准确率在80%左右,这已经基本达到我的预期了,因为至少这是一个能用的模型了
模型改进
后面笔者也尝试通过更改优化器,学习率,学习周期等方法来增加准确率,但是都没能成功
推测一方面是数据集不够多,例如一张图片里的内容是一个楼梯,但是反例中并没有出现楼梯,所以就会造成反例的确信度降低
另一方面,这个可能是这个网络结构的上限就是如此了,所以我们或许可以通过更改网络结构来提高准确率
其中扩增数据集的工作量较大,而且效果不显著,所以就不再考虑了,这里主要尝试通过修改网络结构来提高准确率
新的网络结构参考了沐神书中提到的AlexNet
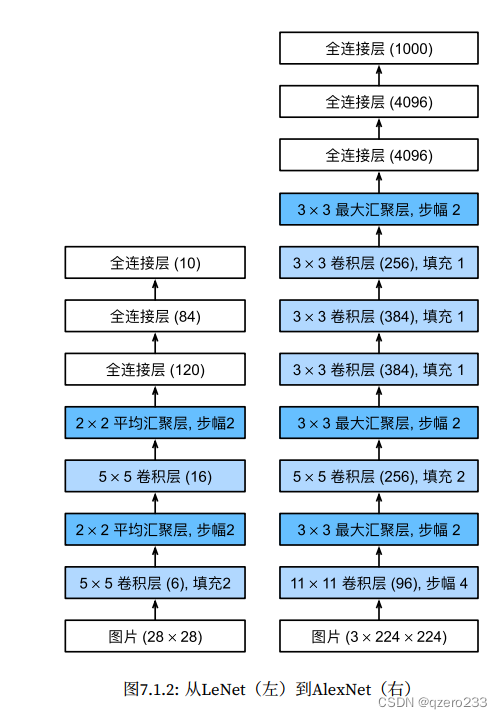
具体代码实现为,将get_net函数修改为如下
def get_net():
return nn.Sequential(
nn.Conv2d(3, 96, kernel_size=11,stride=4,padding=1), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(96, 256, kernel_size=5,padding=2), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(256,384,kernel_size=3,padding=1),nn.ReLU(),
nn.Conv2d(384, 384, kernel_size=3, padding=1), nn.ReLU(),
nn.Conv2d(384, 256, kernel_size=3, padding=1), nn.ReLU(),
nn.MaxPool2d(kernel_size=3,stride=2),
nn.Flatten(),
nn.Linear(9216, 4096), nn.ReLU(),
nn.Dropout(p=0.5),
nn.Linear(4096, 4096), nn.ReLU(),
nn.Dropout(p=0.5),
nn.Linear(4096, 2), nn.Softmax()
).to(device)
可以看到,这个网络结构更为复杂了,所以需要的显存也更大了,在实际测试中,10GB的RTX3080已经顶不住了,需要换上24GB的RTX3090来进行训练,最终训练出的模型在测试数据集中的表现达到了87%
其实这并不奇怪,更多的网络参数就意味着这个模型的拟合能力更强,但同时过拟合的可能性也越大,这也是需要我们去权衡的一个trade off
写在最后
这是笔者第一次进行人工智能方向的实战,能做出成果,自然是非常开心的。在这过程中,最深的感悟有两点:
- 数据为王
虽然深度学习不需要像早起机器学习一样,去精心处理数据,但是大量且合理的数据仍然是有必要的,还记得在kaggle上做过一个数字识别的题目,当时kaggle给出的训练数据集中包含了40000个,即使是使用比较简单的LeNet,也能做到91%的识别准确率,所以可见,如果增大数据量,这个模型是有进步空间的 - 硬件决定上限
前面也提到过了,在人工智能发展的早期,硬件资源制约了这个领域的发展。在那个显卡显存可能只有512MB的时代,如果要跑AlexNet这种光是模型参数都有221MB的模型,应该是非常困难的
最后,这篇文章中可能有一些错误或者描述不清的地方,欢迎大家在评论区里批评指正,也欢迎大家在评论区进行探讨与交流