写在前面
时空预测是很多领域都存在的问题,不同于时间序列,时空预测不仅需要探究时间的变化,也需要关注空间的变化。许多预测问题都只片面的关注时间问题,如预测某人未来3年患某种病的概率,食堂就餐人数等,往往忽视了空间问题,如作为决策者,我不仅想知道明天患新冠的人数,而且想知道这些人会在哪些位置发病,以便精准管理。换句话说,决策者更多关注的是人群层面,而干预和施控是工作人员主要关注的问题。空间问题能够解答众多人对于预测问题最后的疑问,既:事件A可能会发生,那它会在哪里发生?
近些年关于时空预测的问题不断刺激着机器学习领域的科学家和学者,有别于传统统计学时空预测模型,机器学习或深度学习已经展现了其强大的优势:非线性拟合、高维数据的处理能力、较少担心变量共线性对模型的影响等。目前,通过长短期记忆网络LSTM和卷积神经网络CNN分别提取时间和空间特征来实现时空预测已经成为了可能,本文主要基于2015年发表在arxiv平台上的一篇building block文章《Convolutional LSTM Network: A Machine Learning Approach for Precipitation Nowcasting》来实现时空预测的经典问题――下一帧视频预测,当然,其他机器学习时空预测模型和时空预测问题不在本文讨论范围内,有兴趣的同学可以自行尝试。
一、时空预测
很多问题都可以尝试时空预测,如新冠疫情发病,交通流量、天气预报、慢性病区域发病风险预测等,空间可以被时间切分为无数个2维图片,这样用CNN来提取图片中的信息,用LSTM来处理时序问题,便能很好的解决时空预测问题,如下图所示。注意,与普通的LSTM不同,时空预测在其他维度上仍有位置变化,这是空间的体现。

关于论文中提到ConvLSTM的公式原理,在很多博客上都有详细论述,这里不再过多介绍,有兴趣的同学可以自己在网络上查看或者查看原文献的解读。
二、数据集的选取和下载
和论文中一样,我们也选取Moving-MNIST数据集,既移动MNIST数据集,该公开数据集可以在多伦多大学提供的网站上下载,Moving-MNIST数据集是时空预测常用的数据集之一,数据集下载代码如下:
import numpy as np
from tensorflow import keras
fpath = keras.utils.get_file(
"moving_mnist.npy",
"http://www.cs.toronto.edu/~nitish/unsupervised_video/mnist_test_seq.npy",
)
dataset = np.load(fpath)
print(dataset.shape)
下载好数据集后,我们输出数据集的shape,结果为(20, 10000, 64, 64),表示一个seq有二十个图片,前十帧为input,后十帧为target,一共有10000个sequence,每个图片的大小为64?64,如下图所示:

三、数据集预处理与数据集划分
由于我们的ConvLSTM接受的输入是(sanmples,seq,wide,height,channel),因此我们要把数据集进行改造以符合模型的输入要求。
# 转换数据集的seq和samples维度,便于输入我们的模型
dataset = np.swapaxes(dataset, 0, 1)
# 10000个样本太多,我们只选取1000个
dataset = dataset[:1000, ...]
# 我们此时是二维灰度图片,因此要增加一维,代表单通道,如果是彩色,则为3
dataset = np.expand_dims(dataset, axis=-1)
print(dataset.shape)
转换后数据集的shape为(1000,20,64,64,1)已经符合模型的输入要求,接下来是划分数据集,这里要打乱索引,实现随机划分训练集和测试集。
indexes = np.arange(dataset.shape[0])
np.random.shuffle(indexes) # 打乱索引顺序
# 训练集:测试集=9:1
train_index = indexes[: int(0.9 * dataset.shape[0])]
val_index = indexes[int(0.9 * dataset.shape[0]):]
train_dataset = dataset[train_index]
val_dataset = dataset[val_index]
print(train_dataset.shape)
print(val_dataset.shape)
划分好数据集后我们通过除以255实现归一化,归一化要在划分数据集之后完成,不然会导致数据泄露。
# 归一化,除255就是把3基色都调到0-1区间,得到绝对色彩信息
train_dataset = train_dataset / 255
val_dataset = val_dataset / 255
分离x和y,按照论文,我们是前20帧预测后20帧,类似于下图:

代码如下:
# 分离x和y,注意,此时的y是下一帧图像,既最后一个片子,我们用前20帧预测后20帧,既序号0-19
def create_shifted_frames(data):
x = data[:, 0: data.shape[1] - 1, :, :]
y = data[:, 1: data.shape[1], :, :]
return x, y
x_train, y_train = create_shifted_frames(train_dataset)
x_val, y_val = create_shifted_frames(val_dataset)
四、模型构建
# 模型构建核心代码,这里我们修改超参数与keras官方超参数一致
model = Sequential([
keras.layers.ConvLSTM2D(filters=64, kernel_size=(5, 5),
input_shape=(None, 64, 64, 1),
padding='same', return_sequences=True),
keras.layers.BatchNormalization(),
keras.layers.ConvLSTM2D(filters=64, kernel_size=(3, 3),
padding='same', return_sequences=True),
keras.layers.BatchNormalization(),
keras.layers.ConvLSTM2D(filters=64, kernel_size=(1, 1),
padding='same', return_sequences=True),
keras.layers.Conv3D(filters=1, kernel_size=(3, 3, 3),
activation='sigmoid',
padding='same', data_format='channels_last')
])
model.compile(loss='binary_crossentropy', optimizer='adadelta')
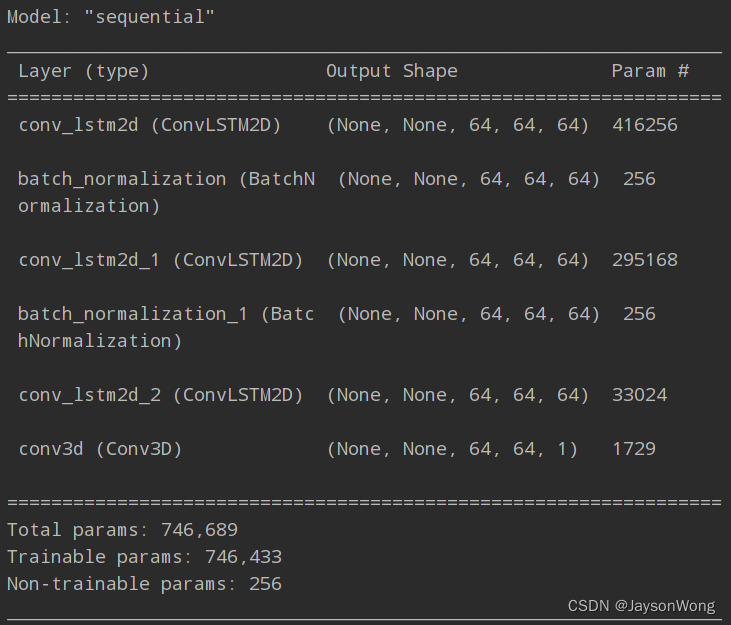
model.summary()
模型结构如下:
五、模型训练
构建好模型后,我们开始训练,本人电脑显卡为GTX1660ti ,显存6G,显存有限,因此把batch size调小一些,并适当增大一些epoch,如果算力允许,可以增大epoch和batch size。这里定义了早期终止训练和调整学习率回调函数,因此无需担心无效训练时间增加问题。
# 定义回调
early_stopping = keras.callbacks.EarlyStopping(monitor="val_loss", patience=10)
reduce_lr = keras.callbacks.ReduceLROnPlateau(monitor="val_loss", patience=5)
# 设置训练参数
epochs = 50
batch_size = 2
# 拟合模型.
model.fit(
x_train,
y_train,
batch_size=batch_size,
epochs=epochs,
validation_data=(x_val, y_val),
callbacks=[early_stopping, reduce_lr],
)
model.save('model.h5')
六、结果查看

与自然语言处理不同,时空预测不能单纯对比accuracy、F1-score这些指标,要对比预测结果和实际的差别。从结果来看,我们预测结果比较模糊,因此,考虑改用adam优化和调整卷积核的个数至30个以及epoch改为15,结果如下:
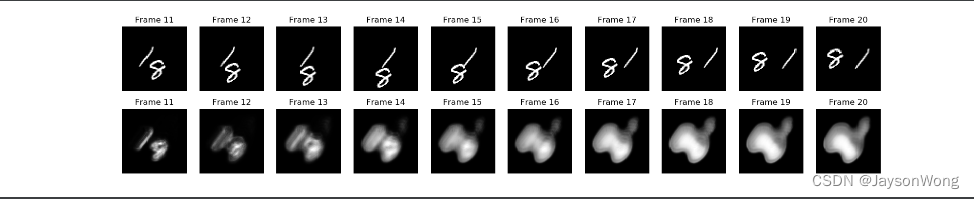
从效果来看,略微有所提升,验证集损失在0.0244,继续增加epoch发现尽管验证集上的cost function在不断减小,但图像效果又变差了,和论文中图像一样,效果可以看到还是依然很差的,说实话这个想做好确实难度很高,因为数字在图中极度的非线性运动,很难全部学到运动的规则,就算是学到了,单个字的空间信息可能也会丢失,所以越往后效果越差。
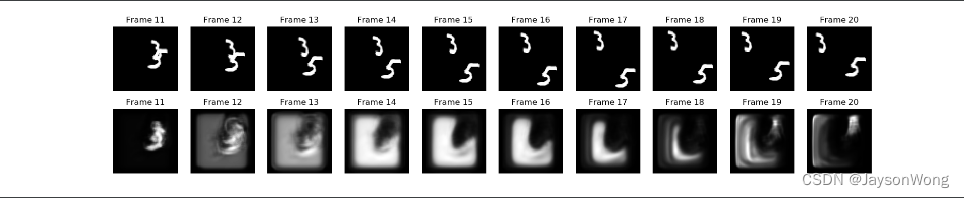
查看了一些博主的解决方法,有提示改用SSIM(结构相似度)损失函数的,有建议减小学习率的,有建议用反卷积的等等,但深度学习本身就是一个“炼丹“的过程,无非就是增加一些卷积核,或者增加减少一些卷积层,ConvLSTM在本次任务中本质是图像生成,图像生成的超参数调整是比较敏感的,由于本人未安装tensorflow_contrib库,无法使用SSIM损失函数,后续如有新的进展,将第一时间发出来。
七、总结
目前来讲,空间统计学在医疗领域的运用是较为普遍的,特别是传染病和环境暴露因素的研究中,时常能看到论文作者使用时空统计模型,而ConLSTM的诞生和近些年来的改进能够推动基于机器学习的时空预测模型在传染病和环境暴露因素研究中的应用,除此之外,ConvLSTM甚至能够分析患者的视频数据,如步态或者某区域慢性病风险矩阵图等,这些领域依旧空白,我相信,AI的助力能够推动这些领域的蓬勃发展。