前排提示
这是我补充的内容,仅代表个人观点,和作者本人无关。
主要是意译+我的补充,想看原文表达的拖到最底下有链接。
原文翻译
在科技界我们可以看到很多关于GPT-3的新闻。大型语言模型(比如GPT-3)已经展示出让我们惊讶的性能。虽然对于大部分企业来说想让GPT-3落地还是比较困难的,这些功能不完全可靠的模型还是不能摆到用户面前的,但是这些大模型的出现展示出了加速自动化进程和智能计算机系统的前景。接下来让我们扒一扒GPT-3,看一看它神秘光环背后是如何训练和工作的。
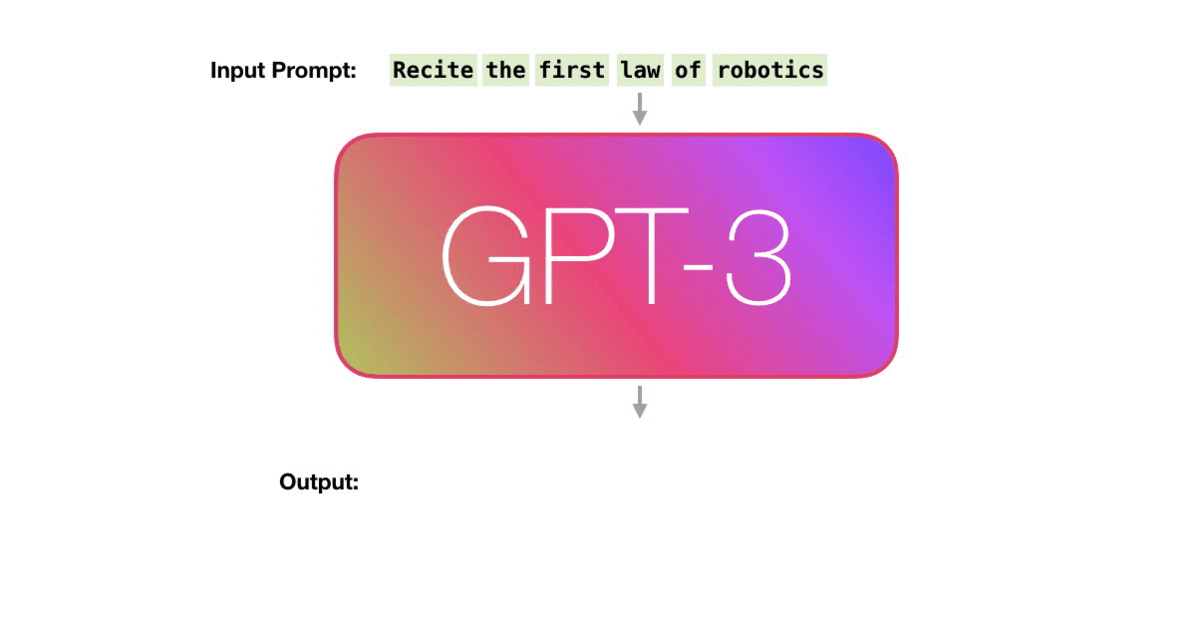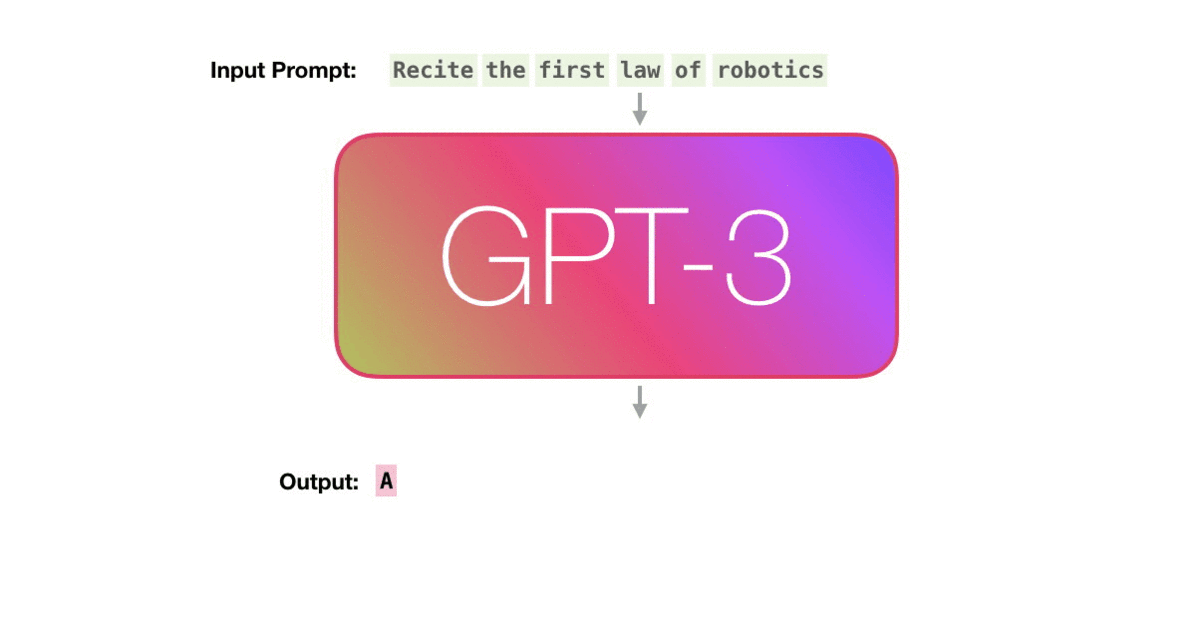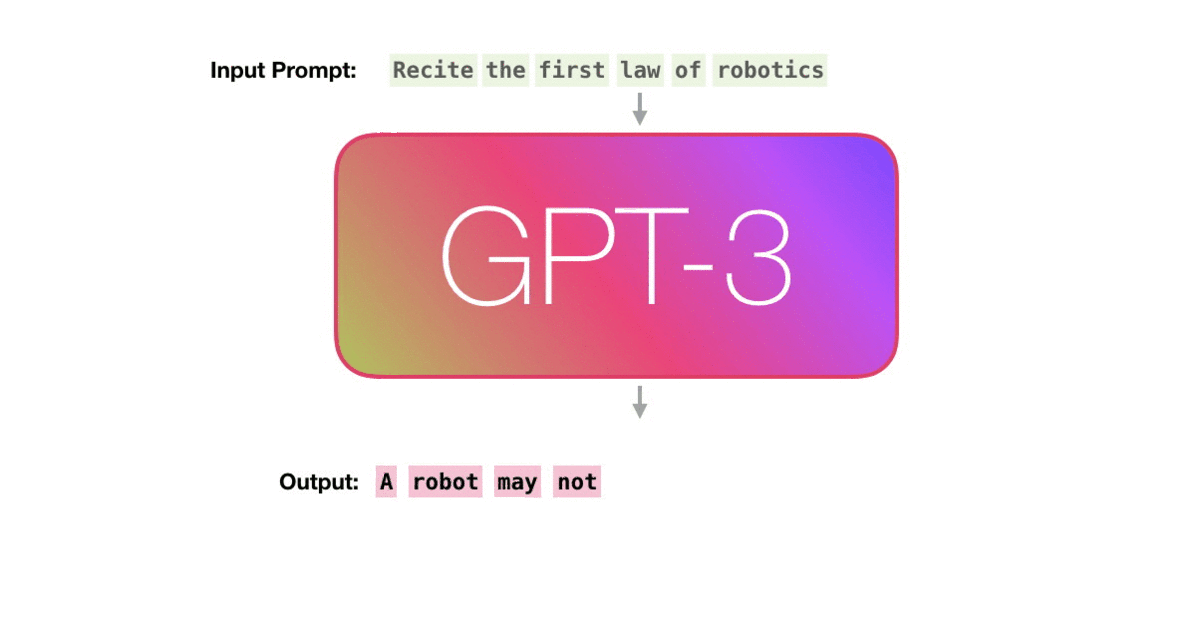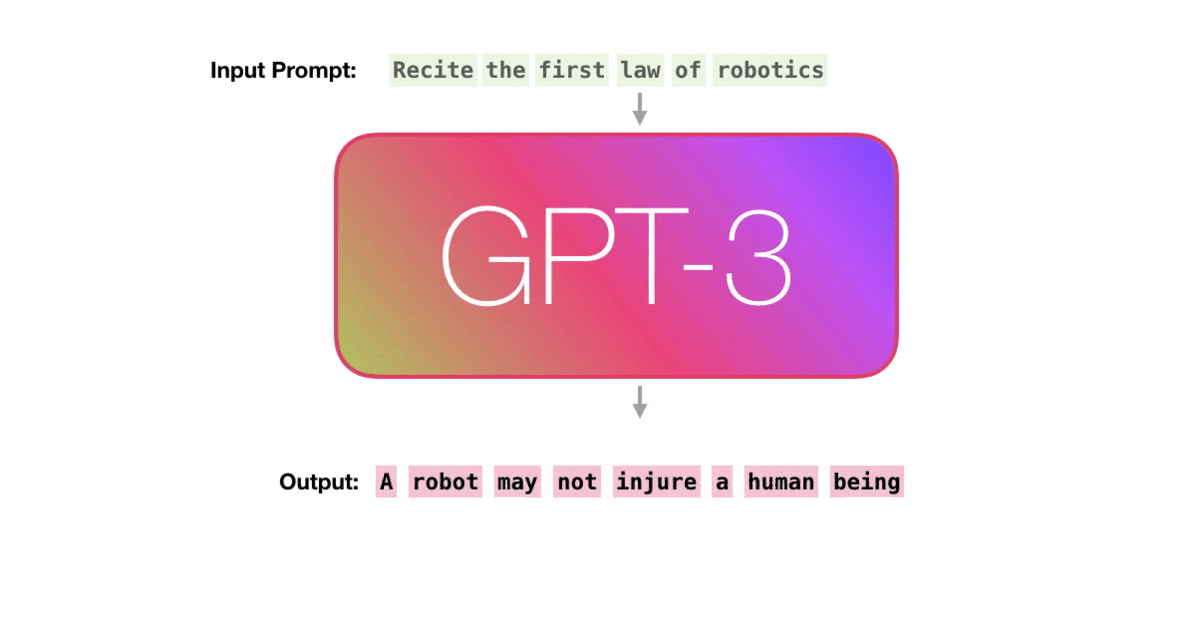
用一个训练好的语言模型生成文本。
我们可以选择给模型输入文本,从而影响模型的输出。在训练期间,模型会通过大量文本学习知识,模型的输出是根据其在训练期间“学习”过的这些内容生成的。
比如下图,给训练好的GPT-3输入一个prompt,模型会给我们对应的输出。
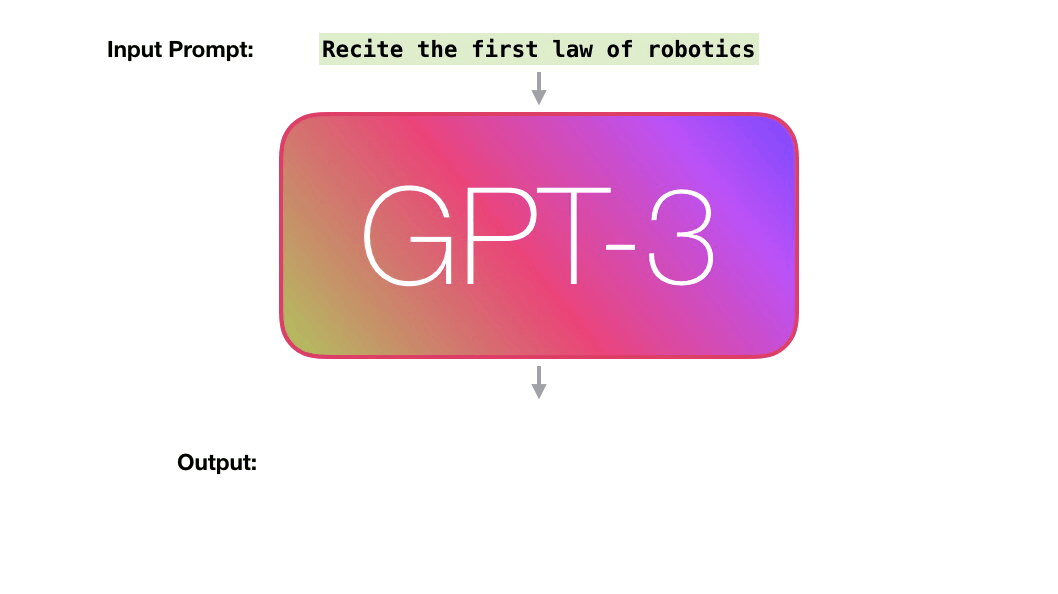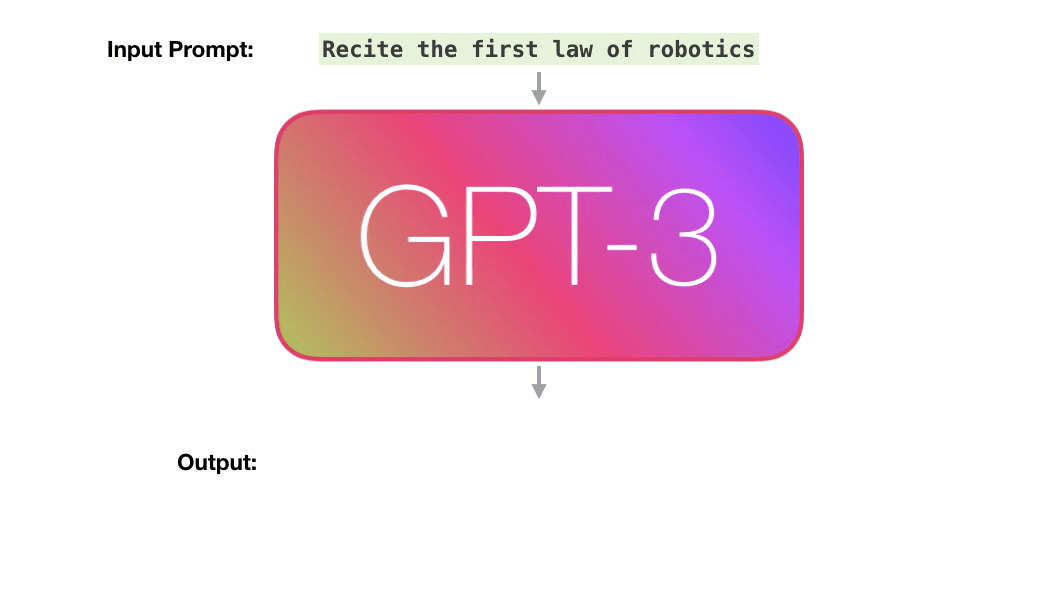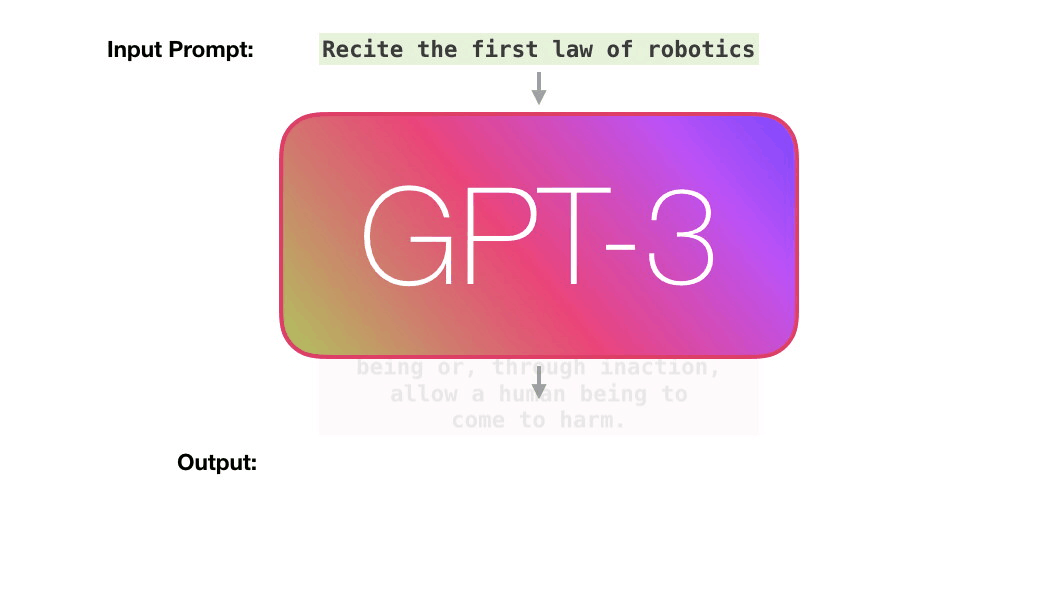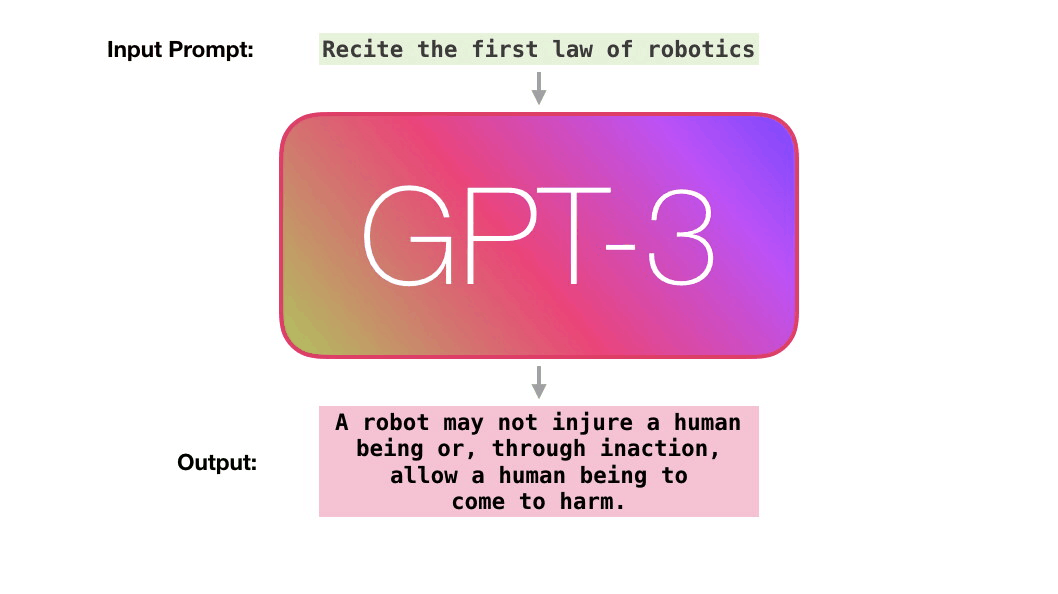
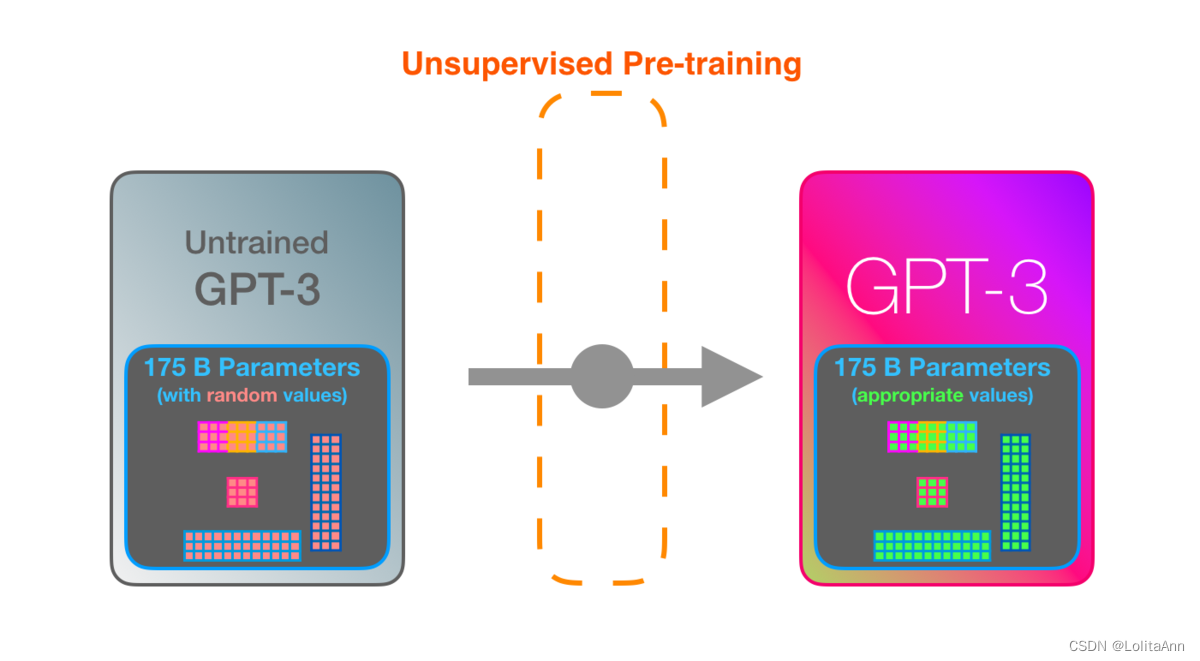
训练是将模型暴露于大量文本的过程,当然GPT-3已经训练好了。你现在看到的所有基于GPT-3的实验都是用的已经训练好的GPT-3模型。据估计,GPT-3训练使用的算力为355 GPU年,成本460万美元,使用无监督训练,训练数据集高达3000亿个文本tokens。
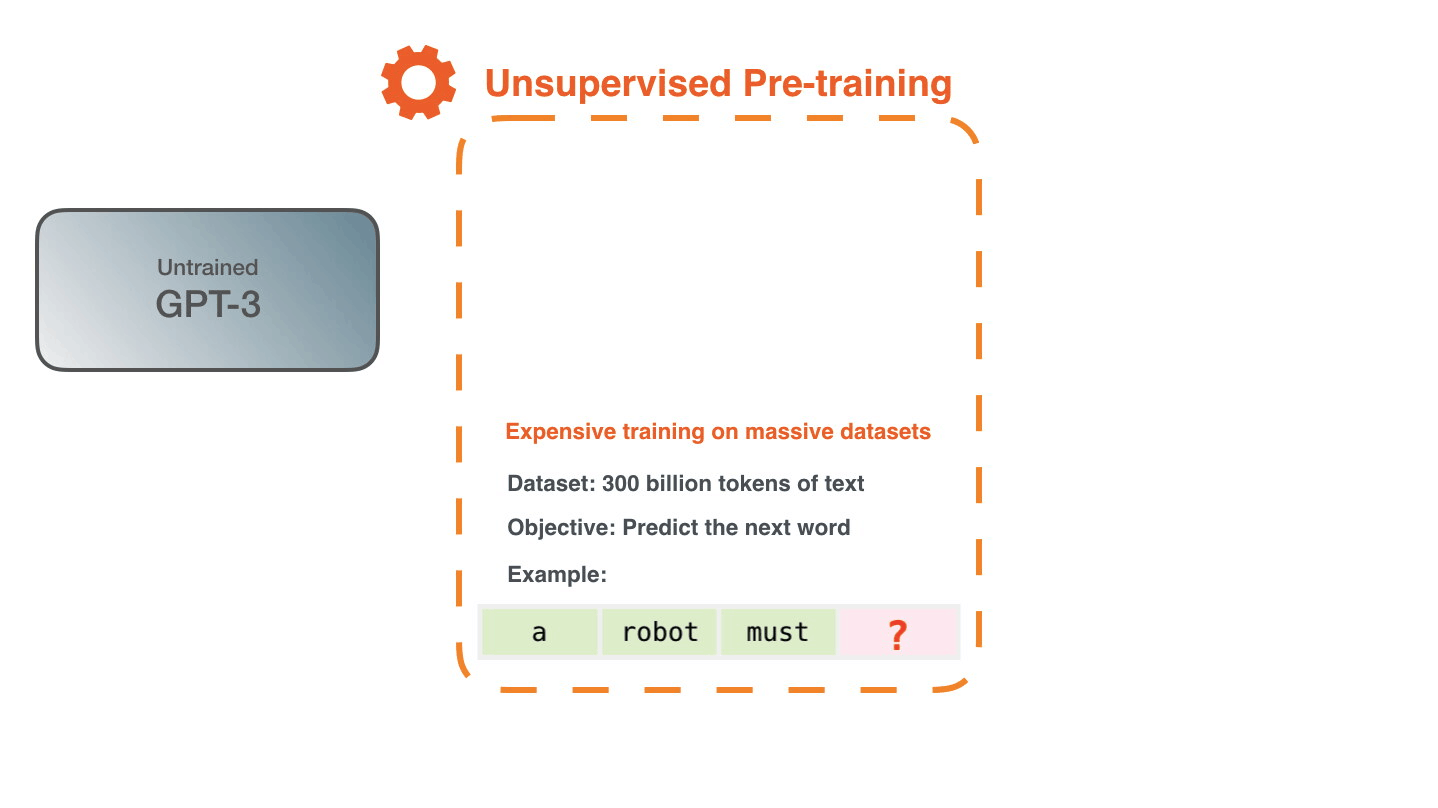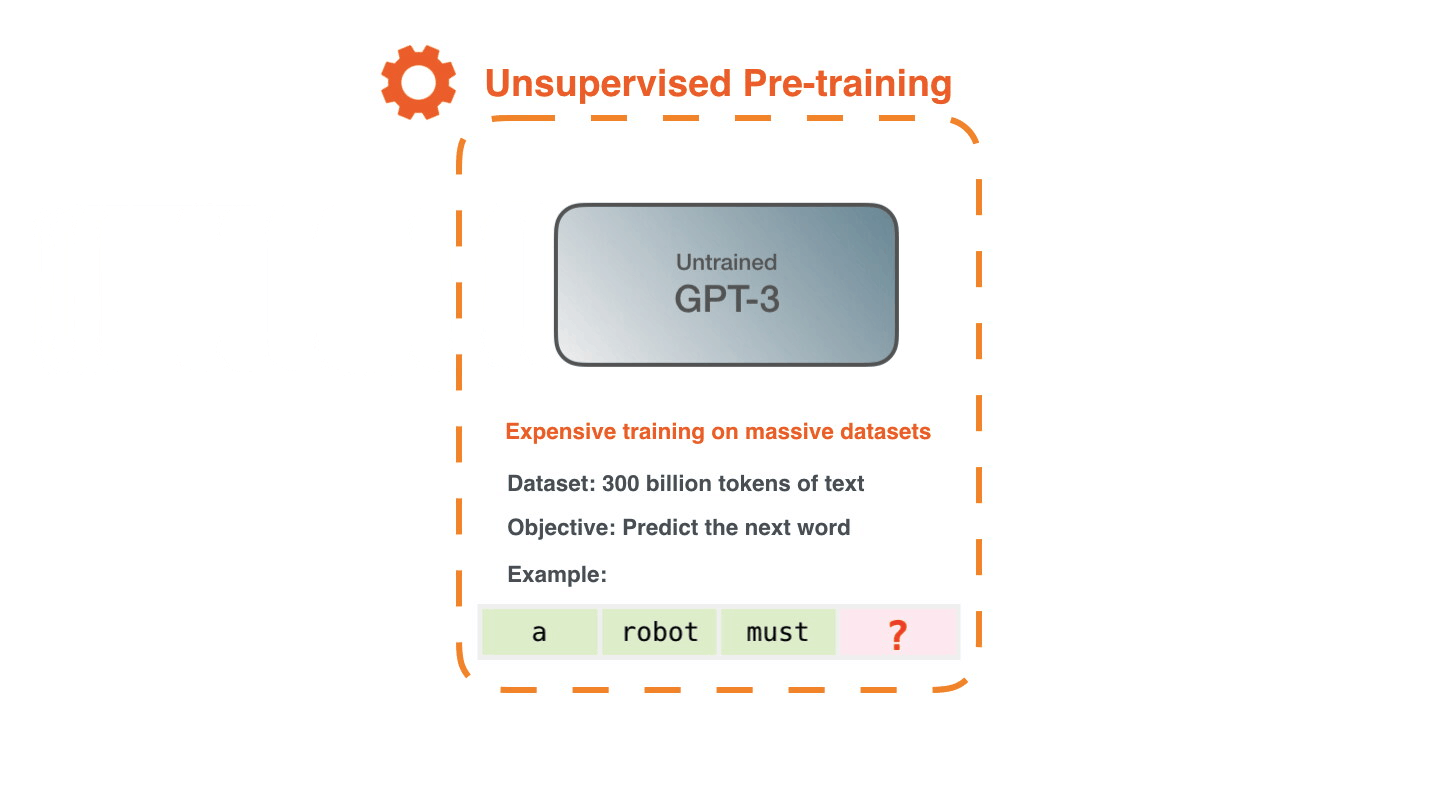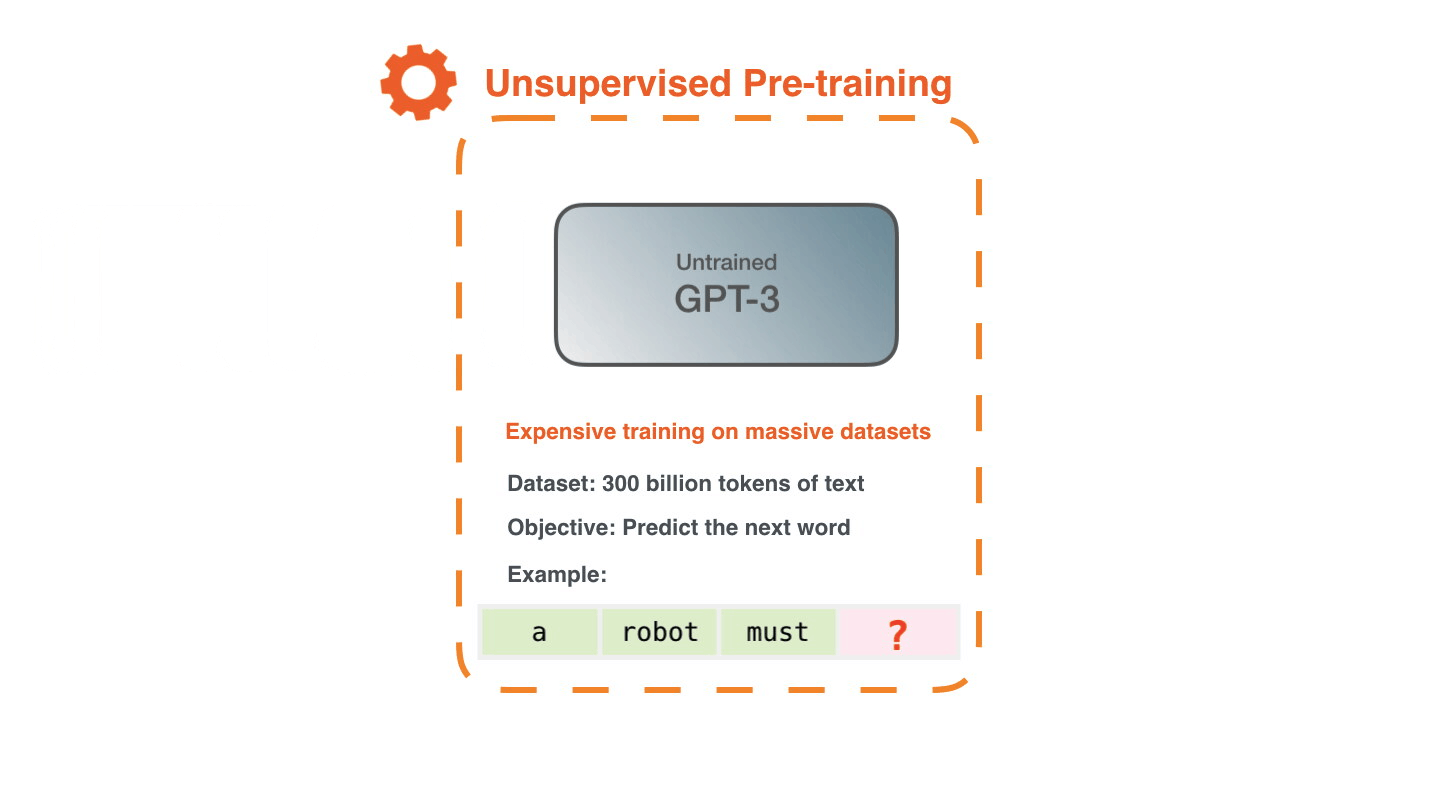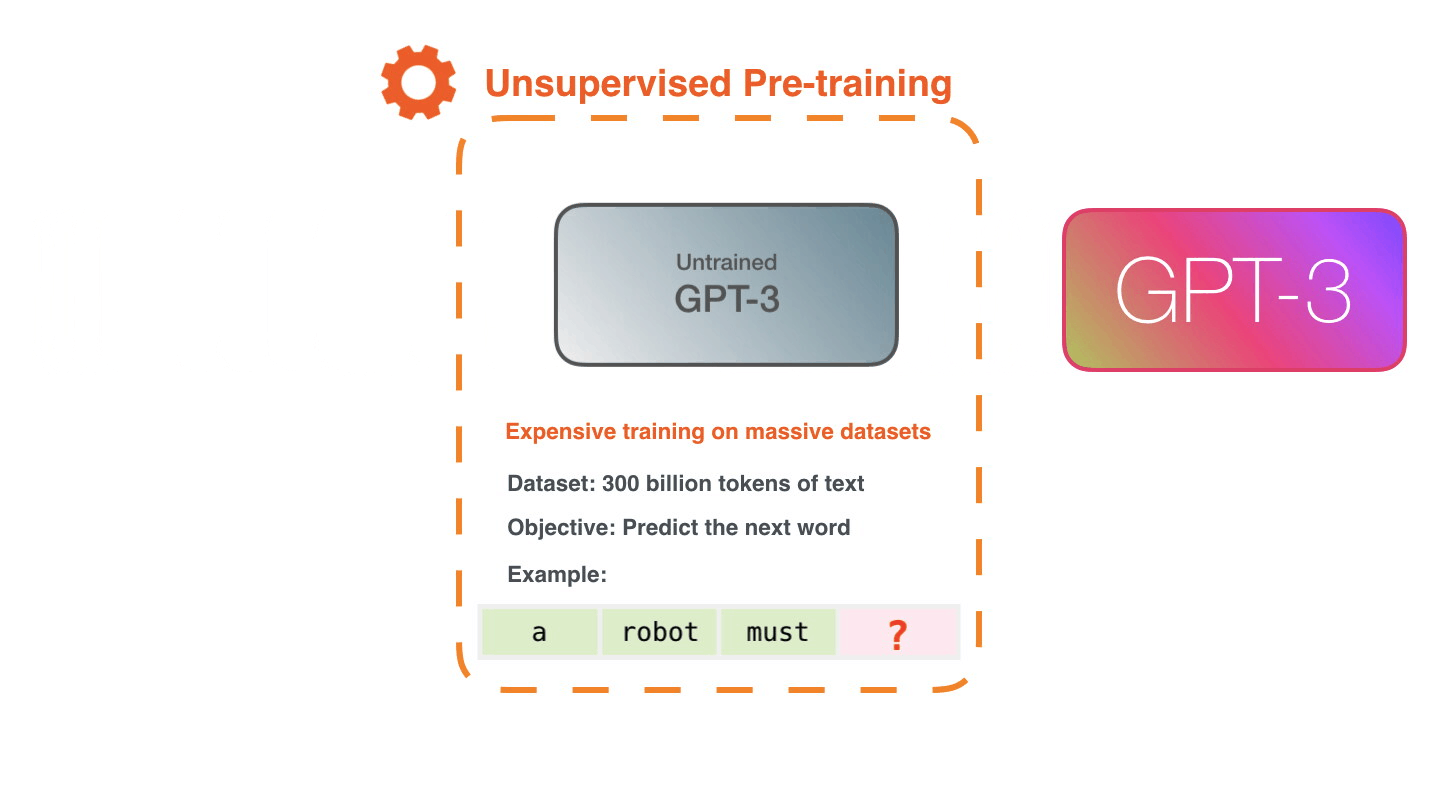
举个栗子,下图是使用顶上的这个文本进行生成的三个样例。你可以看到,如何在所有文本上滑动窗口并产生输出。
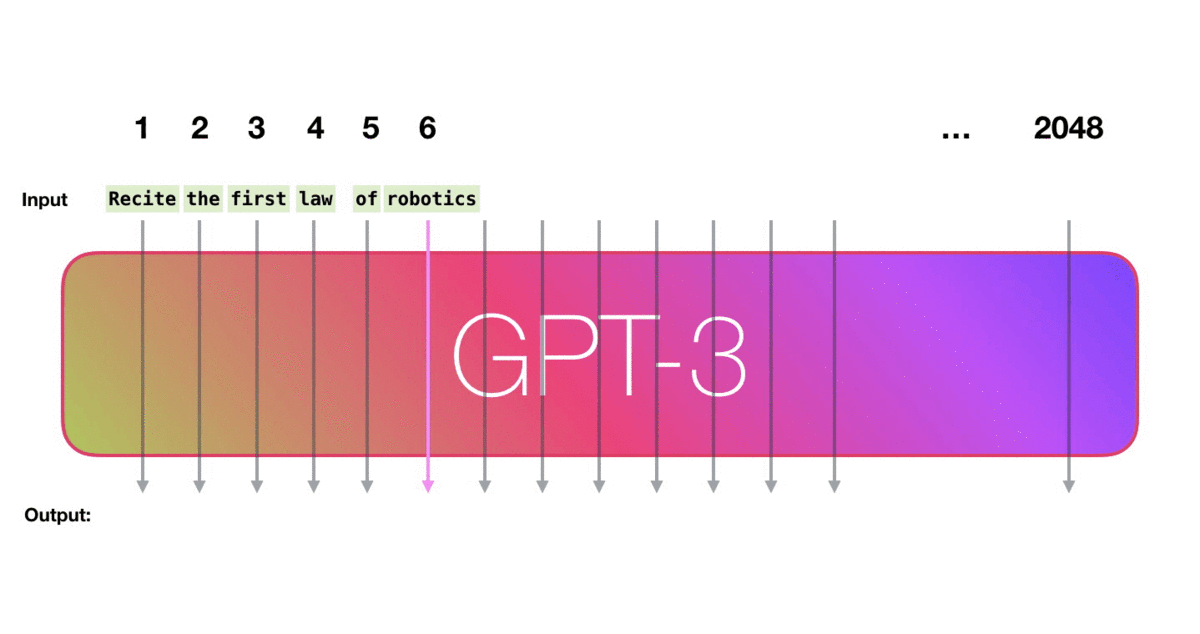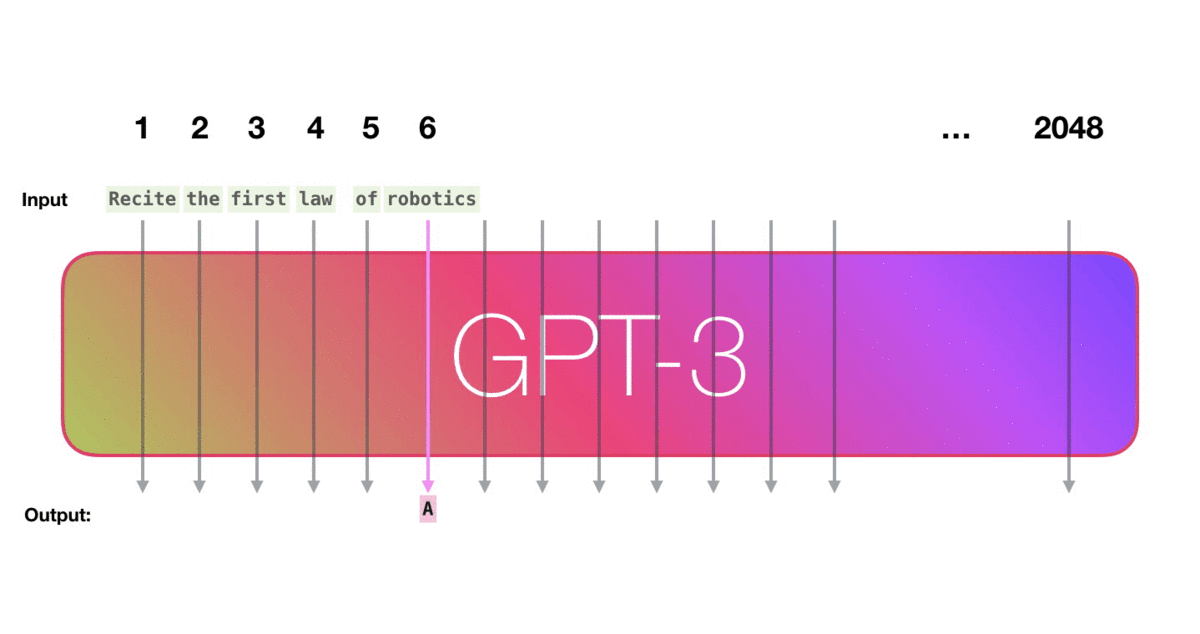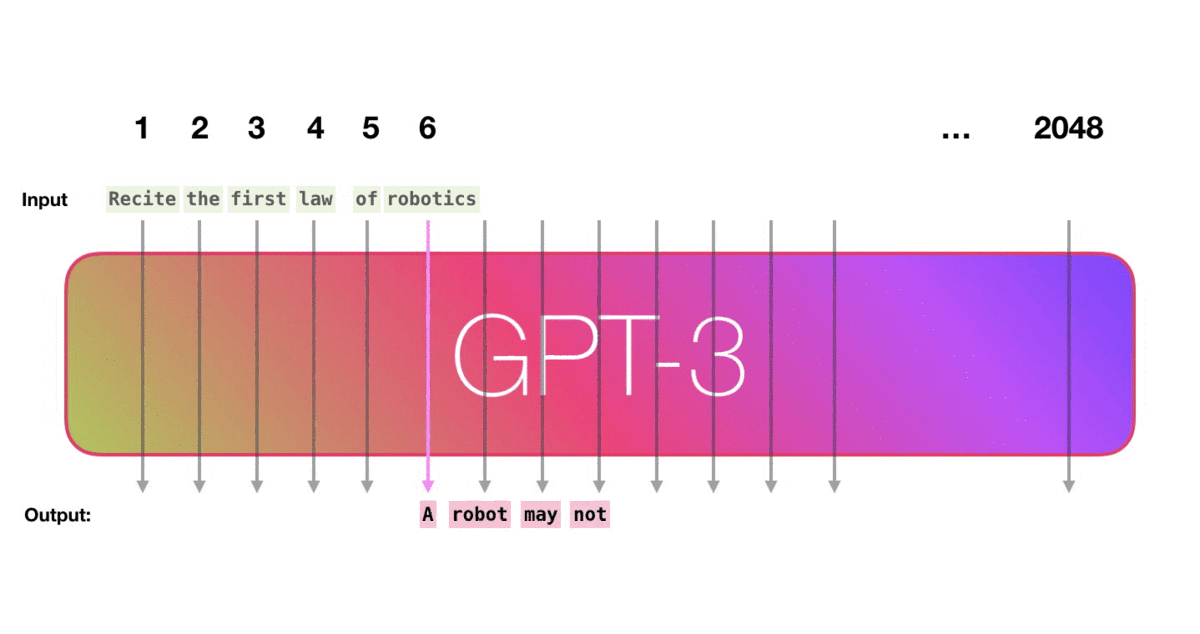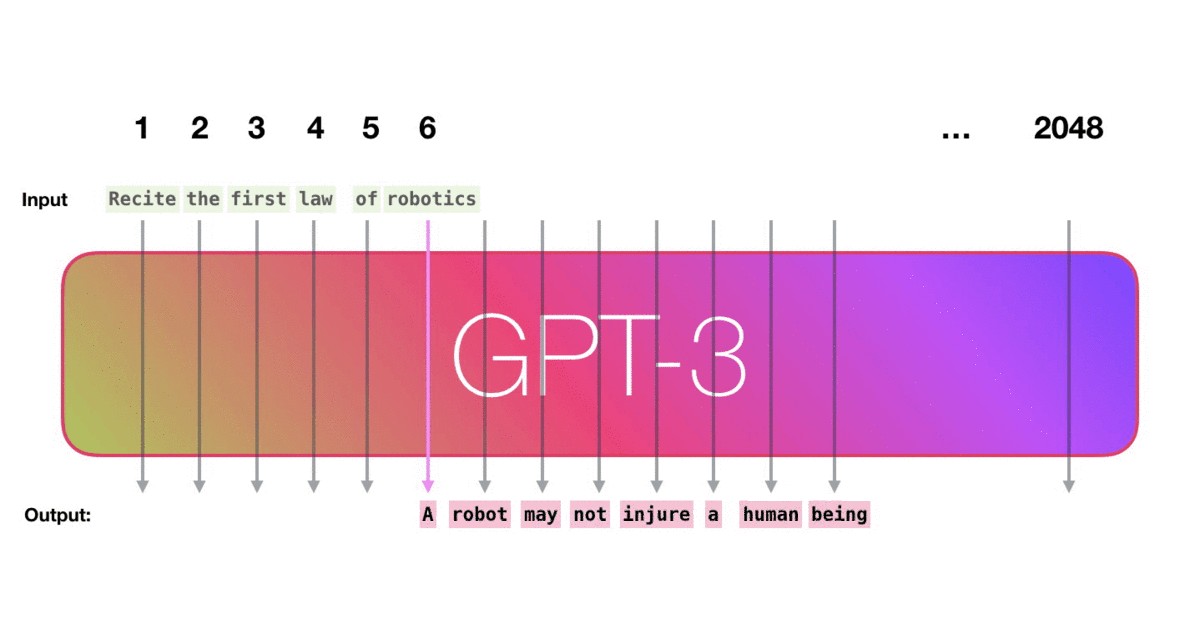
看下图,作者的意思是,模型在训练时候学习到了训练样例 “Second Law of Robotics: A robot obey the orders given it by human beings.”
现在使用这个模型进行输出,每次都输出下一个单词:
- Example 1 :prompt 为
Second Law of Robotics:,模型就会根据训练样例学习到的内容,输出下一个单词A。- Example 2:此时prompt 变为
Second Law of Robotics: A,模型会扫描所有prompt内容,产生下一个预测单词robot`。- Example 3 :prompt 为
Second Law of Robotics: A robot,模型会输出预测must。
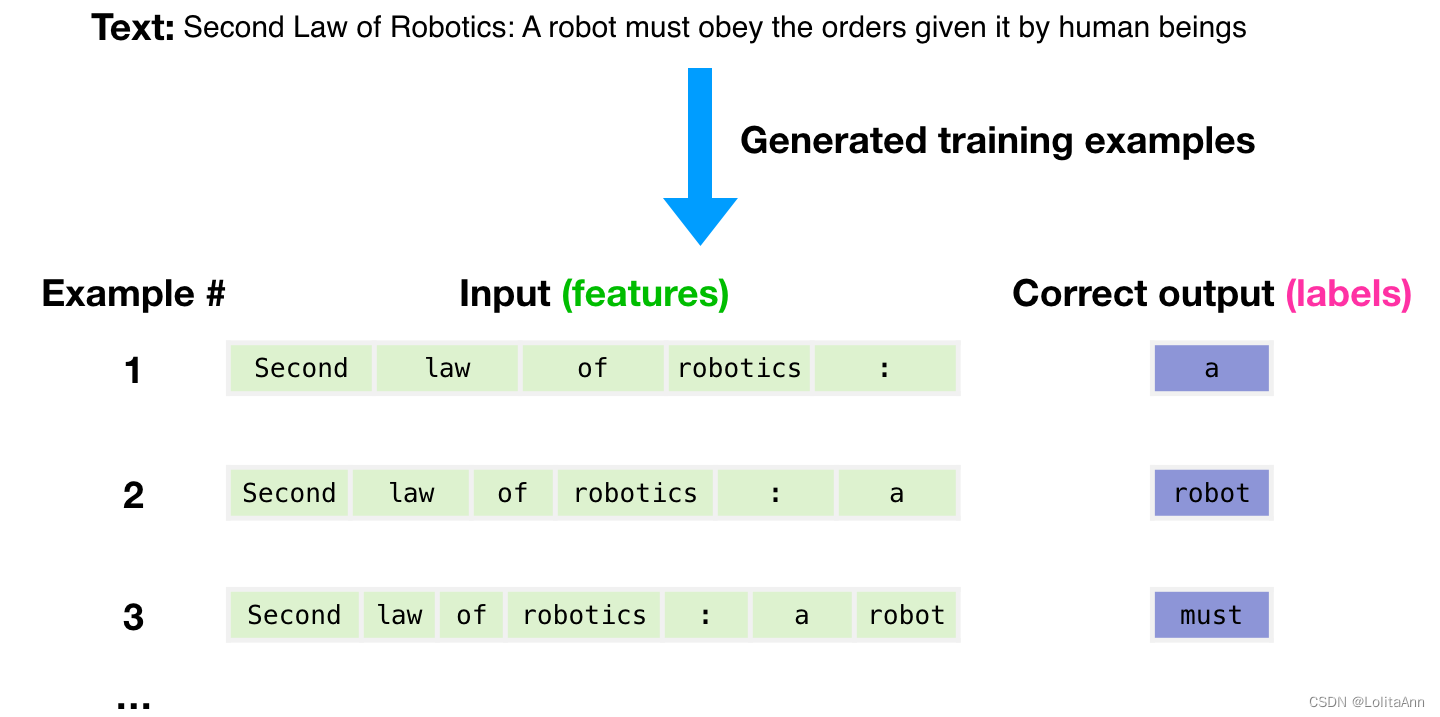
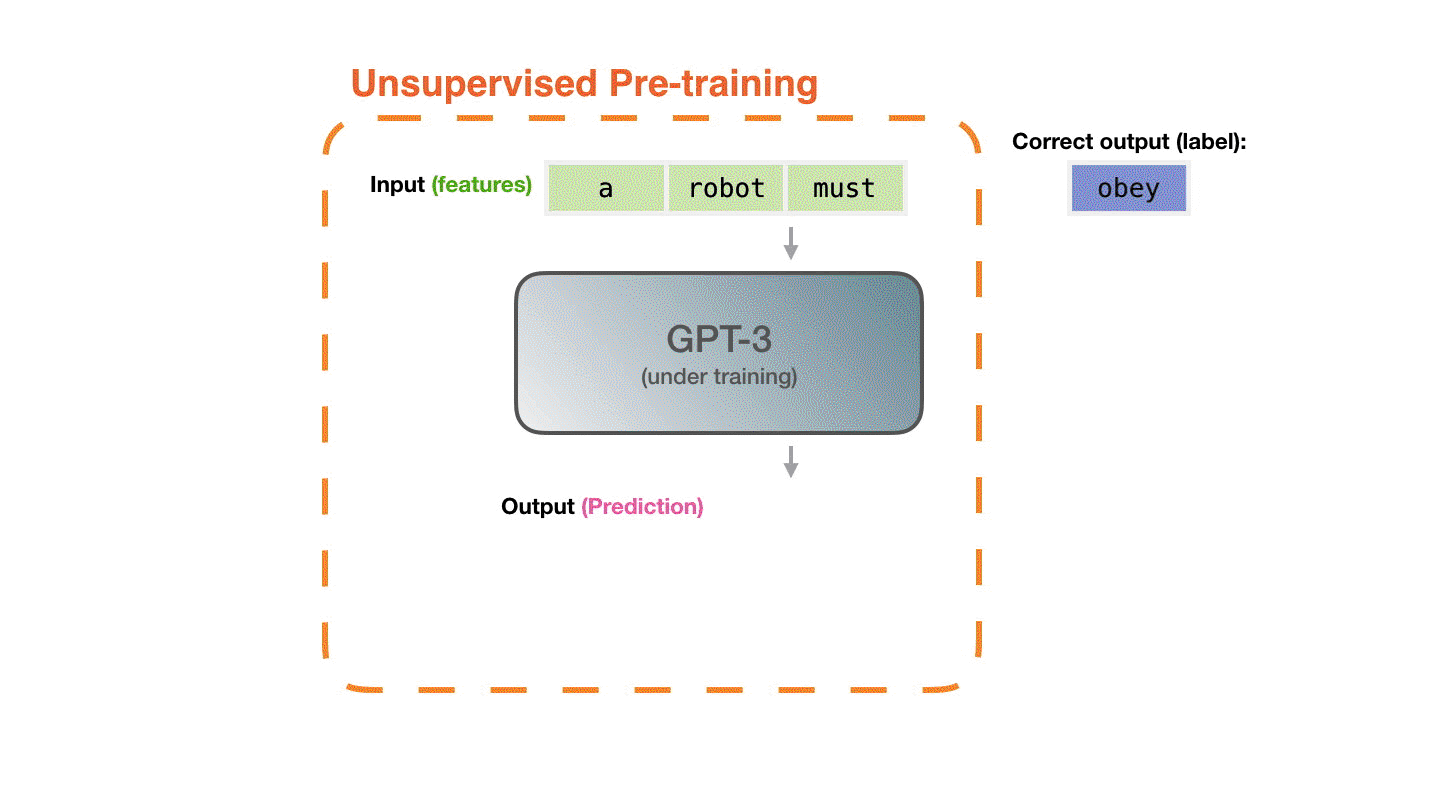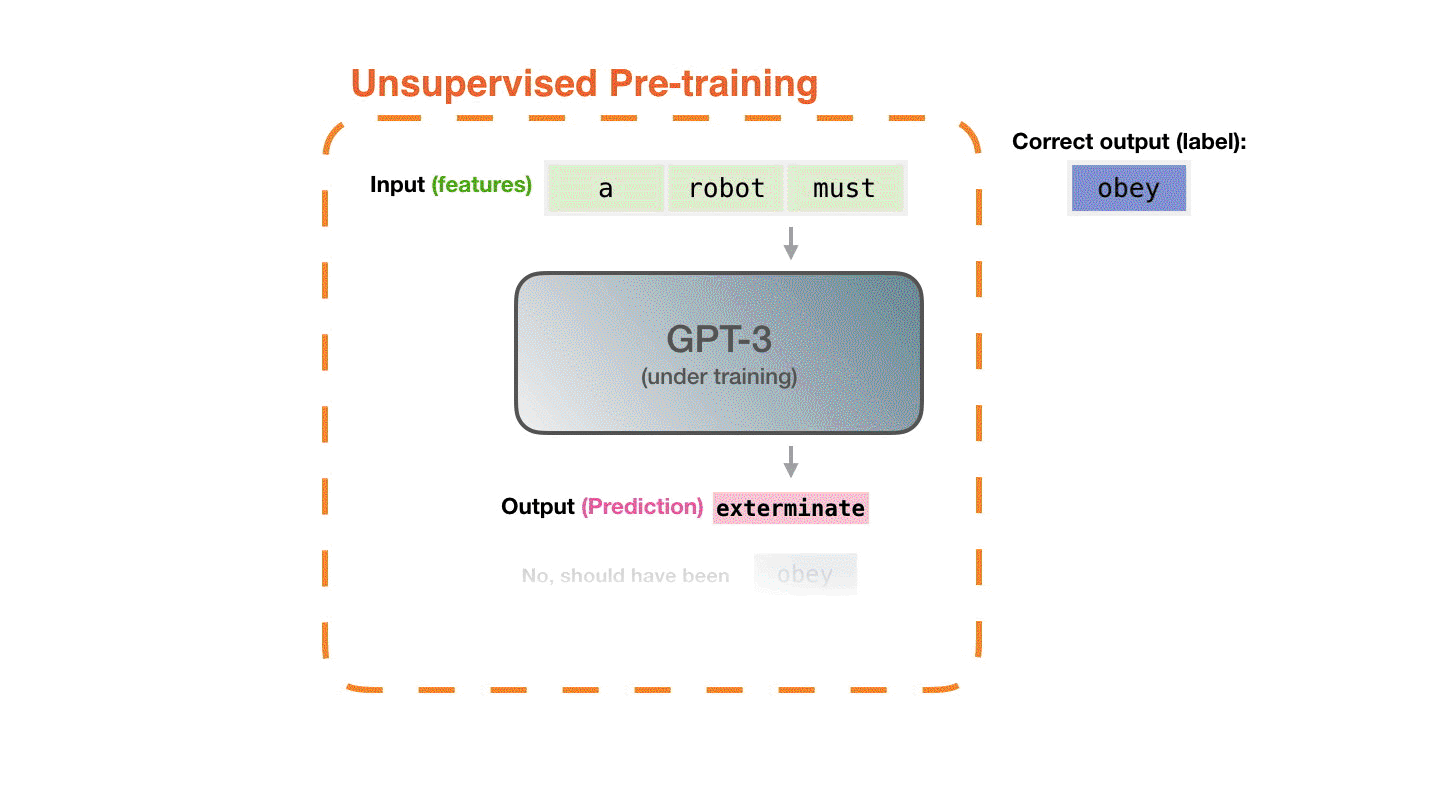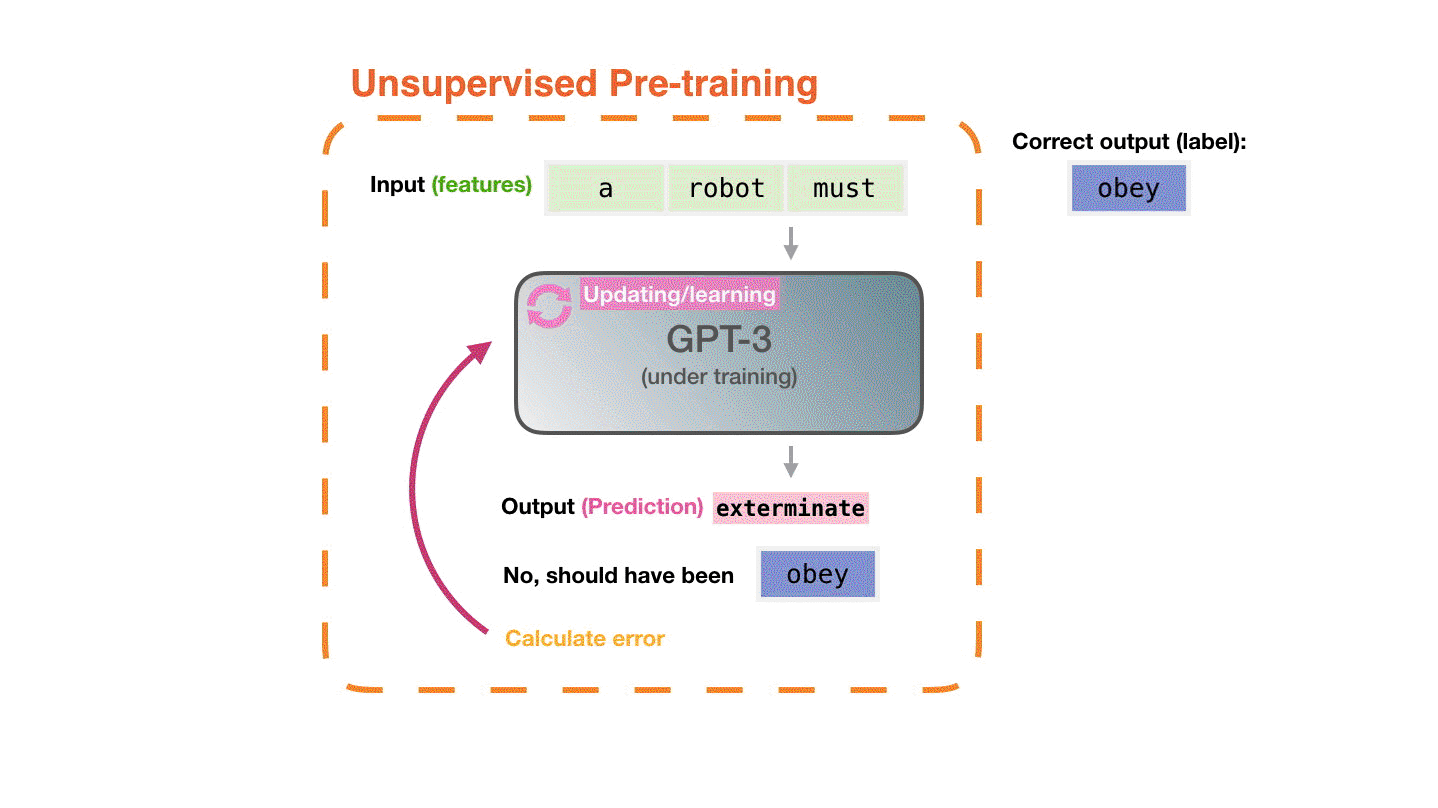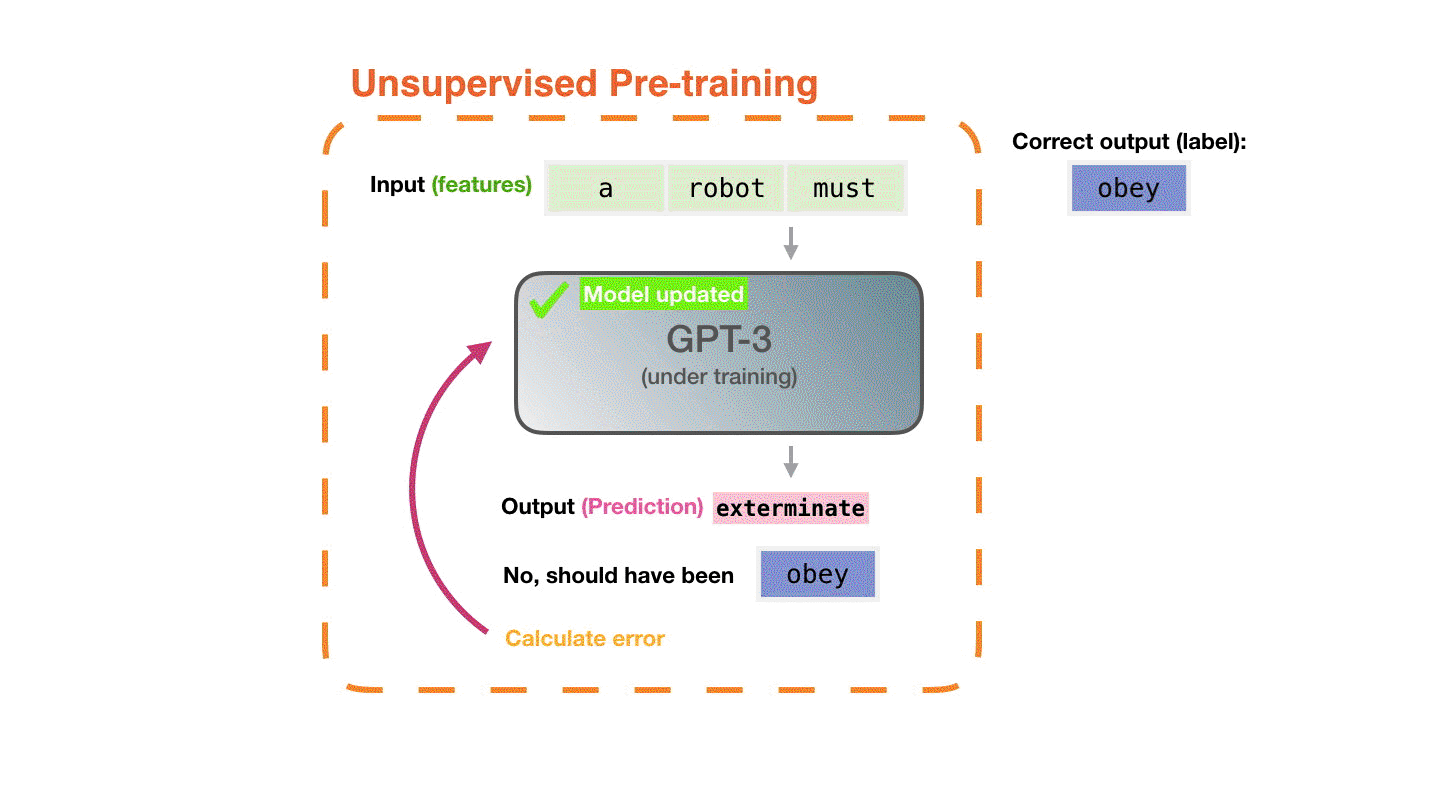
我们给模型输入一个样本。将特征传递给模型,并要求它预测下一个单词。模型的输出应该是错的。我们计算其预测的错误并更新模型,以求下次获得更好的预测。然后我们将这一过程重复无数次。
结合下图,可以看到灰色的GPT-3在这里代表一个没训练好的模型,每次给它输入样本的features,让其进行预测获得prediction,预测错误之后,计算其预测的错误值和正确的标签(labels)之间的误差并更新网络。重复该步骤。最后就会获得一个训练好的GPT-3模型。
现在我们来详细地介绍一下上边提到的这个需要重复的步骤。GPT-3实际上每次只生成一个token(我们现在默认一个token就是一个单词。)
注意:本文是对GPT-3工作原理的描述,重点不是讨论其创新点(巨大的模型结构)。该模型的体系结构是基于这篇文章Generating Wikipedia by Summarizing Long Sequences的Transformer的decoder模型。
GPT-3体力巨大,拥有1750亿个参数编码它在训练过程中学到的东西。这些参数用于计算每次运行时要生成的token。
未经训练的模型参数是随机初始化的,训练过程就是寻找参数值使其产生更好的输出的过程。
这些参数是模型中数百个矩阵的一部分。预测过程就是是大量的矩阵乘法运算。
在我YouTube上的AI简介的视频中,我讲了一个仅有一个参数的简单深度学习模型,这个视频可以作为入门,让你能理解这个1750亿参数的巨大模型。
为了阐明这些参数是如何分布和使用的,我们需要看一下模型的内部结构。
GPT-3接受token的宽度为2048,我们也可以称之为“上下文窗口”。这意味着它有2048个路径,每个token都要沿着这些路径进行处理。
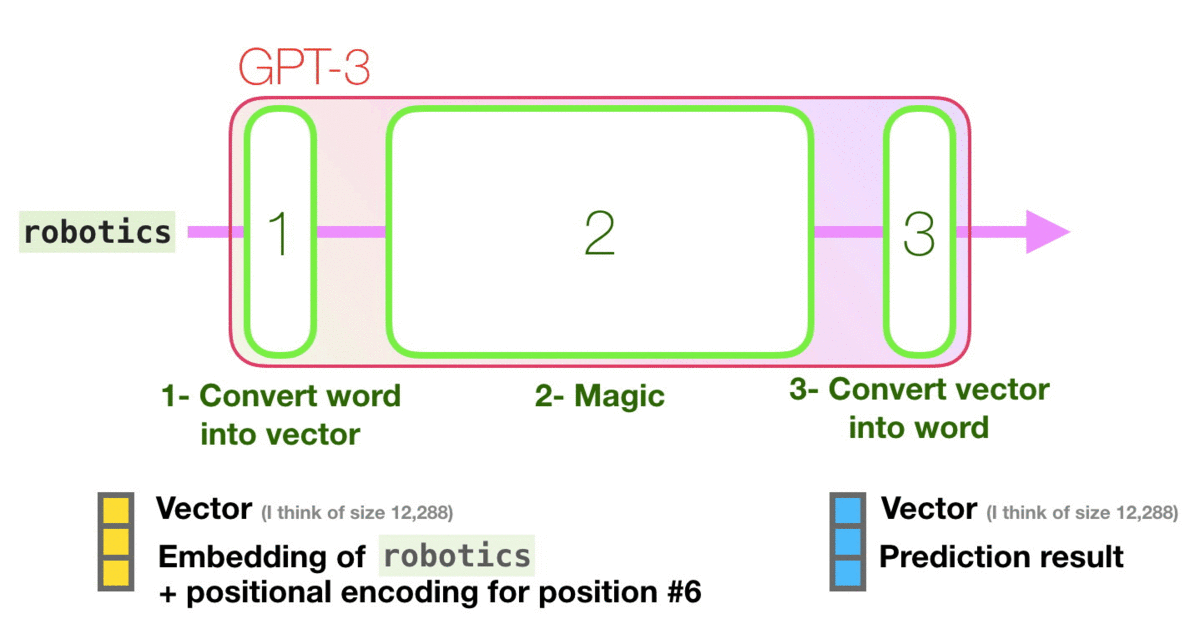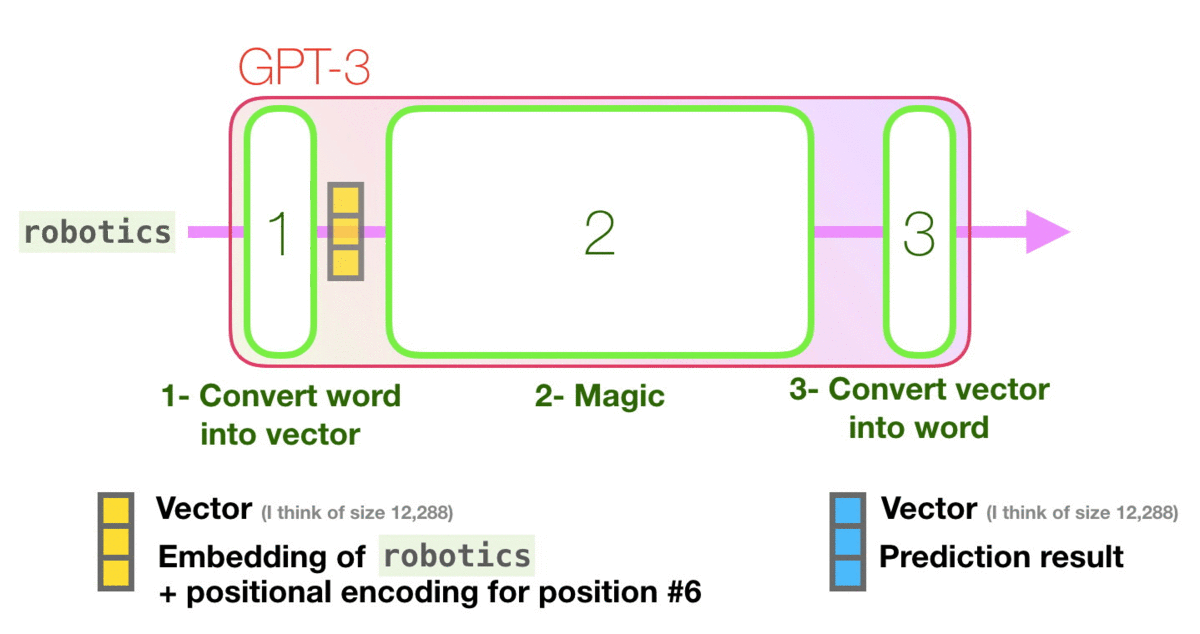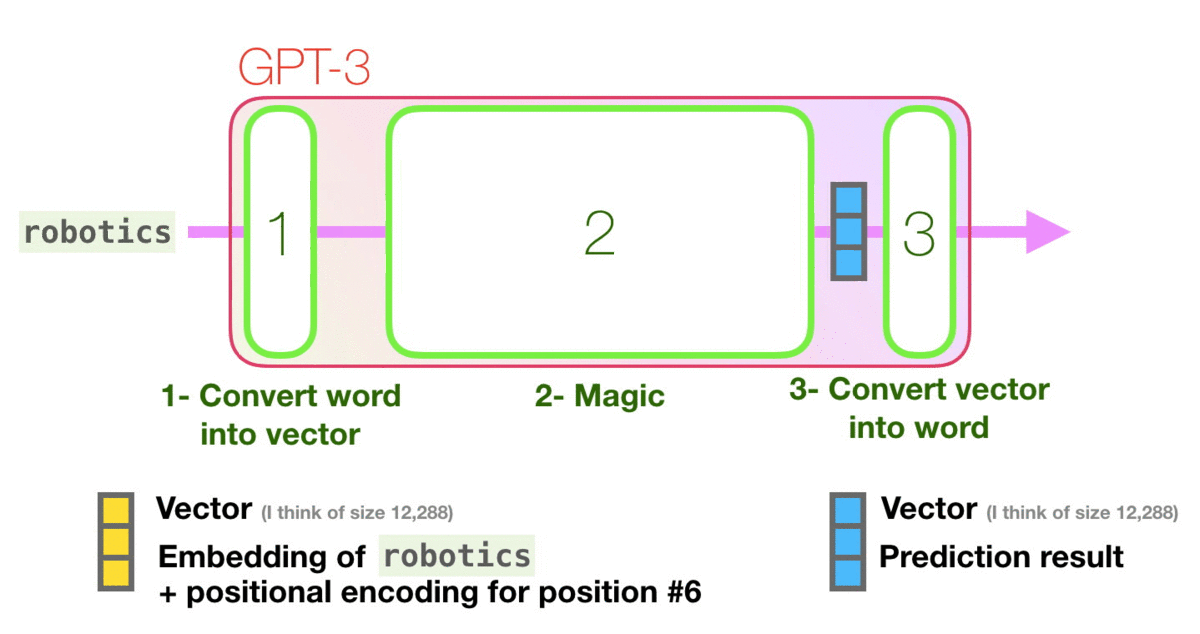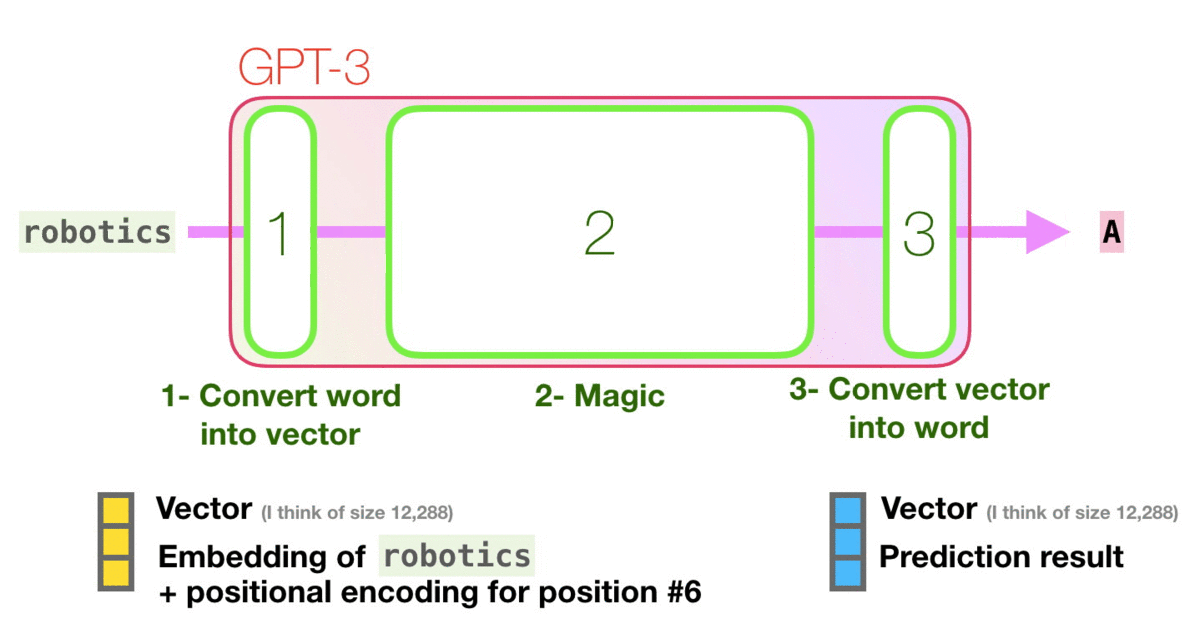
让我们看着下图紫色箭头的轨迹,看一下系统如何处理robot一词并产生预测A的:
高级步骤:
- 将单词转换为表示单词的向量
- 计算预测值
- 将预测结果向量再转换回单词
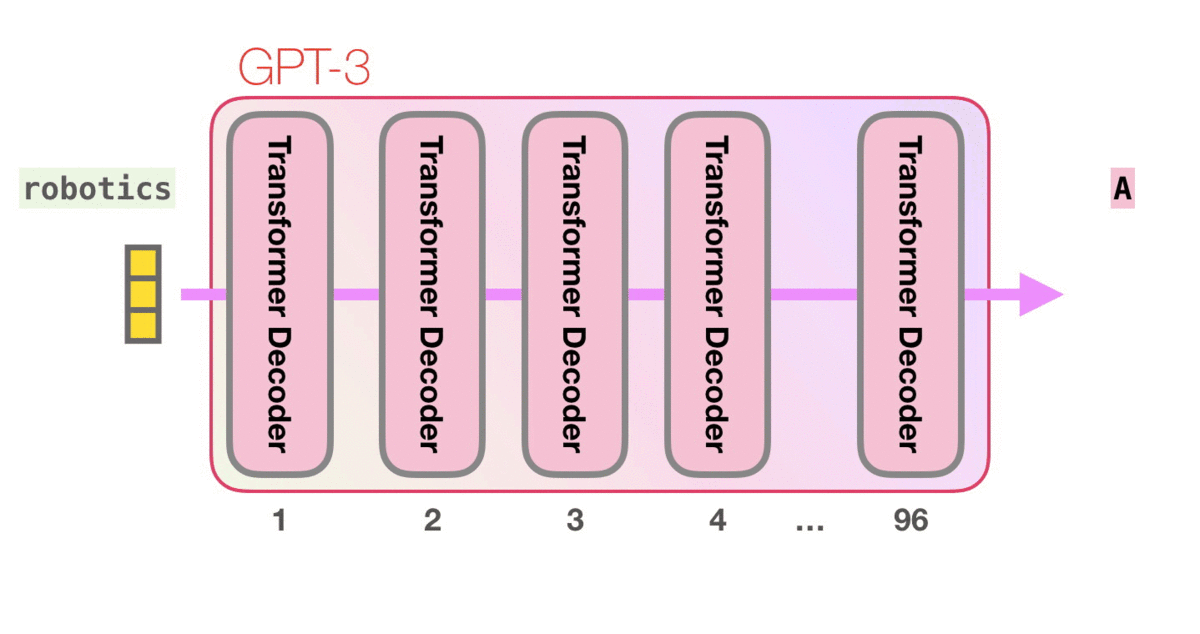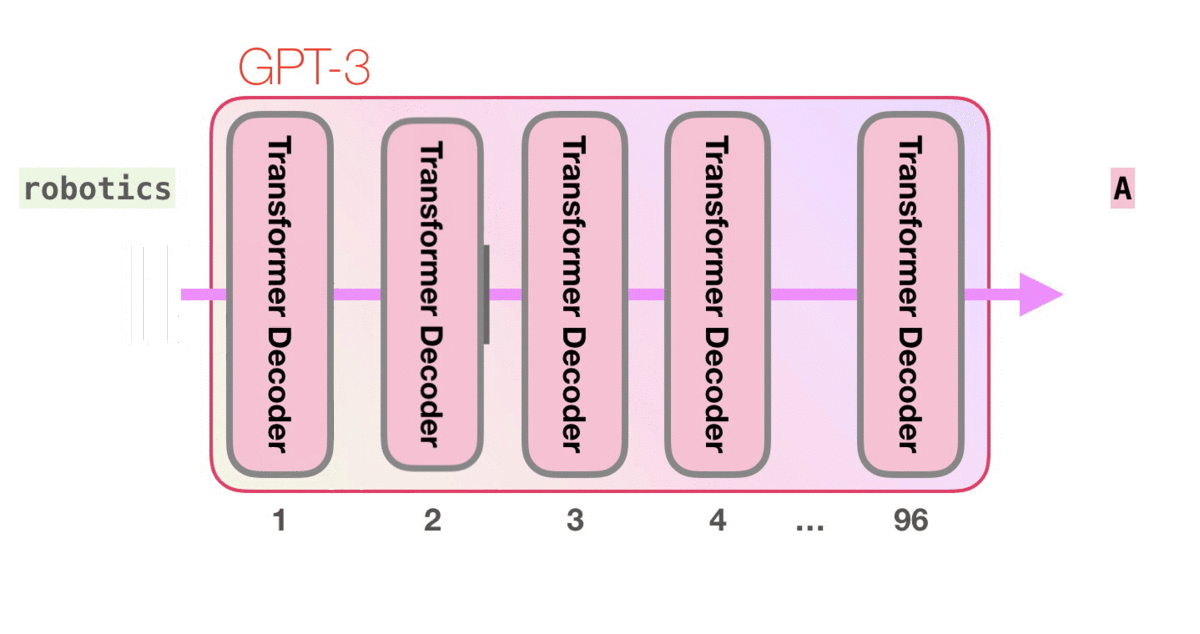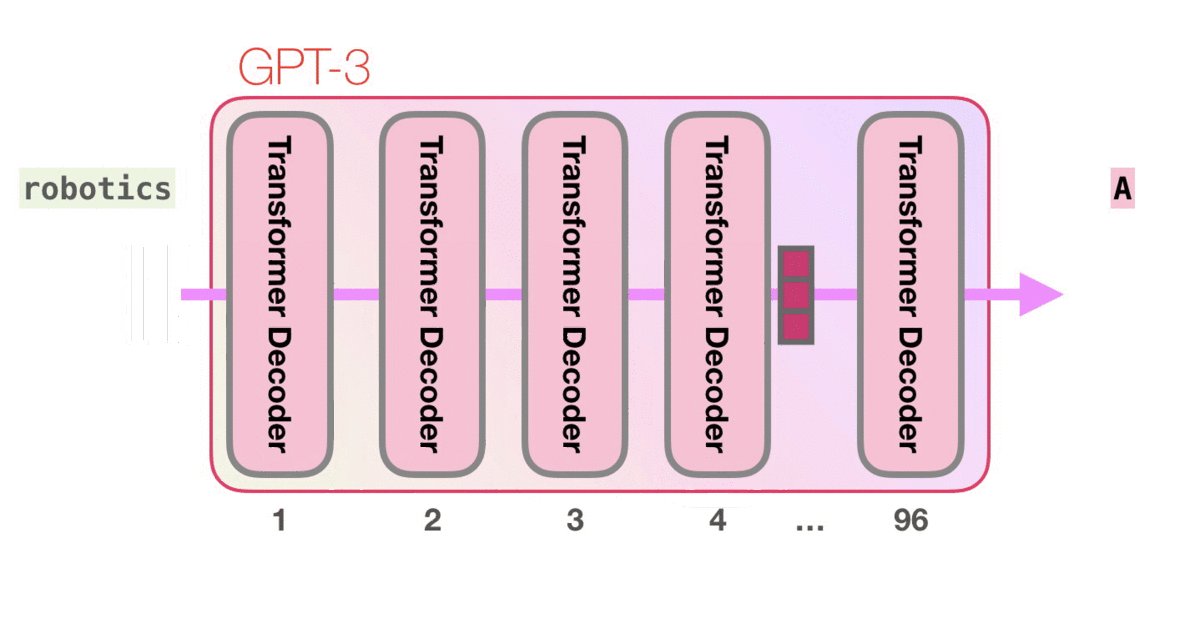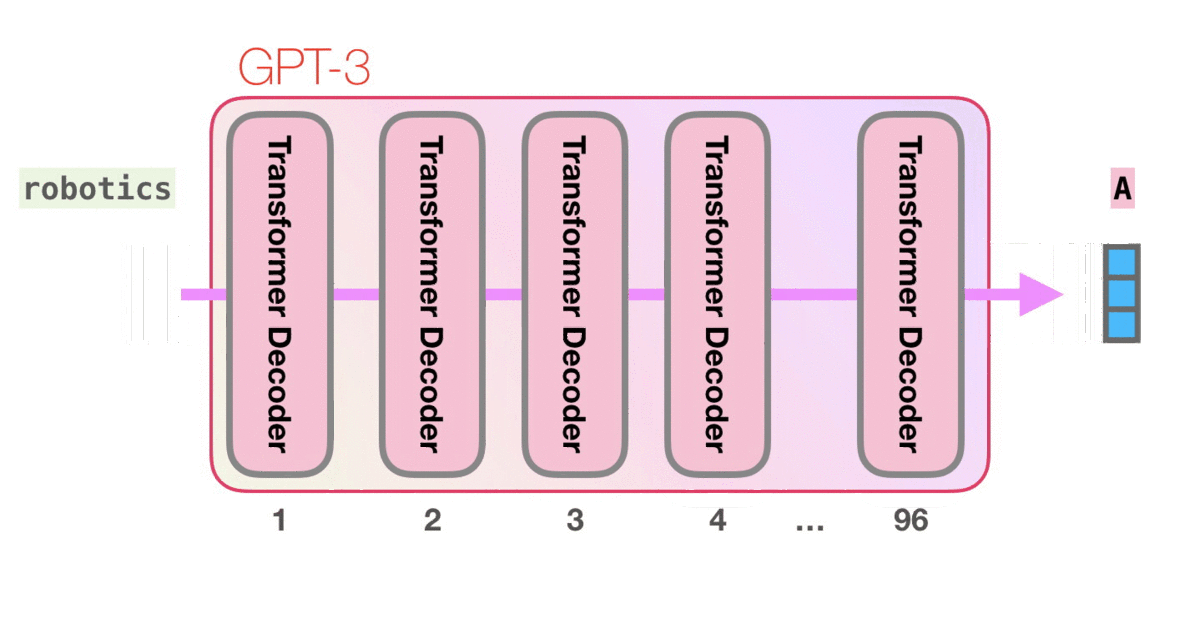
GPT-3的这些计算发生在96个Transformer的decoder层中。
看到这么多层了吗?这大概就是“深度学习”中的“深度”吧。
也就是说GPT-3是由96个Transformer的decoder组成的。GPT-2最大的型号应该是48层decoder。
每个层都有单独的18亿参数,也就是让GPT-3如此强大到玄幻的地方,计算流程如下:
如果想了解decoder的内部构造可以看《图解GPT-2》。
GPT-3的不同之处是交替使用稠密自注意力层和稀疏的自注意力层。
这是给定GPT-3输入并获得输出(Okey human)的流程。我们可以看到每个token是如何流经整个模型层的。模型并不关心第一个单词的输出是什么。当我们输入的句子都经过模型层之后,开始输出其预测的第一个单词,这时候模型才会关心输出的token是什么,并将这个输出放回到模型输入中。
看一下这个示例:React代码生成。
上边这个代码生成是twitter上的,如果你看不了就直接看我的截图行了。就是这个人说,我让GPT-3生成一个todo list的应用程序,然后它就真的几秒钟之内给我一段功能完整的React写的todo list的代码。
上边这个代码生成的例子中,我认为是先给模型几个description=>code的示例,然后再给一个prompt描述。然后模型会输出像这些粉色的token一样逐个生成出来。
我的假设是,基础提示和描述作为额外输入,使用特定的分隔token符将提示内容和描述(结果)拆分开。然后将其喂给模型。
如过大家感兴趣可以去看一下GPT-3的原文,是支持zero-shot、one-shot、few-shot的。这三个x-shot我在这里不解释了,默认大家都懂。上边这两段话就是作者猜测的GPT-3使用few-shot的过程。

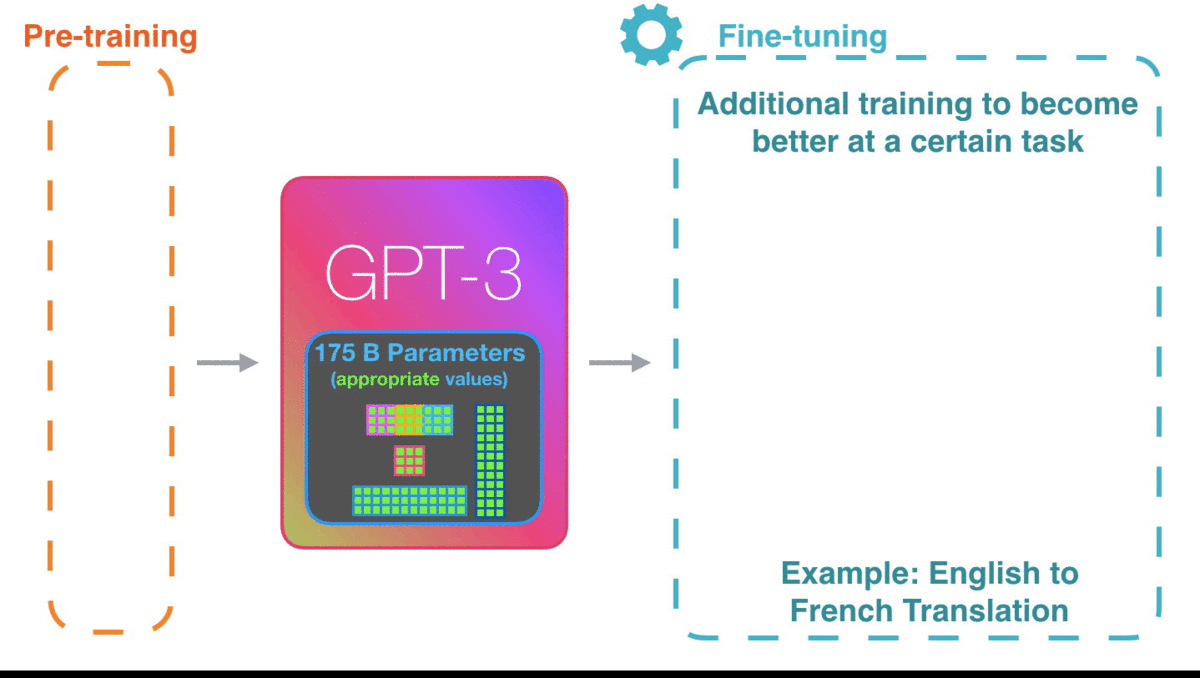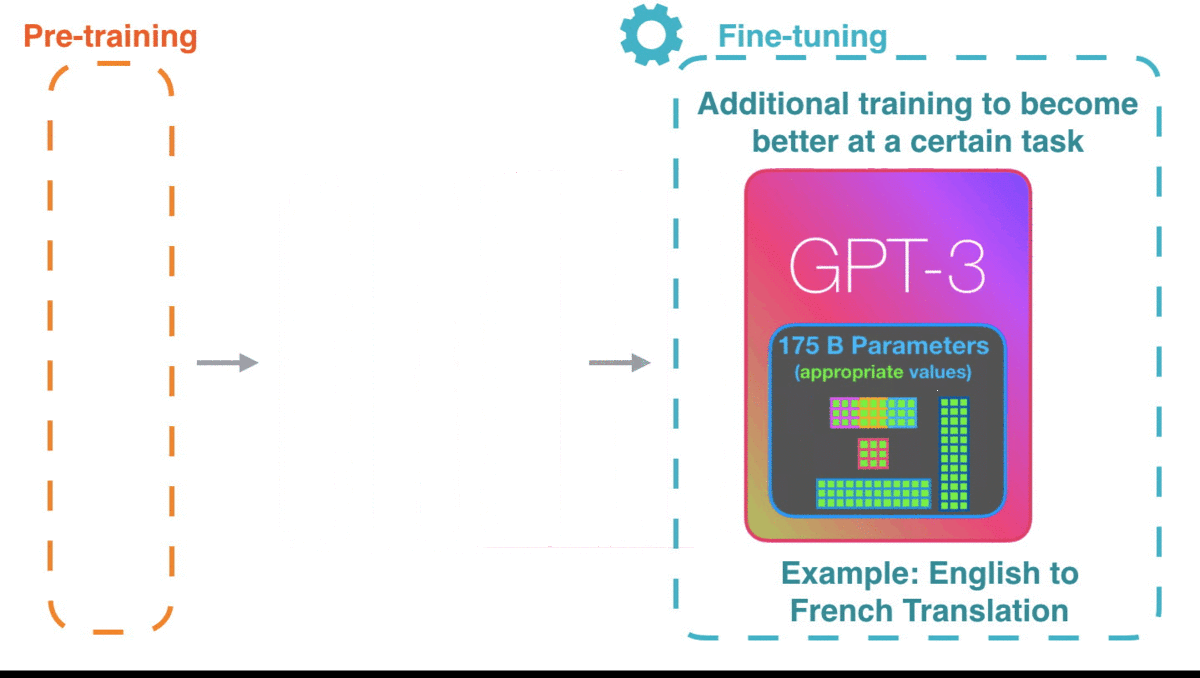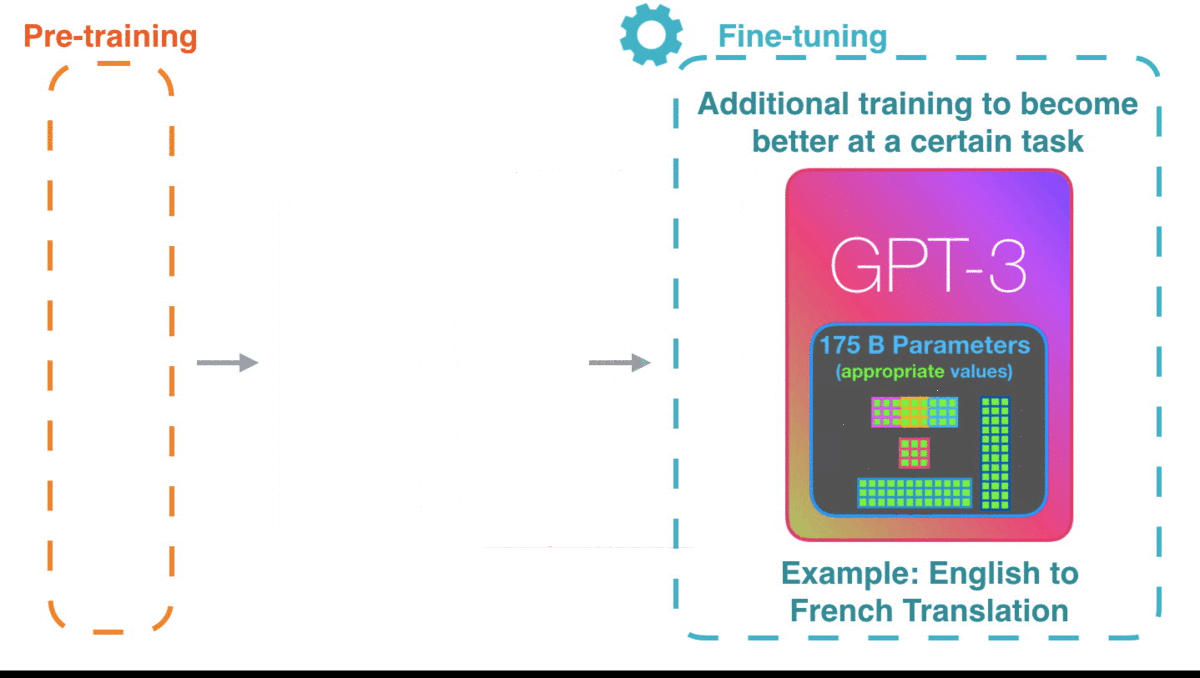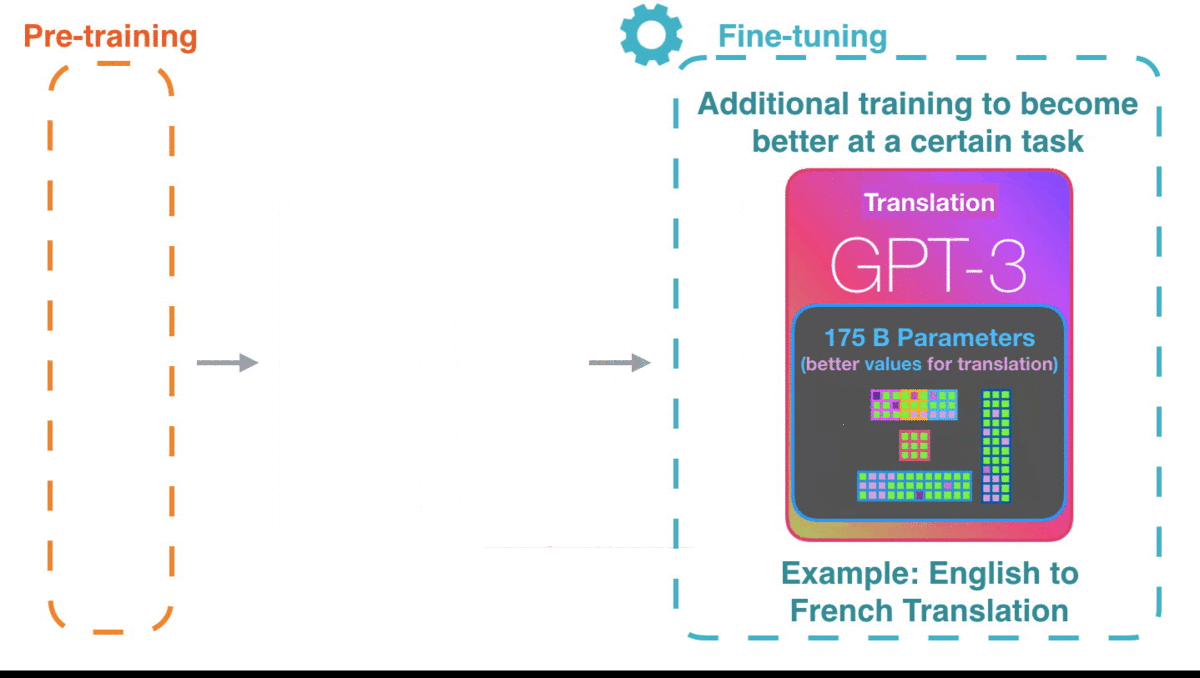
GPT-3已经很令人惊艳了,如果你能等到GPT-3的微调模型,性能可能会更加惊艳。
微调会更新模型的权重,使模型更适配于某一领域。
碎碎念

作者博客:@Jay Alammar
原文链接:How GPT3 Works - Visualizations and Animations
这是我翻译这位大佬的第四篇文章了。之前的工作可以看: