Blockchained On-Device Federated Learningѧϰ�ʼ�
һ��������
֪��������
�����������豸�Ͻ�������ѧϰ
**ժҪ:**ͨ������������,���������һ������������ѧϰ(BlockFL)�ܹ�,���н�������֤����ѧϰģ�͵ĸ��¡�ͨ��ʹ���������еĹ�ʶ����,������û���κμ���ѵ�����ݻ�Э���������ʵ���豸�ϵĻ���ѧϰ������,���Ƿ�����BlockFL�Ķ˵����ӳ�ģ��,������ͨ��ͨ�š������ʶ�ӳ����������ŵĿ��������ʡ�
һ������
δ��������ϵͳ���ۺ�ʱ�ε�,����ȷ�����ӳٺ߿ɿ��ԡ�Ϊ��,�豸�ϵĻ���ѧϰ��һ������עĿ�Ľ������,ÿ���豸�洢һ���������Ļ���ѧϰģ��,�Ӷ��ܹ���������,��ʹ��ʧȥ����ͨ�ԡ�ѵ������һ���豸�ϵĻ���ѧϰģ����Ҫ��ÿ���豸�ı��������������������,������Ҫ�������豸������������[4]-[6]�����������,����ͨ���������豸���������ѵ��ÿ���豸�ı���ģ�͵����⡣
һ���ؼ�����ս�DZ�������������ÿ���豸ӵ�С����,������Ӧ�ñ���ԭʼ�����������������豸�ĸ��š�Ϊ��,�ȸ������ѧϰ(federal learning, FL) [4], [5] (vanilla FL)�����,ÿ���豸�����䱾��ģ����,��ѧϰģ�͵�Ȩֵ���ݶȲ���,���ܴ��е���ԭʼ���ݡ���ͼ1a��ʾ,��ͨFL�Ľ�����ͨ��һ�������������ʵ�ֵ�,�÷����������б���ģ���½��оۺϲ�ȡ����ƽ��ֵ,�Ӷ�����һ��ȫ��ģ���¡�Ȼ��,ÿ���豸����ȫ��ģ����,����������һ�ξֲ�����,ֱ��ȫ��ģ��ѵ�����[5]��������Щ����,��ͨFL��ѵ������ӳٿ����Ǽ�ʮ���ӻ����,��ȸ�ļ���Ӧ�ó���[7]��ʾ��
��ͨFL�����ľ��������������档����,��������һ����һ�����������,�����ܵ����������ϵ�Ӱ�졣��ᵼ�²�ȷ��ȫ��ģ����,Ť�����б���ģ���¡����,�������������豸�����н϶������������豸��ȫ��ѵ���Ĺ����������ڲ��ṩ�����������,�������豸��̫Ը����ӵ���������������������豸���ϡ�

Ϊ�˽����Щ���ȵ�����,ͨ������������[8],[9]���������������,���������һ��������FL (BlockFL)�ܹ�,�����������ܹ�����֤���ṩ��Ӧ������ͬʱ�����豸�ı���ģ���¡�BlockFL�˷��˵����������,��ͨ���Ա���ѵ���������֤����,��������ķ�Χ��չ�����������в����ŵ��豸������,ͨ���ṩ��ѵ��������С�ɱ����Ľ���,BlockFL�ٽ��˸����豸�����ѵ�����������ϡ�
��ͼ1-b��ʾ,BlockFL�����ṹ���豸�Ϳ���ɡ��������Ͽ��������ѡ����豸,Ҳ�����Ƕ����Ľڵ�,�������Ե(�����������еĻ�վ),��Щ�ڵ����ھ��������Բ�������Լ����BlockFL�IJ����ܽ�����:ÿ���豸���㲢�ϴ�����ģ���µ�������������������Ŀ�;��������֤���б���ģ����,Ȼ������proof - of- work (PoW) [8];һ����������PoW,���ͻ�����һ����,���м�¼�˾�����֤�ı���ģ����;���,���ɵĴ洢�ۺϱ���ģ���µĿ鱻���ӵ�������,Ҳ��Ϊ�ֲ�ʽ������,�����豸���ء�ÿ���豸���¿����ȫ��ģ���¡�
ע��,BlockFL��ȫ��ģ��������ÿ���豸�ϱ��ؼ���ġ�������豸���ϲ�Ӱ�������豸��ȫ��ģ���¡�����ͨ��FL���,BlockFL��������Щ�ô�,����BlockFL��Ҫ������������������Ķ����ӳ١�Ϊ�˽���������,BlockFL�Ķ˵����ӳ�ģ����ͨ������ͨ�š������PoW�ӳ����ƶ��ġ�ͨ����������������,��PoW�Ѷ�,���������ӳ���С����
�����ܹ��ͷ���
BlockFL�е�FL����:���о���FL�ǻ���һ���豸D ={1,2,������,
D
N
D_N
DN?}չ����,����|D| =
D
N
D_N
DN?����į
D
i
D_i
Di?ӵ��һ����������
S
i
S_i
Si? ����,|
S
i
S_i
Si?| =
N
i
N_i
Ni?,��ѵ����ֲ�ģ�͡�����ģ�����豸
D
i
D_i
Di?�ϴ���������Ŀ�
M
j
M_j
Mj?,�ÿ��Ǵ�һ���M={1,2,������,
N
M
N_M
NM?}��һ�����ѡ��ġ�
���ǵ��ֲ�ʽģ��ѵ���������Բ��з�ʽ����ع�����,����һ�������豸����������
��
Ŀ������С��ȫ��Ȩֵ��������ʧ����f(w),ѡȡ��ʧ����f(w)��Ϊ�������,����������µ�������ʧ�������Ժ����ؼ���,��[10]��
Ϊ�˽����������,��ѭ[4]�е�vanilla FL����,ͨ���������ݶ��㷨[4]���豸
D
i
D_i
Di?ģ�ͽ��оֲ�ѵ��,��ʹ�÷ֲ�ʽ����ţ�ٷ��������豸�ľֲ�ģ���½��оۺϡ�����ÿ��epoch,�õ�������
N
i
N_i
Ni?�����豸�ľֲ�ģ�͡��ڵ�t��epoch�ĵ�t�ξֲ�����ʱ,�õ��ֲ�Ȩֵ
w
i
w_i
wi?
��
��[4],[5]��vanilla FL��,�豸
D
i
D_i
Di?�ϴ����ı���ģ���µ����ķ�����,ģ���´�С
��
m
\delta_m
��m?�������е��豸����һ���ġ�ȫ��ģ���������ɷ��������㡣��BlockFL��,������ʵ�屻�����������滻,��������������
BlockFL�е�Blockchain����:��BlockFL��,M�еĿ����鼰����֤���������,�Ա�ͨ���ֲ�ʽ�˱���ʵ�ؽ�������ģ���¡��������е�ÿ�����鱻��Ϊ���岿�ֺͱ��ⲿ�֡���BlockFL��,����洢D���豸�ı���ģ����,��,�����豸
D
i
D_i
Di?�ڵ�t��epoch,�Լ����ľֲ�����ʱ��T,�⽫�ڱ�С�ڵ�ĩβ���ۡ� ��ͷ����ָ��ǰһ�����ָ����Ϣ,����������
��
\lambda
��,�Լ�PoW�����ֵ.
��
�ֱ�,ÿ���������һ����ѡ��,�������������������豸��/����������ı���ģ���¡������̼�������,ֱ�����ﵽ���С��ȴ�ʱ��
T
w
T_w
Tw?��
��PoW[8]֮��,��ͨ���ı������������������һ����ϣֵ,��:nonce,ֱ�����ɵ�ɢ��ֵС��Ŀ��ֵΪֹ��һ����
M
1
M_1
M1?�ɹ��ҵ���ϣֵ,���ĺ�ѡ�齫������Ϊһ���¿�,��ͼ2��ʾ������������
��
\lambda
�����Ա�PoW���Ѷ�������,����:�ϵ͵�PoWĿ��ɢ��ֵ,ԽС��
��
\lambda
�������ڼ�³����,PoW��Ӧ��������ϵͳ,��[11],[12]��BlockFL������ʹ��������ʶ�㷨,��Ȩ��֤��(PoS)���ռͥ�ݴ�(BFT),�������Ҫ�����ӵIJ����ͳ������������ڿ�֮���ɹ�ʶ��
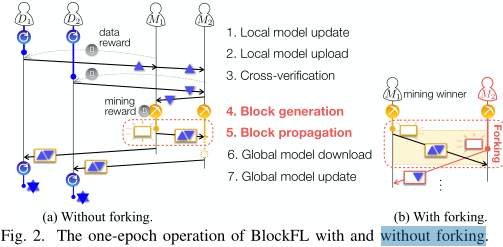
���ɵ����鱻����������������Ϊ��,����[8]������������,���н��յ���������Ŀ�����ֹͣ���ǵ�PoW����,�������ɵ��������ӵ����ǵı����˱��С���ͼ2��ʾ,�����һ����
M
2
M_2
M2?�ڵ�һ�����ɿ�Ĵ����ӳ��ڳɹ��������Լ��Ŀ�,��ô���ֿ��ܻ����ؽ��ڶ������ɵĿ����ӵ��Լ��ı����˱���,��Ϊfork����BlockFL��,forkʹ��һЩ�豸�������ȫ��ģ����Ӧ�õ���һ�α���ģ�����С�Ƶ����fork������
��
\lambda
���Ϳ鴫���ӳ١����Ľ��ڵ���������ϸ˵��������Ļ����ʩ��
���������绹Ϊ�豸�������������ھ��ߵ���֤�����ṩ����,�ֱ��Ϊ���ݽ������ھ������豸
D
i
D_i
Di?�������������յ������ݽ���,������������������С
N
i
N_i
Ni?�����ȡ������
M
j
M_j
Mj?����һ������ʱ,���IJɿ�����������������,����ͳ���������ṹ[8]�������������ھ����������������й����豸�Ļ�������������С�����ȡ�ֵ��ע�����,BlockFL����ʹ�ý������ƽ�һ���Ľ�,�û��Ʋ������ǵ�Ӱ��FLȷ�Ե����������Ĵ�С,�����ǵ���������������������ʵ���豸���ܻ�ͨ�����Ȿ��ģ������������������С�����ڴ洢����֮ǰ,ͨ���Ƚ�������С
N
i
N_i
Ni?������Ӧ�ļ���ʱ��T����֤��ʵ�ľֲ����¡������ͨ��Ӣ�ض�������������չ��ʵ���еõ���֤,������Ӧ�ó�����һ���ܱ����Ļ���������,���������������еõ������á�
BlockFL һ��epoch�IJ���:��Ҫ�����µ��߸����衣
1.����ģ����:�豸Di����Ni�ε���
2.����ģ���ϴ�:
3.������֤:�����õ��ı���ģ����,���ͬʱ,�������豸���߿���֤���յ��ı���ģ����
4.���ɿ�:ÿһ����ʼ���й�����֤��ֱ�����ҵ���������ߵõ��γɵ�����
5.���鴫��:������һ���ҵ�������Ŀ�
6.ȫ��ģ������:�豸������Ӧ�Ŀ������γɵ�����
7.ȫ��ģ����:�豸���ؼ���ȫ�ֵ�ģ����,ͨ�����γɵ�����ʹ�þۺϵı���ģ����
����ʽFL�����ܵ����������ϵ�Ӱ��,�⽫Ť�������豸��ȫ��ģ�͡�Ȼ��,��BlockFL��,ȫ��ģ��������ÿ���豸�ϱ��ؼ����,��Թ����ǽ�׳��,����ֹ�Ĺ��ȼ��㿪����
�����˶Զ��ӳٷ���
һ��epoch��BlockFL���ӳ�ģ��: ��
ʱ�����������γ�����: ��
�ġ���ֵ���������
��
REFERENCES
[1] P . Popovski, J. J. Nielsen, C. Stefanovic, E. de Carvalho, E. G. Str?m,K. F. Trillingsgaard, A. Bana, D. Kim, R. Kotaba, J. Park, and R. B.S?rensen, ��Wireless Access for Ultra-Reliable Low-Latency Communi-cation (URLLC): Principles and Building Blocks,�� IEEE Netw., vol. 32,
pp. 16�C23, Mar. 2018.
[2] M. Bennis, M. Debbah, and V . Poor, ��Ultra-Reliable and Low-Latency Wireless Communication: Tail, Risk and Scale,�� [Online]. Available:https://arxiv.org/abs/1801.01270.
[3] J. Park, D. Kim, P . Popovski, and S.-L. Kim, ��Revisiting Frequency Reuse towards Supporting Ultra-Reliable Ubiquitous-Rate Communica-tion,�� in Proc. IEEE WiOpt Wksp. SpaSWiN, May 2017.
[4] J. Kone�� cn�� y, H. B. McMahan, D. Ramage, ��Federated Optimization:Distributed Machine Learning for On-Device Intelligence,�� [Online].Available: https://arxiv.org/abs/1610.02527.
[5] H. B. McMahan, E. Moore, D. Ramage, S. Hampson, B. A.y Arcas,��Communication-Efficient Learning of Deep Networks from Decentral-ized Data,�� in Proc. AISTATS, F ort Lauderdale, FL, USA, Apr. 2017.
[6] J. Park, S. Samarakoon, M. Bennis, and M. Debbah, ��Wireless network intelligence at the edge,�� submitted to Proc. IEEE [Online]. ArXiv preprint: https://arxiv.org/abs/1812.02858.
[7] H. B. McMahan, and D. Ramage, ��Federated Learning: Collabo-rative Machine Learning without Centralized Training Data,�� [On-line] Available at: https://ai.googleblog.com/2017/04/federated-learning-
collaborative.html, 2017.
[8] S. Nakamoto, ��Bitcoin: A Peer-to-Peer Electronic Cash System,�� [On-line]. Available: https://bitcoin.org/bitcoin.pdf.
[9] C. Decker, and R. Wattenhofer, ��Information Propagation in the Bitcoin Network,�� in Proc. IEEE P2P , Torento, Italy, Sep. 2013.
[10] S. Samarakoon, M. Bennis, W. Saad, and M. Debbah, ��Distributed Federated Learning for Ultra-Reliable Low-Latency V ehicular Commu-nications,�� [Online]. Available: https://arxiv.org/abs/1807.08127.
[11] P . Danzi, A. E. Kal?r, C. Stefanovi�� c, and P . Popovski, ��Analysis of the Communication Traffic for Blockchain Synchronization of IoT Devices,�� Proc. IEEE Int. Conf. on Commun. (ICC), 2018.
[12] N. C. Luong, D. Niyato, P . Wang, and Z. Xiong, ��Optimal Auction for Edge Computing Resource Management in Mobile Blockchain Networks: A Deep Learning Approach,�� Proc. IEEE Int. Conf. on
Commun. (ICC), 2018.
[13] L. Chen, L. Xu, N. Shah, Z. Gao, Y . Lu, and W. Shi, ��On Security Analysis of Proof-of-Elapsed-Time,�� in Proc. SSS, Boston, MA, USA,Nov. 2017.