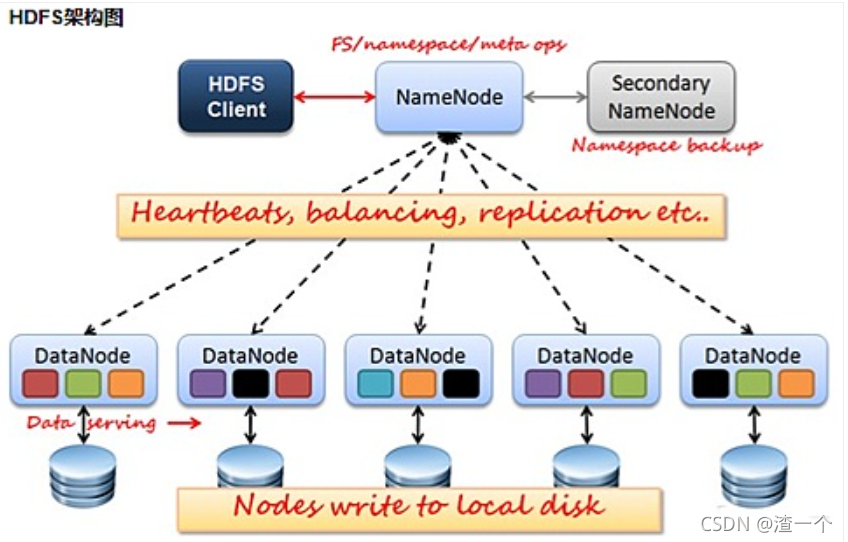
HDFS
hadoop项目的核心子项目,基于流数据模式访问和处理超大文件的需求而开发的。
数据的分布式存储和处理。
namenode 和 datanode 的内置服务器可帮助用户轻松检查群集的状态。
namenode:管理维护着文件系统树以及整个文件树内所有的文件和目录即文件系统的元数据
DateNode:管理所存储的数据;按照客户端的请求, 执行在文件系统上的读写操作;大量节点构成一个集群
Block:读写最小单位,文件系统中的文件将分为一个或多个片段存储在单个数据节点中。这些文件段称为block。
首先从 NameNode 获取该文件的位置,然后从该 DataNode 获取具体的数据。
HDFS 包含大量产品硬件,组件故障频繁。因此,HDFS 应具有快速自动故障检测和恢复的机制。
?
?
IPFS
ipfs是使用p2p协议的,之前的分布式文件系统都是基于地址去寻址,比如说需要根据ip地址或者域名再加上资源名,就能得到
对应的资源,当然资源存在,但是有的场景资源已经不存在了;这个时候基于内容寻址就派上用场,
比如网络上有别的主机已经获取到这个资源,那么客户只需要向网络中发送对应内容的资源请求就可,别的节点存在该资源就会反馈。
还有一个好处就是它的文件名称和路径等都是进行hash加密的,只能根据hash串值去获取访问数据的,在一定程度上保证了安全性。
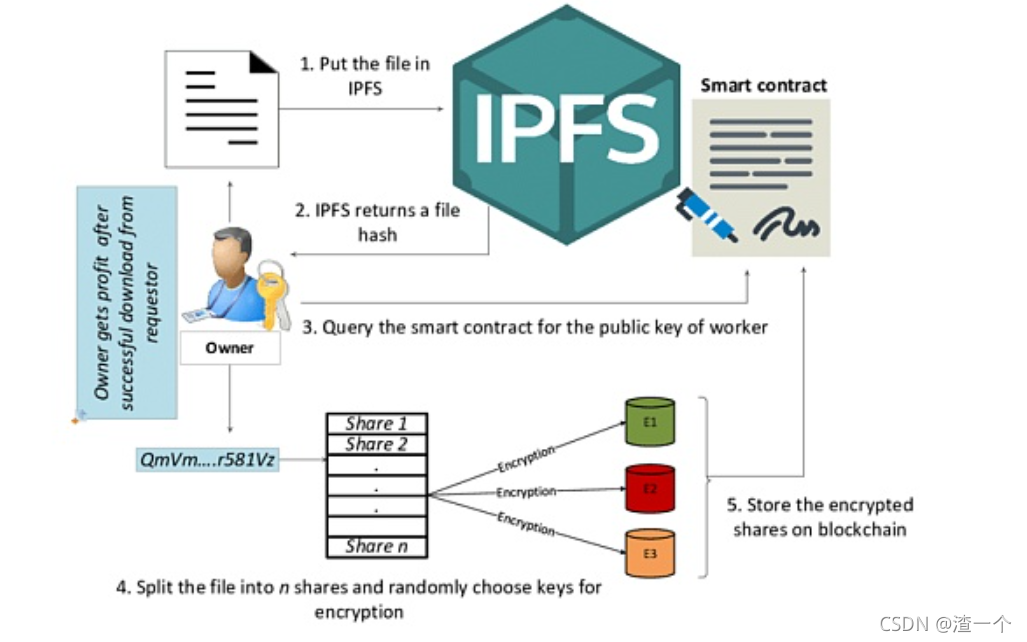
存储流程
1.将文件放入ipfs
2.ipfs返回一个文件哈希值
3.向智能合约查询工作者的公钥
4.将文件分成n份,并随机选择密钥进行加密
5.在区块链上存储加密后的份额
?
?