2021SC@SDUSC
вЛЁЂMerkleProof
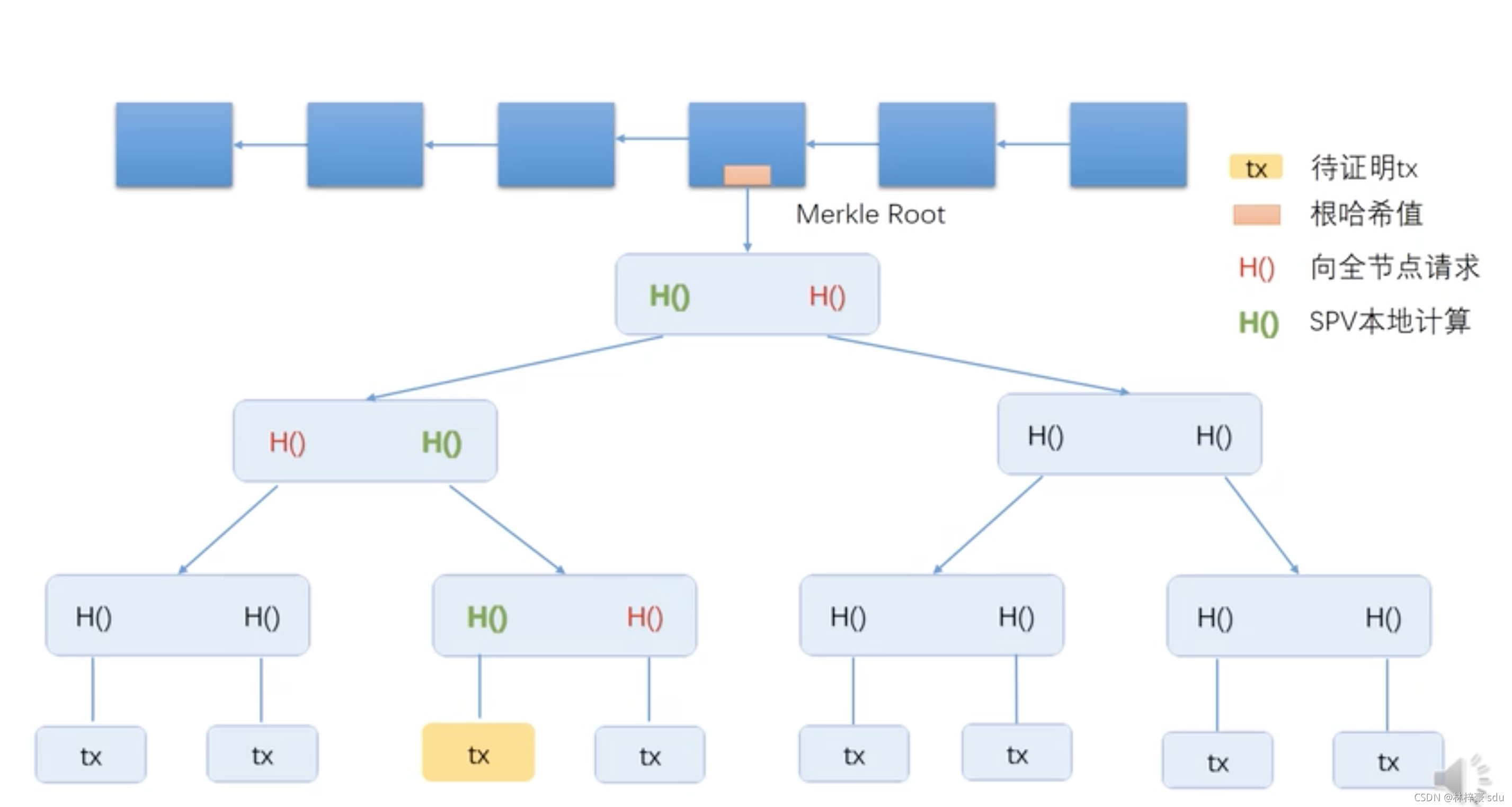
МйШчвЛИіЧсНкЕуЯыжЊЕРвЛИіЪТЮяаХЯЂЪЧЗёБЛБЃДцЕНСЫЧјПщжа,ЫќПЩвдЯђЭОжаЕФШЋНкЕуЗЂГіЧыЧѓ,етИіЧсНкЕуЛсБЛИјЕНЯТЭМжаШ§ИіКьЩЋЕФЙўЯЃжИеы,етбљЫћОЭПЩвддкБОЕиЫуГіТЬЩЋЕФЙўЯЃжИеы,МДгЩетИіЪТЮёЫуГіЕФЙўЯЃжЕ,ЫГзХвЖНкЕуОЭПЩвдевЕНMerkleTreeЕФИљНкЕу,ЖјетИіheaderОЭБЛБЃДцдкЧјПщСДЕФФГИіНкЕуЕБжаЁЃ
ФЧУДНгЯТРДЮвУЧОЭПДПДjdchainжаMerkleProofЕФФкШн,ШчЯТЗНДњТы:
package com.jd.blockchain.ledger;
public interface MerkleProof {
com.jd.blockchain.crypto.HashDigest getRootHash();
com.jd.blockchain.ledger.MerkleProofLevel[] getProofLevels();
com.jd.blockchain.crypto.HashDigest getDataHash();
}
ЮвУЧПЩвдПДЕНMerkleProofжаАќКЌзХШ§ИіНгПк,вЛИіЪЧHashDigest getRootHash()СэвЛИіЪЧgetDataHash();ЙЫУћЫМвх,ЮвУЧПЩвджЊЕРетИіЪТвЛИіЛёШЁИљНкЕуЛёШЁЙўЯЃЕФЪ§ОнЕФЗНЗЈ;ОПЦфИљБО,ЮвУЧПЩвдПДЕНетУДСНИіНгПк,ЕквЛИіЙигкзжНкађСаЕФНгПк,етИіНгПкЖЈвхСЫMerkleTreeЕФЮВВПЪТЮяађСа,ОпгаВЛДцдкжЄУїЕФжАФмЁЃЕкЖўИіНгПкПЩвдЪЙЪТЮёСЌај,етбљПЩвдЗРжЙЫћШЫДлИФЁЃ
public interface ByteSequence {
int size();
byte byteAt(int index);
default boolean equal(byte[] data) { /* compiled code */ }
utils.ByteSequence subSequence(int start, int end);
int copyTo(int srcOffset, byte[] dest, int destOffset, int length);
default int copyTo(byte[] dest, int destOffset, int length) { /* compiled code */ }
}
public interface BytesSerializable {
byte[] toBytes();
}
ЮвУЧЛЙПЩвдПДЕНвЛИіgetProofLevels();,етИіЪЧЪїЕФlevelЪЧАДееЕЙжУЕФЗНЪНМЦЫу,ЖјВЛЪЧвдИљНкЕуЕФОрРыКтСП,МДвЖзгНкЕуЕФ level ЪЧ 0; ЫљгаЕФЪ§ОнЕФЙўЯЃЫїв§ЖМвдвЖзгНкЕуНјааМЧТМУПвЛИіЪ§ОнНкЕуЖМвдБъМЧвЛИіађСаКХ(Sequence Number, ЫѕаДЮЊ SN),ВЂАДееађСаКХЕФДѓаЁЭГвЛЕидк level 0;
ЯТУцЕФДњТыЮвУЧПЩвдПДГі,ЫќЭЌбљЕїгУСЫHashDigestЕФЗНЗЈ,ЛёШЁСЫНкЕуЕФnode,гУРДБцБ№MerkleЪїЕФВуМЖЁЃ
public interface MerkleProofLevel {
int getProofPoint();
com.jd.blockchain.crypto.HashDigest[] getHashNodes();
}
ЖўЁЂMerkleSortTree
ЪзЯШетИіРрimplementsСЫTransactionalЕФНгПк,етИіНгПкЕФжАФмОЭЛљБОЪЧИќаТ,ЬсНЛ,ЩОГ§ЕФЪТЮяЁЃ
public interface Transactional {
boolean isUpdated();
void commit();
void cancel();
}
ФЌПЫЖћХХађЪї;ЫљгаЕФЪ§ОнЕФЙўЯЃЫїв§ЖМвдвЖзгНкЕуНјааМЧТМ;ЫцзХЪ§ОнНкЕуЕФдіМг,ећПУЪївдЕЙжУЗНЪНЯђЩЯдіГЄ(ИљНкЕудкЩЯ,вЖзгНкЕудкЯТ),ДЫЩшМЦДјРДЯджјЬиадЪЧвбгаНкЕуЕФаХЯЂЖМПЩвдВЛБиаоИФ;ЕЋгЩгкЖдЕЅИіеЫБОжаЕФаДШыЙ§ГЬБЛЩшМЦЮЊЭЌВНаДШы,вђЖјЗЧЯпГЬАВШЋЕФЩшМЦВЂВЛЛсгАЯьдкДЫГЁОАЯТЕФЪЙгУ,ЖјЧвгЩгкЪЁШЅСЫЯпГЬМфЭЌВНВйзї,ЗДЖјЬсЩ§СЫадФм;
ЙЙНЈСЫвЛИіПеЕФЪї
public MerkleSortTree(TreeOptions options, String keyPrefix, ExPolicyKVStorage kvStorage,BytesConverter<T> converter) {
this(TreeDegree.D3, options, Bytes.fromString(keyPrefix), kvStorage, converter);
}
ДДНЈСЫвЛИіMerkleSortTree:
rootHash НкЕуЕФИљHash;
ШчЙћжИЖЈЮЊ null,дђЪЕМЪЩЯДДНЈвЛИіПеЕФ Merkle Tree;
options ЪїЕФХфжУбЁЯю;
keyPrefix ДцДЂЪ§ОнЕФ key ЕФЧАзК;
kvStorage БЃДц Merkle НкЕуЕФДцДЂЗўЮё;
converter ФЌПЫЖћЪїЕФзЊЛЛЦї;
dataPolicy Ъ§ОнНкЕуЕФДІРэВпТд;
ПЩвдЭЈЙ§ИќИФsettingРДДДНЈВЛЭЌЪ§ОнРраЭЕФЪї
public MerkleSortTree(HashDigest rootHash, TreeOptions options, Bytes keyPrefix, ExPolicyKVStorage kvStorage,
BytesConverter<T> converter, DataPolicy<T> dataPolicy) {
this.KEY_PREFIX = keyPrefix;
this.OPTIONS = options;
this.KV_STORAGE = kvStorage;
this.DEFAULT_HASH_FUNCTION = Crypto.getHashFunction(options.getDefaultHashAlgorithm());
this.CONVERTER = converter;
this.DATA_POLICY = dataPolicy;
MerkleIndex merkleIndex = loadMerkleEntry(rootHash);
int subtreeCount = merkleIndex.getChildCounts().length;
TreeDegree degree = null;
for (TreeDegree td : TreeDegree.values()) {
if (td.DEGREEE == subtreeCount) {
degree = td;
}
}
if (degree == null) {
throw new MerkleProofException("The root node with hash[" + rootHash.toBase58() + "] has wrong degree!");
}
this.DEGREE = degree.DEGREEE;
this.MAX_LEVEL = degree.MAX_DEPTH;
this.MAX_COUNT = MathUtils.power(DEGREE, MAX_LEVEL);
this.root = new PathNode(rootHash, merkleIndex, this);
refreshMaxId();
}
ДгжИЖЈЕФФЌПЫЖћЫїв§ПЊЪМ,ЫбЫїжИЖЈ id ЕФЪ§Он,ВЂМЧТМЫбЫїОЙ§ЕФНкЕуЕФЙўЯЃ;ШчЙћЪ§ОнВЛДцдк,дђЗЕЛи null;
merkleIndex ПЊЪМЫбЫїЕФФЌПЫЖћЫїв§НкЕу;
id вЊВщевЕФЪ§ОнЕФ id;
pathSelector ТЗОЖбЁдёЦї,МЧТМЫбЫїЙ§ГЬОЙ§ЕФФЌПЫЖћНкЕу;
ЫбЫїЕНЕФжИЖЈ ID ЕФЪ§Он;
private T seekData(MerkleIndex merkleIndex, long id, MerkleEntrySelector pathSelector) {
int idx = index(id, merkleIndex);
if (idx < 0) {
return null;
}
if (merkleIndex.getStep() > 1) {
MerkleIndex child;
if (merkleIndex instanceof PathNode) {
PathNode path = (PathNode) merkleIndex;
child = path.getChild(idx);
if (child == null) {
return null;
}
HashDigest childHash = path.getChildHashs()[idx];
pathSelector.accept(childHash, child);
} else {
HashDigest[] childHashs = merkleIndex.getChildHashs();
HashDigest childHash = childHashs[idx];
if (childHash == null) {
return null;
}
child = loadMerkleEntry(childHash);
pathSelector.accept(childHash, child);
}
return seekData((MerkleIndex) child, id, pathSelector);
}
// leaf node;
T child;
if (merkleIndex instanceof LeafNode) {
@SuppressWarnings("unchecked")
LeafNode<T> path = (LeafNode<T>) merkleIndex;
child = path.getChild(idx);
} else {
HashDigest[] childHashs = merkleIndex.getChildHashs();
HashDigest childHash = childHashs[idx];
if (childHash == null) {
return null;
}
child = CONVERTER.fromBytes(loadNodeBytes(childHash));
}
return child;
}
КЯВЂжИЖЈЕФЫїв§НкЕуКЭЪ§ОнНкЕу
indexNodeHash Ыїв§НкЕуЕФЙўЯЃ;
indexNode Ыїв§НкЕу;
dataId Ъ§ОнНкЕуЕФ id;
data Ъ§Он;
ЗЕЛиЙВЭЌЕФИИНкЕу;ШчЙћЮДИќаТЪ§Он,дђЗЕЛи null;
private MerkleNode mergeChildren(HashDigest indexNodeHash, MerkleIndex indexNode, long dataId, T data) {
final long PATH_OFFSET = indexNode.getOffset();
final long PATH_STEP = indexNode.getStep();
long pathId = PATH_OFFSET;
long dataOffset = calculateOffset(dataId, PATH_STEP);
long pathOffset = PATH_OFFSET;
long step = PATH_STEP;
while (dataOffset != pathOffset) {
step = upStep(step);
if (step >= MAX_COUNT) {
throw new IllegalStateException("The 'step' overflows!");
}
dataOffset = calculateOffset(dataId, step);
pathOffset = calculateOffset(pathId, step);
}
// ХаЖЯВЮЪ§жИЖЈЕФЫїв§НкЕуКЭЪ§ОнНкЕуЪЧЗёОпгаДгЪєЙиЯЕ,ЛЙЪЧВЂСаЙиЯЕ;
if (step == PATH_STEP && pathOffset == PATH_OFFSET) {
// Ъ§ОнНкЕуЪєгк pathNode ТЗОЖНкЕу;
// АбЪ§ОнНкЕуКЯВЂЕН pathNode ТЗОЖНкЕу;
int index = index(dataId, pathOffset, step);
if (PATH_STEP > 1) {
PathNode parentNode;
if (indexNode instanceof PathNode) {
parentNode = (PathNode) indexNode;
} else {
parentNode = new PathNode(indexNodeHash, indexNode, this);
}
boolean ok = updateChildAtIndex(parentNode, index, dataId, data);
return ok ? parentNode : null;
} else {
// while PATH_STEP == 1, this index node is leaf;
LeafNode<T> parentNode;
if (indexNode instanceof LeafNode) {
parentNode = (LeafNode<T>) indexNode;
} else {
parentNode = new LeafNode<T>(indexNodeHash, indexNode, this);
}
boolean ok = updateChildAtIndex(parentNode, index, dataId, data);
return ok ? parentNode : null;
}
} else {
// Ъ§ОнНкЕуВЛДгЪєгк pathNode ТЗОЖНкЕу,ЫќУЧгаЙВЭЌЕФИИНкЕу;
// ДДНЈЙВЭЌЕФИИНкЕу;
PathNode parentPathNode = new PathNode(pathOffset, step, this);
int dataChildIndex = parentPathNode.index(dataId);
boolean ok = updateChildAtIndex(parentPathNode, dataChildIndex, dataId, data);
if (!ok) {
return null;
}
int pathChildIndex = parentPathNode.index(pathId);
updateChildAtIndex(parentPathNode, pathChildIndex, indexNodeHash, indexNode);
return parentPathNode;
}
}
етИіЪЧвЛИіХаЖЯзгНкЕуЪЧЗёвчГі,ЛђГЌГіЗЖЮЇЕФЗНЗЈЁЃ
public long skip(long count) {
if (count < 0) {
throw new IllegalArgumentException("The specified count is out of bound!");
}
if (count == 0) {
return 0;
}
if (childIndex >= TREE.DEGREE) {
return 0;
}
long s = ArrayUtils.sum(childCounts, 0, childIndex + 1);
long skipped;// ЪЕМЪПЩТдЙ§ЕФЪ§СП;
long currLeft = s - cursor - 1;
if (count < currLeft) {
// ЪЕМЪТдЙ§ЕФЪ§СПдк index жИЪОЕФЕБЧАзгНкЕуЕФЗЖЮЇФк;
if (childIterator == null) {
childIterator = createChildIterator(childIndex);
}
skipped = count;
long sk = childIterator.skip(skipped);
assert sk == skipped;
} else {
// вбОГЌЙ§ index жИЪОЕФЕБЧАзгНкЕуЕФЪЃгрЪ§СП,жБНгКіТдЕБЧАзгНкЕу;
childIterator = null;
skipped = currLeft;
childIndex++;
while (childIndex < TREE.DEGREE && skipped + childCounts[childIndex] <= count) {
skipped += childCounts[childIndex];
childIndex++;
}
if (childIndex < TREE.DEGREE) {
// ЮДГЌГізгНкЕуЕФЗЖЮЇ;
long c = count - skipped;
childIterator = createChildIterator(childIndex);
long sk = childIterator.skip(c);
assert sk == c;
skipped = count;
}
}
cursor = cursor + skipped;
return skipped;
}