第五讲 比特币系统的实现
区块链是去中心化的账本,比特币使用的是基于交易的这种账本模式(transaction-based- ledger)每个区块里记录的是交易信息。有转账交易,有铸币交易。但是系统当中并不会显示每个账户有多少钱。
比如说你要知道A这个账户有多少钱,那我们只能通过交易来推算A账户有多少钱。
比特币系统的全节点要维护一个叫UTXO的数据结构(unspent transaction output)(还没有被花出去的交易的输出)
区块链上有很多交易,有些交易的输出可能已经被花掉,有些还没有被花掉。所有没有被花掉的输出的集合就叫做UTXO。
一个交易可能有多个输出。假如A给B5个比特币,B花掉了。A也给了C3个比特币,C没有花掉。这时5个比特币就不算UTXO,而3个比特币算。同一个交易有的输出在,有的输出不在里面。
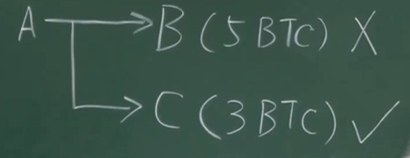
UTXO集合当中的每个元素要给出产生输出的交易的哈希值,以及它在这个交易里是第几个输出。这两个信息就可以定位到UTXO中的输出。
那么要着UTXO干什么用呢?为什么要维护这么一个数据结构?
为了检测double spending(为了防止双花攻击)。即检测新发布的交易是否合法。因为花掉的币只有在UTXO里面才是合法的,如果不在集合里面,要么花掉的这个币不存在要么就是以前已经被花过了。因此全节点要在内存中维护UTXO这样一个数据结构,以便快速检测double spending。
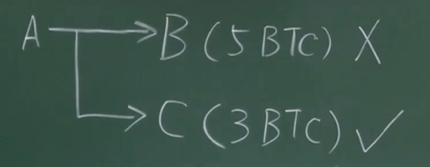
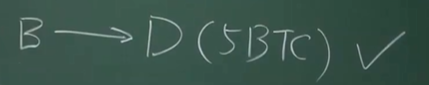
每个交易要消耗掉一部分输出,也会产生新的输出。还看上面的例子,B花掉的5个比特币虽然不在UTXO里面,但如果他转账给D,又产生一个新的输出,又要保存在UTXO里面。
随着交易的发布,每个交易都会消耗UTXO作为输出,但是又会产生新的输出。
如果有人收到比特币的交易之后始终都不花,那么这个信息就要永久的 保存在UTXO里面。可能有人不想花(像创始人中本聪),那么这个信息要永久保存在UTXO里面。也有可能想花没法花,例如把密钥丢了,也是永久保存在UTXO里面。
每个交易可以有多个输入,也可以有多个输出,但是所有输入金额之和要等于输出金额之和。即total inputs=total outputs。
我们上面那个例子是给出了多个输出的,输入也可能有多个输入,而且多个输入不一定来自于同一个地址。这也是为什么一个输入有可能有多个签名,每个输入地址都要提供对应的地址。
有些交易total inputs略微大于total outputs。假如输入1比特币,输出0.99比特币,另外0.01比特币作为交易费给获得记账权发布区块的节点。
为什么节点要消耗计算资源来竞争记账权?
因为获得出块奖励,你发布一个区块,可以有一个coinbase transaction,获得一定数量的比特币作为报酬,所谓的reward block。
但是光有这个出块奖励是不够的,发布区块的那个节点为什么要把你的交易打包到区块里?这样做对它有什么好处呢?
比如某个比较自私的节点,它可能发布区块的时候只包含它自己的那些交易,别的交易都不管,因为把别的交易打包进去的话对他来说没有什么好处,而且还有一定的代价,因为你要验证这个交易的合法性,而且你区块里如果装的交易多了的话,它占用的带宽也比较多,在网络上传播的速度也会慢,所以如果只有出块奖励的话,这个节点比较自私的话,它就不管别人的交易,它只管自己的交易。
所以比特币设计了一个新的交易机制,就是交易费(transaction fee)。
这个可以理解成就是一种小费,你把我的交易打包在区块里,我给你一些小费。目前比特币种交易费一般很小,也有一些简单的交易没有交易费。(0.01就算比较大的了)
目前来说矿工去挖矿,去争夺这个记账权主要的目的还是为了争夺这个出块奖励,因为那个有12.5个比特币,但是出块奖励是逐渐减小的,每隔21万个区块要减半。21万个区块大概要挖多长时间呢?大约是4年。比特币系统设计的平均出块时间是10分钟,就是整个系统平均10分钟会产生一个新的区块。
除了比特币这种基于交易的模式,与之对应的还有基于账户的模式(account-based ledger),比如以太坊系统。在这种模式中,系统是要显示的记录每个账户上有多少币。比特币基于交易的模式,隐私保护性较好。缺点是比特币当中的转账交易要说明币的来源,而基于账户的模式就不用。
为什么要说明币的来源?
比如你要转20个比特币,谁知道你有没有这20个比特币,因为没有账户记录你一共有多少个比特币,你要说明来源,来确保有足够的比特币。
下面这张图描述了一个区块链例子
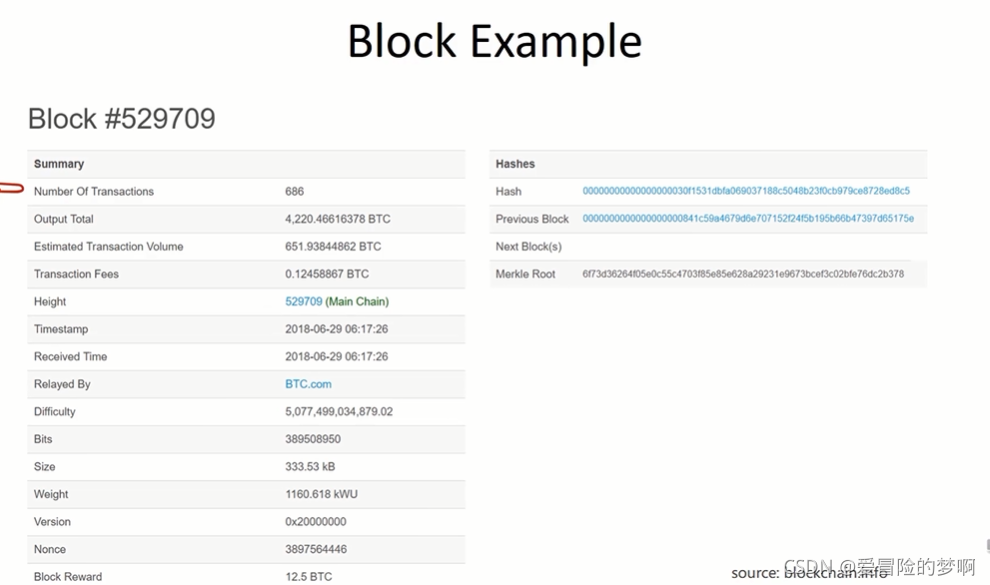
第一行表明:该区块包含了686个交易
第二行:总输出XXX个比特币
第四行:总交易费(686个交易的交易费之和)
最下面一行:区块奖励(矿工挖矿的主要动力) (出块奖励差不多是交易费的100倍占大头)
第五行Height:区块的序号
第六行Timestamp:区块的时间戳
第九行:挖矿的难度(每隔2016个区块要调整挖矿的难度,保持出块时间在10分钟左右)
倒数第二行:挖矿时尝试的随机数,图中的是复合难度的要求的随机数
右边:第一行:该区块块头的哈希值
第二行:前一个区块块头的哈希值 (计算哈希值的时候都是只算block head)
两个哈希值的共同点:前面都有一串0。是因为,设置的目标预值,表示成16进制,就是前面一长串的0。所谓的挖矿就是不断调整,所以凡是符合难度要求的区块,块头的哈希值算出来都是要有一长串的0。
第四行:merkle root 是该区块中包含的那些交易构成的merkle tree的根哈希值。
下图是块头的数据结构

最后一行:是32位的无符号整数。挖矿的时候要调整这个nNonce,但是这个nNonce只有2的32次方个可能的取值。按照比特币现在的挖矿情况来说,很可能把2的32次方个取值都遍历一遍也找不到合适的。因为现在随着挖矿的人越来越多,挖矿的难度也是越来越大。
那怎么办呢?block header 的数据结构里还有哪些域是可以调整的呢?
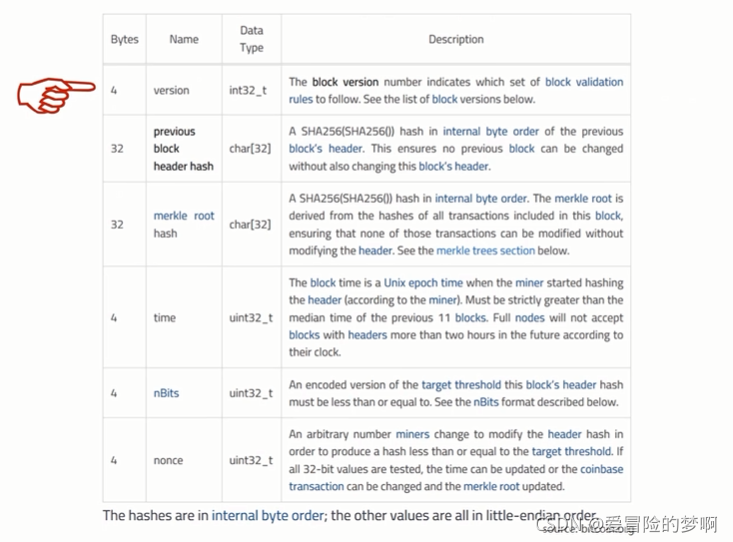
第一行:比特币协议的版本号(无法更改的)
第二行:前一个区块的块头的哈希值(无法更改)
第三行:merkle tree的根哈希值(可以更改)
第四行:区块产生的时间(可以调整)比特币系统不要求特别精确的时间,可以在一定范围内调整。
第五行:目标预值(编码后的版本)(只能按协议中的要求定期调整)
第六行:随机数