�������ҽ���������ǹ��ڹ����������û������,����������Ŀ�ǡ�����������ע������:����̫���û����з�����ȥ��������
����Ŀ¼
??2009��,���رҵ����ˡ����ĵ���������һ���µ�ȥ���Ļ�����ģʽ���ڱ��رҵĽ���ģʽ��,����¼��������,���Ե�ַ�������˻�������ֻ�ܿ�����ַ֮��Ľ�����Ϣ,��������ȡʹ���ߵ�������Ϣ,����û�����˽�Եõ��˼���ı�֤��
?? ����,���������Ը����Ҽ�ܻ��������˼���IJ���,����:ϴǮ����˽����Ʒ���ȷǷ����������������ģʽ�º�����ʶ�����,�����رҽ���ȥ��������һ��dz��б�Ҫ�ġ�
?? ���������ȥ����������,������ƪ���ĵ���������̫��������һЩ̽��,�������һЩ�µĽ��˼·��
?? ������,�ҽ�����������������н���:��ظ���,����ʵ�鷽�������,���������ݷ������û�������˼����
��ظ���
��ʶ�� Quasi-identifier
?? �����Ա�����ʽ��ʾ,ÿһ�б�ʾһ����¼(record),ÿһ�б�ʾһ������(attribute)��ÿһ����¼��һ���ض��û�/�����������Щ���Կ��Է�Ϊ����:1. ��ʶ��:��ֱ��ȷ��һ������,��:����֤��;2.��ʶ����:���Ժ��ⲿ��������ʶ��������С���Լ�,��:ͼ1{�ʱ�,����};3.��������:�û���ϣ������֪��������,������Ϊ���ݱ��г��˱�ʶ������ʶ��֮�ⶼ����������,��ͼ2��disease��
?? ���������ݱ�ʱ,Ӧ�����û����������ݱ�����,Ҳ�������ù۲����߽�ij����¼��һ��ȷ�����û���ϵ��������Ϣ����(information disclosure)���Է�Ϊ����:1. ���ݹ���::ָ���Խ��û����ض���¼��ϵ����;2.���Թ���:���¹�������Ϣ����ʹ�۲��߸�ȷ���Ʋ��û�������ʱ,�Ʒ��������Թ�����
?? ����ͼ��ʾ,ͼ2��ͼ1����k-���������������,��ʹ��ͬһ�ȼ����м�¼�����������Բ���������k-1����¼�����֡�


ȥ������De-anonymization
??ȥ��������ָһ�������ھ����,���е��������ݺ�����������Դ�����������ʶ��������������Դ������һ��������Դ����һ��������Դ����һ��Ϣ��������ȥ��������
?? ����������Ҫ���������Ϊ��,��Ϊ��������ͼ�ṹ�ں���ὲ������������ȥ��������Ҫ��Ե��ǽڵ��ȥ������,ʶ��һ���ڵ���ǻ��һ���˵���ʵ��Ϣ��������������ȥ�������������Է�Ϊ����,һ���ǻ���ӳ��ķ���,��һ���ǻ��ڲ²�ķ���������ӳ��ķ����ǽ��������˽�Ļ���ȡ�õ�����ʵ����ṹ�빫���ľ���������������ṹ�������ڵ�ƥ�䡣���ڲ²�ķ����������ù�������֪�ı���֪ʶ�ڹ����������ҵ����ϵ�һ�������ڵ㡣������������ȥ������ʵ���������ǵ�ַƥ�����˵�ڵ�ƥ�䡣

�û����� User Profiling
??�û�����,���û���Ϣ��ǩ��,������ҵͨ���ռ������������������ԡ�����ϰ�ߡ�������Ϊ����Ҫ��Ϣ������֮������һ���û�����ҵȫò��

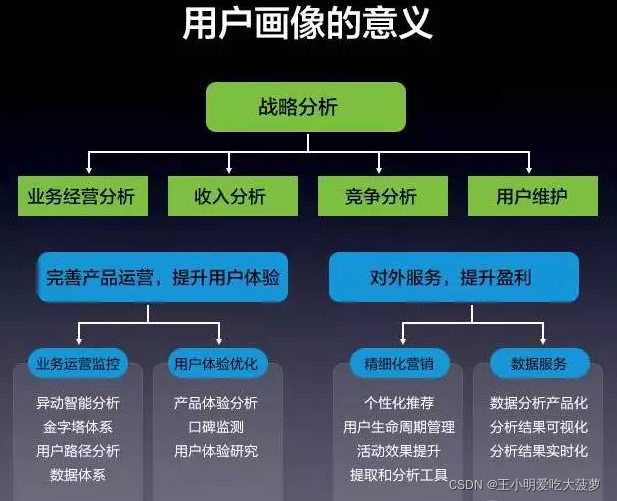
�ڵ�Ƕ�� Node Embedding
??��ʽ�Ͻ�,Embedding������һ����ά���ܵ���������ʾ��һ������,������˵�Ķ��������һ����(Word2Vec),Ҳ������һ����Ʒ(Item2Vec),����������ϵ�еĽڵ�(Graph Embedding)�����С���ʾ���������ζ��Embedding�����ܹ�������Ӧ�����ijЩ����,ͬʱ����֮��ľ��뷴ӳ�˶���֮��������ԡ�����˵��ֱ��һ��,������һ������Embedding��һ������ӳ���һ������,���������������,��ô�õ�����������ͻ��С������ټ�������:
- Word Embedding: ������ӳ�������:�����������˼���,���������ŷʽ�����С
- User Embedding: ���û�ӳ�������,����û���Ϊϰ�߽ӽ�,��������ŷʽ�����С
?? ֪��ʲô��Embedding֮��,���ǿ�ʼ����Node Embedding�ˡ��ڴ�ͳ����ѧϰ������,������Ҫ����������������ȡָ��������,�����������仯��,��ȡ������Ҳ��Ҫ�仯,Ҳ������������������
?? ����Ȼ,��ͳ����ѧϰ�㷨������ȡͼ�ṹ���ݵ������ġ���Ϊ,ͼ��������Ϣ�ܶ�����ʽ�ġ�����ġ���ά�ġ��������صġ����,������Ҫ����ͼ��ʾѧϰ����ά����Ϣ��ά����ά�ȿռ�,ͬʱ�����ԭ��ͼԭ���Ľṹ��Ϣ������,������һ������Ҫ��һ���ŵ�����������˶��������������,����Ҫ��Բ�ͬ������ÿ�ζ����в�ͬ��������ȡ��
?? ���,���ǿ���ʹ��Node Embedding��ͼ�нڵ�ӳ�䵽һ�������ռ�,ͬʱ���ֽڵ��ijЩ���ʡ�
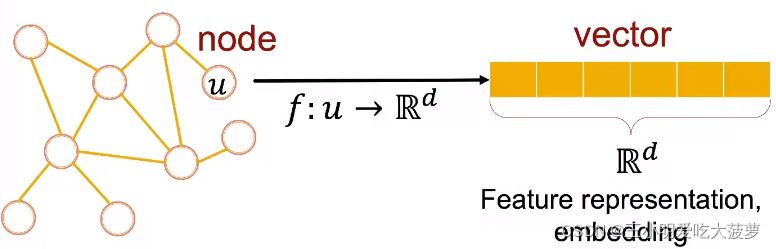

??���ڵ�ӳ�䵽�����ռ�֮��Ϳ��Խ��и������������ˡ�

Danaan-Gift Attack
?? Danaan-Gift attack �״��ڡ�Privacy Aspects and Subliminal Channels in Zcash���б����,������˼��˵:��������Ŀ���shielded address������������Ⱦ��zcash,��Ŀ��de-shieldedʱ��Щֵ�ᱣ������,��ǵ����á�����������һ����ʵ:zcash�Ľ���ֵ��ȷ�Ⱥܸ�,���λ����û�о�������,���ǿ��Ա�����fingerprint value��
?? �����ߵĶ�����,����ֵ��ָ�������� Zatoshis �е���� 7 λ����,���������4λ�����ر��ȶ������������λ���ֵ��ڽ����ż�����,������û��ʲô��������,ֻ��������ǰ���IJ��ࡣ��������������,���֧��������ȫ���ȼ����,��˻��������Ч�����в�������ֲ�,����fingerprint value�Ķ����Կ��Եõ���֤�������ߵ�ʵ����,������Ϊ������7λ����5λ����ͬ��,�������4λ������ȵ�,������fingerprint value����ƥ��ġ�
����ʵ�������
?? ����������Ҫ��������ʵ��:��̫���û�������ȥ���������Ի�ҷ������ȥ����������̫���ϵ�Danaan-Gift������
ʵ������
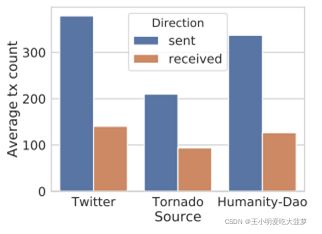
?? ����ʵ��������ETH��ַΪ����,��Դ������:Twitter API��Humanity DAO��TC mixer contracts�������ռ�����ַ֮��ͨ��ETH�����������ѯ������Ϣ��Humanity DAO��������Ϊһ��ʵ��,�����������߽���ȥ���Ļ��ĵǼ���ע��;TC mixer contracts
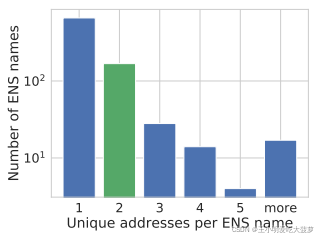
- Twitter API�ṩ��������ENS names,ÿ��ENS names������һ���������ݹ���
- Humanity DAO��������Ϊһ��ʵ��,�����������߽���ȥ���Ļ��ĵǼ���ע��
- TC mixer contracts��һ����Һ�Լ,��������߽��ȶ��ʽ���뵽��Լ��,�����һ��������
��������
?? ���ĵ���������������,һ����AUC,����һ���������档
AUC
?? ����ǰ����ʵ��,�㷨��Ϊ���Լ��е�ÿ���˻�����һ����ѡ�Ե������б�,ÿ�������б�����ֻ��һ������ȷƥ���,��AUC���Ա�ʾΪ��ʽ:
A
U
C
=
a
v
g
(
r
(
a
)
�O
c
(
a
)
�O
)
AUC=avg(\frac{r(a)}{|c(a)|})
AUC=avg(�Oc(a)�Or(a)?) over all
a
a
a, and
r
(
a
)
r(a)
r(a) is the rank of correct pair.
������
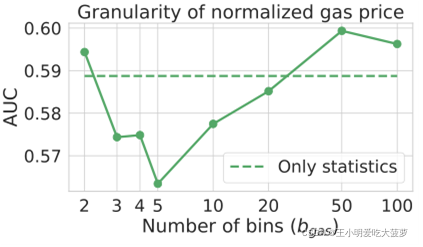
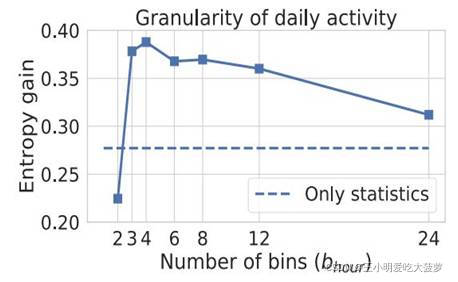
?? ���˺���ƥ���AUC֮��,����������ȥ������ƥ���������˽��ʧ��������,��������ؽ�������õ���Ϣ��ʾΪ������,�������غͺ����صIJ��졣ע:��������ָû��ʹ��ȥ����������������TC mixer contracts��˵,�������Ĵ�С�Ƕ�̬�仯��,���������Ҫ����֤���������Ĵ�С�������DZȽ���������û��Ӱ��ġ�
��֤:������������С��������û��Ӱ��
��
=
g
a
i
n
(
2
n
,
p
)
?
g
a
i
n
(
n
,
p
)
\Delta=gain(2n,p)-gain(n,p)
��=gain(2n,p)?gain(n,p),�����ڸ��ʷֲ�Ϊp��������,�Դ�СΪ2n��n�����������������������������ʷֲ���ƽ����,��������Χ�ڱ仯��С,��ô�����IJ�ֵ�ͻ��С,�Ϳ��Խ�����Ϊ������������С��������û��Ӱ�졣
�ƶϺ�����ʷֲ�
?? ����ÿ����СΪ
n
n
n����ȷƥ�������Ϊ
r
r
r��������,�����
P
(
n
,
r
)
P(n,r)
P(n,r)��
[
(
r
?
1
)
/
n
,
r
/
n
]
[(r-1)/n,r/n]
[(r?1)/n,r/n]���ȷֲ���������ʷֲ�����
P
(
n
,
r
)
P(n,r)
P(n,r)��ƽ��ֵ��ע:ǰ��˵���㷨Ϊÿ���˻����غ�ѡ���б�,��ʵ������������
����������
ʵ��һ:��̫���û��������
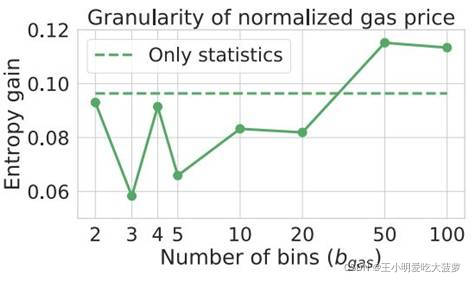
?? ����ѡ��ǡ����������ַ��ENS names,����ѡ������ʶ��:����ʱ�䡢���ͷѡ���̫������ͼλ�ý����û��������,�������ͬһ�û����˻�����������
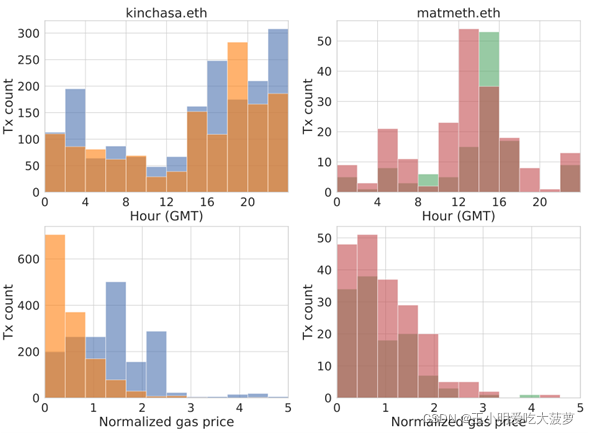
?? �ڽ��н���ͼ������ʱ��,�����������Ȳ��ýڵ�Ƕ��ķ�����ͬһ�û����˻�����ƥ��ʶ��,��ͬ��ʹ������������ʶ������ʶ��ķ������жԱȡ�

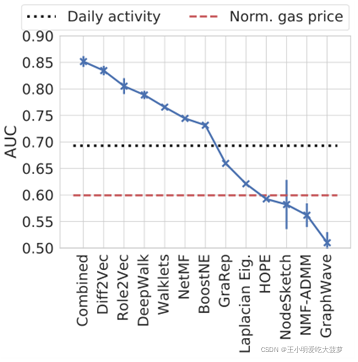
?? �ڽ��н���ͼ������ʱ��,�����������Ȳ��ýڵ�Ƕ��ķ�����ͬһ�û����˻�����ƥ��ʶ��,��ͬ��ʹ������������ʶ������ʶ��ķ������жԱȡ�

������:�Ի�ҷ������ȥ������
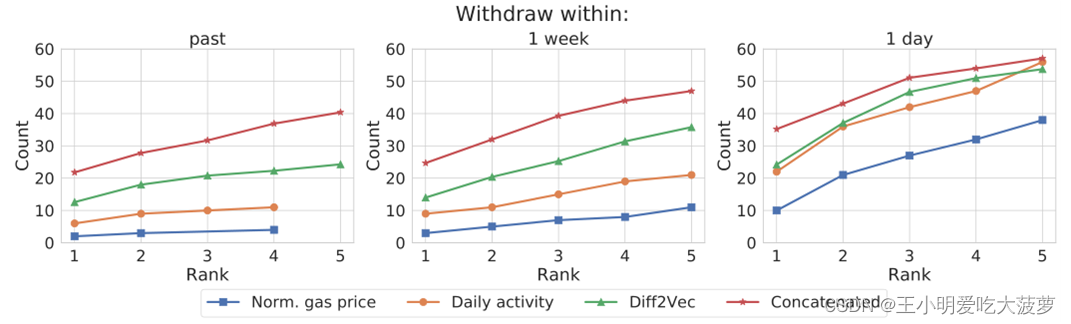
??��TC mixer contracts�Ļ�ҷ�����,�����ַ����ص�ַ���ܴ����ظ�ʹ�õ����,��ᵼ����˽����ķ��ա�����,���߲��ýڵ�Ƕ�뷽������ȥ������,�����ҵ������ַ��Ӧ����ص�ַ��
������:��̫���ϵ�Danaan-Gift����
??���߶���̫���Ͻ���Danaan-Gift��������һ��ָ�ƴ����ʵķ���,˵��������̫�����иù����Ŀ����ԡ�

������ȥ���������û�����˼��
��ַ�����֪��������
?? ��ַ�����������һ���������Ե�ָ��,��Ϊ�������еĵ�ַ��ͬ����Ҫ�����״�����һ��������ʱ��ת�˵ĵ�ַ,��Ȼ���ܺ���һ�����ڳ����ʲ���Ǯ����ַ���Ტ�ۡ�
������ vs. �ɽ����
?? �����������ݼ�����������ɽ����֮���Ħ�������˵���Ƚ�С��һ�����������ݼ���������Խ��,���л�ȡ���������Ϣ���ѶȾ�Խ��
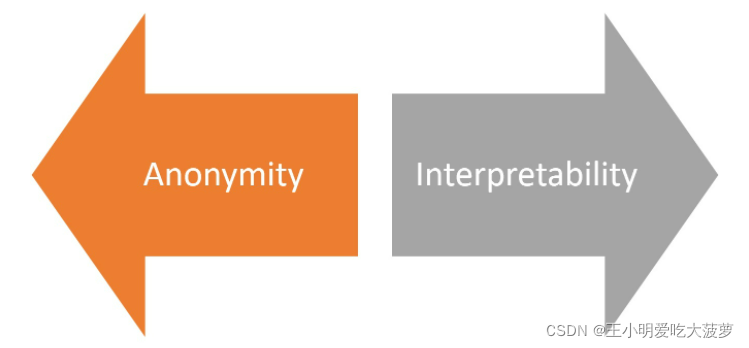
ȥ������ vs. ��˽����
ȥ���������������ݼ������漰�˽�ÿ�������ߵ���ʵ���ݡ�������ʲô��Զ�ȡ�����˭��Ҫ��Ҫ��

