Decentralized Collaborative Learning Framework for Next POI Recommendation
1. What does literature study?
- Ϊ�˴ٽ�Э��ѧϰ,��������Ե����ϻ����������Ƶ��û���֪ʶ���ϵ�ÿһ������ģ����,�Խ��оۺϺͻ���Ϣ���
2. What��s the innovation?
1. Past shortcomings
- ��Դ�ĸ�����:�Է�������˵�����Ĺ���Ĵ洢�ռ�ͼ�����Դ��
- ��˽����:POI�Ƽ�����ʷ�Ǽ����ݻ�ֱ����ʾ�û��������켣��
- weak ����:����ʽPOI�Ƽ��߶������������ĺͻ��������ӵ��ȶ��ԡ�һ��������������߹���ӵ��,��������������֤,�Ƽ�������ȷ����ʱ��,���������ѻ���
- POI�Ƽ�����������Ȼ�Ǵ洢�ͼ�����Դ�ܼ���,��������û��ռ�����Ȥ�Ķ�̬�ԡ������ԡ�
2. innovation:
- ������POI�Ƽ��ķֲ�ʽЭͬѧϰ���DCLR,�û����ݴ洢����,��С�������Ʒ�������
- ����������Լලѧϰ����������POI�ĵ�������Ժͷ����ǩ�IJ�����Ϣ,�Լ�������ϡ���ԡ�
- ���ڷ������ƺ͵��������������ָ����ʶ���ھӡ�����,��������ھ�ͨ�Ų�����ѧϰ�ھӵ�֪ʶ,�Խ��оۺϺͻ���Ϣ���
3. What was the methodology?
Э��ѧϰ���������豸֮���ͨ��,ͬʱ����Ҫ�������������������Ϳ���ʶ���û���,�����볣������˽��������(�����˽)����ݡ�
����������������ṩԤ��ѵ���IJ���(POI embeddings),��ȫ�ķ�ʽ�������û�����(���ھ�)��
��������:
����������Լල��Ԥѵ������:������͵�����Ϣע��POI��ʾ,��һ��������:ͨ��MIM(����Ϣ���)������POI������ط����ǩ֮��������;�ڶ���������:ͨ��ѧϰ��Ԥ��POI֮��ľ�������ǿPOI��ʾ����ѵ��POI embeddings��Ϊģ�Ͳ�����һ����,�������û��豸�Ͻ����������¡�
�ھ�ʶ�����:����,���������������������ʶ�������û�����Э��ѧϰ,����:�����ֲ������Ծ��������ھ�,����˵,�����û�֮������ֲ����ƶ�Խ��,����Խ�п������ھӡ�����:�����ϵ��ھ��������������,���������û�֮��ľ�������������֮�����С����,ͨ�������з��ʹ���POI���侭�Ⱥ�ά�Ƚ��о���,���һ���û��Ķ�����ġ�Ϊ�˼������ֲ����ƶȺ���������,������������豸���ռ����ֲ������ġ�

����Spatio-Temporal Attention Network (STAN) ʱ��ע�����硣
1. ���ڵ���λ���������Լලѧϰ:
ͨ��ע�������Ϣ����ǿPOI��ʾ,ÿ��POI
p
p
p��һ����������
(
l
o
n
p
,
l
a
t
p
)
(lon_p,lat_p)
(lonp?,latp?)�����,һ��POI֮����ʵ�������ͨ��Haversine��������:
d
i
s
(
p
i
,
p
j
)
=
H
a
v
e
r
s
i
n
e
(
(
l
o
n
p
i
,
l
a
t
p
i
)
,
(
l
o
n
p
j
,
l
a
t
p
j
)
)
dis(p_i,p_j)=Haversine((lon_{p_i},lat_{p_i}),(lon_{p_j},lat_{p_j}))
dis(pi?,pj?)=Haversine((lonpi??,latpi??),(lonpj??,latpj??)),��ͬ�ľ����в�ͬ�ı�ǩ,
��
5
\leq 5
��5Ϊsmall,
(
5
,
10
]
(5,10]
(5,10]Ϊ�м�,
>
10
>10
>10Ϊlage,����Ԥ��Ϊ:
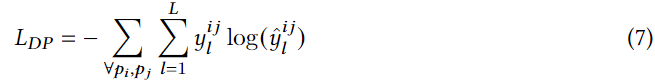
L��ʾ���������ǩ,
y
l
i
j
y_l^{ij}
ylij?�DZ�ǩ
l
l
l��one-hot indicator,
y
^
l
i
j
\hat{y}_l^{ij}
y^?lij?�DZ�ǩ
l
l
l��Ԥ�����,Lά���ʷֲ�
y
^
i
j
\hat{y}_{ij}
y^?ij?:
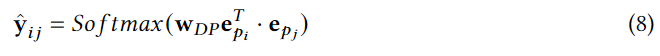
���� e p i e_{p_i} epi??�� e p j e_{p_j} epj??��POI p i p_i pi?�� p j p_j pj?��Ƕ��, w D P �� R 3 �� 1 w_{DP}\in \reals^{3��1} wDP?��R3��1�ǿ�ѧϰ����,�����豸��Դ��Ч,������POI�Խ��о���Ԥ��û������,���,ÿ��POI,ѵ�������������ѡ��Ķ̾��롢�о��롢������POI��
2. ����֪�Լලѧϰ:
ͨ�����û���Ϣ��������������Ϣ���ḻPOIǶ��,����Ϣ��ָ��������֮���������
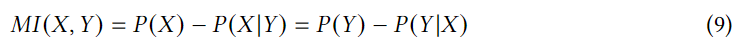
����ϢMI�û�ѧϰ������ʾ,���ǽ�һ��POI
p
p
p������ص����
c
c
c��ΪPOI��������ͼ,���һ�����Ԥ��(CP)��ʧ,�������������ͼ֮��Ļ���Ϣ:
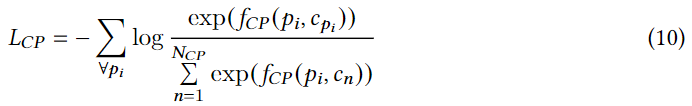
c
p
i
c_{p_i}
cpi??��һ��POI��ص����,
N
C
P
N_{CP}
NCP?��������
(
p
i
,
c
n
)
(p_i,c_n)
(pi?,cn?)�Ǵ����
C
\
c
p
i
C\text{\textbackslash}c_{p_i}
C\cpi??������,
f
C
P
(
)
f_{CP}()
fCP?()��POI �����֮��ijɶ������Ժ���,��DCLR��������һ�����б��������˫��������ʵ�֡�

����Ƕ��άPOI�����, W C P W_{CP} WCP?��һ����ѧϰ��������,ͨ���Ż���ʧ����,���ǿ��������������֮��Ļ���Ϣ,ͬʱ��С����������֮��Ļ���Ϣ��
3. ��˽��֪�ھ�ʶ��
���û��豸�����ھӽ���ͨ��,��Щ�ھ��뵱ǰ�û����ơ�������Ϊÿ���û�ִ���ھ�ʶ��,������ʽ�û�ƫ���������ھ�ʶ��
1. �����ھ�:
��POI�Ƽ��������,�����û���������ͬһ�����ij���,���Ǿ��кܸߵĵ��������ԡ�����ͨ�����������û�����POIs������(ƽ������)֮��ľ�����ʶ�������û�,����ԽС����������Խ�ߡ������������ʹ���POIs��������ͨ��k-means����Ϊÿ���û����ɶ������,���ĵ�������Ϊÿ���û�����Ӧȷ����,ʹ��û�з��ʹ���POI��������������ľ��볬������Ԥ�������ֵ��ÿ���û�
u
n
u_n
un?�����ļ���:
O
(
u
n
)
=
{
o
1
,
o
2
,
.
.
.
,
o
v
}
O(u_n)=\{ o^1,o^2,...,o^v \}
O(un?)={o1,o2,...,ov},ÿ���û�����������
v
v
v�Dz�ͬ��,��Ϊ��ͬ�û����ʵĵط��������͵���λ���϶���������ͬ�������û���������:
d
g
e
o
(
u
n
,
u
m
)
=
m
i
n
(
H
a
v
e
r
s
i
n
e
(
o
n
,
o
m
)
)
d_{geo}(u_n,u_m)=min(Haversine(o_n,o_m))
dgeo?(un?,um?)=min(Haversine(on?,om?))�����ľ��롣
2. �����ھ�:
���ʹ����Ƶĵط������û�������ͬ����Ȥ,��Щ�û�����Ϊ�����Ƶ�,�������ھӱ���Ϊ�����ھӡ���Ȼ���ƫ�ú�POI��ƫ�ö��ܷ�Ӧ�û�֮�����������,���������������ƫ����Ϊ�������ƶȵĶ�����:ӵ����ͬ��Ȥ���õ��˿��������Զ,��˲�̫�п��������Ƶ�POI��ƫ��;���û����ض�POIs�ϵ�check-in���,��������ϵĽ�������ܼ�,ʹ�����ƫ�ó�Ϊ��ȷ���������ƶ�ָ��;�����б�¶�û�POI��ƫ�ø���������˽й¶��
C
P
(
u
n
)
=
{
c
p
1
n
,
c
p
2
n
,
.
.
.
c
p
�O
C
�O
n
}
CP(u_n)=\{ cp_1^n, cp_2^n,...cp_{|C|}^n\}
CP(un?)={cp1n?,cp2n?,...cp�OC�On?}Ϊ�û���C��POI ����ϵķֲ�,����ֱ�Ӵ��û���ѵ�����������з��ʹ���POIs�л�á�����:һ�����ݼ����������,����Bar,Music,Steakhouse�û����ʹ�Bar2��,Music3��,Steakhouse5��,���û����ֲ�Ϊ
C
P
(
u
n
)
=
{
0.2
,
0.3
,
0.5
}
CP(u_n)=\{ 0.2, 0.3,0.5\}
CP(un?)={0.2,0.3,0.5},����KLɢ�������������û�����ƫ��֮��ľ���:
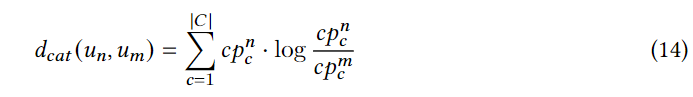
�������ܹ������κ�һ���û�֮��ĵ����ͷ������, D g e o , D c a t �� R �� 0 U �� U D_{geo},D_{cat} \in \reals_{\ge0}^{U��U} Dgeo?,Dcat?��R��0U��U?��ʾ���ɵĵ��������������,��������ĵ� i i i�б�ʾ�� n n n���û������������û�֮��ĵ�������ͷ������,�������ͨ������� n n n��(�������� n n n���û�)��ѡ�������С�� q q q���û���ȷ���� n n n���û��� q q q������ھӡ�֮������û� u n u_n un?�������� N g e o ( u n ) = { ( u m , d g e o ( u n , u m ) ) } m = 1 q N_{geo}(u_n)=\{ (u_m,d_{geo}(u_n,u_m)) \}_{m=1}^q Ngeo?(un?)={(um?,dgeo?(un?,um?))}m=1q?�� N c a t ( u n ) = { ( u m �� , d c a t ( u n , u m �� ) ) } m �� = 1 q N_{cat}(u_n)=\{ (u_{m^{\rq}},d_{cat}(u_n,u_{m^{\rq}})) \}_{m^{\rq}=1}^q Ncat?(un?)={(um��?,dcat?(un?,um��?))}m��=1q?����ʾʶ��ĵ����ͷ����ھ�IDs�Լ������� u n u_n un?�ľ��롣�����������Ƿ����������ھӱ�ʶ֮���������û��л��Խ��к����������Ϣ��
4. �ϲ������˽:
�������ռ������û������ļ���
O
(
u
n
)
O(u_n)
O(un?)�����ƫ��
C
P
(
u
n
)
CP(u_n)
CP(un?),ͨ��������������������������,����������֪ͨ�����û����ھ�IDs,��������˹�ֲ��õ�������ע������
O
(
u
n
)
O(u_n)
O(un?)�����ֲ�
C
P
(
u
n
)
CP(u_n)
CP(un?)��ʵ��
?
\epsilon
?�����˽��

D
D
D�����û��ύ������,
f
(
)
f()
f()��ʾһ��������������,
?
\epsilon
?Ϊ��˽Ԥ��(��˽�����̶�),
��
f
\Delta f
��f�Ǻ���
f
(
)
f()
f()�����ж�:
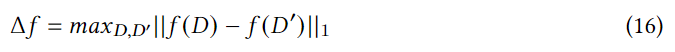
D D D�� D �� D' D�����������ڵ����ݼ�,ֻ��һ����¼��ͬ,�������� O ( u n ) O(u_n) O(un?),�����ȿ��Ժ�����ͨ��������Զ������֮��ľ�γ��֮�������,���� C P ( u n ) CP(u_n) CP(un?),���ֲ������û�����POI�����û����ʼ���,������ѯ��������Ϊ1,�ڽ�����ת��Ϊ���ֲ�֮ǰ,Ϊ���������ʴ�����������,ͨ������ ? \epsilon ?�����û���˽��
5. ���������ھ�
N
g
e
o
(
u
n
)
N_{geo}(u_n)
Ngeo?(un?)�������ھ�
N
c
a
t
(
u
n
)
N_{cat}(u_n)
Ncat?(un?),���������ھ��в�ͬ��֪ʶ,�ۺ������ھӻᵼ�������½�:����,ͨ�������ھӺ������ھӷֱ����֪ʶ����,����������ǿģ��;Ȼ���һ�������������ǿģ����ÿ���û���ȫ���Ի��ı����Ƽ���ϡ�������ͨ�Ź����ڱ���ʵ��,�ھӵ�ģ��Ȩ�ش�
N
g
e
o
(
u
n
)
N_{geo}(u_n)
Ngeo?(un?)��
N
c
a
t
(
u
n
)
N_{cat}(u_n)
Ncat?(un?)ת�Ƶ�
u
n
u_n
un?���ÿ����,�����ھӺ������ھӾ��в�ͬ��Ȩ��,��Ϊ���ǶԵ�ǰ�û��в�ͬ�ľ��롣���,�����һ�ֻ���������ģ�;ۺϲ���ѧϰ�ھӵ�֪ʶ��Ϊ��ѧϰ���е����ھӵ���ǿģ��,���ȸ����ھӺ͵�ǰ�û�֮��ľ����������֮������ƶ�:
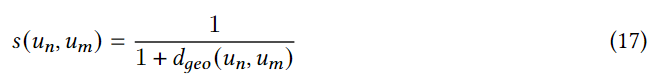
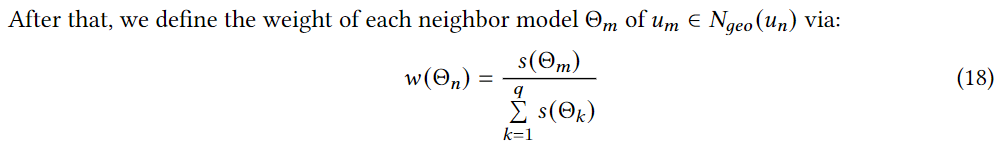
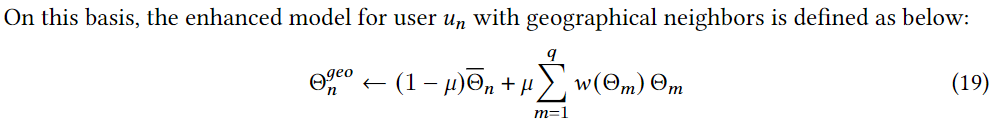
��
��
\bar{\Theta}
�����ǵ�ǰ�û��ij�ʼģ��,
��
\mu
���dz��������Ƶ�ǰģ�ͺͻ����ھӵľۺ�ģ�͵ı���,
��
n
c
a
t
\Theta_n^{cat}
��ncat?��������,�������ʧ�ؽ������ģ�������ÿ���û�������ģ��:��������ǿģ�Ϳ��Կ����ǵ�ǰģ�͵IJ�ͬ��ͼ,����ʹ�û���Ϣ������˴˻��֪ʶ����������ģ���е�ͬһ��POIǶ�����������������ѵ������,����ÿ������,����Ӧ��ģ���������ȡһ����ͬ��POIǶ�뽻��һ��POIǶ��,�Ӷ����ɸ�������
����ģ�͵������ʧ:
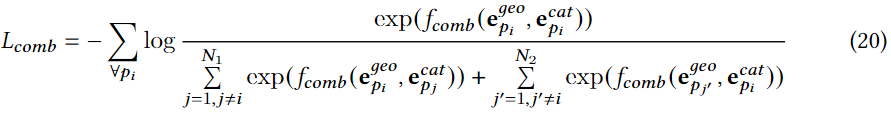
e
p
i
g
e
o
e_{p_i}^{geo}
epi?geo?��
e
p
i
c
a
t
e_{p_i}^{cat}
epi?cat?������ģ����ͬPOI��Ƕ��,
e
p
j
c
a
t
e_{p_j}^{cat}
epj?cat?��
e
p
j
��
g
e
o
e_{p_{j'}}^{geo}
epj��?geo?�ֱ���
��
n
c
a
t
\Theta_n^{cat}
��ncat?��
��
n
g
e
o
\Theta_n^{geo}
��ngeo?�ĸ�Ƕ��,��ÿ��ģ�͵ĸ�������,
N
1
=
N
2
N_1 = N_2
N1?=N2?������ģ�͵ĸ�������,
f
c
o
m
b
(
,
)
f_{comb}(,)
fcomb?(,)�������������ʵ��˫��������,
w
c
o
m
b
w_{comb}
wcomb?�ǿ�ѧϰ��������,һ��ͨ����С��
L
c
o
m
b
L_{comb}
Lcomb?���������ǿģ�͵�ϸ��,���ǽ�һ��ƽ������ϸ��ģ�͵õ����յĸ��Ի�ģ�͡�
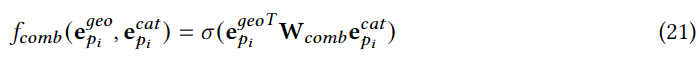

ʵ����������,�û������ռ����ھӵ�ģ��Ȩ��,����ܻᵼ����˽й¶,���ƹ������ĺ����ֲ�ʱ�IJ���,�ڽ����Ǵ��ݸ��ھ��û��豸֮ǰ,���ǽ�����ע��ģ��Ȩ���С�
6. �������˿�ʼ
line1-5�������Լලѧϰ�źų�ʼ���Ƽ���Ԥѵ��POI��ʾ��ͨ���������û��豸�����Ŷ������ĺ����ƫ��line6,������ͨ��������������������������line7-8,Ȼ���ھ���Ϣ���������û�line9,�������IJ������;�ص��û���,�ڻ��Ԥѵ����POIǶ���line10-12,������ÿ��ѵ��epoch��¼���µ��û�ģ�Ͳ���Ϊ
��
��
n
\bar{\Theta}_n
����n?line14-16;֮��
��
��
n
\bar{\Theta}_n
����n?ͨ�������Ϻ����������Ƶ��û�������ǿ,�⽫����һ������Ϣ�����,Ȼ��ϲ�;���豸�Ͻ���Эͬѧϰָ���ֲ�ģ��������

4. What are the conclusions?
- �����DCLR�ֲ�ʽ��ʽ,����ѵ�����Ի��Ƽ���Ϊ�˽������ϡ�������,��������������Լල�ź�,������ͷ����ǩ����ǿPOI��ʾ;Ȼ����ڷֲ�ʽЭ��ѧϰ,���Ƕ���������ָ��:��ʶ���������ͷ���ƫ�������Ե��ھ�;���������ע�����ͻ���Ϣ�����,��ͬѧϰ����������ھӵ�֪ʶ��������ʵ�����ݼ��ϵ�ʵ����֤�������ǵ�ģ������һ�� POI �Ƽ��е���Խ��,��Ϊ�������ṩȷ�ĸ��Ի� POI �Ƽ���ǿ�����˽������
5. others
- POI�Ƽ��ѳ�Ϊ����λ�õ��罻����(LBSN)�в��ɻ�ȱ�Ĺ��ܡ�

- check-in �: x = ( u , p , t ) x = (u, p, t) x=(u,p,t),�û�u,��Ȥ��p,ʱ���t��
- check-in ����:�����û�u��M������check-in�,��ʾΪ X ( u i ) = { x 1 , x 2 , . . . , x M } X(u_i) = \{ x_1, x_2,...,x_M \} X(ui?)={x1?,x2?,...,xM?}���ӷ��������յ���������IDs,ÿ���ƶ��豸�������ھ������ȡ���ۺ�֪ʶ,�Ը��±���ģ�͡����� X ( u i ) X(u_i) X(ui?)���ھ�IDs,����ģ�ͱ�ѵ��Ϊ����ÿ���û��������Ȥ��Ϊ�Ƽ��ṩһ��POIs�������б���
- ÿ��check-in������x��
e
x
=
e
p
+
e
t
��
R
d
e_x = e_p + e_t \in \reals^d
ex?=ep?+et?��Rd,ÿ���û����е�����Ϊ
X
u
=
[
e
x
1
,
e
x
2
,
.
.
.
,
e
x
M
]
��
R
M
��
d
X_u = [ e_{x_1}, e_{x_2},...,e_{x_M} ] \in \reals^{M��d}
Xu?=[ex1??,ex2??,...,exM??]��RM��d,STAN�����һ����������check-in֮���ʱ����:
e
a
b
��
��
R
d
,
e
a
b
��
=
��
a
b
s
��
e
��
s
+
��
a
b
t
��
e
��
t
e_{ab}^\Delta \in \reals^d,e_{ab}^\Delta=\Delta_{ab}^s��e_{\Delta_s}+\Delta_{ab}^t��e_{\Delta_t}
eab��?��Rd,eab��?=��abs?��e��s??+��abt?��e��t??,����
e
��
s
e_{\Delta_s}
e��s??��
e
��
t
e_{\Delta_t}
e��t??Ϊ��λǶ���ʾ�ض������Ŀռ�(һ����)��ʱ��(һСʱ)���졣
��
a
b
s
\Delta_{ab}^s
��abs?��
��
a
b
t
\Delta_{ab}^t
��abt?��
x
a
x_a
xa?��
x
b
x_b
xb?����check-in֮��������ʱ�ղ���(����:10�����5Сʱ)���켣ʱ��-ʱ��Ƕ���ϵ������
��
��
R
M
��
M
\Delta \in \reals^{M��M}
����RM��M:
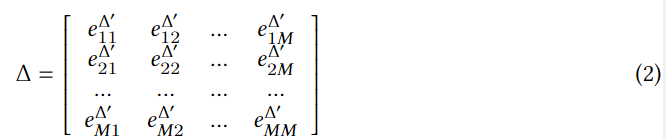
e
a
b
��
��
e_{ab}^{\Delta^{\rq}}
eab����?��
e
a
b
��
e_{ab}^\Delta
eab��?Ԫ�غ�,֮�������ע����ƽ�һ�����Ƕ�����к�ʱ�ղ���,���յ�Ƕ������Ϊ:
E
u
��
R
M
��
d
E_u\in \reals^{M��d}
Eu?��RM��d
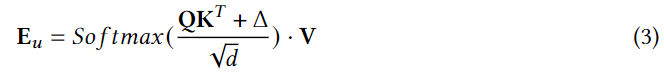
�û����ʺ�ѡPOI�Ŀ����Լ���Ϊ:
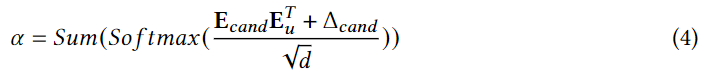
֮�����ÿ���û��豸ģ��,���ý������������û��Ż���POIԤ����ʧ:
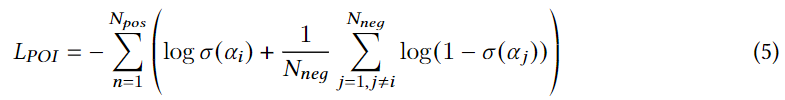
����
N
p
o
s
N_{pos}
Npos?���û�������������,
N
n
e
g
N_{neg}
Nneg?�Ǵ��û�δ���ʵ�POIs�������ȡ��������
p
i
p_i
pi?�ĸ���������(ÿ��������
p
i
p_i
pi?�ĸ�������),
��
i
\alpha_i
��i?��
��
j
\alpha_j
��j?�ֱ�Ϊ�������������ķ�����
6. POI�Ƽ��ѳ�Ϊ����λ�õ��罻����(LBSN)�в��ɻ�ȱ�Ĺ��ܡ�
�Լල��������Ԥѵ���������ϵ�POIǶ��,Ȼ�����豸�������û��Լ��Ľ�����һ���Ż����벻�����û��豸ͨ�Ų����뱾��ģ���Ż�������ģ�����,DCLR�еIJ���ѵ����һ��һ���Թ���,���漰�����еĹ�������ѵ���Ĺ���POIǶ�롣
������Ϣ����һ��POI�Ƽ����DZز����ٵ�,��Ϊ�û�����һ��POIƫ�ø߶������û���ǰPOI�ľ���,Ȼ��,��ǰ��POI�Ƽ�ϵͳ�����������ڹ켣�Ϲ۲��POI֮��ĵ�������ԡ����,���ǽ�һ��ʹ��POIs֮��ijɶԾ���������������ԡ�
�û����ض�POIs��check-inϡ��,���������Ļ������(��,����)�ܼ���������Ԥ���ܹ���POI�����û�����Ȥ�ṩ������Ԥ���ź�,����,�û������ֳ�����ǿ��ƫ�ñ���,�����ܻ������������ֳ���,�����ӰԺ�;ưɡ�

