前言
去中心化搜索随着P2P分享软件的兴起而来到了聚光灯下。
说起P2P分享软件的发展史,是单个节点能力不断发展的历史,也是探索如何集合节点们的能力成为有机整体的历史,其强大的单个节点能力和相对落后脆弱的集群能力的矛盾贯穿始终,推动了去中心化搜索的架构的演进。
所谓去中心化搜索,就是理论上P2P的节点是对等的,需要有方法在网络上搜索到对方,并协调对外提供一致服务的过程。
这个架构的演进,经历了从中心化到部分去中心化的演进,向着完全去中心化方向发展,推动架构演进的动力,包括:
- 性能需求
- 抗审查性需求
第一代 中心index服务器
起源于上个世纪末的Nasper引领了P2P分享软件的革命,在这崭新的模式下,用户们不是从中央的服务器去下载音乐,而是经过中心index服务器介绍认识,互相之间交换音乐。尽管音乐的存储和交换活动是分散的,但是需要一个中介(中心index服务器)介绍他们相互认识和列出清单,这会导致单点问题,如果关闭中心服务器,整个网络就不能用了。事实上后来的历史发展也证明,当Nasper发展损害了传统唱片公司的利益,通过关闭中心index服务器来摧毁Nasper网络并非难事。中心化的index服务器架构有其脆弱性。
特点:
- 性能OK。从宏观视角上看,可以以O(1)的时间复杂度获得搜索结果
- 抗审查性不符合需求。
第二代 去中心化:洪泛模型,两眼一抹黑的暴力搜索
本文的前言中提到,P2P软件发展史上的主要矛盾是强大的单个节点能力和相对落后脆弱的集群能力的矛盾。Nasper的成功实践证明,哪怕是在互联网的上古时代,单个设备存储1000首音乐,每日交换100首,技术上并无问题,瓶颈是如何组织这些个体,如何让他们互相发现并建立连接。
于是洪泛模型应运而生,随着Gnutella等软件兴起而兴起。其原理是每个节点向身边节点查询,身边节点再向其它节点查询,如此递归下去,直到查询到为止。从描述的字里行间我们已经感觉到查询次数将随层级成指数上升,“洪泛”是对该算法实现细节的完美描述。
而且,如果3个节点形成了回路,这下好了,没完没了。
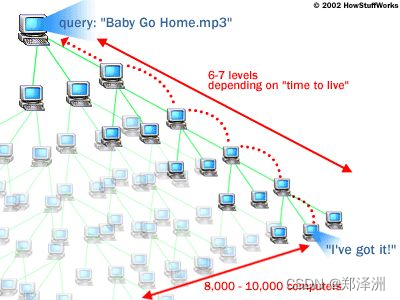
特点:
- 性能不佳
- 抗审查性符合要求
第三代 去中心化:基于虚拟空间精巧结构的DHT
21世纪初,BT下载横空出世。BT下载,也就是Bittorrent,对下载文件核心思想是“化整为零”,发布文件之前需要制作种子文件,种子是一个记录了下载文件的服务器信息的索引文件。BitTorrent 协议下载的特点是,下载的人越多,提供的带宽也越多,下载速度就越快。同时,拥有完整文件的用户也会越来越多,文件的“寿命”也就越长。
BitTorrent 引入了分布式哈希技术( DHT ),相比泛洪查询技术,DHT 效率显著提升。
那么DHT是怎么做到这点的呢?首先,“家国同构”,NodeId和FileId都是UUID,格式上统一,并且建立了联系,也就是说,一个BT文件被制作出来后,“生而”就是属于某些特点的Node的,更具体的说,是通过海明距离的计算,在虚拟世界里面建立了有形的结构,让特定的文件归属于距离最近的节点。
一个文件的id计算出来后,看本地有缓存吗?没有的话,问距离这个文件最近的节点
- 如果那个节点存了,就返回给你
- 没有的话它继续问它那边认为的距离最近的
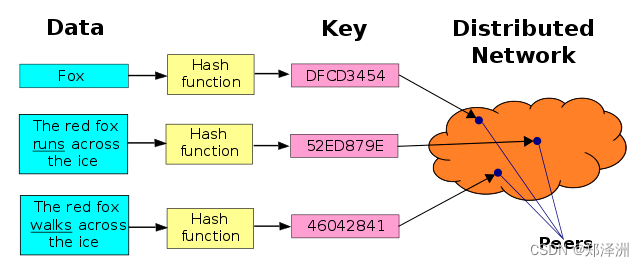
打个不太恰当的比方,假设世界上的每个人(文件)一出生就有个统一的身份证号(FileId),现在有个美国用户只知道我身份证号,但想找到我并把我复制一份。于是他先在美国本地主机找缓存,之所以要先查本地缓存,因为他知道我可能是名人,其他美国用户干过查找我并复制我的事情,恰好美国主机上有一个我的副本,于是他立马就找到了,幸运!但是也可能没有找到,于是他根据身份证前4位的国别代码,知道我是中国人,于是发出跨国请求,请求中国的主机们响应,中国响应的主机也会先查本地缓存,有就立即响应;没有的话,就根据相邻3位的省别代码,知道我是浙江人,转发请求到浙江群组的主机里面去查找,如此递归,直到最小粒度,要么找到,要么找不到。
可以把IPFS的节点看成传统单机哈希的桶
这里会有很多问题
- 你身边有个节点本来离A文件最近,你也把A文件发给它了。这时候突然有个新节点上线,偏巧NodeId更近
- 按照算法,你问A文件,是会问新节点,但是这时候,它还没有A文件,所以返回找不到
- 实际上这个文件有的!
所以IPFS的存储看起来并不靠谱
除非你建立一个私有的文件域,能体现ipfs的冗余和高可用,又不会有之前的各种问题
但是pinata是公域,所以要解决节点宕机和新增的再平衡问题
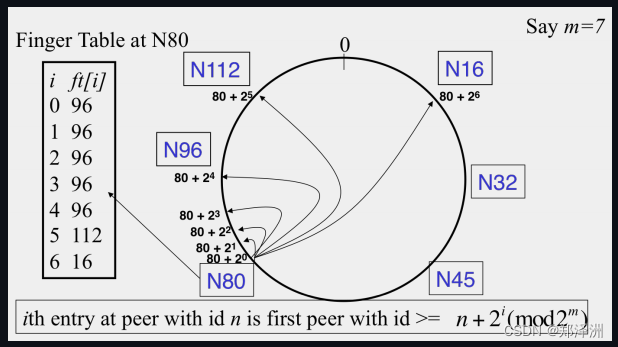
这个问题被Chord协议给解决了
- 一致性hash,让NodeId空间变成了一个环 有successor 和 predecessor 概念 数据归属于顺时针距离最小的节点
- 最简单搜索算法是一个一个successor接力棒查下去 O(n) 但是效率低
- 高级路由算法是O(logn) 是自己节点到Key值最大的节点之间,步长递增地去找
节点加入
- 任何一个新来的节点(假设叫 A),需要先跟 DHT 中已有的任一节点(假设叫 B)建立连接。
- A 随机生成一个散列值作为自己的 ID(对于足够大的散列值空间,ID 相同的概率忽略不计)
- A 通过跟 B 进行查询,找到自己这个 ID 在环上的接头人。也就是――找到自己这个 ID 对应的继任(假设叫 C)与前任(假设叫 D)
- 接下来,A 需要跟 C 和 D 进行一系列互动,使得自己成为 C 的前任,以及 D 的继任。 这个互动过程,大致类似于在双向链表当中插入元素。
节点异常退出
作为一个分布式系统,任何节点都有可能意外下线(也就是说,来不及进行善后就挂掉了)
假设节点A的继任者异常下线了,那么节点 A 该如何处理?
Chord 引入了一个继任者候选列表的概念。每个节点都用这个列表来包含:距离自己最近的 N 个节点的信息,顺序是由近到远。一旦自己的继任者下线了,就在列表中找到一个距离最近且在线的节点,作为新的继任者。然后节点 A 更新该列表,确保依然有 N个候选。更新完继任者候选列表后,节点 A 也会通知自己的前任,那么 A 的前任也就能更新自己的继任者候选列表。
第四代 进化:带激励模型的去中心化
随着DHT和Chord等技术的兴趣,去中心化搜索的效率得到了提升,抗审查性也符合需求。但进化并无停止,技术的天花板,并不等于系统的天花板。
2009年,xxxcoin的出现给去中心化系统带来了激励系统的启示,Namecoin 是一个去中心化的域名系统,功能和传统的域名供应商类似,用来解析域名,做的也是找人找资源的搜索的事情。我们现在使用的域名系统是分布式而非去中心化的,所以理论上强权是可以做到控制整个域名系统,从而控制互联网的访问。而 Namecoin 是去中心化的,理论上是没有人可以关闭他的。
所以第三代故事里面的美国用户找一个中国人的故事将会再次升级,将不仅仅是向一个个“活雷锋”发请求,而且也是向一个个去中心化的专业服务提供者发送请求,查找过程将引入激励机制。

