
一、前言
当前公司的大数据实时链路如下图,数据源是MySQL数据库,然后通过Binlog Query的方式消费或者直接客户端采集到Kafka,最终通过基于Spark/Flink实现的批流一体计算引擎处理,最后输出到下游对应的存储。

二、 模型特征架构的演进
2.1 第一代架构
广告业务发展初期,为了提升策略迭代效率,整理出一套通用的特征生产框架,该框架由三部分组成:特征统计、特征推送和特征获取模型训练。如下图所示:

- 客户端以及服务端数据先通过统一服务Sink到HDFS上
- 基于基HDFS数据,统计特定维度的总量、分布等统计类特征并推送到Codis中
- 从Codis中获取特征小时维度模型增量Training,读取HDFS文件进行天级别增量Training
该方案能够满足算法的迭代,但是有以下几个问题 - 由于Server端直接Put本地文件到HDFS上无法做到根据事件时间精准分区,导致数据源不同存在口径问题
- 不可控的小文件、空文件问题
- 数据格式单一,只支持json格式
- 用户使用成本较高,特征抽取需要不断的Coding
- 整个架构扩展性较差
为解决上述问题,我们对第一代架构进行了演进和改善,构建了第二代批流一体架构(另外该架构升级也是笔者在饿了么进行架构升级的演进路线)。
2.2 第二代架构
2.2.1 批流一体平台的构建
首先将数据链路改造为实时架构,将Spark Structured Streaming(下文统一简称SS)与Flink SQL语法统一,同时实现与Flink SQL语法大体上一致的批流一体架构,并且做了一些功能上的增强与优化。

为什么有了Flink还需要支持SS呢?主要有以下几点原因
- Spark生态相对更完善,当然现在Flink也做的非常好了
- 用户使用习惯问题,有些用户对从Spark迁移到Flink没有多大诉求
- SS Micro Batch引擎的抽象做批流统一更加丝滑
- 相比Flink纯内存的计算模型,在延迟不敏感的场景Spark更友好
这里举一个例子,比如批流一体引擎SS与Flink分别创建Kafka table并写入到ClickHouse,语法分别如下
Spark Structured Streaming语法如下
--Spark Structured Streaming
CREATE STREAM spark (
ad_id STRING,
ts STRING,
event_ts as to_timestamp(ts)
) WITH (
'connector' = 'kafka',
'topic' = 'xx',
'properties.bootstrap.servers'='xx',
'properties.group.id'='xx',
'startingOffsets'='earliest',
'eventTimestampField' = 'event_ts',
'watermark' = '60 seconds',
'format'='json'
);
create SINK ck(
ad_id STRING,
ts STRING,
event_ts timestamp
) WITH(
'connector'='jdbc',
'url'='jdbc:clickhouse://host:port/db',
'table-name'='table',
'username'='user',
'password'='pass',
'sink.buffer-flush.max-rows'='10',
'sink.buffer-flush.interval' = '5s',
'sink.parallelism' = '3'
'checkpointLocation'= 'checkpoint_path',
);
insert into ck select * from spark ;
Flink SQL语法如下
CREATE TABLE flink (
ad_id STRING,
ts STRING,
event_ts as to_timestamp(ts)
)
WITH (
'connector' = 'kafka',
'topic' = 'xx',
'properties.bootstrap.servers'='xx',
'properties.group.id'='xx',
'scan.topic-partition-discovery.interval'='300s',
'format' = 'json'
);
CREATE TABLE ck (
ad_id VARCHAR,
ts VARCHAR,
event_ts timestamp(3)
PRIMARY KEY (ad_id) NOT ENFORCED
) WITH (
'connector'='jdbc',
'url'='jdbc:clickhouse://host:port/db',
'table-name'='table',
'username'='user',
'password'='pass',
'sink.buffer-flush.max-rows'='10',
'sink.buffer-flush.interval' = '5s',
'sink.parallelism' = '3'
);
insert into ck select * from flink ;
2.2.2 模型特征处理新架构
新的模型特征处理采用批流一体的架构,上游对接数据源还是Kafka,模型主要有两个诉求
?支持增量读取方式减少模型更新的实效性
?利用CDC来实现特征的回补
整个流程如下图

2.2.3 Hudi、Delta还是Iceberg
3个项目都是目前活跃的开源数据湖方案,feature to feature的展开详细说篇幅太长,大致列举一下各自的优缺点。
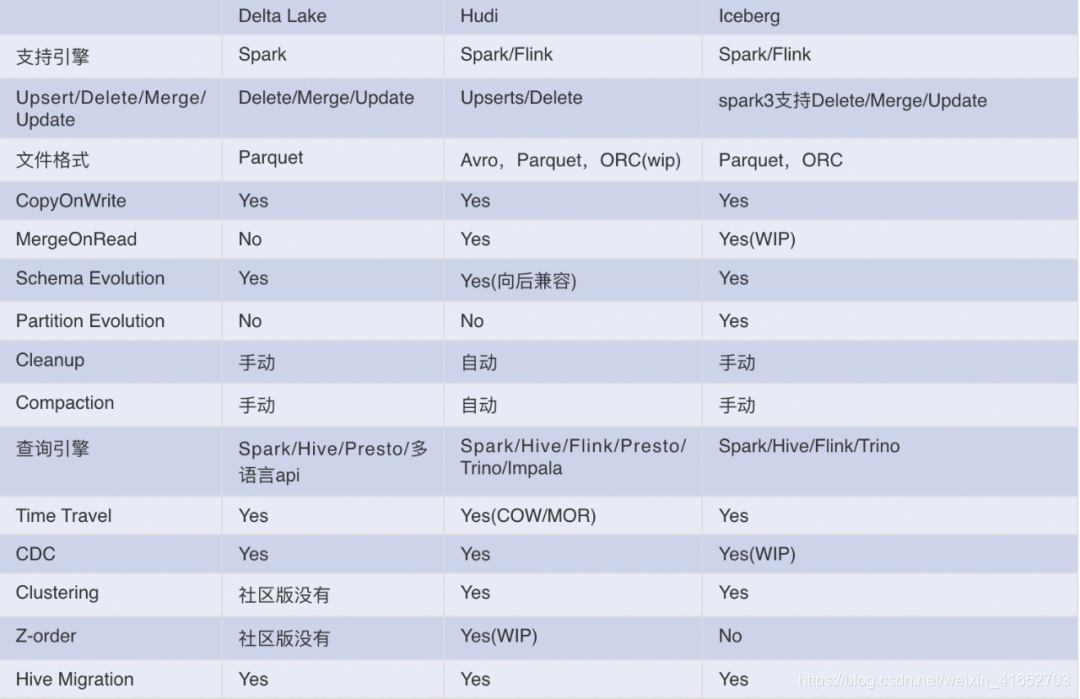
其实通过对比可以发现各有优缺点,但往往会因为诉求不同,在实际落地生产时3种选型会存在同时多个共存的情况,为什么我们在模型特征的场景最终选择了Hudi呢?主要有以下几点
- 国内Hudi社区非常活跃,问题可以很快得到解决
- Hudi对Spark2的支持更加友好,公司算法还是Spark2为主
- 算法希望有增量查询的能力,而增量查询能力是Hudi原生主打的能力,与我们的场景非常匹配
- Hudi非常适合CDC场景,对CDC场景支持非常完善
2.2.4 方案上线
我们计划用Spark跟Flink双跑,通过数据质量以及资源成本来选择合适的计算引擎。选择的一个case是广告曝光ed流跟用户点击Click流Join之后落地到Hudi,然后算法增量查询抽取特征更新模型。
2.2.4.1 Flink方案
最初我们用的是Flink 1.12.2 + Hudi 0.8.0,但是实际上发现任务跑起来并不顺利,使用master最新代码0.9.0-SNAPSHOT之后任务可以按照预期运行,运行的Flink SQL如下:
CREATE TABLE ed (
`value` VARCHAR,
ts as get_json_object(`value`,'$.ts'),
event_ts as to_timestamp(ts),
WATERMARK FOR event_ts AS event_ts - interval '1' MINUTE,
proctime AS PROCTIME()
)WITH (
'connector' = 'kafka',
'topic' = 'ed',
'scan.startup.mode' = 'group-offsets',
'properties.bootstrap.servers'='xx',
'properties.group.id'='xx',
'scan.topic-partition-discovery.interval'='100s',
'scan.startup.mode'='group-offsets',
'format'='schemaless'
);
CREATE TABLE click (
req_id VARCHAR,
ad_id VARCHAR,
ts VARCHAR,
event_ts as to_timestamp(ts),
WATERMARK FOR event_ts AS event_ts - interval '1' MINUTE,
proctime AS PROCTIME()
)WITH (
'connector' = 'kafka',
'topic' = 'click',
'properties.bootstrap.servers'='xx',
'scan.startup.mode' = 'group-offsets',
'properties.bootstrap.servers'='xx',
'properties.group.id'='xx',
'scan.topic-partition-discovery.interval'='100s',
'format'='json'
);
CREATE TABLE hudi(
uuid VARCHAR,
ts VARCHAR,
json_info VARCHAR,
is_click INT,
dt VARCHAR,
`hour` VARCHAR,
PRIMARY KEY (uuid) NOT ENFORCED
)
PARTITIONED BY (dt,`hour`)
WITH (
'connector' = 'hudi',
'path' = 'hdfs:///xx',
'write.tasks' = '10',
'write.precombine.field'='ts',
'compaction.tasks' = '1',
'table.type' = 'COPY_ON_WRITE'
);
insert into hudi
SELECT concat(req_id, ad_id) uuid,
date_format(event_ts,'yyyyMMdd') AS dt,
date_format(event_ts,'HH') `hour`,
concat(ts, '.', cast(is_click AS STRING)) AS ts,
json_info,is_click
FROM (
SELECT
t1.req_id,t1.ad_id,t1.ts,t1.json_info,
if(t2.req_id <> t1.req_id,0,1) as is_click,
ROW_NUMBER() OVER (PARTITION BY t1.req_id,t1.ad_id,t1.ts ORDER BY if(t2.req_id <> t1.req_id,0,1) DESC) as row_num
FROM
(select ts,event_ts,map_info['req_id'] req_id,map_info['ad_id'] ad_id, `value` as json_info from ed,LATERAL TABLE(json_tuple(`value`,'req_id','ad_id')) as T(map_info)) t1
LEFT JOIN
click t2
ON t1.req_id=t1.req_id and t1.ad_id=t2.ad_id
and t2.event_ts between t1.event_ts - INTERVAL '10' MINUTE and t1.event_ts + INTERVAL '4' MINUTE
) a where a.row_num=1;
标注:上述SQL中有几处与官方SQL不一致,主要是实现了统一规范Schema为一列的Schemaless的Format、与Spark/Hive语义基本一致的get_json_object以及json_tuple UDF,这些都是在批流一体引擎做的功能增强的一小部分。
但是在运行一周后,面临着业务上线Delay的压力以及暴露出来的两个问题让我们不得不先暂时放弃Flink方案
- 任务反压的问题(无论如何去调整资源似乎都会出现严重的反压,虽然最终我们通过在写入Hudi之前增加一个upsert-kafka的中间流程解决了,但链路过长这并不是我们预期内的)
- 还有一点是任务存在丢数据的风险,对比Spark方案发现Flink会有丢数据的风险
标注:这个case并非Flink集成Hudi不够,国内已经有很多使用Flink引擎写入Hudi的实践,但在我们场景下因为为了确保上线时间,没有太多时间细致排查问题。实际上我们这边Kafka -> Hive链路有95%的任务都使用Flink替代了Spark Structured Streaming(SS)
2.2.4.2 Spark方案
由于没有在Hudi官方网站上找到SS集成的说明,一开始笔者快速实现了SS与Hudi的集成,但是在通读Hudi代码之后发现其实社区早已有了SS的完整实现,另外咨询社区同学leesf之后给出的反馈是当前SS的实现也很稳定。稍作适配SS版本的任务也在一天之内上线了,任务SQL如下:
CREATE STREAM ed (
value STRING,
ts as get_json_object(value,'$.ts'),
event_ts as to_timestamp(get_json_object(value,'$.ts'))
) WITH (
'connector' = 'kafka',
'topic' = 'ed',
'properties.bootstrap.servers'='xx',
'properties.group.id'='xx',
'startingOffsets'='earliest',
'minPartitions' = '60',
'eventTimestampField' = 'event_ts',
'maxOffsetsPerTrigger' = '250000',
'watermark' = '60 seconds',
'format'='schemaless'
);
CREATE STREAM click (
req_id STRING,
ad_id STRING,
ts STRING,
event_ts as to_timestamp(ts)
) WITH (
'connector' = 'kafka',
'topic' = 'click',
'properties.bootstrap.servers'='xxxx'properties.group.id'='dw_ad_algo_naga_dsp_ed_click_rt',
'startingOffsets'='earliest',
'maxOffsetsPerTrigger' = '250000',
'eventTimestampField' = 'event_ts',
'minPartitions' = '60',
'watermark' = '60 seconds',
'format'='json'
);
--可以动态注册python、java、scala udf
create python function py_f with (
'code' = '
def apply(self,m):
return 'python_{}'.format(m)
',
'methodName'= 'apply',
'dataType' = 'string'
);
create SINK hudi(
uuid STRING,
dt STRING,
hour STRING,
ts STRING,
json_info STRING,
is_click INT
) WITH (
'connector'='hudi',
'hoodie.table.name' = 'ed_click',
'path' ='hdfs:///xx',
'hoodie.datasource.write.recordkey.field' = 'uuid',
'hoodie.datasource.write.precombine.field' = 'ts',
'hoodie.datasource.write.operation' = 'upsert',
'hoodie.datasource.write.partitionpath.field' = 'dt,hour',
'hoodie.datasource.write.keygenerator.class'= 'org.apache.hudi.keygen.ComplexKeyGenerator',
'hoodie.datasource.write.table.type' = 'COPY_ON_WRITE',
'hoodie.datasource.write.hive_style_partitioning'='true',
'hoodie.datasource.write.streaming.ignore.failed.batch'='false',
'hoodie.keep.min.commits'='120',
'hoodie.keep.max.commits'='180',
'hoodie.cleaner.commits.retained'='100',
--'hoodie.datasource.write.insert.drop.duplicates' = 'true',
--'hoodie.fail.on.timeline.archiving'='false',
--'hoodie.datasource.hive_sync.table'='true',
-- 'hoodie.datasource.hive_sync.database'='ods_test',
-- 'hoodie.datasource.hive_sync.table'='ods_test_hudi_test2',
-- 'hoodie.datasource.hive_sync.use_jdbc'='false',
-- 'hoodie.datasource.meta.sync.enable' ='true',
-- 'hoodie.datasource.hive_sync.partition_fields'='dt,hour',
-- 'hoodie.datasource.hive_sync.partition_extractor_class'='org.apache.hudi.hive.MultiPartKeysValueExtractor',
'trigger'='30',
'checkpointLocation'= 'checkpoint_path'
);
INSERT INTO
hudi
SELECT
concat(req_id, ad_id) uuid,
date_format(ts,'yyyyMMdd') dt,
date_format(ts,'HH') hour,
concat(ts, '.', cast(is_click AS STRING)) AS ts,
json_info,
is_click
FROM
(
SELECT
t1.req_id,
t1.ad_id,
t1.ts,
t1.json_info,
IF(t2.req_id is null, 0, 1) AS is_click
FROM
(select ts,event_ts,req_id,ad_id,value as json_info from ed
lateral view json_tuple(value,'req_id','ad_id') tt as req_id,ad_id) t1
LEFT JOIN click t2 ON t1.req_id = t2.req_id
AND t1.ad_id = t2.ad_id
AND t2.event_ts BETWEEN t1.event_ts - INTERVAL 10 MINUTE
AND t1.event_ts + INTERVAL 4 MINUTE
) tmp;
标注:Spark批流一体引擎在流语法上尽量与Flink对齐,同时我们实现了python/java/scala多语言udf的动态注册以方便用户使用
三、新方案收益
通过链路架构升级,基于Flink/Spark + Hudi的新的流批一体架构带来了如下收益
?构建在Hudi上的批流统一架构纯SQL化极大的加速了用户的开发效率
?Hudi在COW以及MOR不同场景的优化让用户有了更多的读取方式选择,增量查询让算法可以实现分钟级别的模型更新,这也是用户的强烈诉求
?利用SS以及Flink的事件时间语义抹平了口径上的Gap
?Hudi自动Compact机制+小文件智能处理,对比第一版实现甚至对比需要手动Compact无疑极大的减轻了工程负担
四、踩过的坑
- 写Hudi重试失败导致数据丢失风险。解决办法:hoodie.datasource.write.streaming.ignore.failed.batch设置为false,不然Task会间隔hoodie.datasource.write.streaming.retry.interval.ms(默认2000)重试hoodie.datasource.write.streaming.retry.count(默认3)
- 增量查询Range太大,导致算法任务重试1小时之前的数据获取到空数据。解决办法:调大保留版本数对应参数为hoodie.keep.min.commits、hoodie.keep.max.commits调大cleanup
retention版本数对应参数为hoodie.cleaner.commits.retained - Upsert模式下数据丢失问题。解决办法:hoodie.datasource.write.insert.drop.duplicates设置为false,这个参数会将已经存在index的record丢弃,如果存在update的record会被丢弃
- Spark读取hudi可能会存在path not exists的问题,这个是由于cleanup导致的,解决办法:调整文件版本并进行重试读取
五、 未来规划
基于Hudi线上运行的稳定性,我们也打算基于Hudi进一步探索流批一体的更多应用场景,包括
- 使用Hudi替代Kafka作为CDC实时数仓Pipeline载体
- 深度结合Hive以及Presto,将Hive表迁移为基于Hudi的架构,以解决分区小文件以及产出失效的问题
- 探索Flink+Hudi作为MySQL Binlog归档方案
- 探索Z-Order加速Spark在多维查询上的性能表现
获取更多最新资料请见微信 公众号:
