日志数据实时分析计算基于Spark Streaming和Kafka实现,本文主要介绍其中采集模块、数据清洗模块、指标计算模块、数据存储模块。
1、日志实时分析系统架构
实时日志分析系统通过Logstash采集数据,并通过Kafka将数据实时推送到Spark节点。Spark Streaming接收到流数据,通过Spark节点对数据进行清洗转换,并进行统计分析,并将分析结果保存到外部数据库MySQL。Spark处理后的指标数据通过机器学习模型进行实时评估和预测,并将预测结果保存到外部数据库MySQL。最后,分析和预测后的结果输出到UI API进行消费和展示。总的分为以下7个模块:采集模块、数据清洗模块、指标计算模块、模型训练模块、模型预测评估模块、数据存储模块和指标展示模块,具体如下图所示:

1.1 环境准备
实时日志分析系统涉及到的组件包括数据采集logstash、流数据管道Kafka和Zookeeper、数据分析和计算Spark Streaming和Spark SQL、数据存储MongoDB和MySQL,相关环境的准备如下:
- ELK集群环境,参考“大数据库系列之ELK集群环境部署”
- Kafka和Zookeeper集群环境,参考“大数据系列之Kafka集群环境部署”
- Spark集群环境,参考“大数据系列之Spark集群环境部署”
- MongoDB集群环境,参考“数据库系列之MongoDB集群环境部署”
- MySQL环境,参考“数据库系列之MySQL主从复制集群部署”
1.2 实时分析系统处理逻辑
日志实时分析系统处理逻辑如下图所示:
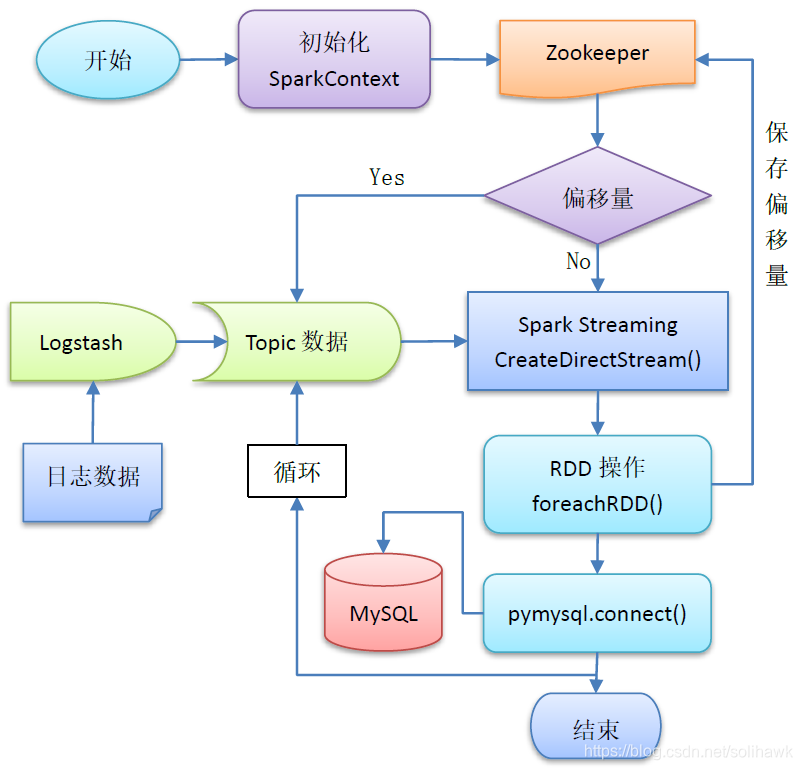
2、日志数据实时分析计算实现
2.1 日志数据采集
实时数据采集部分参考“大数据系列之ELK集群环境部署”的Logstash配置部分,通过logstash对SYSLOG运行日志数据进行实时采集、过滤然后推送到目标端如elasticsearch、MongoDB和Kafka。
1)Logstash配置文件
Logstash配置中的filter细节参考《logstash字段过滤优化》,每一种类型的Input和Output组件会设置不同配置参数。
- Input部分:logstash读取的源数据组件,如Redis、file、kafka和http等
- Filter部分:对源数据内容进行过滤解析等操作,如split、grok、truncate等
- Output部分:将数据发送到目标端组件,包括kafka、MongoDB、Redis等
2)Logstash将数据推送到MongoDB
# For detail structure of this file
# Set: https://www.elastic.co/guide/en/logstash/current/configuration-file-structure.html
input {
file {
type => "system-message"
path => "/var/log/messages"
start_position => "beginning"
}
}
filter {
#Only matched data are send to output.
}
output {
mongodb {
uri => "mongodb://192.168.112.101:27017" ――MongoDB集群的主节点
database => "syslogdb"
collection => "syslog_tango_01"
}
}
3)Logstash将数据推送到Kafka
# For detail structure of this file
# Set: https://www.elastic.co/guide/en/logstash/current/configuration-file-structure.html
input {
file {
type => "system-message"
path => "/var/log/messages"
start_position => "beginning"
}
}
filter {
#Only matched data are send to output.
}
output {
kafka {
bootstrap_servers => "192.168.112.101:9092,192.168.112.102:9092,192.168.112.103:9092"
topic_id => "system-messages-tango-01"
compression_type => "snappy"
}
}
4)启动Logstash环境
nohup ./bin/logstash -f ./config/elk-syslog/ &
./config/elk-syslog/目录下存放logstash-mongodb和logstash-kafka配置文件
2.2 数据存储模块
数据存储模块分为两个部分,一部分是通过logstash将输入的非结构化数据转到MongoDB进行永久保存,另外一部分将指标分析计算后的结构化时间转存到MySQL中
1)源数据转存到MongoDB
实时运行数据通过logstash-output-mongodb插件将数据转存到MongoDB中保存。在logstash的output配置中定义目标数据库的database名称和collection名称:
output {
mongodb {
uri => "mongodb://192.168.112.101:27017" ――MongoDB集群的主节点
database => "syslogdb"
collection => "syslog_tango_01"
}
}
2)Spark分析计算结果转存到MySQL
Spark RDD计算结果调用PyMySQL模块建立和MySQL的连接,保存数据到表中:
import pymysql
conn=pymysql.connect(user="root",passwd="123456qaz",\
host="192.168.112.10",db="test",charset="utf8")
def mysql_func(conn,sql,data):
mysql_cursor=conn.cursor()
mysql_cursor.executemany(sql,data)
conn.commit()
2.3 数据接口调用
Spark计算节点主要消费两类数据:实时增量数据和存量数据。实时数据使用Spark Streaming实时接入Kafka转送数据,用于指标实时分析计算和预测;存量数据则访问MongoDB数据库,用于机器学习的模型训练。
1)Spark接入Kafka数据
Spark中通过Spark Streaming模块使用Direct读取方式读入Kafka数据,详细内容见“大数据系列之Spark Streaming接入Kafka数据”,程序实现如下:
from pyspark import SparkContext
from pyspark.streaming import StreamingContext
from pyspark.streaming.kafka import KafkaUtils
sc = SparkContext(appName="SparkAllContext")
ssc = StreamingContext(sc, 10)
topic="kafka_spark_test1"
brokers = "192.168.112.101:9092,192.168.112.102:9092,192.168.112.103:9092"
def kafka_input(ssc,topic,brokers):
kvs = KafkaUtils.createDirectStream(ssc, [topic], {"metadata.broker.list": brokers})
lines = kvs.map(lambda x: x[1])
counts = lines.flatMap(lambda line: line.split(" ")) \
.map(lambda word: (word, 1)) \
.reduceByKey(lambda a, b: a+b)
counts.pprint()
2)Spark接入MongoDB数据
Spark通过mongo-spark connector接入MongoDB数据,详细内容见“大数据系列之Spark和MongoDB集成”,程序实现如下:
#settings mongodb configuration infomation
urlAddr = "mongodb://192.168.112.102:27017"
dbName = "syslogdb"
collID ="syslog_tango_01"
sc = SparkContext(appName="SparkAllContext")
# Connect to mongodb
# URL address and database and collection name
def ConnectMongo(sc):
ctx = SQLContext(sc)
test_collection = ctx.read.format("com.mongodb.spark.sql").\
options(uri=urlAddr, database=dbName, collection=collID).load()
return test_collection
2.4 数据清洗和指标计算
数据清洗的目的是对通过MongoDB或Kafka读取的非结构化数据进行指标提取,转化为运维使用到的指标值,比如在日志数据中通过Python正则表达式提取时间戳、主机名称、消息码和消息内容关键字。当指标值筛选出来后,通过Spark RDD算子对这些指标进行量化统计、消息内容的解析,再通过学习模型实现对指标值进行分类或回归、告警内容的模式识别和关联分析等功能。代码实现如下:
1)Spark Streaming接收到的Kafka数据有两项,其中第二项为数据部分
kvs = KafkaUtils.createDirectStream(ssc, [topic], {"metadata.broker.list": brokers})
lines = kvs.map(lambda x: x[1]).map(lambda x: re.split('\s?',x,7))
利用Python正则表达式对接收到的信息进行解析
2)统计消息中单词数
s_count = rdd.map(lambda x: x[7]).map(lambda x: x.split(" ")).map(lambda x:len(x))
3)格式化时间为标准GMT格式"%Y-%m-%d %H:%M:%S"
s_year = str(datetime.datetime.now().year)
c_time = rdd.map(lambda x: str(x[2])+' '+str(x[3])+' '+str(x[4])+' '+s_year)
gmt_fmt = "%b %d %H:%M:%S %Y"
#format message timestamp
s_time = c_time.map(lambda x:time.strftime("%Y-%m-%d %H:%M:%S",time.strptime(x,gmt_fmt)))
4)Spark Streaming一个时间窗口内接收到的数据为一个RDD,可能包含多个items,需要对其中做字符串处理,以插入到MySQL表中
x1 = rdd.map(lambda x:x[5]).collect()
x2 = rdd.map(lambda x:x[6]).collect()
x3 = rdd.map(lambda x:x[7]).collect()
x_t1 = s_time.collect()
x_c1 = s_count.collect()
#rt_data = s_time.union(cal_data).union(s_count)
ins_data=[]
for ix in range(len(x1)):
d1=x1[ix].encode('gbk')
d2=x2[ix].encode('gbk')
d3=x3[ix].encode('gbk')
x_data = [x_t1[ix],d1,d2,d3,int(x_c1[ix])]
ins_data.append([x_data[0],x_data[1],x_data[2],x_data[3],x_data[4]])
2.5 模型训练和预测
模型训练是基于Spark Mlib模块对读取的存量MongoDB数据完成的,具体流程可参考《Python+Spark 2.0+Hadoop机器学习与大数据实战》部分内容。训练好模型后,再对量化好的实时指标数据进行实时分析判断,比如日志告警是否为正常告警、一段时间日志输出统计是否正常。
2.6 实时分析运行
1)实时分析场景
通过logstash采集其中一台服务器的日志,经过Kafka转发到Spark集群中对日志数据进行分析统计。其中日志消息格式如下:
Aug 24 17:02:24 tango-01 tango: hello tango
2)环境准备
a) 启动MySQL
[root@tango-01 mysql]# ./bin/mysqld_safe &
[root@tango-01 mysql]# ./bin/mysql -u root -p
b) 创建MySQL表
mysql> create table tb_kpi_01(stime char(20),hostid char(20),uid char(16),message char(100),scount char(8));
c) 启动zookeeper和Kafka集群
[root@tango-centos01]# nohup ./bin/zookeeper-server-start.sh ./config/zookeeper.properties &
[root@tango-centos01]# nohup ./bin/kafka-server-start.sh ./config/server.properties &
d) 检查定义的Kafka topics
[root@tango-centos01 kafka_2.11-1.1.0]# ./bin/kafka-topics.sh --describe --zookeeper 192.168.112.101:2181,192.168.112.102:2181,192.168.112.103:2181 --topic system-messages-tango-01
Topic:system-messages-tango-01 PartitionCount:3 ReplicationFactor:2 Configs:
Topic: system-messages-tango-01 Partition: 0 Leader: 1 Replicas: 1,2 Isr: 1,2
Topic: system-messages-tango-01 Partition: 1 Leader: 2 Replicas: 2,3 Isr: 2,3
Topic: system-messages-tango-01 Partition: 2 Leader: 3 Replicas: 3,1 Isr: 3,1
e) 启动logstash集群
[root@tango-01 logstash-6.2.0]# nohup ./bin/logstash -f ./config/elk-syslog/logstash-kafka.conf &
f) 启动Hadoop集群
[root@tango-spark01 spark-2.3.0]# start-dfs.sh
[root@tango-spark01 spark-2.3.0]# start-yarn.sh
g) 在Spark集群执行程序
[root@tango-spark01 spark-2.3.0]# spark-submit --master local --jars jars/spark-streaming-kafka-0-8-assembly_2.11-2.3.1.jar /usr/local/spark/ipynotebook/03-kafka2streaming-02.py
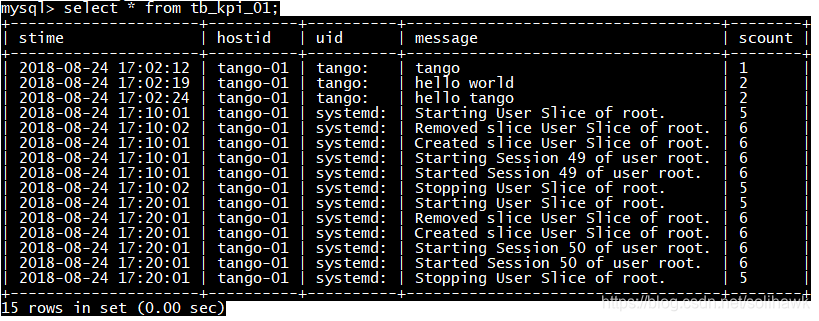
f) 在MySQL中查询表数据如下
mysql> select * from tb_kpi_01
参考资料
转载请注明原文地址:https://blog.csdn.net/solihawk/article/details/118480499
文章会同步在公众号“牧羊人的方向”更新,感兴趣的可以关注公众号,谢谢!
