Hadoop全集1-Hadoop简介
前言
??《大数据时代》有这么一句话,大数据时代的到来,可能要求 IT 将重点从 T(Technology/技术)转向 I(Information/信息)。对于行业来说,I(数据)是资源之源,数据越发膨胀,重要性也越发突出。作为大数据工程师,越发了解 I(数据)的重要性,就越是要熟练使用 T 工具来存储挖掘处理 I。本系列博文旨在记录大数据技术,包括技术的使用,调优,架构以及源码等层面,以不断增强博主对它们的理解。系列第一篇,就从大数据开山之作--Hadoop开始!?
一、Hadoop是什么
?
??Hadoop是大数据领域的开山之作,是一个由Apache基金会所开发的分布式系统基础架构。其目的是解决海量数据的存储和计算问题。从2001年Hadoop成为Apache开源项目起,20年间以Hadoop为核心,出现了处理大数据各类问题的优秀产品,所以广义的Hadoop指的是Hadoop生态
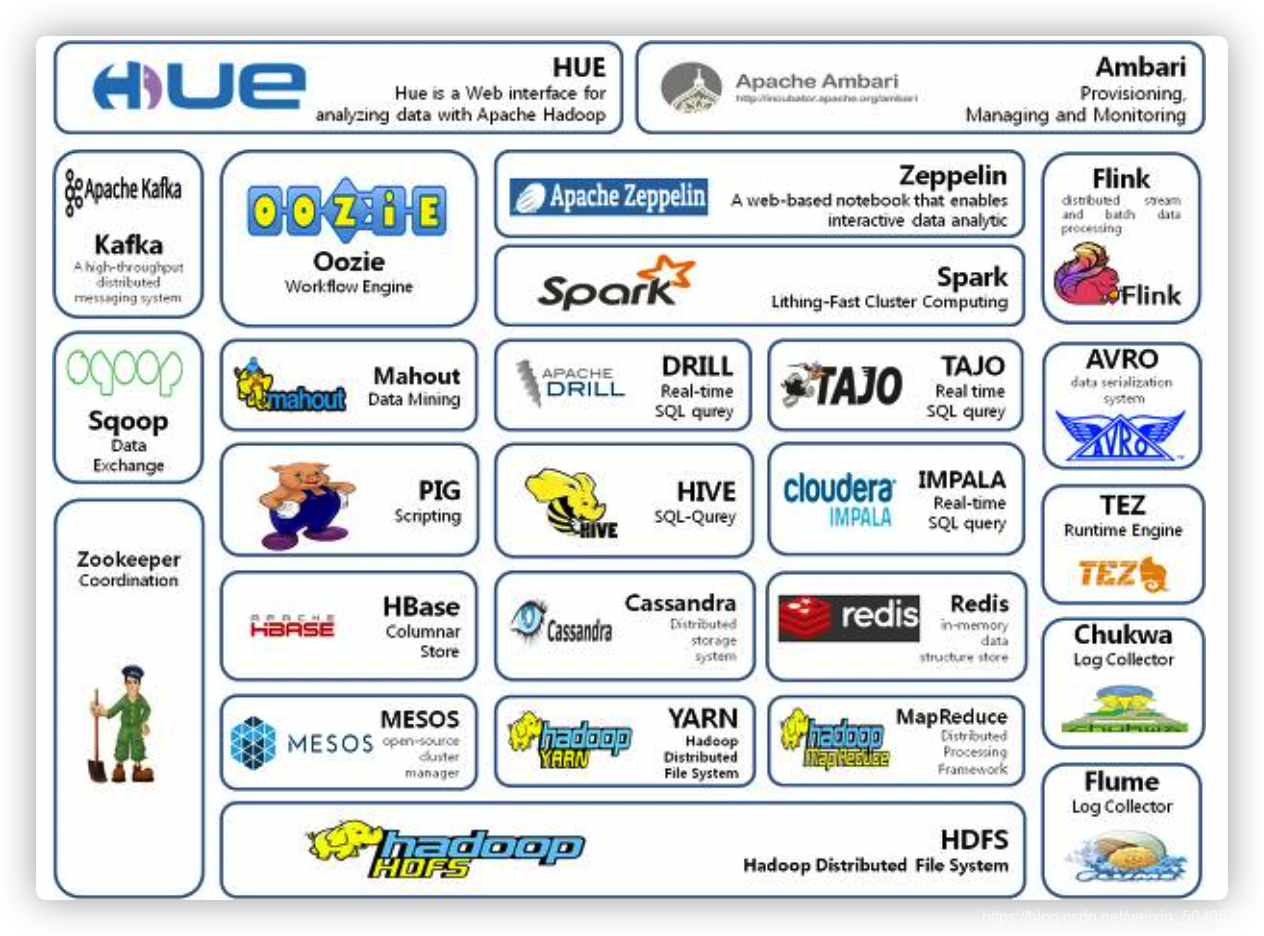
?
二、Hadoop的优势
-
高可靠性:
- Hadoop底层维护多个数据副本,所以即使Hadoop某个计算元素或存储出现故障,也不会导致数据的丢失。 高扩展性:
- 在集群间分配任务数据,可方便的扩展数以千计的节点。 高效性:
- 在MapReduce的思想下,Hadoop是并行工作的,以加快任务处理速度。 高容错性:
- 能够自动将失败的任务重新分配。 庞大生态:
- Hadoop发展的20年间,出现了许多以Hadoop为核心的大数据生态
?
三、Hadoop的组成
1、HDFS
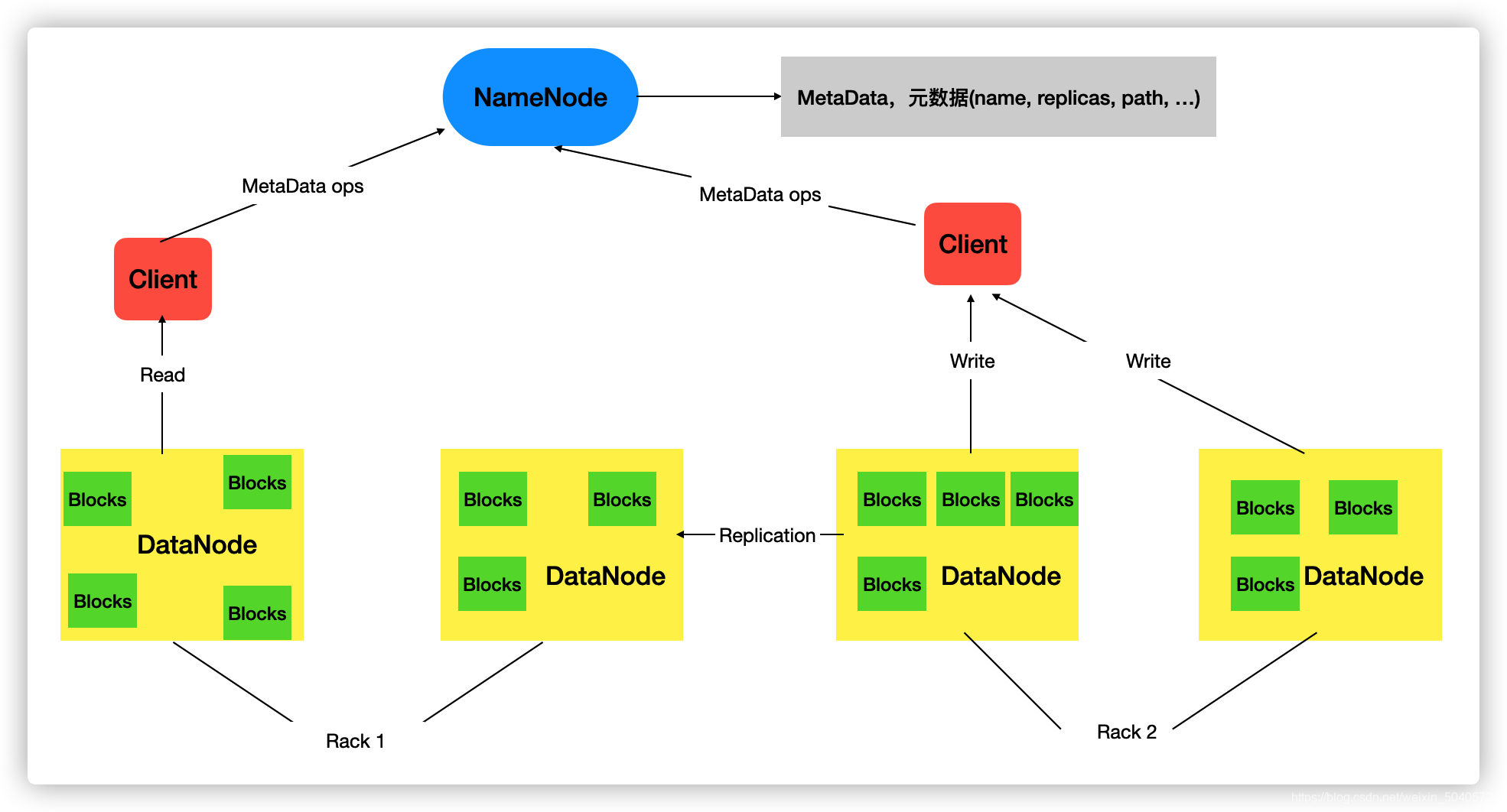
??Hadoop Distributed File System,简称HDFS,Hadoop分布式文件系统,是Hadoop海量数据储存的解决方案
??HDFS将海量数据分散储存到多个数据节点DataNode,不同DataNode存在于不同机器。资源管理者NameNode,将数据的元数据储存在本节点的目录结构中。在HDFS客户端请求存储或读取时,NameNode首先通过查询元数据,再分配储存或读取节点信息,从而提供分布式的数据存储服务
-
NameNode是资源管理者:
- (1) 管理HDFS的名称空间;
- (2) 配置副本策略;
- (3) 管理数据块(Block)映射信息;
- (4) 处理客户端读写请求。 DataNode是Slave,执行实际的操作:
- (1) 存储实际的数据块;
-
(2) 执行数据块的读/写操作。
?
2、MapReduce
?
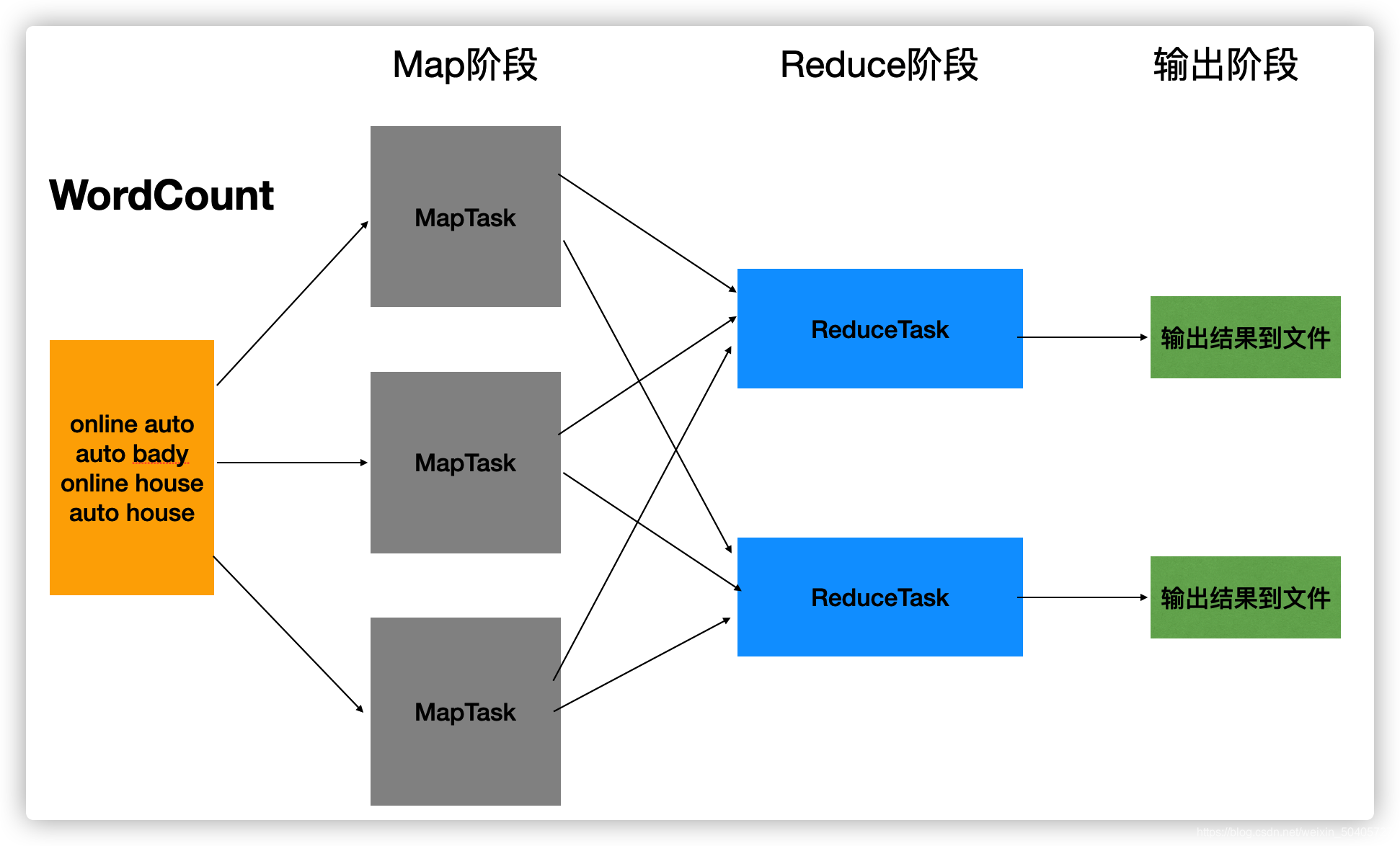
??MapReduce的作用就是处理海量数据计算,它是-个分布式运算程序的编程框架,开发人员可以再这个框架中编写数据计算代码。MapReduce 核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并发运行在一个 Hadoop 集群上
-
MapReduce核心思想:
- (1)分布式的运算程序往往需要分成至少 2 个阶段。
- (2)第一个阶段的 MapTask 并发实例,完全并行运行,互不相干。
- (3)第二个阶段的 ReduceTask 并发实例互不相干,但是他们的数据依赖于上一个阶段数据的所有 MapTask 并发实例的输出。
-
(4)MapReduce 编程模型只能包含一个 Map 阶段和一个 Reduce 阶段,如果用户的业务逻辑非常复杂,那就只能多个 MapReduce 程序,串行运行。
?
3、Yarn
?
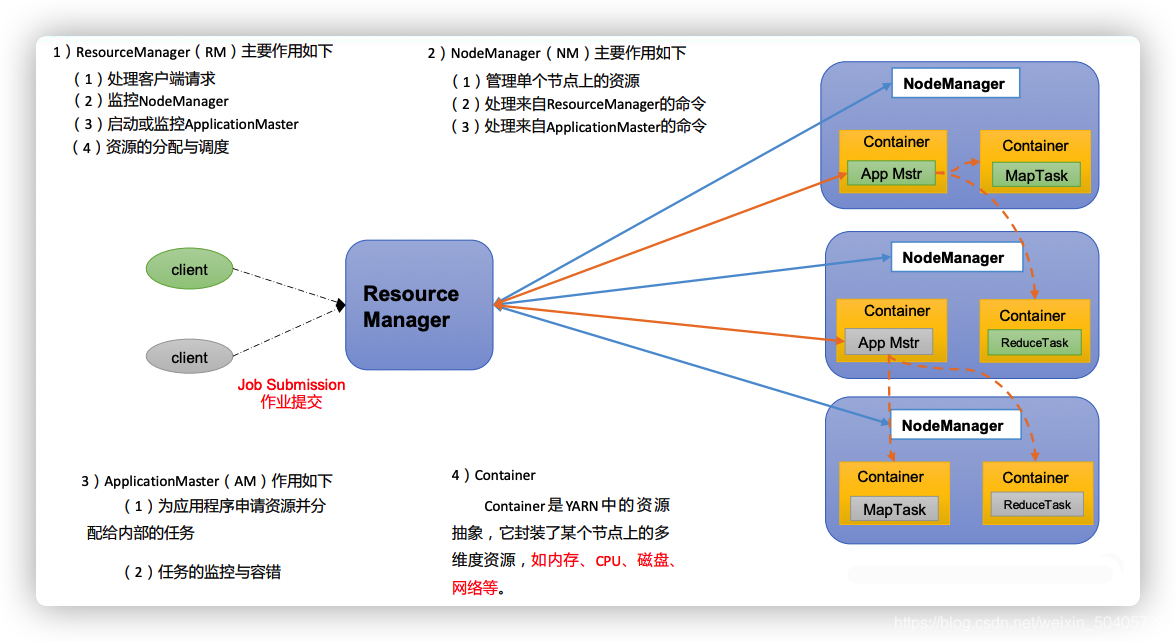
??Yarn --Yet Another Resource Negotiator 简称 YARN ,是 Hadoop2.x 版本中的一个新特性。将Yarn从MapReduce中解耦出来,作为资源调度平台,负责为运算程序提供服务器运算资源,相当于一个分布式的操作系统平台,现在的 MapReduce 等运算程序则相当于运行于操作系统之上的应用程序。
??YARN 主要由 ResourceManager、NodeManager、ApplicationMaster 和 Container 等组件
构成。
小结
??本系列博文是博主的个人知识归纳,后续会坚持更新整理所得。