1.д��ǰ��
ǰ��IJ���,���Ѿ��Ľ�����elasticsearch�İ�װ,�Լ�һЩ�Ĺ��ߵİ�װ,ֻ�Ǽ������һ����,����elasticsearchһ�㶼�벻����Ⱥ,����֪������һ���ֲ�ʽ,�����ܡ��߿��á��������������ͷ���ϵͳ,���Խ���IJ��ʹ������һ�����ļ�Ⱥ�ķ�ʽ,���������ҵĵ��Ե���������,��������ͼ����һ̨��������������elasticsearch,Ȼ����Ⱥ,��Ȼ��̨�������Ⱥ�ķ�ʽ�Ƚϼ�,��������Ͳ������ˡ�
2.���Ⱥ�ķ�ʽ
���������Ҫ�ǽ������ַ�ʽ,һ����ͨ�������õ��ļ��ķ�ʽ������̨elasticsearch,һ����ͨ�������õ��ļ��ķ�ʽ��������̨elasticsearch��
2.1.�������ļ��ķ�ʽ������̨elasticsearch
�ڽ������ֵ����,���������˽��¶�Ӧ�������ļ��е����õ������˼,���������:
#��Ⱥ������
cluster.name: king
#�ڵ������
node.name: node�\1
#�Ƿ������ڵ�
node.master: true
node.data: true
#��ַ
network.host: 0.0.0.0
#�˿�
http.port: 9200
#��������һϵ�з������ڵ������Ľڵ���������� IP ��ַ������������Ⱥ��
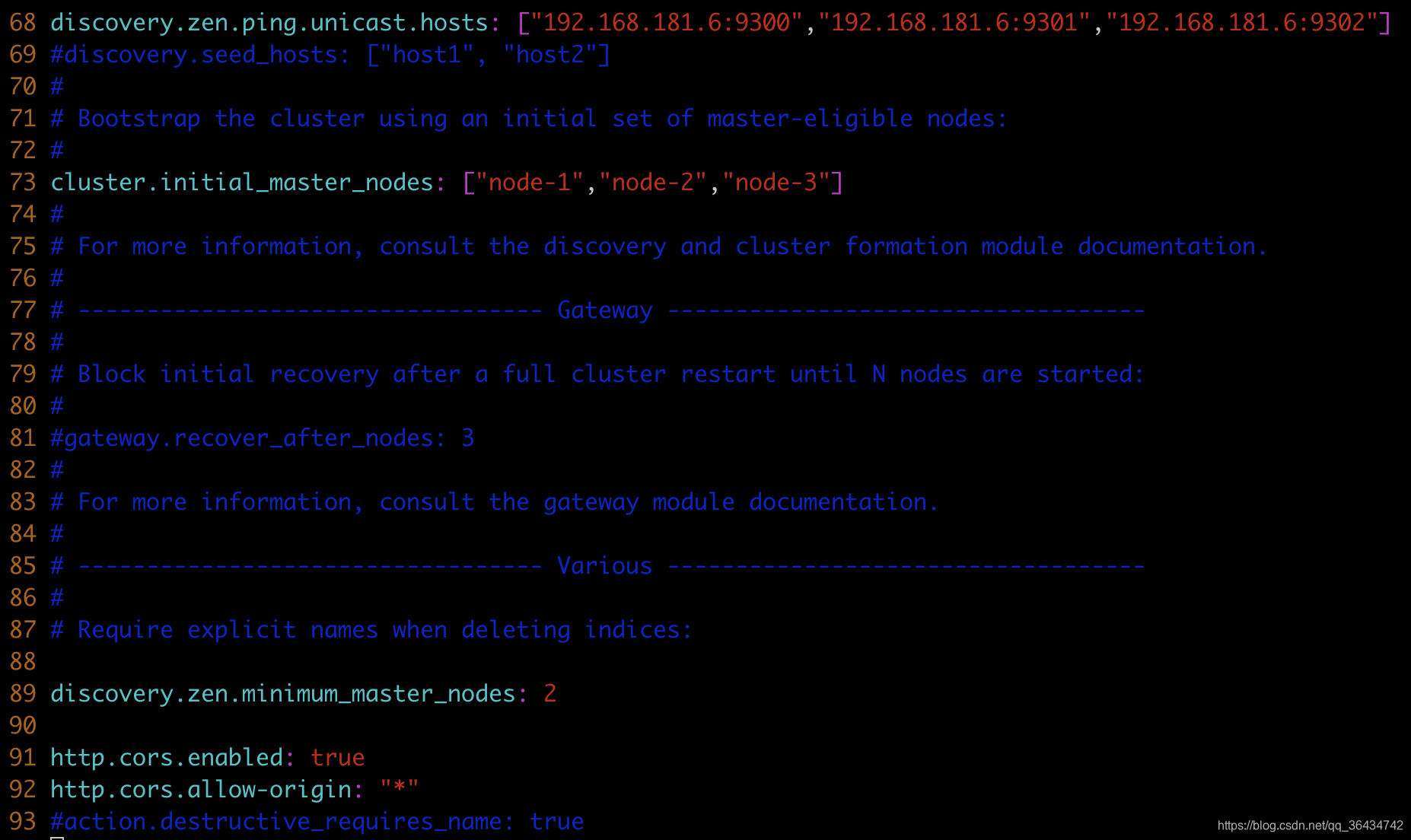
cluster.initial_master_nodes: ["node�\1"]
# �����½ڵ㱻����ʱ�ܹ����ֵ����ڵ��б�(��Ҫ���ڲ�ͬ���λ�������)
discovery.zen.ping.unicast.hosts: ["192.168.181.6","192.168.181.7","192.168.181.8"]
# �ò�������Ϊ�˷�ֹ�����ѡ��IJ������������Ϊ���γ�һ����Ⱥ,�����ڵ��ʸ������ӵĽڵ����С��Ŀ�����ƹ������
discovery.zen.minimum_master_nodes: 2
# ���������������
http.cors.enabled: true
http.cors.allow�\origin: "*"
��Ȼ�����Ѿ��˽���������õ���,��ô���Ǿ�������������Ⱥ�Ļ�����!�����Ķ�Ӧ�������ļ�,���������:
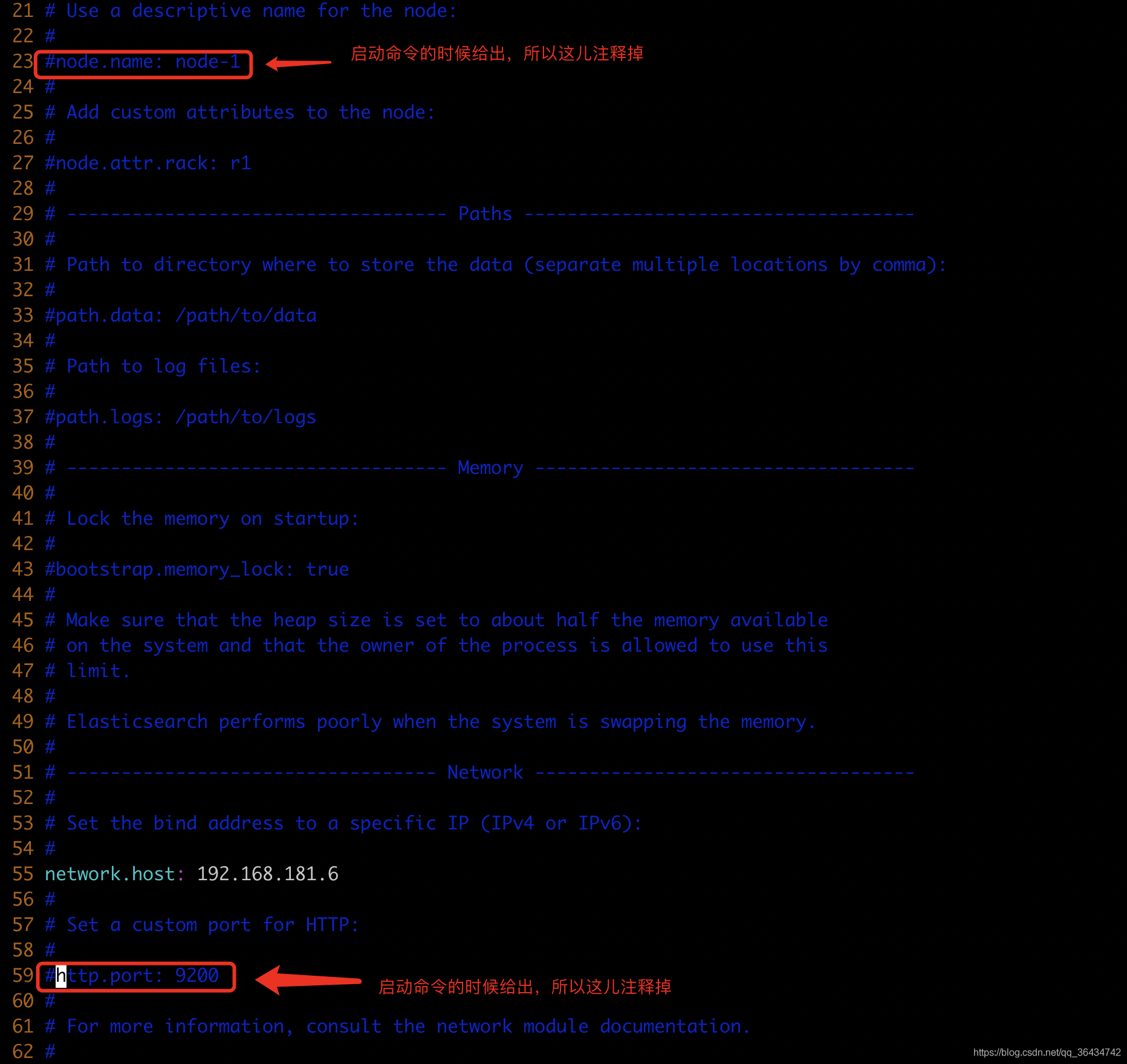
���úö�Ӧ����,Ȼ��,����elasticsearch��������ʱ��Ļ���log�ļ�����data����,�������ʱ��,������Ҫ��������ļ���,�����洢��Щ���ļ�,����/ES/node1/data``/ES/node1/logs``/ES/node2/data``/ES/node2/logs``/ES/node3/data``/ES/node3/logs�⼸���ļ���,���������:

���ʱ�����������������Ӧ����̨elasticsearch��,��������������:
./elasticsearch -d -E node.name=node-1 -E http.port=9200 -E transport.port=9300 -E path.data=/ES/node1/data -E path.logs=/ES/node1/logs
./elasticsearch -d -E node.name=node-2 -E http.port=9201 -E transport.port=9301 -E path.data=/ES/node2/data -E path.logs=/ES/node2/logs
./elasticsearch -d -E node.name=node-3 -E http.port=9202 -E transport.port=9302 -E path.data=/ES/node3/data -E path.logs=/ES/node3/logs
�������������,Ȼ������ͨ����Ӧ��ps����,��ѯ�Ľ������:

�����˵˵�ҵ������Ĵ����!֮ǰ��������ʱ��һֱ˵�ҵ�http.cors.allow�\origin: "*"����������������,Ӧ���DZ��������,���������´���һ��,Ȼ����utf-8��ʽ��������,Ȼ����������ʱ��,ֱ�ӱ���,������һ�����е�û�б��Ĵ�:**max number of threads [2048] for user [tongtech] is too low, increase to at least [4096]�û�������߳���[2048]����,���ӵ�����[4096]**��ҿ��Բο���ƪ�����½��linux��limits.conf����Ч,����ڹȸ�������п���������������������������:

�����һ�ַ�ʽ������,Ȼ�����ǿ��ڶ��ֵķ�ʽ
2.2�������ļ��ķ�ʽ������̨elasticsearch
���ַ�ʽ�Ƚϼ�,����ֻ��Ҫ��ԭ����elasticsearch��Ŀ¼��������,Ȼ��ֱ��Ķ�Ӧ�������ļ�,���������:
elasticsearch-7.3.2_node1
cluster.name: king
node.name: node�\1
node.master: true
node.data: true
network.host: 0.0.0.0
http.port: 9200
transport.port: 9300
cluster.initial_master_nodes: ["node�\1"]
discovery.seed_hosts: ["92.168.181.6:9300", "92.168.181.6:9301","92.168.181.6:9302"]
discovery.zen.minimum_master_nodes: 2
http.cors.enabled: true
http.cors.allow�\origin: "*"
elasticsearch-7.3.2_node2
cluster.name: king
node.name: node�\2
node.master: true
node.data: true
network.host: 0.0.0.0
http.port: 9201
transport.port: 9301
cluster.initial_master_nodes: ["node�\1"]
discovery.seed_hosts: ["192.168.181.6:9300", "92.168.181.6:9301","92.168.181.6:9302"]
discovery.zen.minimum_master_nodes: 2
http.cors.enabled: true
http.cors.allow�\origin: "*"
elasticsearch-7.3.2_node3
cluster.name: king
node.name: node�\3
node.master: true
node.data: true
network.host: 0.0.0.0
http.port: 9202
transport.port: 9302
cluster.initial_master_nodes: ["node�\1"]
discovery.seed_hosts: ["192.168.181.6:9300", "92.168.181.6:9301","92.168.181.6:9302"]
discovery.zen.minimum_master_nodes: 2
http.cors.enabled: true
http.cors.allow�\origin: "*"
�ֱ�����:
./elasticsearch �\p /tmp/elasticsearch_9200_pid �\d
./elasticsearch �\p /tmp/elasticsearch_9201_pid �\d
./elasticsearch �\p /tmp/elasticsearch_9202_pid �\d
���ַ�ʽ������Ͳ���ʾ,��Ϊ���ַ�ʽ�Ƚϼ�,ֻҪ��Ӧ�����õ��ļ����úþ����ˡ�
3.д�Ļ���
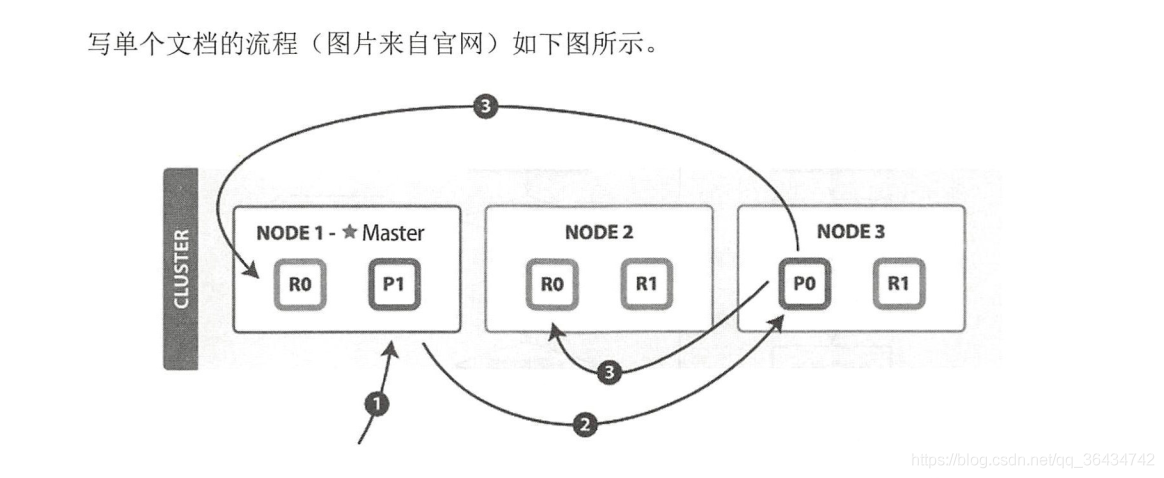
����:
- �ͻ����� NODE I ����д����
- ���Active��Shard����
- NODEI ʹ���ĵ� ID ��ȷ���ĵ����ڷ�Ƭ 0,ͨ����Ⱥ״̬�е�����·�ɱ���Ϣ��֪��Ƭ 0 ������Ƭλ��NODE3 ,�������ת���� NODE3 �ϡ�
- NODE3 �ϵ�����Ƭִ��д���� �� ���д��ɹ�,������������ת���� NODE I �� NODE2 �ĸ���Ƭ��,�ȴ����ؽ�� �������еĸ���Ƭ������ɹ�, NODE3 ����Э���ڵ㱨�� �ɹ�,Э���ڵ�����ͻ��˱���ɹ� �� �ڿͻ����յ��ɹ���Ӧʱ ,��ζ��д�����Ѿ�������Ƭ�����и���Ƭ��ִ����ɡ�
ע��:
-
ΪʲôҪ���Active��Shard��?
ES����һ������,����waitforactiveshards,���������Index��һ��setting,Ҳ�����������д��������������������ĺ�����,��ÿ��д��ǰ,��shard���پ��е�active������������������һ��Index,��ÿ��Shard��3��Replica,����Primary���ܹ���4���������������waitforactiveshardsΪ3,��ô���������һ��Replica�ҵ�,���������Replica�ҵ�,��Active�ĸ���������3,��ʱ������д�롣
�������Ĭ����1,��ֻҪPrimary�ھͿ���д��,��ʲô���á�������ô���1,������һ�ֱ���������,��֤д������ݾ��и��ߵĿɿ��ԡ������������ֻ��д��ǰ���,������֤����һ����������Щ��������д��ɹ�,���Բ������ϸ�֤������д���˶��ٸ�������
-
����ǰ�İ汾��,��дһ���Ի���,�ֱ��滻Ϊwaitforactiveshards
one:Ҫ���������д����,ֻҪ��һ��primary shard��active��Ծ���õ�,�Ϳ���ִ��
all:Ҫ���������д����,�������е�primary shard��replica shard���ǻ�Ծ��,�ſ���ִ�����д����
quorum:Ҫ�����е�shard��,�����Ǵֵ�shard���ǻ�Ծ��,���õ�,�ſ���ִ�����д����
дһ���Ե�Ĭ�ϲ����� quorum,�������ķ�Ƭ(���з�Ƭ��������������Ƭ��Ƭ)�� д�����ʱ���ڿ���״̬��
put /index/type/id?consistency=quorum quroum = int( (primary + number_of_replicas) / 2 ) + 1���� ��� version �����ĵ��汾�š���Ҫ����ʵ���ֹ��� version_type ����汾���� op_type ������Ϊ create �� ���������ĵ�������ʱ��д�� �� ����ĵ�������,��д����
��ʧ��routing ES Ĭ��ʹ���ĵ� ID ����·��,ָ�� routing ��ʹ�� routing ֵ����·�� wait_for_active_shards ���ڿ���дһ����,��ָ�������ķ�Ƭ��������ʱ��ִ��д��,��������ֱ����
ʱ ��Ĭ��Ϊ l , ����Ƭ���� ��ִ��д��refresh д����Ϻ�ִ�� refresh ,ʹ��������ɼ� timeout ����ʱʱ�� , Ĭ��Ϊ l ���� pipeline ָ�����ȴ����õ� pipeline ���� -
д��Primary��ɺ�,Ϊ��Ҫ�ȴ�����Replica��Ӧ(������ʧ��)��
�ڸ����ES�汾,Primary��Replica֮���������첽���Ƶ�,��д��Primary�ɹ����ɷ��ء���������ģʽ��,���Primary�ҵ�,���ж����ݵķ���,���Ҵ�Replica������Ҳ���ѱ�֤�ܶ������µ����ݡ����Ժ���ES��ȡ���첽ģʽ��,�ij�Primary��Replica���غ��ٷ��ظ��ͻ��ˡ�
��ΪPrimaryҪ������Replica���ز��ܷ��ظ��ͻ���,��ô�ӳپͻ��ܵ�������Replica��Ӱ��,��ȷʵ��ĿǰES�ܹ���һ���ˡ�֮ǰ������Ϊ�����ǵ�waitforactive_shards������д��ɹ����ɷ���,���Ǻ�����Դ�뷢���ǵ�����Replica���صġ�
���Replicaд��ʧ��,ES��ִ��һЩ��������,�����ղ���ǿ��һ��Ҫ�ڶ��ٸ��ڵ�д��ɹ����ڷ��صĽ����,����������ڶ��ٸ�shard��д��ɹ���,���ٸ�ʧ����
���Replicaд��ʧ��,ES��ִ��һЩ��������,�������ʧ����,��ͨ���㲥�ķ�ʽ��֪ͨ�����ķ�Ƭ����,���Խ�����������ˡ�
4.�µĽڵ��������нڵ�崻������
����ʾ���������ʱ��,�����ȴ���3����Ƭ,��������,���������ǵ�kibana,Ȼ�������ǵ�kibana����������,����kibana�������,���Բο��ҵ���һƪ���͡�
�����ǵ�kibana�Ľ�������:
�����ڿ���̨�������µ�����:
PUT /king
{
"settings": {
"number_of_shards": "4", //��Ƭ��
"number_of_replicas": "2" //������
}
}
��������:


����ĵľ��Ƿ�Ƭ,dzɫ�ľ��Ǹ���,���ʱ������������һ���ڵ�,����ԭ���ķ�ʽ,�����ȴ���/ES/node4/data``/ES/node4/logs�����ļ�,Ȼ��ִ�����µ�����:
./elasticsearch -d -E node.name=node-4 -E http.port=9203 -E transport.port=9303 -E path.data=/ES/node4/data -E path.logs=/ES/node4/logs
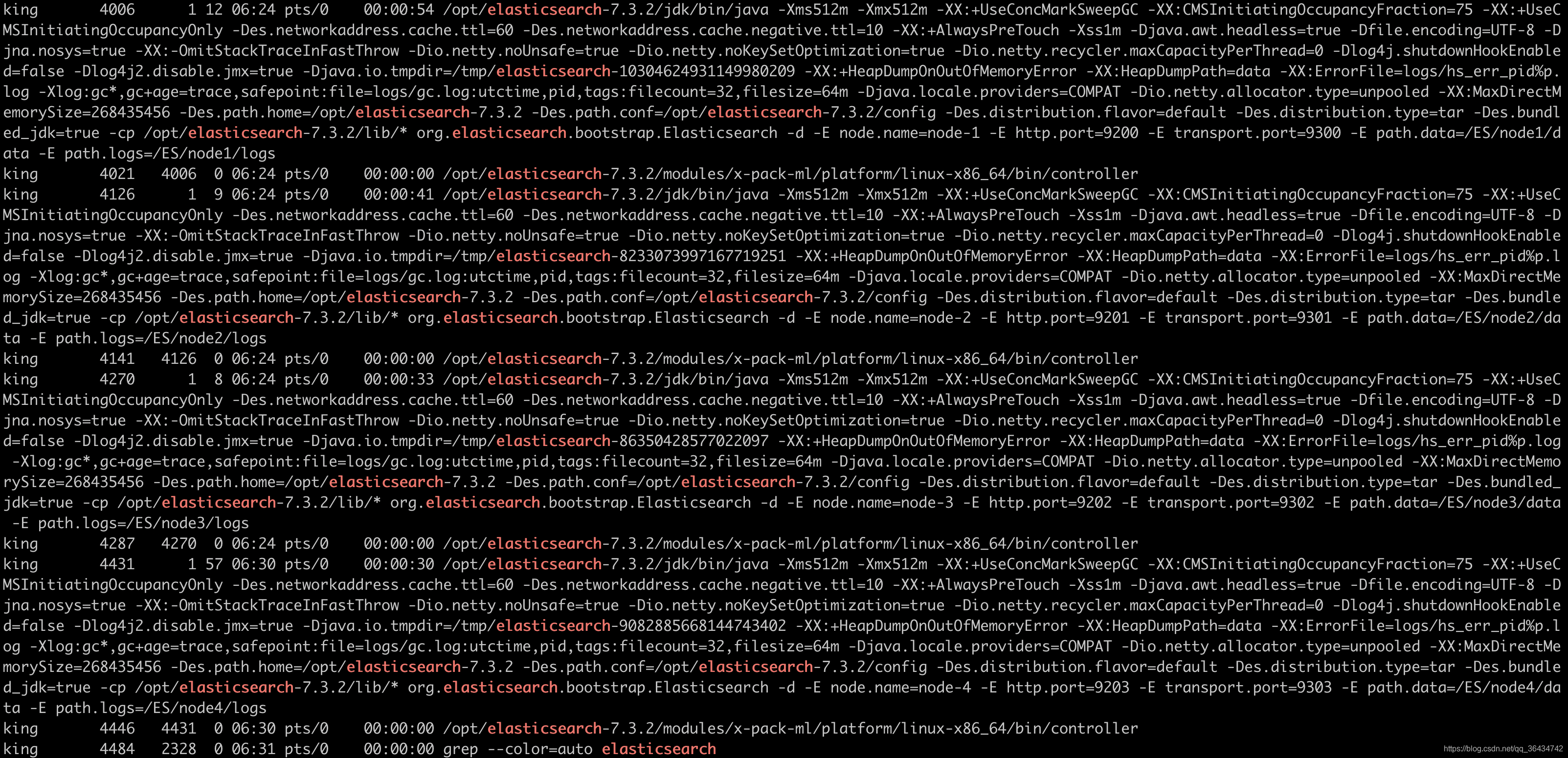
���Է������ǵ�node4�Ѿ�����������,���ʱ�����������½ڵ����Ϣ,���������:
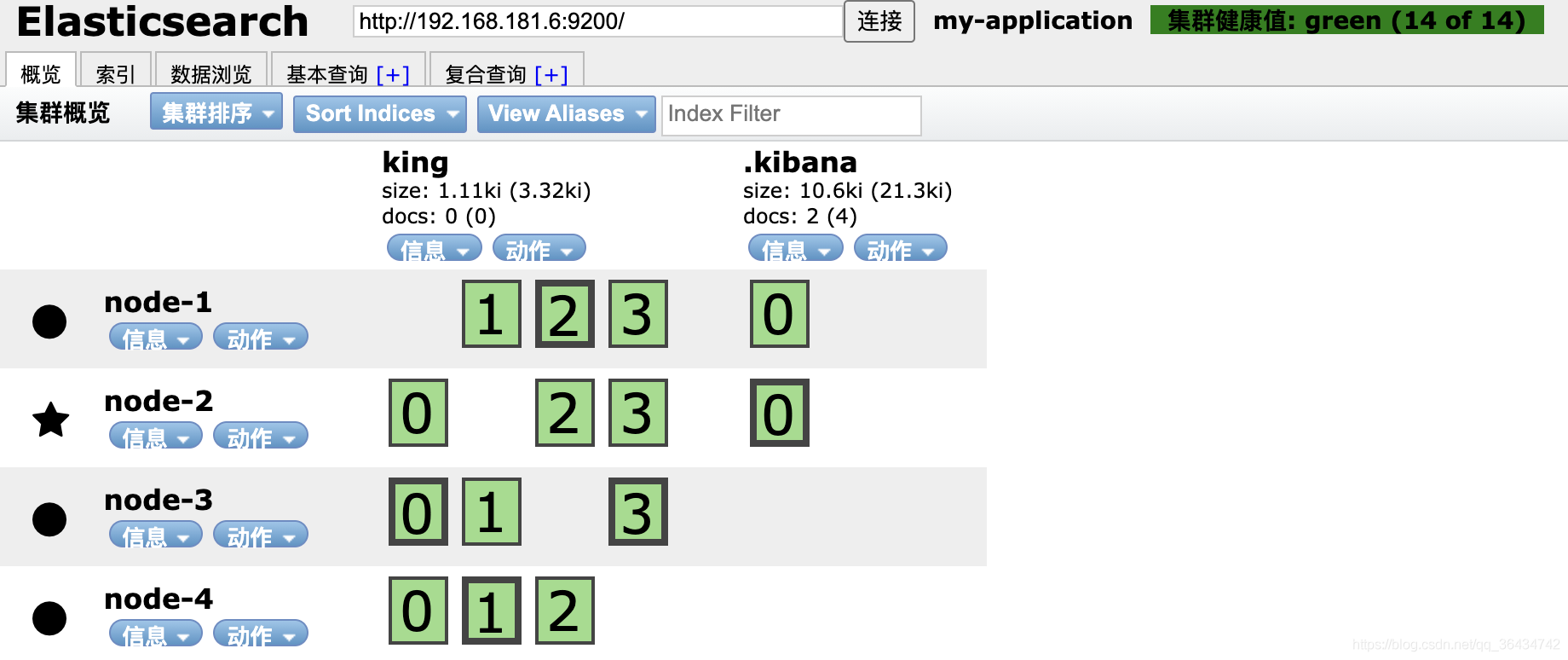
���������Ϣ���Է���:һ���ڵ�����ж������Ƭ,һ���ڵ�ֻ����һ��ͬ������ �����ܳ�������һ���ĸ�������һ���ڵ�,�������½ڵ�ʱ �����ᱻ���·�������ƬҲ��
���ʱ����������ʾ崻������,���ǽ�node-4��kill��,���������:
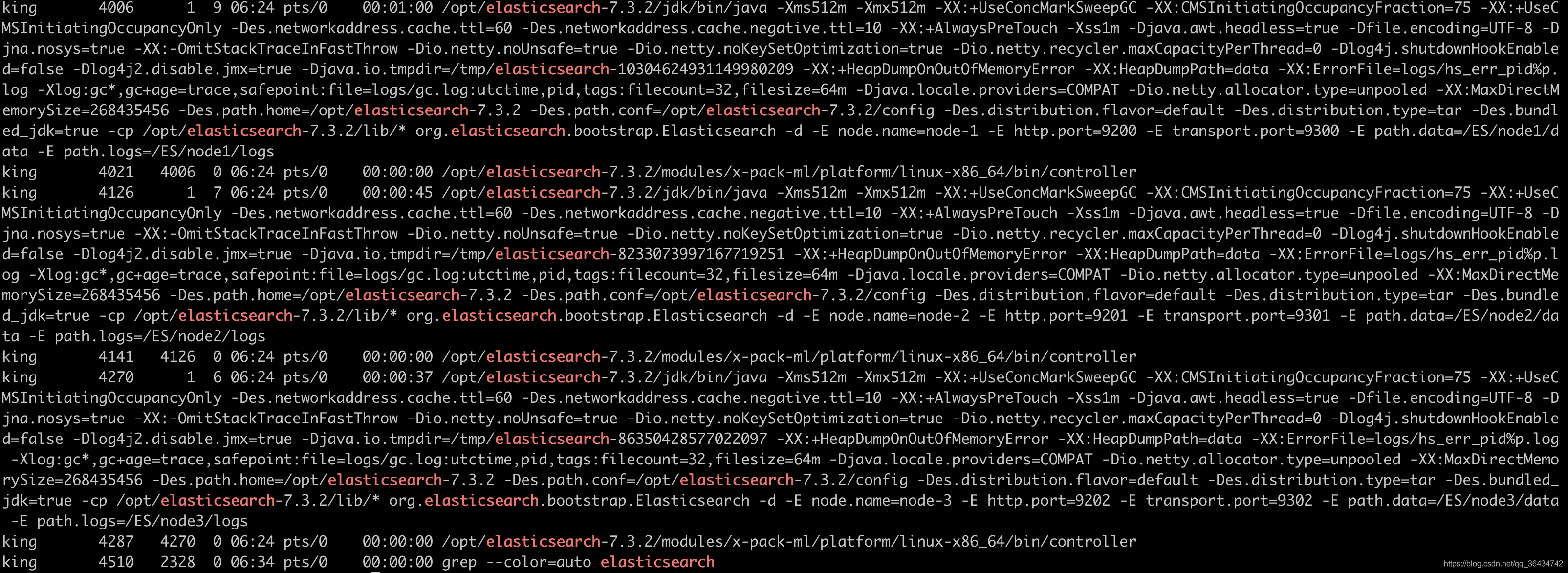
Ȼ�������������ڵ�����,�ڵ���������:

���������Ϣ���Է���:ֻ�и����ķ�Ƭ崻���Ⱥ�Զ����·��丱�� ��Ⱥ��ȻΪ��ɫ��������Ƭ�Ļ���崻��� �������Ϊ����Ƭ
�ܽ�: һ���ڵ�����ж������Ƭ,һ���ڵ�ֻ����һ��ͬ������ �����ܳ�������һ���ĸ�������һ���ڵ�,�������½ڵ�ʱ �����ᱻ���·���,����ƬҲ��,ֻ�и����ķ�Ƭ,崻���Ⱥ�Զ����·��丱��,��Ⱥ��ȻΪ��ɫ,��������Ƭ�Ļ���崻��� �������Ϊ����Ƭ
5.����
��ƪ�IJ�����Ҫ������elasticsearch�ļ�Ⱥ�Ĵ,elasticsearch��д�Ļ���,�Լ��µĽڵ�ļ���ͽڵ�崻��Է�Ƭ������Ӱ�졣