目前比较常用的注册中心有Eureka、Zookeeper、Consul和Nacos。最近对这四种注册中心的整体框架和实现进行了学习,并主要针对Nacos从源码角度学习了服务注册和订阅的具体实现。最后比较了这四种注册中心的区别。
一.Eureka
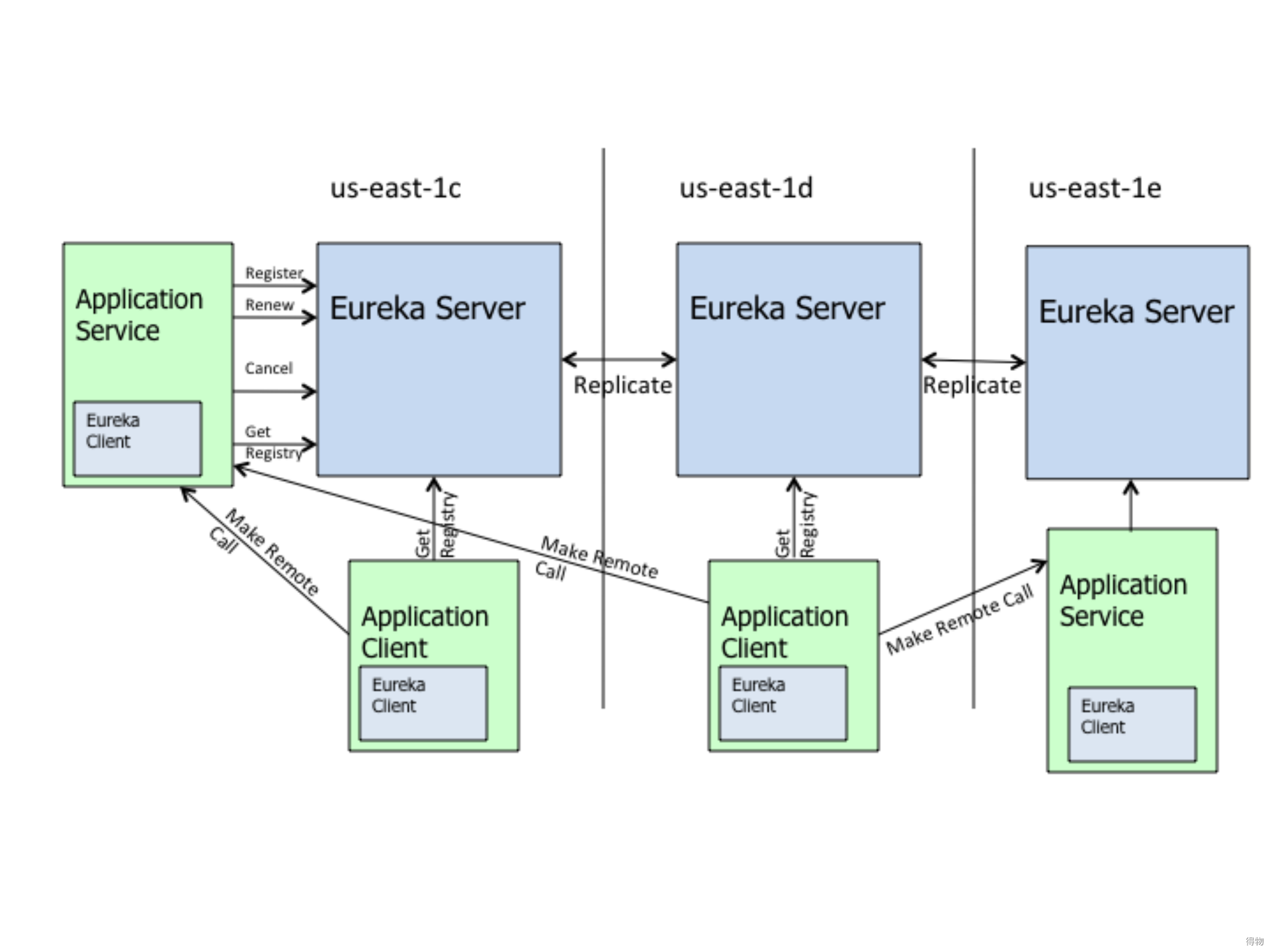
-
左上角的Eureka Client是服务提供者:向Eureka Server注册和更新自己的信息,同时能从Eureka Server注册表中获取到其他服务的信息。具体有以下四种操作:
-
Register注册:Client端向Server端注册自身的元数据以供服务发现;
-
Renew续约:通过发送心跳到Server以维持和更新注册表中服务实例元数据的有效性。当在一定时长内,Server没有收到Client的心跳信息,将默认服务下线,会把服务实例的信息从注册表中删除;
-
Cancel下线:Client在关闭时主动向Server注销服务实例元数据,这时Client的服务实例数据将从Server的注册表中删除;
-
Get Registry获取注册表:Client向Server请求注册表信息,用于服务发现,从而发起服务间远程调用。
-
-
Eureka?Server服务注册中心:提供服务注册和发现的功能。每个Eureka Client向Eureka Server注册自己的信息,也可以通过Eureka Server获取到其他服务的信息达到发现和调用其他服务的目的。
-
Eureka Client服务消费者:通过Eureka Server获取注册到其上其他服务的信息,从而根据信息找到所需的服务发起远程调用。
-
Replicate同步复制:Eureka Server之间注册表信息的同步复制,使Eureka Server集群中不同注册表中服务实例信息保持一致。由于集群间的同步复制是通过HTTP的方式进行,基于网络的不可靠性,集群中的Eureka Server间的注册表信息难免存在不同步的时间节点,不满足CAP中的C(数据一致性)。
-
Make?Remote?Call远程调用:服务客户端之间的远程调用。
二.Zookeeper
2.1 Zookeeper整体框架
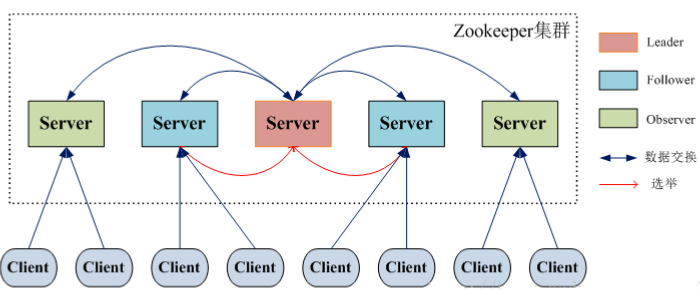
-
Leader:zookeeper 集群工作的核心,事务请求(写操作)的唯一调度和处理者,保证集群事务处理的顺序性;集群内部各个服务的调度者。 对于 create,set?data,delete 等有写操作的请求,则需要统一转发给 leader 处理,leader 需要决定编号、执行操作,这个过程称为一个事务。
-
Follower:处理客户端非事务(读操作)请求 转发事务请求给 Leader 参与集群 leader。
-
Observer:观察者角色是针对访问量较大的 zookeeper 集群新增的角色。观察zookeeper集群的最新状态变化并将这些状态同步过来,其对于非事务请求可以进行独立处理,对于事务请求,则会转发给Leader服务器处理。不会参与任何形式的投票只提供服务,通常用于在不影响集群事务处理能力的前提下提升集群的非事务处理能力,用于增加并发的请求。
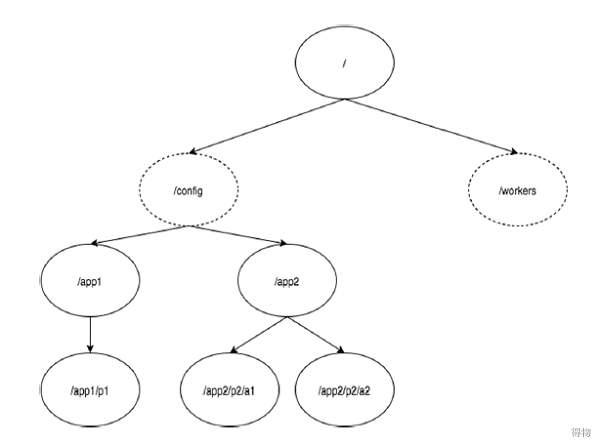
2.2 Zookeeper存储结构
下图描述了用于内存表示的ZooKeeper文件系统的树结构。ZooKeeper节点称为 znode。每个znode由一个名称标识,并用路径(/)序列分隔。在图中,首先有一个由“/”分隔的znode。在根目录下有两个逻辑命名空间 config 和 workers 。config 命名空间用于集中式配置管理,workers 命名空间用于命名。
在config命名空间下,每个znode最多可存储1MB的数据。这与UNIX文件系统相类似,除了父znode也可以存储数据。这种结构的主要目的是存储同步数据并描述znode的元数据。此结构称为 ZooKeeper数据模型。ZooKeeper命名空间中的每个节点都由路径标识。
znode兼具文件和目录两种特点。既像文件一样维护着数据长度、元信息、ACL、时间戳等数据结构,又像目录一样可以作为路径标识的一部分:
-
版本号 - 每个znode都有版本号,这意味着每当与znode相关联的数据发生变化时,其对应的版本号也会增加。当多个zookeeper客户端尝试在同一znode上执行操作时,版本号的使用就很重要。
-
操作控制列表(ACL) - ACL基本上是访问znode的认证机制。它管理所有znode读取和写入操作。
-
时间戳 - 时间戳表示创建和修改znode所经过的时间。它通常以毫秒为单位。ZooKeeper从“事务ID"(zxid)标识znode的每个更改。Zxid 是唯一的,并且为每个事务保留时间,以便你可以轻松地确定从一个请求到另一个请求所经过的时间。
-
数据长度 - 存储在znode中的数据总量是数据长度。最多可以存储1MB的数据。
ZooKeeper还具有短暂节点的概念。只要创建znode的会话处于活动状态,这些znode就存在。会话结束时,将删除znode。
2.3 Zookeeper监视功能
ZooKeeper支持watch的概念,客户端可以在znode上设置观察。znode更改时,将触发并删除监视。触发监视后,客户端会收到一个数据包,说明znode已更改。如果客户端和其中一个ZooKeeper服务器之间的连接断开,则客户端将收到本地通知。3.6.0中的新增功能:客户端还可以在znode上设置永久性的递归监视,这些监视在触发时不会删除,并且会以递归方式触发注册znode以及所有子znode的更改。
2.4 Zookeeper选举过程
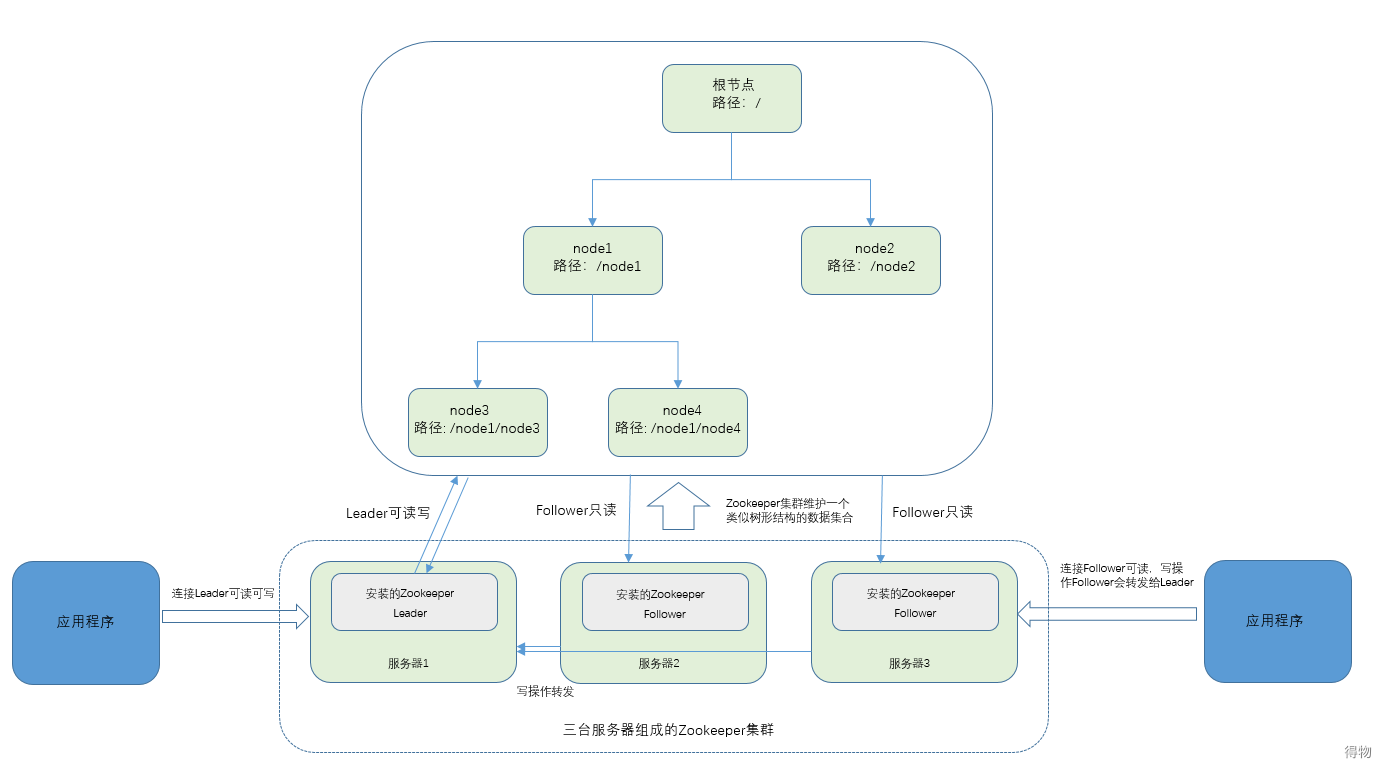
ZooKeeper至少需要三个节点才能工作,Zookeeper节点状态一般认为有4个:
-
LOOKING:表示正在进行选举的节点,处于该状态需要进入选举流程
-
LEADING:领导者状态,处于该状态的节点说明是角色已经是Leader
-
FOLLOWING:跟随者状态,表示Leader已经选举出来,当前节点角色是follower
-
OBSERVER:观察者状态,表明当前节点角色是observer,observer表示不会进入选举,仅仅只是接受选举结果,也就是说不会成为Leader节点,但是是follower节点一样提供服务。
推选Leader过程如下图所示:
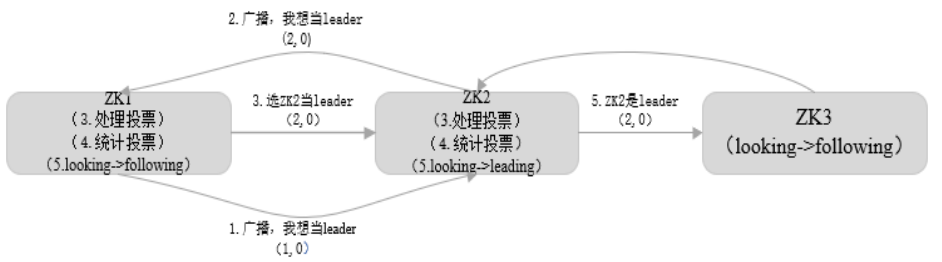
在集群初始化阶段,当有一台服务器 ZK1 启动时,无法单独进行和完成 Leader 选举,当第二台服务器 ZK2 启动时,此时两台机器可以相互通信,每台机器都试图找到 Leader,于是进入 Leader 选举过程。选举过程开始,过程如下:
(1) 每个Server发出一个投票。由于是初始情况,ZK1 和 ZK2 都会将自己作为 Leader 服务器来进行投票,每次投票会包含所推举的服务器的 ID 和 ZXID(事务ID),使用(ID, ZXID)来表示,此时ZK1的投票为(1, 0),ZK2的投票为(2, 0),然后各自将这个投票发给集群中其他机器。
(2) 接受来自各个服务器的投票。集群的每个服务器收到投票后,首先判断该投票的有效性,如检查是否是本轮投票、是否来自LOOKING状态的服务器。
(3) 处理投票。针对每一个投票,服务器都需要将别人的投票和自己的投票进行比较,规则如下:
-
优先检查 ZXID。ZXID 比较大的服务器优先作为 Leader。
-
如果 ZXID 相同,那么就比较服务器 ID 。ID 较大的服务器作为Leader服务器。
????对于 ZK1 而言,它的投票是(1, 0),接收 ZK2 的投票为(2, 0),首先会比较两者的 ZXID,均为 0,再比较 ID,此时 ZK2 的 ID更大,于是 ZK2 胜。ZK1 更新自己的投票为(2, 0),并将投票重新发送给 ZK2。
(4) 统计投票。每次投票后,服务器都会统计投票信息,判断是否已经有过半机器接受到相同的投票信息,对于 ZK1、ZK2 而言,都统计出集群中已经有两台机器接受了(2, 0)的投票信息,此时便认为已经选出 ZK2 作为Leader。
(5) 改变服务器状态。一旦确定了 Leader,每个服务器就会更新自己的状态,如果是Follower,那么就变更为FOLLOWING,如果是Leader,就变更为LEADING。当新的 Zookeeper节点ZK3启动时,发现已经有Leader了,不再选举,直接将状态从LOOKING 改为FOLLOWING。
三.Consul
3.1 Consul整体框架

?
Consul 支持多数据中心,在上图中有两个Data?Center,他们通过WAN GOSSIP在 Internet 互联,同时为了提高通信效率,只有 Server 节点才加入跨数据中心的通信。因此,consul是可以支持多个数据中心之间基于WAN来做同步的。
在单个数据中心中,Consul 分为 Client 和 Server 两种节点(所有的节点也被称为 Agent)。
-
Server节点:参与共识仲裁、存储群集状态(日志存储)、处理查询、维护与周边(LAN/WAN)各节点关系
-
Agent节点:负责通过该节点注册到consul的微服务的健康检查、将客户端注册请求以及查询转化为对server的RPC请求、维护与周边(LAN/WAN)各节点关系
它们之间通过GRPC通信。除此之外,Server和Client之间,还有一条LAN GOSSIP通信,这是用于当LAN内部发生了拓扑变化时,存活的节点们能够及时感知,比如Server节点down掉后,Client就会触发将对应Server节点从可用列表中剥离出去。所有的Server节点共同组成了一个集群,他们之间运行raft协议,通过共识仲裁选举出leader。所有的业务数据都通过leader写入到集群中做持久化,当有半数以上的节点存储了该数据后,server集群才会返回ACK,从而保障了数据的强一致性。当然,Server数量大了之后,也会影响写数据的效率。所有的follower会跟随leader的脚步,保障其有最新的数据副本。集群内的 Consul 节点通过 gossip 协议维护成员关系,如集群内现在还有哪些节点,这些节点是 Client 还是 Server。
单个数据中心的流言协议同时使用 TCP 和 UDP 通信,并且都使用 8301 端口。跨数据中心的流言协议也同时使用 TCP 和 UDP 通信,端口使用 8302。集群内数据的读写请求既可以直接发到 Server,也可以通过 Client 使用 RPC 转发到 Server,请求最终会到达 Leader 节点。
四.Nacos
4.1 Nacos整体框架
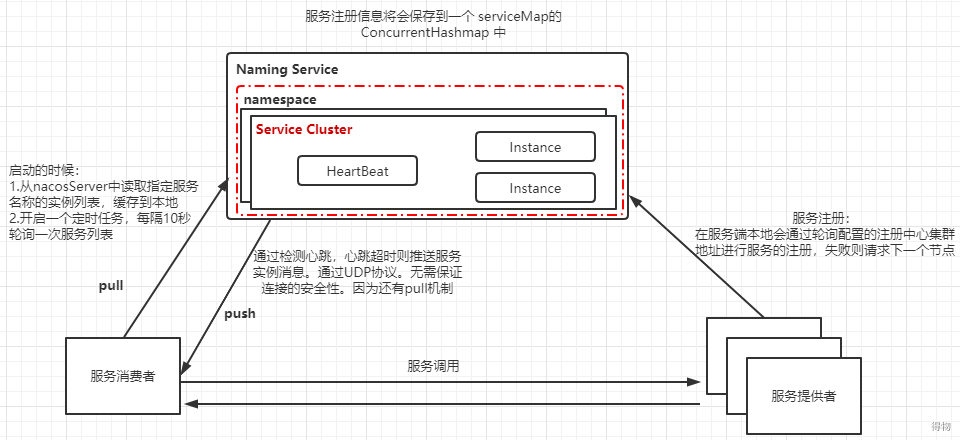
服务注册时在服务端本地会通过轮询注册中心集群节点地址进行服务得注册,在注册中心上,即Nacos Server上采用了Map保存实例信息,配置了持久化的服务会被保存到数据库中,在服务的调用方,为了保证本地服务实例列表的动态感知,Nacos与其他注册中心不同的是,采用了 Pull/Push同时运作的方式。
4.2 Nacos选举
Nacos的集群类似于zookeeper, 它分为leader角色和follower角色, 那么从这个角色的名字可以看出来,这个集群存在选举的机制。因为如果自己不具备选举功能,角色的命名可能就是master/slave了。
选举算法 :
Nacos集群采用 raft 算法来实现,它是相对zookeeper的选举算法较为简单的一种。选举算法的核心在 RaftCore 中,包括数据的处理和数据同步。
在Raft中,节点有三种角色:
-
Leader:负责接收客户端的请求
-
Candidate:用于选举Leader的一种角色(竞选状态)
-
Follower:负责响应来自Leader或者Candidate的请求
所有节点启动的时候,都是follower状态。 如果在一段时间内如果没有收到leader的心跳(可能是没有leader,也可能是leader挂了),那么follower会变成Candidate。然后发起选举,选举之前,会增加term,这个term和zookeeper 中的 epoch 的道理是一样的。
follower会投自己一票,并且给其他节点发送票据信息,等到其他节点回复在这个过程中,可能出现几种情况:
-
收到过半的票数通过,则成为leader
-
被告知其他节点已经成为leader,则自己切换为follower
-
一段时间内没有收到过半的投票,则重新发起选举。约束条件在任一term中,单个节点最多只能投一票
第一种情况,赢得选举之后,leader会给所有节点发送消息,避免其他节点触发新的选举。
第二种情况,比如有三个节点A B C。A B同时发起选举,而A的选举消息先到达C,C给A投了一票,当B的消息到达C时,已经不能满足上面提到的约束条件,即C不会给B投票,而A和B显然都不会给对方投票。A胜出之后,会给B,C发心跳消息,节点B发现节点A的term不低于自己的term,知道有已经有Leader了,于是转换成follower。
第三种情况,没有任何节点获得大多数投票,可能是平票的情况。加入总共有四个节点(A/B/C/D),Node C、Node D同时成为了candidate,但Node A投了Node D一票,Node B投了Node C一票,这就出现了平票 的情况。这个时候大家都在等待,直到超时后重新发起选举。如果出现平票的情况,那么就延长了系统不可用的时间,因此raft引入了randomizedelection timeouts来尽量避免平票情况。
4.3 Nacos服务注册流程源码
Nacos源码是在https://github.com/alibaba/nacos下载的最新版本2.0.0-bugfix (Mar 30th, 2021)。
当需要注册时,Spring-Cloud会注入实例NacosServiceRegistry。
@Override
public void registerInstance(String serviceName, String groupName, Instance instance) throws NacosException {
NamingUtils.checkInstanceIsLegal(instance);
String groupedServiceName = NamingUtils.getGroupedName(serviceName, groupName);
//添加心跳信息
if (instance.isEphemeral()) {
BeatInfo beatInfo = beatReactor.buildBeatInfo(groupedServiceName, instance);
beatReactor.addBeatInfo(groupedServiceName, beatInfo);
}
//调用服务代理类进行注册
serverProxy.registerService(groupedServiceName, groupName, instance);
}然后调用 registerService方法进行注册,构建请求参数,发起请求。
public void registerService(String serviceName, String groupName, Instance instance) throws NacosException {
NAMING_LOGGER.info("[REGISTER-SERVICE] {} registering service {} with instance: {}", namespaceId, serviceName,
instance);
final Map<String, String> params = new HashMap<String, String>(16);
params.put(CommonParams.NAMESPACE_ID, namespaceId);
params.put(CommonParams.SERVICE_NAME, serviceName);
params.put(CommonParams.GROUP_NAME, groupName);
params.put(CommonParams.CLUSTER_NAME, instance.getClusterName());
params.put("ip", instance.getIp());
params.put("port", String.valueOf(instance.getPort()));
params.put("weight", String.valueOf(instance.getWeight()));
params.put("enable", String.valueOf(instance.isEnabled()));
params.put("healthy", String.valueOf(instance.isHealthy()));
params.put("ephemeral", String.valueOf(instance.isEphemeral()));
params.put("metadata", JacksonUtils.toJson(instance.getMetadata()));
reqApi(UtilAndComs.nacosUrlInstance, params, HttpMethod.POST);
}进入reqApi方法,我们可以看到服务在进行注册的时候会轮询配置好的注册中心的地址:
public String reqApi(String api, Map<String, String> params, Map<String, String> body, List<String> servers,
String method) throws NacosException {
params.put(CommonParams.NAMESPACE_ID, getNamespaceId());
if (CollectionUtils.isEmpty(servers) && StringUtils.isBlank(nacosDomain)) {
throw new NacosException(NacosException.INVALID_PARAM, "no server available");
}
NacosException exception = new NacosException();
//service只有一个的情况
if (StringUtils.isNotBlank(nacosDomain)) {
for (int i = 0; i < maxRetry; i++) {
try {
return callServer(api, params, body, nacosDomain, method);
} catch (NacosException e) {
exception = e;
if (NAMING_LOGGER.isDebugEnabled()) {
NAMING_LOGGER.debug("request {} failed.", nacosDomain, e);
}
}
}
} else {
Random random = new Random(System.currentTimeMillis());
int index = random.nextInt(servers.size());
for (int i = 0; i < servers.size(); i++) {
String server = servers.get(index);
try {
return callServer(api, params, body, server, method);
} catch (NacosException e) {
exception = e;
if (NAMING_LOGGER.isDebugEnabled()) {
NAMING_LOGGER.debug("request {} failed.", server, e);
}
}
//轮询
index = (index + 1) % servers.size();
}
}最后通过 callServer(api, params, server, method) 发起调用
public String callServer(String api, Map<String, String> params, Map<String, String> body, String curServer,
String method) throws NacosException {
long start = System.currentTimeMillis();
long end = 0;
injectSecurityInfo(params);
Header header = builderHeader();
String url;
//发送http请求
if (curServer.startsWith(UtilAndComs.HTTPS) || curServer.startsWith(UtilAndComs.HTTP)) {
url = curServer + api;
} else {
if (!IPUtil.containsPort(curServer)) {
curServer = curServer + IPUtil.IP_PORT_SPLITER + serverPort;
}
url = NamingHttpClientManager.getInstance().getPrefix() + curServer + api;
}
}Nacos服务端的处理:
服务端提供了一个InstanceController类,在这个类中提供了服务注册相关的API
@CanDistro
@PostMapping
@Secured(parser = NamingResourceParser.class, action = ActionTypes.WRITE)
public String register(HttpServletRequest request) throws Exception {
final String namespaceId = WebUtils
.optional(request, CommonParams.NAMESPACE_ID, Constants.DEFAULT_NAMESPACE_ID);
final String serviceName = WebUtils.required(request, CommonParams.SERVICE_NAME);
NamingUtils.checkServiceNameFormat(serviceName);
// 从请求中解析出instance实例
final Instance instance = parseInstance(request);
serviceManager.registerInstance(namespaceId, serviceName, instance);
return "ok";
}然后调用 ServiceManager 进行服务的注册
public void registerInstance(String namespaceId, String serviceName, Instance instance) throws NacosException {
//创建一个空服务,在Nacos控制台服务列表展示的服务信息,实际上是初始化一个serviceMap,它是一个ConcurrentHashMap集合
createEmptyService(namespaceId, serviceName, instance.isEphemeral());
//从serviceMap中,根据namespaceId和serviceName得到一个服务对象
Service service = getService(namespaceId, serviceName);
if (service == null) {
throw new NacosException(NacosException.INVALID_PARAM,
"service not found, namespace: " + namespaceId + ", service: " + serviceName);
}
//调用addInstance创建一个服务实例
addInstance(namespaceId, serviceName, instance.isEphemeral(), instance);
}创建空服务实例时
public void createServiceIfAbsent(String namespaceId, String serviceName, boolean local, Cluster cluster)
throws NacosException {
//从serviceMap中获取服务对象
Service service = getService(namespaceId, serviceName);
//如果为空。则初始化
if (service == null) {
Loggers.SRV_LOG.info("creating empty service {}:{}", namespaceId, serviceName);
service = new Service();
service.setName(serviceName);
service.setNamespaceId(namespaceId);
service.setGroupName(NamingUtils.getGroupName(serviceName));
// now validate the service. if failed, exception will be thrown
service.setLastModifiedMillis(System.currentTimeMillis());
service.recalculateChecksum();
if (cluster != null) {
cluster.setService(service);
service.getClusterMap().put(cluster.getName(), cluster);
}
service.validate();
putServiceAndInit(service);
if (!local) {
addOrReplaceService(service);
}
}
}getService 方法中用到了Map进行存储:
private final Map<String, Map<String, Service>> serviceMap = new ConcurrentHashMap<>();Nacos是通过不同的 namespace 来维护服务的,而每个namespace下有不同的group,不同的group下才有对应的Service ,再通过这个 serviceName 来确定服务实例。第一次进来则会进入初始化,初始化完会调用 putServiceAndInit。
private void putServiceAndInit(Service service) throws NacosException {
//把服务信息保存到serviceMap集合
putService(service);
service = getService(service.getNamespaceId(), service.getName());
//建立心跳检测机制
service.init();
//实现数据一致性监听,ephemeral(标识服务是否为临时服务,默认是持久化的,也就是true)=true表示采用raft协议,false表示采用Distro
consistencyService
.listen(KeyBuilder.buildInstanceListKey(service.getNamespaceId(), service.getName(), true), service);
consistencyService
.listen(KeyBuilder.buildInstanceListKey(service.getNamespaceId(), service.getName(), false), service);
Loggers.SRV_LOG.info("[NEW-SERVICE] {}", service.toJson());
}获取到服务以后把服务实例添加到集合中,然后基于一致性协议进行数据的同步。然后调用 addInstance
public void addInstance(String namespaceId, String serviceName, boolean ephemeral, Instance... ips)
throws NacosException {
// 组装key
String key = KeyBuilder.buildInstanceListKey(namespaceId, serviceName, ephemeral);
// 获取刚刚组装的服务
Service service = getService(namespaceId, serviceName);
synchronized (service) {
List<Instance> instanceList = addIpAddresses(service, ephemeral, ips);
Instances instances = new Instances();
instances.setInstanceList(instanceList);
// 也就是上一步实现监听的类里添加注册服务
consistencyService.put(key, instances);
}
}4.4 Nacos服务订阅源码
节点的订阅在不同的注册中心中都有不同的实现,一般分为拉取和推送两种。
推送是指当订阅的节点发生更新的时候会主动向订阅方进行推送,ZK就是推送的实现方式,客户端和服务端会建立一个TCP长连接,客户端会注册一个watcher,然后当有数据更新的时候,服务端会通过长连接进行推送。通过这种建立长连接的模式,会严重消耗服务端的资源,所以当watcher比较多,并且当更新频繁的时候,Zookeeper的性能会非常低,甚至挂掉。
拉取是指订阅的节点主动定时获取服务端节点的信息,然后再本地去做一个比对,如果有改变就会做一些更新。在Consul中也有一个watcher机制,但和ZK不一样的是,他是通过Http长轮询去实现的,Consul服务端会对请求的url中是否包含wait参数进行立即返回,还是先挂起等待指定wait时间内如果服务有变化在返回。使用该方法的性能可能较高但是实时性可能不高。
在Nacos中,结合了这两个思想,既提供了拉取又提供了主动推送。
-
拉取的部分,从 hostReactor 获取 serviceInfo的具体操作如下:
public ServiceInfo getServiceInfo(final String serviceName, final String clusters) {
NAMING_LOGGER.debug("failover-mode: " + failoverReactor.isFailoverSwitch());
//拼接服务名称+集群名称(默认为空)
String key = ServiceInfo.getKey(serviceName, clusters);
if (failoverReactor.isFailoverSwitch()) {
return failoverReactor.getService(key);
}
//从ServiceInfoMap中根据key来查找服务提供者列表,ServiceInfoMap是客户端的服务地址的本地缓存
ServiceInfo serviceObj = getServiceInfo0(serviceName, clusters);
//如果为空,表示本地缓存不存在
if (null == serviceObj) {
serviceObj = new ServiceInfo(serviceName, clusters);
//如果找不到则创建一个新的然后放入serviceInfoMap,同时放入updatingMap,执行updateServiceNow,再从updatingMap移除;
serviceInfoMap.put(serviceObj.getKey(), serviceObj);
updatingMap.put(serviceName, new Object());
// 立马从Nacos server中去加载服务地址信息
updateServiceNow(serviceName, clusters);
updatingMap.remove(serviceName);
} else if (updatingMap.containsKey(serviceName)) {
//如果从serviceInfoMap找出来的serviceObj在updatingMap中则等待UPDATE_HOLD_INTERVAL
if (UPDATE_HOLD_INTERVAL > 0) {
// hold a moment waiting for update finish
synchronized (serviceObj) {
try {
serviceObj.wait(UPDATE_HOLD_INTERVAL);
} catch (InterruptedException e) {
NAMING_LOGGER
.error("[getServiceInfo] serviceName:" + serviceName + ", clusters:" + clusters, e);
}
}
}
}
// 开启定时调度,每10s去查询一次服务地址
//如果本地缓存中存在,则通过scheduleUpdateIfAbsent开启定时任务,再从serviceInfoMap取出serviceInfo
scheduleUpdateIfAbsent(serviceName, clusters);
return serviceInfoMap.get(serviceObj.getKey());
}-
Nacos推送功能,Nacos会记录上面我们的订阅者到我们的PushService
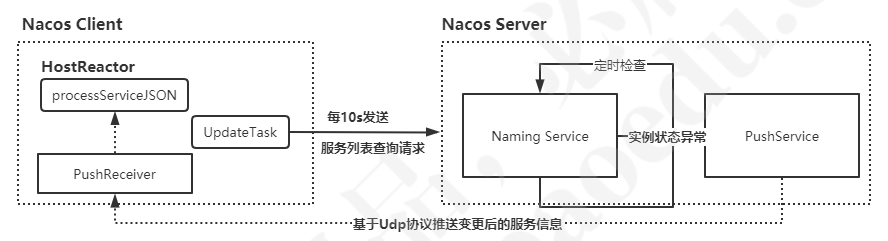
而 PushService 类实现了 ApplicationListener<ServiceChangeEvent> 所以本身又会取监听该事件,监听服务状态变更事件,然后遍历所有的客户端,通过udp协议进行消息的广播通知:
public void onApplicationEvent(ServiceChangeEvent event) {
Service service = event.getService();//获取到服务
String serviceName = service.getName();//服务名
String namespaceId = service.getNamespaceId();//命名空间
//执行任务
Future future = GlobalExecutor.scheduleUdpSender(() -> {
try {
Loggers.PUSH.info(serviceName + " is changed, add it to push queue.");
ConcurrentMap<String, PushClient> clients = clientMap
.get(UtilsAndCommons.assembleFullServiceName(namespaceId, serviceName));
if (MapUtils.isEmpty(clients)) {
return;
}
Map<String, Object> cache = new HashMap<>(16);
long lastRefTime = System.nanoTime();
for (PushClient client : clients.values()) {
if (client.zombie()) {
Loggers.PUSH.debug("client is zombie: " + client.toString());
clients.remove(client.toString());
Loggers.PUSH.debug("client is zombie: " + client.toString());
continue;
}
Receiver.AckEntry ackEntry;
Loggers.PUSH.debug("push serviceName: {} to client: {}", serviceName, client.toString());
String key = getPushCacheKey(serviceName, client.getIp(), client.getAgent());
byte[] compressData = null;
Map<String, Object> data = null;
if (switchDomain.getDefaultPushCacheMillis() >= 20000 && cache.containsKey(key)) {
org.javatuples.Pair pair = (org.javatuples.Pair) cache.get(key);
compressData = (byte[]) (pair.getValue0());
data = (Map<String, Object>) pair.getValue1();
Loggers.PUSH.debug("[PUSH-CACHE] cache hit: {}:{}", serviceName, client.getAddrStr());
}
if (compressData != null) {
ackEntry = prepareAckEntry(client, compressData, data, lastRefTime);
} else {
ackEntry = prepareAckEntry(client, prepareHostsData(client), lastRefTime);
if (ackEntry != null) {
cache.put(key, new org.javatuples.Pair<>(ackEntry.origin.getData(), ackEntry.data));
}
}
Loggers.PUSH.info("serviceName: {} changed, schedule push for: {}, agent: {}, key: {}",
client.getServiceName(), client.getAddrStr(), client.getAgent(),
(ackEntry == null ? null : ackEntry.key));
//执行 UDP 推送
udpPush(ackEntry);
}
} catch (Exception e) {
Loggers.PUSH.error("[NACOS-PUSH] failed to push serviceName: {} to client, error: {}", serviceName, e);
} finally {
futureMap.remove(UtilsAndCommons.assembleFullServiceName(namespaceId, serviceName));
}
}, 1000, TimeUnit.MILLISECONDS);
futureMap.put(UtilsAndCommons.assembleFullServiceName(namespaceId, serviceName), future);
}服务消费者此时需建立一个udp服务的监听,否则服务端无法进行数据的推送。这个监听是在HostReactor的构造方法中初始化的。
Nacos这种推送模式,对于Zookeeper那种通过tcp长连接来说会节约很多资源,就算大量的节点更新也不会让Nacos出现太多的性能瓶颈,在Nacos中客户端如果接受到了udp消息会返回一个ACK,如果一定时间Nacos-Server没有收到ACK,那么还会进行重发,当超过一定重发时间之后,就不在重发了,虽然通过udp并不能保证能真正的送到订阅者,但是Nacos还有定时轮训作为兜底,不需要担心数据不会更新的情况。
Nacos通过这两种手段,既保证了实时性,又保证了数据更新不会漏掉。
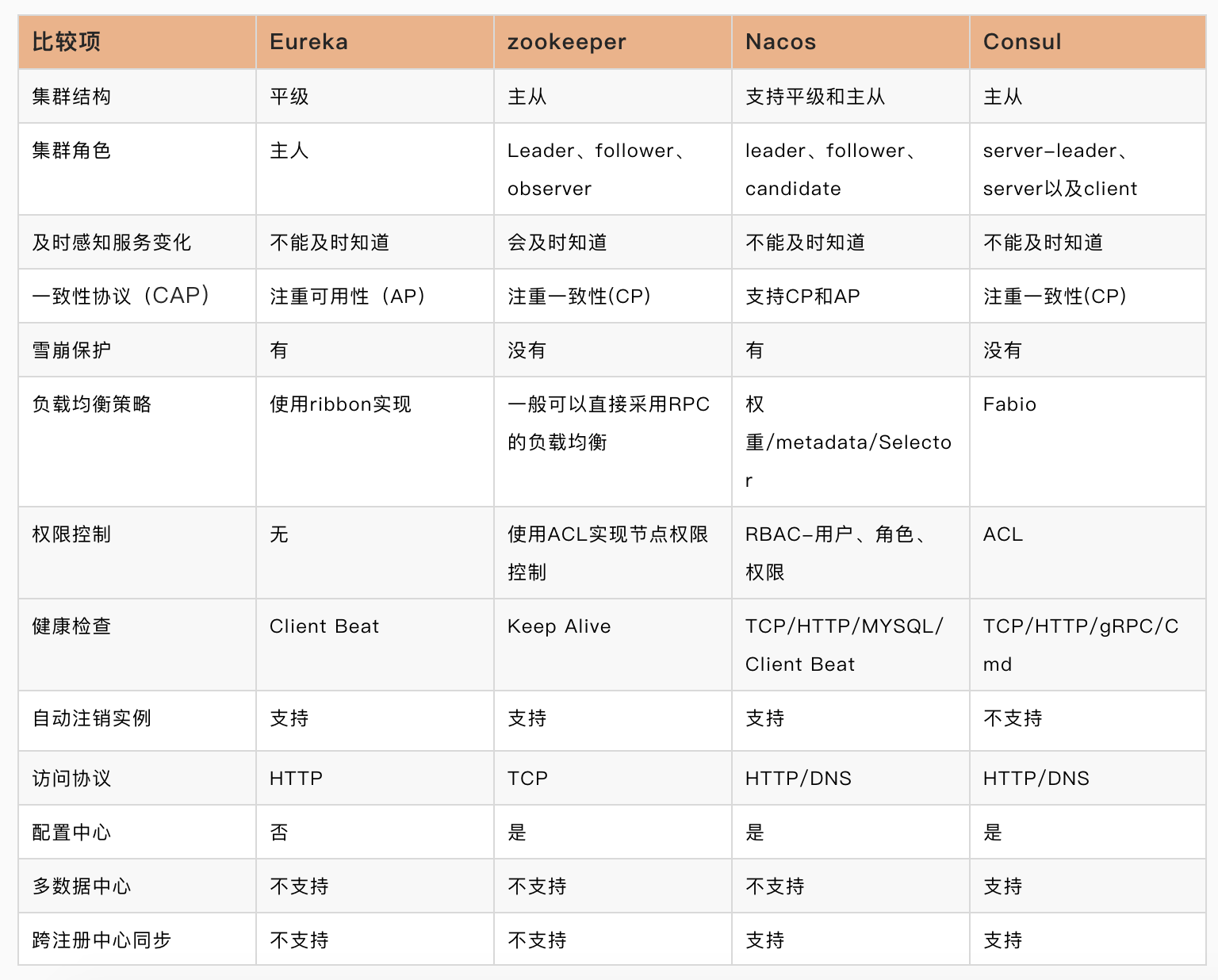
五.四种注册中心比较
四种注册中心有着各自的特点,通过以下列表可以比较清晰地对比他们的不同点:
文/hz
关注得物技术,携手走向技术的云端