数栈是云原生―站式数据中台PaaS,我们在github和gitee上有一个有趣的开源项目:FlinkX,FlinkX是一个基于Flink的批流统一的数据同步工具,既可以采集静态的数据,也可以采集实时变化的数据,是全域、异构、批流一体的数据同步引擎。大家喜欢的话请给我们点个star!star!star!
github开源项目:https://github.com/DTStack/flinkx
gitee开源项目:https://gitee.com/dtstack_dev_0/flinkx
平台建设背景
传统离线数据开发时效性较差,无法满足快速迭代的互联网需求。伴随着以Flink为代表的实时技术的飞速发展,实时计算越来越多的被企业使用,但是在使用中下面提到的各种问题也随之而来。开发者使用门槛高、产出的业务数据质量没有保障、企业缺少统一平台管理难以维护等。在诸多不利因素的影响下,我们决定利用现有的Flink技术构建一套完整的实时计算平台。
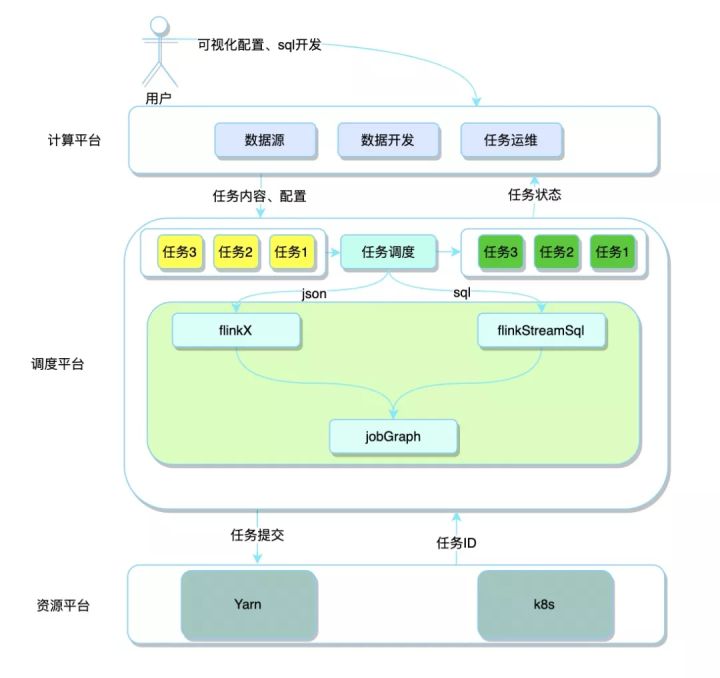
平台总体架构
从总体架构来看,实时计算平台大体可以分为三层,计算平台、调度平台、资源平台。每层承担着相应的功能,同时层于层之间又有交互,符合高内聚、低耦合的设计原则,架构图如下:
01
计算平台
直接面向开发人员使用,可以根据业务接入各种外部数据源,提供后续任务使用。数据源配置完成后,就可以在上面做基于Flink框架可视化的数据同步、sql化的数据计算的工作,并且可以对运行中的任务进行多维度的监控和告警。
02
调度平台
该层接收到平台传过来的任务内容、配置后,接下来就是比较核心的工作,也是下文中重点展开的内容,这里先做一个大体的介绍。根据任务类型的不同将使用不同的插件进行解析。
- 数据同步任务:接收到上层传过来的json后,进入到FlinkX框架中,根据数据源端和写出目标端的不同生成对应的DataStream,最后转换成JobGraph。
- 数据计算任务:接收到上层传过来的sql后,进入到FlinkStreamSql框架中,解析sql、注册成表、生成transformation,最后转换成JobGraph。
调度平台将得到的JobGraph提交到对应的资源平台,完成任务的提交。
03
资源平台
目前可以对接多套不同的资源集群,并且也可以对接不同的资源类型,如:yarn和k8s.
数据同步和数据计算
在调度平台中,接收到用户的任务后就开始了后面的一系列的转换操作,最终让任务运行起来。我们从底层的技术细节看看到底是如何基于Flink构建实时计算平台,如何使用FlinkX、FlinkStreamSql做一站式开发。
01
FlinkX
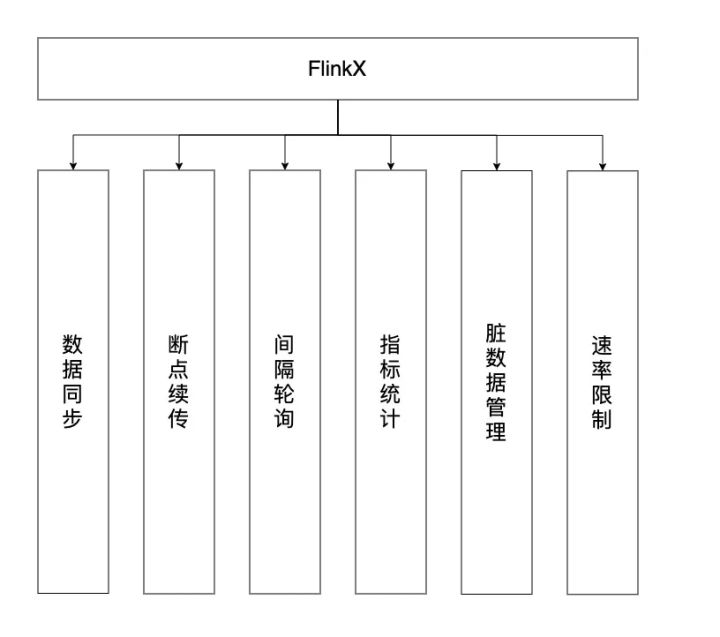
作为数据处理的第一步,也是最基础的一步,我们看看FlinkX是如何在Flink的基础上做二次开发,使用用户只需要关注同步任务的json脚本和一些配置,无需关心调用Flink的细节,并支持下图中的功能。
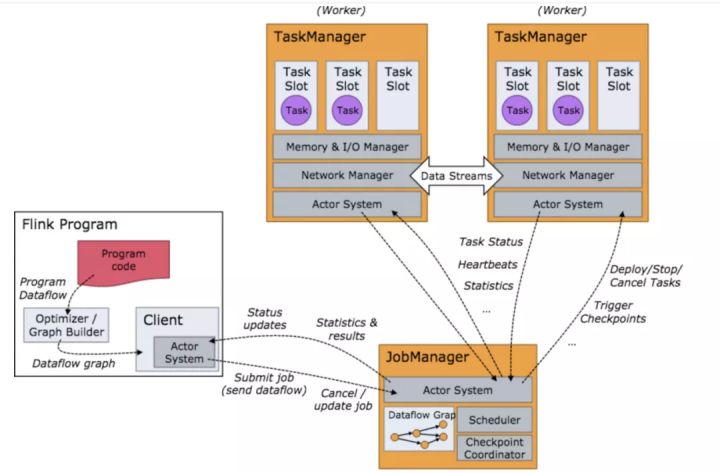
我们先看下Flink任务提交中涉及到流程,其中的交互流程图如下:
那么FlinkX又是如何在Flink的基础对上述组件进行封装和调用的,使得Flink作为数据同步工具使用更加简单,主要从Client、JobManager、TaskManager三个部分进行扩展,涉及到的内容如下图:
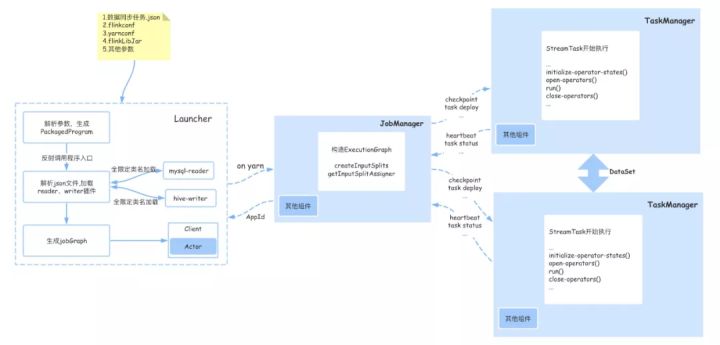
1、Client端:
FlinkX对原生的client做了部分定制化开发,在FlinkX-launcher模块下,主要有以下几个步骤:
1)解析参数,如:并行度、savepoint路径、程序的入口jar包(平常写的Flink demo)、Flink-conf.yml中的配置等。
2)通过程序的入口jar包、外部传入参数、savepoint参数生成PackagedProgram
3)通过反射调用PackagedProgram中指定的程序的入口jar包的main方法,在main方法中,通过用户配置的reader和writer的不同,加载对应的插件。
4)生成JobGraph,将其中需要的资源(Flink需要的jar包、reader和writer的jar包、Flink配置文件等)加入到YarnClusterDescriptor的shipFiles中,最后YarnClusterDescriptor就可以和yarn交互启动JobManager
5)任务提交成功后,Client端就可得到yarn返回的applicationId,后续既可以通过application跟踪任务的状态。
2、JobManager端:
client端提交完后,随后yarn启动jobmanager,jobmanager会启动一些自己内部服务,并且会构建ExecutionGraph在这个过程中FlinkX主要做了以下两件事:
1)不同插件重写InputFormat接口中的createInputSplits方法创建分片,在上游数据量较大或者需要多并行度读取的时候,该方法就起到给每个并行度设置不同的分片作用。
比如:在两个并行度读取mysql时,通过配置的分片字段(比如自增主键id)。
第一个并行度读取sql为:select * from table where id mod 2=0;
第二个并行度读取sql为:select * from table where id mod 2=1;
2)分片创建完后通过getInputSplitAssigner按顺序返回分配给各个并发实例。
3、TaskManager端:
在TaskManager端接收到JobManager调度过来的task之后,就开始了自己的生命周期的调用,主要包含以下几个重要的阶段。
1)initialize-operator-states():循环遍历该task所有的operator,并调用实现了CheckpointedFunction接口的 initializeState 方法,在FlinkX中为DtInputFormatSourceFunction和DtOutputFormatSinkFunction,该方法在任务第一次启动的时候会被调用,作用是恢复状态,当任务失败时可以从最近一次checkpoint恢复读取位置已经,从而可以达到续跑的目的,如下图所示。
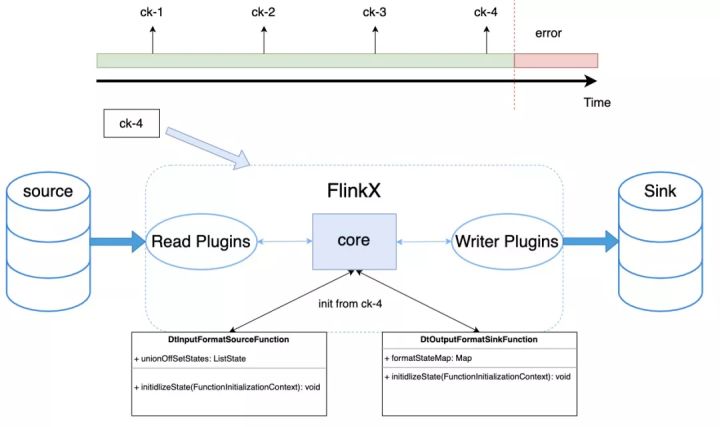
2)open-operators():该方法调用OperatorChain中所有StreamOperator的open方法,最后调用的是BaseRichInputFormat中的open方法。
该方法主要做以下几件事
- 初始化累加器,记录读入、写出的条数、字节数
- 初始化自定义的Metric
- 开启限速器
- 初始化状态
- 打开读取数据源的连接(根据数据源的不同,每个插件各自实现)
3)run():调用InputFormat中的nextRecord方法、OutputFormat中的writeRecord方法进行数据的处理了数据处理。4)close-operators():做一些关闭操作,例如调用InputFormat、OutputFormat的 close 方法等,并做一些清理工作。以上就是TaskManager中StreamTask整体的生命流程,除了上面介绍的FlinkX是如何调用Flink接口,FlinkX还有如下一些特性。
4、FlinkX的特性
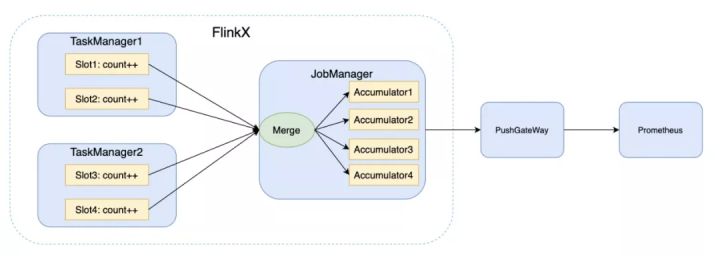
1)自定义累加器
累加器是从用户函数和操作中,分布式地统计或者聚合信息。每个并行实例创建并更新自己的Accumulator对象, 然后合并收集不同并行实例,在作业结束时由系统合并,并可将结果推动到普罗米修斯中,如图:
2)支持离线和实时同步
我们知道FlinkX是一个支持离线和实时同步的框架,这里以mysql数据源为例,看看是如何实现的。
- 离线任务:
在DtInputFormatSourceFunction的run方法中会调用InputFormat的open方法读取数据记录到resultSet中,之后再调用reachedEnd方法的判断resultSet的数据是否读取完,如果读取完,就走后续的close流程。
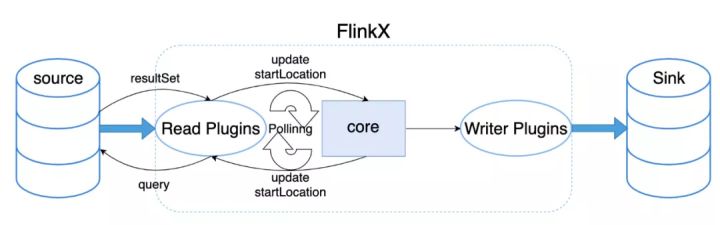
- 实时任务:
open方法和离线一致,在reachedEnd时判断是否是轮询任务,如果是则会进入到间隔轮询的分支中,将上一次轮询读取到的最大的一个增量字段值,作为本次轮询开始位置进行下一次轮询,轮询流程图如下:
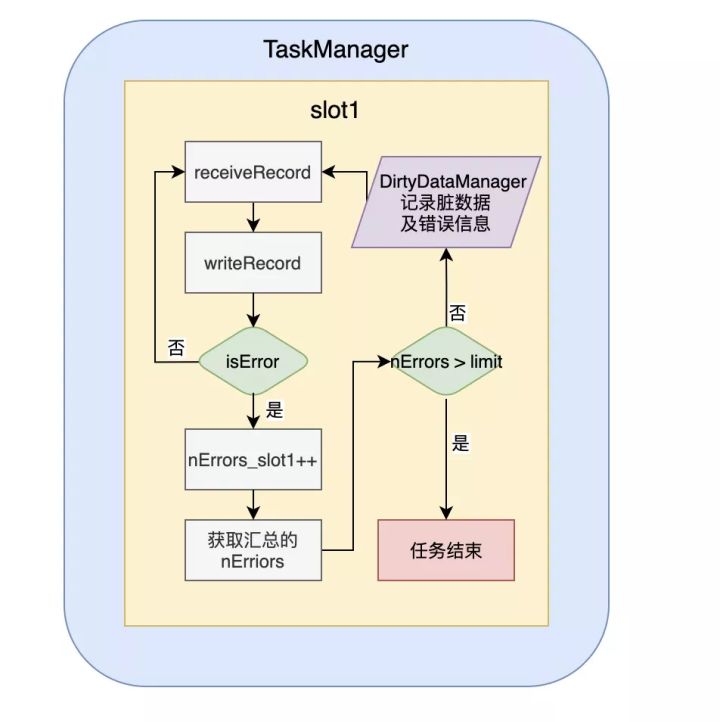
3)脏数据管理和错误控制
是把写入数据源时出错的数据记录下来,并把错误原因分类,然后写入配置的脏数据表。
错误原因目前有:类型转换错误、空指针、主键冲突和其它错误四类。
错误控制是基于Flink的累加器,运行过程中记录出错的记录数,然后在单独的线程里定时判断错误的记录数是否已经超出配置的最大值,如果超出,则抛出异常使任务失败。这样可以对数据精确度要求不同的任务,做不同的错误控制,控制流程图如下:
4)限速器
对于一些上游数据产生过快的任务,会对下游数据库造成较大的压力,故而需要在源端做一些速率控制,FlinkX使用的是令牌桶限流方式控制速率,如下图。当源端产生数据的速率达到某个阈值时,就不会在读取新的数据,在BaseRichInputFormat的open阶段也初始化了限速器。

以上就是FlinkX数据同步的基本原理,但是数据业务场景中数据同步只是第一步,由于FlinkX目前的版本中只有ETL中的EL,并不具备对数据的转换和计算的能力,故而需要将产生的数据流入到下游的FlinkStreamSql。
02
FlinkStreamSql
基于Flink,对其实时sql进行扩展,主要扩展了流与维表的join,并支持原生Flink SQL所有的语法,目前FlinkStreamSql source端只能对接kafka,所以默认上游数据来源都是kafka。
我们看看FlinkStreamSql 又是如何在Flink基础之上做到用户只需要关注业务sql代码,屏蔽底层是如何调用Flink api。整体流程和上面介绍的FlinkX基本类似,不同点在Client端,这里主要包括sql解析、注册表、执行sql 三个部分,所以这里重点介绍这部分。
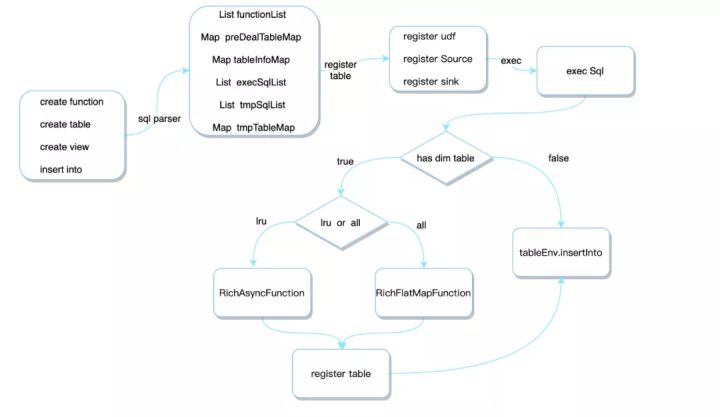
1、解析SQL这里主要是解析用户写的create function、create table、create view、insert into四种sql语句,封装到结构化的SqlTree数据结构中,SqlTree中包含了自定义函数集合、外部数据源表集合、视图语句集合、写数据语句集合。2、表注册得到了上面解析的SqlTree之后,就可以将sql中create table语句对应的外部数据源集合作为表注册到tableEnv中,并且将用户自定的udf注册进tableEnv中。3、执行SQL将数据源注册成表之后,就可以执行后面的insert into的sql语句了,执行sql这里会分两种情况1)sql中没有关联维表,就直接执行sql
2)sql中关联了维表,由于在Flink早期版本中不支持维表join语法,我们在这块做了扩展,不过在FlinkStreamsql v1.11之后和社区保持了一致,支持了和维表join的语法。根据维表的类型不同,使用不同的关联方式
- 全量维表:将上游数据作为输入,使用RichFlatMapFunction作为查询算子,初始化时将数据全表捞到内存中,然后和输入数据组拼得到打宽后的数据,然后重新注册一张大表,供后续sql使用。
- 异步维表:将上游数据作为输入,使用RichAsyncFunction作为查询算子,并将查询得到的数据使用LRU缓存,然后和输入数据组拼得到打宽后的数据,然后重新注册一张大表,供后续sql使用。
上面介绍的就是和FlinkX在client端的不同之处,由于source端只有kafka且使用了社区原生的kafka-connector,所以在jobmanager端也没有数据分片的逻辑,taskmanager逻辑和FlinkX基本类似,这里不再介绍。
任务运维
当使用FlinkX和FlinkStreamSql开发完业务之后,接下来进入到了任务运维阶段了,在运维阶段,我们主要在任务运行信息、数据进出指标metrics、数据延迟、反压、数据倾斜等维度做了监控。
01
任务运行信息
我们知道FlinkStreamSql是基于Flinksql封装的,所以在提交任务运行时最终还是走的Flinksql的解析、验证、逻辑计划、逻辑计划优化、物理计划,最后将任务运行起来,也就得到了我们经常看见的DAG图:
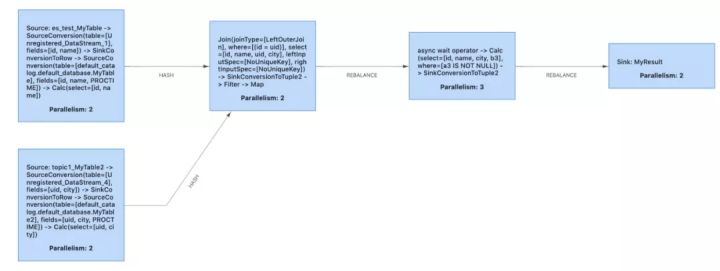
但是由于Flinksql对任务做了很多优化,以至于我们只能看到如上图的大体DAG图,子DAG图里面的一些细节我们是没法直观的看到发生了什么事情。
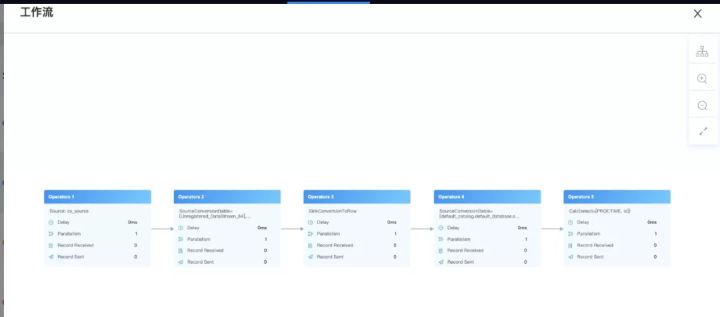
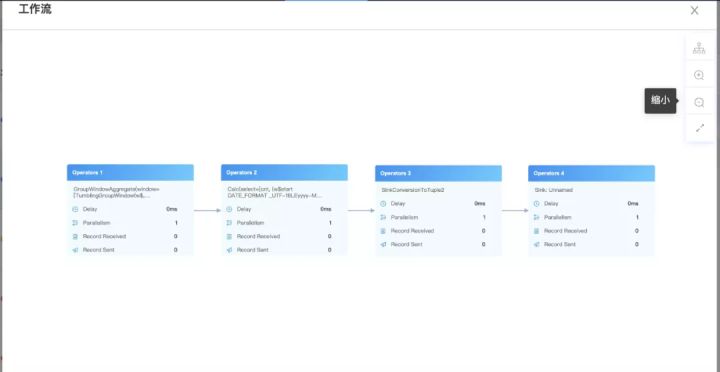
所以我们在原来生成DAG图的方式上进行了一定的改造,这样就能直观的看到子DAG图中每个Operator和每个并行度里面发生了什么事情,有了详细的DAG图后其他的一些监控维度就能直观的展示,比如:数据输入输出、延时、反压、数据倾斜,在出现问题时就能具体定位到,如下图的反压:
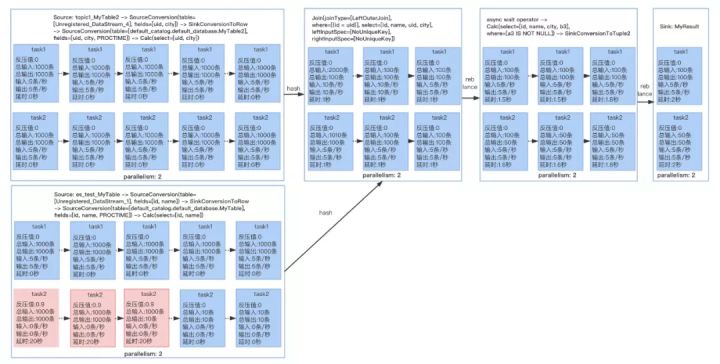
了解了上面的结构后,我们看看是如何实现的。我们知道在client提交任务时,会生成JobGraph,JobGraph中的taskVertices集合就封装了上图完整的信息,我们将taskVertices生成json后,然后在结合LatencyMarker和相关的metrics,在前端即可生成上图,并做相应的告警。除了上面的DAG以外,还有自定义metrics、数据延时获取等,这里不具体介绍,有兴趣的同学可以参考FlinkStreamSql项目。
使用案例
通过上面的介绍后,我们看下如何在平台上使用,下面展示了一个完整的案例:使用FlinkX将mysql中新增用户数据实时同步到kafka,然后使用Flinkstreamsql消费kafka实时计算每分钟新增用户数,产出结果落库到下游mysql,供业务使用。
01
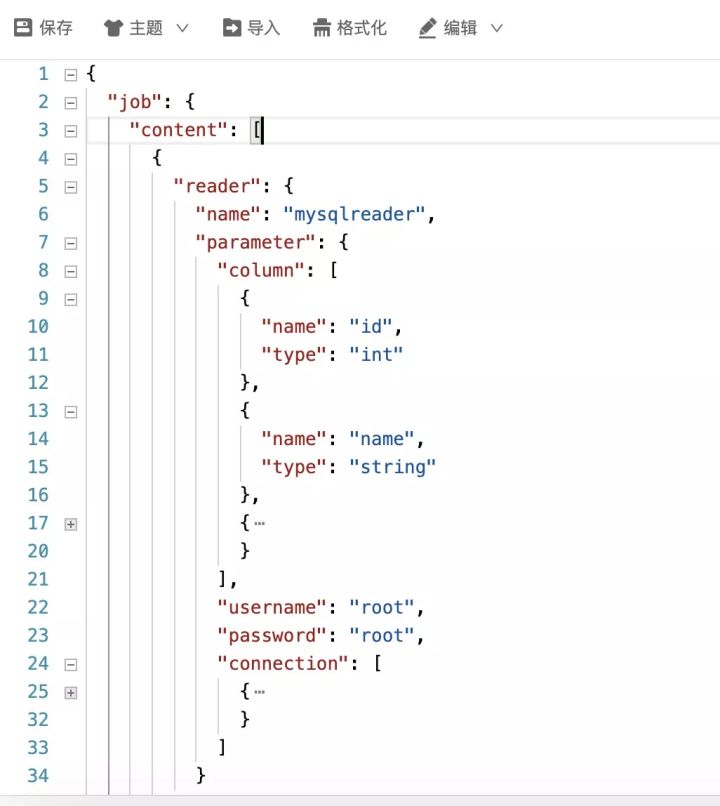
实时同步mysql新增数据
02
实时计算每分钟新增用户数

03
运行信息
整体DAG,可以直观的显示上面提到的多项指标
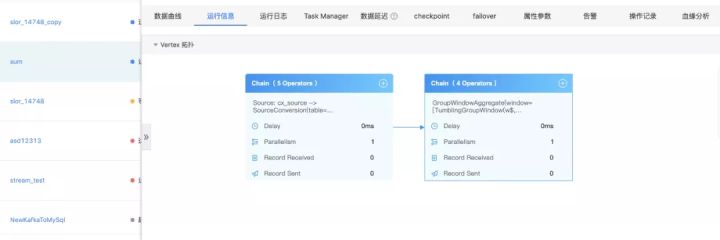
解析后的详细DAG图,可以看到子DAG内部的多项指标
以上就是Flink在袋鼠云实时计算平台总体架构和一些关键的技术点,如有不足之处欢迎大家指出。
