Hadoop3��Ⱥ����
����
master 192.168.128.130
slave1 192.168.128.131
slave2 192.168.128.132
slave3 192.168.128.133
��װ��
hadoop-3.2.2.tar.gz
����: https://pan.baidu.com/s/1esiIfOfC7nm-B9b1oTm8AQ
��ȡ��: a2ng
jdk-8u151-linux-x64.rpm
����: https://pan.baidu.com/s/1PA_EX5-IY6mtHsgxfUQbtw
��ȡ��: ny9i
��װjdk(��̨�������Ҫ)
1.��jdk��װ���ϴ����������/optĿ¼��(����ʹ��Xmanager Enterprise 5��xfp�ϴ�,����Ļ����аٶ���)
Ȼ��ִ������cd /opt,�л���optĿ¼��,��ʹ������rpm �C ivh jdk-8u151-linux-x64.rpm��ѹ��/usrĿ¼��
2.ʹ��vi /etc/profile����������������
#java_home���ݸ��˰�װ��javaλ��,��Ҫ�����ʵ�����
export JAVA_HOME=/usr/java/jdk1.8.0_151
export PATH=$PATH:$JAVA_HOME/bin
��ʹ��source /etc/profileʹ������Ч
3.ʹ������java -version�鿴jdk�Ƿ����óɹ�
Hadoop3.2.2��װ(master�ڵ�)
1.��hadoop-3.2.2.tar.gz�ϴ���master�ڵ��/optĿ¼��
ʹ������cd /opt�л���/optĿ¼��,��ʹ��tar -zxf hadoop-3.2.2.tar.gz -C /usr/local��ѹ(ps:hadoop3.2.2ͦ���,��ѹ��Ҫһ��ʱ��)
2.ʹ��cd /usr/local/hadoop-2.6.5/etc/hadoop/����hadoopĿ¼���ļ�(������Xmanager Enterprise 5��xfp����master������,�ȽϷ���)
���ݸ��������������,���ļ��еij��ֵ�master��slave1��slave2��slave3�����ʵ�����;����java_home��λ��ҲҪ���������jdk��װλ��
PS:�����е��ļ�ԭ������.template,��Ҫ�����ļ���(���ǽ��ļ�����.templateȥ��)
- core-site.xml
ĩβ�������´���:
<configuration>
<property>
<name>fs.defaultFS</name><value>hdfs://master:8020</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/var/log/hadoop/tmp</value>
</property>
</configuration>
- hadoop-env.sh
ĩβ�������´���:
export JAVA_HOME=/usr/java/jdk1.8.0_151
- hdfs-site.xml
ĩβ�������´���:
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///data/hadoop/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///data/hadoop/hdfs/data</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:50090</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
</configuration>
- mapred-site.xml
ĩβ�������´���:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- jobhistory properties -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name><value>master:19888</value>
</property>
</configuration>
- yarn-env.sh
ĩβ�������´���:
export JAVA_HOME=/usr/java/jdk1.8.0_151
- yarn-site.xml
ĩβ�������´���:
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>${yarn.resourcemanager.hostname}:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>${yarn.resourcemanager.hostname}:8030</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>${yarn.resourcemanager.hostname}:8088</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.https.address</name>
<value>${yarn.resourcemanager.hostname}:8090</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>${yarn.resourcemanager.hostname}:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>${yarn.resourcemanager.hostname}:8033</value>
</property>
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>/data/hadoop/yarn/local</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.nodemanager.remote-app-log-dir</name>
<value>/data/tmp/logs</value></property>
<property>
<name>yarn.log.server.url</name>
<value>http://master:19888/jobhistory/logs/</value>
<description>URL for job history server</description>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>2048</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>512</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>4096</value>
</property>
<property>
<name>mapreduce.map.memory.mb</name>
<value>2048</value>
</property>
<property>
<name>mapreduce.reduce.memory.mb</name>
<value>2048</value>
</property>
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>1</value>
</property>
</configuration>
- workers(��ʵ����hadoop2�е�slaves�ļ�)
ĩβ�������´���:
master
slave1
slave2
slave3
3.ʹ��cd /usr/local/hadoop-3.2.2/sbin����sbinĿ¼���ļ�(�����hadoop3������,֮ǰhadoop2û�и�����,������ĵĻ�hadoop3��Ⱥ�����ᱨ��)
��start-dfs.sh��stop-dfs.sh��ͷ�������´���:
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
��start-yarn.sh��stop-yarn.sh��ͷ�������´���:
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
�����ļ������ٶ�������,����hyn4
4.master�ڵ㿽��hadoop�ļ�������slave�ڵ�
��������:
scp -r /usr/local/hadoop-3.2.2 slave1:/usr/local
scp -r /usr/local/hadoop-3.2.2 slave2:/usr/local
scp -r /usr/local/hadoop-3.2.2 slave3:/usr/local
5.��ʽ��namenode�ڵ�(��̨�������Ҫ)
��������:
cd /usr/local/hadoop-3.2.2/bin
./hdfs namenode -format
6.hadoop��Ⱥ����
��master�ڵ�ʹ������cd /usr/local/hadoop-3.2.2/sbin�л���sbinĿ¼��
���ַ�������hadoop��Ⱥ
- start-all.sh
- ��./start-dfs.sh,Ȼ����./start-yarn.sh
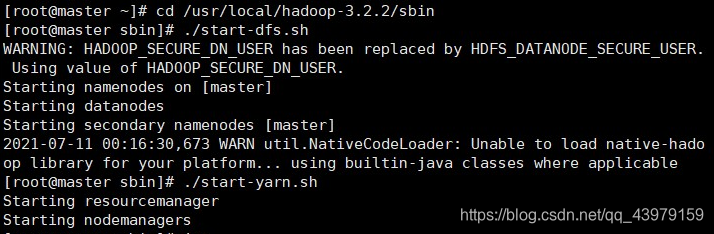
7.jps�鿴���:




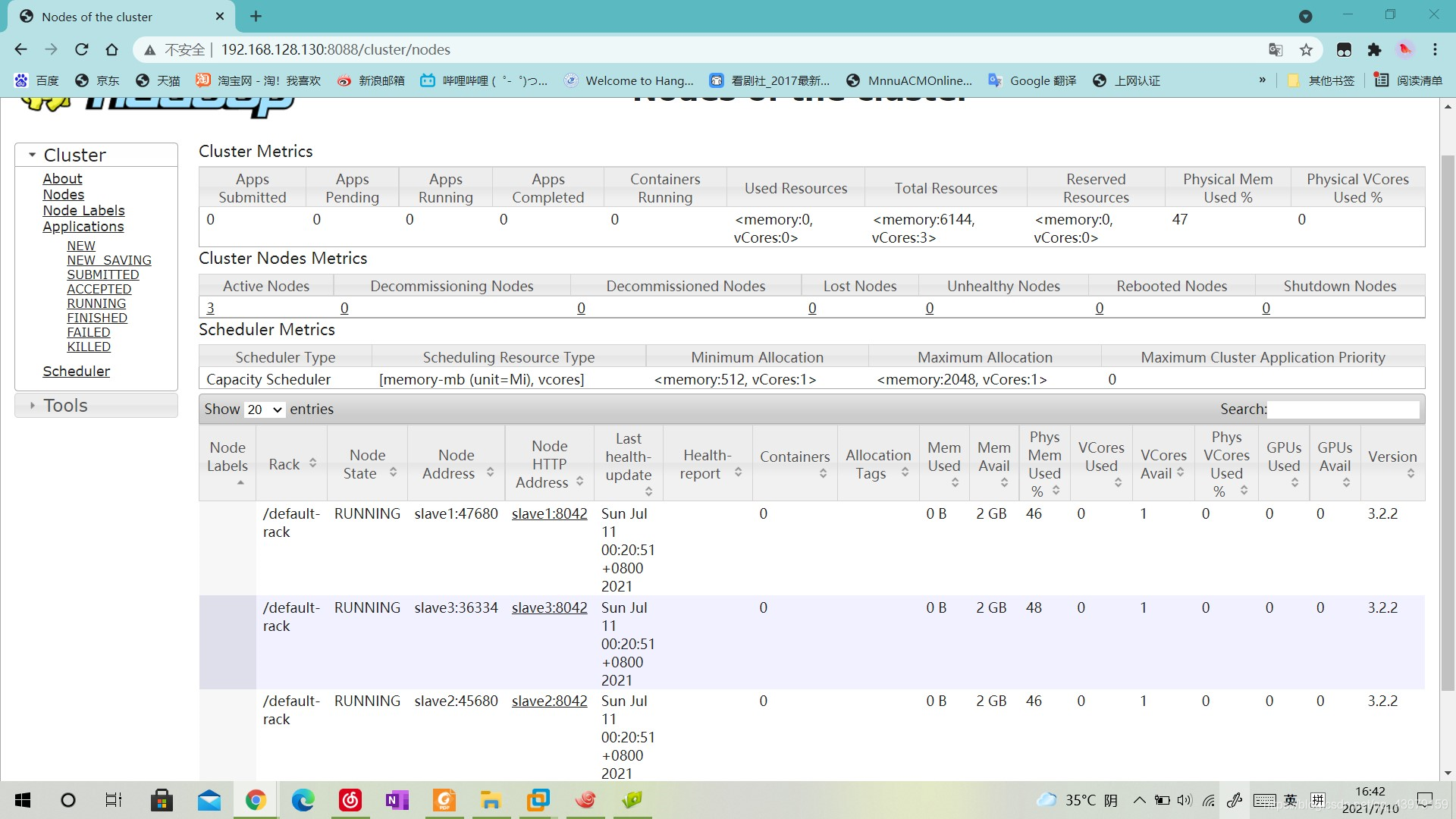
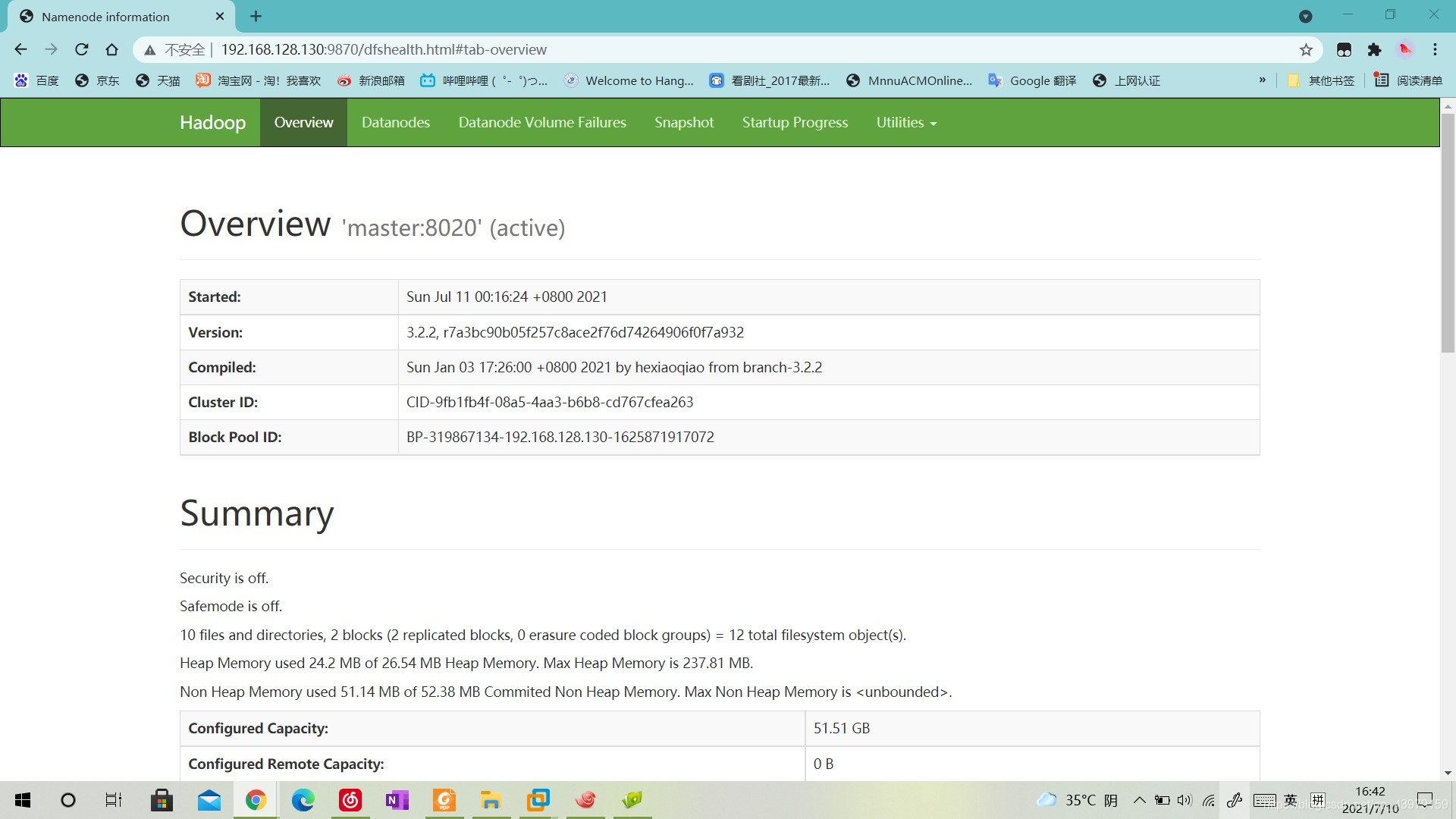
8.���Է���http://192.168.128.130:9870/(ip��master�ڵ��ip)
http://192.168.128.130:8088/cluster/(ip��master�ڵ��ip)�鿴