? 常见函数
-- 随机函数
select rand();
select rand(8); --在某范围内随机
-- round() 保留小数点位数
select round(rand()*100,2);
-- floor() 向下取整
select floor(rand()*100);
-- ceil() 向上取整
select ceil(rand()*100);
-- split() 切分
select split(rand()*100,'\\.')[0];
-- substr() 或者 substring() 截取
select substr(rand()*100,0,2);
select substring(rand()*100,0,2);
-- cast(value as 类型) 类型转换
select cast(rand()*100 as int);
-- concat(col1,col2,col3,....) 字符串拼接
select concat("1.0","2.0");
select concat(1,2,3,4,5,6);
-- concat_ws() 带分隔符拼接
select concat_ws('_',"1","2","3","4","5","6");
-- if(条件表达式,满足true执行,满足false执行)
select if(1==1,'true','false');
select if(1!=2,if(2==2,'女','妖'),'false');
-- case when end
--when后面写条件
select
case
when sex=1 then '男'
when sex=2 then '女'
else '妖' end
from t_stu
;
--case后面写字段
select
case sex
when 1 then '男'
when 2 then '女'
else '妖' end
from t_stu
;
-- length() 字符串长度
select length("abcde");
-- size() 数组和map的长度
select size(array(1,2,5,6));
select size(map(1,2,5,6));
-- lower() 转小写
select lower("Acc");
-- upper() 转大写
-- nvl(值1,值2) 判空,如果值1为空值2;如果不为空值1
select nvl(123,666);
select nvl(NULL,666);
-- ifnull() 或者 ifnotnull() 判空
select isnull(NULL);
窗口函数
窗口是将真个数据集(表)划分成多个小数据集进行统计分析。分为:物理窗口和逻辑窗口。
关键字:over(分组 排序 窗口) 中的order by后的语法:
1、物理窗口(真实往上下移动多少行rows between)
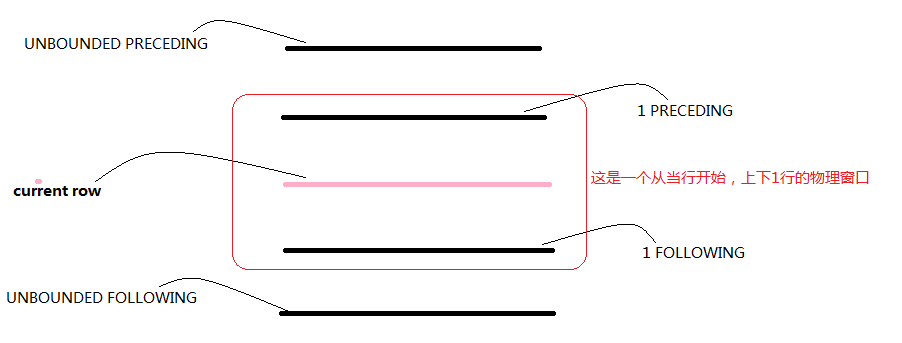
2、 逻辑窗口(满足条件上下多少行)
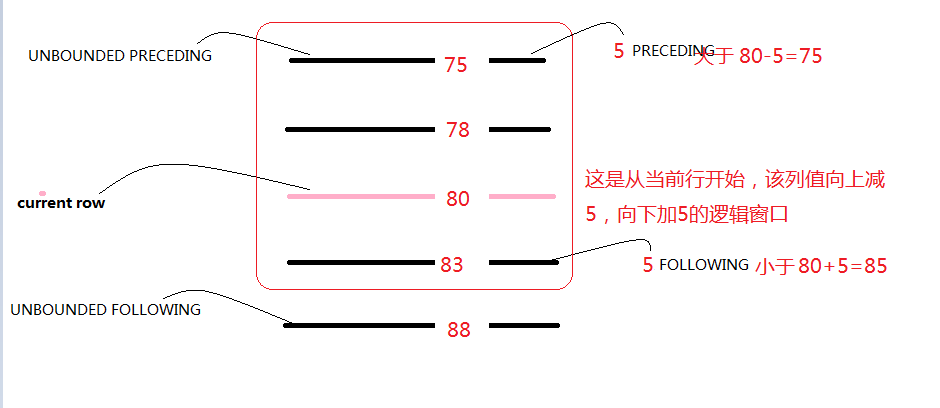
注意:窗口函数一般不和group by搭配使用
窗口函数和聚合函数的区别:
聚合函数是一个分组返回一个值;而窗口函数是每一行都要返回一个聚合值。
举例:
id price
1? 12
1 15
1 22
2 23
2 13
按照id分组sum:
1 12+15+22
2 36
窗口函数id分组截止当前行sum:
1 12
1 27
1 49
2 23
2 36
默认的数据库的查询都是要么详细记录,要么聚合分析,如果要查询详细记录和聚合数据,必须要经过两次查询
简单的说窗口函数对每条详细记录开一个窗口,进行聚合统计的查询
默认mysql老版本没有支持,在最新的8.0版本中支持, Oracle和Hive中都支持窗口函数
同时整合查询聚集前的结果和聚集后的结果
-- 数据准备order.txt
-- 格式为:
-- 姓名,购买日期,购买数量
-- 具体数据请看不做举例
-- 创建order表:
create table if not exists t_order
(
name string,
orderdate string,
cost int
) row format delimited fields terminated by ',';
-- 加载数据:
load data local inpath "/home/order.txt" into table t_order;
-- over 开窗语法
-- 使用窗口函数之前一般要通过over()进行开窗,简单可以写成==函数+over==简单的写法如下:
-- 一般搭配:
sum(col) over()
count() over()
-- 示例
-- 1.不使用窗口函数
-- 查询所有明细
select * from t_order;
# 查询总量
select name,orderdate,count(*) from t_order;
-- 2.使用窗口函数
select *, count(*) over() from t_order;
-- 注意:
-- 窗口函数是针对每一行数据的.
-- 如果over中没有参数,默认的是全部结果集
-- 需求:查询在2018年1月份购买过的顾客购买明细及总人数
select
*,
count(*) over ()
from t_order
where substring(orderdate,1,7) = '2018-01'
;
-- partition by子句
-- 在over窗口中进行分区,对某一列进行分区统计,窗口的大小就是分区的大小
-- 需求:查看顾客的购买明细及月购买总额
select
*,
sum(tor.cost) over(partition by month(tor.orderdate))
from t_order tor
;
-- order by
-- order by子句会让输入的数据强制排序 ;;建议sort by更好一些。
select
*,
sum(tor.cost) over(distribute by month(tor.orderdate) sort by tor.orderdate asc)
from t_order tor
;
-- Window子句
-- 如果要对窗口的结果做更细粒度的划分,那么就使用window字句,常见的有下面几个
-- PRECEDING:往前
-- FOLLOWING:往后
-- CURRENT ROW:当前行
-- UNBOUNDED:无限制;UNBOUNDED PRECEDING 无上限;UNBOUNDED following 无下限
-- 一般window子句都是==rows==开头
-- 案例:
select name,orderdate,cost,
sum(cost) over() as sample1,--所有行相加
sum(cost) over(partition by name) as sample2,--按name分组,组内数据相加
sum(cost) over(partition by name order by orderdate) as sample3,--按name分组,组内数据累加
sum(cost) over(partition by name order by orderdate rows between UNBOUNDED PRECEDING and current row ) as sample4 ,--和sample3一样,由起点到当前行的聚合
sum(cost) over(partition by name order by orderdate rows between 1 PRECEDING and current row) as sample5, --当前行和前面一行做聚合
sum(cost) over(partition by name order by orderdate rows between 1 PRECEDING AND 1 FOLLOWING ) as sample6,--当前行和前边一行及后面一行
sum(cost) over(partition by name order by orderdate rows between current row and UNBOUNDED FOLLOWING ) as sample7 --当前行及后面所有行
from t_order;