esѧϰ�ʼǼ�¼����,�����ڸ���
1. Elastic Stack����
ELK,�ֱ���Elasticsearch��Logstash��Kibana��� ,֮�������³�ԱBeats�ļ���,���Ծ��γ���Elastic Stack��
Elasticsearch
Elasticsearch ����java,�Ǹ���Դ�ֲ�ʽ��������,�����ص���:�ֲ�ʽ,������,�Զ�����,�����Զ���Ƭ,������������,restful���ӿ�,������Դ,�Զ��������صȡ�
Logstash
Logstash ����java,��һ����Դ�������ռ�,�����ʹ洢��־�Ĺ���
Kibana
Kibana ����nodejs,Ҳ��һ����Դ����ѵĹ���,Kibana����Ϊ Logstash �� ElasticSearch �ṩ����־�����Ѻõ�Web ����,���Ի��ܡ�������������Ҫ������־
Beats
Beats��elastic��˾��Դ��һ��ɼ�ϵͳ������ݵĴ���agent,���ڱ���ط��������Կͻ�����ʽ���е������ռ�����ͳ��,����ֱ�Ӱ����ݷ���Elasticsearch����ͨ��Logstash����Elasticsearch,Ȼ����к��������ݷ���� ��
Beats���������:
- Packetbeat:��һ���������ݰ�������,���ڼ�ء��ռ�����������Ϣ,Packetbeat��̽������֮�������,����Ӧ�ò�Э��,����������Ϣ�Ĵ���,��֧ ��ICMP (v4 and v6)��DNS��HTTP��Mysql��PostgreSQL��Redis��MongoDB��Memcache��Э��;
- Filebeat:���ڼ�ء��ռ���������־�ļ�,����ȡ�� logstash
- Metricbeat:�ɶ��ڻ�ȡ�ⲿϵͳ�ļ��ָ����Ϣ,����Լ�ء��ռ� Apache��HAProxy��MongoDB��MySQL��Nginx��PostgreSQL��Redis��System��Zookeeper�ȷ���
- Winlogbeat:���ڼ�ء��ռ�Windowsϵͳ����־��Ϣ
2. Elasticsearch
2.1 ����
Elastic Stack�ĺ���,ȫ���������档����:https://www.elastic.co/cn/products/elasticsearch
2.2 ��װ
2.2.1 �汾˵��
Ŀǰ�����汾:7.2.0
2.2.2 �����氲װ
#����elsearch�û��Լ���Ŀ¼,Elasticsearch��֧��root�û�����
useradd -d /home/es -m elasticsearch
# �������� 12345678����
passwd elasticsearch
#����
cd /home/es
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.2.0-linux-x86_64.tar.gz
#��ѹ��װ��
tar -zxvf elasticsearch-7.2.0-linux-x86_64.tar.gz
#�������ļ�
vim config/elasticsearch.yml
network.host: 0.0.0.0 #����ip��ַ,����������ɷ���
#��jvm��������
vim conf/jvm.options
-Xms128m #�����Լ����������
-Xmx128m
# ===== root�û��µIJ��� ======
# ���ļ������� �趨ͬһʱ����ļ��������ֵΪ65535
vim /etc/profile
ulimit -n 65535
# ��Ч
source /etc/profile
# ��limits.conf
vim /etc/security/limits.conf
* soft nofile 65536
* hard nofile 65536
# ��֤
ulimit -a
# �� ���ӳ������ MMP
vim /etc/sysctl.conf
vm.max_map_count=262144
# ��Ч
sysctl -p
# ====��������====
su - elasticsearch
cd /home/es/elasticsearch-7.2.0-linux-x86_64/bin
./elasticsearch �� ./elasticsearch -d #��̨����
elasticsearch.yml�ɲο�
cluster.name: cms
network.host: 0.0.0.0
# custom config
node.name: "node-1"
discovery.seed_hosts: ["127.0.0.1", "[::1]"]
cluster.initial_master_nodes: ["node-1"]
# �����������֧��,Ĭ��Ϊfalse
http.cors.enabled: true
# �������������������ַ,(������������)����ʹ������
http.cors.allow-origin: /.*/
2.2.3 elasticsearch-head
ES�ٷ���û��ΪES�ṩ�����������,�������ṩ�˺�̨�ķ���elasticsearch-head��һ��ΪES������һ��ҳ
��ͻ��˹���,��Դ���й���GitHub,��ַΪ:https://github.com/mobz/elasticsearch-head
����ͨ��docker��Chrome�����װ
docker��װ
#��ȡ����
docker pull mobz/elasticsearch-head:5
#��������
docker create --name elasticsearch-head -p 9100:9100 mobz/elasticsearch-head:5
#��������
docker start elasticsearch-head
docker��װ���ܳ��ֵ�����:
����: ʹ�� Elasticsearch Head �鿴�����������ʱ,�Ҳ������,ʹ�������F12�鿴��,���� 406 Not Acceptable ����
���:
-
���� es-head ��װĿ¼;
-
cd _site/
-
�༭ vendor.js ��������:
�� 6886�� contentType: ��application/x-www-form-urlencoded�� ��Ϊ contentType: ��application/json;charset=UTF-8��
�� 7574�� var inspectData = s.contentType === ��application/x-www-form-urlencoded�� && ��Ϊ var inspectData = s.contentType === ��application/json;charset=UTF-8�� &&
-
ˢ���������֤
2.3 ��������
����
- ����(index)��Elasticsearch�������ݵ����洢,���������Է�Ϊ��С�IJ���
- �����������ɹ�ϵ�����ݿ�ı�,�����Ľṹ��Ϊ������Ч��ȫ����������,�ر��������洢ԭʼֵ
- Elasticsearch�������������һ̨�������߷�ɢ�ڶ�̨��������,ÿ��������һ������Ƭ(shard),ÿ����Ƭ�����ж������(replica)
�ĵ�
-
�洢��Elasticsearch�е���Ҫʵ����ĵ�(document)���ù�ϵ�����ݿ�����ȵĻ�,һ���ĵ��൱�����ݿ���е�һ�м�¼
-
Elasticsearch��MongoDB�е��ĵ�����,�������в�ͬ�Ľṹ,��Elasticsearch���ĵ���,��ͬ�ֶα�������ͬ����
-
�ĵ��ɶ���ֶ����,ÿ���ֶο��ܶ�γ�����һ���ĵ���,�������ֶνж�ֵ�ֶ�(multivalued)
-
ÿ���ֶε�����,�������ı�����ֵ�����ڵȡ��ֶ�����Ҳ�����Ǹ�������,һ���ֶΰ����������ĵ���������
ӳ��
- �����ĵ�д������֮ǰ�����Ƚ��з���,��ν�������ı��ָ�Ϊ��������Щ�����ֻᱻ����,������Ϊ����ӳ��(mapping)��һ�����û��Լ��������
�ĵ�����
- ��Elasticsearch��,һ������������Դ洢�ܶͬ��;�Ķ�������,һ������Ӧ�ó�����Ա������º�����
- ÿ���ĵ������в�ͬ�Ľṹ
- ��ͬ���ĵ����Ͳ���Ϊ��ͬ���������ò�ͬ�����͡�����,��ͬһ�����е������ĵ�������,һ����title���ֶα��������ͬ������
2.4 RESTful API
��Elasticsearch��,�ṩ�˹��ܷḻ��RESTful API�IJ���,����������CRUD������������ɾ�������Ȳ���
7.x�Ժ�ĸ���:
- ��������:
PUT {index}/{type}/{id}��Ҫ�ij�PUT {index}/_doc/{id} - Mapping ����:
PUT {index}/{type}/_mapping����PUT {index}/_mapping - ������ɾ�IJ������������ؽ������Ĺؼ���
_type�������Ƴ�
2.4.1 �����ǽṹ������
��Lucene��,������������Ҫ�����ֶ������Լ��ֶε����͵�,��Elasticsearch���ṩ�˷ǽṹ��������,���Dz�
��Ҫ���������ṹ,����д�����ݵ�������,ʵ������Elasticsearch�ײ����нṹ������,�˲������û�����
���������� :
PUT /haoke
{
"settings": {
"index": {
"number_of_shards": "2", #��Ƭ��
"number_of_replicas": "0" #������
}
}
}
#ɾ������
DELETE /haoke
{
"acknowledged": true
}
2.4.2 ��������
url����:POST /{����}/{����}/{id} 7.x�Ժ�Ϊ/{����}/_doc/{id}
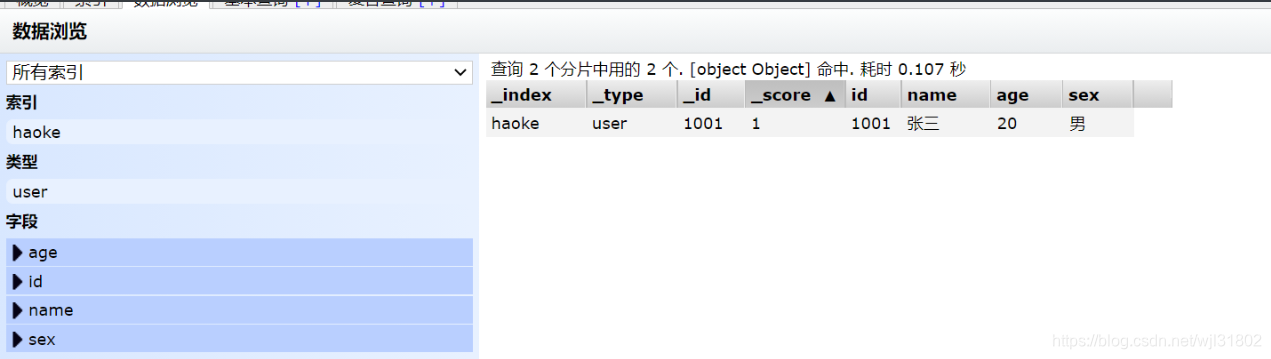
POST /haoke/user/1001
#����
{
"id":1001,
"name":"����",
"age":20,
"sex":"��"
}
#��Ӧ
{
"_index": "haoke",
"_type": "user",
"_id": "1",
"_version": 1,
"result": "created",
"_shards": {
"total": 1,
"successful": 1,
"failed": 0
},
"_seq_no": 0,
"_primary_term": 1
}
˵��:�ǽṹ��������,����Ҫ���ȴ���,ֱ�Ӳ�������Ĭ�ϴ�������
��ָ��id��������:
POST /haoke/user/
{
"id":1002,
"name":"����",
"age":20,
"sex":"��"
}
2.4.3 ��������
��Elasticsearch��,�ĵ������Dz������ĵ�,���ǿ���ͨ�����ǵķ�ʽ���и���
PUT /haoke/user/1001
{
"id":1001,
"name":"����",
"age":21,
"sex":"Ů"
}
���º�,�汾_version�ֶλ��1
�ֲ�����:
#ע��:�������_update��ʶ
POST /haoke/user/1001/_update
{
"doc":{
"age":23
}
}
2.4.4 ɾ������
����DELETE����
DELETE /haoke/user/1001
ɾ��һ���ĵ�Ҳ���������Ӵ������Ƴ�,��ֻ�DZ���dz���ɾ����Elasticsearch��������֮�����Ӹ���������ʱ��Ż��ں�̨����ɾ�����ݵ�����
2.4.5 ��������
����id��������
GET /haoke/user/BbPe_WcB9cFOnF3uebvr
����ȫ������
GET /haoke/user/_search
Ĭ�Ϸ���10������
7.x�Ժ�
GET /haoke/_search
�ؼ�����������
#��ѯ�������20���û�
GET /haoke/user/_search?q=age:20
2.4.6 DSL����
DSL��ѯ(Query DSL),�������㹹�����Ӹ��ӡ�ǿ��IJ�ѯ
DSL(Domain Specific Language�ض���������)��JSON���������ʽ����
POST /haoke/user/_search
#������
{
"query" : {
"match" : { #matchֻ�Dz�ѯ��һ��
"age" : 20
}
}
}
ʵ��:��ѯ�������30��������û�
POST /haoke/user/_search
#��������
{
"query": {
"bool": {
"filter": {
"range": {
"age": {
"gt": 30
}
}
},
"must": {
"match": {
"sex": "��"
}
}
}
}
}
ȫ�ļ���
POST /haoke/user/_search
#��������
{
"query": {
"match": {
"name": "���� ����"
}
}
}
2.4.7 ������ʾ
POST /haoke/user/_search
{
"query": {
"match": {
"name": "���� ����"
}
},
"highlight": {
"fields": {
"name": {}
}
}
}
2.4.8 �ۺ�
����SQL�е�group by����
POST /haoke/user/_search
{
"aggs": {
"all_interests": {
"terms": {
"field": "age"
}
}
}
}
����30����2������,20����һ��,40��һ��
3 �������
3.1 �ĵ�
�ĵ���JSON��ʽ���д洢,�����Ǹ��ӵĽṹ
{
"_index": "haoke",
"_type": "user",
"_id": "1005",
"_version": 1,
"_score": 1,
"_source": {
"id": 1005,
"name": "����",
"age": 37,
"sex": "Ů",
"card": {
"card_number": "123456789"
}
}
}
����,card��һ�����Ӷ���,Ƕ��Card����
Ԫ���� metadata
�ĵ���ֻ������,������Ԫ����metadata�C�����ĵ�����Ϣ��
���������Ԫ���ݽڵ�:
_index�ĵ��洢�ĵط�_type�ĵ������Ķ������,7.x�Ժ�typeֻ��_doc_id�ĵ���Ψһ��ʶ
_index
����(index)�����ڹ�ϵ�����ݿ���ġ����ݿ⡱�����������Ǵ洢�������������ݵĵط�
�����ռ���,���ݱ��洢�������ڷ�Ƭshards��,�����ǰ�һ��������Ƭ������һ������ռ䡣��Ȼ,javaӦ�ò��ÿ��Ƿ�Ƭ,��Ϊ�洢�������С�
_type
ʹ����ͬ����(type)���ĵ���ʾ��ͬ�ġ����,��Ϊ���ǵ����ݽṹҲ����ͬ��,������java����class
ÿ������(type)�����Լ���ӳ��(mapping)���߽ṹ����,����ͳ���ݿ���е���һ�������������µ��ĵ����洢��ͬһ��������,�������͵�ӳ��(mapping)�����Elasticsearch��ͬ���ĵ���α�����
_id
id��_index���,��es��Ψһ��ʶһ���ĵ�,���Լ�����id,Ҳ��es�Զ�����32λid��
3.2 ��ѯ��Ӧ
3.2.1 pretty
�����ڲ�ѯurl��������pretty����,����json��ʽ
xxx/user/1005?pretty
3.2.2 ָ����Ӧ�ֶ�
��Ӧ��������,�������Ҫȫ�����ֶ�,����ָ��ijЩ��Ҫ���ֶν��з���
GET /haoke/user/1005?_source=id,name
#��Ӧ
{
"_index": "haoke",
"_type": "user",
"_id": "1005",
"_version": 1,
"found": true,
"_source": {
"name": "����",
"id": 1005
}
}
�������Ҫ����Ԫ����
GET /haoke/user/1005/_source
��
GET /haoke/user/1005/_source?_source=id,name
3.3 �ж��ĵ��Ƿ����
ֻ��Ҫ�ж��ĵ��Ƿ����,�����Dz�ѯ�ĵ�����,��ô��������
HEAD /haoke/user/1005
ֻ����status��200����404,��ʾ��ѯ����һ���ĵ�������
3.4 ��������
3.4.1 ������ѯ
POST /haoke/user/_mget
{
"ids" : [ "1001", "1003" ]
}
���,ijһ�����ݲ�����,��Ӱ��������Ӧ,��Ҫͨ��found��ֵ�����ж��Ƿ��ѯ������
3.4.2 _bulk����
֧�������IJ��롢�ġ�ɾ������,����ͨ��_bulk��api��ɵ�
��ʽ:
{ action: { metadata }}\n
{ request body }\n
{ action: { metadata }}\n
{ request body }\n
...
��������
{"create":{"_index":"haoke","_type":"user","_id":2001}}
{"id":2001,"name":"name1","age": 20,"sex": "��"}
{"create":{"_index":"haoke","_type":"user","_id":2002}}
{"id":2002,"name":"name2","age": 20,"sex": "��"}
{"create":{"_index":"haoke","_type":"user","_id":2003}}
{"id":2003,"name":"name3","age": 20,"sex": "��"}
���һ����Ҫ�и��س�
����ɾ��
{"delete":{"_index":"haoke","_type":"user","_id":2001}}
{"delete":{"_index":"haoke","_type":"user","_id":2002}}
{"delete":{"_index":"haoke","_type":"user","_id":2003}}
һ��������ٸ��������?
��ѵ�sweetspot��Ҫ����,��ʼ����������1000-5000���ĵ�֮��,һ���õ����������5-15MB��С��
3.5 ��ҳ
��SQLʹ�� LIMIT �ؼ��ַ���ֻ��һҳ�Ľ��һ��,Elasticsearch����from�� size ����
size: �����,Ĭ��10
from: ������ʼ�Ľ����,Ĭ��0
�������ÿҳ��ʾ5�����,ҳ���1��3:
GET /_search?size=5
GET /_search?size=5&from=5
GET /_search?size=5&from=10
��Ҫ���ķ�ҳ̫���һ�������������,��Ϊ�������֮ǰ������
3.6 ӳ��
��Щʱ����������Ҫ������ȷ�ֶ����͵�,����,�Զ��жϵ����ͺ�ʵ�������Dz������
��ElasticSearch 5.x��ʼ����֧��string,��text��keyword�������
- text����,�ֶ�Ҫ��ȫ������,��email���ݡ���Ʒ�������ֶλᱻ�ִʡ�text���Ͳ���������,�������ھۺ�
- keyword����,�����������ṹ�����ֶ�,��email��ַ����������״̬��ͱ�ǩ�����ֶ���Ҫ����(���ѯstatusΪtrue��)�����ۺϡ�keywordֻ��ͨ����ȷֵ��ѯ����
PUT /school
{
"settings": {
"index": {
"number_of_shards": "2",
"number_of_replicas": "0"
}
},
"mappings": {
"person": { # 7.x�Ժ���Ҫ��person���typeɾ��
"properties": {
"name": {
"type": "text"
},
"age": {
"type": "integer"
},
"mail": {
"type": "keyword"
},
"hobby": {
"type": "text"
}
}
}
}
}
�鿴ӳ��
GET /school/_mapping
3.7 �ṹ����ѯ
3.7.1 term��ѯ
term ��Ҫ���ھ�ȷƥ����Щֵ,��������,����,����ֵ�� not_analyzed ���ַ���(δ���������ı���������)
POST /school/person/_search
{
"query" : {
"term" : {
"age" : 20
}
}
}
3.7.2 terms��ѯ
terms �� term �е�����,�� terms ����ָ�����ƥ�������� ���ij���ֶ�ָ���˶��ֵ,��ô�ĵ���Ҫһ��ȥ��ƥ��
{
"terms": {
"tag": [ "search", "full_text", "nosql" ]
}
}
eg.
POST /itcast/person/_search
{
"query" : {
"terms" : {
"age" : [20,21]
}
}
}
3.7.3 range��ѯ
����ָ����Χ����һ������:
{
"range": {
"age": {
"gte": 20,
"lt": 30
}
}
}
3.7.4 exists��ѯ
�����ĵ����Ƿ����ָ���ֶλ�û��ij���ֶ�
POST /haoke/user/_search
{
"query": {
"exists": { #�������
"field": "card"
}
}
}
3.7.5 match��ѯ
����������ѯ֮ǰ�÷������ȷ��� match һ�²�ѯ�ַ�
{
"match": {
"tweet": "Leehom"
}
}
3.7.6 bool��ѯ
�ϲ����������ѯ���,����������
must�����ѯ��������ȫƥ�� ����&must not�����ѯ�������෴ƥ��,����!should������һ�� ����or
{
"bool": {
"must": { "term": { "folder": "inbox" }},
"must_not": { "term": { "tag": "spam" }},
"should": [
{ "term": { "starred": true }},
{ "term": { "unread": true }}
]
}
}
3.8 ���˲�ѯ
��,��ѯ����20���û�
POST /itcast/person/_search
{
"query": {
"bool": {
"filter": {
"term": {
"age": 20
}
}
}
}
}
��ѯ���˵ĶԱ�
- ��������ѯ��ÿ���ĵ����ֶ�ֵ�Ƿ�������ض�ֵ
- ��ѯ����ѯ��ÿ���ĵ����ֶ�ֵ���ض�ֵ��ƥ��̶����,����һ�����������
_score,���� ��������Զ�ƥ
�䵽���ĵ��������� - ����ȷƥ������ʱ,����ù������,��Ϊ���������Ի�������
4 ���ķִ�
4.1 �ִ�
�ִʾ���ָ��һ���ı�ת����һϵ�е��ʵĹ���,Ҳ���ı�����,��Elasticsearch�г�֮ΪAnalysis,�������й��� --> ��/��/�й���
4.2 �ִ�API
ָ���ִ������зִ�
POST /_analyze
{
"analyzer":"standard",
"text":"hello world"
}
ָ�������ִ�
POST /itcast/_analyze
{
"analyzer": "standard",
"field": "hobby",
"text": "������"
}
4.3 ���ķִ�
�Ƽ�IK�ִ���,�㷨�����������ϸ�����з��㷨��
IK�ִ��� Elasticsearch�����ַ:https://github.com/medcl/elasticsearch-analysis-ik
cd plugins;
wget https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.2.0/elasticsearch-analysis-ik-7.2.0.zip;
mkdir ik;cd ik;
unzip ../elasticsearch-analysis-ik-6.5.4.zip
# ����
./bin/elasticsearch
����
POST /_analyze
{
"analyzer": "ik_max_word",
"text": "�������"
}
5 ȫ������
ȫ��������������Ҫ�ķ�����:
- �����(Relevance) �������۲�ѯ�����������س̶�,������������س̶ȶԽ��������һ������,��
�ּ��㷽ʽ������ TF/IDF ����������λ���ڽ���ģ������,��������ijЩ�㷨�� - �ִ�(Analysis) ���ǽ��ı���ת��Ϊ������ġ��淶���� token ��һ������,Ŀ����Ϊ�˴������������Լ�
��ѯ��������
5.1 ��������
POST /itcast/person/_search
{
"query":{
"match":{
"hobby":"����"
}
},
"highlight": {
"fields": {
"hobby": {}
}
}
}
�ڲ�ִ�й���:
- ����ֶ����� hobby �ֶ���һ�� text ����( ָ����IK�ִ���),����ζ�Ų�ѯ�ַ�������ҲӦ�ñ��ִ�
- ������ѯ�ַ��� ����ѯ���ַ��� �����֡� ����IK�ִ�����,����Ľ���ǵ����� ���֡���Ϊֻ��һ��������,���� match ��ѯִ�е��ǵ����ײ� term ��ѯ
- ����ƥ���ĵ� �� term ��ѯ�ڵ��������в��� �����֡� Ȼ���ȡһ�����������ĵ�
- Ϊÿ���ĵ����� �� term ��ѯ����ÿ���ĵ���ض����� _score ,�����ֽ� ��Ƶ(term frequency,���� �����֡� ������ĵ���hobby �ֶ��г��ֵ�Ƶ��)�� �����ĵ�Ƶ��(inverse document frequency,���� �����֡� �������ĵ���hobby �ֶ��г��ֵ�Ƶ��),�Լ��ֶεij���(���ֶ�Խ����ض�Խ��)���ϵļ��㷽ʽ
5.2 �������
��match��hobby��Ϊ "hobby":"���� ����"
������������ǼȰ��������֡��ְ����������û�,��ָ����֮�������ϵ
"match":{
"hobby":{
"query":"���� ����",
"operator":"and"
}
}
���Ҫ����һ�������ƶȾͿ��Բ�ѯ������,��Elasticsearch��Ҳ֧�������IJ�ѯ,ͨ��minimum_should_match��ָ��ƥ���,��:70%
"match":{
"hobby":{
"query":"��Ӿ ��ë��",
"minimum_should_match":"80%"
}
}
�������ƶ���Ҫ���ҵ���������ԡ�
5.4 �������
������ʱ,Ҳ����ʹ�ù������н�����bool��ϲ�ѯ,ʾ��
"query":{
"bool":{
"must":{
"match":{
"hobby":"����"
}
},
"must_not":{
"match":{
"hobby":"����"
}
},
"should":[
{
"match": {
"hobby":"��Ӿ"
}
}
]
}
}
must_not ��Ӱ������,����ֻ�ǽ�����ص��ĵ��ų���
5.5 Ȩ��
��Щʱ��,���ǿ�����Ҫ��ijЩ������Ȩ����Ӱ��������ݵĵ÷�
eg. �����ؼ���Ϊ����Ӿ����,�������а����ˡ����֡�Ȩ��Ϊ10,�����ˡ��ܲ���Ȩ��Ϊ2
"query": {
"bool": {
"must": {
"match": {
"hobby": {
"query": "��Ӿ����",
"operator": "and"
}
}
},
"should": [
{
"match": {
"hobby": {
"query": "����",
"boost": 10
}
}
},
{
"match": {
"hobby": {
"query": "�ܲ�",
"boost": 2
}
}
}
]
}
}
6 es��Ⱥ
6.1 ��Ⱥ�ڵ�
ELasticsearch�ļ�Ⱥ���ɶ���ڵ���ɵ�,ͨ��cluster.name���ü�Ⱥ����,�����������������ļ�Ⱥ,ÿ���ڵ�ͨ��node.nameָ���ڵ������
�ڵ�����:
master�ڵ�
- �����ļ���node.master����Ϊtrue(Ĭ��Ϊtrue),�����ʸ�ѡΪmaster�ڵ�
- master�ڵ����ڿ���������Ⱥ�IJ��������紴����ɾ������,����������master�ڵ��
data�ڵ�
- �����ļ���node.data����Ϊtrue(Ĭ��Ϊtrue),�����ʸ����ó�data�ڵ�
- data�ڵ���Ҫ����ִ��������صIJ����������ĵ���CRUD
�ͻ��˽ڵ�
- �����ļ���node.master���Ժ�node.data���Ծ�Ϊfalse
- ������Ϊ�ͻ��˽ڵ�,������Ӧ�û�������,������ת���������ڵ�
����ڵ�
- ��һ���ڵ�����tribe.*��ʱ��,����һ������Ŀͻ���,���������Ӷ����Ⱥ,���������ӵļ�Ⱥ��ִ����������������
6.2 ���Ⱥ
# 3�������,�ֱ���װes
mkdir /home/es-cluster
cp -R /home/es /home/es-cluster
elasticsearch.yml����������������ļ�,node02����Ϊmaster�ڵ�,node03����Ϊ��ͨ���ݽڵ㡣
�����elasticsearch.yml�ļ�
cluster.name: es-itcast-cluster
node.name: node01
node.master: true
node.data: true
network.host: 192.168.200.207
http.port: 9200
discovery.zen.ping.unicast.hosts: ["192.168.200.207","192.168.200.208","192.168.200.209"]
discovery.zen.minimum_master_nodes: 2
http.cors.enabled: true
http.cors.allow-origin: "*"
cluster.initial_master_nodes: ["192.168.200.207","192.168.200.208"]
�鿴��Ⱥ״̬:_cluster/health
����״̬Ϊgreen��ʾ������
6.3 ��Ƭ����
- һ����Ƭ(shard)��һ����С���𡰹�����Ԫ(worker unit)��,��ֻ�DZ������������������ݵ�һ����
- ��Ƭ����һ��Luceneʵ��,��������������һ���������������档Ӧ�ó������ֱ��ͨ��
- ��Ƭ����������Ƭ(primary shard)�����Ǹ��Ʒ�Ƭ(replica shard)
- �����е�ÿ���ĵ�����һ������������Ƭ,��������Ƭ��������������������ܴ洢��������
- ���Ʒ�Ƭֻ������Ƭ��һ������,�����Է�ֹӲ�����ϵ��µ����ݶ�ʧ,ͬʱ�����ṩ������
- ������������ɵ�ʱ��,����Ƭ�������̶���,���Ǹ��Ʒ�Ƭ������������ʱ����
6.4 ����ת��
ͣ��node01,elasticsearch-header��cluster״̬���,��һ����Զ����̡�
��node01������,�ָ�������¼���cluster,���·���ڵ���Ϣ��
˵��:����������ļ���discovery.zen.minimum_master_nodes���õIJ���N/2+1ʱ,�������������,��˽���3��������,����2��master;5��������,����3��master
6.5 �ֲ�ʽ�ĵ�
6.5.1 ·��
��������һ����Ⱥ�����ĵ�ʱ,�ĵ��ô洢���ĸ��ڵ���? �������? ����ѯ��?
ʵ���и����㹫ʽ,�����洢�ڵ�:
shard = hash(routing) % number_of_primary_shards
routingֵĬ����_id ,hash��,��������Ƭ���õ�����,�����ķ�Χ��0������Ƭ��֮��,��ֵ���Ǹ��ĵ����ڵķ�Ƭ��
6.5.2 �ĵ���д����
�½���������ɾ��������д(write)����,���DZ���������Ƭ�ϳɹ���ɲ��ܸ��Ƶ���صĸ�����Ƭ��
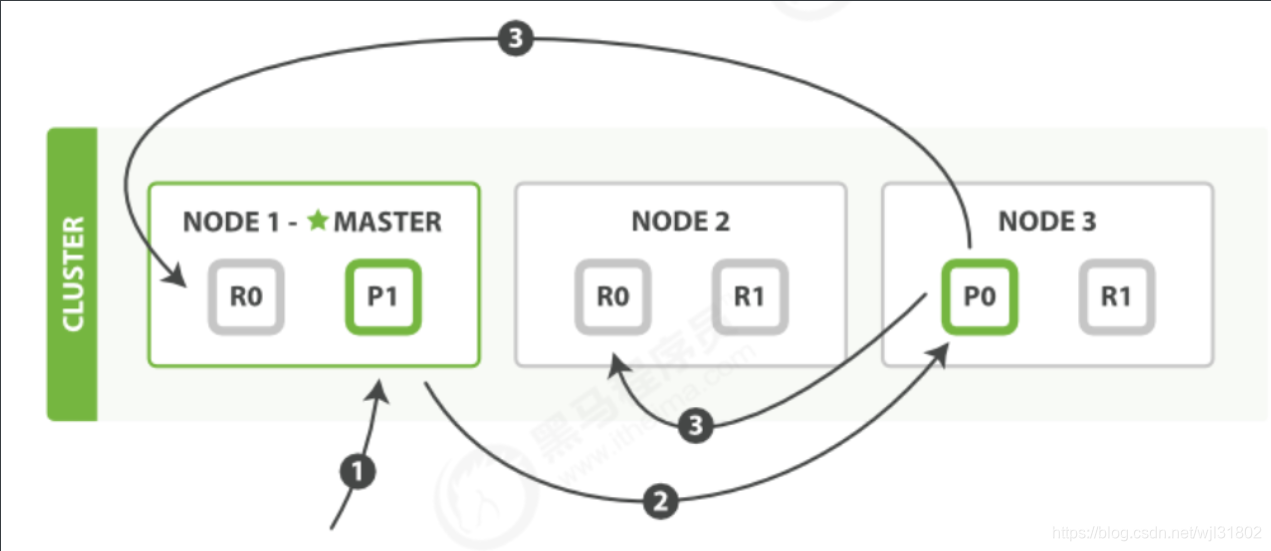
����:
- client��node01���½���������ɾ��������
- �����ĵ���
_id�����ĵ����ڷ�Ƭ0,ת������node03,��Ƭ0������Ƭλ�ڸýڵ� - node03������Ƭ��ִ������,����ɹ�,ת������node01��node02�ĸ�����Ƭ�ϡ�node03�յ��ɹ��ķ��غ�,�ٸ�client��������
6.5.3 �����ĵ�(�����ĵ�)
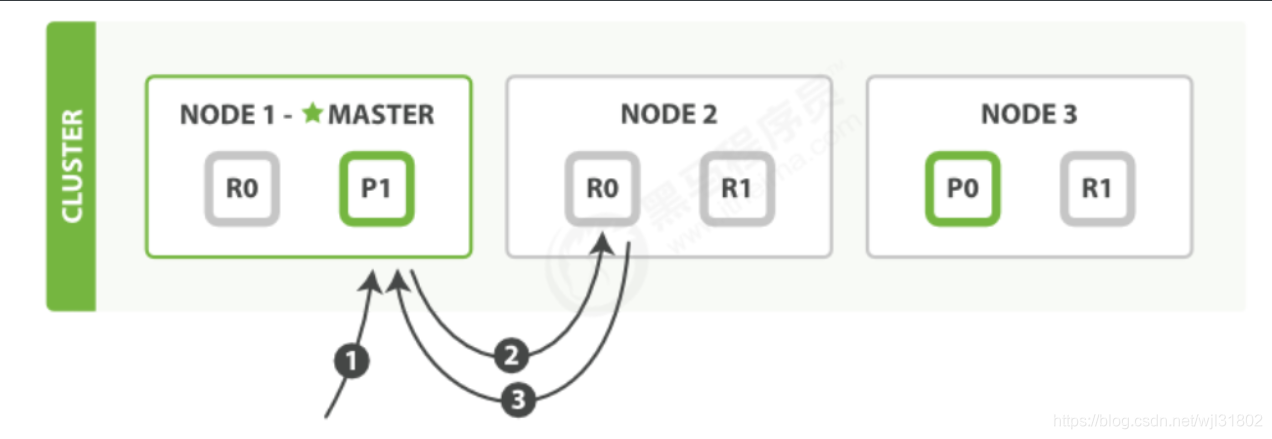
����:
- client��node01��get����
- �����ĵ���
_idȷ���ĵ����ڷ�Ƭ0,��Ӧ�ĸ�����Ƭ��node01��node02����,ת������node02. - node02�����ĵ���node01,���ظ�client
���ڶ�����,Ϊƽ�⸺��,��Ϊÿ������ѡ��ͬ�ķ�Ƭ��
����һ�����������ĵ�����������Ƭ,��û���ü�ͬ����������Ƭ,������Ƭ�ᱨ��δ�ҵ�,����Ƭ�ɹ������ĵ�����������ɹ����ظ�client��,�ĵ���primary��replica��Ƭ�����á�
6.5.4 ȫ������
�ĵ���ɢ�ڸ����ڵ�,�ֲ�ʽ�����,�������?��������:����query+ȡ��fetch
����query
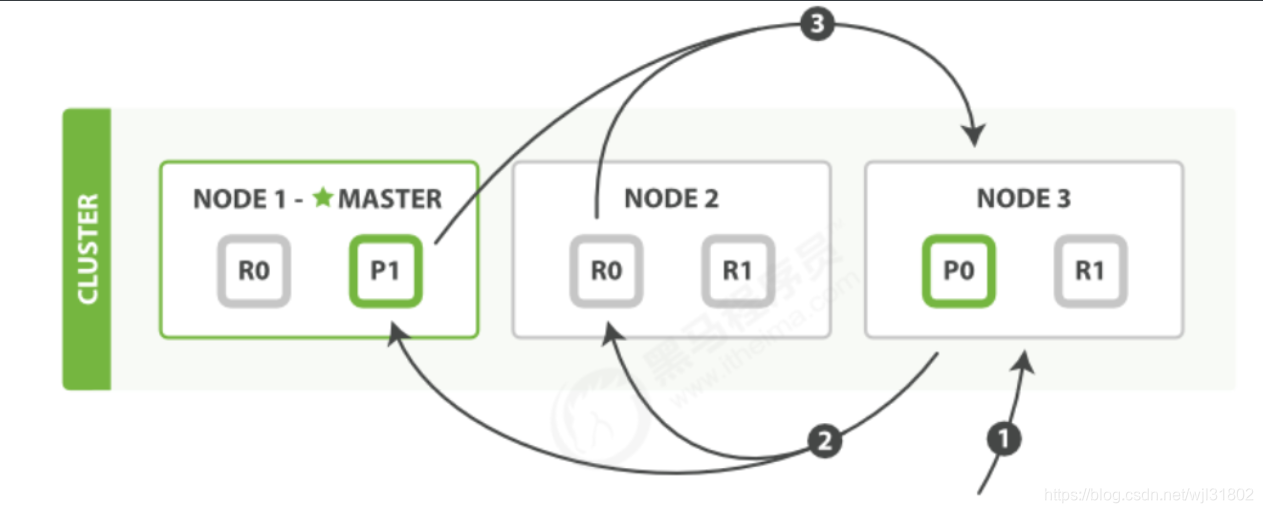
��ѯ�η�����:
- client����search�����node03,node03��������Ϊ
from+size�Ŀ����ȶ��� - node03ת����������������ÿ����Ƭ��primary��replica,ÿ����Ƭ����ִ�в�ѯ����������СΪ
from+size�ı������ȶ��� - ÿ����Ƭ����document��id�����ȶ��е�����document������ֵ��Э���ڵ�node03,node03ȡ�غ�ϲ����Լ������ȶ��в���ȫ��������
ȡ��fetch
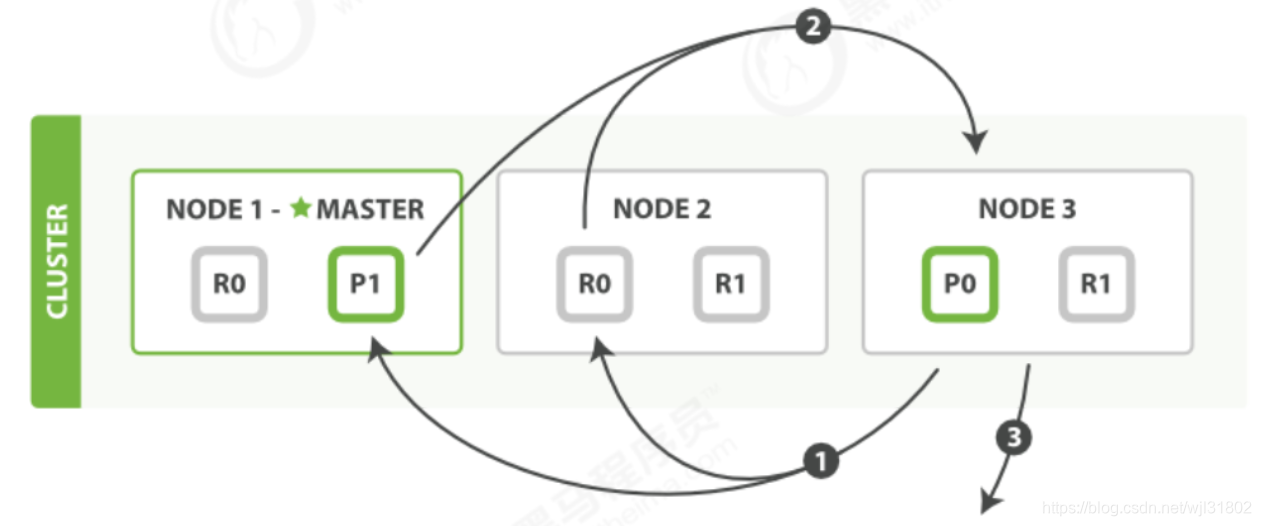
�ַ��εIJ���:
- Э���ڵ�ֱ���ЩdocumentҪȡ��,����ط�Ƭ��get����
- ÿ����Ƭ����document��������Ҫ�ḻenrich����,�ٽ�document����Э���ڵ�node03
- ����document����ȡ�غ�,Э���ڵ�node03���������client
7. java�ͻ���
����DSL��ѯ,���ø߽ͻ���,������д�������
�ο�
- ��ѧ��elasticsearch�γ�
- Elasticsearch �Ƴ� type ֮���������
- es������������������