在进行saprk renwu 调度时候出现这个问题
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/jars/hive-jdbc-2.1.1-cdh6.3.2-standalone.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/jars/avro-tools-1.8.2-cdh6.3.2.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/jars/log4j-slf4j-impl-2.8.2.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/jars/slf4j-simple-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/jars/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/jars/parquet-tools-1.9.0-cdh6.3.2.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
ANTLR Tool version 4.7 used for code generation does not match the current runtime version 4.5.1ANTLR Runtime version 4.7 used for parser compilation does not match the current runtime version 4.5.1
Log Type: stdout
Log Upload Time: 星期六 七月 10 17:37:04 +0800 2021
Log Length: 2576
17:36:26.715 [ERROR - Driver] (Logging.scala:94) User class threw exception: java.lang.ExceptionInInitializerError
java.lang.ExceptionInInitializerError: null
at org.apache.spark.sql.catalyst.parser.AbstractSqlParser.parse(ParseDriver.scala:84) ~[spark-catalyst_2.11-2.4.0-cdh6.3.2.jar:2.4.0-cdh6.3.2]
at org.apache.spark.sql.execution.SparkSqlParser.parse(SparkSqlParser.scala:48) ~[spark-sql_2.11-2.4.0-cdh6.3.2.jar:2.4.0-cdh6.3.2]
at org.apache.spark.sql.catalyst.parser.AbstractSqlParser.parseTableIdentifier(ParseDriver.scala:49) ~[spark-catalyst_2.11-2.4.0-cdh6.3.2.jar:2.4.0-cdh6.3.2]
at org.apache.spark.sql.SparkSession.table(SparkSession.scala:633) ~[spark-sql_2.11-2.4.0-cdh6.3.2.jar:2.4.0-cdh6.3.2]
at com.kuaidi100.util.common.DetermineUtils$.determineStringToList(DetermineUtils.scala:169) ~[__app__.jar:?]
at com.kuaidi100.executionEnv$.prodEnv(executionEnv.scala:40) ~[__app__.jar:?]
at com.kuaidi100.StartSpiderPoi$.main(StartSpiderPoi.scala:28) ~[__app__.jar:?]
at com.kuaidi100.StartSpiderPoi.main(StartSpiderPoi.scala) ~[__app__.jar:?]
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) ~[?:1.8.0_181]
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) ~[?:1.8.0_181]
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) ~[?:1.8.0_181]
at java.lang.reflect.Method.invoke(Method.java:498) ~[?:1.8.0_181]
at org.apache.spark.deploy.yarn.ApplicationMaster$$anon$2.run(ApplicationMaster.scala:673) [spark-yarn_2.11-2.4.0-cdh6.3.2.jar:2.4.0-cdh6.3.2]
Caused by: java.lang.UnsupportedOperationException: java.io.InvalidClassException: org.antlr.v4.runtime.atn.ATN; Could not deserialize ATN with UUID 59627784-3be5-417a-b9eb-8131a7286089 (expected aadb8d7e-aeef-4415-ad2b-8204d6cf042e or a legacy UUID).
at org.antlr.v4.runtime.atn.ATNDeserializer.deserialize(ATNDeserializer.java:153) ~[antlr4-runtime-4.5.1-1.jar:4.5.1-1]
at org.apache.spark.sql.catalyst.parser.SqlBaseLexer.<clinit>(SqlBaseLexer.java:1175) ~[spark-catalyst_2.11-2.4.0-cdh6.3.2.jar:2.4.0-cdh6.3.2]
... 13 more
Caused by: java.io.InvalidClassException: org.antlr.v4.runtime.atn.ATN; Could not deserialize ATN with UUID 59627784-3be5-417a-b9eb-8131a7286089 (expected aadb8d7e-aeef-4415-ad2b-8204d6cf042e or a legacy UUID).
at org.antlr.v4.runtime.atn.ATNDeserializer.deserialize(ATNDeserializer.java:153) ~[antlr4-runtime-4.5.1-1.jar:4.5.1-1]
at org.apache.spark.sql.catalyst.parser.SqlBaseLexer.<clinit>(SqlBaseLexer.java:1175) ~[spark-catalyst_2.11-2.4.0-cdh6.3.2.jar:2.4.0-cdh6.3.2]
... 13 more
注意这里方框这里信息
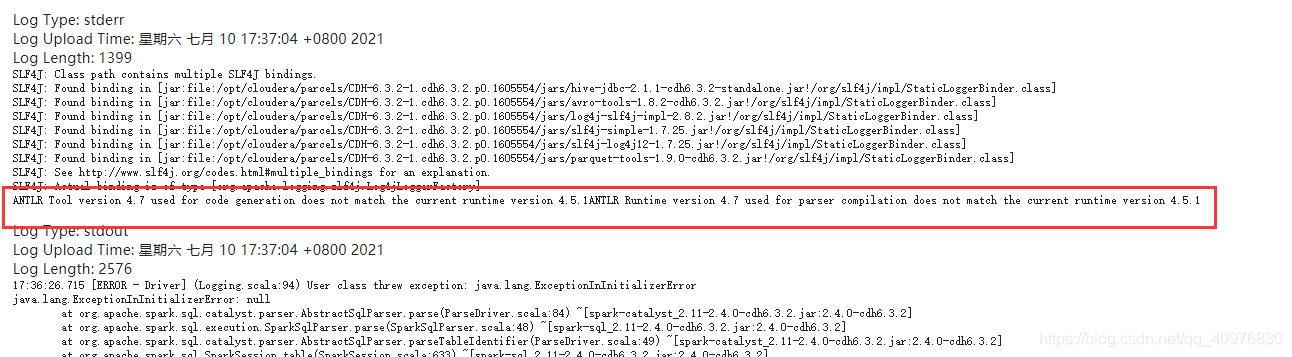
自己翻译一下,发现可能出现的问题是这里

spark执行SQL的流程是 解析(逻辑计划) --> 优化 --> 编译(物理计划) --> 执行
那么问题开始就是编译的时候采用antlr4-runtime-4.7.jar 的包,但是执行的时候用了antlr4-runtime-4.5.1-1.jar
具体为什么执行原因突然采用了4.5的jar 包原因不得而知;
排查问题:
在网上查找问题的时候发现这个情况
Anaconda 安装提示
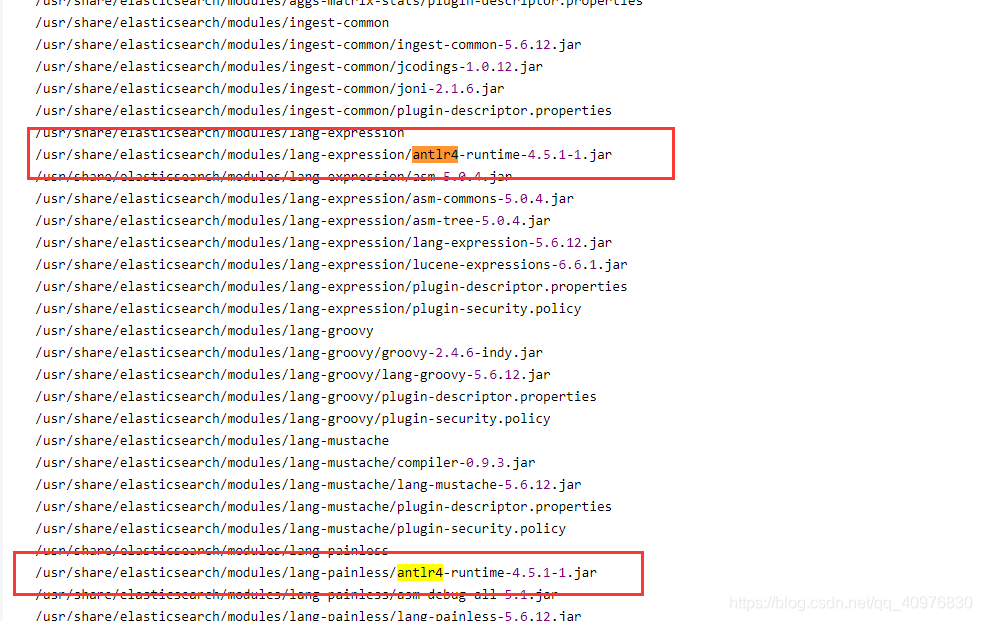
可能原因是安装Anaconda 导致添加了antlr4-runtime-4.5.1-1.jar

所以不知道为什么spark执行计划就突然调用了4.5的包jar 导致编译跟执行的时候版本不匹配,报这个问题
思路分析:
结合自己采用的是CDH 版本,spark 执行spark-submit 任务的时候在调用jar包库里是否有该jar 包,然后去注销(重命名)这个4.5.1-1的jar包
先查看自己的spark-defaults.conf
[root@sz-h37-v-bd-master02 conf]# vim spark-defaults.conf
发现driver 和executor的jar目录
spark.driver.extraClassPath=/opt/cloudera/parcels/CDH/jars/*
spark.executor.extraClassPath=/opt/cloudera/parcels/CDH/jars/*

所以就要去对应的目录下去重命名这个jar包就好了
这里注意:
是去执行端的节点下更改,所以你要去各个节点dn1-10 去进行更名操作,
[root@sz-h37-v-bd-master02 jars]# pwd
/opt/cloudera/parcels/CDH/jars
[root@sz-h37-v-bd-master02 jars]# mv antlr4-runtime-4.5.1-1.jar antlr4-runtime-4.5.1-1.jar.txt
然后就可以正常执行你的spark-submit 任务了