1、任务和任务链
在分布式计算环境中,Flink会将同一个Flink程序中具有依赖关系的多个操作符的子任务链接到一起形成一个任务链,每一个任务链都是由一个独特的线程进行执行。这样的优点:它减少了线程的切换和缓冲的开销,并在减少延迟的同时提高了总体的吞吐量(序列化和反序列化的影响,减少数据在缓冲区的交换)

假定该程序中Source,Map,KeyBy/Window操作符的并行度均为2,而Sink操作符的并行度均为1,由于Flink会尽可能地将多个操作符的子任务链接成一个任务链。我们首先看看如下的程序流图
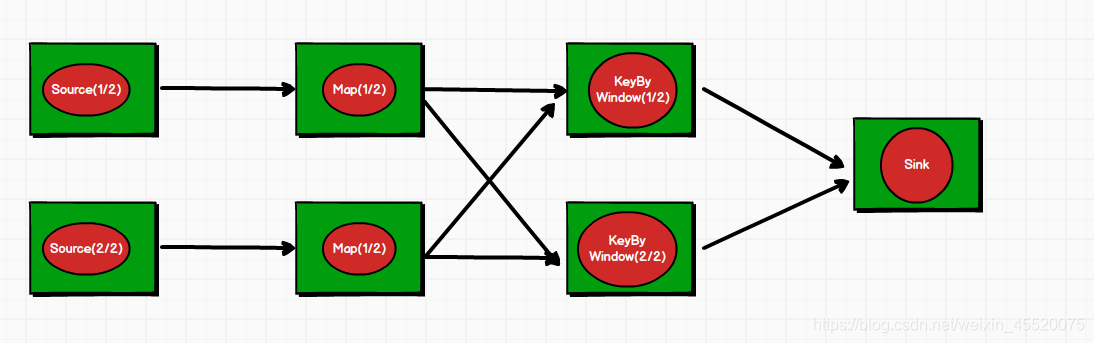
上图是程序优化前的数据流并行化视图
因为Source算子和Map算子之间的数据传递是一对一模式,KeyBy/Window则是个shuffle操作,而又因为Source算子和Map算子的任务并行度相同,可以链接成一个任务链。KeyBy/Window则单独形成一个任务链。Sink操作符子任务不会与KeyBy/Window操作符形成一个任务链。因为并行度不同。以下是数据流优化之后视图

最后以上就形成了5个任务(5个任务链),然后交由5个并行的线程去执行任务。
2、任务槽和资源
Flink架构分为JobManager和TaskManager,每个任务管理器对应的就是一个JVM进程(TaskManager),进程中对应分配资源(网络,磁盘,CPU,内存),进程中又至少又一个线程来执行任务。而Flink程序中的每个子任务就是运行在独立的线程中,为了控制一个任务管理器接收能处理的任务的数量,在任务管理器中引入了任务槽这个概念。
在任务管理器中只有有一个任务槽,而这个任务槽又是进程所分配资源的资源子集。这样可以在一个任务管理器中运行多个子任务。
根据第一部分的图,我们可以画出该Flink程序的子任务在任务槽中的分布图:
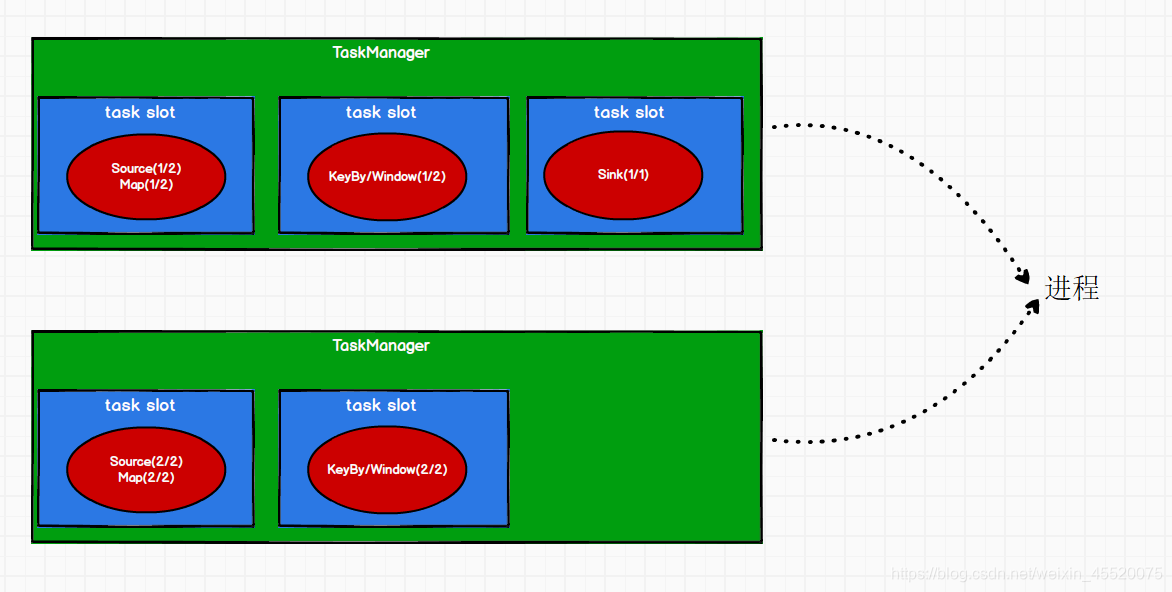
任务槽是静态的概念,指的是任务管理器最多能同时并发执行的任务数量,可以通过在flink-conf.xml文件中修改taskmanager.numberOfTaskSlots参数进行配置。而Flink程序中任务的并行度是动态的概念,指的是在任务管理器中运行该程序时实际使用的任务槽数通过修改flink-conf.xml文件中修改parallelism.default参数去配置Flink程序默认的并行度。
共享任务槽
在Flink程序中,默认情况下Flink允许子任务共享同一个任务槽,即使它们是不同操作符的子任务。在使用共享槽之后,上面的任务分布图改变成如下
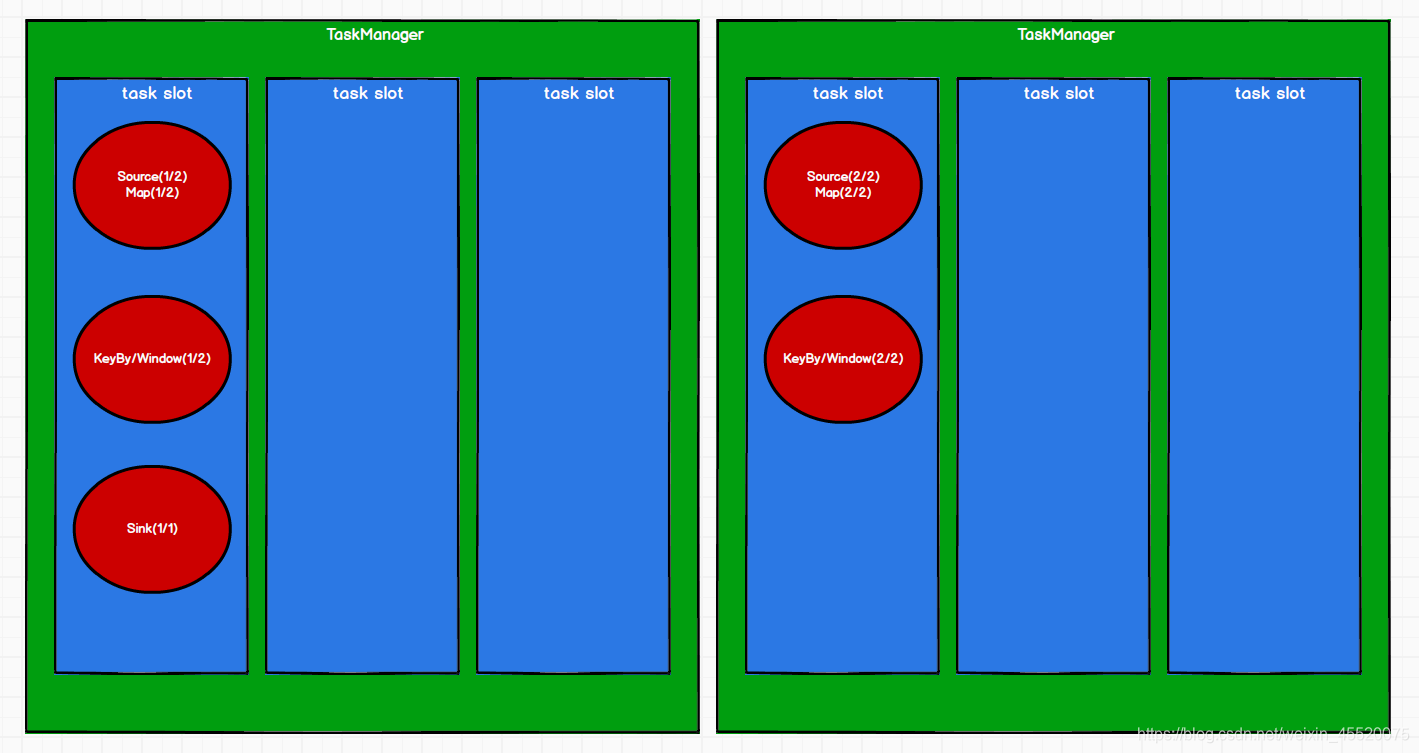
Flink程序允许共享任务槽有两个优点:
- 开发者不需要计算Flink程序有多少任务,只需要知道该程序中操作符的最大并行度是多少。
- 共享任务槽可以充分提高资源利用率
本章主要讲述Flink程序的分布式执行模型。大家觉得可以的话,动动小手点赞赞👍
