全局目录结构,滑下去后在侧边栏边
1.Hive 简介
1.1 简介
我们知道大数据主要解决海量数据的三大问题:「传输问题、存储问题、计算问题」。
而 Hive 主要解决**「存储和计算问题」**。
Hive 是由 Facebook 开源的基于 Hadoop 的数据仓库工具,用于解决海量**「结构化日志」**的数据统计。
Hive 存储的数据是在 hdfs 上的,但它可以将结构化的数据文件映射为一张表,并提供类 SQL 的查询功能。(我们称之为 Hive-SQL,简称 HQL)
简单来说,Hive 是在 Hadoop 上**「封装了一层 HQL 的接口」**,这样开发人员和数据分析人员就可以使用 HQL 来进行数据的分析,而无需关注底层的 MapReduce 的编程开发。
所以 Hive 的本质是**「将 HQL 转换成 MapReduce 程序」**。
1.2 优缺点
1.2.1 优点
- Hive 封装了一层接口,并提供类 SQL 的查询功能,避免去写 MapReduce,减少了开发人员的学习成本;
- Hive 支持用户自定义函数,可以根据自己的需求来实现自己的函数;
- 适合处理大数据:;
- 可扩展性强:可以自由扩展集群的规模,不需要重启服务而进行横向扩展;
- 容错性强:可以保障即使有节点出现问题,SQL 语句也可以完成执行;
1.2.2 缺点
- Hive 不支持记录级别的增删改操作,但是可以通过查询创建新表来将结果导入到文件中;(hive 2.3.2 版本支持记录级别的插入操作)
- Hive 延迟较高,不适用于实时分析;
- Hive 不支持事物,因为没有增删改,所以主要用来做 OLAP(联机分析处理),而不是 OLTP(联机事物处理);
- Hive 自动生成的 MapReduce 作业,通常情况下不够智能。
1.3 架构原理
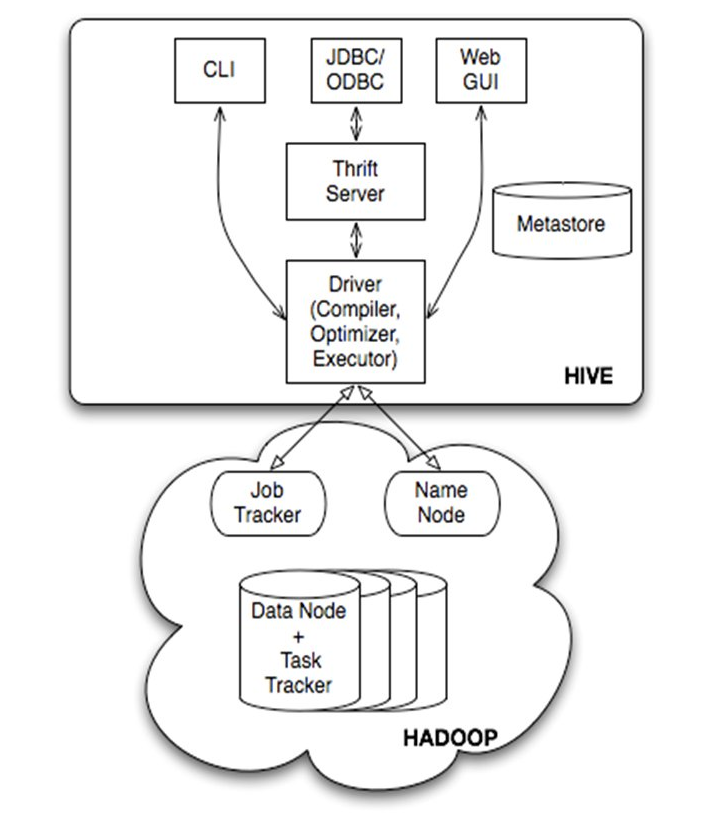
如上图所示:
-
Hive 提供了 CLI(hive shell)、JDBC/ODBC(Java 访问 hive)、WeibGUI 接口(浏览器访问 hive);
-
Hive的Metastore组件是hive元数据集中存放地。Metastore组件包括两个部分:metastore服务和后台数据的存储。后台数据存储的介质就是关系数据库,例如hive默认的嵌入式磁盘数据库derby,还有mysql数据库。Metastore服务是建立在后台数据存储介质之上,并且可以和hive服务进行交互的服务组件,默认情况下,metastore服务和hive服务是安装在一起的,运行在同一个进程当中。我也可以把metastore服务从hive服务里剥离出来,metastore独立安装在一个集群里,hive远程调用metastore服务,这样我们可以把元数据这一层放到防火墙之后,客户端访问hive服务,就可以连接到元数据这一层,从而提供了更好的管理性和安全保障。使用远程的metastore服务,可以让metastore服务和hive服务运行在不同的进程里,这样也保证了hive的稳定性,提升了hive服务的效率。
-
Thrift Server 为 Facebook 开发的一个软件框架,可以用来进行可扩展且跨语言的服务开发,Hive 通过集成了该服务能够让不同编程语言调用 Hive 的接口;
-
Hadoop 使用 HDFS 进行存储,并使用 MapReduce 进行计算;
-
Driver 中包含解释器(Interpreter)、编译器(Compiler)、优化器(Optimizer)和执行器(Executor), 它的作用是将我们写的HiveQL(类SQL)语句进行解析、编译优化,生成执行计划,然后调用底层的mapreduce计算框架。
-
- 「解释器」:利用第三方工具将 HQL 查询语句转换成抽象语法树 AST,并对 AST 进行语法分析,比如说表是否存在、字段是否存在、SQL 语义是否有误;
- 「编译器」:将 AST 编译生成逻辑执行计划;
- 「优化器」:多逻辑执行单元进行优化;
- 「执行器」:把逻辑执行单元转换成可以运行的物理计划,如 MapReduce、Spark。
所以 Hive 查询的大致流程为:通过用户交互接口接收到 HQL 的指令后,经过 Driver 结合元数据进行类型检测和语法分析,并生成一个逻辑方法,通过进行优化后生成 MapReduce,并提交到 Hadoop 中执行,并把执行的结果返回给用户交互接口。
hive的执行流程图
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-awgDSuo3-1626059967133)(C:\Users\qingc\AppData\Roaming\Typora\typora-user-images\1625651774204.png)]
1.4 与 RDBMS 的比较
Hive 采用类 SQL 的查询语句,所以很容易将 Hive 与关系型数据库(RDBMS)进行对比。但其实 Hive 除了拥有类似 SQL 的查询语句外,再无类似之处。我们需要明白的是:数据库可以用做 online 应用;而 Hive 是为数据仓库设计的。
| Hive | RDBMS | |
|---|---|---|
| 查询语言 | HQL | SQL |
| 数据存储 | HDFS | 本地文件系统中 |
| 数据更新 | 读多写少(不建议改写) | 增删改查 |
| 数据操作 | 覆盖追加 | 行级别更新删除 |
| 索引 | 0.8 版本后引入 bitmap 索引 | 建立索引 |
| 执行 | MapReduce | Executor |
| 执行延迟 | 延迟较高 | 延迟较低 |
| 可扩展性 | 可扩展性高 | 可扩展性低 |
| 数据规模 | 很大 | 较小 |
| 分区 | 支持 | 支持 |
总的来说,Hive 只具备 SQL 的外表,但应用场景完全不同。Hive 只适合用来做海量离线数据统计分析,也就是数据仓库。清楚这一点,有助于从应用角度理解 Hive 的特性。
2.Hive 基本操作
2.1 Hive 常用命令
在终端输入 hive -help 会出现:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-I2ZHsIPC-1626059967134)(C:\Users\qingc\AppData\Roaming\Typora\typora-user-images\1625626135969.png)]
常用的两个命令是 “-e” 和 “-f”:
- “-e” 表示不进入 hive cli 直接执行 SQL 语句;
hive -e "select * from teacher;"
- “-f” 表示执行 SQL 语句的脚本(方便用 crontab 进行定时调度);
hive -f /opt/module/datas/hivef.sql
2.2 本地文件导入 Hive 表中
首先需要创建一张表:
create table student( id int, name string) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
简单介绍下字段:
- ROW FORMAT DELIMITED:分隔符的设置的开始语句;
- FIELDS TERMINATED BY:设置每一行字段与字段之间的分隔符,我们这是用 ‘\t’ 进行划分;
除此之外,还有其他的分割符设定:
- COLLECTION ITEMS TERMINATED BY:设置一个复杂类型(array/struct)字段的各个 item 之间的分隔符;
- MAP KEYS TERMINATED BY:设置一个复杂类型(Map)字段的 key value 之间的分隔符;
- LINES TERMINATED BY:设置行与行之间的分隔符;
这里需要注意的是 ROW FORMAT DELIMITED 必须在其它分隔设置之前;LINES TERMINATED BY 必须在其它分隔设置之后,否则会报错。
然后,我们需要准备一个文件:
# stu.txt
1 Xiao_ming
2 xiao_hong
3 xiao_hao
需要注意,每行内的字段需要用 ‘\t’ 进行分割。
接着需要使用 load 语法加载本地文件,load 语法为:
load data [local] inpath 'filepath' [overwrite] into table tablename [partition (partcol1=val1,partcol2=val2...)]
- local 用来控制选择本地文件还是 hdfs 文件;
- overwrite 可以选择是否覆盖原来数据;
- partition 可以制定分区;
hive> load data local inpath '/Users/***/Desktop/stu1.txt' into table student;
最后查看下数据:
hive> select * from student;
OK
1 Xiao_ming
2 xiao_hong
3 xiao_hao
Time taken: 1.373 seconds, Fetched: 3 row(s)
2.3 Hive 其他操作
- quit:不提交数据退出;
- exit:先隐性提交数据,再退出。
不过这种区别只是在旧版本中有,两者在新版本已经没有区别了。
在 hive cli 中可以用以下命令查看 hdfs 文件系统和本地文件系统:
dfs -ls /; # 查看 hdfs 文件系统!
ls ./; # 查看本地文件系统
用户根目录下有一个隐藏文件记录着 hive 输入的所有历史命令:
cat ./hivehistory
注意:hive 语句不区分大小写。
3.Hive 常见属性配置
3.1 数据仓库位置
Default 的数据仓库原始位置是在 hdfs 上的:/user/hive/warehoues 路径下。如果某张表属于 Default 数据库,那么会直接在数据仓库目录创建一个文件夹。
我们以刚刚创建的表为例,来查询其所在集群位置:
hive> desc formatted student;
OK
# col_name data_type comment
id int
name string
# Detailed Table Information
Database: default
OwnerType: USER
Owner: **
CreateTime: Fri Jul 17 08:59:14 CST 2020
LastAccessTime: UNKNOWN
Retention: 0
Location: hdfs://localhost:9000/user/hive/warehouse/student
Table Type: MANAGED_TABLE
Table Parameters:
bucketing_version 2
numFiles 1
numRows 0
rawDataSize 0
totalSize 34
transient_lastDdlTime 1594948899
# Storage Information
SerDe Library: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
InputFormat: org.apache.hadoop.mapred.TextInputFormat
OutputFormat: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
Compressed: No
Num Buckets: -1
Bucket Columns: []
Sort Columns: []
Storage Desc Params:
field.delim \t
serialization.format \t
Time taken: 0.099 seconds, Fetched: 32 row(s)
可以看到,Table Information 里面有一个 Location,表示当前表所在的位置,因为 student 是 Default 数据仓库的,所以会在 ‘/user/hive/warehouse/’ 路径下。
如果我们想要修改 Default 数据仓库的原始位置,需要在 hive-site.xml(可以来自 hive-default.xml.template)文件下加入如下配置信息,并修改其 value:
<property>
<name>hive.metastore.warehouse.dir</name> <value>/user/hive/warehouse</value>
<description>location of default database for the warehouse</description> </property>
同时也需要给修改的路径配置相应的权限:
hdfs dfs -chmod g+w /user/hive/warehouse
hive 中 formatted 的用法:
- select * from 表名: 查询该表名的所有字段记录
- desc formatted 表名: 查看该表的结构化数据,但并不列出表中的数据
3.2 查询信息显示配置
我们可以在 hive-site.xml 中配置如下信息,便可以实现显示当前数据库以及查询表的头信息:
<property>
<name>hive.cli.print.header</name>
<value>true</value>
</property>
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
</property>
当然我们也可以通过 set 命令来设置:
set hive.cli.print.header=true; # 显示表头
set hive.cli.print.current.db=true; # 显示当前数据库
看下前后对比:
# 前
hive> select * from studenT;
OK
1 Xiao_ming
2 xiao_hong
3 xiao_hao
Time taken: 0.231 seconds, Fetched: 3 row(s)
# 后
hive (default)> select * from student;
OK
student.id student.name
1 Xiao_ming
2 xiao_hong
3 xiao_hao
Time taken: 0.202 seconds, Fetched: 3 row(s)
3.3 参数配置方式
可以用 set 查看当前所有参数配置信息:
hive> set
但是一般不这么玩,会显示很多信息。
通常配置文件有三种方式:
-
配置文件方式:
默认配置文件:hive-default.xml
用户自定义配置文件:hive-site.xml
注意:用户自定义配置会覆盖默认配置。另外,Hive 也会读入 Hadoop 的配置,因为 Hive 是作为 Hadoop 的客户端启动的,Hive 的配置会覆盖 Hadoop 的配置。配置文件的设定对本机启动的所有 Hive 进程都有效。
-
命令行参数方式:
启动 Hive 时,可以在命令行添加 -hiveconf param=value 来设定参数。比如
# 设置 reduce 个数> hive -hiveconf mapred.reduce.tasks=10;这样设置是仅对本次 hive 启动有效。
-
参数声明方式
可以在 hive cli 中通过 set 关键字设定参数:
hive (default)> set mapred.reduce.tasks=100;这样设置也是仅对本次 hive 启动有效。
上述三种设定方式的优先级依次递增。即配置文件<命令行参数<参数声明。注意某些系统级的参数,例如 log4j 相关的设定,必须用前两种方式设定,因为那些参数的读取在会话建立以前已经完成了。
4.Hive 数据类型
4.1 基本数据类型
| Hive 数据类型 | Java 数据类型 | 长度 |
|---|---|---|
| TINYINT | byte | 1byte 有符号整数 |
| SMALINT | short | 2byte 有符号整数 |
| INT | int | 4byte 有符号整数 |
| BIGINT | long | 8byte 有符号整数 |
| BOOLEAN | boolean | 布尔类型,true 或者 false |
| FLOAT | float | 单精度浮点数 |
| DOUBLE | double | 双精度浮点数 |
| STRING | string | 字符系列。可以指定字符集。可以使用单引号或者双引号。 |
| TIMESTAMP | 时间类型 | |
| BINARY | 字节数组 |
Hive 的 String 类型相当于数据库的 varchar 类型,该类型是一个可变的字符串,不过它不能声明其中最多能存储多少个字符,理论上它可以存储 2GB 的字符数。
4.2 集合数据类型
| 数据类型 | 描述 | 语法示例 |
|---|---|---|
| STRUCT | 和 c 语言中的 struct 类似,都可以通过“点”符号访问元素内容。例如,如果某个列的数据类型是 STRUCT{first STRING, last STRING},那么第 1 个元素可以通过字段.first 来引用。 | struct() |
| MAP | MAP 是一组键-值对元组集合,使用数组表示法可以访问数据。例如,如果某个列的数据类型是 MAP,其中键->值对 是 ’first’->’John’ 和 ’last’->’Doe’,那么可以通过字段名 [‘last’] 获取最后一个元素。 | map() |
| ARRAY | 数组是一组具有相同类型和名称的变量的集合。这些变量称为数组的元素,每个数组元素都有一个编号,编号从零开始。例如,数组值为 [‘John’, ‘Doe’], 那么第 2 个元素可以通过数组名 [1] 进行引用。 | Array() |
Hive 有三种复杂数据类型 ARRAY、MAP、STRUCT。ARRAY 和 MAP 与 Java 中的 Array 和 Map 类似,而 STRUCT 与 C 语言中的 Struct 类似,它封装了一个命名字段集合,复杂数据类型允许任意层次的嵌套。
案例实操:
-
假设某表有如下一行,我们用 JSON 格式来表示其数据结构。在 Hive 下访问的格式为:
{ "name": "songsong", "friends": ["bingbing" , "lili"] , //列表 Array, "children": { //键值 Map, "xiao song": 18 , "xiaoxiao song": 19 }, "address": { //结构 Struct, "street": "hui long guan" , "city": "beijing" } } -
基于上述数据结构,我们在 Hive 里创建对应的表,并导入数据。创建本地测试文件 text.txt:
songsong,bingbing_lili,xiao song:18_xiaoxiao song:19,hui long guan_beijing注意:MAP,STRUCT 和 ARRAY 里的元素间关系都可以用同一个字符表示,这里用“_”。
-
Hive 上创建测试表 test:
create table test( name string, friends array<string>, children map<string, int>, address struct<street:string, city:string> ) row format delimited fields terminated by ',' collection items terminated by '_' map keys terminated by ':' lines terminated by '\n';字段解释:
- row format delimited fields terminated by ‘,’:列分隔符;
- collection items terminated by ‘_’:MAP STRUCT 和 ARRAY 的分隔符(数据分割符号);
- map keys terminated by ‘:’:MAP 中的 key 与 value 的分隔符;
- lines terminated by ‘\n’:行分隔符。
-
导入文本数据到测试表中:
hive (default)> load data local inpath '/Users/chenze/Desktop/test.txt' into table test; -
访问三种集合列里的数据:
先看一下数据:
hive (default)> select * from test; OK test.name test.friends test.children test.address songsong ["bingbing","lili"] {"xiao song":18,"xiaoxiao song":19} {"street":"hui long guan","city":"beijing yangyang"} Time taken: 0.113 seconds, Fetched: 1 row(s)查看 ARRAY,MAP,STRUCT 的访问方式:
hive (default)> select friends[1],children['xiao song'],address.city from test where name="songsong"; OK _c0 _c1 city lili 18 beijing Time taken: 0.527 seconds, Fetched: 1 row(s)
4.3 数据类型转化
Hive 的原子数据类型是可以进行隐式转换的,类似于 Java 的类型转换,例如某表达式使用 INT 类型,TINYINT 会自动转换为 INT 类型,但是 Hive 不会进行反向转化,例如,某表达式使用 TINYINT 类型,INT 不会自动转换为 TINYINT 类型,它会返回错误,除非使用 CAST 操作。
-
隐式类型转换规则如下
-
- 任何整数类型都可以隐式地转换为一个范围更广的类型,如 TINYINT 可以转换 成 INT,INT 可以转换成 BIGINT;
- 所有整数类型、FLOAT 和 STRING 类型都可以隐式地转换成 DOUBLE;
- TINYINT、SMALLINT、INT 都可以转换为 FLOAT;
- BOOLEAN 类型不可以转换为任何其它的类型。
-
可以使用 CAST 操作显示进行数据类型转换
例如 CAST(‘1’ AS INT) 将把字符串 ‘1’ 转换成整数 1;如果强制类型转换失败,如执行 CAST(‘X’ AS INT),表达式返回空值 NULL。
5.数据组织
1、Hive 的存储结构包括**「数据库、表、视图、分区和表数据」**等。数据库,表,分区等等都对 应 HDFS 上的一个目录。表数据对应 HDFS 对应目录下的文件。
2、Hive 中所有的数据都存储在 HDFS 中,没有专门的数据存储格式,因为 「Hive 是读模式」 (Schema On Read),可支持 TextFile,SequenceFile,RCFile 或者自定义格式等。
- 「TextFile」:默认格式,存储方式为行存储。数据不做压缩,磁盘开销大,数据解析开销大;
- 「SequenceFile」:Hadoop API 提供的一种二进制文件支持,其具有使用方便、可分割、可压缩的特点。SequenceFile 支持三种压缩选择:NONE, RECORD, BLOCK。Record 压缩率低,一般建议使用 BLOCK 压缩;
- 「RCFile」:一种行列存储相结合的存储方式;
- 「ORCFile」:数据按照行分块,每个块按照列存储,其中每个块都存储有一个索引。Hive 给出的新格式,属于 RCFILE 的升级版,性能有大幅度提升,而且数据可以压缩存储,压缩快,且可以快速列存取;
- 「Parquet」:一种行式存储,同时具有很好的压缩性能;同时可以减少大量的表扫描和反序列化的时间。
3、 只需要在创建表的时候告诉 Hive 数据中的**「列分隔符和行分隔符」**,Hive 就可以解析数据
- Hive 的默认列分隔符:控制符 「Ctrl + A,\x01 Hive」 等;
- Hive 的默认行分隔符:换行符 「\n」。
4、Hive 中包含以下数据模型:
- 「database」:在 HDFS 中表现为${hive.metastore.warehouse.dir}目录下一个文件夹;
- 「table」:在 HDFS 中表现所属 database 目录下一个文件夹;
- 「external table」:与 table 类似,不过其数据存放位置可以指定任意 HDFS 目录路径;
- 「partition」:在 HDFS 中表现为 table 目录下的子目录;
- 「bucket」:在 HDFS 中表现为同一个表目录或者分区目录下根据某个字段的值进行 hash 散列之后的多个文件;
- 「view」:与传统数据库类似,只读,基于基本表创建
5、Hive 的元数据存储在 RDBMS 中,除元数据外的其它所有数据都基于 HDFS 存储。默认情 况下,Hive 元数据保存在内嵌的 Derby 数据库中,只能允许一个会话连接,只适合简单的 测试。实际生产环境中不适用,为了支持多用户会话,则需要一个独立的元数据库,使用 MySQL 作为元数据库,Hive 内部对 MySQL 提供了很好的支持。
6、Hive 中的表分为内部表、外部表、分区表和 Bucket 表
-
「内部表和外部表的区别:」
-
- 创建内部表时,会将数据移动到数据仓库指向的路径;创建外部表时,仅记录数据所在路径,不对数据的位置做出改变;
- 删除内部表时,删除表元数据和数据**;**删除外部表时,删除元数据,不删除数据。所以外部表相对来说更加安全些,数据组织也更加灵活,方便共享源数据;
- 内部表数据由 Hive 自身管理,外部表数据由 HDFS 管理;
- 未被 external 修饰的是内部表,被 external 修饰的为外部表;
- 对内部表的修改会直接同步到元数据,而对外部表的表结构和分区进行修改,则需要修改 ‘MSCK REPAIR TABLE [table_name]’。
-
「内部表和外部表的使用选择:」
-
- 大多数情况,他们的区别不明显,如果数据的所有处理都在 Hive 中进行,那么倾向于选择内部表;但是如果 Hive 和其他工具要针对相同的数据集进行处理,外部表更合适;
- 使用外部表访问存储在 HDFS 上的初始数据,然后通过 Hive 转换数据并存到内部表中;
- 使用外部表的场景是针对一个数据集有多个不同的 Schema( 数据库对象的集合 );
- 通过外部表和内部表的区别和使用选择的对比可以看出来,hive 其实仅仅只是对存储在 HDFS 上的数据提供了一种新的抽象,而不是管理存储在 HDFS 上的数据。所以不管创建内部表还是外部表,都可以对 hive 表的数据存储目录中的数据进行增删操作。
-
「分区表和分桶表的区别:」
-
- Hive 数据表可以根据某些字段进行分区操作,细化数据管理,可以让部分查询更快。同时表和分区也可以进一步被划分为 桶(Buckets),分桶表的原理和 MapReduce 编程中的 Spark分区器(HashPartitioner) 的原理类似;
- 分区和分桶都是细化数据管理,但是分区表是手动添加区分,由于 Hive 是读模式,所以对添加进分区的数据不做模式校验,分桶表中的数据是按照某些分桶字段进行 hash 散列形成的多个文件,所以数据的准确性也高很多。
6.HQL 语法
SQL 语言分为四大类:
- 数据查询语言 DQL:基本结构由 SELECT、FROM、WEHERE 子句构成查询块;
- 数据操纵语言 DML:包括插入、更新、删除;
- 数据定义语言 DDL:包括创建数据库中的对象――表、视图、索引等;
- 数据控制语言 DCL:授予或者收回数据库的权限,控制或者操纵事务发生的时间及效果、对数据库进行监视等。
而 HQL 中,分类如下(以 Hive 的 wiki 分类为准):
HQL DDL 语法包括:
- 创建:CREATE DATABASE/SCHEMA, TABLE, VIEW, FUNCTION, INDEX;
- 删除:DROP DATABASE/SCHEMA, TABLE, VIEW, INDEX;
- 替代:ALTER DATABASE/SCHEMA, TABLE, VIEW
- 清空:TRUNCATE TABLE;
- 修复:MSCK REPAIR TABLE (or ALTER TABLE RECOVER PARTITIONS);
- 展示:SHOW DATABASES/SCHEMAS, TABLES, TBLPROPERTIES, VIEWS, PARTITIONS, FUNCTIONS, INDEX[ES], COLUMNS, CREATE TABLE;
- 描述:DESCRIBE DATABASE/SCHEMA, table_name, view_name, materialized_view_name。
HQL DML 语法包括:
- 导入:Load file to table;
- 导出:Writing data into thie filesystem from queries;
- 插入:Inserting data into table from queries/ SQL;
- 更新:Update;
- 删除:Delete;
- 合并:Merge。
6.1.DDL
1.1 DATABASE
1.1.1 Create Database
CREATE (DATABASE|SCHEMA) [IF NOT EXISTS] database_name [COMMENT database_comment] [LOCATION hdfs_path] [MANAGEDLOCATION hdfs_path] [WITH DBPROPERTIES (property_name=property_value, ...)];
- SCHEMA 和 DATABASE 的用法是可互换,因为含义相同;
- IF NOT EXISTS 最好加上,防止冲突;
- LOCATION hdfs_path 加载 hdfs 上的数据;
- MANAGEDLOCATION 出现在 Hive 4.0 中,指外部表的默认目录;
- WITH DBPROPERTIES 可以设置属性和值,会存储在 Mysql 中的元数据库中。
1.1.2 Drop Database
DROP (DATABASE|SCHEMA) [IF EXISTS] database_name [RESTRICT|CASCADE];
删除数据库的模型行为是 RESTRICT,如果数据库不为空,需要添加 CASCADE 进行级联删除。
1.1.3 Alter Database
ALTER (DATABASE|SCHEMA) database_name SET DBPROPERTIES (property_name=property_value, ...); -- (Note: SCHEMA added in Hive 0.14.0) ALTER (DATABASE|SCHEMA) database_name SET OWNER [USER|ROLE] user_or_role; -- (Note: Hive 0.13.0 and later; SCHEMA added in Hive 0.14.0) ALTER (DATABASE|SCHEMA) database_name SET LOCATION hdfs_path; -- (Note: Hive 2.2.1, 2.4.0 and later) ALTER (DATABASE|SCHEMA) database_name SET MANAGEDLOCATION hdfs_path; -- (Note: Hive 4.0.0 and later)
可以修改数据库的属性(property)、所属人(owner)、位置(location)、外部表位置(menaged location)。
修改位置时,并不会将数据库的当前目录的内容移动到新的位置,只是更改了默认的父目录,在该目录中为此数据库添加新表。
数据库的其他元素无法进行更改。
1.1.4 User Database
USE database_name;USE DEFAULT;
1.2 TABLE
1.2.1 Create Table
CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name -- (Note: TEMPORARY available in Hive 0.14.0 and later)
[(col_name data_type [column_constraint_specification] [COMMENT col_comment], ... [constraint_specification])]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
[CLUSTERED BY (col_name, col_name, ...) [SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
[SKEWED BY (col_name, col_name, ...) -- (Note: Available in Hive 0.10.0 and later)]
ON ((col_value, col_value, ...), (col_value, col_value, ...), ...)
[STORED AS DIRECTORIES]
[
[ROW FORMAT row_format]
[STORED AS file_format]
| STORED BY 'storage.handler.class.name' [WITH SERDEPROPERTIES (...)] -- (Note: Available in Hive 0.6.0 and later)
]
[LOCATION hdfs_path]
[TBLPROPERTIES (property_name=property_value, ...)] -- (Note: Available in Hive 0.6.0 and later)
[AS select_statement]; -- (Note: Available in Hive 0.5.0 and later; not supported for external tables)
- Hive 表名和列名不区分大小写,但 SerDe(序列化/反序列化) 和属性名称是区分大小写的;
- TEMPORARY:临时表只对此次 session 有效,退出后自动删除;
- EXTERNAL:由 hdfs 托管的外部表,不加则为由 hive 管理的内部表;
- PARTITIONED:分区,可以用一个或多个字段进行分区,「分区的好处在于只需要针对分区进行查询,而不必全表扫描」;
- CLUSTERED:分桶,并非所有的数据集都可以形成合理的分区。可以对表和分区进一步细分成桶,桶是对数据进行更细粒度的划分。Hive 默认采用对某一列的数据进行 Hash 分桶。分桶实际上和 MapReduce 中的分区是一样的。分桶数和 Reduce 数对应;
- SKEWED:数据倾斜,通过制定经常出现的值(严重倾斜),hive 会在元数据中记录这些倾斜的列名和值,在 join 时能够进行优化。若是指定了 STORED AS DIRECTORIES,也就是使用列表桶(ListBucketing),hive 会对倾斜的值建立子目录,查询会更加得到优化;
- STORED AS file_format:文件存储类型;
- LOCATION hdfs_path:hdfs 的位置;
- TBLPROPERTIES:表的属性和值;
- AS select_statement:可以设置一个代号,不支持外部表;
- CTAS:Create table as select,用查询结果来创建和填充。CTAS 有些限制:目标表不能是分区表、不能是外部表、不能是列表桶表。
当然,我们也可以从已有的数据中进行 Copy,使用 Like 字段:
CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name LIKE existing_table_or_view_name [LOCATION hdfs_path];
1.2.2 Drop Table
DROP TABLE [IF EXISTS] table_name [PURGE]; -- (Note: PURGE available in Hive 0.14.0 and later)
删除表的元数据和数据。如果加 PURGE 字段,则数据不会转移到 .Trash/Current 目录下。因此,误操作后将无法恢复。
1.2.3 Truncate Table
TRUNCATE [TABLE] table_name [PARTITION partition_spec]; partition_spec: : (partition_column = partition_col_value, partition_column = partition_col_value, ...)
清空表或分区(一个或多个分区)的所有行。
1.2.3 Alter Table/Partition/Column
1.2.3.1 Table
修改表名:
ALTER TABLE table_name RENAME TO new_table_name;
更改表属性:
ALTER TABLE table_name SET TBLPROPERTIES table_properties; table_properties: : (property_name = property_value, property_name = property_value, ... )
修改表注释:
ALTER TABLE table_name SET TBLPROPERTIES ('comment' = new_comment);
添加 SerDe 属性:
ALTER TABLE table_name [PARTITION partition_spec] SET SERDE serde_class_name [WITH SERDEPROPERTIES serde_properties]; ALTER TABLE table_name [PARTITION partition_spec] SET SERDEPROPERTIES serde_properties; serde_properties: : (property_name = property_value, property_name = property_value, ... )
Hive 4.0 支持删除 SerDe 属性:
ALTER TABLE table_name [PARTITION partition_spec] UNSET SERDEPROPERTIES (property_name, ... );
更改表存储属性:
ALTER TABLE table_name CLUSTERED BY (col_name, col_name, ...) [SORTED BY (col_name, ...)] INTO num_buckets BUCKETS;
修改表倾斜:
ALTER TABLE table_name SKEWED BY (col_name1, col_name2, ...) ON ([(col_name1_value, col_name2_value, ...) [, (col_name1_value, col_name2_value), ...] [STORED AS DIRECTORIES];
更改表不倾斜:
ALTER TABLE table_name NOT SKEWED;
更改表未存储为目录:
ALTER TABLE table_name NOT STORED AS DIRECTORIES;
更改表的约束:
ALTER TABLE table_name ADD CONSTRAINT constraint_name PRIMARY KEY (column, ...) DISABLE NOVALIDATE;ALTER TABLE table_name ADD CONSTRAINT constraint_name FOREIGN KEY (column, ...) REFERENCES table_name(column, ...) DISABLE NOVALIDATE RELY;ALTER TABLE table_name ADD CONSTRAINT constraint_name UNIQUE (column, ...) DISABLE NOVALIDATE;ALTER TABLE table_name CHANGE COLUMN column_name column_name data_type CONSTRAINT constraint_name NOT NULL ENABLE;ALTER TABLE table_name CHANGE COLUMN column_name column_name data_type CONSTRAINT constraint_name DEFAULT default_value ENABLE;ALTER TABLE table_name CHANGE COLUMN column_name column_name data_type CONSTRAINT constraint_name CHECK check_expression ENABLE; ALTER TABLE table_name DROP CONSTRAINT constraint_name;
1.2.3.2 Partition
添加分区:
ALTER TABLE table_name ADD [IF NOT EXISTS] PARTITION partition_spec [LOCATION 'location'][, PARTITION partition_spec [LOCATION 'location'], ...]; partition_spec: : (partition_column = partition_col_value, partition_column = partition_col_value, ...)
重命名分区:
ALTER TABLE table_name PARTITION partition_spec RENAME TO PARTITION partition_spec;
交换分区:
-- Move partition from table_name_1 to table_name_2ALTER TABLE table_name_2 EXCHANGE PARTITION (partition_spec) WITH TABLE table_name_1;-- multiple partitionsALTER TABLE table_name_2 EXCHANGE PARTITION (partition_spec, partition_spec2, ...) WITH TABLE table_name_1;
恢复分区:
MSCK [REPAIR] TABLE table_name [ADD/DROP/SYNC PARTITIONS];
如果新的分区被直接加入到 HDFS(比如 hadoop fs -put),或从 HDFS 移除,metastore 并将不知道这些变化,除非用户在分区表上每次新添或删除分区时分别运行 ALTER TABLE table_name ADD/DROP PARTITION 命令。
我们可以运行恢复分区来进行维修。
删除分区:
ALTER TABLE table_name DROP [IF EXISTS] PARTITION partition_spec[, PARTITION partition_spec, ...] ``[IGNORE PROTECTION] [PURGE]; -- (Note: PURGE available in Hive ``1.2``.``0` `and later, IGNORE PROTECTION not available ``2.0``.``0` `and later)
1.2.3.3 Column
更改列名称/类型/位置/注释:
ALTER TABLE table_name [PARTITION partition_spec] CHANGE [COLUMN] col_old_name col_new_name column_type [COMMENT col_comment] [FIRST|AFTER column_name] [CASCADE|RESTRICT];
添加/替换列:
ALTER TABLE table_name [PARTITION partition_spec] -- (Note: Hive 0.14.0 and later) ADD|REPLACE COLUMNS (col_name data_type [COMMENT col_comment], ...) [CASCADE|RESTRICT] -- (Note: Hive 1.1.0 and later)
1.3 VIEW
1.3.1 Create View
CREATE VIEW [IF NOT EXISTS] [db_name.]view_name [(column_name [COMMENT column_comment], ...) ] ``[COMMENT view_comment] ``[TBLPROPERTIES (property_name = property_value, ...)] ``AS SELECT ...;
- 视图是纯逻辑对象,没有相关的存储;
- 如果视图的定义 SELECT 表达式无效,则 CREATE VIEW 语句将失败;
- 视图只读,不能用作 LOAD/INSERT/ALTER 的目标;
- 视图可能包含 ORDER BY 和 LIMIT 子句;
1.3.2 Delete View
DROP VIEW [IF EXISTS] [db_name.]view_name;
1.3.3 Alter View
ALTER VIEW [db_name.]view_name SET TBLPROPERTIES table_properties; table_properties: : (property_name = property_value, property_name = property_value, ...)
同 Table。
1.3.4 Alter View As Select
ALTER VIEW [db_name.]view_name AS select_statement;
更改视图的定义。
1.4 INDEX
1.4.1 Create Index
CREATE INDEX index_name ON TABLE base_table_name (col_name, ...) AS index_type [WITH DEFERRED REBUILD] [IDXPROPERTIES (property_name=property_value, ...)] [IN TABLE index_table_name] [ [ ROW FORMAT ...] STORED AS ... | STORED BY ... ] [LOCATION hdfs_path] [TBLPROPERTIES (...)] [COMMENT "index comment"];
使用给定的列作为键在表上创建索引
1.4.2 Drop Index
DROP INDEX [IF EXISTS] index_name ON table_name;
1.4.3 Alter Index
ALTER INDEX index_name ON table_name [PARTITION partition_spec] REBUILD;
REBUILD 为使用 WITH DEFERRED REBUILD 子句的索引建立索引或重建先前建立的索引。如果指定分区,那么只有该分区重建。
1.5 MACRO
宏命令,与 Java 中的宏一致。
1.5.1 Create Macro
CREATE TEMPORARY MACRO macro_name([col_name col_type, ...]) expression;
举个例子:
CREATE TEMPORARY MACRO fixed_number() 42;
CREATE TEMPORARY MACRO string_len_plus_two(x string) length(x) + 2;
CREATE TEMPORARY MACRO simple_add (x int, y int) x + y;
宏的有效期存在于该 Session 内。
1.5.2 Drop Macro
DROP TEMPORARY MACRO [IF EXISTS] macro_name;
1.6 FUNCTION
1.6.1 Temporary Function
创建和删除临时函数:
CREATE TEMPORARY FUNCTION function_name AS class_name;DROP TEMPORARY FUNCTION [IF EXISTS] function_name;
1.6.2 Permanent Function
在 Hive0.13 或更高版本中,函数可以注册到 metastore,这样就可以在每次查询中进行引用,而不需要每次都创建临时函数。
创建和删除永久函数:
CREATE FUNCTION [db_name.]function_name AS class_name ``[USING JAR|FILE|ARCHIVE ``'file_uri'` `[, JAR|FILE|ARCHIVE ``'file_uri'``] ]; DROP FUNCTION [IF EXISTS] function_name;
重载函数:
RELOAD (FUNCTIONS|FUNCTION);
1.7 SHOW
Show 操作可以利用正则表达式进行过滤,而正则表达式中的通配符只能是“ *”或“ |” 供选择。
展示数据库:
SHOW (DATABASES|SCHEMAS) [LIKE ``'identifier_with_wildcards'``];
将列出了元存储中定义的所有数据库。
展示表:
SHOW TABLES [IN database_name] [LIKE ``'identifier_with_wildcards'``];
展示视图
SHOW VIEWS [IN/FROM database_name] [LIKE ``'pattern_with_wildcards'``];
展示表/分区扩展
SHOW TABLE EXTENDED [IN|FROM database_name] LIKE ``'identifier_with_wildcards'` `[PARTITION(partition_spec)];
展示表的属性
SHOW TBLPROPERTIES tblname;SHOW TBLPROPERTIES tblname(``"foo"``);
展示函数
SHOW FUNCTIONS [LIKE ``"<pattern>"``];
1.8 DESCRIBE
描述数据库,包括数据库名、注释、位置等。EXTENDED 还会显示了数据库属性。
DESCRIBE DATABASE [EXTENDED] db_name;DESCRIBE SCHEMA [EXTENDED] db_name; -- (Note: Hive ``1.1``.``0` `and later)
描述表/视图/材料化视图/列:
DESCRIBE [EXTENDED|FORMATTED] ``table_name[.col_name ( [.field_name] | [.``'$elem$'``] | [.``'$key$'``] | [.``'$value$'``] )* ]; ``-- (Note: Hive ``1``.x.x and ``0``.x.x only. See ``"Hive 2.0+: New Syntax"` `below)
描述列统计:
DESCRIBE FORMATTED [db_name.]table_name column_name; -- (Note: Hive ``0.14``.``0` `and later)DESCRIBE FORMATTED [db_name.]table_name column_name PARTITION (partition_spec); -- (Note: Hive ``0.14``.``0` `to ``1``.x.x) ``-- (see ``"Hive 2.0+: New Syntax"` `below)
描述分区:
DESCRIBE [EXTENDED|FORMATTED] table_name[.column_name] PARTITION partition_spec; ``-- (Note: Hive ``1``.x.x and ``0``.x.x only. See ``"Hive 2.0+: New Syntax"` `be
6.2DML
2.1 Load data
在将数据加载到表中时,Hive 不执行任何转换。Load 操作是纯复制/移动操作,仅将数据文件移动到与 Hive 表对应的位置。
LOAD DATA [LOCAL] INPATH ``'filepath'` `[OVERWRITE] INTO TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)]LOAD DATA [LOCAL] INPATH ``'filepath'` `[OVERWRITE] INTO TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)] [INPUTFORMAT ``'inputformat'` `SERDE ``'serde'``] (``3.0` `or later)
- filepath 可以是绝对路径也可以是相对路径,也可以是一个 URI;
- 加载到目标可以是一个表或一个分区。如果是分区表,则必须制定所有分区列的值来确定加载特定分区;
- filepath 可以是文件,也可以是目录;
- 制定 LOCAL 可以加载本地文件系统,否则默认为 HDFS;
- 如果使用了 OVERWRITE,则原内容将被删除;否则,将直接追加数据。
Hive 3.0 开始支持 Load 操作。
举例子:
CREATE TABLE tab1 (col1 ``int``, col2 ``int``) PARTITIONED BY (col3 ``int``) STORED AS ORC;LOAD DATA LOCAL INPATH ``'filepath'` `INTO TABLE tab1;
2.2 Insert data
将查询数据插入到 Hive 表中。
-- 标准语法:INSERT OVERWRITE TABLE tablename1 [PARTITION (partcol1=val1, partcol2=val2 ...) [IF NOT EXISTS]] select_statement1 FROM from_statement;INSERT INTO TABLE tablename1 [PARTITION (partcol1=val1, partcol2=val2 ...)] select_statement1 FROM from_statement;-- Hive 扩展(多表插入模式):FROM from_statementINSERT OVERWRITE TABLE tablename1 [PARTITION (partcol1=val1, partcol2=val2 ...) [IF NOT EXISTS]] select_statement1[INSERT OVERWRITE TABLE tablename2 [PARTITION ... [IF NOT EXISTS]] select_statement2][INSERT INTO TABLE tablename2 [PARTITION ...] select_statement2] ...;FROM from_statementINSERT INTO TABLE tablename1 [PARTITION (partcol1=val1, partcol2=val2 ...)] select_statement1[INSERT INTO TABLE tablename2 [PARTITION ...] select_statement2][INSERT OVERWRITE TABLE tablename2 [PARTITION ... [IF NOT EXISTS]] select_statement2] ...;-- Hive 扩展 (动态分区插入模式):INSERT OVERWRITE TABLE tablename PARTITION (partcol1[=val1], partcol2[=val2] ...) select_statement FROM from_statement;INSERT INTO TABLE tablename PARTITION (partcol1[=val1], partcol2[=val2] ...) select_statement FROM from_statement;
- INSERT OVERWRITE 将覆盖在表或分区的任何现有数据;
- INSERT INTO将追加到表或分区,保留原有数据不变;
- 插入目标可以是一个表或分区。如果是分区表,则必须由设定所有分区列的值来指定表的特定分区;
- 可以在同一个查询中指定多个INSERT子句(也称为多表插入)。多表插入可使数据扫描所需的次数最小化。通过对输入数据只扫描一次(并应用不同的查询操作符),Hive可以将数据插入多个表中;
- 如果给出分区列值,我们将其称为静态分区,否则就是动态分区;
2.3 Export data
将查询数据写入到文件系统中。
-- 标准语法:INSERT OVERWRITE [LOCAL] DIRECTORY directory1 [ROW FORMAT row_format] [STORED AS file_format] (Note: Only available starting with Hive 0.11.0) SELECT ... FROM ...-- Hive 扩展 (多表插入):FROM from_statementINSERT OVERWRITE [LOCAL] DIRECTORY directory1 select_statement1[INSERT OVERWRITE [LOCAL] DIRECTORY directory2 select_statement2] ...row_format : DELIMITED [FIELDS TERMINATED BY char [ESCAPED BY char]] [COLLECTION ITEMS TERMINATED BY char] [MAP KEYS TERMINATED BY char] [LINES TERMINATED BY char] [NULL DEFINED AS char] (Note: Only available starting with Hive 0.13)
- 目录可以是一个完整的 URI;
- 使用 LOCAL,可以将数据写入到本地文件系统的目录上;
- 写入文件系统的数据被序列化为由 ^A 做列分割符,换行做行分隔符的文本。如果任何列都不是原始类型(而是 MAP、ARRAY、STRUCT、UNION),则这些列被序列化为 JSON 格式;
- 可以在同一查询中,INSERT OVERWRITE到目录,到本地目录和到表(或分区);
- INSERT OVERWRITE 语句是 Hive 提取大量数据到 HDFS 文件目录的最佳方式。Hive 可以从 map-reduce 作业中的并行写入 HDFS 目录;
2.4 Insert values
直接从 SQL 将数据插入到表中。
--标准语法:INSERT INTO TABLE tablename [PARTITION (partcol1[=val1], partcol2[=val2] ...)] VALUES values_row [, values_row ...]-- 此处的values_row is:-- ( value [, value ...] )-- 此处的value或者是NULL或者是任何有效的sql表达式。
- 在 VALUES 子句中列出的每一行插入到表 tablename 中;
- 以 INSERT … SELECT 同样的方式,来支持动态分区。
- 不支持 INSERT INTO VALUES 子句将数据插入复杂的数据类型(数组、映射、结构、联合)列中。
2.5 Update
UPDATE tablename SET column = value [, column = value ...] [WHERE expression]
- 被引用的列必须是被更新表中的列;
- 设置的值必须是 Hive Select 子句中支持的表达式。算术运算符,UDF,转换,文字等,是支持的,子查询是不支持的;
- 只有符合 WHERE 子句的行才会被更新;
- 分区列不能被更新;
- 分桶列不能被更新;
2.6 Delete
DELETE FROM tablename [WHERE expression]
- 只有符合WHERE子句的行会被删除。
2.7 Merge
-- 标准语法:MERGE INTO <target table> AS T USING <source expression/table> AS SON <boolean expression1>WHEN MATCHED [AND <boolean expression2>] THEN UPDATE SET <set clause list>WHEN MATCHED [AND <boolean expression3>] THEN DELETEWHEN NOT MATCHED [AND <boolean expression4>] THEN INSERT VALUES<value list>
- Merge 允许根据与源表 Join 的结果对目标表执行操作;
- on 语句会对源与目标进行检查,此计算开销很大;
6.3.select
6.3.1、HIVE SQL 语法
SELECT [ALL | DISTINCT] select_expr, select_expr, ...
FROM tablename
[WHERE where_condition] --where条件语句
[GROUP BY col_list] --group by 分组语句
[ORDER BY col_list] --order by 排序语句
[CLUSTER BY col_list | [DISTRIBUTE BY col_list] [SORT BY col_list] ]
[LIMIT number]
大家都知道hive底层跑的是mapreduce程序,在执行hql语句时,mapreduce会解析hql产生执行逻辑,生成结果。
MapReduce引擎执行计划
Map阶段:
1、执行from加载,进行表的查找与加载。
2、执行where过滤,进行条件过滤与筛选。
3、执行select查询,进行输出项的筛选。
4、执行group by分组,描述了分组后需要计算的函数。
5、map端文件合并,map端本地溢出写文件的合并操作,每个map最终形成一个临时文件。然后按列映射到对应的Reduce阶段:
Reduce阶段:
1、group by:对map端发送过来的数据进行分组并进行计算。
2、select:最后过滤列用于输出结果。
3、limit排序后进行结果输出到HDFS文件。
注意,以上顺序不是绝对的,会根据语句的不同,有所调整。
可以通过执行计划查看大概顺序
explain sql 语句
如:explain select * from tablename 即可查看执行计划
6.3.2、Hive Join
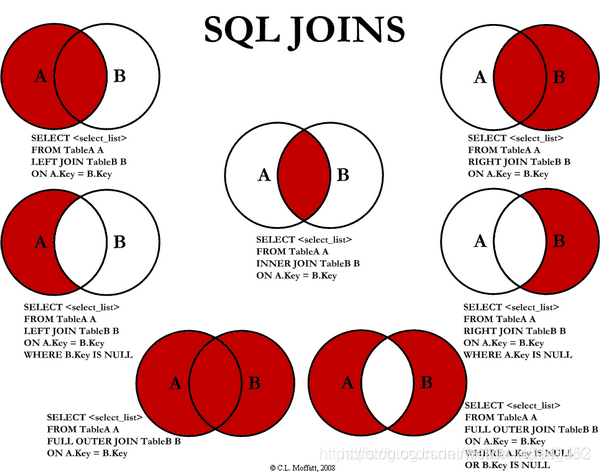
Hive只支持等连接、外连接。Hive不支持非相等的Join条件,不过我们可以通过其他方式实现,如left outer join,因为它很难在map/reduce job实现这样的条件。建表对Join操作进行试验,建表语句和数据如下:
2.0.create table
//我们创建三个表用来测试
CREATE TABLE testA(
id INT COMMENT 'id',
name STRING COMMENT '姓名',
age INT COMMENT '年龄'
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
CREATE TABLE testB(
id INT COMMENT 'id',
name STRING COMMENT '姓名',
age INT COMMENT '年龄'
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
CREATE TABLE testC(
id INT COMMENT 'id',
name STRING COMMENT '姓名',
age INT COMMENT '年龄'
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
INSERT INTO TABLE testA VALUES (1,"唐三",20);
INSERT INTO TABLE testA VALUES (2,"石昊",21);
INSERT INTO TABLE testA VALUES (5,"林动",18);
INSERT INTO TABLE testA VALUES (6,"萧炎",17);
INSERT INTO TABLE testB VALUES (1,"周元",19);
INSERT INTO TABLE testB VALUES (3,"李明",22);
INSERT INTO TABLE testB VALUES (4,"叶修",23);
INSERT INTO TABLE testB VALUES (5,"吴邪",17);
INSERT INTO TABLE testC VALUES (1,"孙无",24);
INSERT INTO TABLE testC VALUES (2,"沙沙",25);
INSERT INTO TABLE testC VALUES (6,"唐四",21);
INSERT INTO TABLE testC VALUES (7,"叶凡",20);
2.1、两表的inner join
SELECT
a.id id,
a.name aname,
a.age aage,
--b.id bid,
b.name bname,
b.age bage
FROM
testa a
INNER JOIN
testb b
ON a.id = b.id
结果:
1 唐三 20 周元 19
5 林动 18 吴邪 17
2.2、外连接:left join 和 right join
--left join
SELECT
a.id id,
a.name aname,
a.age aage,
b.name bname,
b.age bage
FROM
testa a
LEFT JOIN
testb b
ON a.id = b.id
结果:
1 唐三 20 周元 19
2 石昊 21 NULL NULL
5 林动 18 吴邪 17
6 萧炎 17 NULL NULL
--right join
SELECT
a.id id,
a.name aname,
a.age aage,
b.name bname,
b.age bage
FROM
testa a
RIGHT JOIN
testb b
ON a.id = b.id
结果:
1 唐三 20 周元 19
NULL NULL NULL 李明 22
NULL NULL NULL 叶修 23
5 林动 18 吴邪 17
2.3、 实现非等值连接
查询testa有,testb没有,用 left join + is null
查询testa没有,testb有,用 right join + is null
--查询testa有,testb没有
SELECT
a.id aid,
a.name aname,
a.age aage,
b.id bid,
b.name bname,
b.age bage
FROM
testa a
LEFT JOIN
testb b
ON
a.id = b.id
WHERE
b.id IS NULL
结果:
2 石昊 21 NULL NULL NULL
6 萧炎 17 NULL NULL NULL
--查询testa没有,testb有。同理,如上把b.id改为a.id即可。
注意下面的Sql和上面的Sql结果是不一样的:
SELECT
a.id aid,
a.name aname,
a.age aage,
b.id bid,
b.name bname,
b.age bage
FROM
testa a
LEFT JOIN
testb b
ON
a.id = b.id
AND
b.id IS NULL
结果:
1 唐三 20 NULL NULL NULL
2 石昊 21 NULL NULL NULL
5 林动 18 NULL NULL NULL
6 萧炎 17 NULL NULL NULL
2.4、多表join
--笛卡尔积的SQL
select
a.id id,
a.name aname,
a.age aage,
b.name bname,
b.age bage
from testa a
inner join testb b;
简单应用:使用join计算新增用户
--计算新增用户
select count(1) from
(select uid from user_table where dt='20200506' group by uid) a
right join
(select uid from user_table where dt='20200507' group by uid) b
on b.uid=a.uid
where a.uid is null;
2.5、使用join时要避免的查询操作
--笛卡尔积的SQL
select
a.id id,
a.name aname,
a.age aage,
b.name bname,
b.age bage
from testa a
inner join testb b;
设置 set hive.mapred.mode=strict 这个参数,可以限制以下情况:
1)限制执行可能形成笛卡尔积的SQL;
2)partition表使用时不加分区;
3)order by全局排序的时候不加limit的情况;
取消限制:set hive.mapred.mode=nonstrict
2.6、full outer join
full outer join意思是包括两个表join的结果。左边有、右边NULL,右边有、左边NULL。其结果等价于left join union right join
select
a.id id,
a.name aname,
a.age aage,
b.name bname,
b.age bage
from testa a
full outer join testb b
on a.id = b.id
结果:
1 唐三 20 周元 19
6 萧炎 17 NULL NULL
NULL NULL NULL 李明 22
5 林动 18 吴邪 17
NULL NULL NULL 叶修 23
2 石昊 21 NULL NULL
使用union 实现 full outer join效果
select
a.id id,
a.name aname,
a.age aage,
b.name bname,
b.age bage
from testa a
LEFT JOIN testb b
on a.id = b.id
UNION
select
a.id id,
a.name aname,
a.age aage,
b.name bname,
b.age bage
from testa a
RIGHT JOIN testb b
on a.id = b.id
2.7、map端的join操作
当大表 join 小表时,小表没有运行Map,两个表连在一起也没有用Reduce,直接跳过,将小表数据刷入内存,默认是自动mapjoin。
hive 默认是开启 MapJoin/*+ MAPJOIN? */
//将小表刷入内存中,默认是true
set hive.auto.convert.join=true
set hive.ignore.mapjoin.hint=true
//刷入内存表的大小(字节),根据自己的数据集加大
set hive.mapjoin.smalltable.filesize=2000000
不开启MapJoin,可以按照如下设置
set hive.auto.convert.join=false;
set hive.ignore.mapjoin.hint=false;
在设置成false 或 true时,可以手动的 /*+ MAPJOIN? **/
select /*+ MAPJOIN(c) */ * from user_table_a a
inner join user_table_b b
on a.id=b.id
where a.dt='20200507'
注意:map join 类似于 MapReduce中的semijoin。
当把set hive.auto.convert.join设置成false时,可以手动的加 /*+ MAPJOIN? ***/外连接不允许用mapjoin ,内连接可以用mapjoin / *+ MAPJOIN? */把c放到内存。
7.Hive 的内置函数
不需要强记,只需要有一个大致的印象就行,需要时再去查找。
Hive 的内置函数包括:
- 数学函数(Mathematical Functions);
- 集合函数(Collection Functions);
- 类型转换函数(Type Conversion Functions);
- 日期函数(Date Functions);
- 条件函数(Conditional Functions);
- 字符串函数(String Functions);
- 聚合函数(Aggregate Functions);
- 表生成函数(Table-Generating Functions);
当然,Hive 还在一直更新,有需要的话,可以去官网去查看最新的函数。
1.Mathematical Functions
| 「Name (Signature)」 | 「Description」 |
|---|---|
| round(DOUBLE a) | Returns the rounded BIGINT value of a.「返回对 a 四舍五入的 BIGINT 值」 |
| round(DOUBLE a, INT d) | Returns a rounded to d decimal places.「返回 DOUBLE 型 d 的保留 n 位小数的 DOUBLE 型的近似值」 |
| bround(DOUBLE a) | Returns the rounded BIGINT value of a using HALF_EVEN rounding mode (as of Hive 1.3.0, 2.0.0). Also known as Gaussian rounding or bankers’ rounding. Example: bround(2.5) = 2, bround(3.5) = 4. 「银行家舍入法(14:舍,69:进,5->前位数是偶:舍,5->前位数是奇:进)」 |
| bround(DOUBLE a, INT d) | Returns a rounded to d decimal places using HALF_EVEN rounding mode (as of Hive 1.3.0, 2.0.0). Example: bround(8.25, 1) = 8.2, bround(8.35, 1) = 8.4. 「银行家舍入法,保留 d 位小数」 |
| floor(DOUBLE a) | Returns the maximum BIGINT value that is equal to or less than a「向下取整,最数轴上最接近要求的值的左边的值 如:6.10->6 -3.4->-4」 |
| ceil(DOUBLE a), ceiling(DOUBLE a) | Returns the minimum BIGINT value that is equal to or greater than a.「求其不小于小给定实数的最小整数如:ceil(6) = ceil(6.1)= ceil(6.9) = 6」 |
| rand(), rand(INT seed) | Returns a random number (that changes from row to row) that is distributed uniformly from 0 to 1. Specifying the seed will make sure the generated random number sequence is deterministic.「每行返回一个 DOUBLE 型随机数 seed 是随机因子」 |
| exp(DOUBLE a), exp(DECIMAL a) | Returns ea where e is the base of the natural logarithm. Decimal version added in Hive 0.13.0.「返回 e 的 a 幂次方,a 可为小数」 |
| ln(DOUBLE a), ln(DECIMAL a) | Returns the natural logarithm of the argument a. Decimal version added in Hive 0.13.0.「以自然数为底 d 的对数,a 可为小数」 |
| log10(DOUBLE a), log10(DECIMAL a) | Returns the base-10 logarithm of the argument a. Decimal version added in Hive 0.13.0.「以 10 为底 d 的对数,a 可为小数」 |
| log2(DOUBLE a), log2(DECIMAL a) | Returns the base-2 logarithm of the argument a. Decimal version added in Hive 0.13.0.「以 2 为底数 d 的对数,a 可为小数」 |
| log(DOUBLE base, DOUBLE a)log(DECIMAL base, DECIMAL a) | Returns the base-base logarithm of the argument a. Decimal versions added in Hive 0.13.0.「以 base 为底的对数,base 与 a 都是 DOUBLE 类型」 |
| pow(DOUBLE a, DOUBLE p), power(DOUBLE a, DOUBLE p) | Returns ap.「计算 a 的 p 次幂」 |
| sqrt(DOUBLE a), sqrt(DECIMAL a) | Returns the square root of a. Decimal version added in Hive 0.13.0.「计算 a 的平方根」 |
| bin(BIGINT a) | Returns the number in binary format.「计算二进制 a 的 STRING 类型,a 为 BIGINT 类型」 |
| hex(BIGINT a) hex(STRING a) hex(BINARY a) | If the argument is an INT or binary, hex returns the number as a STRING in hexadecimal format. Otherwise if the number is a STRING, it converts each character into its hexadecimal representation and returns the resulting STRING. 「计算十六进制 a 的 STRING 类型,如果 a 为 STRING 类型就转换成字符相对应的十六进制」 |
| unhex(STRING a) | Inverse of hex. Interprets each pair of characters as a hexadecimal number and converts to the byte representation of the number. (BINARY version as of Hive 0.12.0, used to return a string.)「hex 的逆方法」 |
| conv(BIGINT num, INT from_base, INT to_base), conv(STRING num, INT from_base, INT to_base) | Converts a number from a given base to another.「将 BIGINT/STRING 类型的 num 从 from_base 进制转换成 to_base 进制」 |
| abs(DOUBLE a) | Returns the absolute value.「计算 a 的绝对值」 |
| pmod(INT a, INT b), pmod(DOUBLE a, DOUBLE b) | Returns the positive value of a mod b.「a 对 b 取模」 |
| sin(DOUBLE a), sin(DECIMAL a) | Returns the sine of a (a is in radians). Decimal version added in Hive 0.13.0.「求 a 的正弦值」 |
| asin(DOUBLE a), asin(DECIMAL a) | Returns the arc sin of a if -1<=a<=1 or NULL otherwise. Decimal version added in Hive 0.13.0.「求反正弦值」 |
| cos(DOUBLE a), cos(DECIMAL a) | Returns the cosine of a (a is in radians). Decimal version added in Hive 0.13.0.「求余弦值」 |
| acos(DOUBLE a), acos(DECIMAL a) | Returns the arccosine of a if -1<=a<=1 or NULL otherwise. Decimal version added in Hive 0.13.0.「求反余弦值」 |
| tan(DOUBLE a), tan(DECIMAL a) | Returns the tangent of a (a is in radians). Decimal version added in Hive 0.13.0.「求正切值」 |
| atan(DOUBLE a), atan(DECIMAL a) | Returns the arctangent of a. Decimal version added in Hive 0.13.0.「求反正切值」 |
| degrees(DOUBLE a), degrees(DECIMAL a) | Converts value of a from radians to degrees. Decimal version added in Hive 0.13.0.「奖弧度值转换角度值」 |
| radians(DOUBLE a), radians(DOUBLE a) | Converts value of a from degrees to radians. Decimal version added in Hive 0.13.0.「将角度值转换成弧度值」 |
| positive(INT a), positive(DOUBLE a) | Returns a.**返回 a ** |
| negative(INT a), negative(DOUBLE a) | Returns -a.「返回 a 的相反数」 |
| sign(DOUBLE a), sign(DECIMAL a) | Returns the sign of a as ‘1.0’ (if a is positive) or ‘-1.0’ (if a is negative), ‘0.0’ otherwise. The decimal version returns INT instead of DOUBLE. Decimal version added in Hive 0.13.0.「如果 a 是正数则返回 1.0,是负数则返回 -1.0,否则返回 0.0」 |
| e() | Returns the value of e.「数学常数 e」 |
| pi() | Returns the value of pi.「数学常数 pi」 |
| factorial(INT a) | Returns the factorial of a (as of Hive 1.2.0). Valid a is [0…20]. 「求 a 的阶乘」 |
| cbrt(DOUBLE a) | Returns the cube root of a double value (as of Hive 1.2.0). 「求 a 的立方根」 |
| shiftleft(TINYINT|SMALLINT|INT a, INT b)shiftleft(BIGINT a, INT b) | Bitwise left shift (as of Hive 1.2.0). Shifts a b positions to the left.Returns int for tinyint, smallint and int a. Returns bigint for bigint a.「按位左移」 |
| shiftright(TINYINT|SMALLINT|INT a, INTb)shiftright(BIGINT a, INT b) | Bitwise right shift (as of Hive 1.2.0). Shifts a b positions to the right.Returns int for tinyint, smallint and int a. Returns bigint for bigint a.「按拉右移」 |
| shiftrightunsigned(TINYINT|SMALLINT|INTa, INT b),shiftrightunsigned(BIGINT a, INT b) | Bitwise unsigned right shift (as of Hive 1.2.0). Shifts a b positions to the right.Returns int for tinyint, smallint and int a. Returns bigint for bigint a.「无符号按位右移(<<<)」 |
| greatest(T v1, T v2, …) | Returns the greatest value of the list of values (as of Hive 1.1.0). Fixed to return NULL when one or more arguments are NULL, and strict type restriction relaxed, consistent with “>” operator (as of Hive 2.0.0). 「求最大值」 |
| least(T v1, T v2, …) | Returns the least value of the list of values (as of Hive 1.1.0). Fixed to return NULL when one or more arguments are NULL, and strict type restriction relaxed, consistent with “<” operator (as of Hive 2.0.0). 「求最小值」 |
8.Reference
- LanguageManual DDL
- LanguageManual DML