文章目录
Sink
kafka
package com.atguigu.apitest.sinkstudy
import com.atguigu.apitest.SensorReading
import org.apache.flink.api.common.serialization.SimpleStringSchema
import org.apache.flink.streaming.api.functions.sink.filesystem.StreamingFileSink
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer011
object kafka_sinkstudy {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
val inputStream = env.readTextFile("D:\\Flink\\20-Flink【www.hoh0.com】\\FlinkTutorial\\src\\main\\resources\\sensor.txt")
val dataStream : DataStream[String] = inputStream
.map(
data =>{
val dataArray = data.split(",")
SensorReading(dataArray(0),dataArray(1).toLong,dataArray(2).toDouble).toString
})
dataStream.addSink(new FlinkKafkaProducer011[String]("hadoop103:9092","sinkTest",new SimpleStringSchema()))
env.execute("sink study job")
}
}

Window API
窗口(window)

?一般真实的流都是无界的,怎样处理无界的数据?
?可以把无限的数据流进行切分,得到有限的数据集进行处理 ―― 也就是得到有界流
?窗口(window)就是将无限流切割为有限流的一种方式,它会将流数据分发到有限大小的桶(bucket)中进行分析
滚动窗口(Tumbling Windows)

- 将数据依据固定的窗口长度对数据进行切分
- 时间对齐,窗口长度固定,没有重叠
将数据流按固定的时间切开,不同部分之间没有重叠。
滑动窗口(Sliding Windows)
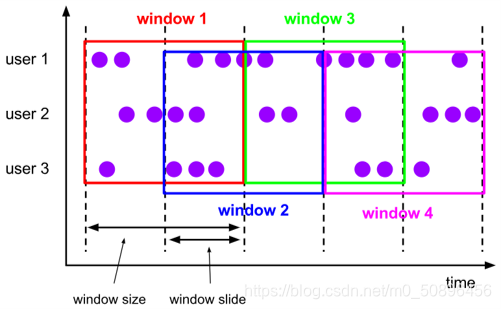
滚动窗口的长度同样是固定的,但是可以存在重叠。
滑动窗口由固定的窗口长度和滑动间隔组成。
会话窗口(Session Windows)

会话窗口没有规定的长度,只要一段时间内没有接收到新的数据就会生成新的窗口,此窗口没有固定的时间。
Window API
窗口分配器――window()方法
我们可以用 .window() 来定义一个窗口,然后基于这个 window 去做一些聚合或者其它处理操作。注意 window () 方法必须在 keyBy 之后才能用。
Flink 提供了更加简单的 .timeWindow 和 .countWindow 方法,用于定义时间窗口和计数窗口。
val minTemPerWindow = dataStream
.map(data => (data.id,data.temperature))
.keyBy(_._1)
.timeWindow(Time.seconds(15))
.reduce((data1,data2) => (data1._1,data2._2.min(data2._2)))
窗口分配器(window assigner)
?window() 方法接收的输入参数是一个 WindowAssigner
?WindowAssigner 负责将每条输入的数据分发到正确的 window 中
?Flink 提供了通用的 WindowAssigner
滚动窗口(tumbling window)
滑动窗口(sliding window)
会话窗口(session window)
全局窗口(global window)
val minTemPerWindow = dataStream
.map(data => (data.id,data.temperature))
.keyBy(_._1)
//.timeWindow(Time.seconds(15))//TODO 滚动时间窗口
//.timeWindow(Time.seconds(15),Time.seconds(5))//TODO 滑动时间窗口
.window(EventTimeSessionWindows.withGap(Time.minutes(10)))//TODO 会话窗口 时间为窗口失效时间
.reduce((data1,data2) => (data1._1,data2._2.min(data2._2)))
.countWindow(5) // TODO 滚动计数窗口
.countWindow(10,2) //TODO 滑动计数窗口
窗口函数(window function)
?window function 定义了要对窗口中收集的数据做的计算操作
?可以分为两类
增量聚合函数(incremental aggregation functions)
?每条数据到来就进行计算,保持一个简单的状态
?ReduceFunction, AggregateFunction
全窗口函数(full window functions)
?先把窗口所有数据收集起来,等到计算的时候会遍历所有数据
?ProcessWindowFunction
其它可选API
?.trigger() ―― 触发器
定义 window 什么时候关闭,触发计算并输出结果
?.evictor() ―― 移除器
定义移除某些数据的逻辑
?.allowedLateness() ―― 允许处理迟到的数据
?.sideOutputLateData() ―― 将迟到的数据放入侧输出流
?.getSideOutput() ―― 获取侧输出流
问题记录

解决方法
1.添加水位线
2.删去第三行
四、flink中的时间语义和watermark
时间语义
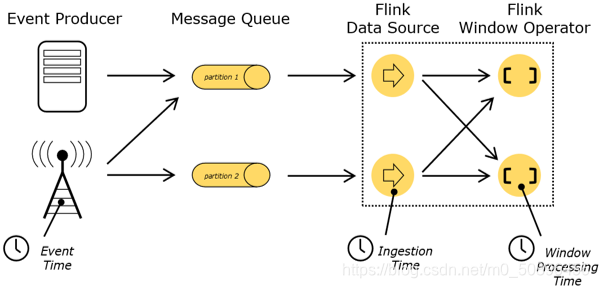
?Event Time:事件创建的时间
?Ingestion Time:数据进入Flink的时间
?Processing Time:执行操作算子的本地系统时间,与机器相关
水位线(WaterMark)
一个延迟的机制。
watermark就是事件时间。
?Watermark 是一种衡量 Event Time 进展的机制,可以设定延迟触发
?Watermark 是用于处理乱序事件的,而正确的处理乱序事件,通常用Watermark 机制结合 window 来实现;
?数据流中的 Watermark 用于表示 timestamp 小于 Watermark 的数据,都已经到达了,因此,window 的执行也是由 Watermark 触发的。
?watermark 用来让程序自己平衡延迟和结果正确性
flink处理乱序数据的三重保证:
1.watermark可以设置延迟时间
2.window的allowedLateness方法,可以设置窗口允许处理迟到的数据的时间
3.window的sideOutputLateData方法,可以将迟到的数据写入侧输出流
遇到一个时间戳达到了窗口关闭时间,不应该立刻触发窗口计算,而是等待一段时间,等迟到的数据来了再关闭窗口。
特点

?watermark 是一条特殊的数据记录
?watermark 必须单调递增,以确保任务的事件时间时钟在向前推进,而不是在后退
?watermark 与数据的时间戳相关
传递
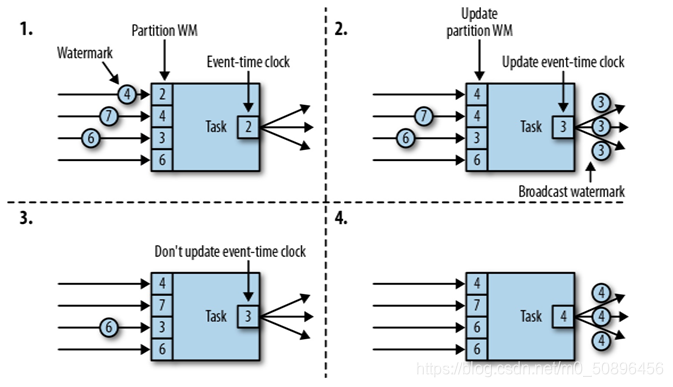
乱序数据的影响
- 当flink以Event Time模式处理数据流时,它会根据数据里的时间戳来处理基于时间的算子
- 由于网络、分布式等原因,会导致乱序数据的产生。
watermark表示之后不会再出现比watermark里面的数值的时间戳更小的数据了。
比如前5s的数据到齐了,后面的数据不会出现5s之前的数据了,这时就可以把窗口关闭了。
如果有不同的上游分区,当前任务会对他们创建的各自的分区watermark,当前任务的时间时间就是最小的那个。
延迟时间一般定义为最大乱序程度。
关窗
必须是时间进展到窗口关闭时间,事件时间语义下就是watermark到达窗口关闭时间
当前最大时间戳 - 延迟时间 = watermark(指的是当前的水位线)
如果现在的watermark大于等于窗口结束时间,就关闭窗口。
如果水位线到达要求的高度(时间),那就关门(不继续放数据进来了)。
使用
一个简单的定义watermark
val dataStream : DataStream[SensorReading] = inputStream
.map(data => {
val dataArray = data.split(",")
SensorReading(dataArray(0),dataArray(1).toLong,dataArray(2).toDouble)
})
.assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor[SensorReading](Time.seconds(10)) {//延迟时间
override def extractTimestamp(element: SensorReading): Long = element.timestamp*1000L //提取时间戳的方法
})//处理乱序数据
val resultStream = dataStream
.keyBy("id")
.timeWindow(Time.seconds(15),Time.seconds(5))
.allowedLateness(Time.minutes(1))//到时间后进行一次计算,输出结果,但是不关闭窗口,直到延迟时间也过去之后才关闭
我:延迟了一分钟!数据肯定都来了吧。
杠精:如果1分钟了还有2秒的数据来呢?
我:。。。
我:我还有办法!
.sideOutputLateData(new OutputTag[SensorReading]("late"))//将数据丢到侧输出流中
手动滑稽。
丢进侧输出流的数据也可以取出
resultStream.getSideOutput(new OutputTag[SensorReading]("late"))
watermark延迟时间的设置,一般要根据数据的乱序情况来定,通常设置成最大乱序程度
如果按照最大乱序程度定,那么就能保证所有窗口的数据都是正确的。
要权衡正确性和实时性的话,可以不按照最大乱序程度,而是给一个相对较小的watermark延迟
