消息队列的两种模式
1、点对点,一条消息只能被一个消费者所消费
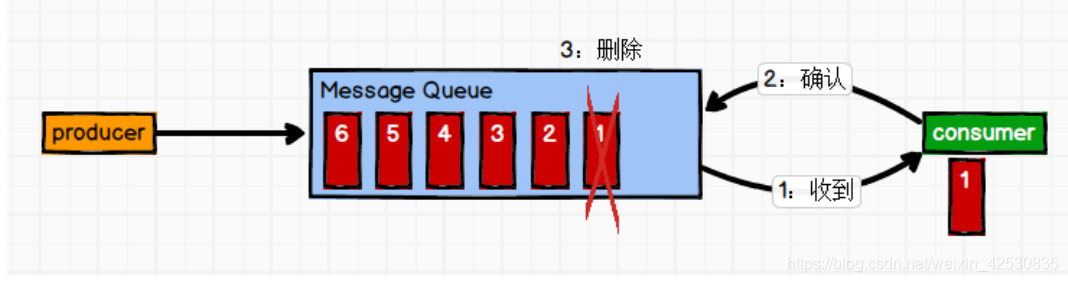
2、发布订阅
生产者将消息发布后,订阅的消费者会拿到该消息
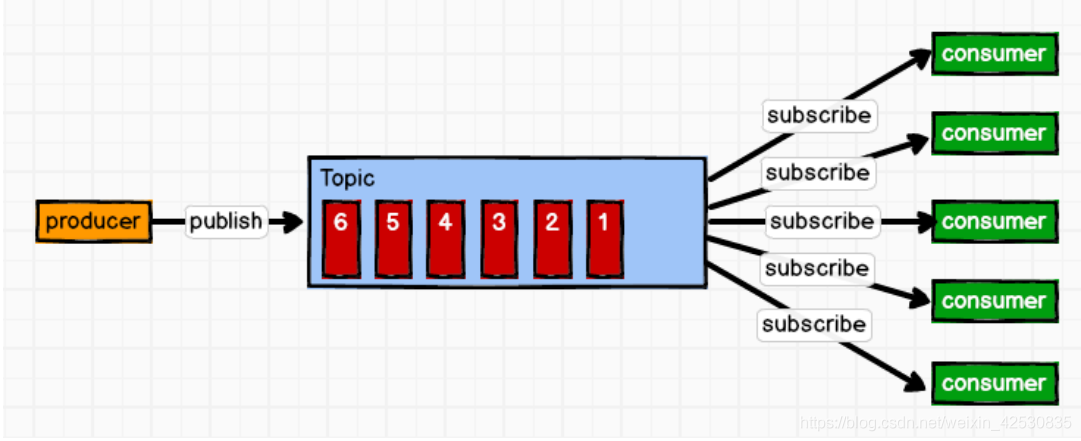
发布订阅模式分为推模式和拉模式两种:
1、推模式(producer将消息推送到可用的consumer中)
缺点:不能根据每个消费者的消费能力来选择性推送
2、拉模式(producer有消息后,consumer从topic中根据自己的消费能力拉取消息)
缺点:consumer需要维持一个长链接,一直查看topic中有没有新的消息,没有数据时会导致空轮询
? topic中要存一个消费者队列
针对这一点,kafka在拉取完数据后,还会获取到一个timeout参数,如果之后没有数据,会等待相应的时间。
Kafka架构
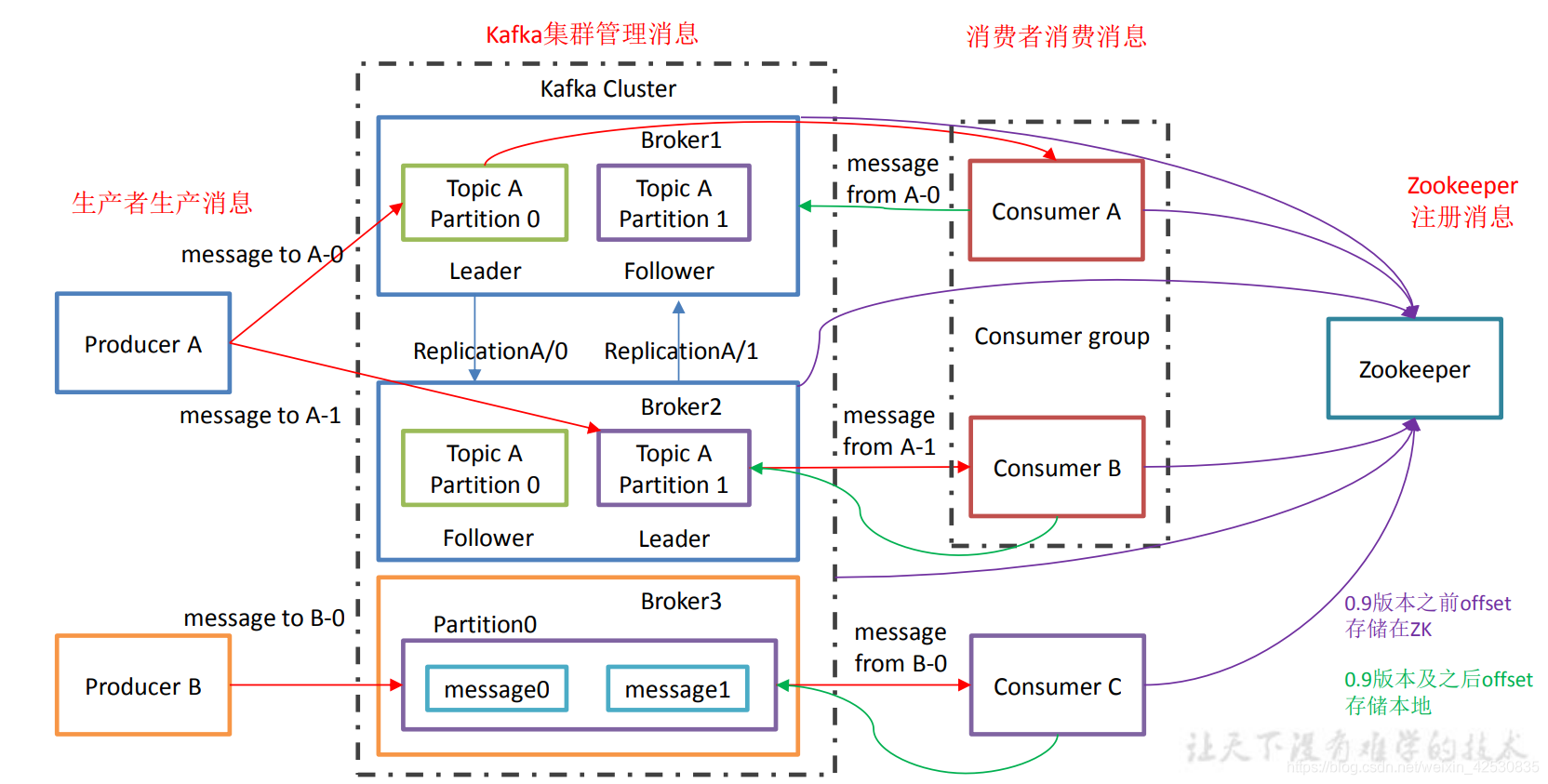
broker:就是一个kafka服务器,一个broker中有多个topic
topic:producer和consumer从topic中拿消息,topic相当于将消息进行了分类
partition:消息分区,将一个topic分为多个分区经行管理
注意: kafka中的leader和follower是针对partition来说的。一个partition的leader用来做数据的读写,而follower的作用只能做数据的备份。
replication:partition的副本,做数据备份
consumerGroup:消费者组,由多个消费者组成,一个partition的内容只能由一个组中的一个消费者消费,但是可以消费多个topic,消费组与组之间互不关联。
zookeeper:zk中存储kafka的集群信息,和消费者的offset(也就是consumer上次消费到的位置信息,类似计数器,保证consumer挂了后,再次启动仍继续消费),0.9版本之后offset改为存储在kafka中,logs目录下
生产者可靠性、一致性的问题
一、可靠性,确保数据从producer 发送到partititon中
为了保证 producer 发送的数据,能可靠的发送到指定的 topic,topic 的每个 partition 收到producer 发送的数据后,都需要向 producer 发送 ack(acknowledgement 确认收到),如果producer 收到 ack,就会进行下一轮的发送,否则重新发送数据。
如何保证重发时候的幂等性
这时,如果producer发了一条消息后没有收到ACK,但是partion中已经将消息保存了,这时候它再重发的话导致消息重复了。
为了保证它的幂等性,kafka在发送消息时会携带一个PID 和 sequence NUM, 会和partition中的sequence NUM进行比较,如果一致,说明消息已经保存成功了,没必要重发,会返回给producer一个 ACK应答。
应答机制
1、半数以上follower完成同步后,向leader发送ack
2、全部完成同步才会发送ack
kafka采用第二种,第一种会造成大量的数据冗余。
ISR队列(正在存活的副本)
如果采用第二种机制,那么假设现在只有follower久久没有同步,那么leader只能一直等下去,直到完成同步。
对此,leader维护了一个ISR队列,当ISR中的follower长时间没有同步,会将他踢出ISR队列。
ISR队列筛选follower的策略
1、根据同步时间的快慢(默认)
2、根据follower中数据条数的多少
生产者ACK参数配置
0:broker接受到数据后,立即返回ack
1:当partititon中leader写入磁盘后返回ack
-1:等leader和follower都写入磁盘后返回ack,但当正要返回ack前leader发生故障,那么producer又会发送一遍消息,可能会造成数据重复
二、 一致性,确保消费数据的一致性
消费者只能获取到HW前的数据,之后的不可见
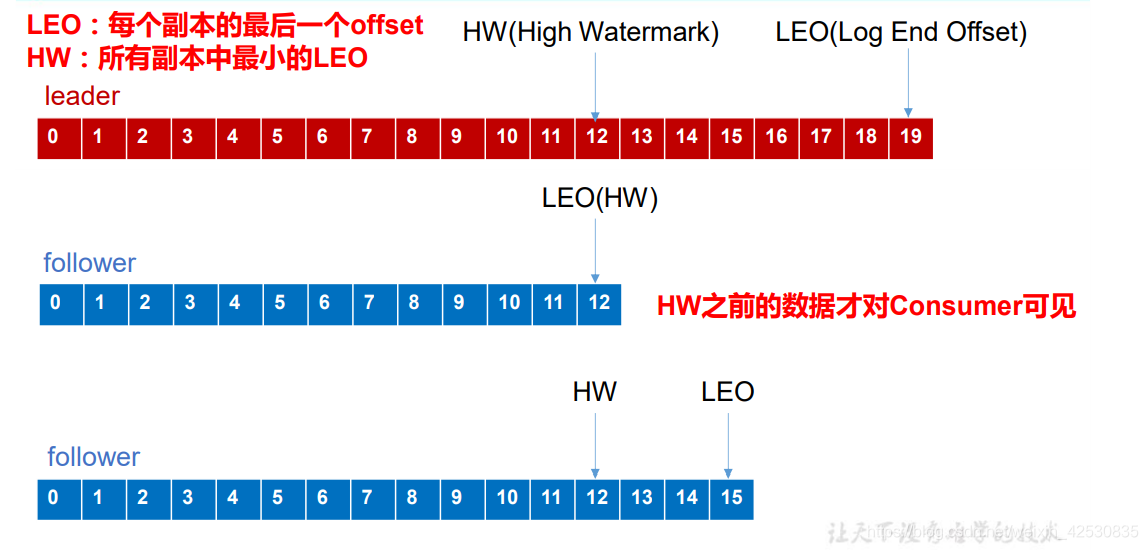
(1)、当follower故障,会将他提出ISR,等follower恢复后,从HW高水位处截掉后面的数据,然后从leader处同步,当follower的LEO>leader的HW后,再将他恢复到ISR中
(2)、当leader故障 ,从ISR中选新的Leader,其他follower从HW处截掉后面的数据,然后再慢慢同步
生产者写入partition策略
1、轮询的方式写入partition
当写入消息时,指定key为null,默认使用轮询的方式写入partition
2、随机策略(不适用)
3、按key写入(key.hash()%分区数)
4、自定义策略
消费者数据分配策略
有关partition具体分配给哪个consumer的问题,kafka的分配策略由两种:
1、RoundRobin
就是将A,B两个消费者订阅的所有partition经过hash后看成一个整体,然后轮询分配
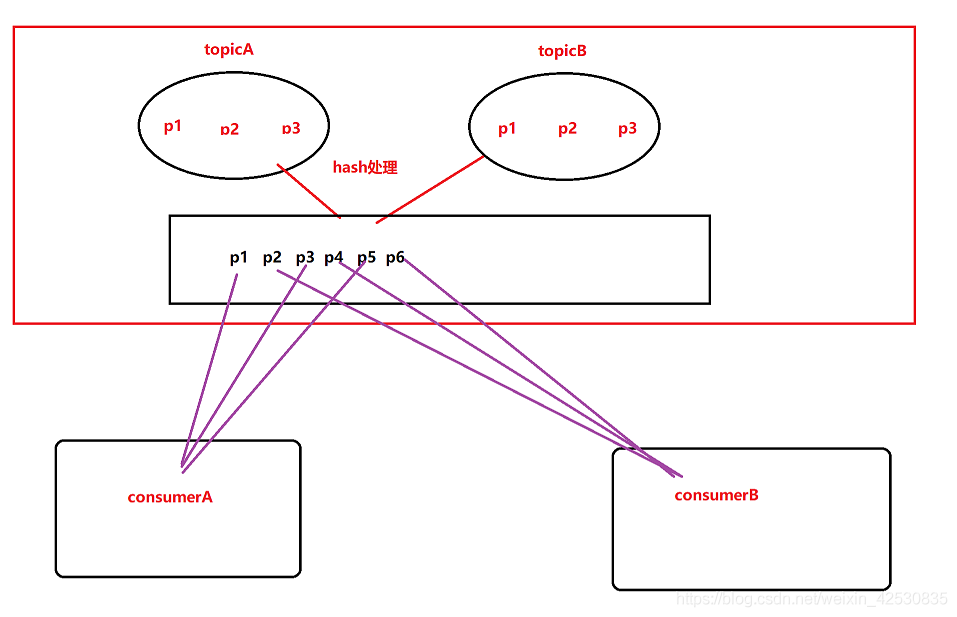
缺点:这样会导致A本来没有订阅topicB,但是却拿到topicB的消息。
2、Range(默认)
前提是要保证当前topic被多个消费者消费了,然后才能分配,这样就不会消费到没有订阅的消息
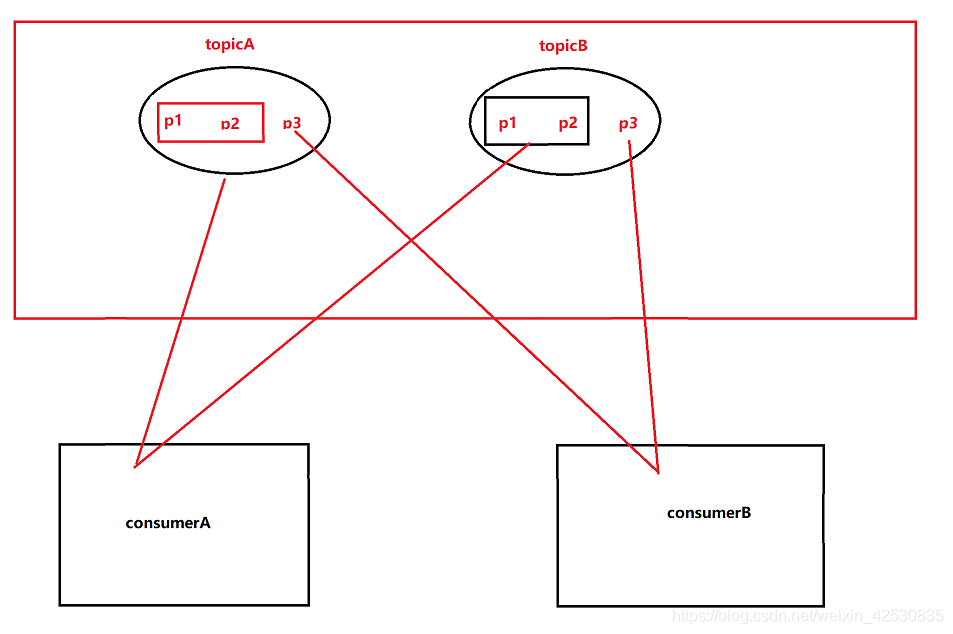
但是这样分配的话也会导致分配到的消息偏差较大。
Kafka读写流程
1、producer写入kafka
- producer从ZK中获取指定partition中的leader(leader负责读写)
- 向leader中写入数据
- ISR队列中的副本开始同步,返回ack
- ack返回producer
2、consumer读取kafka
- consumer从ZK中获取对应leader信息
- 找到对应consumer的offset
- 根据offset从leader中拉取数据
- 提交offset
kafka高效的原因:
1、顺序写磁盘
我们知道kafka中生产者的产生的数据要写到log中,kafka写入的方式是采用顺序写入磁盘的,减少了随机写入时寻址的时间
2、零复制技术
采用DMA直接从操作系统主内存中拿数据,不在经过用户态
脑裂问题
kafka中只有一个控制器controller 负责分区的leader选举,同步broker的新增或删除消息,但有时由于网络问题,可能同时有两个broker认为自己是controller
解决方案:
没当新的controller产生会在zk中生成一个controller epoch标识,并同步给其他broker,这样其他controller发送指令时就会忽略。