(һ)hivesql ��ת��(collect_set)����ת��(explode��posexplode)
https://blog.csdn.net/zhouqi1991i/article/details/91957007
hivesql ��ת������ת��
��ת�к�������collect_set��collect_list
hive��ͨ��ͨ��collect_set��collect_list��������ת��,����collect_listΪ��ȥ��ת��,collect_setΪȥ��ת����
�������ǽ�ͨ��һ��ʵ��������˵��:
����һ��ѧ���ɼ���
CREATE table student_score(
stu_id string comment ��ѧ�š�,
stu_name string comment ��������,
course string comment ����Ŀ��,
score string comment ��������
) comment ��ѧ���ɼ�����;
ѧ��������Ϊ:
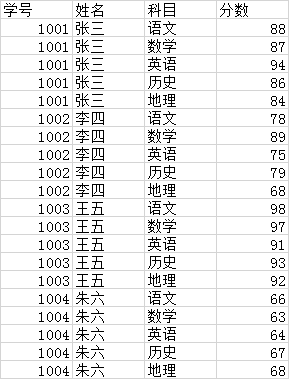
?
���������ݵ��봴���ı�����:
LOAD DATA INPATH :dataPath OVERWRITE INTO TABLE student_score;
����������Ҫ��ÿ��ѧ���Ŀγ̺ͳɼ��ŵ�һ��չʾ,��ÿ��ѧ��ֻ������ʾһ������,��ʱ����ʹ�õ���ת�к���,ʹ���������:
�Cʹ��collect_set����������ת�в�ѯ
SELECT
stu_id,
stu_name,
concat_ws(��,��,collect_set(course)) as course,
concat_ws(��,��,collect_set(score)) as score
from student_score
group by stu_id,stu_name
��ѯ���Ľ��Ϊ:
��� stu_id stu_name course score
1 1001 ���� ����,��ѧ,Ӣ��,��ʷ,���� 88,87,94,86,84
2 1002 ���� ����,��ѧ,Ӣ��,��ʷ,���� 78,89,75,79,68
3 1003 ���� ����,��ѧ,Ӣ��,��ʷ,���� 98,97,91,93,92
4 1004 ���� ����,��ѧ,Ӣ��,��ʷ,���� 66,63,64,67,68
����һ���µ�ѧ����,ʹ��������ת�еĽ������Ϊ��ת�е�����:
CREATE table student_score_new
as
SELECT
stu_id,
stu_name,
concat_ws(��,��,collect_set(course)) as course,
concat_ws(��,��,collect_set(score)) as score
from student_score
group by stu_id,stu_name;
��ת�к�������explode��posexplode
explode��������array��map��ʽ���ֶ�ת�����е���ʽ,��Ȼstring��ʽ���ֶ���ʵҲ����ת��,ֻ��Ҫ��split�������ֶηָ��һ���������ʽ����,�������ǿ��ѱ����е�ÿ����ҵĿ�Ŀ���е���ʽ��ѯ����:
�Cʹ��explode����������ת�в�ѯ
SELECT stu_id,
stu_name,
ecourse
from student_score_new
lateral view explode(split(course,��,��)) cr as ecourse
��ѯ�������:
��� stu_id stu_name ecourse
1 1001 ���� ����
2 1001 ���� ��ѧ
3 1001 ���� Ӣ��
4 1001 ���� ��ʷ
5 1001 ���� ����
6 1002 ���� ����
7 1002 ���� ��ѧ
8 1002 ���� Ӣ��
9 1002 ���� ��ʷ
10 1002 ���� ����
11 1003 ���� ����
12 1003 ���� ��ѧ
13 1003 ���� Ӣ��
14 1003 ���� ��ʷ
15 1003 ���� ����
16 1004 ���� ����
17 1004 ���� ��ѧ
18 1004 ���� Ӣ��
19 1004 ���� ��ʷ
20 1004 ���� ����
���ǵ�������Ҫ��ѯÿ��ѧ���γ̶�Ӧ�ķ���ʱ,ʹ��explode������������½��:
����ʹ���������:
SELECT stu_id,
stu_name,
ecourse,
escore
from student_score_new
lateral view explode(split(course,��,��)) cr as ecourse
lateral view explode(split(score,��,��)) sc as escore;
��ѯ�Ľ������:
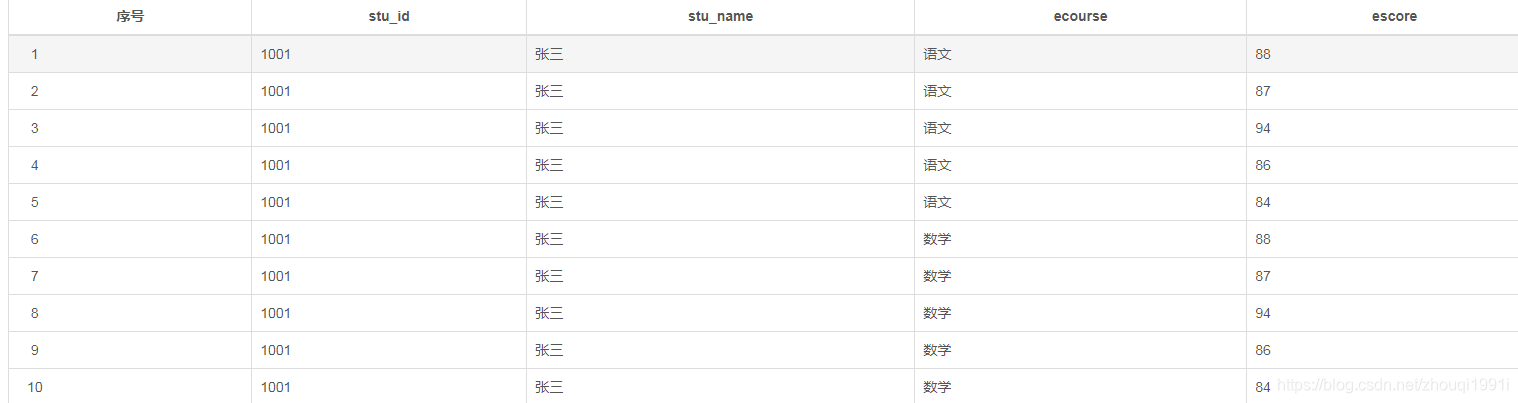
?
���������������Ϊ�������е�explode��sqlû�취ʶ��ÿ����Ŀ��Ӧ�ijɼ��Ƕ���,���ڶ���������ת�п���ʹ��posexplode����,����ʹ�����²�ѯ���:
�Cʹ��posexplode����������ת�в�ѯ
SELECT stu_id,
stu_name,
ecourse,
escore
from student_score_new
lateral view posexplode(split(course,��,��)) cr as a,ecourse
lateral view posexplode(split(score,��,��)) sc as b,escore
where a=b;
��ѯ�������:
��� stu_id stu_name ecourse escore
1 1001 ���� ���� 88
2 1001 ���� ��ѧ 87
3 1001 ���� Ӣ�� 94
4 1001 ���� ��ʷ 86
5 1001 ���� ���� 84
6 1002 ���� ���� 78
7 1002 ���� ��ѧ 89
8 1002 ���� Ӣ�� 75
9 1002 ���� ��ʷ 79
10 1002 ���� ���� 68
11 1003 ���� ���� 98
12 1003 ���� ��ѧ 97
13 1003 ���� Ӣ�� 91
14 1003 ���� ��ʷ 93
15 1003 ���� ���� 92
16 1004 ���� ���� 66
17 1004 ���� ��ѧ 63
18 1004 ���� Ӣ�� 64
19 1004 ���� ��ʷ 67
20 1004 ���� ���� 68
��������������������������������
��Ȩ����:����ΪCSDN���������������¡���ԭ������,��ѭCC 4.0 BY-SA��ȨЭ��,ת���븽��ԭ�ij������Ӽ���������
ԭ������:https://blog.csdn.net/zhouqi1991i/article/details/91957007
(��)Hive Explode/Lateral�鿴�������
https://qa.1r1g.com/sf/ask/1446723141/
����һ���������¼ܹ������õ�Ԫ��:
COOKIE | PRODUCT_ID | CAT_ID | QTY
1234123 [1,2,3] [r,t,null] [2,1,null]
����ι淶������,�Ա�õ����½��
COOKIE | PRODUCT_ID | CAT_ID | QTY
1234123 [1] [r] [2]
1234123 [2] [t] [1]
1234123 [3] null null
�ҳ��Թ����·���:
select concat_ws('|',visid_high,visid_low) as cookie
,pid
,catid
,qty
from table
lateral view explode(productid) ptable as pid
lateral view explode(catalogId) ptable2 as catid
lateral view explode(qty) ptable3 as qty
Ȼ������ǵѿ�����.
Jerome Banks..??15
������ʹ��Brickhouse�е�numeric_range��array_indexUDF(http://github.com/klout/brickhouse)�����������.��һƪ���ݷḻ�IJ���������ϸ������http://brickhouseconfessions.wordpress.com/2013/03/07/exploding-multiple-arrays-at-the-same-time-with-numeric_range/
ʹ����ЩUDF,��ѯ����������
select cookie,
array_index( product_id_arr, n ) as product_id,
array_index( catalog_id_arr, n ) as catalog_id,
array_index( qty_id_arr, n ) as qty
from table
lateral view numeric_range( size( product_id_arr )) n1 as n;
��..??15
��û��ʹ���κ�UDF���ҵ��˽���������ķdz��õĽ������,?posexplode��һ���dz��õĽ������:
SELECT COOKIE , ePRODUCT_ID, eCAT_ID, eQTY FROM TABLE LATERAL VIEW posexplode(PRODUCT_ID) ePRODUCT_IDAS seqp, ePRODUCT_ID LATERAL VIEW posexplode(CAT_ID) eCAT_ID AS seqc, eCAT_ID LATERAL VIEW posexplode(QTY) eQTY AS seqq, eDateReported WHERE seqp = seqc AND seqc = seqq;
- ��,���е�ͨ!��Ҫע�����,����������Ҫ������ͬ�ij���,���û��,�����ǽض�Ϊ��̵ij��ȡ���Ҳ��ȷ����������,��������Խ��Խ��IJ�����ͼ�С�?(3��ͬ
(��)Hive�ַ���תΪ���Ӹ�ʽ����
1���ַ���תΪmap
str_to_map(text[, delimiter1, delimiter2])
ʹ�������ָ������ı����Ϊ��ֵ�ԡ� Delimiter1���ı��ֳ�K-V��,Delimiter2�ָ�ÿ��K-V�ԡ�����delimiter1Ĭ�Ϸָ�����',',����delimiter2Ĭ�Ϸָ�����'='��
ʾ��:
select str_to_map('aaa:11&bbb:22', '&', ':');
select str_to_map('aaa:11&bbb:22', '&', ':')['aaa'];
?
select str_to_map('device_ds:2&uid_cnt:1','&',',') ?--��ֵ�ָ��,ֵ�����Null
�ۺ�ʹ��ʾ��:
select a1.appkey,a1.appsource,index_key,index_value
from tab_sum a1?
lateral view explode(str_to_map(concat('device_ds:',a1.device_ds_cnt,'&','uid_cnt:',a1.uid_cnt),'&',':')) mid_list_tab as index_key,index_value;
2���ַ���תΪarray
�ָ��ַ�������: split
�: ?split(string str, stringpat)
����ֵ: ?array
˵��: ����pat�ַ����ָ�str,�᷵�طָ����ַ�������
����:
select split('aaa:11:bbb:22',':');
["aaa","11","bbb","22"]
select split('aaa:11:bbb:22',':')[0];
aaa
3���ַ��ֶ�ȥ�ػ���ת��array
collect_set����:�ú����������ǽ�ij�ֶε�ֵ����ȥ�ػ���,����Array�����ֶΡ�
drop table if exists xxxxx_tabletest;
CREATE TABLE xxxxx_tabletest(
? id string,?
? name string)
ROW FORMAT SERDE?
? 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'?
WITH SERDEPROPERTIES (?
? 'field.delim'=',',?
? 'line.delim'='\n',?
? 'serialization.format'=',');
insert into xxxxx_tabletest(id,name)
values
('1','A'),
('1','C'),
('1','B'),
('2','B'),
('2','C'),
('2','D'),
('3','B'),
('3','C'),
('3','D');
select id,collect_set(name) from xxxxx_tabletest group by id;
OK
1 ? ? ? ["A","C","B"]
2 ? ? ? ["B","C","D"]
3 ? ? ? ["B","C","D"]
Time taken: 36.966 seconds, Fetched: 3 row(s)
��������������������������������
��Ȩ����:����ΪCSDN������BabyFish13����ԭ������,��ѭCC 4.0 BY-SA��ȨЭ��,ת���븽��ԭ�ij������Ӽ���������
ԭ������:https://blog.csdn.net/BabyFish13/article/details/78951928
(��)hivesql�е�concat����,concat_ws����,concat_group����֮�������
https://www.cnblogs.com/wqbin/p/10266783.html
һ��CONCAT()����
CONCAT()�������ڽ�����ַ������ӳ�һ���ַ�����
ʹ�����ݱ�Info��Ϊʾ��,����SELECT id,name FROM info LIMIT 1;�ķ��ؽ��Ϊ
+----+--------+ | id | name | +----+--------+ | 1 | BioCyc | +----+--------+
1�����ʹ���ص�:
CONCAT(str1,str2,��)???????????????????????
���ؽ��Ϊ���Ӳ����������ַ����������κ�һ������ΪNULL ,��ֵΪ NULL��������һ������������
2��ʹ��ʾ��:
SELECT CONCAT(id, ��,��, name) AS con FROM info LIMIT 1;���ؽ��Ϊ
+----------+ | con | +----------+ | 1,BioCyc | +----------+
SELECT CONCAT(��My��, NULL, ��QL��);���ؽ��Ϊ
+--------------------------+
| CONCAT('My', NULL, 'QL') |
+--------------------------+
| NULL |
+--------------------------+
����CONCAT_WS����
���ָ������֮��ķָ���
ʹ�ú���CONCAT_WS()��ʹ���Ϊ:CONCAT_WS(separator,str1,str2,��)
CONCAT_WS() ���� CONCAT With Separator ,��CONCAT()��������ʽ����һ�����������������ķָ������ָ�����λ�÷���Ҫ���ӵ������ַ���֮�䡣�ָ���������һ���ַ���,Ҳ��������������������ָ���Ϊ NULL,����Ϊ NULL������������κηָ���������� NULL ֵ������CONCAT_WS()��������κο��ַ����� (Ȼ����������е� NULL)��
��SELECT CONCAT_WS('_',id,name) AS con_ws FROM info LIMIT 1;���ؽ��Ϊ
+----------+ | con_ws | +----------+ | 1_BioCyc | +----------+
SELECT CONCAT_WS(',','First name',NULL,'Last Name');���ؽ��Ϊ
+----------------------------------------------+
| CONCAT_WS(',','First name',NULL,'Last Name') |
+----------------------------------------------+
| First name,Last Name |
+----------------------------------------------+
����GROUP_CONCAT()����
GROUP_CONCAT��������һ���ַ������,�ý���ɷ����е�ֵ������϶��ɡ�
ʹ�ñ�info��Ϊʾ��,�������SELECT locus,id,journal FROM info WHERE locus IN('AB086827','AF040764');�ķ��ؽ��Ϊ

+----------+----+--------------------------+ | locus | id | journal | +----------+----+--------------------------+ | AB086827 | 1 | Unpublished | | AB086827 | 2 | Submitted (20-JUN-2002) | | AF040764 | 23 | Unpublished | | AF040764 | 24 | Submitted (31-DEC-1997) | +----------+----+--------------------------+
1��ʹ������ص�:
GROUP_CONCAT([DISTINCT] expr [,expr ...]
[ORDER BY {unsigned_integer | col_name | formula} [ASC | DESC] [,col ...]]
[SEPARATOR str_val])
�� MySQL ��,����Եõ�����ʽ����������ֵ��ͨ��ʹ�� DISTINCT �����ų��ظ�ֵ�����ϣ���Խ���е�ֵ��������,����ʹ�� ORDER BY �Ӿ䡣
SEPARATOR ��һ���ַ���ֵ,�������ڲ��뵽���ֵ�С�ȱʡΪһ������ (","),����ͨ��ָ�� SEPARATOR "" ��ȫ���Ƴ�����ָ�����
����ͨ������ group_concat_max_len ����һ�����ij��ȡ�������ʱִ�еľ䷨����: SET [SESSION | GLOBAL] group_concat_max_len = unsigned_integer;
�����ȱ�����,���ֵ�����е������ȡ����������ַ�����,���Զ�ϵͳ������������:SET @@global.group_concat_max_len=40000;
2��ʹ��ʾ��:
��� SELECT locus,GROUP_CONCAT(id) FROM info WHERE locus IN('AB086827','AF040764') GROUP BY locus; �ķ��ؽ��Ϊ
+----------+------------------+ | locus | GROUP_CONCAT(id) | +----------+------------------+ | AB086827 | 1,2 | | AF040764 | 23,24 | +----------+------------------+
��� SELECT locus,GROUP_CONCAT(distinct id ORDER BY id?DESC SEPARATOR '_')?FROM info WHERE locus IN('AB086827','AF040764') GROUP BY locus;�ķ��ؽ��Ϊ
+----------+----------------------------------------------------------+ | locus | GROUP_CONCAT(distinct id ORDER BY id DESC SEPARATOR '_') | +----------+----------------------------------------------------------+ | AB086827 | 2_1 | | AF040764 | 24_23 | +----------+----------------------------------------------------------+
���SELECT locus,GROUP_CONCAT(concat_ws(', ',id,journal) ORDER BY id DESC SEPARATOR '. ') FROM info WHERE locus IN('AB086827','AF040764') GROUP BY locus;�ķ��ؽ��Ϊ
+----------+--------------------------------------------------------------------------+
| locus | GROUP_CONCAT(concat_ws(', ',id,journal) ORDER BY id DESC SEPARATOR '. ') |
+----------+--------------------------------------------------------------------------+
| AB086827 | 2, Submitted (20-JUN-2002). 1, Unpublished |
| AF040764 | 24, Submitted (31-DEC-1997) . 23, Unpublished |
�ġ�CONCAT_WS(SEPARATOR?,collect_set(column))
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?===>GROUP_CONCAT()����
? �����ǹ�˾��hive(��Ϊ��ȺFunctionInsight)��Ϊhive�汾����,��û��GROUP_CONCAT������ֻ����concat_ws��collect_set��������
����������ɥʧ��