Hive
Hive ����
���
hive��facebook��Դ,��������apache��֯,��Ϊapache��֯�Ķ�����Ŀ(hive.apache.org)�� hive��һ�����ڴ����ݼ��������ݲֿ�(DataWareHouse)����,��Ҫ��ͨ�����û���д��SQL��䷭���MapReduce����,Ȼ�������MR���ִ��,���SQL �� MapReduce��ת�������Խ��ṹ���������ļ�ӳ��Ϊһ�����ݿ��,���ṩ��SQL��ѯ���ܡ�
�ܽ�
- Hive��һ�����ݲֿ�
- Hive������HDFS��,���Դ洢�������ݡ�
- Hive��������Աʹ��SQL������������ݵķֲ�ʽ����,���㹹����yarn֮�ϡ�(Hive�ὫSQLת��ΪMR����)
�ŵ�:
? ����Ա�Ŀ����Ѷ�,дSQL����,������ȥдmapreduce,���ٿ�����Ա��ѧϰ�ɱ�
ȱ��:
? �ӳٽϸ�(MapReduce�����ӳ�,Hive SQL��MapReduceת���Ż��ύ),�ʺ��������ݵ����ߴ���(TB PB���������,ͳ�ƽ���ӳ�1�����)
Hive���ʺϳ���:
? 1:������
? 2:ʵʱ����
- ���ݿ� DataBase
- ��������С,���ݼ�ֵ��
- ���ݲֿ� DataWareHouse
- ����������,���ݼ�ֵ��
Hive �ļܹ�
1. ���
HDFS:�����洢hive�ֿ�������ļ�
yarn:�������hive��HQLת����MR�����ִ��
MetaStore:�������hiveά����Ԫ����
Hive:����ͨ��HQL��ִ��,ת��ΪMapReduce�����ִ��,�Ӷ���HDFS��Ⱥ�е������ļ�����ͳ�ơ�
2. ͼ

Hive�İ�װ
# ����
1. HDFS(Hadoop2.9.2)
2. Yarn(Hadoop2.9.2)
3. MySQL(5.6)
4. Hive(1.2.1)
������ڴ���������1G
1. ��װmysql���ݿ�
�ο�MySQL��װ�ĵ�
2. ��װHadoop
# ����hdfs��yarn��������Ϣ
[root@hive40 ~]# jps
1651 NameNode
2356 NodeManager
2533 Jps
1815 DataNode
2027 SecondaryNameNode
2237 ResourceManager
3. ��װhive
1 �ϴ�hive��װ����linux��
2 ��ѹ��hive
[root@hadoop ~]# tar -zxvf apache-hive-1.2.1-bin.tar.gz -C /opt/installs
[root@hadoop ~]# mv apache-hive-1.2.1-bin hive1.2.1
3 ���û�������
export HIVE_HOME=/opt/installs/hive1.2.1
export PATH=$PATH:$HIVE_HOME/bin
4 ����ϵͳ������Ч
[root@hadoop ~]# source /etc/profile
5 ����hive
hive-env.sh
����һ��hive-env.sh:[root@hadoop10 conf]# cp hive-env.sh.template hive-env.sh
# ����hadoopĿ¼
HADOOP_HOME=/opt/installs/hadoop2.9.2/
# ָ��hive�������ļ�Ŀ¼
export HIVE_CONF_DIR=/opt/installs/hive1.2.1/conf/
hive-site.xml
�����õ�hive-site.xml:[root@hadoop10 conf]# cp hive-default.xml.template hive-site.xml
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!--hive��Ԫ���ݱ�����mysql��,��Ҫ����mysql,�������÷���mysql����Ϣ-->
<!--url:���������ip-->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://hadoop10:3306/hive</value>
</property>
<!--drivername-->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<!--username-->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<!--password-->
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
</configuration>
��¼mysql����hive���ݿ�(ʹ�������д���)
create database hive
����mysql����jar��hive��libĿ¼��
4 ����
1. ���� hadoop
����hadoop
# ����HDFS start-dfs.sh # ����yarn start-yarn.sh

2. ��������hive
��ʼ��Ԫ����:schematool -dbType mysql -initSchema��ʼ��mysql��hivedatabase�е���Ϣ��
3. ����Hive�����ַ�ʽ
# ����ģʽ���� ������Աģʽ��
# ����hive������,ͬʱ����hive�Ŀͻ��ˡ�ֻ��ͨ�����ط�ʽ���ʡ�
[root@hadoop10 ~]# hive
Logging initialized using configuration in jar:file:/opt/installs/hive1.2.1/lib/hive-common-1.2.1.jar!/hive-log4j.properties
hive>
# 1.�ͻ��˲���֮HQL(Hive Query language)
# 1.�鿴���ݿ�
hive> show databases;
# 2. ����һ�����ݿ�
hive> create database baizhi;
# 3. �鿴database
hive> show databases;
# 4. �л��������ݿ�
hive> use baizhi;
# 5.�鿴���б�
hive> show tables;
# 6.����һ����
hive> create table t_user(id string,name string,age int);
# 7. ����һ������(ת��ΪMRִ��--������,��������)
hive> insert into t_user values('1001','zhangsan',20);
# 8.�鿴���ṹ
hive> desc t_user;
# 9.�鿴����schema������Ϣ��(��Ԫ����,������Ϣ)
hive> show create table t_user;
# ��ȷ����,�ñ������ݴ����hdfs�С�
# 10 .�鿴���ݿ�ṹ
hive> desc database baizhi;
# 11.�鿴��ǰ��
hive> select current_database();
# 12 ����sql
select * from t_user;
select count(*) from t_user; (Hive������MapReduce)
select * from t_user order by id;
5.hive�Ŀͻ��˺ͷ����
# ����hive�ķ�����,��������Զ�����ӷ�ʽ���ʡ�
// ǰ̨����
[root@hadoop10 ~]# hiveserver2
// ��̨����
[root@hadoop10 ~]# hiveserver2 &
beeline�ͻ���
# �����ͻ���
[root@hadoop10 ~]# beeline
beeline> !connect jdbc:hive2://hadoop10:10000
�س�����mysql�û���
�س�����mysql����
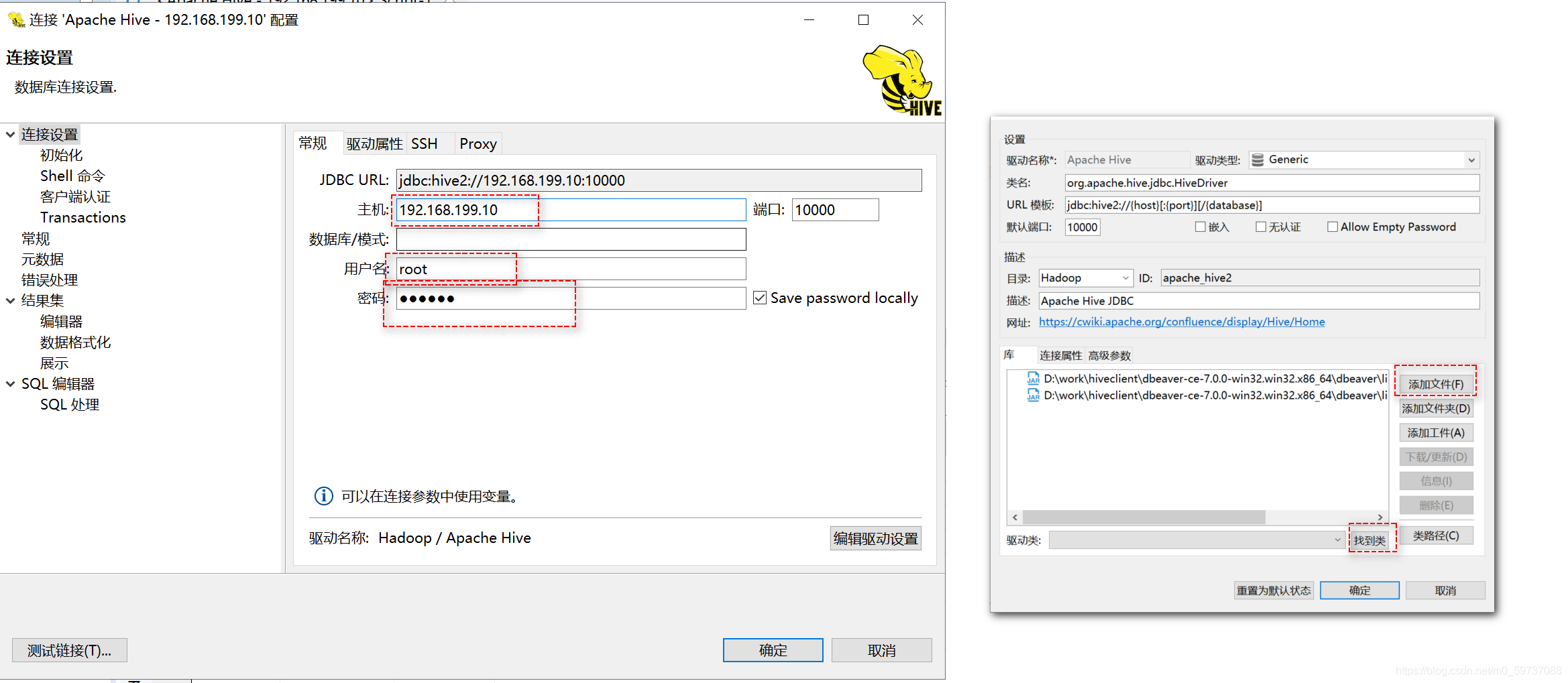
DBeaver�ͻ���(ͼ�λ�����)
# 1: ��ѹ
# 2: ��dbeaver����hive������jar
hadoop-common-2.9.2
hive-jdbc-1.2.1-standalone
# 3:����
Hive���ݵ���
1.�Զ���ָ��� [��Ҫ]
# �ָ������
| �ָ��� | ���� | ��ע |
|---|---|---|
| , | ������ʾÿ���е�ֵ֮��ָ����� fields | |
| - | �����ָ�array��ÿ��Ԫ��,�Լ�struct�е�ÿ��ֵ,�Լ�map��kv��kv֮�䡣 collection items | |
| | | �����ָ�map��k��v֮�� map keys | |
| \n | ÿ�����ݷָ�ʹ�û��С� lines |
# ����
create table t_person(
id string,
name string,
salary double,
birthday date,
sex char(1),
hobbies array<string>,
cards map<string,string>,
addr struct<city:string,zipCode:string>
) row format delimited
fields terminated by ','--�еķָ�
collection items terminated by '-'--���� struct������ map��kv��kv֮��
map keys terminated by '|'-- map��k��v�ķָ�
lines terminated by '\n';--������֮��ķָ�
# ��������
1,����,8000.0,2019-9-9,1,����-�Ⱦ�-��ͷ,123456|�й�����-22334455|��������,����-10010
2,����,9000.0,2019-8-9,0,����-�Ⱦ�-��ͷ,123456|�й�����-22334455|��������,֣��-45000
3,����,7000.0,2019-7-9,1,�Ⱦ�-��ͷ,123456|�й�����-22334455|��������,����-10010
4,��6,100.0,2019-10-9,0,����-��ͷ,123456|�й�����-22334455|��������,֣��-45000
5,��ǫ,1000.0,2019-10-9,0,����-�Ⱦ�,123456|�й�����-22334455|��������,����-10010
6,���¸�,1000.0,2019-10-9,1,����-��ͷ,123456|�й�����-22334455|��������,���-20010
# ��������
# ��hive��������ִ��
-- local ��������·��,�����д,������ȡ�ļ�������HDFS
-- overwrite �Ǹ��ǵ���˼,����ʡ�ԡ�
load data [local] inpath ��/opt/datas/person1.txt�� [overwrite] into table t_person;
# �����Ͼ��ǽ������ϴ���hdfs��(��������hive�Ĺ���)
2.JSON�ָ��
jar���Ӻ����ݵ���,����,��beeline�������
����
# 1.���ش���json�ļ�
{"id":1,"name":"zhangsan","sex":0,"birth":"1991-02-08"}
{"id":2,"name":"lisi","sex":1,"birth":"1991-02-08"}
���Ӹ�ʽ��������jar(���ؿͻ�������)
# ��hive�Ŀͻ���ִ��(��ʱ����jar��hive��classpath,��Ч�ڱ�������)
add jar /opt/installs/hive1.2.1/hcatalog/share/hcatalog/hive-hcatalog-core-1.2.1.jar
# ����:��������,Hive��������������
1. ����Ҫ���ӵ�hive��classpath��jar,������hive�µ�auxlibĿ¼��,
2. ����hiveserver���ɡ�
����
create table t_person2(
id string,
name string,
sex char(1),
birth date
)row format serde 'org.apache.hive.hcatalog.data.JsonSerDe';
�����ļ�����(���ؿͻ�������)
# ע��:�����json����dbeaver�����ˡ�(��Ϊ�����ı������Ͼ��Ǹ�json�ļ���)
load data local inpath '/opt/person.json' into table t_person2;
3. ����ָ���
����:access.log
INFO 192.168.1.1 2019-10-19 QQ com.baizhi.service.IUserService#login
INFO 192.168.1.1 2019-10-19 QQ com.baizhi.service.IUserService#login
ERROR 192.168.1.3 2019-10-19 QQ com.baizhi.service.IUserService#save
WARN 192.168.1.2 2019-10-19 QQ com.baizhi.service.IUserService#login
DEBUG 192.168.1.3 2019-10-19 QQ com.baizhi.service.IUserService#login
ERROR 192.168.1.1 2019-10-19 QQ com.baizhi.service.IUserService#register
�������
create table t_access(
level string,
ip string,
log_time date,
app string,
service string,
method string
)row format serde 'org.apache.hadoop.hive.serde2.RegexSerDe'--�������ʽ�ĸ�ʽת����
with serdeproperties("input.regex"="(.*)\\s(.*)\\s(.*)\\s(.*)\\s(.*)#(.*)");--(.*) ��ʾ�����ַ� \\s��ʾ�ո�
��������
load data local inpath '/opt/access.log' into table t_access;
�鿴����
select * from t_access;
HQL��
�C SQL�ؼ���ִ��˳��
from > where���� > group by > having����>select>order by>limitע��:sqlһ������group by,�����Ĺؼ����ܹ������ֶ�ֻ��(���������ֶ�,�麯���������)
HQL��
# 0. �����������͵��ֶη���(array��map��struct)
select name,salary,hobbies[1],cards['123456'],addr.city from t_person;
# 1. ������ѯ:= != >= <=
select * from t_person where addr.city='֣��';
# 2. and or between and
select * from t_person where salary>5000 and array_contains(hobbies,'����');
# 3. order by[�ײ������mapreduce��������]
select * from t_person order by salary desc;
# 4. limit(hiveû����ʼ�±�)
select * from t_person sort by salary desc limit 5;
# 5. ȥ��
select distinct addr.city from t_person;
select distinct(addr.city) from t_person;
# ������
select ...
from table1 t1 left join table2 t2 on ����
where ����
group by
having
# ���к���(show functions) �鿴���к���
-- �鿴hiveϵͳ���к���
show functions;
1. array_contains(��,ֵ);
select name,hobbies from t_person where array_contains(hobbies,'�Ⱦ�');
2. length(��)
select length('123123');
3. concat(��,��)
select concat('123123','aaaa');
4. to_date('1999-9-9')
select to_date('1999-9-9');
5. year(date),month(date),
6. date_add(date,����)
select name,date_add(birthday,-9) from t_person;
# �麯��
����:
max��min��sum��avg��count��
count(����)
# ը�Ѻ���(���Ϻ���)
# explode(�����ֶ�)
# lateral view
-- Ϊָ����,�ı�Եƴ��һ���С�(���Ʊ�����)
-- lateral view:Ϊ����ƴ��һ����(ը�ѽ��)
-- �:from �� lateral view explode(�����ֶ�) ���� as �ֶ���;
# ����
1. group by(�鿴�������еľ�н)
2. having(�鿴ƽ�����ʳ���5000�ij��к;�н)
3. ͳ�Ƹ������õ�����
--explod+lateral view
select hobby,count( * )
from t_person lateral view explode(hobbies) t_hobby as hobby
group by hobby;
4. ͳ�����ܻ�ӭ�İ���TOP1
SELECT hb,count( * ) num
from t_person lateral view explode(hobbies) h as hb
group by hb
order by num desc limit 1;
# �Ӳ�ѯ
-- ͳ������Щ����,��ȥ�ء�
select distinct t.hobby from
(select explode(hobbies) as hobby from t_person ) t
������ת
# collect_list(�麯��)
����:�Է�����,ÿ�����ij���е�ֵ�����ռ����ܡ�
�:select collect_list(��) from �� group by ������;
select username,collect_list(video_name) from t_visit_video group by username;

# collect_set(�麯��)
����:�Է�����,ÿ�����ij���е�ֵ�����ռ�����,��ȥ���ظ�ֵ��
�:select collect_set(��) from �� group by ������;
select username,collect_set(video_name) from t_visit_video group by username;

# concat_ws(�����)
����:���ij���ֶ�������,�Ը�ֵ�ö��Ԫ��ʹ��ָ���ָ���ƴ�ӡ�
select id,name,concat_ws(',',hobbies) from t_person;
--# ��t_visit_video����ת��Ϊ����ͼЧ��
--ͳ��ÿ����,2020-3-21�����ĵ�Ӱ��
select username,concat_ws(',',collect_set(video_name)) from t_visit_video group by username;

ȫ����;ֲ�����
# ȫ������
�:select * from �� order by �ֶ� asc|desc;
# �ֲ�����(��������)
����:�������reduceTask,�����ݽ�������(Ԥ����),�ֲ�����
�ֲ�����ؼ��� sort by
Ĭ��reducetask����ֻ��1��,���з���Ҳֻ��һ��������Ĭ�Ϻ�ȫ����Ч��һ����
�:select * from �� distribute by �����ֶ� sort by �ֶ� asc|desc;
-- 1. ����reduce����
-- ����reduce����
set mapreduce.job.reduces = 3;
-- �鿴reduce����
set mapreduce.job.reduces;
-- 2. ʹ��sort by���� +distribute by ָ�������С�(ʹ��distribute��select��ֻ��*)
select * from t_person distribute by addr.city sort by salary desc;
-- 3.���Խ���ѯ���д�뱾�ش���,���ڲ���sort by��Ч��
-- ���������ļ� ����reduces���� ·�����Բ����� �Զ�����
insert overwrite local directory '/opt/data/sortby'
select * from t_person distribute by addr.city sort by salary desc;
Hive�����
4.1 ������
��HiveȫȨ�����ı�? ��ν�Ĺ�����ָhive�Ƿ�߱����ݵĹ���Ȩ��,����ñ��ǹ�����,���û�ɾ������ͬʱ,hiveҲ�Ὣ������Ӧ������ɾ��,���������������,Ϊ�˷�ֹ�����,����������ʧ,һ�㿼�ǽ�����Ϊ�ǹ�����-�ⲿ��
�ܽ�:Hive�Ĺ���,���ṹ,hdfs�б��������ļ�,����HiveȫȨ������---- hiveɾ��������,HDFS��Ӧ�ļ�Ҳ�ᱻɾ����
ȱ��:���ݲ���ȫ��
4.2 �ⲿ��
����ӳ��HDFS������Ϊ������,����ɾ�������ⲿ��������������������ɾ���ⲿ��,ֻ�ǽ�MySQL�ж�Ӧ�ñ���Ԫ������Ϣɾ��,������ɾ��hdfs�ϵ�����,����ⲿ������ʵ�ֺ͵�����Ӧ�ù������ݡ��ڴ��������ʱ����Ҫ����һ���ؼ���"external"���ɡ�create external xxx()��
4.3 ������
��������ij���е�һ��������з������,���ٺ�����������µ����ݼ�����Χ,��߲�ѯЧ��;
����:��Ӱ�����û���
��������:�����û�����Ӱ����
Ӧ��:����ʵ��ҵ����,�ò�ѯ����������Ϊ�����������з���,��СMapReduce��ɨ�跶Χ,���MapReduce��ִ��Ч��,
�ܽ�:
? table�еĶ�������������Ƿ�������
? 1:ɾ�����ݰ��շ���ɾ�������ɾ��ij������,������Ӧ������Ҳɾ��(�ⲿ��,����ɾ��,�����ļ���Ȼ��)��
? 2:��ѯͳ��,���������һ��������������
? select * from �� where �����ֶ�Ϊ������
4.3.1 ����������
����Դ�ļ�
# �ļ�"bj.txt" (china bj����)
1001,����,1999-1-9,1000.0
1002,����,1999-2-9,2000.0
1008,��˧,1999-9-8,50000.0
1010,����ϣ,1999-10-9,10000.0
1009,������,1999-9-9,10.0
# �ļ���tj.txt�� (china tj����)
1006,���¸�,1999-6-9,6000.0
1007,���Ά�,1999-7-9,7000.0
����
create external table t_user_part(
id string,
name string,
birth date,
salary double
)partitioned by(country string,city string)--ָ��������,���չ��Һͳ��з�����
row format delimited
fields terminated by ','
lines terminated by '\n';
��������������������
# ����china��bj������
load data local inpath "/opt/bj.txt" into table t_user_part partition(country='china',city='bj');
# ����china��heb������
load data local inpath "/opt/tj.txt" into table t_user_part partition(country='china',city='tj');
�鿴������Ϣ
show partitions t_user_part;
ʹ�÷�����ѯ:������ֻҪ��ѯ�����ڴ��ڷ�����
select * from t_user_part where city = 'bj'
# ������
1. ������
hive��table���ݺ�hdfs�����ļ����DZ�hive������
2. �ⲿ��--����--hdfs�ļ���ȫ��
hive��table����,���ɾ��hive�е�table,�ⲿhdfs�������ļ����ɱ�����
3. ������--��Ҫ��
��table���ղ�ͬ����������
�ô�:���where�������з����ֶ�,��Hive���Զ��Է����ڵ����ݽ��м���(����ɨ��������������),���hive�IJ�ѯЧ�ʡ�
Hive�Զ��庯��
���ú���
# �鿴hive���ú���
show functions;
# �鿴����������Ϣ
desc function max;
�û��Զ��庯��UDF
�û����庯��-UDF
user-defined function���������ڵ���������,���Ҳ���һ����������Ϊ����������������������һ��(������ѧ�������ַ�������)��
����˵:
UDF:���ض�Ӧֵ,һ��һ
# 0. ����hive����
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>1.2.1</version>
</dependency>
# 1.����һ����̳�UDF
1. ����̳�UDF
2. ������������evaluate
# 2. ����maven�������,���jar
<properties>
<!--��������GBK������-->
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<build>
<finalName>funcHello</finalName>
</build>
# ���
mvn package
# 3. �ϴ�linux,���뵽�������С�
# ��hive������ִ��
add jar /opt/data/funcHello.jar; # hive session���������,
delete jar /opt/data/funcHello.jar; # �����д,�ǵ�ɾ����
-- �����ĺ�����Ϊ��ʱ���������ú���
create [temporary] function hello as "���ȫ����"; # temporary�ǻỰ����
# ɾ������ĺ���
drop [temporary] function hello;
# 4. �鿴������ʹ�ú���
-- 1. �鿴����
desc function hello;
desc function extended hello;
-- 2. ʹ�ú������в�ѯ
select hello(userid,cityname) from logs;
��:�����������������-pentahu
# ����
https://public.nexus.pentaho.org/repository/proxied-pentaho-public-repos-group/org/pentaho/pentaho-aggdesigner-algorithm/5.1.5-jhyde/pentaho-aggdesigner-algorithm-5.1.5-jhyde-javadoc.jar
# ���ڱ���Ӣ��Ŀ¼��
D:\work\pentaho-aggdesigner-algorithm-5.1.5-jhyde-javadoc.jar
# ִ��mvn��װ��������������
D:\work> mvn install:install-file -DgroupId=org.pentaho -DartifactId=pentaho-aggdesigner-algorithm -Dversion=5.1.5-jhyde -Dpackaging=jar -Dfile=pentaho-aggdesigner-algorithm-5.1.5-jhyde-javadoc.jar
���� ��������(��ȷ���Ժ���)
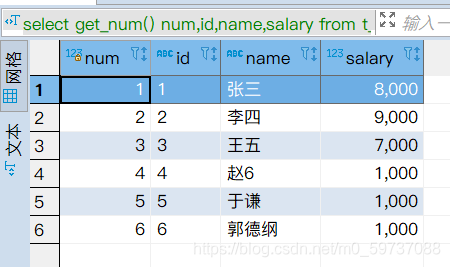
# ����һ������ get_number()
select get_num() num,id,name,salary from t_person;
# ����
1. ����һ��java��
�̳�UDF
��дevaluate����
import org.apache.hadoop.hive.ql.exec.Description;
import org.apache.hadoop.hive.ql.exec.UDF;
import org.apache.hadoop.io.LongWritable;
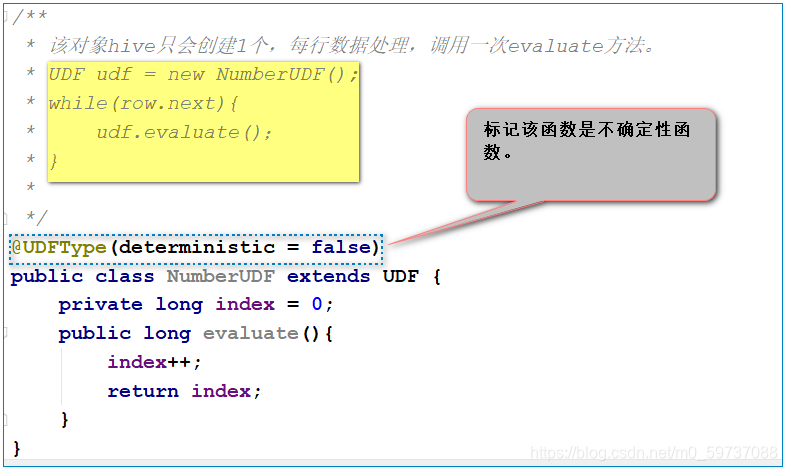
@UDFType(deterministic = false) //����ȷ��,���ȷ���ĺ���,false,��Ϊ�ú���û������,������Ҳ��仯��
public class NumberUDF extends UDF {
private long index = 0;
public long evaluate(){
index++;
return index;
}
}
2. ���
mvn clean package
3. �ϴ�linux
4. ���뵽hive����������
add jar /opt/doc/myhive1.2.jar;
5. ��������
create temporary function get_num as 'function.NumberUDF';
6. ʹ��
select get_num() num,id,name,salary from t_person;
�û��Զ��庯��UDTF
�Զ���һ�� UDTF ʵ�ֽ�һ������ָ�����ַ����и�ɶ����ĵ���,����: Line:��hello,world,hadoop,hive�� Myudtf(line, ��,��)
hello
world
hadoop
hive
����ʵ��:
import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDTF;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspectorFactory;
import org.apache.hadoop.hive.serde2.objectinspector.StructObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;
import java.util.ArrayList;
import java.util.List;
public class MyUDTF extends GenericUDTF {
private ArrayList<String> outList = new ArrayList<String>();
@Override
public StructObjectInspector initialize(StructObjectInspector argOIs) throws UDFArgumentException {
//1.����������ݵ�����������
List<String> fieldNames = new ArrayList<String>();
List<ObjectInspector> fieldOIs = new ArrayList<ObjectInspector>();
//2.����������ݵ�����������
fieldNames.add("lineToWord");
fieldOIs.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);
return ObjectInspectorFactory.getStandardStructObjectInspector(fieldNames, fieldOIs);
}
@Override
public void process(Object[] args) throws HiveException {
//1.��ȡԭʼ����
String arg = args[0].toString();
//2.��ȡ���ݴ���ĵڶ�������,�˴�Ϊ�ָ���
String splitKey = args[1].toString();
//3.��ԭʼ���ݰ��մ���ķָ��������з�
String[] fields = arg.split(splitKey);
//4.�����зֺ�Ľ��,��д��
for (String field : fields) {
//����Ϊ���õ�,������ռ���
outList.clear();
//��ÿһ����������������
outList.add(field);
//�����������
forward(outList);
}
}
@Override
public void close() throws HiveException {
}
}
���Է�ʽͬ�Զ���UDF:���������jar������������
add jar xxxxx.jar;
create temporary function myudtf as "com.baizhi.function.MyUDTF";
select myudtf(line, ",") word
������ת�浼�����(4��)
# 1.���ļ����ݵ���hive����,
load data local inpath '�ļ���·��' overwrite into table ����
# 2.ֱ�ӽ���ѯ���,����һ���´����ı��С�(ִ�в�ѯ�Ĵ���)
create table �� as select��...
1. ִ��select���
2. ����һ���µı�,����ѯ���������С�
# 3.����ѯ���,�����Ѿ����ڱ���
insert into ��
select���...
insert overwrite table ��
select���...
# 4.��HDFS���Ѿ������ļ�,�����½���hive����
create table Xxx(
...
)row format delimited
fields terminated by ','
location 'hdfs�ı����ݶ�Ӧ��Ŀ¼'
��SQL��ִ�н�����뵽��һ������
create table �� as select���
--## ����:
--ͳ��ÿ����,2020-3-21�����ĵ�Ӱ,���������hive�ı�:t_video_log_20200321
create table t_video_log_20200321 as select ...;