一、ElasticSearch了解
????????ElasticSearch是一个基于lucene的分布式检索服务器。相对于solr搜索,在大数据量和数据并发量上更有优势,同时,也有数据库的数据存储功能,但提供了比数据库更多的存储功能,如分词搜索、关联度搜索等,同时搜索速度也不是一个级别,达到百万数据/秒的查询数据。总结优点为:实时搜索、稳定、可靠、快速、安装方便等。
????? ??ElasticSearch中的概念(或叫做结构)和数据库中进行对比:
????? ? (1)index:索引,相当于数据库中的一个库,里面可以建立很多表,存储不同类型的数据
????? ? (2)type:类型,相当于数据库中的一张表,存储json类型的数据
????? ? (3)document:文档,一个文档相当于数据库中的一条数据
????? ? (4)field:列,相当于数据库中的列,也就是一个属性
????? ? (5)shards:分片,通俗理解,就是数据分成几块区域来存储,可以理解为mysql中的分库分表(不太恰当)
????? ? (6)replicas:备份,就是分片的备份数,相当于数据库中的备份库
二、ElasticSearch+nodejs+head集成安装(安装环境:jdk8,window10)
????? ? 1、先安装ElasticSearch
????????? ? (注意:ElasticSearch目前最新版本达到了7.0.1,但不同的版本在不同的安装环境下回出现不同的兼容性问题,详见百度,目前遇到的问题有:用7.0.1版本时无法设置network.host为0.0.0.0,这样见无法让外部服务去访问当前服务器,故改成现在的6.7.2是可以的,并且,ElasticSearch是Java项目,需要依赖jdk,并且对jdk版本有要求,目前安装的是jdk8。另外,安装es服务时安装路径最好不要包含空格,否则在做通过logstash数据同步的时候会报莫名的错误)
????????? ? (1)安装:具体安装为在官网https://www.elastic.co/cn/downloads/elasticsearch#ga-release下载相应的版本后如:elasticsearch-6.7.2.zip,进行解压即可。
????????? ? (2)启动:到elasticsearch-6.7.2\bin目录下,启动elasticsearch.bat即可
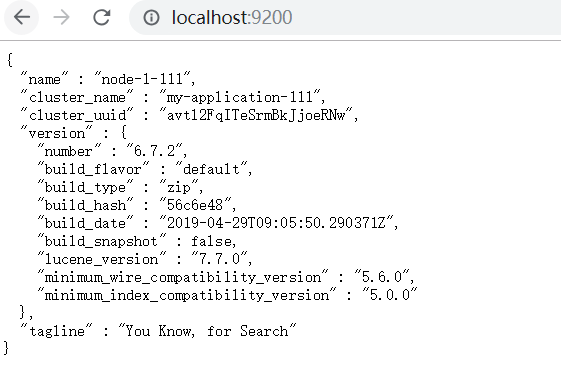
????????? ? (3)判断是否安装启动成功:访问http://localhost:9200,出现如下图即为成功
? ? ? ? ? ?? ??
????? ? 2、安装nodejs
????????? ? (1)在https://nodejs.org/en/download/?下载对应的版本,进行傻瓜式安装(默认安装成功后自动配置环境变量)
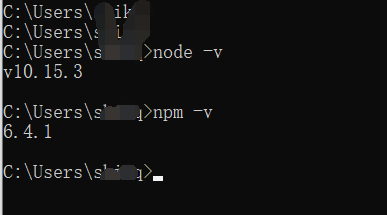
????????? ? (2)安装成功后使用 node -v查看nodejs的版本,使用npm -v查看npm的版本,如图:
? ? ? ? ? ? ? ? ? ? ? ??
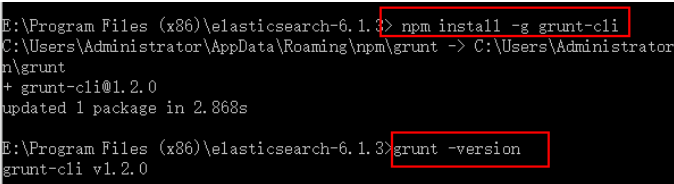
????????? ? (3)在nodejs的根目录下,执行npm install -g grunt-cli命令,安装grunt,安装完成后执行grunt -version查看是否安装成功,如图:
????????????????????????
????????? ? 3、安装head
????????????????(1)网上下载elasticsearch-head.zip文件解压即可
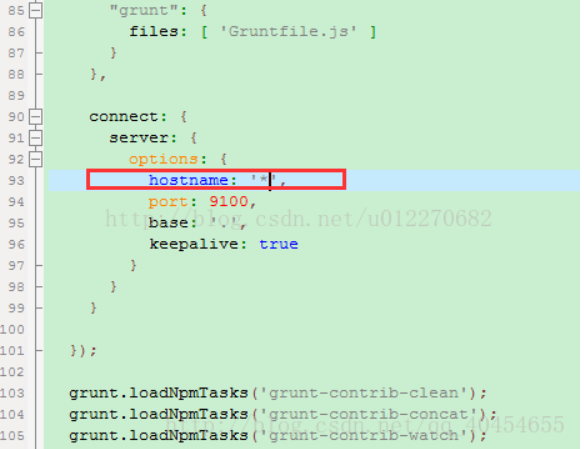
????????????? ? (2)修改elasticsearch-head文件目录下的Gruntfile.js文件,添加如下内容:
??????????????????????????
????????????? ? (3)修改elasticsearch-head\_site文件目录下的app.js文件内容,将红框中的内容修改为服务器地址,或是本机部署则不用修改。
? ? ? ? ? ? ? ? ? ? ? ?
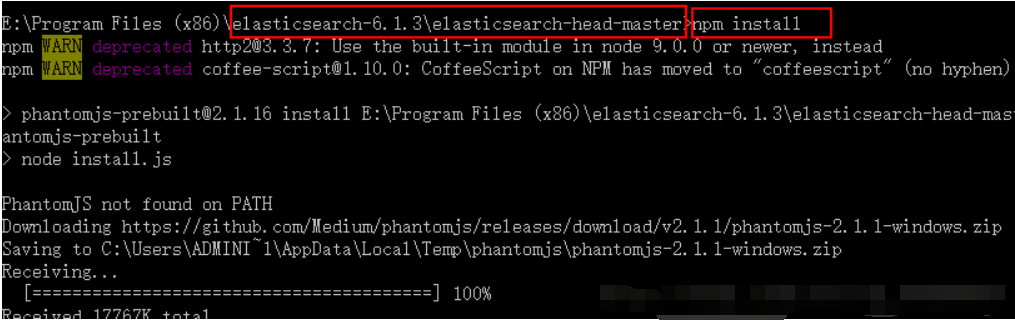
????????????????? (4)进入elasticsearch-head的跟目录下执行npm install 命令,如图:
? ? ? ? ? ? ? ? ? ? ? ?
????????? ? (5)在elasticsearch-head的根目录下启动nodejs,执行grunt server 或者 npm run start,如图:
? ? ? ? ? ? ? ? ? ? ? ??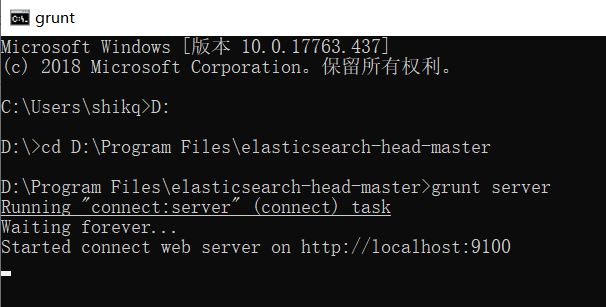 ????
????
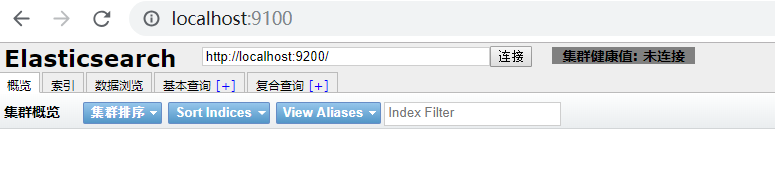
????????? ? (6)访问http://localhost:9100,出现如图所示,则head+nodejs安装成功
????????????????????? ??
????????????? ?(7)、若想让head启动并链接elasticsearch成功,需先启动elasticsearch,若head和elasticsearch不在同一服务器上时,需要在elasticsearch中做如下配置:
????????????????????????????修改elasticsearch.yml文件,在文件末尾加入:
????????????????????????????http.cors.enabled: true?
????????????????????????????http.cors.allow-origin: "*"
????????????????????????????node.master: true
????????????????????????????node.data: true
????????????????????????????放开network.host: 192.168.0.1的注释并改为network.host: 0.0.0.0(这样外部服务器也能访问es服务)
????????????????????????????放开cluster.name(集群名称,服务启动前修改后,以后不要再随意修改);node.name(集群使用时回用到);http.port(默认端口号即可)的注释
????????????????????????????双击elasticsearch.bat重启es
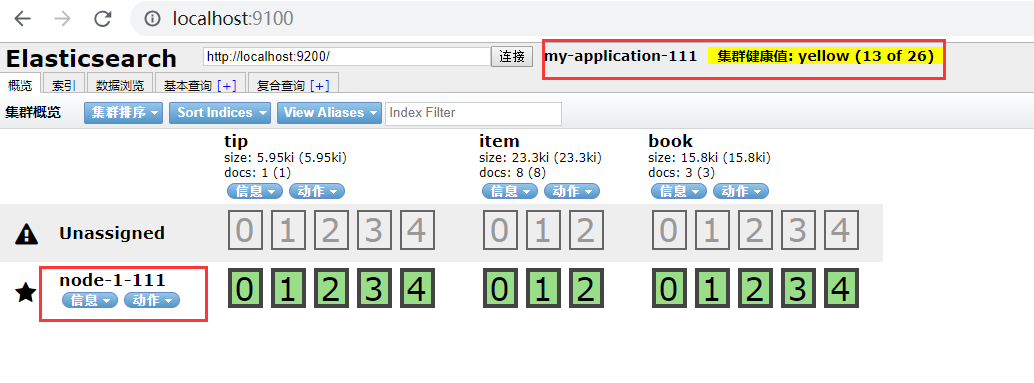
????????????????????????? ?修改完elasticsearch.yml文件完启动es后再访问http://localhost:9100,若head链接es成功后如下图:
????????????????????????????
????? ? 4、在head中对es数据进行操作,如,添加删除索引,对索引中的数据进行增删改差等操作。(详见百度)
三、springboot+elasticsearch集成及简单使用
????? ?1、先搭建好单独的springboot项目,以及部署好es服务(这里我是在之前搭建的SpringBoot多模块项目集成es)
????? ?2、相关依赖
<!-- SpringBoot与elasticsearch整合的相关依赖 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>? ? ? 3、配置文件
#增加elasticsearch配置
spring.data.elasticsearch.repositories.enabled = true
spring.data.elasticsearch.cluster-nodes=127.0.0.1:9300
spring.data.elasticsearch.cluster-name=my-application-111? ? ? 4、相关代码
??? Story
package net.cnki.es.entity;
import org.springframework.data.annotation.Id;
import org.springframework.data.elasticsearch.annotations.Document;
import org.springframework.data.elasticsearch.annotations.Field;
import org.springframework.data.elasticsearch.annotations.FieldType;
import java.util.Date;
@Document(indexName = "story",type="doc",shards=5,replicas=1)
public class Story {
/**
* @Document 作用在类,标记实体类为文档对象,一般有两个属性:
* indexName:对应索引库名称
* type:对应索引库中的类型(从其他文档中查看说是相当于关系型数据库中的一个表)
* shards:分片数量,默认5个
* replicas:副本数量,默认1个
* @Id 作用在成员变量,标记一个字段作为id主键
* @Field 作用在成员变量,标记为文档的字段,并指定字段映射属性:
* type:字段类型,是枚举:FieldType,可以是text、long、short、date、integer、object等
* text:存储数据时候,会自动分词,并生成索引
* keyword:存储数据时候,不会分词建立索引
* Numerical:数值类型,分两类
* 基本数据类型:long、interger、short、byte、double、float、half_float
* 浮点数的高精度类型:scaled_float
* 需要指定一个精度因子,比如10或100。elasticsearch会把真实值乘以这个因子后存储,取出时再还原。
* Date:日期类型
* elasticsearch可以对日期格式化为字符串存储,但是建议我们存储为毫秒值,存储为long,节省空间。
* index:是否索引,布尔类型,默认是true
* store:是否存储,布尔类型,默认是false
* analyzer:分词器名称,这里的ik_max_word即使用ik分词器
* IK分词器有两种类型,分别是ik_smart分词器和ik_max_word分词器。
* ik_smart: 会做最粗粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国,国歌”。
* ik_max_word: 会将文本做最细粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国,中华人民,中华,华人,人民共和国,人民,人,民,共和国,共和,和,国国,国歌”,会穷尽各种可能的组合;
*/
@Id
private Integer id;
@Field(type= FieldType.text,analyzer = "ik_smart",searchAnalyzer = "ik_smart")
private String volume;
@Field(type=FieldType.text,analyzer = "ik_smart",searchAnalyzer = "ik_smart")
private String chapter;
@Field(type=FieldType.text,analyzer = "ik_smart",searchAnalyzer = "ik_smart")
private String content;
@Field(type=FieldType.Date)
private Date createdate;
/**
* @return id
*/
public Integer getId() {
return id;
}
/**
* @param id
*/
public void setId(Integer id) {
this.id = id;
}
public String getVolume() {
return volume;
}
public void setVolume(String volume) {
this.volume = volume;
}
public String getChapter() {
return chapter;
}
public void setChapter(String chapter) {
this.chapter = chapter;
}
public String getContent() {
return content;
}
public void setContent(String content) {
this.content = content;
}
public Date getCreatedate() {
return createdate;
}
public void setCreatedate(Date createdate) {
this.createdate = createdate;
}
@Override
public String toString() {
return "Story{" +
"id=" + id +
", volume='" + volume + '\'' +
", chapter='" + chapter + '\'' +
", content='" + content + '\'' +
", createdate=" + createdate +
'}';
}
}
????????StoryService
package net.cnki.es.service;
import com.github.pagehelper.PageInfo;
import net.cnki.es.entity.Story;
import org.springframework.data.domain.Page;
import java.util.Iterator;
import java.util.List;
import java.util.Map;
public interface StoryService{
/**
* 多条件模糊分页查询
* @param searchMap
* 查询条件以searchMap中key、value形式传入,其中key为要查询的字段名称,value为查询字段值
* @param ordersMap
* 排序条件以ordersMap中key、value形式传入,其中key为排序的字段名称,value为排序规则:desc/asc
* @param pageUtil
* 分页对象信息
* @param clazz
* @return
* 返回一个map数据,包含:
* map.("data",dataListInfo<T>);
* map.("pageEsInfo",pageEsInfo);
*/
<T> Map<String,Object> queryByMapParamsForPage(Map<String,Object> searchMap, Map<String, Object> ordersMap, PageInfo<T> pageUtil, Class<T> clazz);
/**
* 多条件模糊高亮显示分页查询
* @param searchMap
* 查询条件以searchMap中key、value形式传入,其中key为要查询的字段名称,value为查询字段值
* @param ordersMap
* 排序条件以ordersMap中key、value形式传入,其中key为排序的字段名称,value为排序规则:desc/asc
* @param pageUtil
* 分页对象信息
* @param clazz
* @param color
* 设置高亮显示的颜色
* @return
* 返回一个map数据,包含:
* map.("data",dataListInfo<T>);
* map.("pageEsInfo",pageEsInfo);
*/
<T> Map<String,Object> highLigthQueryForPage(Map<String,Object> searchMap, Map<String, Object> ordersMap, PageInfo<T> pageUtil, Class<T> clazz, String color);
/**
* 根据id删除es服务器上的数据(由于MySQL数据库同步数据到es时,无法同步MySQL中删除的历史数据,故需在es服务器上自行删除)
* @param id
* @param clazz
* @return
*/
<T> String deleteEsDataById(String id, Class<T> clazz);
/**
* 新增数据到es服务器
* @param id
* 当前数据的id值
* @param modelJson
* 新增对象的实体类,以json字符串格式传入
* @param index
* 新增对象的索引值
* @param type
* 新增对象的类型值
* @return
*/
String addEsData(String id, String modelJson, String index, String type);
/**
* 更新数据到es服务器
* @param id
* 当前数据的id值
* @param modelMap
* 更新对象属性值,以map格式传入
* @param index
* 更新对象的索引值
* @param type
* 更新对象的类型值
* @param clazz
* 更新对象类
* @return
*/
<T> String updEsData(String id, Map<String,Object> modelMap, String index, String type, Class<T> clazz);
/**
* 判断es服务器中是否有该id
* @param id
* @return
*/
String getIdById(String id);
/**
* 保存单条记录
* @param story
*/
void save(Story story);
/**
* 保存多条记录
* @param list
*/
void saveAll(List<Story> list);
/**
* 查询所有记录
* @return
*/
Iterator<Story> findAll();
Page<Story> findByContent(String content);
Page<Story> findByFirstCode(String firstCode);
Page<Story> findBySecordCode(String secordCode);
Page<Story> query(String key);
void getStoryData();
}
StoryServiceImpl
package net.cnki.es.service.impl;
import java.net.URL;
import java.util.*;
import java.util.Map.Entry;
import com.github.pagehelper.PageInfo;
import net.cnki.es.dao.EsDataQueryRepository;
import net.cnki.es.entity.Story;
import net.cnki.es.service.StoryService;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.action.update.UpdateRequest;
import org.elasticsearch.action.update.UpdateResponse;
import org.elasticsearch.index.query.BoolQueryBuilder;
import org.elasticsearch.index.query.QueryBuilder;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.SearchHits;
import org.elasticsearch.search.fetch.subphase.highlight.HighlightBuilder;
import org.elasticsearch.search.fetch.subphase.highlight.HighlightBuilder.Field;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.domain.Page;
import org.springframework.data.domain.PageRequest;
import org.springframework.data.domain.Pageable;
import org.springframework.data.domain.Sort;
import org.springframework.data.elasticsearch.core.ElasticsearchTemplate;
import org.springframework.data.elasticsearch.core.SearchResultMapper;
import org.springframework.data.elasticsearch.core.aggregation.AggregatedPage;
import org.springframework.data.elasticsearch.core.aggregation.impl.AggregatedPageImpl;
import org.springframework.data.elasticsearch.core.query.IndexQuery;
import org.springframework.data.elasticsearch.core.query.NativeSearchQuery;
import org.springframework.data.elasticsearch.core.query.NativeSearchQueryBuilder;
import org.springframework.data.elasticsearch.core.query.SearchQuery;
import org.springframework.data.elasticsearch.core.query.UpdateQuery;
import org.springframework.stereotype.Service;
import com.alibaba.druid.util.StringUtils;
@Service
public class StoryServiceImpl implements StoryService {
@Autowired
private ElasticsearchTemplate elasticsearchTemplate;
@Autowired
private EsDataQueryRepository esRepository;
private Pageable pageable = PageRequest.of(0,10);
@SuppressWarnings({ "deprecation", "static-access" })
@Override
public <T> Map<String, Object> queryByMapParamsForPage(Map<String, Object> searchMap, Map<String, Object> ordersMap,
PageInfo<T> pageEsInfo, Class<T> clazz) {
Map<String, Object> map = new HashMap<String,Object>();
//封装字段查询条件
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
if(searchMap!=null && !searchMap.isEmpty()) {
for(Entry<String, Object> vo : searchMap.entrySet()) {
String key = vo.getKey();
String value = (String) vo.getValue();
if(!StringUtils.isEmpty(value)) {
boolQueryBuilder = boolQueryBuilder.must(QueryBuilders.matchQuery(key, value));
}
}
}
QueryBuilder queryBuilder = boolQueryBuilder;
SearchQuery searchQuery = new NativeSearchQueryBuilder().withQuery(queryBuilder).build();
//获取封装分页查询条件,默认取第一页
Pageable pageable= null;
if(pageEsInfo!=null) {
Integer currentPageNum = pageEsInfo.getPageNum();
if(currentPageNum!=null&¤tPageNum>0) {
currentPageNum = currentPageNum-1;
}else {
map.put("success", false);
map.put("msg", "当前页数有误,请输入大于0的正整数");
return map;
}
Integer pageSize = pageEsInfo.getPageSize();
if(pageSize==null || pageSize==0) {
map.put("success", false);
map.put("msg", "每页条数有误,请输入大于0的正整数");
return map;
}
//获取封装排序条件
Sort sort = null;
if(ordersMap!=null && !ordersMap.isEmpty()) {
for(Entry<String, Object> vo : ordersMap.entrySet()) {
String key = vo.getKey();
String value = (String) vo.getValue();
if("desc".equals(value)) {
sort = sort.by(key).descending();
}else {
sort = sort.by(key).ascending();
}
}
}
if(sort!=null) {
pageable = new PageRequest(currentPageNum, pageSize,sort);
}else {
pageable = new PageRequest(currentPageNum, pageSize);
}
searchQuery = new NativeSearchQueryBuilder().withQuery(queryBuilder).withPageable(pageable).build();
}
List<T> list = elasticsearchTemplate.queryForList(searchQuery, clazz);
Long count = elasticsearchTemplate.count(searchQuery);
pageEsInfo.setTotal(count.intValue());
pageEsInfo.setSize(count.intValue());
map.put("data", list);
map.put("pageEsInfo", pageEsInfo);
return map;
}
@SuppressWarnings({ "deprecation", "static-access" })
@Override
public <T> Map<String, Object> highLigthQueryForPage(Map<String, Object> searchMap, Map<String, Object> ordersMap,
PageInfo<T> pageEsInfo, Class<T> clazz,String color) {
Map<String,Object> mapRel = new HashMap<String,Object>();
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
//封装字段查询条件,及高亮显示字段
String preTag = "<font color='red'>";//google的色值
String postTag = "</font>";
//不传默认红色
if(!StringUtils.isEmpty(color)) {
preTag = preTag.replace("red", color);
}
int size = 0;
for(Entry<String, Object> vo : searchMap.entrySet()) {
if(!StringUtils.isEmpty((String)vo.getValue())) {
size = size+1;
}
}
HighlightBuilder.Field[] highlightFields = new Field[size];
if(searchMap!=null && !searchMap.isEmpty()) {
int i=0;
for(Entry<String, Object> vo : searchMap.entrySet()) {
if(!StringUtils.isEmpty((String)vo.getValue())) {
String key = vo.getKey();
String value = (String) vo.getValue();
if(!StringUtils.isEmpty(value)) {
boolQueryBuilder = boolQueryBuilder.must(QueryBuilders.matchQuery(key, value));
Field field = new HighlightBuilder.Field(key).preTags(preTag).postTags(postTag);
highlightFields[i] = field;
i = i+1;
}
}
}
}
NativeSearchQuery searchQuery = new NativeSearchQueryBuilder()
.withQuery(boolQueryBuilder).withHighlightFields(highlightFields).build();
//封装分页信息
Pageable pageable= null;
if(pageEsInfo!=null) {
Integer currentPageNum = pageEsInfo.getPageNum();
if(currentPageNum!=null&¤tPageNum>0) {
currentPageNum = currentPageNum-1;
}else {
mapRel.put("success", false);
mapRel.put("msg", "当前页数有误,请输入大于0的正整数");
return mapRel;
}
Integer pageSize = pageEsInfo.getPageSize();
if(pageSize==null || pageSize==0) {
mapRel.put("success", false);
mapRel.put("msg", "每页条数有误,请输入大于0的正整数");
return mapRel;
}
//封装排序条件
Sort sort = null;
if(ordersMap!=null && !ordersMap.isEmpty()) {
for(Entry<String, Object> vo : ordersMap.entrySet()) {
String key = vo.getKey();
String value = (String) vo.getValue();
if("desc".equals(value)) {
sort = sort.by(key).descending();
}else {
sort = sort.by(key).ascending();
}
}
}
if(sort!=null) {
pageable = new PageRequest(currentPageNum, pageSize,sort);
}else {
pageable = new PageRequest(currentPageNum, pageSize);
}
searchQuery = new NativeSearchQueryBuilder()
.withQuery(boolQueryBuilder).withPageable(pageable)
.withHighlightFields(highlightFields).build();
}
Page<T> page = elasticsearchTemplate.queryForPage(searchQuery, clazz, new SearchResultMapper() {
@SuppressWarnings({ "unchecked", "hiding" })
@Override
public <T> AggregatedPage<T> mapResults(SearchResponse response, Class<T> clazz, Pageable pageable) {
ArrayList<Map<String,Object>> poems = new ArrayList<Map<String,Object>>();
SearchHits hits = response.getHits();
for (SearchHit searchHit : hits) {
if (hits.getHits().length <= 0) {
return null;
}
Map<String,Object> mapResult = searchHit.getSourceAsMap();
for(Entry<String, Object> vo : searchMap.entrySet()) {
String key = vo.getKey();
//将高亮内容设置进去
String valueSearch = (String) vo.getValue();
if(!StringUtils.isEmpty(valueSearch)) {
String highLightMessage = searchHit.getHighlightFields().get(key).fragments()[0].toString();
mapResult.put(key, highLightMessage);
}
}
poems.add(mapResult);
}
if (poems.size() > 0) {
return new AggregatedPageImpl<T>((List<T>) poems);
}
return null;
}
});
List<T> poems = new ArrayList<T>();
if(page!=null) {
poems = (List<T>) page.getContent();
}
Long count = elasticsearchTemplate.count(searchQuery);
int num = (int) count.longValue();
pageEsInfo.setTotal(count.intValue());
pageEsInfo.setSize(count.intValue());
//pageEsInfo.setPages(count.intValue());
if(num%pageEsInfo.getPageSize()==0){
pageEsInfo.setPages(num%pageEsInfo.getPageSize());
}else {
pageEsInfo.setPages(num%pageEsInfo.getPageSize()+1);
}
pageEsInfo.setList(poems);
mapRel.put("data", poems);
mapRel.put("pageEsInfo", pageEsInfo);
return mapRel;
}
@Override
public <T> String deleteEsDataById(String id, Class<T> clazz) {
String delId = elasticsearchTemplate.delete(clazz, id);
return delId;
}
@Override
public String addEsData(String id, String modelJson, String index, String type) {
IndexQuery indexQuery = new IndexQuery();
indexQuery.setId(id);
indexQuery.setSource(modelJson);
indexQuery.setIndexName(index);
indexQuery.setType(type);
String strId = elasticsearchTemplate.index(indexQuery);
return strId;
}
@Override
public <T> String updEsData(String id, Map<String, Object> modelMap, String index, String type, Class<T> clazz) {
UpdateQuery updateQuery = new UpdateQuery();
updateQuery.setId(id);
updateQuery.setClazz(clazz);
updateQuery.setIndexName(index);
updateQuery.setType(type);
UpdateRequest updateRequest = new UpdateRequest();
updateRequest.doc(modelMap);
updateQuery.setUpdateRequest(updateRequest);
UpdateResponse up = elasticsearchTemplate.update(updateQuery);
return up.getId();
}
@Override
public String getIdById(String id) {
// 构造搜索条件
SearchQuery searchQuery = new NativeSearchQueryBuilder().withQuery(QueryBuilders.boolQuery().must(QueryBuilders.matchQuery("id", id))).build();
List<String> ids = elasticsearchTemplate.queryForIds(searchQuery);
if(ids!=null&&ids.size()>0) {
return ids.get(0);
}
return null;
}
@Override
public void save(Story docBean) {
esRepository.save(docBean);
}
@Override
public void saveAll(List<Story> list) {
esRepository.saveAll(list);
}
@Override
public Iterator<Story> findAll() {
return esRepository.findAll().iterator();
}
@Override
public Page<Story> findByContent(String content) {
return esRepository.findByContent(content,pageable);
}
@Override
public Page<Story> findByFirstCode(String firstCode) {
return esRepository.findByFirstCode(firstCode,pageable);
}
@Override
public Page<Story> findBySecordCode(String secordCode) {
return esRepository.findBySecordCode(secordCode,pageable);
}
@Override
public Page<Story> query(String key) {
return esRepository.findByContent(key,pageable);
}
/**
* 爬取小说数据
* 小说名:剑来
*/
@Override
public void getStoryData() {
try {
int htmlPages = 2324764;
int id = 1;
String urlstart = "http://www.shuquge.com/txt/8659/";
String url = "http://www.shuquge.com/txt/8659/2324752.html";
String volume = "第一卷 笼中雀";
while (htmlPages<=38147404) {
//拼接url
//url = urlstart + htmlPages + ".html";
Document document = Jsoup.parse(new URL(url), 30000);
//获取小说内容元素
Elements element = document.getElementsByClass("content");
//获取结果集的第一个元素
Element li = element.first();
//章节
String chapter = li.getElementsByTag("h1").eq(0).html();
//内容
String content = li.getElementById("content").html();
Story story = new Story();
//小说详情页没有第几卷,根据章节判断
if (url.contains("2324837")) {
volume = "第二卷 山水郎";
}
story.setId(id);
story.setVolume(volume);
story.setChapter(chapter);
story.setContent(content);
Date date = new Date();
story.setCreatedate(date);
System.out.println(story.toString());
//插入es
save(story);
//获取下一章节地址
Element nextChapterElement = document.getElementsByClass("page_chapter").first();
String nextChapter = nextChapterElement.getElementsByTag("a").eq(2).attr("href");
if(nextChapter.contains("index.html")){
return;
}
url = urlstart + nextChapter;
htmlPages++;
id++;
}
}catch(Exception e){
}
}
}
EsDataQueryRepository
package net.cnki.es.dao;
import net.cnki.es.entity.Story;
import org.springframework.data.domain.Page;
import org.springframework.data.domain.Pageable;
import org.springframework.data.elasticsearch.annotations.Query;
import org.springframework.data.elasticsearch.repository.ElasticsearchRepository;
public interface EsDataQueryRepository extends ElasticsearchRepository<Story, Long> {
//默认的注释
//@Query("{\"bool\" : {\"must\" : {\"field\" : {\"content\" : \"?\"}}}}")
Page<Story> findByContent(String content, Pageable pageable);
@Query("{\"bool\" : {\"must\" : {\"field\" : {\"firstCode.keyword\" : \"?\"}}}}")
Page<Story> findByFirstCode(String firstCode, Pageable pageable);
@Query("{\"bool\" : {\"must\" : {\"field\" : {\"secordCode.keyword\" : \"?\"}}}}")
Page<Story> findBySecordCode(String secordCode, Pageable pageable);
}
StoryController
package net.cnki.es.controller;
import com.alibaba.fastjson.JSON;
import com.github.pagehelper.PageHelper;
import com.github.pagehelper.PageInfo;
import net.cnki.es.entity.Story;
import net.cnki.es.service.StoryService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Controller;
import org.springframework.util.StringUtils;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.ResponseBody;
import java.util.Date;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
@Controller
@RequestMapping("es")
public class StoryController {
@Autowired
private StoryService storyService;
/**
* 查询页面
* @return
*/
@GetMapping("/search")
public String searchPage() {
//ClassUtils.getDefaultClassLoader().getResource("templates").getPath()+
return "pages/elasticsearch/search.html";
}
/**
* 查询所有数据
*/
@RequestMapping("/all")
@ResponseBody
public Iterator<Story> all(){
return storyService.findAll();
}
/**
* 抓取网页数据
*/
@RequestMapping("/getStoryData")
public void getStoryData(){
storyService.getStoryData();
}
/**
* 分页查询
* @return
*/
@RequestMapping("getStoryList")
@ResponseBody
public PageInfo getStoryList(@RequestParam(value = "limit",defaultValue = "10")Integer limit,
@RequestParam(value = "page",defaultValue = "1")Integer page,String content,String chapter) {
Map<String,Object> mapParams = new HashMap<String,Object>();
mapParams.put("content", content);
mapParams.put("chapter", chapter);
PageInfo<Story> pageInfo = new PageInfo<Story>();
PageHelper.startPage(page,limit);
pageInfo.setPageNum(page);
pageInfo.setPageSize(limit);
Map<String,Object> mapOrders = new HashMap<String,Object>();
mapOrders.put("id", "desc");
Map<String,Object> map = new HashMap<String,Object>();
map= storyService.highLigthQueryForPage(mapParams, mapOrders, pageInfo, Story.class,"");
return (PageInfo)map.get("pageEsInfo");
}
/**
* 分页查询
*/
@RequestMapping("searchByPage")
@ResponseBody
public String getSyslogListTest2() {
Map<String,Object> mapParams = new HashMap<String,Object>();
mapParams.put("content", "平安");
PageInfo<Story> pageInfo = new PageInfo<Story>();
pageInfo.setPageNum(3);
pageInfo.setPageSize(5);
Map<String,Object> mapOrders = new HashMap<String,Object>();
mapOrders.put("_id", "desc");
Map<String,Object> map = new HashMap<String,Object>();
map = storyService.queryByMapParamsForPage(mapParams, mapOrders, pageInfo, Story.class);
return JSON.toJSONString(map);
}
/**
* 高亮分页查询
* @return
*/
@RequestMapping("searchByHighPage")
@ResponseBody
public String getSyslogListTest1() {
Map<String,Object> mapParams = new HashMap<String,Object>();
mapParams.put("content", "东");
PageInfo<Story> pageInfo = new PageInfo<Story>();
pageInfo.setPageNum(1);
pageInfo.setPageSize(5);
Map<String,Object> mapOrders = new HashMap<String,Object>();
mapOrders.put("id", "desc");
Map<String,Object> map = new HashMap<String,Object>();
map = storyService.highLigthQueryForPage(mapParams, mapOrders, pageInfo, Story.class,"#53FF53");
return JSON.toJSONString(map);
}
/**
* 删除记录
* @return
*/
@RequestMapping("delById")
@ResponseBody
public String delSyslogByIdTest() {
String id = "1";
if(!StringUtils.isEmpty(id)) {
String delId = storyService.deleteEsDataById(id, Story.class);
if(id.equals(delId)) {
return "true";
}else {
return "false";
}
}else {
return "false";
}
}
/**
* 添加记录
* @return
*/
@RequestMapping("addSyslog")
@ResponseBody
public String addSyslogInfoTest() {
Story sysLog = new Story();
sysLog.setId(100);
sysLog.setVolume("skq");
sysLog.setChapter("手动添加");
sysLog.setContent("shoudong");
sysLog.setCreatedate(new Date());
String modelJson = JSON.toJSONString(sysLog);
String id = sysLog.getId().toString();
String strId = storyService.addEsData(id, modelJson, "syslog", "syslog");
return strId;
}
/**
* 更新记录
* @return
*/
@RequestMapping("updSyslog")
@ResponseBody
public String updSyslogInfoTest() {
Map<String,Object> modelMap = new HashMap<String,Object>();
modelMap.put("id", 100);
modelMap.put("user_name", "skq12");
modelMap.put("type", "sd");
String strId = storyService.updEsData("100", modelMap, "syslog", "syslog", Story.class);
return strId;
}
}
? ? ? ? ? ?5、测试es全文检索,在service中写了爬取剑来小说的方法,将爬取的每一章内容直接存到es中,效果如下图所示:

?
?
?
四、利用logstash实现MySQL中的数据全量/增量同步到elasticsearch服务器中(window10环境)
????? ? 1、logstash的下载安装(logstash的安装时路径不要包含空格,某种在数据同步的时候会数据同步不成功)
?????????????logstash的官网下载地址:https://www.elastic.co/downloads/logstash,注意下载的版本要与elasticsearch版本必须一直,如当前elasticsearch的版本是6.7.2,则logstash的版本也必须是6.7.2
????????? ? 注意,在网上各种查找资料发现好多资料都需集成logstash-jdbc-input插件才能实现数据同步,后台才发现这个和版本有关系,在elasticsearch5.X及之后的版本是不需要集成该插件即可
????????? ? 下载好相应的版本后解压即可(注意解压的路径,最好不要有中文和空格)。
????? ? 2、logstash配置
???????????(1)在logstash-6.7.2路径下创建空文件夹,如mysql,用来存放相关配置文件等
????????? ?(2)在创建的新文件夹中(mysql文件夹)中放入驱动包:mysql-connector-java.jar
????????? ?(3)在创建的新文件夹中(mysql文件夹)中创建一个sql文件,如find.sql,从这里开始,就是logstash同步数据库的核心操作了,在这里创建的sql文件主要内容是:mysql需要同步Elasticsearch的具体数据的查询方式,如果是全量同步,只需要select * from [table]即可
????????? ? (4)在创建的新文件夹中(mysql文件夹)中创建一个conf文件,如jdbc.conf文件,该文件用于链接数据库和elasticsearch,其内容为:(注意,有的可能不识别注解,运行时需要将注解去掉)
input {
stdin {
}
jdbc {
jdbc_connection_string => "jdbc:mysql://localhost:3306/quick_platform?characterEncoding=utf8&useSSL=false&serverTimezone=UTC"
jdbc_user => "root"
jdbc_password => "cnki_TTOD_7"
jdbc_driver_library => "D:\ELK\logstash-6.7.2\mysql\mysql-connector-java-8.0.11.jar"
jdbc_driver_class => "com.mysql.cj.jdbc.Driver"
jdbc_paging_enabled => "true"
jdbc_page_size => "50000"
clean_run => false
jdbc_default_timezone => "Asia/Shanghai"
statement => "SELECT * FROM story where createdate > :sql_last_value order by createdate desc"
schedule => "* * * * *"
type => "sy"
lowercase_column_names => false
record_last_run => true
use_column_value => true
tracking_column => "createdate"
tracking_column_type => "timestamp"
last_run_metadata_path => "D:\ELK\logstash-6.7.2\mysql\lw_last_time"
clean_run => false
}
}
filter {
json {
source => "message"
remove_field => ["message"]
}
}
output {
elasticsearch {
hosts => "127.0.0.1:9200"
index => "mysql_story"
}
stdout {
codec => json_lines
}
}网上的第二中配置,部分不同而已:
input {
??? stdin {
??? }
??? jdbc {
????? jdbc_connection_string => "jdbc:mysql://localhost:3306/你的数据库名字"
? ? ? ? jdbc_user => "你的数据库用户名"
? ? ? ? jdbc_password => "你的数据库密码"
? ? ? ? jdbc_driver_library => "C:/logstash/bin/mysql-connector-java-5.1.44-bin.jar"
? ? ? ? jdbc_driver_class => "com.mysql.jdbc.Driver"
? ? ? ? jdbc_paging_enabled => "true"
? ? ? ? jdbc_page_size => "50000"
? ? ? ? statement => "SELECT id(主键),其他内容 FROM 你的表"
? ? ? ? schedule => "* * * * *"
??? }
}
output {
? ? ?stdout {
? ? ? ? codec => json_lines
? ? }
? ? elasticsearch {
? ? ? ? hosts => "localhost:9200"
? ? ? ? index => "你要创建的索引名"
? ? ? ? document_type => "你要创建的索引类型"
? ? ? ? document_id => "%{id}"
? ? }
}另一个说明比较详细的版本:
input {
? ? stdin {
? ? }
? ? jdbc {
? ? ? # 连接的数据库地址和哪一个数据库,指定编码格式,禁用SSL协议,设定自动重连
? ? ? jdbc_connection_string => "jdbc:mysql://数据库地址:端口号/数据库名?characterEncoding=UTF-8&useSSL=false&autoReconnect=true"
? ? ? # 你的账户密码
? ? ? jdbc_user => "账号"
? ? ? jdbc_password => "密码"
? ? ? # 连接数据库的驱动包,建议使用绝对地址
? ? ? jdbc_driver_library => "mysql/mysql-connector-java-5.1.45-bin.jar"
? ? ? # 这是不用动就好
? ? ? jdbc_driver_class => "com.mysql.jdbc.Driver"
? ? ? jdbc_paging_enabled => "true"
? ? ? jdbc_page_size => "50000"
?
? ? #处理中文乱码问题
? ? ? codec => plain { charset => "UTF-8"}
?
? ? ? ?#使用其它字段追踪,而不是用时间
? ? ? use_column_value => true
? ? ? ?#追踪的字段 ? ? ?
? ? tracking_column => testid ? ? ?
? ? record_last_run => true ? ??
? ? #上一个sql_last_value值的存放文件路径, 必须要在文件中指定字段的初始值 ? ??
? ? last_run_metadata_path => "mysql/station_parameter.txt"
?
? ? ? jdbc_default_timezone => "Asia/Shanghai"
?
? ? ? statement_filepath => "mysql/jdbc.sql"
? ? ??
? ? #是否清除 last_run_metadata_path 的记录,如果为真那么每次都相当于从头开始查询所有的数据库记录
? ? clean_run => false
?
? ? ? # 这是控制定时的,重复执行导入任务的时间间隔,第一位是分钟
? ? ? schedule => "*/5 * * * *"
? ? ? type => "jdbc"
? ? }
}
?
filter {
? ? json {
? ? ? ? source => "message"
? ? ? ? remove_field => ["message"]
? ? }
}
?
output {
? ? elasticsearch {
? ? ? ? # 要导入到的Elasticsearch所在的主机
? ? ? ? hosts => "192.168.105.180:9200"
? ? ? ? # 要导入到的Elasticsearch的索引的名称
? ? ? ? index => "db_anytest"
? ? ? ? # 类型名称(类似数据库表名)
? ? ? ? document_type => "table_anytest"
? ? ? ? # 主键名称(类似数据库主键)
? ? ? ? document_id => "%{testid}"
? ? ? ? # es 账号
? ? ? ? user => elastic
? ? ? ? password => changeme
? ? ? ??
? ? }
?
? ? stdout {
? ? ? ? # JSON格式输出
? ? ? ? codec => json_lines
? ? }
}?????? ?3、启动logstash开始同步数据库
????????????? (1)确保elasticsearch服务已启动,并且要同步的表里有相应的数据
????????????? (2)cmd一个新窗口,进入到D:\logstash-6.7.2\bin
????????????? (3)运行命令logstash -f ../mysql/jdbc.conf? ,其中logstash -f表示运行指令,?../mysql/jdbc.conf表示我们配置的jdbc.conf文件路径,成功启动后,可以在终端中看见运行的sql和同步的数据,如图: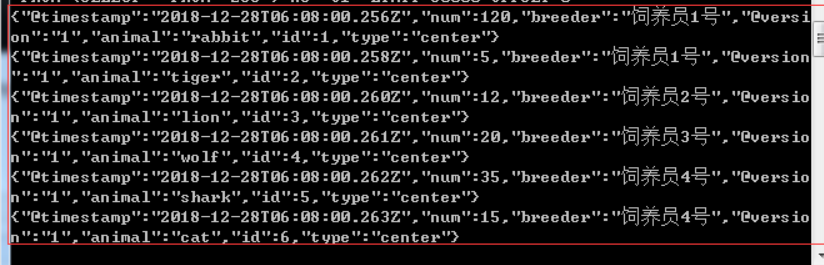
????????? ? ? ?(4)同步成功后即可在head中查看同步到elasticsearch中的数据,其中timestamp和version是elastisearch自己添加的字段。???????
????????????? ? (5)注意点:
????????????????????? ? a、在同步的时候,如果是首次全量同步的话,可以不需要在elasticsearch中去新建索引和类型,同步的时候会根据配置自动创建
????????????????????? ? b、若是增量更新的话,在sql中添加查询条件即可,如
????????????????????where? testid?>=?:sql_last_start