0 背景
HIVE中我们经常使用窗口函数中的排序函数ROW_NUMBER() OVER(PARTITION BY 'xxx' ORDER BY 'xxx' DESC/ASC)对数据集生成顺序编号或者进行数据去重的操作。然而在Clickhouse中没有提供该功能的函数,那么在clickhouse我们要想实现类似的功能我们应该如何实现呢?今天我们就来用实例说明下在clickhouse该如何实现ROW_NUMBER()功能。
1 数据准备
1.1 Clickhouse数据准备
- 建表语句:
CREATE TABLE test.row_number
(
`user_id` String,
`user_phone` String,
`create_time` DateTime,
`update_time` DateTime
)
ENGINE = MergeTree
ORDER BY user_id
SETTINGS index_granularity = 8192;
- 数据准备
┌─user_id─┬─user_phone──┬─────────create_time─┬─────────update_time─┐
│ 1 │ 13234567891 │ 2021-07-14 11:54:19 │ 2021-07-14 11:54:19 │
│ 1 │ 13234567890 │ 2021-07-14 11:40:09 │ 2021-07-14 11:40:09 │
│ 1 │ 13234567892 │ 2021-07-14 11:54:37 │ 2021-07-14 11:54:37 │
│ 2 │ 13234567893 │ 2021-07-14 11:55:05 │ 2021-07-14 11:55:05 │
│ 2 │ 13234567894 │ 2021-07-14 11:57:22 │ 2021-07-14 11:57:22 │
│ 3 │ 13234567895 │ 2021-07-14 11:57:30 │ 2021-07-14 11:57:30 │
│ 3 │ 13234567896 │ 2021-07-14 11:57:45 │ 2021-07-14 11:57:45 │
└─────────┴─────────────┴─────────────────────┴─────────────────────┘
1.2 Hive 数据准备
- 建表语句:
CREATE TABLE test.row_number
(
`user_id` string,
`user_phone` string,
`create_time` timestamp,
`update_time` timestamp
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
STORED AS textfile
LOCATION '/big-data/test/row_number';
- 数据准备:
1 13234567891 2021-07-14 11:54:19 2021-07-14 11:54:19
1 13234567890 2021-07-14 11:40:09 2021-07-14 11:40:09
1 13234567892 2021-07-14 11:54:37 2021-07-14 11:54:37
2 13234567894 2021-07-14 11:57:22 2021-07-14 11:57:22
2 13234567893 2021-07-14 11:55:05 2021-07-14 11:55:05
3 13234567896 2021-07-14 11:57:45 2021-07-14 11:57:45
3 13234567895 2021-07-14 11:57:30 2021-07-14 11:57:30
2 ROW_NUMBER()排序实现
Hive:- 实现:
SELECT
user_id,
user_phone,
create_time,
update_time,
ROW_NUMBER() OVER(PARTITION BY user_id ORDER BY update_time DESC) AS rank
FROM test.row_number
ORDER BY user_id
- 查询结果
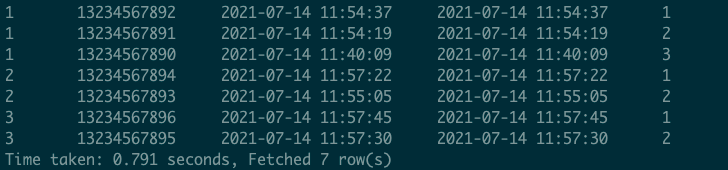
ClickHouse:- 实现:
SELECT user_id,
groupArray(user_phone) AS user_phone,
groupArray(create_time) AS create_time,
groupArray(update_time) AS update_time,
arrayEnumerate(update_time) AS row_number
FROM
(SELECT DISTINCT user_id,
user_phone,
create_time,
update_time
FROM test.row_number
ORDER BY update_time DESC
)
GROUP BY user_id
ORDER BY user_id;
- 查询结果:
┌─user_id─┬─user_phone──────────────────────────────────┬─create_time─────────────────────────────────────────────────────────┬─update_time─────────────────────────────────────────────────────────┬─row_number─┐
│ 1 │ ['13234567892','13234567891','13234567890'] │ ['2021-07-14 11:54:37','2021-07-14 11:54:19','2021-07-14 11:40:09'] │ ['2021-07-14 11:54:37','2021-07-14 11:54:19','2021-07-14 11:40:09'] │ [1,2,3] │
│ 2 │ ['13234567894','13234567893'] │ ['2021-07-14 11:57:22','2021-07-14 11:55:05'] │ ['2021-07-14 11:57:22','2021-07-14 11:55:05'] │ [1,2] │
│ 3 │ ['13234567896','13234567895'] │ ['2021-07-14 11:57:45','2021-07-14 11:57:30'] │ ['2021-07-14 11:57:45','2021-07-14 11:57:30'] │ [1,2] │
└─────────┴─────────────────────────────────────────────┴─────────────────────────────────────────────────────────────────────┴─────────────────────────────────────────────────────────────────────┴────────────┘
3 rows in set. Elapsed: 0.005 sec.

3 ROW_NUMBER()排序后取出rank=1的结果
Hive- 实现:
SELECT
user_id,
user_phone,
create_time,
update_time
FROM(
SELECT
user_id,
user_phone,
create_time,
update_time,
ROW_NUMBER() OVER(PARTITION BY user_id ORDER BY update_time DESC) AS rank
FROM test.row_number
)
WHERE rank = 1
ORDER BY user_id
- 查询结果:

ClickHouse- 实现1:利用groupArray
这种实现方式是利用了clickhouse自带函数
groupArray(n)(cloumn_name)实现。ROW_NUMBER() OVER(PARTITION BY user_id ORDER BY update_time DESC),其中排序顺序由子查询中ORDER BY update_time desc实现,分组PARTITION BY user_id由外层查询中 group by user_id实现,rank = 1通过groupArray(1)(cloumn_1)来实现。从深层次理解我们可以认为我们只是将数据放到数组中然后取出数组中的第一个元素并把它作为子数组的唯一元素。
select user_id,
groupArray(1)(user_phone) AS user_phone,
groupArray(1)(create_time) AS create_time,
groupArray(1)(update_time) AS update_time
from (select user_id,
user_phone,
create_time,
update_time
from test.row_number
ORDER BY update_time desc
) a
group by user_id
order by user_id
SELECT
user_id,
user_phone[1] AS user_phone,
create_time[1] AS create_time,
update_time[1] AS update_time
FROM
(
SELECT user_id,
groupArray(user_phone) AS user_phone,
groupArray(create_time) AS create_time,
groupArray(update_time) AS update_time
FROM
(SELECT DISTINCT user_id,
user_phone,
create_time,
update_time
FROM test.row_number
ORDER BY update_time DESC
)
GROUP BY user_id
)
ORDER BY user_id;
-
查询结果1:


-
方法2:利用max函数实现倒序,如果正序使用min函数即可
这里
ROW_NUMBER() OVER(PARTITION BY user_id ORDER BY update_time DESC),PARTITON BY由子查询中的GROUP BY实现,ORDER BY和rank = 1由子查询中max和min实现。
SELECT
user_id,
user_phone,
create_time,
update_time
FROM test.row_number
WHERE update_time in (
SELECT max(update_time) AS update_time
FROM test.row_number
GROUP BY user_id
)
ORDER BY user_id
- 查询结果2:

- 方法3:利用rowNumberInAllBlocks函数
要理解这个方式必须先了解rowNumberInAllBlocks函数结果。我们来看
SELECT
user_id,
user_phone,
create_time,
update_time,
rowNumberInAllBlocks() AS rank
FROM
(
SELECT
user_id,
user_phone,
create_time,
update_time
FROM test.row_number
ORDER BY user_id,update_time DESC
)
结果如下:

我们来看看使用
rowNumberInAllBlocks()如何实现ROW_NUMBER() OVER(PARTITION BY user_id ORDER BY update_time DESC)。由上我们看到我们通过上面的工作已经将数据整体按照user_id做正序,update_time做了倒序排序。那么接下来我们只需要将数据按照user_id进行分组取出第一条就可以了,也就是将rank为0,3,5的三条数据取出来,实现如下:
SELECT
user_id,
user_phone,
create_time,
update_time,
rank
FROM
(
SELECT
user_id,
user_phone,
create_time,
update_time,
rowNumberInAllBlocks() AS rank
FROM
(
SELECT
user_id,
user_phone,
create_time,
update_time
FROM test.row_number
ORDER BY user_id,update_time DESC
) AS a
) AS b
LIMIT 1 BY user_id
- 查询结果3:

我们发现通过使用LIMIT和BY两个关键字实现了分组和取数。自然LIMIT的作用是取数,BY作用是分组。 - 方法4:利用arrayEnumerate函数
对单字段的操作比较好比如只是选出是哪些用户,在实际业务用途不是很大,适用于类似用户生成标签的场景。
SELECT
user_id,
1 AS is_last_active_user
FROM
(
SELECT user_id,
groupArray(update_time) AS update_time,
arrayEnumerate(update_time) AS row_number
FROM
(SELECT DISTINCT user_id,
update_time
FROM test.row_number
ORDER BY update_time DESC
)
GROUP BY user_id
)
WHERE row_number[1] = 1
ORDER BY user_id;
- 查询结果:

4 场景实例分析
- 要求:
对于以下场景,需要按照user_id分组,按照update_time倒序,取最新一条,若日期一致,则随机取一条作为结果即可 - hive写法:
SELECT
user_id,
user_phone,
create_time,
update_time
FROM(
SELECT
user_id,
user_phone,
create_time,
update_time,
ROW_NUMBER() OVER(PARTITION BY user_id ORDER BY update_time DESC) AS rank
FROM test.row_number
)
WHERE rank = 1
ORDER BY user_id
- ClickHouse写法:
有网友说这个很容想到使用关联,我在这里只能说相当无语,下面我们给出该想法仅供大家吸取教训:
select a.user_id as user_id,
a.user_phone as user_phone,
a.create_time as create_time,
a.update_time as update_time
from test.row_number a
inner join (
select user_id,
groupArray(1)(update_time) as update_time
from (
select user_id,
update_time
from test.row_number
ORDER BY user_id, update_time desc
) a
group by user_id) b
on a.user_id = b.user_id
and cast(a.update_time as String) = cast(b.update_time[1] as String)
这里我们是先把符合要求的user_id和时间取出来,再回去关联,取出需要的列,因为这些函数都有一个缺点是只能有partition by的字段和排序字段,不能有其他字段,所以要返回关联,ininer join原表。虽然这种写法实现了相关操作但是不建议推荐使用,这种方式就好像是方法1未用到极致,最终实力不够,join来凑,在大多数业务场景下可能不会出现什么问题,但是在一些特定的业务或者数理场景极容易出现bug,而且join会使效率降低,这里不推荐使用。
其实看到实例的时候大家应该就笑了,我们之前的案例就是按照这个写的,这样我们自然就想到了前三种方式就可以将问题顺利解决,其实第四种使用上边的关联的思路也可以实现,但是显然是有局限性的。和上边关联的思路类似都存在这样的问题:
大家试想,如果同一个用户分组中有多条相同的数据,在与源表发生join的时候这多条数据都会被关联上,也就是我们常说的一对多关联。这就破坏了之前做的取最新一条和随机一条的操作,真是一‘招’回到解放前啊。
总结
讲到这里相信大家对于clickhouse如何实现ROW_NUMBER() OVER(PARTITION BY 'xxx' ORDER BY 'xxx' DESC/ASC)的功法已经小成,希望能够帮助大家解决实际工作中的问题。
