背景:
使用百度云云主机搭建的k8s集群,上面跑着公司的爬虫服务,开发发布新版本结束后,发现服务一直连接kafka集群在重试。
网络环境:
使用百度云vpc专线连接至我们自己的IDC机房网络,从而使pod网络和IDC机房网络打通
问题发现:

排查思路:
1.首先我们进该集群的pod中,发现ping kafka域名可以解析到ip但是确不通,但是可以看的出来DNS是没有问题的。可以正常解析出ip地址。
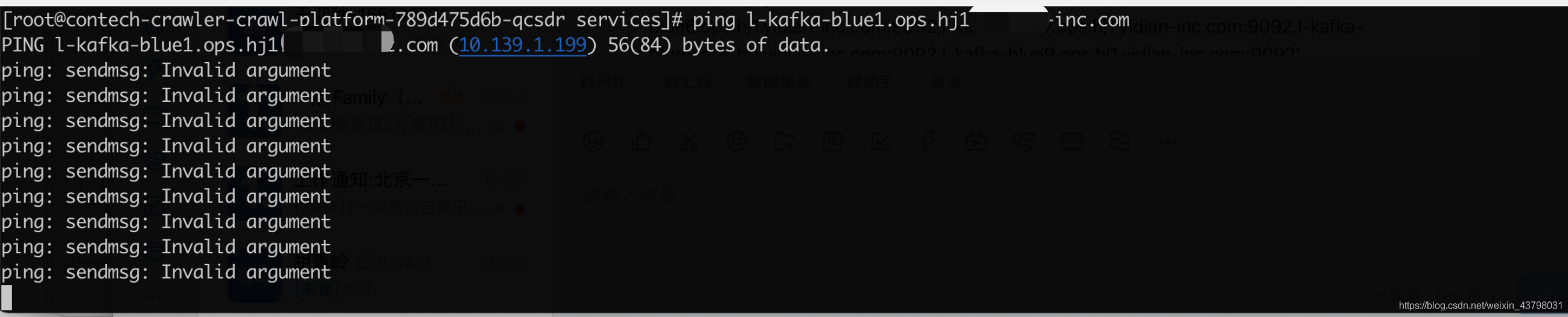
2.随后我们使用node宿主机直接去ping该地址发现居然是通的,说明百度云的宿主机和我们的IDC网络是相通的,那么基本可以确定出大概出问题的地方了。CNI网络插件、kube-proxy、因为是跨网段涉及到VPN专线路由设置。
3.之后看了CNI和kube-proxy的日志,并没有发现有任何异常,于是我们和开发进行了沟通。询问他们是否有替换其他的kafka集群,具体原因是我们公司有多套kafka消息队列,怀疑他们使用了其他网段的kafka集群。

4.问完果然没让我失望,是一个新的kafka集群,从域名可以看的出解析到了。10.139的网段。之后我们让网络组的同学去查了对应的路由条目,果然发现是没有的。同时并加上了相关的路由。
5.这时再次去pod内ping该kafka域名,发现可以通了,但是还一直在丢包。如下图
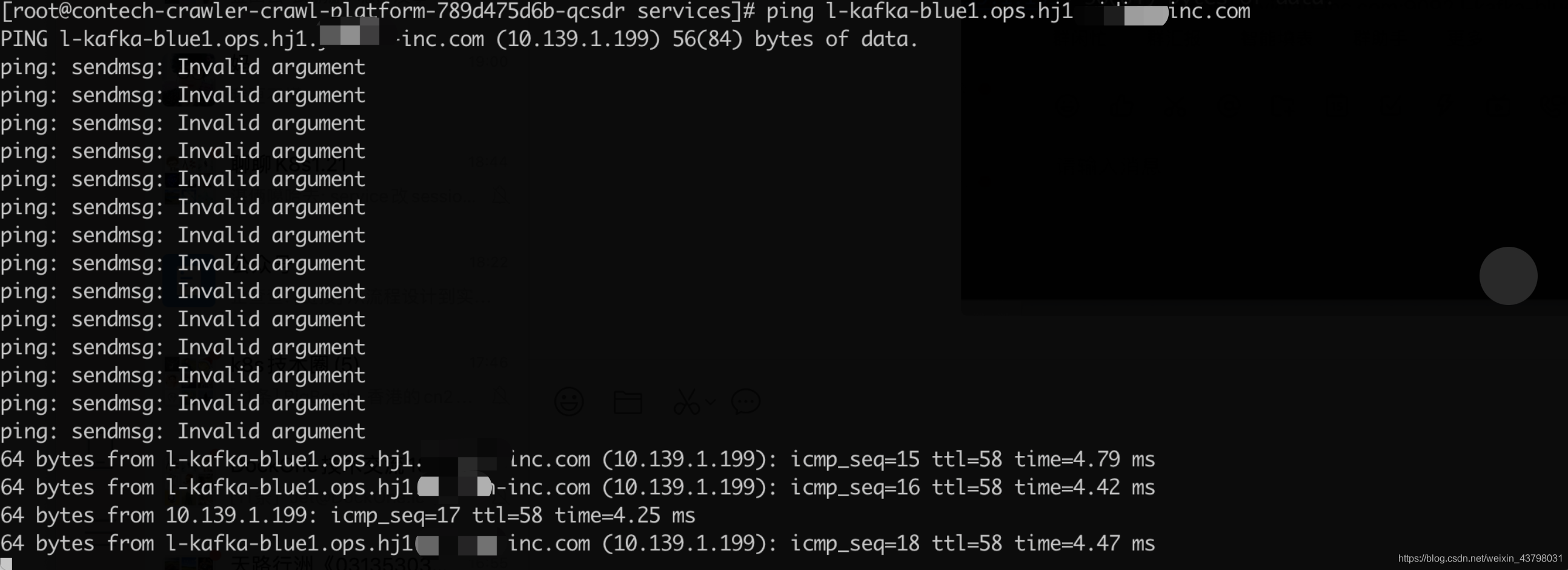
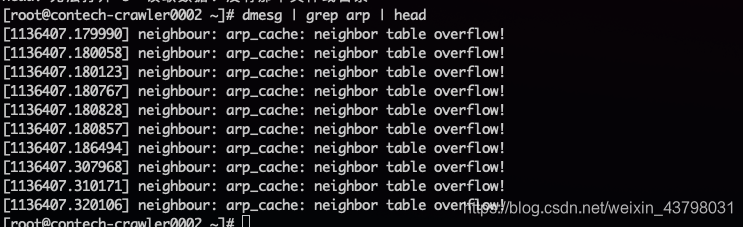
6.此时我们可以说网络已经打通了,但是一直存在丢包的现象。通过使用dmesg命令和查看/var/log/messages系统日志知道是arp表缓存溢出的问题。主要就是由于内核维护的arp表过于庞大, 发生抖动, 因此导致了这种情况。

问题解决
先接受几个内核ARP参数:
gc_stale_time
决定检查一次相邻层记录的有效性的周期。当相邻层记录失效时,将在给它发送数据前,再解析一次。缺省值是60秒。
gc_thresh1
存在于ARP高速缓存中的最少层数,如果少于这个数,垃圾收集器将不会运行。缺省值是128。
gc_thresh2
保存在 ARP 高速缓存中的最多的记录软限制。垃圾收集器在开始收集前,允许记录数超过这个数字 5 秒。缺省值是 512。
gc_thresh3
保存在 ARP 高速缓存中的最多记录的硬限制,一旦高速缓存中的数目高于此,垃圾收集器将马上运行。缺省值是1024。
比如arp -an|wc -l的结果是300左右, 那么应当调高gc_thresh各项数值,防止抖动的发生:
之后将k8s集群的每台机器都调高gc_thresh各项数值。再次ping之前的域名,发现不在丢包了。
echo 8192 > /proc/sys/net/ipv4/neigh/default/gc_thresh1
echo 16384 > /proc/sys/net/ipv4/neigh/default/gc_thresh2
echo 32768 > /proc/sys/net/ipv4/neigh/default/gc_thresh3